N6 word2vec文本分类
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊# 前言
前言
上周学习了训练word2vec模型,这周进行相关实战
1. 导入所需库和设备配置
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd
2. 加载数据
train_data = pd.read_csv('./train.csv', sep='\t', header=None)
print(train_data)
3. 数据预处理
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, yx = train_data[0].values[:]
y = train_data[1].values[:]from gensim.models.word2vec import Word2Vec
import numpy as npw2v = Word2Vec(vector_size=100, min_count=3)
w2v.build_vocab(x)
w2v.train(x, total_examples=w2v.corpus_count, epochs=20)
- 定义自定义数据迭代器
coustom_data_iter。 - 提取文本和标签数据。
- 使用
Word2Vec训练词向量模型,设置词向量维度为100,最小词频为3。
def average_vec(text):vec = np.zeros(100).reshape((1, 100))for word in text:try:vec += w2v.wv[word].reshape((1, 100))except KeyError:continuereturn vecx_vec = np.concatenate([average_vec(z) for z in x])
w2v.save('w2v_model.pkl')train_iter = coustom_data_iter(x_vec, y)
print(len(x), len(x_vec))
label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: average_vec(x)
label_pipeline = lambda x: label_name.index(x)print(text_pipeline("你在干嘛"))
print(label_pipeline("Travel-Query"))
- 定义函数
average_vec,将文本转换为词向量的平均值。 - 将所有文本转换为词向量并保存
Word2Vec模型。 - 打印文本和向量的数量,以及所有标签的名称。
- 定义文本和标签的预处理函数
text_pipeline和label_pipeline。
4. 数据加载器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list = [], []for (_text, _label) in batch:label_list.append(label_pipeline(_label))processed_text = torch.tensor(text_pipeline(_text), dtype=torch.float32)text_list.append(processed_text)label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)return text_list.to(device), label_list.to(device)dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch)
- 定义函数
collate_batch,将批次中的文本和标签转换为张量。 - 创建数据加载器
dataloader。
5. 定义模型
class TextClassificationModel(nn.Module):def __init__(self, num_class):super(TextClassificationModel, self).__init__()self.fc = nn.Linear(100, num_class)def forward(self, text):return self.fc(text)num_class = len(label_name)
model = TextClassificationModel(num_class).to(device)
- 定义文本分类模型
TextClassificationModel,包含一个全连接层。 - 初始化模型,设置输出类别数。
6. 训练和评估函数
import timedef train(dataloader):model.train()total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label) in enumerate(dataloader):predicted_label = model(text)optimizer.zero_grad()loss = criterion(predicted_label, label)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)optimizer.step()total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches | train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx, len(dataloader), total_acc / total_count, train_loss / total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval()total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text, label) in enumerate(dataloader):predicted_label = model(text)loss = criterion(predicted_label, label)total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc / total_count, train_loss / total_count
- 定义训练函数
train和评估函数evaluate。
7. 训练模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_datasetEPOCHS = 10
LR = 5
BATCH_SIZE = 64criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = Nonetrain_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset, [int(len(train_dataset) * 0.8), int(len(train_dataset) * 0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| epoch {:1d} | time: {:4.2f}s | valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为:{:5.4f}'.format(test_acc))
- 定义超参数并初始化损失函数、优化器和学习率调度器。
- 创建数据集并进行训练集和验证集的划分。
- 训练模型并在每个epoch后进行验证。
8. 预测函数
def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text), dtype=torch.float32)print(text.shape)output = model(text)return output.argmax(1).item()ex_text_str = "还有双鸭山到淮阴的汽车票吗13号的"
model = model.to("cpu")
print("该文本的类别是:%s" % label_name[predict(ex_text_str, text_pipeline)])
- 定义预测函数
predict,将文本转换为张量并使用模型进行预测。 - 使用示例文本进行预测并输出结果。
结果

总结
这周学习了通过word2vec文本分类,包括数据加载、预处理、模型训练、评估和预测。进一步加深了对word2vec的理解。
相关文章:
N6 word2vec文本分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊# 前言 前言 上周学习了训练word2vec模型,这周进行相关实战 1. 导入所需库和设备配置 import torch import torch.nn as nn import torchvision …...
excel、word、ppt 下载安装步骤整理
请按照我的步骤开始操作,注意以下截图红框标记处(往往都是需要点击的地方) 第一步:下载 首先进入office下载网址: otp.landian.vip 然后点击下载 拉到下方 下载站点(这里根据自己的需要选择下载&#x…...

【python学习】标准库之日期和时间库定义、功能、使用场景和示例
引言 datetime模块最初是由 Alex Martelli 在 Python 2.3 版本引入的,目的是为了解决之前版本中处理日期和时间时存在的限制和不便 在datetime模块出现之前,Python 主要使用time模块来处理时间相关的功能,但 time模块主要基于 Unix 纪元时间&…...

Android --- Kotlin学习之路:基础语法学习笔记
------>可读可写变量 var name: String "Hello World";------>只读变量 val name: String "Hello World"------>类型推断 val name: String "Hello World" 可以写成 val name "Hello World"------>基本数据类型 1…...
嵌入式智能手表项目实现分享
简介 这是一个基于STM32F411CUE6和FreeRTOS和LVGL的低成本的超多功能的STM32智能手表~ 推荐 如果觉得这个手表的硬件难做,又想学习相关的东西,可以试下这个新出的开发板,功能和例程demo更多!FriPi炸鸡派STM32F411开发板: 【STM32开发板】 FryPi炸鸡派 - 嘉立创EDA开源硬件平…...

`nmap`模块是一个用于与Nmap安全扫描器交互的库
在Python中,nmap模块是一个用于与Nmap安全扫描器交互的库。Nmap(Network Mapper)是一个开源工具,用于发现网络上的设备和服务。虽然Python的nmap模块可能不是官方的Nmap库(因为Nmap本身是用C/C编写的)&…...

JVM系列 | 对象的创建与存储
JVM系列 | 对象的生命周期1 对象的创建与存储 文章目录 前言对象的创建过程内存空间的分配方式方式1 | 指针碰撞方式2 | 空闲列表 线程安全问题 | 避免空间冲突的方式方式1 | 同步处理(加锁)方式2 | 本地线程分配缓存 对象的内存布局Part1 | 对象头Mark Word类型指针…...

【JavaScript 算法】快速排序:高效的排序算法
🔥 个人主页:空白诗 文章目录 一、算法原理二、算法实现三、应用场景四、优化与扩展五、总结 快速排序(Quick Sort)是一种高效的排序算法,通过分治法将数组分为较小的子数组,递归地排序子数组。快速排序通常…...

Excel如何才能忽略隐藏行进行复制粘贴?
你有没有遇到这样的情况:数据很多,将一些数据隐藏后,进行复制粘贴,结果发现粘贴后的内容仍然将整个数据都显示出来了!那么,Excel如何才能忽略隐藏行进行复制粘贴? 打开你的Excel表格 Excel如何…...

行人越界检测 越线 越界区域 多边形IOU越界判断
行人越界判断 越界判断方式:(1)bbox中心点越界(或自定义)(2)交并比IoU判断 越界类型:(1)越线 (2)越界区域 1.越线判断 bbox中心点xc、…...

「UCD」浅谈蓝湖Figma交互设计对齐
在现代数字产品的设计和开发过程中,选择合适的工具对于提高团队效率和保证产品质量至关重要。本文将从开发和设计两个不同的角度,探讨蓝湖和Figma两款流行工具的优势与不足,并提出结论和建议。 开发研发视角:蓝湖 优点: 清晰的设计规范:蓝湖为开发工程师提供了清晰的设计…...

VUE3 播放RTSP实时、回放(NVR录像机)视频流(使用WebRTC)
1、下载webrtc-streamer,下载的最新window版本 Releases mpromonet/webrtc-streamer GitHub 2、解压下载包 3、webrtc-streamer.exe启动服务 (注意:这里可以通过当前文件夹下用cmd命令webrtc-streamer.exe -o这样占用cpu会很少,…...

[PaddlePaddle飞桨] PaddleOCR-光学字符识别-小模型部署
PaddleOCR的GitHub项目地址 推荐环境: PaddlePaddle > 2.1.2 Python > 3.7 CUDA > 10.1 CUDNN > 7.6pip下载指令: python -m pip install paddlepaddle-gpu2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install paddleocr2.7…...

Python应用开发——30天学习Streamlit Python包进行APP的构建(15):优化性能并为应用程序添加状态
Caching and state 优化性能并为应用程序添加状态! Caching 缓存 Streamlit 为数据和全局资源提供了强大的缓存原语。即使从网络加载数据、处理大型数据集或执行昂贵的计算,它们也能让您的应用程序保持高性能。 本页仅包含有关 st.cache_data API 的信息。如需深入了解缓…...

python实现openssl的EVP_BytesToKey及AES_256_CBC加解密算法
python实现openssl EVP_BytesToKey(EVP_aes_256_cbc(), EVP_md5(), NULL, pass, passlen, 1, key, iv); 并实现AES 256 CBC加解密. # encoding:utf-8import base64 from Crypto.Cipher import AES from Crypto import Random from hashlib import md5def EVP_BytesToKey(passw…...

基于SpringBoot+VueJS+微信小程序技术的图书森林共享小程序设计与实现
注:每个学校每个老师对论文的格式要求不一样,故本论文只供参考,本论文页数达到60页以上,字数在6000及以上。 基于SpringBootVueJS微信小程序技术的图书森林共享小程序设计与实现 目录 基于SpringBootVueJS微信小程序技术的图书森…...
【css】image 使用 transform:scale 放大后显示不全的问题
css 可以用 transform: scale(1.2) 实现图片放大 1.2 倍显示的功能,在此基础上可以修改 transform-origin 为用户点击的坐标值优化体验。问题在于 origin 位于图片下方时,图片放大后出现滚动条,而滚动条的高度会忽略放大显示的图片的上半部分…...

损失函数简介
损失函数(Loss Function)是机器学习中用来衡量模型预测值与真实值之间差异的函数。在训练过程中,通过最小化损失函数来优化模型的参数,以提高模型的预测准确性。 以下是损失函数的主要用途和一些常用的损失函数类型: 损失函数的用途: 评估模型性能:损失函数提供了一个…...
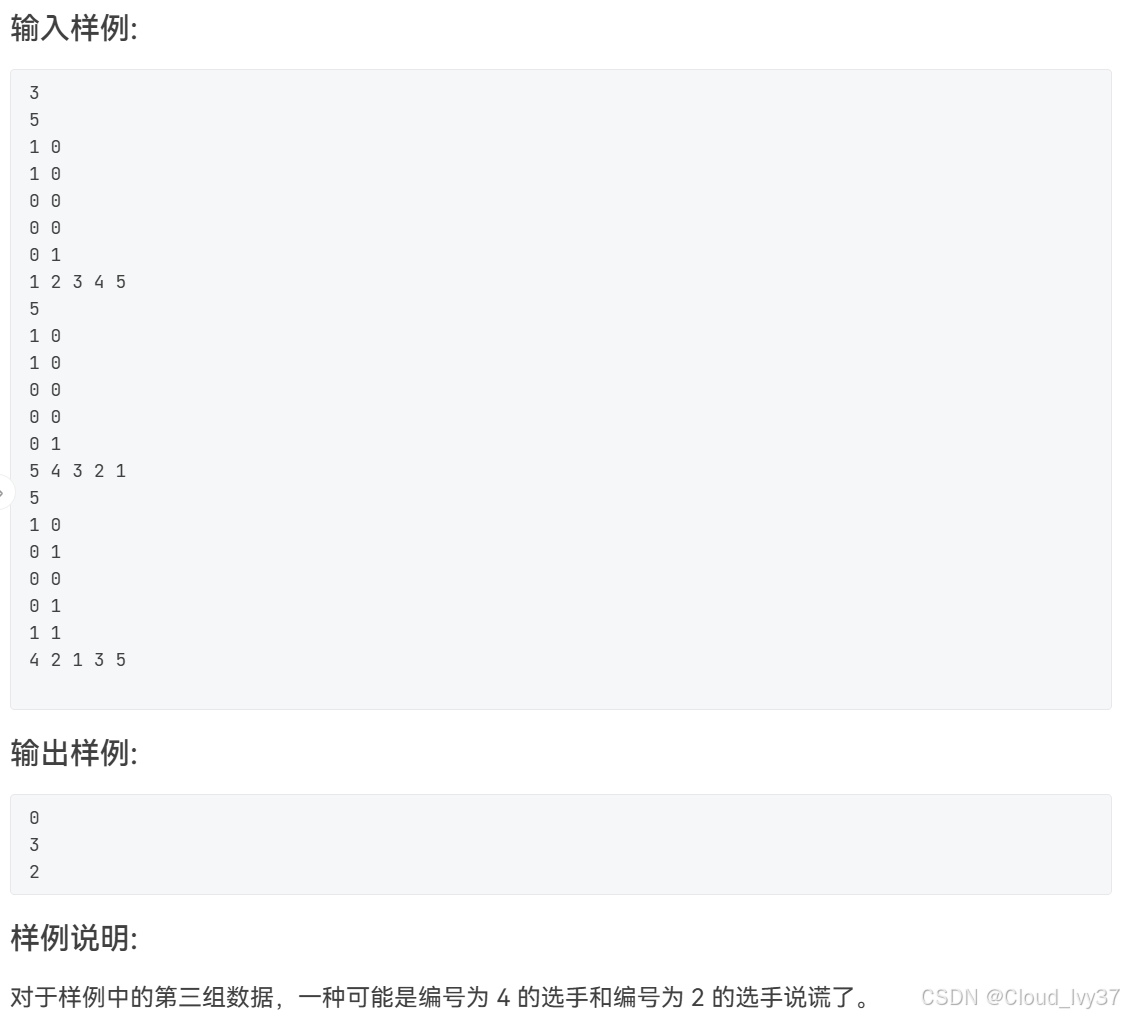
2023睿抗CAIP-编程技能赛-本科组省赛(c++)
RC-u1 亚运奖牌榜 模拟 AC: #include<iostream> using namespace std; struct nation{int j,y,t; }a[2]; int main(){int n;cin>>n;for(int i1;i<n;i){int x,y;cin>>x>>y;if(y1) a[x].j;if(y2) a[x].y;if(y3) a[x].t;}cout<<a[0].j<<&…...

现在国内的ddos攻击趋势怎么样?想了解现在ddos的情况该去哪看?
目前,国内的DDoS攻击趋势显示出以下几个特征: 攻击频次显著增加:根据《快快网络2024年DDoS攻击趋势白皮书》,2023年DDoS攻击活动有显著攀升,总攻击次数达到1246.61万次,比前一年增长了18.1%。 攻击强度和规…...

泉盛UV-K5/K6对讲机专业级固件定制与功能扩展指南
泉盛UV-K5/K6对讲机专业级固件定制与功能扩展指南 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 泉盛UV-K5/K6对讲机LOSEHU固件是一款基于多个开…...

终极CompreFace人脸识别模型实战指南:5大场景选型与部署方案
终极CompreFace人脸识别模型实战指南:5大场景选型与部署方案 【免费下载链接】CompreFace Leading free and open-source face recognition system 项目地址: https://gitcode.com/gh_mirrors/co/CompreFace CompreFace作为领先的免费开源人脸识别系统&#…...

揭秘FPGA内部世界:PrjXRay开源工具完整指南
揭秘FPGA内部世界:PrjXRay开源工具完整指南 【免费下载链接】prjxray Documenting the Xilinx 7-series bit-stream format. 项目地址: https://gitcode.com/gh_mirrors/pr/prjxray 你是否曾好奇FPGA芯片内部的神秘世界?那些二进制位流背后究竟隐…...

Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南
Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop Debian版是一款为Linux系…...

sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 [特殊字符]
sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 🚀 【免费下载链接】sdk-manager-plugin DEPRECATED Gradle plugin which downloads and manages your Android SDK. 项目地址: https://gitcode.com/gh_mirrors/sd/sdk-manager-plugin …...

Android Framework 1
Android Framework 1环境准备Ubuntu 环境配置下载安卓源码编译源码Android Studio 环境编译环境准备 VMware WorkStation Pro 17.6.4 Ubuntu 20.04 安卓源码官方地址 Ubuntu 环境配置 1.安装必须的软件包 sudo apt-get install git-core gnupg flex bison build-essential …...

为什么92%的社交App在AI Agent接入后用户停留时长暴跌?——资深架构师亲授5层调优框架
更多请点击: https://kaifayun.com 第一章:为什么92%的社交App在AI Agent接入后用户停留时长暴跌? 当AI Agent以“智能助手”“聊天搭子”“情绪陪伴者”等名义大规模嵌入社交App时,产品团队普遍预期用户活跃度与停留时长将显著提…...

为什么82%的保险AI Agent项目卡在POC阶段?一线技术总监首度公开6个致命设计盲区
更多请点击: https://codechina.net 第一章:为什么82%的保险AI Agent项目卡在POC阶段? 保险行业正加速拥抱AI Agent技术,但据2024年《亚太保险科技落地白皮书》统计,82%的AI Agent项目在概念验证(POC&…...

智能网络资源下载器:轻松捕获微信、抖音、小红书等平台内容
智能网络资源下载器:轻松捕获微信、抖音、小红书等平台内容 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

第P5周:Pytorch实现运动鞋识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人体悟:今天学习了动态学习率有种豁然开朗的感觉,在引入该部分之后模型的学习速度和学习质量都得到了较大提升!...