采用自动微分进行模型的训练
自动微分训练模型
简单代码实现:
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的线性回归模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(1, 1) # 输入维度是1,输出维度也是1def forward(self, x):return self.linear(x)# 准备训练数据
x_train = torch.tensor([[1.0], [2.0], [3.0]])
y_train = torch.tensor([[2.0], [4.0], [6.0]])# 实例化模型、损失函数和优化器
model = LinearRegression()
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器# 训练模型
epochs = 1000
for epoch in range(epochs):# 前向传播outputs = model(x_train)loss = criterion(outputs, y_train)# 反向传播optimizer.zero_grad() # 清空之前的梯度loss.backward() # 自动计算梯度optimizer.step() # 更新模型参数if (epoch+1) % 100 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')# 测试模型
x_test = torch.tensor([[4.0]])
predicted = model(x_test)
print(f'预测值: {predicted.item():.4f}')
代码分解:
1.定义一个简单的线性回归模型:
LinearRegression类继承自nn.Module,这是所有神经网络模型的基类。- 在
__init__方法中,定义了一个线性层self.linear,它的输入维度是1,输出维度也是1。 forward方法定义了数据在模型中的传播路径,即输入x经过self.linear层后得到输出。class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(1, 1) # 输入维度是1,输出维度也是1def forward(self, x):return self.linear(x)
2.准备训练数据:
x_train和y_train分别是输入和目标输出的训练数据。每个张量表示一个样本,x_train中的每个元素是一个维度为1的张量,因为模型的输入维度是1。x_train = torch.tensor([[1.0], [2.0], [3.0]]) y_train = torch.tensor([[2.0], [4.0], [6.0]])
3.实例化模型,损失函数和优化器:
model是我们定义的LinearRegression类的一个实例,即我们要训练的线性回归模型。criterion是损失函数,这里选择了均方误差损失(MSE Loss),用于衡量预测值与实际值之间的差异。optimizer是优化器,这里选择了随机梯度下降(SGD),用于更新模型参数以最小化损失。model = LinearRegression() criterion = nn.MSELoss() # 均方误差损失函数 optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
4.训练模型:
- 这里进行了1000次迭代的训练过程。
- 在每个迭代中,首先进行前向传播,计算模型对
x_train的预测输出outputs,然后计算损失loss。 - 调用
optimizer.zero_grad()来清空之前的梯度,然后调用loss.backward()自动计算梯度,最后调用optimizer.step()来更新模型参数。epochs = 1000 for epoch in range(epochs):# 前向传播outputs = model(x_train)loss = criterion(outputs, y_train)# 反向传播optimizer.zero_grad() # 清空之前的梯度loss.backward() # 自动计算梯度optimizer.step() # 更新模型参数if (epoch+1) % 100 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
5.测试模型:
x_test是用来测试模型的输入数据,这里表示输入为4.0。model(x_test)对x_test进行前向传播,得到预测结果predicted。predicted.item()取出预测结果的标量值并打印出来。x_test = torch.tensor([[4.0]]) predicted = model(x_test) print(f'预测值: {predicted.item():.4f}')
运行结果:
运行结果如下:
相关文章:

采用自动微分进行模型的训练
自动微分训练模型 简单代码实现: import torch import torch.nn as nn import torch.optim as optim# 定义一个简单的线性回归模型 class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear nn.Linear(1, 1) …...

k8s怎么配置secret呢?
在Kubernetes中,配置Secret主要涉及到创建、查看和使用Secret的过程。以下是配置Secret的详细步骤和相关信息: ### 1. Secret的概念 * Secret是Kubernetes用来保存密码、token、密钥等敏感数据的资源对象。 * 这些敏感数据可以存放在Pod或镜像中&#x…...

算法篇 滑动窗口 leetcode 长度最小的子数组
长度最小的子数组 1. 题目描述2. 算法图分析2.1 暴力图解2.2 滑动窗口图解 3. 代码演示 1. 题目描述 2. 算法图分析 2.1 暴力图解 2.2 滑动窗口图解 3. 代码演示...

数据库作业d8
要求: 一备份 1 mysqldump -u root -p booksDB > booksDB_all_tables.sql 2 mysqldump -u root -p booksDB books > booksDB_books_table.sql 3 mysqldump -u root -p --databases booksDB test > booksDB_and_test_databases.sql 4 mysql -u roo…...
前后端数据交互设计到的跨域问题
前后端分离项目的跨域问题及解决办法 一、跨域简述 1、问题描述 这里前端vue项目的端口号为9000,后端springboot项目的端口号为8080 2、什么是跨域 当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域 当前页面url被请求页面url是否…...

非洲猪瘟监测设备的作用是什么?
TH-H160非洲猪瘟监测设备的主要作用是迅速、准确地检测出非洲猪瘟病毒,从而帮助控制和预防疫情的扩散。这些设备利用先进的生物传感技术和PCR分子生物学方法,能够在极短的时间内提供精确的检测结果<sup>1</sup><sup>2</sup><…...

移动硬盘损坏无法读取?专业恢复策略全解析
在数字化信息爆炸的今天,移动硬盘作为我们存储和传输大量数据的重要工具,其安全性和稳定性直接关系到个人与企业的数据安全。然而,当移动硬盘突然遭遇损坏,无法正常读取时,我们该如何应对?本文将深入探讨移…...

神经网络以及简单的神经网络模型实现
神经网络基本概念: 神经元(Neuron): 神经网络的基本单元,接收输入,应用权重并通过激活函数生成输出。 层(Layer): 神经网络由多层神经元组成。常见的层包括输入层、隐藏层…...
)
java中压缩文件的解析方式(解析文件)
背景了解:java中存在IO流的方式,支持我们对文件进行读取(Input,从磁盘到内存)或写入(output,从内存到磁盘),那么我们在面对 “zip”格式或者 “rar” 格式的压缩文件&…...

巧用 VScode 网页版 IDE 搭建个人笔记知识库!
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 巧用 VScode 网页版 IDE 搭建个人笔记知识库! 描述:最近自己在腾讯云轻量云服务器中部署了一个使用在线 VScode 搭建部署的个人Markdown在线笔记,考虑到在线 VScode 支持终…...

Jupyter Lab 使用
Jupyter Lab 使用详解 Jupyter Lab 是一个基于 Web 的交互式开发环境,提供了比 Jupyter Notebook 更加灵活和强大的用户界面和功能。以下是使用 Jupyter Lab 的详细指南,包括安装、基本使用、设置根目录和扩展功能等内容。 一、Jupyter Lab 安装与启动…...
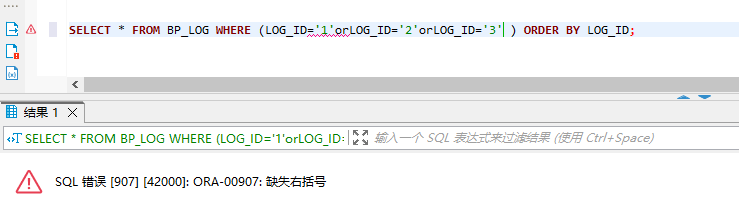
MyBatis where标签内嵌foreach标签查询报错‘缺失右括号‘或‘命令未正确结束‘
MyBatis <where>标签内嵌<foreach>标签查询报错’缺失右括号’或’命令未正确结束’ <where>标签内嵌<foreach>标签 截取一段脱敏xml,写明大概意思 <select id"queryLogByIds" resultMap"BaseResultMap">SELE…...

重生奇迹MU 群战王牌
圣导师是重生奇迹MU游戏中八大职业之一,拥有风度翩翩、潇洒自如的形象和神一样的实力。无论是刷怪、PK、打boss还是混战,圣导师都表现出压制其他职业的强大气势。因此,这个职业在游戏中备受欢迎,人气非常高。 实力强大的二代隐藏…...

SpinalHDL之VHDL 和 Verilog 生成
本文作为SpinalHDL学习笔记第十六篇,记录使用SpinalHDL代码生成Verilog/VHDL代码的方法。 SpinalHDL学习笔记总纲链接如下: SpinalHDL 学习笔记_spinalhdl blackbox-CSDN博客 目录: 1.从 SpinalHDL 组件生成 VHDL 和 Verilog 2.生成的 VHD…...

c语言中的字符串函数
strstr函数 函数介绍 strstr 用于在一个字符串中查找另一个字符串的首次出现。 我们来看这个函数的参数名字:haysytack(干草堆)needle(针),这个其实就是外国的一句谚语:在干草堆中找一根针,就…...

[AI 大模型] 百度 文心一言
文章目录 [AI 大模型] 百度 文心一言简介模型架构发展新技术和优势API 代码示例 [AI 大模型] 百度 文心一言 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0DwAIh0T-1720667576892)(https://i-blog.csdnimg.cn/direct/283919e5d78b4951ba1ade5dcfc…...

机器学习开源分子生成系列(2)-基于三维形状和静电相似性的DeepFMPO v3D安装及使用
前言 本文是基于 3D 的分子生成方法DeepFMPO v3D的介绍及安装使用。 一、DeepFMPO v3D是什么? github代码介绍文章 在药物发现中,如何寻找具新颖性和结构多样性的候选分子是颇受药物设计科学家关注的问题。通过虚拟筛选的化学空间搜索往往会受限于筛选…...

机器学习-16-分布式梯度提升库XGBoost的应用
参考XGBoost库 1 XGBoost分布式梯度提升库 XGBoost,全称为eXtreme Gradient Boosting,是一个优化的分布式梯度提升库,旨在高效、灵活且便携。它在Gradient Boosting框架下实现了机器学习算法,并广泛用于分类、回归和排序任务。XGBoost之所以受到广泛欢迎,主要归功于它的…...

视觉/AIGC面经->多模态
1.ocr检测如何做?qwen的文本检测是否合理? paligemma: <loc0110><loc0124><loc0224><loc0389> plate ; <loc0244><loc0130><loc0281><loc0430> plate ; <loc0364><loc0820><loc0403><loc0951> pl…...

<数据集>钢板缺陷检测数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:1986张 标注数量(xml文件个数):1986 标注数量(txt文件个数):1986 标注类别数:7 标注类别名称:[crescent gap, silk spot, water spot, weld line, oil spot, punchin…...

DPmoire:为莫尔超晶格定制高精度机器学习力场的自动化方案
1. 项目概述:当莫尔物理遇上机器学习力场 在凝聚态物理和计算材料科学的前沿,莫尔(Moir)超晶格系统正以其丰富而奇特的物理现象吸引着全球研究者的目光。通过简单地扭转两层二维材料(如石墨烯或过渡金属硫族化合物&…...

保姆级教程:用Python脚本把UAVDT无人机数据集转成YOLOv5/YOLOv8能用的格式
无人机视觉实战:UAVDT数据集高效转YOLO格式全流程解析无人机目标检测正成为计算机视觉领域的热门方向,而UAVDT作为最具代表性的低空无人机检测数据集,其丰富的场景覆盖和精准标注使其成为算法验证的黄金标准。但原始数据与YOLO训练格式的不匹…...

UE5 GPU崩溃真相:Windows TCC超时机制与注册表调优指南
1. 为什么UE5项目一跑就GPU崩溃,而系统却说“显卡没出问题”?你刚在UE5里搭好一个带Niagara粒子Lumen全局光照的场景,点下Play,画面卡住两秒,然后整个编辑器黑屏、崩溃,任务管理器里UnrealEditor进程直接消…...
Spark Transformer:稀疏化技术提升大模型计算效率
1. Spark Transformer架构解析在深度学习领域,Transformer模型已经成为自然语言处理和多模态任务的事实标准架构。然而,随着模型规模的不断扩大和序列长度的持续增长,计算效率问题日益突出。2025年提出的Spark Transformer通过创新性地重新激…...
)
从纸质报表到Excel:PaddleOCR+Python自动化识别复杂表格(附完整代码)
金融表格自动化革命:用PaddleOCRPython实现纸质报表秒转Excel每次月末结算时,财务部的张经理总要面对堆积如山的纸质报表——供应商对账单、银行流水单、税务申报表,这些表格往往带有手写注释、合并单元格和模糊印章。传统的人工录入不仅耗时…...

AI医疗Agent如何72小时通过NMPA二类证审批:附2024最新审评问答清单与材料模板
更多请点击: https://intelliparadigm.com 第一章:AI医疗Agent的监管合规本质与NMPA二类证核心逻辑 AI医疗Agent并非通用大模型的简单应用延伸,而是以临床决策支持、病灶识别、报告生成等具体医疗器械功能为边界的技术实体。其监管合规本质在…...

揭秘当下匹克球鞋销售厂家,背后隐藏着怎样的行业秘密?
在运动市场中,匹克球运动正逐渐兴起,匹克球鞋销售厂家也受到了更多关注。下面,让我们深入探究其中的行业秘密。市场现状与痛点行业报告显示,随着匹克球运动的普及,匹克球鞋市场规模不断扩大,但也存在诸多痛…...

非结构化数据处理有没有更高效的办法?2026智能体端到端方案彻底终结数据孤岛
在2026年的数字化深水区,企业面对的不再是单纯的数据库增删改查,而是由海量PDF合同、非标图片、多模态音视频、复杂的系统日志以及社交媒体碎片信息构成的“非结构化数据冰山”。 据行业数据显示,企业内部超过80%的数据以非结构化形式存在。过…...

一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南
一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirro…...

内网离线部署RPA:打包EXE+本地激活+数据零上云方案
领导给了一周,我前三天全耗在这个报错上:无法连接到 activation.xxx.com 请检查网络连接后重试2024年5月,我用的蓝印RPA物理隔离内网部,处理核心业务数据,要求"数据不出本机,流程不外传,审…...