单目3D和bev综述
文章目录
- SOTA
- 2D 检测
- 单目3d检测
- 3d bev cam范式
- 1 Transformer attention is all you need 2017
- 2 ViT vision transformer ICLR 2021google
- 3 swin transformer 2021 ICCV bestpaper MS
- 4 DETR 2020
- 5 DETR3D 2021
- 6 PETR 2022
- 7 bevformer
- LSS
- bevdet
- caddn
- 指标 mAP NDS
- 标注:基于点云(sam自动精度差),基于nerf (生成的数据集质量差一些)
SOTA
(指标 3D mAP, NDS,分割 mIOU)
可以查看nscenes 官网
https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Camera
2D 检测
Anchor-based方案
Two-stage Detectors
RCNN
Fast RCNN
Faster RCNN
One-stage Detectors
SSD
YOLO
Anchor-free方案
FCOS
CenterNet
Transformer方案:DETR
单目3d检测
先验几何信息
自动标注: 基于sam,点云投影到图像获取点云分割 label,生成3Dboxes
3d bev cam范式
核心:视角转换
流派:
MLP: VPN,PON
LSS:BEVDET,BEVDET4D,bevdepth
Transformer: (DETR2d延伸)DETR3D, BEVFORMER, PETR, PETRV2
1 Transformer attention is all you need 2017
Transformer中selfatt和muitlhead-att
感受野大:全局交互,
位置编码:与全局交互,顺序改变自己本身attention 输出向量不受影响,这是不对的,因此要位置向量加入input
多头atten: q,k,v 进行分组,一组为一个head,然后输出 concat, 然后 输出 * Wo 得到输出
Multi-Head的优势在哪儿呢?如下图所示,绿色的部分是一个head的query和key,而红色部分则是另一个head的query和key,我们可以看出来,红色head更关注全局信息,绿色head更关注局部信息,Multi-Head的存在其实就是是的网络更加充分地利用了输入的信息:
FEED FORWARD 必要性解释,非线性映射,激活更重要的特征
- 而在Multi-Head Attention层之后还添加了一层Feed Forward层。Feed Forward层是一个两层的fully-connection层,中间隐藏层的单元个数为d_ff = 2048。这里在学习到representation之后,还要再加入一个Feed Forward的作用我的想法是:
注意到在Multi-Head Attention的内部结构中,我们进行的主要都是矩阵乘法(scaled Dot-Product Attention),即进行的都是线性变换。而线性变换的学习能力是不如非线性变化的强的,所以Multi-Head Attention的输出尽管利用了Attention机制,学习到了每个word的新representation表达,但是这种representation的表达能力可能并不强,我们仍然希望可以通过激活函数的方式,来强化representation的表达能力。比如context:The animal didn’t cross the road because it was too tired,利用激活函数,我们希望使得通过Attention层计算出的representation中,单词"it"的representation中,数值较大的部分则进行加强,数值较小的部分则进行抑制,从而使得相关的部分表达效果更好。(这也是神经网络中激活函数的作用,即进行非线性映射,加强大的部分,抑制小的部分)。我觉得这也是为什么在Attention层后加了一个Layer Normalizaiton层,通过对representation进行标准化处理,将数据移动到激活函数的作用区域,可以使得ReLU激活函数更好的发挥作用。同时在fully-connection中,先将数据映射到高维空间再映射到低维空间的过程,可以学习到更加抽象的特征,即该Feed Forward层使得单词的representation的表达能力更强,更加能够表示单词与context中其他单词之间的作用关系。




2 ViT vision transformer ICLR 2021google
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
感受野大:patch 和 patch之间 进行全局交互,提取得到 监督信号注意力集中的特征(分类的特征 区分性更大,特征辨识度更高)
位置编码:与全局交互,顺序改变自己本身attention 输出向量不受影响,这是不对的,因此要位置向量加入input
transformer 层共享,对所有输入token进行并行计算,
class token: 因为是全局交互,所以这里直接用 此 输入得到的输出 特征进行分类,并行分类
encoder内部: atten层的输入 + 输出 = 送入 norm 和MLP
多个transformer layer,

resnet + transformer

混合模型 适用于 数据少的情况


3 swin transformer 2021 ICCV bestpaper MS
https://blog.csdn.net/qq_37541097/article/details/121119988
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows



非局部 network
https://blog.csdn.net/shanglianlm/article/details/104371212
4 DETR 2020
facebook
https://github.com/facebookresearch/detr
https://blog.csdn.net/weixin_43959709/article/details/115708159

BEIT: BERT Pre-Training of Image Transformer
https://blog.csdn.net/HX_Image/article/details/119177742
viT 2021
https://arxiv.org/pdf/2010.11929
5 DETR3D 2021
https://arxiv.org/pdf/2110.06922
https://github1s.com/WangYueFt/detr3d/tree/main
2D feat --> Decoder --> 3Dpred
ref-p query
https://github.com/WangYueFt/detr3d
transformer=dict(
type='Detr3DTransformer',
decoder=dict(type='Detr3DTransformerDecoder',num_layers=6,return_intermediate=True,transformerlayers=dict(type='DetrTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),dict(type='Detr3DCrossAtten',pc_range=point_cloud_range,num_points=1,embed_dims=256)],feedforward_channels=512,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')))),
)
transformer 的层 一般6层,工业的话用3层,bevformer tiny 3层
6 PETR 2022
global attention 显存占用大
通过position embedding 利用 attention多视角图像特征关联
transformer=dict(type='PETRTransformer',decoder=dict(type='PETRTransformerDecoder',return_intermediate=True,num_layers=6,transformerlayers=dict(type='PETRTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),dict(type='PETRMultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),],feedforward_channels=2048,ffn_dropout=0.1,with_cp=True,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')),)),
7 bevformer
比PETR的 全局注意力计算少,
(一般是多路聚合)
Deformable attention ——> 内外参bev空间索引 图像特征
git clone https://github.com/megvii-research/PETR.git
LSS
bevdet
LSS + centerPoint
IDA+BDA + scale NMS
input data augmentation, bev data augmentation
caddn
LSS + 深度监督
imvoxelNet
指标 mAP NDS
标注:基于点云(sam自动精度差),基于nerf (生成的数据集质量差一些)
相关文章:
单目3D和bev综述
文章目录 SOTA2D 检测单目3d检测3d bev cam范式1 Transformer attention is all you need 20172 ViT vision transformer ICLR 2021google3 swin transformer 2021 ICCV bestpaper MS4 DETR 20205 DETR3D 20216 PETR 20227 bevformerLSSbevdetcaddn指标 mAP NDS标注:…...

每日Attention学习11——Lightweight Dilated Bottleneck
模块出处 [TITS 23] [link] [code] Lightweight Real-Time Semantic Segmentation Network With Efficient Transformer and CNN 模块名称 Lightweight Dilated Bottleneck (LDB) 模块作用 改进的编码器块 模块结构 模块代码 import torch import torch.nn as nn import to…...

EM32DX-E4 IO 扩展模块
输入:0x6000-01 // 输入 0-15 6020H——00H IN0 计数【0~7】 ——01H IN0_SetCountMode S32 r/w 初始值默认为 0 设置 IN0 的计数方式:0 电平下 降沿,1 电平上升沿, 2 电平任意沿 ——02H IN0_Set…...

【数据结构与算法】选择排序篇----详解直接插入排序和哈希排序【图文讲解】
欢迎来到CILMY23的博客 🏆本篇主题为:【数据结构与算法】选择排序篇----详解直接插入排序和哈希排序 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:Python | C | C语言 | 数据结构与算法 | 贪心算法 | Linux…...

SpringBoot实战:多表联查
1. 保存和更新公寓信息 请求数据的结构 Schema(description "公寓信息") Data public class ApartmentSubmitVo extends ApartmentInfo {Schema(description"公寓配套id")private List<Long> facilityInfoIds;Schema(description"公寓标签i…...

解决mysql,Navicat for MySQL,IntelliJ IDEA之间中文乱码
使用软件版本 jdk-8u171-windows-x64 ideaIU-2021.1.3 mysql-essential-5.0.87-win32 navicat8_mysql_cs 这个问题我调试了好久,网上的方法基本上都试过了,终于是解决了。 三个地方结果都不一样。 方法一 首先大家可以尝试下面这种方法:…...

虚拟环境操作
1、对虚拟环境的操作 查看虚拟环境列表 conda env list 创建虚拟环境 conda create -n 虚拟环境名称 python3.x 激活虚拟环境 conda activate 虚拟环境名称 退出虚拟环境 conda deactivate 删除虚拟环境 conda remove -n 虚拟环境名称 all 2、对虚拟环境下的包的操作…...

企业网三层架构
企业网三层架构:是一种层次化模型设计,旨在将复杂的网络设计分成三个层次,每个层次都着重于某些特定的功能,以提高效率和稳定性。 企业网三层架构层次: 接入层:使终端设备接入到网络中来,提供…...
)
node.js的安装及学习(node/nvm/npm的区别)
一、什么是node、nvm和npm 1.Node.js node.js 一种Javascript编程语言的运行环境,能够使得javascript能够脱离浏览器运行。以前js只能在浏览器(也就是客户端)上运行,node.js将浏览器中的javascript运行环境进行封装的,…...

性能优化篇:用WebSocket替代传统的http轮循
当我还是初级菜鸟时,我只会写定时器定时调用接口,发起http请求,定时轮训请求接口,返回最新数据,定时器开启的多了还会引起页面卡顿的性能问题,虽然及时销了但还是会影响流畅问题。然后技术leader一声令下说改成websoket的请求方式,为什么这么做呢?下面来谈谈WebSocket相…...

virtualbox的ubuntu默认ipv4地址为10.0.2.15的修改以及xshell和xftp的连接
virtualbox安装Ubuntu后,默认的地址为10.0.2.15 我们查看virtualbox的设置发现是NAT 学过计算机网络的应该了解NAT技术,为了安全以及缓解ip使用,我们留了部分私有ip地址。 私有IP地址网段如下: A类:1个A类网段&…...

Codeforces Round 957 (Div. 3)(A~D题)
A. Only Pluses 思路: 优先增加最小的数,它们的乘积会是最优,假如只有两个数a和b,b>a,那么a 1,就增加一份b。如果b 1,只能增加1份a。因为 b > a,所以增加小的数是最优的。 代码: #include<bi…...

fedora 40 安装拼音输入法
仅做参考,一般主流linux版本在安装完成后,都会自带中文输入法。而需要配置中文输入法的小众发行版往往软件仓库自带的依赖不全。 1,sudo dnf install ibus 2,sudo dnf install im-chooser 3,sudo dnf install ibus-libpinyin 4,在终端输入im-choose…...
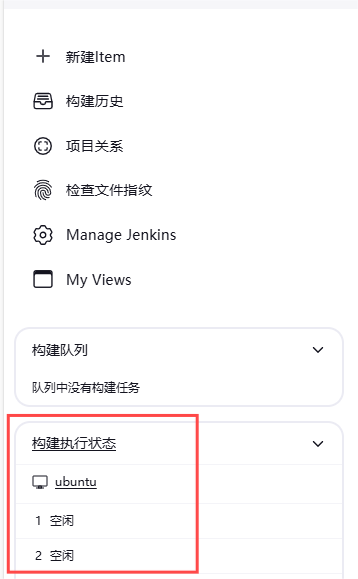
Chromium CI/CD 之Jenkins实用指南2024-如何创建新节点(三)
1. 前言 在前一篇《Jenkins实用指南2024-系统基本配置(二)》中,我们详细介绍了如何对Jenkins进行基本配置,包括系统设置、安全配置、插件管理以及创建第一个Job。通过这些配置,您的Jenkins环境已经具备了基本的功能和…...

Git代码管理工具 — 3 Git基本操作指令详解
目录 1 获取本地仓库 2 基础操作指令 2.1 基础操作指令框架 2.2 git status查看修改的状态 2.3 git add添加工作区到暂存区 2.4 提交暂存区到本地仓库 2.5 git log查看提交日志 2.6 git reflog查看已经删除的记录 2.7 git reset版本回退 2.8 添加文件至忽略列表 1 获…...
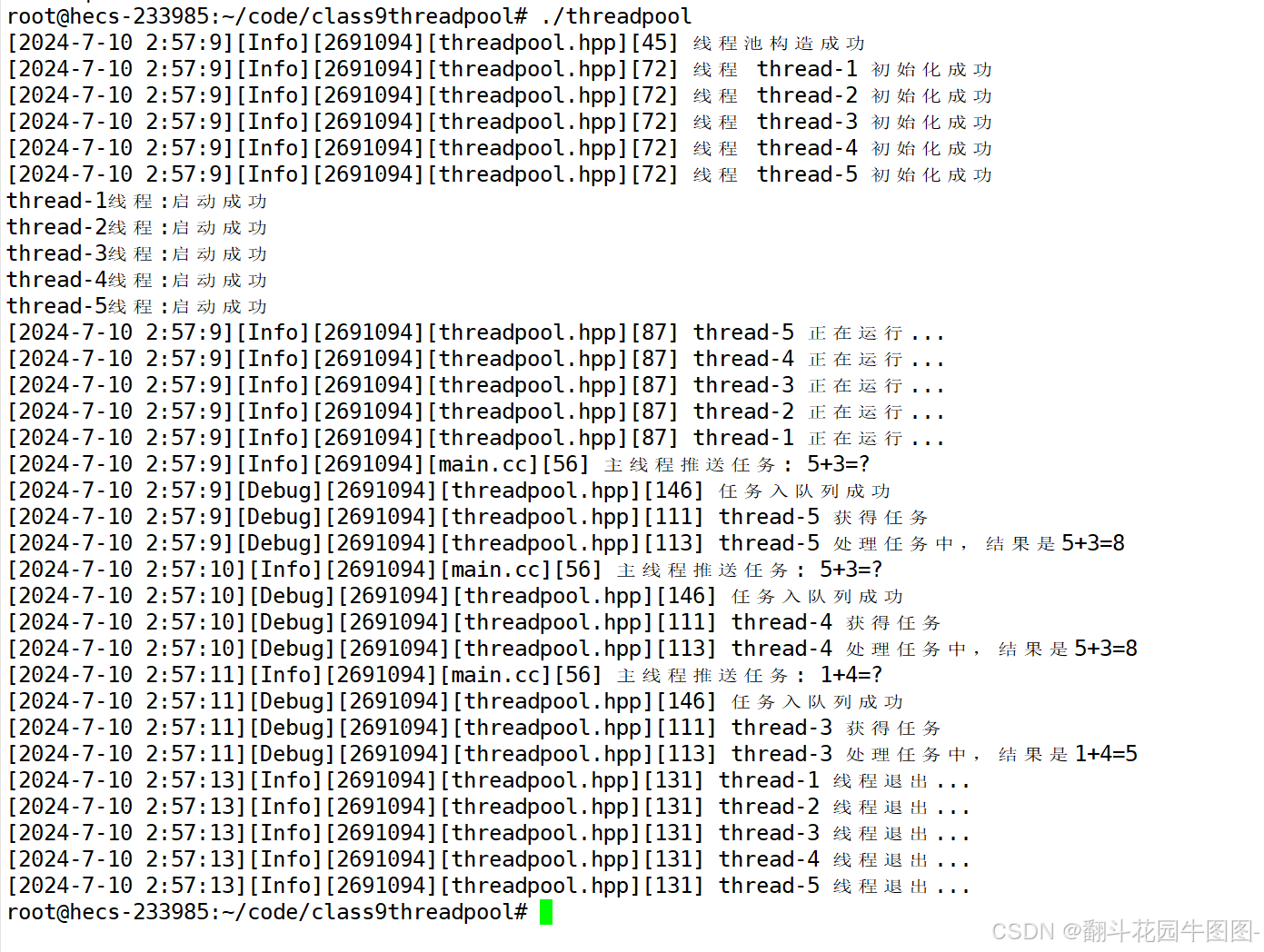
Linux——多线程(五)
1.线程池 1.1初期框架 thread.hpp #include<iostream> #include <string> #include <unistd.h> #include <functional> #include <pthread.h>namespace ThreadModule {using func_t std::function<void()>;class Thread{public:void E…...
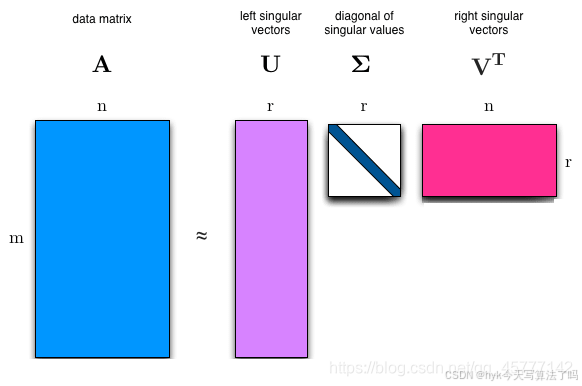
张量分解(4)——SVD奇异值分解
🍅 写在前面 👨🎓 博主介绍:大家好,这里是hyk写算法了吗,一枚致力于学习算法和人工智能领域的小菜鸟。 🔎个人主页:主页链接(欢迎各位大佬光临指导) ⭐️近…...

第三方配件也能适配苹果了,iOS 18与iPadOS 18将支持快速配对
苹果公司以其对用户体验的不懈追求和对创新技术的不断探索而闻名。随着iOS 18和iPadOS 18的发布,苹果再次证明了其在移动操作系统领域的领先地位。 最新系统版本中的一项引人注目的功能,便是对蓝牙和Wi-Fi配件的配对方式进行了重大改进,不仅…...

Docker 部署 Nginx 并在容器内配置申请免费 SSL 证书
文章目录 dockerdocker-compose.yml申请免费 SSL 证书请求头参数带下划线 docker https://hub.docker.com/_/nginx docker pull nginx:1.27注: 国内网络原因无法下载镜像,nginx 镜像文件下载链接 https://pan.baidu.com/s/1O35cPbx6AHWUJL1v5-REzA?pw…...
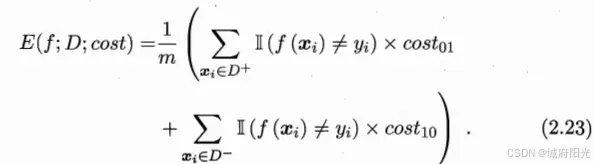
模型评估与选择
2.1 经验误差与过拟合 错误率(error rate): 分类错误的样本数占样本总数的比例 精度(accuracy):1- 错误率 训练误差 / 经验误差:在训练集上的误差 泛化误差:在新样本上的误差 过…...

MDK Middleware网络组件的嵌入式安全防护解析
1. MDK Middleware网络组件的安全特性解析在嵌入式系统开发中,网络安全往往是最容易被忽视却又至关重要的环节。作为Keil MDK开发环境的核心组件,Middleware Network为Cortex-M系列微控制器提供了轻量级TCP/IP协议栈实现。不同于桌面级操作系统自带的网络…...

AI 安全生产管理平台:用数字技术筑牢企业安全防线
传统企业安全生产长期依赖“人工巡检、事后整改”的模式,人工排查存在疲劳漏检、响应滞后、标准不一等痛点,很难全天候守住生产安全底线。而 AI 安全生产管理平台依托人工智能、物联网、边缘计算、大数据等核心技术,彻底打破传统“人防”局限…...

【收藏必备】2026 版大语言模型入门详解:小白 程序员快速上手 LLM 核心原理
大语言模型(LLM)是 2026 年生成式 AI 与智能体(Agent)时代的核心基石,本文系统拆解其发展脉络、应用全流程与完整构建逻辑。从自监督预训练、指令微调至人类反馈强化学习(RLHF),逐层…...

5分钟掌握SVGnest:免费开源矢量嵌套工具,让材料切割效率提升80%
5分钟掌握SVGnest:免费开源矢量嵌套工具,让材料切割效率提升80% 【免费下载链接】SVGnest An open source vector nesting tool 项目地址: https://gitcode.com/gh_mirrors/sv/SVGnest SVGnest是一款完全免费且开源的自动嵌套应用程序,…...

Lovable不是UI美化!揭秘神经科学验证的4层用户依恋模型与落地SDK架构
更多请点击: https://intelliparadigm.com 第一章:Lovable不是UI美化!揭秘神经科学验证的4层用户依恋模型与落地SDK架构 Lovable并非视觉动效堆砌,而是基于fMRI与眼动追踪实验验证的神经认知路径——当用户在300ms内完成「感知→…...

终极AMD Ryzen调试工具:SMUDebugTool完全使用指南
终极AMD Ryzen调试工具:SMUDebugTool完全使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

矿山灾害应急回溯:UWB离线即失联,无感定位全程轨迹留存
矿山灾害应急回溯:UWB离线即失联,无感定位全程轨迹留存矿山井下塌方、瓦斯超限、透水、顶板垮落等突发性灾害具备极强不可预判性,灾害发生后极易伴随断电断网、通信中断、组网瘫痪等状况。应急轨迹回溯、人员位置核查、救援路线规划ÿ…...

FactoryBluePrints:戴森球计划终极蓝图仓库,5步打造高效自动化工厂
FactoryBluePrints:戴森球计划终极蓝图仓库,5步打造高效自动化工厂 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 你是否曾在戴森球计划中花费数小…...

3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移
3分钟快速上手:用ComfyUI-MimicMotionWrapper实现专业级AI动作迁移 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper 你是否曾梦想过让普通人也能跳出专业舞者的优美动作?…...

Burp Suite渗透测试工作流:从环境搭建到报告生成
1. 这不是“学个工具”,而是一套可复用的渗透工作流很多人点开“Burp Suite 入门”类教程,心里想的是:“装个插件、抓个包、改个参数,不就完事了?”——结果三天后连 repeater 怎么发 POST 请求都得翻笔记。我带过二十…...