Spark SQL支持DataFrame操作的数据源
DataFrame提供统一接口加载和保存数据源中的数据,包括:结构化数据、Parquet文件、JSON文件、Hive表,以及通过JDBC连接外部数据源。一个DataFrame可以作为普通的RDD操作,也可以通过(registerTempTable)注册成一个临时表,支持在临时表的数据上运行SQL查询操作。
一、数据源加载保存操作
DataFrame数据源默认文件为Parquet格式,可以通过spark.sql.sources.default参数进行重新修改。
不论何种格式的数据源均采取统一API、read和write进行操作,代码如下:
// 读取parquet格式数据
val df =sqlContext.read.load("file:///$SPARK_HOME/examples/src/main/resources/users.parquet")
// 从DataFrame写数据并保存成Parquet格式
df.write.save("saveusers.parquet")
1,指定选项
Spark支持通过完全限定名称(如org.apache.spark.sql.parquet)指定数据源的附加选项,内置数据源可以使用短名称(json、parquet、jdbc),Spark SQL支持通过format将任何类型的DataFrames转换成其他类型。
val df = sqlContext.read.format("json").load("file:///$SPARK_HOME examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
2,保存模式
可以通过配置SaveMode指定如何处理现有数据,实现保存模式不使用任何锁定,而且不是原子操作;因此,多路数据写入相同位置是不安全的。当执行overwrite时,写入新数据之前原来数据将被删除。

3,保存持久表
当使用HiveContext时,DataFrames通过saveAsTable命令保存为持久表使用,与registerTempTable命令不同,saveAsTable实现Dataframe的内容,并创建一个指向Hive Metastore中数据的指针。即使Spark程序重新启动,连接相同Metastore的数据不会发生变化。
默认情况下saveAsTable将创建一个“管理表”,这意味着数据的位置将由Metastore控制,当表被删除时,管理表将表数据自动删除。
二、Parquet文件
Parquet是一种支持多种数据处理系统的存储格式,Spark SQL提供了读写Parquet文件,并且自动保存原始数据的模式。
1,Parquet文件优点
(1)高效,Parquet采取列式存储避免读入不需要的数据,具有极好的性能和GC。
(2)方便的压缩和解压缩,并具有极好的压缩比例。
(3)可以直接固化为Parquet文件,也可以直接读取Parquet文件,具有比磁盘更好的缓存效果。
Spark SQL对读写Parquet文件提供支持,方便加载Parquet文件数据到DataFrame,供Spark SQL操作,也可以将DataFrame写入Parquet文件,并自动保留原始Scheme架构。
在外部数据源方面,Spark对Parquet的支持有了很大的加强,更快的metadata discovery和schema merging;同时能够读取其他工具或者库生成的非标准合法的Parquet文件;以及更快、更鲁棒的动态分区插入。
2,加载数据编程
通过sqlContext.implicits._隐式转换一个RDD为DataFrame,并将DataFrame保存为Parquet文件;加载保存的Parquet文件,重新构建一个DataFrame,注册成临时表,供SQL查询使用。
// 创建sqlContextval
sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 隐式转换为一个DataFrame
import sqlContext.implicits._
// 使用case定义schema,实现Person接口
case class Person(name: String, age: Int)
// 读取文件创建一个MappedRDD,并将数据写入Person模式类,隐式转换为DataFrame
val peopleDF = sc.textFile("file:///$SPARK_HOME/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
// 保存DataFrame,保存为Parquet格式
peopleDF.write.parquet("people.parquet")
// 加载Parquet文件作为DataFrame
val parquetFile = sqlContext.read.parquet("people.parquet")
// 将DataFrame注册为临时表,供SQL查询使用
parquetFile.registerTempTable("parquetTable")
val result = sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age <= 19")
result.map(t => "Name: " + t(0)).collect().foreach(println)
3,分区发现(partition discovery)
表分区(table partitioning)是一种常见的优化方法,用于像Hive一样的系统。对于分区表,数据通常存储在不同的目录中,在每个分区目录路径中对分区列的值进行编码。
Parquet数据源能够自动发现和推断分区信息,使用以下目录结构存储以前使用的人口数据到一个分区表,以gender和country作为分区列:
path└──table├── gender=male│ ├── ...│ ├── country=US│ │ └── data.parquet│ ├── country=CN│ │ └── data.parquet│ └── ...└── gender=female├── ...├── country=US│ └── data.parquet├── country=CN│ └── data.parquet└── ...
通过路径path/table,使用SQLContext.read的parquet或load命令,Spark SQL自动提取分区信息,返回的DataFrame模式如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
分区列的数据类型是自动映射,支持numeric数据类型和string类型自动推断。
4,模式合并(schema merging)
如同ProtocolBuffer、Avro、Thrift,Parquet也支持模式演进,用户可以从一个简单的模式开始,逐步根据需要添加更多的列。通过这种方式,用户最终得到多个不同但是能相互兼容模式的Parquet文件,Parquet数据源能够自动检测这种情况,进而合并这些文件。
由于模式合并是相对昂贵的操作,在很多情况下并非必须,为了提升性能,在1.5.0版本中默认关闭。
// 隐式转换一个RDD为DataFrame
import sqlContext.implicits._
// 创建一个DataFrame,存储数据到一个分区目录
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("data/test_table/key=1")
// 创建一个新DataFrame,存储在一个新的分区目录
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("data/test_table/key=2")
// 读取分区表
val df3 = sqlContext.read.option("mergeSchema", "true").parquet("data/test_table")
df3.printSchema()
// 通过基础DataFrame函数,以树格式打印Schema,包含分区目录下全部的分区列
df3.printSchema()
// root
// |-- single: int (nullable = true)
// |-- double: int (nullable = true)
// |-- triple: int (nullable = true)
// |-- key: int (nullable = true)
Parquet数据源自动从文件路径中发现了key这个分区列,并且正确合并了两个不相同但相容的Schema。值得注意的是,如果最后的查询中查询条件跳过了key=1这个分区,Spark SQL的查询优化器会根据这个查询条件将该分区目录剪掉,完全不扫描该目录中的数据,从而提升查询性能。
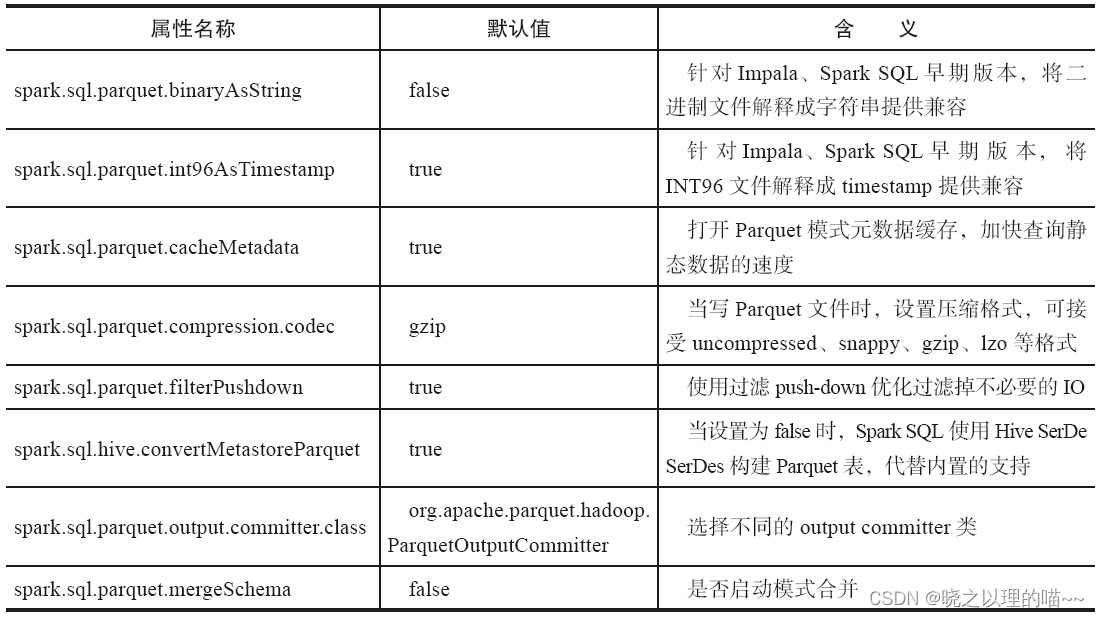
5,配置
在SQLContext中使用setConf方法,或在运行时使用SQL命令SET key=value,实现对Parquet文件的配置
三、JSON数据集
Spark SQL可以自动推断出一个JSON数据集的Schema并作为一个DataFrame加载,通过SQLContext.read.json()方法使用JSON文件创建DataFrame。
// 创建sqlContextval
sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 设置JSON数据集的路径,可以是单个文件或者一个目录
val path= file:///Spark_Home/examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
// 打印schema,并显示推断的schema
people.printSchema()
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// 注册DataFrame作为一个临时表
people.registerTempTable("jsonTable")
// 使用sql运行SQL表达式
val teenagers = sqlContext.sql("SELECT name FROM jsonTable WHERE age >= 13 AND age <= 19")
或者通过转换一个JSON对象的RDD[String]创建DataFrame。
val anotherRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherRDD)
四、Hive表
Spark SQL支持从Hive表中读写数据,然而默认版本Spark组件并不包括Hive大量的依赖关系。Hive支持通过添加-Phive和-Phive-thriftserver标志对Spark重新构建一个包括Hive的新组件,Hive的新组件必须分发到所有的Worker节点上,因为Worker节点需要访问Hive的serialization和deserialization库(SerDes),以便于访问存储在Hive中的数据,所以该Hive集合Jar包必须拷贝到所有的Worker节点。
除了基本的SQLContext,Spark SQL还可以创建一个HiveContext,该HiveContext通过基本的SQLContext提供了一系列的方法集,可以使用更完整的HiveQL解析器查询,访问Hive的UDF,并从Hive表读取数据,以及SerDe支持。
1,示例数据
新建一个kv1.txt文件,数据如下:
238 val_238
86 val_86
311 val_311
27 val_27
165 val_165
409 val_409
255 val_255
278 val_278
98 val_98
2,创建HiveContext
使用Hive,必须先构建一个继承SQLContext的HiveContext对象,并加入在MetaStore中查找表和使用HiveQL写查询功能的支持;可以在conf目录hive-site.xml文件中添加Hive的配置文件,当运行一个YARN集群时,datanucleus jars和hive-site.xml必须在Driver和全部的Executors启动。
一个简单的方法如下:在spark-submit命令行通过–jars参数和–file参数加载,即使hive-site.xml文件没有配置,仍然可以创建一个HiveContext,并会在当前目录下自动地创建metastore_db和warehouse。
使用Scala语言说明HiveContext创建方式:
// SparkContext实例
val sc: SparkContext = ...
// 通过sc创建HiveContext的实例hiveContext
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
3,使用Hive操作数据
使用HiveContext无需单独安装Hive,可以使用spark.sql.dialect选项选择解析查询语句的SQL的特定转化,这个参数可以使用SQLContext上的setConf方法,也可以使用SQL上的SETkey=value命令进行修改。
// 通过HiveContext的sql命令创建表
hiveContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
// 加载数据, $SPARK_HOME指Spark文件安装目录,使用“file:// ...”标识的本地文件,使用“hdfs:// ...”标识的HDFS存储系统的文件
hiveContext.sql("LOAD DATA LOCAL INPATH 'file:///$Spark_Home/examples/src/main/resources/kv1.txt' INTO TABLE src")
// HiveQL的查询表达
hiveContext.sql("FROM src SELECT key,value").collect().foreach(println)
// 使用HiveContext创建表命令
CREATE [EXTERNAL] TABLE[IF NOT EXISTS] table_name
(col_name data_type,…)
[PARTITIONED BY(col_name data_type,…)]
[[ROW FORMAT row_format]]
[STORED AS file_format]
[LOCATION hdfs_path]
4,Spark支持的Hive特性
(1)Hive查询语句,包括:SELECT、GROUP BY、ORDER BY、CLUSTER BY、SORT BY;
(2)Hive运算符,包括:关系运算符(=、<>、、<>、<、>、>=、<=等)、算术运算符(+、-、*、/、%等)、逻辑运算符(AND、&&、OR、||等)、复杂类型构造函数、数据函数(sign、ln、cos等)、字符串函数(instr、length、printf等);
(3)用户自定义函数(UDF);
(4)用户自定义聚合函数(UDAF);
(5)用户定义的序列化格式(SerDes);
(6)连接操作,包括:JOIN、{LEFT|RIGHT|FULL}OUTER JOIN、LEFT SEMI JOIN、CROSS JOIN;
(7)联合操作(Unions);
(8)子查询:SELECT col FROM(SELECT a+b AS col from t1)t2;
(9)抽样(Sampling);
(10)解释(Explain);
(11)分区表(Partitioned tables);
(12)所有的HiveDDL操作函数,包括:CREATE TABLE、CREATE TABLE AS SELECT、ALTER TABLE;
(13)大多数Hive数据类型TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING、BINARY、TIMESTAMP、DATE、ARRAY<>、MAP<>、STRUCT<>。
五、通过JDBC连接数据库
Spark SQL还包括一个可以通过JDBC从其他数据库读取数据的数据源,并返回一个DataFrame,在Spark SQL很容易处理,或者Join其他的数据源。除了Scala语言,Java或Python语言也很容易操作而不需要提供一个Class Tag。(不同于Spark SQL JDBC server允许其他应用程序使用Spark SQL运行查询。)
在Spark类路径中包含特定数据库的JDBC驱动程序,如通过Spark Shell连接postgresql命令:
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell
val jdbcDF = sqlContext.load("jdbc", Map("url" -> "jdbc:postgresql:dbserver","dbtable" -> "schema.tablename"))
使用数据源API,加载远程数据库的表作为一个DataFrame和Spark SQL临时表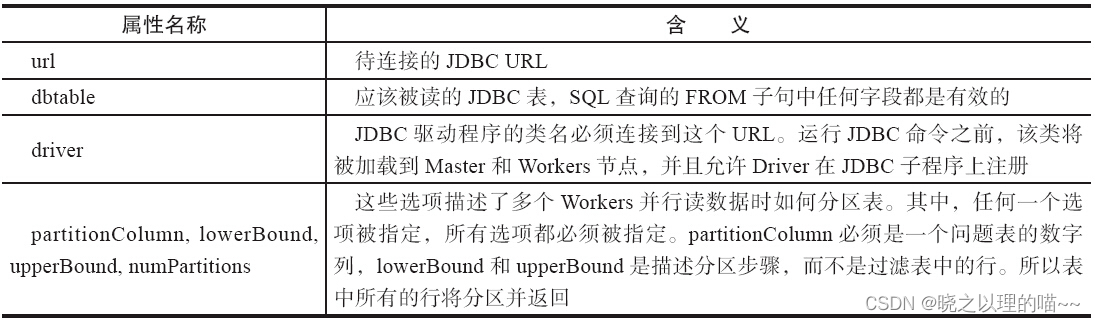
文章来源:《Spark核心技术与高级应用》 作者:于俊;向海;代其锋;马海平
文章内容仅供学习交流,如有侵犯,联系删除哦!
相关文章:
Spark SQL支持DataFrame操作的数据源
DataFrame提供统一接口加载和保存数据源中的数据,包括:结构化数据、Parquet文件、JSON文件、Hive表,以及通过JDBC连接外部数据源。一个DataFrame可以作为普通的RDD操作,也可以通过(registerTempTable)注册成…...
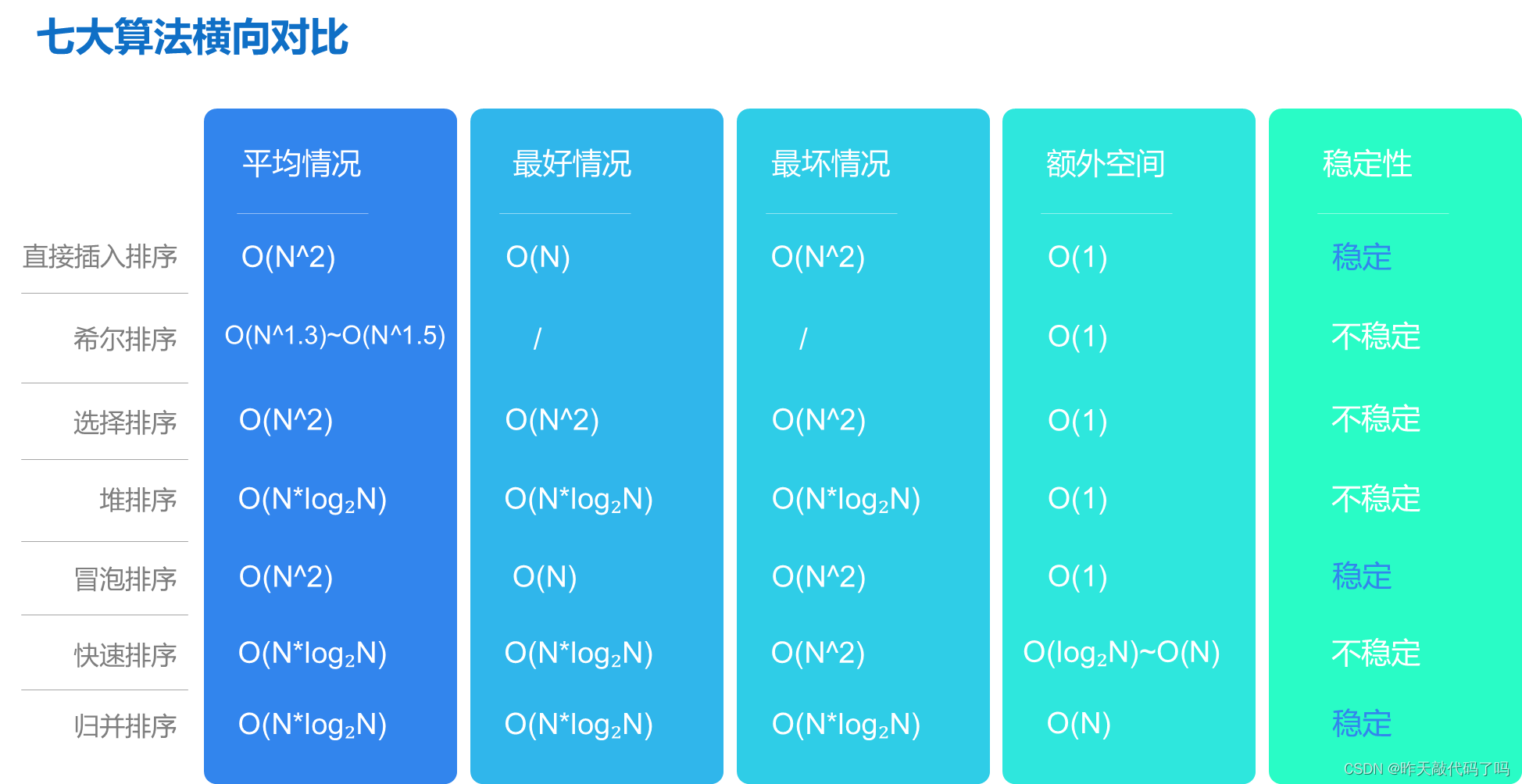
Java【归并排序】算法, 大白话式图文解析(附代码)
文章目录前言一、排序相关概念1, 什么是排序2, 什么是排序的稳定性3, 七大排序分类二、归并排序1, 图文解析2, 代码实现三、性能分析四、七大排序算法总体分析前言 各位读者好, 我是小陈, 这是我的个人主页 小陈还在持续努力学习编程, 努力通过博客输出所学知识 如果本篇对你有…...

【springboot】数据库访问
1、SQL 1、数据源的自动配置-HikariDataSource 1、导入JDBC场景 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency>数据库驱动? 为什么导入JD…...

普通和hive兼容模式下sql的差异
–odps sql –– –author:宋文理 –create time:2023-03-08 15:23:52 –– – 差异分为三块 – 1.运算符的差异 – 2.类型转换的差异 – 3.内建函数的差异 – 以下是运算符的差异: – BITAND(&) – 当输入参数是BIGINT类型的时候&…...
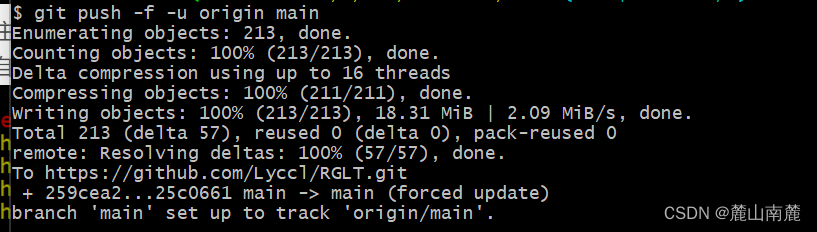
github开源自己代码
接下来,我们需要先下载Git,的网址:https://git-scm.com/downloads,安装时如果没有特殊需求,一直下一步就可以了,安装完成之后,双击打开Git Bash 出现以下界面: 第一步:…...
数据库基础语法
sql(Structured Query Language 结构化查询语言) SQL语法 use DataTableName; 命令用于选择数据库。set names utf8; 命令用于设置使用的字符集。SELECT * FROM Websites; 读取数据表的信息。上面的表包含五条记录(每一条对应一个网站信息&…...
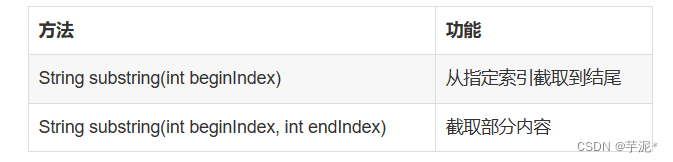
【Java】期末复习知识点总结(4)
适合Java期末的复习~ (Java期末复习知识点总结分为4篇,这里是最后一篇啦)第一篇~https://blog.csdn.net/qq_53869058/article/details/129417537?spm1001.2014.3001.5501第二篇~https://blog.csdn.net/qq_53869058/article/details/1294751…...
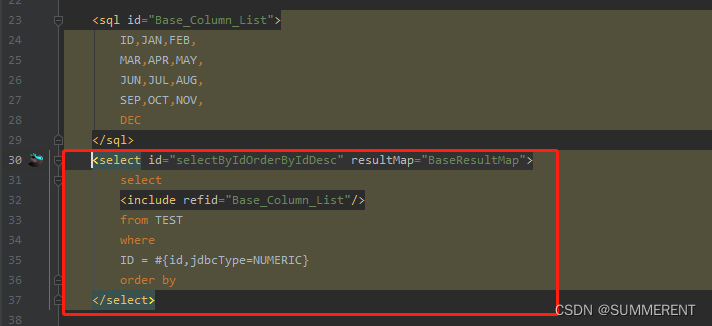
IDEA好用插件:MybatisX快速生成接口实体类mapper.xml映射文件
目录 1、在Idea中找到下载插件,Install,重启Idea 2、一个测试java文件,里面有com包 3、在Idea中添加数据库 --------以Oracle数据库为例 4、快速生成entity-service-mapper方法 5、查看生成的代码 6、自动生成(增删查改࿰…...

【JavaEE】初识线程
一、简述进程认识线程之前我们应该去学习一下“进程" 的概念,我们可以把一个运行起来的程序称之为进程,进程的调度,进程的管理是由我们的操作系统来管理的,创建一个进程,操作系统会为每一个进程创建一个 PCB&…...
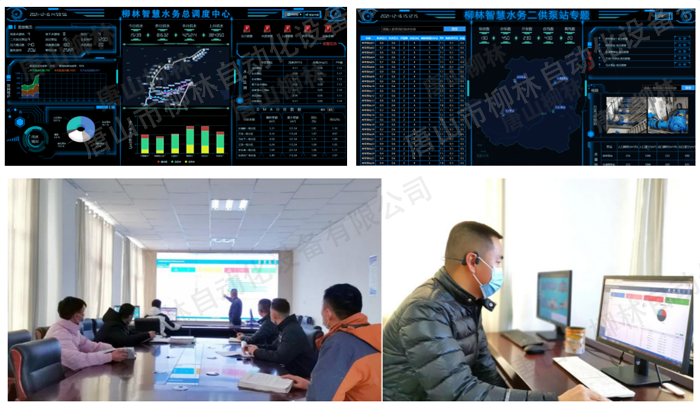
智慧水务监控系统-智慧水务信息化平台建设
平台概述柳林智慧水务监控系统(智慧水务信息化平台)是以物联感知技术、大数据、智能控制、云计算、人工智能、数字孪生、AI算法、虚拟现实技术为核心,以监测仪表、通讯网络、数据库系统、数据中台、模型软件、前台展示、智慧运维等产品体系为…...
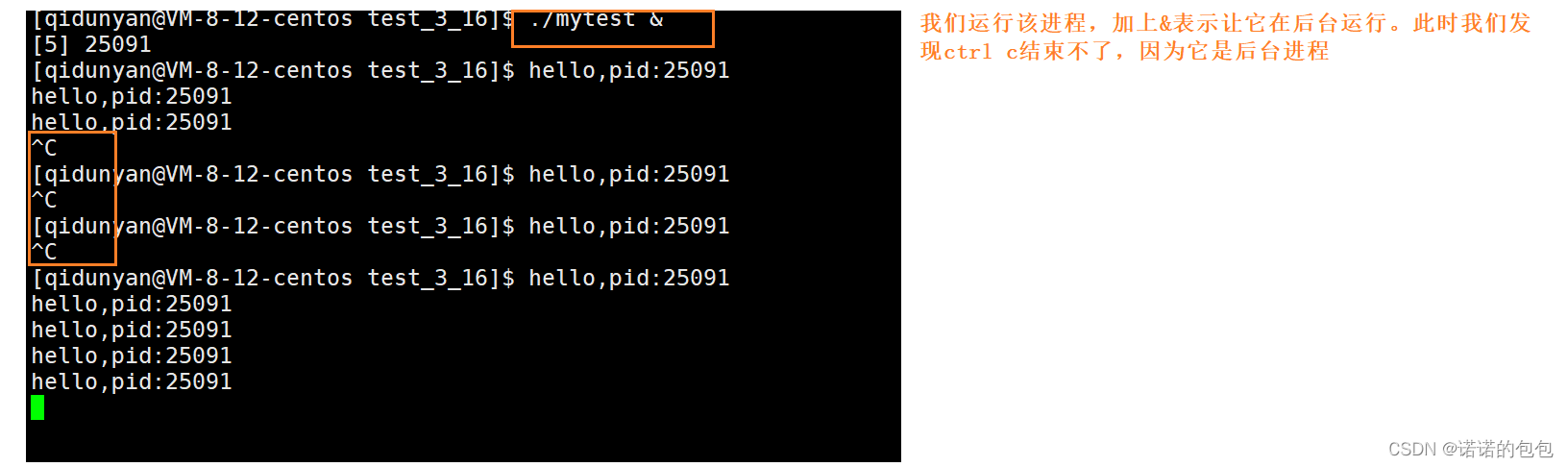
【Linux】进程优先级前后台理解
环境:centos7.6,腾讯云服务器Linux文章都放在了专栏:【Linux】欢迎支持订阅🌹相关文章推荐:【Linux】冯.诺依曼体系结构与操作系统【Linux】进程理解与学习(Ⅰ)浅谈Linux下的shell--BASH【Linux…...
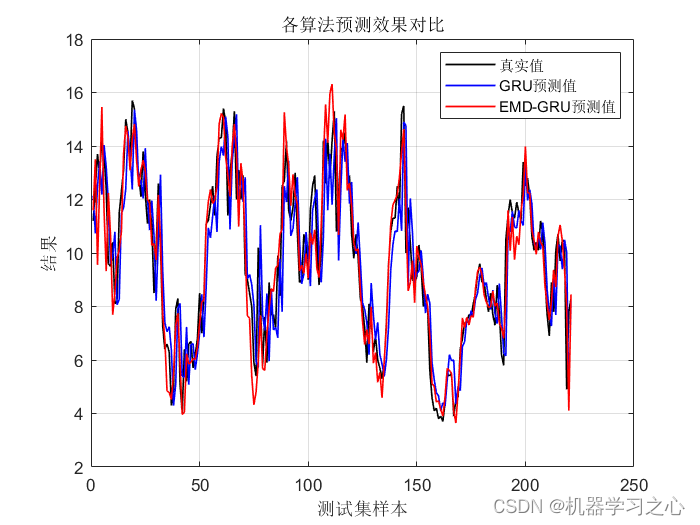
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元) 目录 时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)效果一览基本描述模型描述程序设计参考资料效果一览...

python 模拟鼠标,键盘点击
信息爆炸 消息轰炸模拟鼠标和键盘敲击import time from pynput.keyboard import Controller as key_col from pynput.mouse import Button,Controller def keyboard_input(insertword):keyboardkey_col()keyboard.type(insertword)def mouth():mouseController()mouse.press(…...
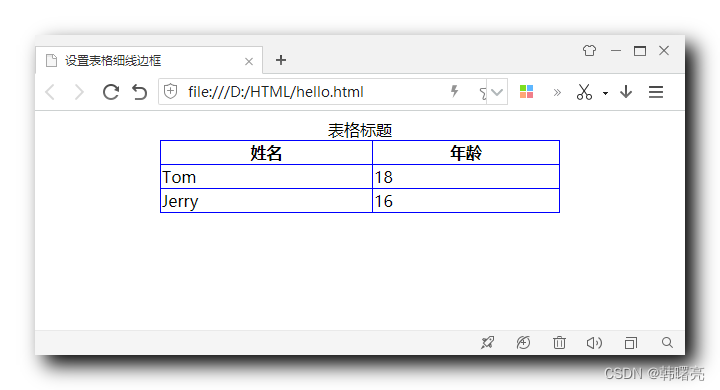
【CSS】盒子边框 ③ ( 设置表格细线边框 | 合并相邻边框 border-collapse: collapse; )
文章目录一、设置表格细线边框1、表格示例2、合并相邻边框3、完整代码示例一、设置表格细线边框 1、表格示例 给定一个 HTML 结构中的表格 , 默认样式如下 : <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8" />…...
)
TensorRT量化工具pytorch_quantization代码解析(一)
量化工具箱pytorch_quantization 通过提供一个方便的 PyTorch 库来补充 TensorRT ,该库有助于生成可优化的 QAT 模型。该工具包提供了一个 API 来自动或手动为 QAT 或 PTQ 准备模型。 API 的核心是 TensorQuantizer 模块,它可以量化、伪量化或收集张量的…...
【Kubernetes】第二十七篇 - 布署前端项(下)
一,前言 上一篇,介绍了前端项目的部署:项目的创建和 jenkins 配置; 本篇,创建 Deployment、Service,完成前端项目的部署; 二,创建 Deployment 创建 Deployment 配置文件ÿ…...
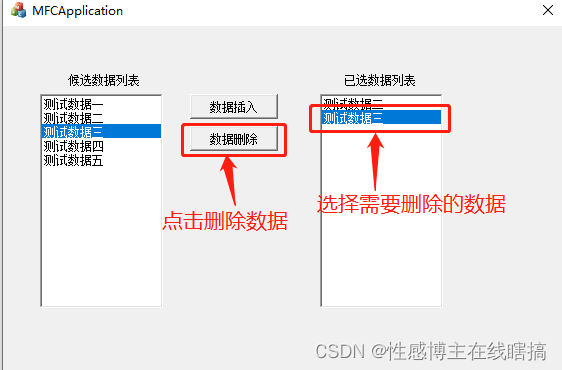
【MFC】两个ListBox控件数据交互
一.控件ID名称 界面如图下所示: 候选数据列表的ID为: 已选数据列表的ID为: 二.数据添加 可以使用以下代码往框中添加数据: ((CListBox *)GetDlgItem(IDC_LIST_TO_CHO))->AddString("测试数据"); 显示效果如下&#…...

sklearn库学习--SelectKBest 、f_regression
目录 一、SelectKBest 介绍、代码使用 介绍: 代码使用: 二、评分函数 【1】f_regression: (1)介绍: (2)F值和相关系数 【2】除了f_regression函数,还有一些适用于…...

蓝桥杯刷题第十三天
第一题:特殊日期问题描述对于一个日期,我们可以计算出年份的各个数位上的数字之和,也可以分别计算月和日的各位数字之和。请问从 1900 年 11 月 1 日至 9999 年 12 月 31 日,总共有多少天,年份的数位数字之和等于月的数…...

CPU 和带宽之间的时空权衡
在 从一道面试题看 TCP 的吞吐极限 一文的开始,我提到在环形域上两个数字比较大小的前提是在同一个半圆内,进而得到滑动窗口最大值被限定在一个环形域的一半。 现在来看更为基本的问题。如果序列号只有 2bit,甚至仅有 1bit,保序传…...

如何轻松构建多平台直播录制系统的完整指南
如何轻松构建多平台直播录制系统的完整指南 【免费下载链接】stream-rec Automatic streaming record tool. Live stream and bullet comments recorder. 虎牙/抖音/斗鱼/Twitch/PandaTV/微博直播,弹幕自动录制 项目地址: https://gitcode.com/gh_mirrors/st/stre…...

如何高效解决Unity游戏插件框架BepInEx启动失败:完整指南与最佳实践
如何高效解决Unity游戏插件框架BepInEx启动失败:完整指南与最佳实践 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏最强大的插件框架之一&#x…...

XMem实战教程:从DAVIS到YouTubeVOS数据集的完整评估流程
XMem实战教程:从DAVIS到YouTubeVOS数据集的完整评估流程 【免费下载链接】XMem [ECCV 2022] XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model 项目地址: https://gitcode.com/gh_mirrors/xm/XMem 你是否正在寻找一个强大…...
--CubeMX配置说明)
基于STM32HAL库的平衡小车设计(二)--CubeMX配置说明
项目开源链接 本项目资料完全开源。资料包获取方式: github : https://github.com/snqx-lqh/ProjectReleasePage gitee(国内镜像) :https://gitee.com/snqx-lqh/ProjectOpenSourceReleasePage。 项目属于 32 的编号 B005 ,在发…...

CANN/ops-nn自适应平均池化3D反向计算
aclnnAdaptiveAvgPool3dBackward 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 📄 查看源码 产品是否支持Ascend 950PR/Ascend 950DT√…...

Obsidian Quiz Generator:用AI从笔记生成交互测验,打造学习闭环
1. 项目概述:用AI将笔记变成互动测验 如果你和我一样,是个重度Obsidian用户,同时又经常需要备考、复习或者制作教学材料,那你肯定体会过那种痛苦:面对几十上百页的笔记,想要生成一些高质量的练习题来检验学…...

基于星座匹配的眼动追踪角膜反射检测技术解析
1. 项目概述:基于星座匹配的角膜反射检测框架在眼动追踪技术领域,瞳孔-角膜反射(P-CR)方法一直是最可靠的解决方案之一。这种方法的核心在于准确检测和匹配角膜反射点(glints)——即红外LED在角膜表面形成的…...

终极Notero使用指南:如何快速实现Zotero与Notion文献同步
终极Notero使用指南:如何快速实现Zotero与Notion文献同步 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 在学术研究和工作流管理中,我们常常面临一个共…...
)
城市大脑实战:如何用Max Pressure思想优化Python+SUMO交通仿真(附PressLight代码解析)
城市交通信号优化实战:基于Max Pressure的PythonSUMO仿真与PressLight实现 在智慧城市建设浪潮中,交通信号控制系统的智能化升级已成为缓解城市拥堵的关键突破口。传统定时控制方案如SCATS、SCOOT在面对动态交通流时显得力不从心,而纯强化学习…...

Windows与Office一键激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程
Windows与Office一键激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office办公软件激活而烦恼吗?…...