语音识别概述
语音识别概述
一.什么是语音?
语音是语言的声学表现形式,是人类自然的交流工具。

图片来源:https://www.shenlanxueyuan.com/course/381
二.语音识别的定义
语音识别(Automatic Speech Recognition, ASR 或 Speech to Text, STT)是将语音转换为文本的任务。其主要目标是解决机器“听清”问题,处理声学和(部分)语言上的混淆,确保每个人的语音都能被正确识别为文本。
1.主要解决的问题:
- 将语音转换成文本。
- 解决机器“听清”问题。
- 处理声学和部分语言上的混淆。
- 确保不同人的语音都能被正确识别。
2.不解决的问题:
- 说话人识别。
- 副语言信息的分析与识别(如发音、质量、韵律、情感)。
- 语言理解。
3.评估标准:
-
Accuracy(准确率):
- 音素错误率(Phone Error Rate, PER)
- 词错误率(Word Error Rate, WER)
- 字错误率(Character Error Rate, CER)
- 句错误率(Sentence Error Rate, SER)
-
Efficiency(效率):
- 实时率(Real-time Factor, RTF)
4.错误率计算实例:
Ref: THE CAT IN THE HAT
Hyp: CAT IS ON THE GREEN HATDEL SUB INS INS
在这个例子中:
- 第一行为正确的抄本(Ref)。
- 第二行为识别结果(Hyp)。
- 错误类型:第一列为删除错误(DEL),第三列为替换错误(SUB),第四列和第六列为插入错误(INS)。
错误率计算公式:Error rate=100×(1S+1D+2I)/5=80
计算过程中关注三种错误:插入错误、替换错误和删除错误。实际计算时,错误率有可能超过100%。
5.语音识别系统分类:
- 说话人:特定人、非特定人
- 语种:单一语种、多语种
- 词汇量:大词汇量、中词汇量、小词汇量
- 设备:云端、端侧
- 距离:近距离、远距离
三.语音识别的重要性
语音识别(ASR,Automatic Speech Recognition)是一项极具挑战性的技术,被誉为“镶嵌在人工智能皇冠上的明珠”。它在现代技术和应用中占有重要地位,主要体现在以下几个方面:
1. 快速、便捷、无接触的优点
- 快速:语音输入的速度通常比键盘输入更快,使信息传递更加高效。
- 便捷:用户只需说话,无需学习复杂的输入方法,使用门槛低。
- 无接触(Hands-Free):特别适用于开车、做家务等需要双手操作的场景,提升了用户的便利性和安全性。
2. 音频内容分析与理解的基础
- 文字转写:语音识别是将音频内容转化为文本的第一步,这一过程是进一步分析与理解音频内容的基础。
- 文本分析:转写后的文本可以进行情感分析、主题识别等处理。
- 数据存档:转写文本便于存储和检索,提升了数据的可用性。
3. AIoT和智能服务的入口
-
AIoT(人工智能物联网):语音识别是AIoT设备的主要交互方式,用户可以通过语音控制智能家居、可穿戴设备等。
- 智能家居:语音助手控制灯光、温度、家电等。
- 可穿戴设备:语音识别用于健康监测、运动记录等。
-
智能服务:语音识别在智能客服、自动翻译等领域有广泛应用。
- 智能客服:自动应答用户问题,提高客服效率。
- 自动翻译:实时翻译语音内容,打破语言障碍。
4. 满足自然人机交互和内容理解与生成的需求
-
自然人机交互:语音识别使人机交互更加自然,用户可以通过语音指令与设备进行交流,提升用户体验。
- 虚拟助手:如Siri、Alexa、Google Assistant等通过语音识别实现自然对话。
- 导航系统:通过语音输入目的地,提高驾驶安全性。
-
内容理解与生成:语音识别技术与自然语言处理(NLP)结合,实现内容的理解与生成。
- 语音搜索:用户通过语音进行信息搜索,快速获取答案。
- 语音生成:将文本转化为自然语音,实现双向交流。
5. 技术与应用的广泛性
- 医疗领域:医生通过语音输入病历,提高工作效率,减少误诊。
- 教育领域:语音识别用于语言学习、课堂记录等,提高学习效果。
- 安防领域:通过语音识别进行身份验证和监控,提高安全性。
四.语音交互

图片来源:http://techchannel.att.com/play-video.cfm/2011/8/10/AT&T-Archives-The-Speech-Chain
五.语音生成
语音生成(Speech Production)是指通过大脑指挥神经系统发出肌肉命令,进而控制发音器官运动,最终产生声音的过程。
1.语音生成过程
-
大脑指挥:大脑发出神经信号,控制肌肉运动。
-
神经肌肉命令:神经系统将命令传递到发音器官。
-
发音器官运动:发音器官(如声带、口腔、鼻腔等)根据神经信号进行运动,产生声音。
2.发音的基本原理
- 声门运动:声门的快速打开与关闭产生不同的声音。
- 基本频率:声门震动的快慢决定声音的基本频率。
- 口腔、鼻腔、舌头的位置及嘴型:这些因素共同决定声音的内容。
- 肺部空气压力:肺部压缩空气的力量决定音量。
2.声音类型
-
浊音(Voiced Sounds):由声带震动引起,波形具有明显的周期性,人们可以感受到稳定的高音。
-
清音(Unvoiced Sounds):声带不震动,波形类似白噪声,人们无法感受到稳定的高音。
3.语音单元
-
音素(Phonemes):
- 音素是语言中语音的最小单元,分为辅音(consonants)和元音(vowels)。
- 音素的数量因语言而异。
- 同位异音(Allophone):音素的声学实现受到上下文影响,一个音素可能有不同的实现。
-
词素(Morpheme):语言中最小的具有语义的结构单元。
-
音节(Syllable):
- 由元音和辅音结合构成。
- 音节头(声母):元音之前的辅音。
- 韵母:音节头后的元音及随后的辅音。
- 音节核:韵母中的元音。
- 音节尾:随后的辅音。
- 在中文中,一个汉字的读音为一个带调音节(如普通话约1300多个带调音节,去掉声调后约400个基础音节)。
4.声学特征
-
共振峰(Formants):
- 在声音的频谱中,能量相对集中的区域。
- 共振峰决定音质,反映声道的物理特征,不同元音会产生不同种类的共振。
-
协同发音(Coarticulation):
- 发音过程中,每个音素会受到前后音素的影响。
- 协同发音使得音素的声学实现与上下文强相关,因此语音识别中常建立上下文相关模型。
5.音素抄本
音素抄本(Phonetic Transcription)是一段语音对应的音素列表,可以带或不带边界。音素抄本提供时间信息,可以通过人工标注或自动对齐获得。它在语音识别的声学建模中非常重要。
六.语音感知
语音感知(Speech Perception)是指人耳将外界声音信号传递到大脑,并由大脑进行处理和理解的过程。该过程包括外耳、中耳和内耳的协同工作,以及声音的物理特性与人耳听觉特性之间的关系。
1.人耳结构
-
外耳:
- 功能:声源定位,对声音进行放大。
- 组成:耳廓和外耳道。
-
中耳:
- 功能:进行声阻抗变换,放大声压,保护内耳。
- 组成:鼓膜和听小骨(锤骨、砧骨、镫骨)。
-
内耳:
- 功能:将声压刺激转化为神经冲动,发送到大脑。
- 组成:耳蜗和听神经。
2.物理特性与听觉特性
语音感知涉及声音的物理量和感知量之间的关系。下表总结了这些关系:
| 物理量 (Physical Quantity) | 感知量 (Perceptual Quantity) |
|---|---|
| 声强 (Intensity) | 响度 (Loudness) |
| 基频 (Fundamental Frequency) | 音高或音调 (Pitch) |
| 频谱形状 (Spectral Shape) | 音色或音品 (Timbre) |
| 起始/结束时间 (Onset/offset time) | 时间感知 (Timing) |
| 双耳听觉的相位差 (Phase difference in binaural hearing) | 定位 (Location) |
3.声音三要素
-
响度(Loudness):
- 响度是人主观感受到的声音强度,与声音的频率成分有关。
- 闻阈:人耳刚好能听见的最小响度。
- 痛阈:声音使人耳感到疼痛时的响度。

图片来源:https://www.shenlanxueyuan.com/course/381
-
音高或音调(Pitch):
-
音调是人耳对声音频率的感知,是非线性的,近似对数函数。
-
音调和频率的近似关系:𝑇𝑚𝑒𝑙=2595log10(1+𝑓7000)。
𝑓为物理频率,𝑇𝑚𝑒𝑙为音调,单位是美(Mel)
-
-
音色或音品(Timbre):
- 音色由声音波形的谐波频谱和包络决定。
- 基音:声音波形的基频产生的最清楚的音。
- 泛音:各次谐波的微小震动产生的音。
- 纯音:单一频率的音。
- 复音:具有谐波的音。
- 不同声源的音色特征由声音波形各次谐波的比例和随时间的衰减大小决定。
4.掩蔽效应
掩蔽效应(Masking)是指一个较强声音掩蔽附近较弱声音,使其不易被察觉的现象。分为两种情况:
-
同时掩蔽(Simultaneous Masking):一个强纯音会掩蔽其附近频率同时发生的弱纯音。
-
异时掩蔽(Temporal Masking):在时间上相邻的声音之间的掩蔽现象。
掩蔽阈值是时间、频率和声压级的函数。
七.语音识别的挑战性
语音识别(Automatic Speech Recognition, ASR)是一个非常具有挑战性的任务,其在众多方面表现出强大的可变性。以下是影响语音识别性能的主要因素及其可变性:
1.主要影响因素及其可变性
| 因素 | 可变性描述 |
|---|---|
| 规模 | 词表大小、复杂度/困惑度、书面化或口语化 |
| 说话人 | 是否特定说话人、适应特定说话人的特性 |
| 声学环境 | 噪声、干扰人声、信道条件(麦克风、传输空间、空间声学) |
| 讲话风格 | 连续或孤立词、有计划或即兴对话、大声或轻声细语 |
| 口音/方言 | 是否能识别各种口音 |
| 语种 | 中文、英文、超过5000种语言、语言混杂 |
| 信道特性 | 不同麦克风、不同采样率、传输编码等 |
| 环境影响 | 距离衰减、噪声、混响、干扰人声 |
2.语音识别中的变异性
-
说话人之间的变异性:不同说话人的口音、语速、发音方式、语调等各不相同。适应多种说话人的特性是语音识别的一个重要挑战。
-
说话人之内的变异性:同一个人在不同时间、不同情绪状态、不同健康状态下,语音特性也会有所不同。不同讲话方式(如大声、轻声、低语)对语音识别系统的要求也各不相同。
-
信道变异性:不同麦克风的性能、采样率和传输编码会影响语音信号的质量。在不同传输条件下,信号可能会受到干扰或衰减。
-
环境变异性:环境噪声、回声、混响以及干扰人声等都会影响语音信号的清晰度。距离衰减效应,尤其在远讲场景下,语音信号会显著衰减。
3.特殊场景挑战
CHiME-5场景: 多说话人完全自由对话。现实生活中的家居声学场景。远讲情况下的语音识别。说话人移动及语音交叠。
八.语音识别的发展历史
1.早期阶段(1950-1960年代)
在语音识别研究的初期,研究人员主要集中于提出一些基础的方法和引入关键的思想与概念。由于受限于方法、计算能力和数据量,这一阶段的研究主要针对小词表的语音识别,且缺乏大规模测试。主要特点包括:
- 初步探索:提出个别方法和概念。
- 小词表研究:主要集中在小范围词汇的语音识别。
- 技术限制:计算能力和数据量的限制使得研究进展缓慢。
2.现代语音识别的诞生(1970-1980年代)
这个阶段标志着语音识别从基础研究进入了统计学习时代,几乎忽略了语音学和语言学的专家知识,转而使用数据驱动的方法。关键技术和方法在此期间得以发展,包括:
- 统计学习方法:将语音识别视为统计学习任务。
- 关键技术:引入了EM算法、N-gram等。
- 中大词表尝试:开始尝试中大词表的语音识别系统。
3.平稳发展期(1990-2000年代)
在这一阶段,GMM-HMM(高斯混合模型-隐马尔科夫模型)框架成为主导,语音识别系统得以进一步发展。主要进展包括:
- GMM-HMM框架:成为语音识别的主流框架。
- 上下文相关建模:声学建模开始考虑基于上下文相关的模型。
- n-gram语言模型:使用大量文本统计概率关系。
- 数据和任务复杂度增加:数据量和任务复杂度逐步增加。
- 判别式学习:引入区分性训练技术推动进步。
尽管技术不断进步,但语音识别的准确率在这一时期鲜有显著提升。
3.深度学习时代(2006年至今)
2006年是语音识别历史上的一个重要转折点,标志着深度学习技术的引入和广泛应用。在此之后,语音识别的准确率显著提升,主要特点包括:
- 深度神经网络(DNNs):深度学习模型的应用大幅提升了语音识别的性能。
- 大规模数据和计算能力:利用更大的数据集和更强的计算能力进行训练。
- 持续改进:技术不断进步,推动语音识别系统向更高的准确率和更广泛的应用场景发展。
九.现代语音识别框架
现代语音识别框架主要分为两类:统计模型和端到端系统。
1.统计模型
统计模型的核心思想是通过计算最有可能的单词序列来进行语音识别。假设有一个声学特征向量(观测向量)的序列 X,表示一个单词序列 W,那么最有可能的单词序列可以通过以下公式计算得出:
W ^ = arg max W P ( W ∣ X ) \hat{W} = \arg\max_W P(W|X) W^=argWmaxP(W∣X)
应用贝叶斯定理,这一公式可以进一步推导为:
P ( W ∣ X ) = p ( X ∣ W ) P ( W ) p ( X ) ∝ p ( X ∣ W ) P ( W ) P(W|X) = \frac{p(X|W)P(W)}{p(X)} \propto p(X|W)P(W) P(W∣X)=p(X)p(X∣W)P(W)∝p(X∣W)P(W)
其中:
- p(X∣W) 是 声学模型,用于计算给定单词序列 W 下的声学特征向量 X的概率。
- P(W) 是 语言模型,用于计算单词序列 W的先验概率。
通过组合声学模型和语言模型,统计模型可以通过给定的声学特征向量 X获取最有可能的词序列。
现代的统计模型通常使用三大组件:
-
声学模型:用于计算声学特征向量的概率分布。
-
语言模型:用于计算单词序列的先验概率。
-
发音词典:提供单词与其发音之间的映射。

图片来源:https://www.shenlanxueyuan.com/course/381
2.端到端系统
端到端系统使用一个神经网络直接将输入的声学特征向量 X映射为词序列。这种方法简化了传统统计模型的复杂架构,避免了多个组件的独立优化和组合,具有以下特点:
- 直接映射:通过神经网络直接将声学特征向量转换为单词序列。
- 简化架构:省去声学模型、语言模型和发音词典的独立建模和组合。
- 统一训练:在一个训练过程中同时优化声学和语言模型的参数。

图片来源:https://www.shenlanxueyuan.com/course/381
十.语料库与工具包
1.英文数据
- TIMIT:用于音素识别,由 LDC 管理版权。
- WSJ:新闻播报语料库,由 LDC 管理版权。
- Switchboard:电话对话语料库,由 LDC 管理版权。
- Librispeech:有声读物语料库,包含 1000 小时的开源数据。 Librispeech
- AMI:会议语料库,开源数据。 AMI
- TED-LIUM:TED 演讲语料库,开源数据。 TED-LIUM
- CHiME-4:平板远讲语料库,需要申请。
- CHiME-5/6:聚会聊天语料库,需要申请。
2.中文数据
- THCHS-30:30 小时的开源语料库。 THCHS-30
- HKUST:150 小时的电话对话语料库,由 LDC 管理版权。
- AIShell-1:178 小时的开源语料库。 AIShell-1
- AIShell-2:1000 小时的开源语料库,需申请。 AIShell-2
- aidatatang_200zh:200 小时的开源语料库。 aidatatang_200zh
- MAGICDATA:755 小时的开源语料库。 MAGICDATA
3.工具包
- HTK:一款语音识别工具包。 HTK
- Kaldi:目前使用最广泛的语音识别工具包,支持 C++ 和 Python。 Kaldi
- ESPNet:基于 Pytorch 的端到端语音识别工具包。 ESPNet
- Lingvo:基于 Tensorflow 的语音识别工具包。 Lingvo
相关文章:
语音识别概述
语音识别概述 一.什么是语音? 语音是语言的声学表现形式,是人类自然的交流工具。 图片来源:https://www.shenlanxueyuan.com/course/381 二.语音识别的定义 语音识别(Automatic Speech Recognition, ASR 或 Speech to Text, ST…...
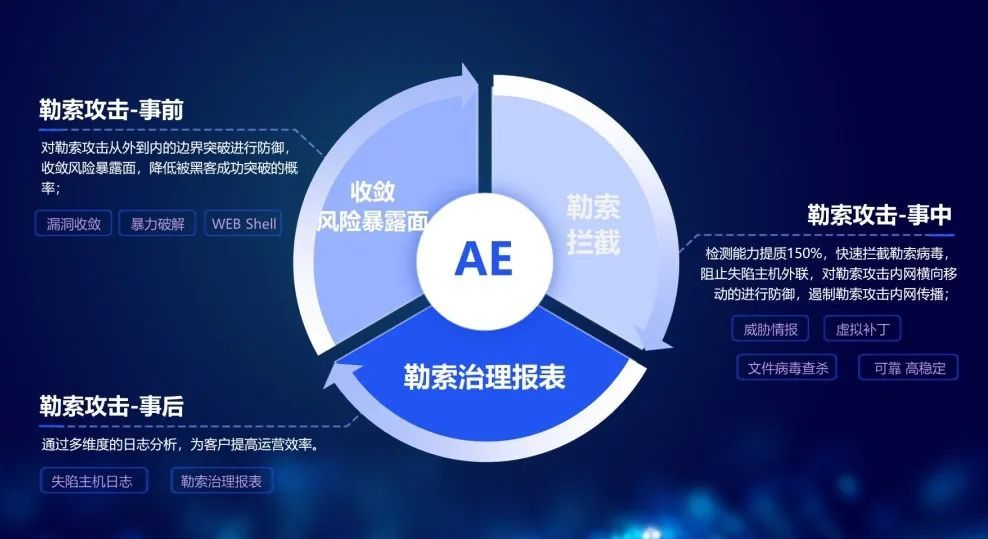
勒索防御第一关 亚信安全AE防毒墙全面升级 勒索检出率提升150%
亚信安全信舷AE高性能防毒墙完成能力升级,全面完善勒索边界“全生命周期”防御体系,筑造边界勒索防御第一关! 勒索之殇,银狐当先 当前勒索病毒卷携着AI技术,融合“数字化”的运营模式,形成了肆虐全球的网…...

elementui 日历组件el-calendar使用总结
功能: 1.日历可以周视图、月视图切换; 2.点击月视图中日期可以切换到对应周视图; 3.点击周视图查看当日对应数据; 4.周、月视图状态下,点击前后按钮,分别切换对应上下的周、月; 5.点击回到…...
)
RK3568 安卓12 EC20模块NOCONN没有ip的问题(已解决)
从网上东拼西凑找了不少教程,但是里面没有提到rillib.so需要替换,替换掉就可以上网了,系统也有4G图标了。 注意,这个rillib.so是移远提供的。把他们提供的文件放到rk3568_android_sdk/vendor/rockchip/common/phone/lib下&#x…...
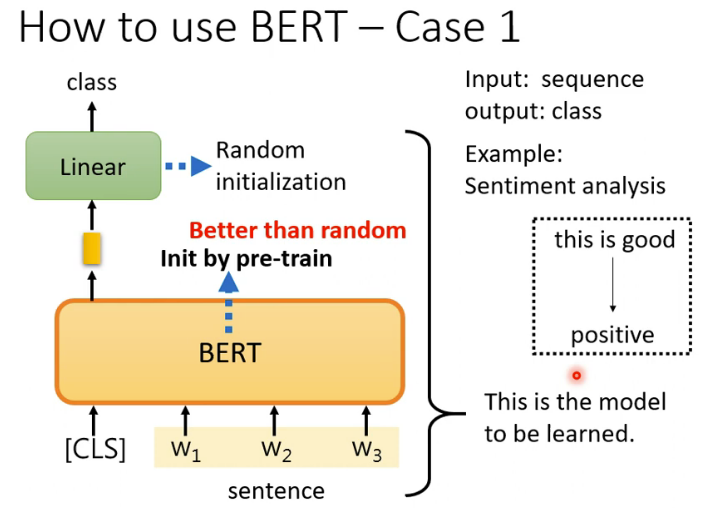
【NLP自然语言处理】基于BERT实现文本情感分类
Bert概述 BERT(Bidirectional Encoder Representations from Transformers)是一种深度学习模型,用于自然语言处理(NLP)任务。BERT的核心是由一种强大的神经网络架构——Transformer驱动的。这种架构包含了一种称为自注…...

CSS选择器(1)
以内部样式表编写CSS选择器,其主要编写在<head></head>元素里,通过<style></style>标签来定义内部样式表。 基本语法为: 选择器{ 声明块 } 声明块:是由一对大括号括起来,声明块中是一个一个的…...

Claude 3.5 Sonnet模型发布,对比ChatGPT4o孰强孰弱
Anthropic 这家生而为打击 OpenAI 安全问题的公司,正式发布了Claude 3.5 Sonnet模型! 用官网的话就是: 今天,我们推出了 Claude 3.5 Sonnet,这是我们即将推出的 Claude 3.5 型号系列中的第一个版本。Claude 3.5 Sonne…...

MySQL 分库分表
分表 分表 将表按照某种规则拆分成多个表。 分表的使用原因 当数据量超大的时候,B-Tree索引效果很变差。 垂直分区 切分原则:把不常用或存储内容比较多的字段分到新的表中可使表存储更多数据。 原因,Innodb主索引叶子节点存储着当前行的所有信…...
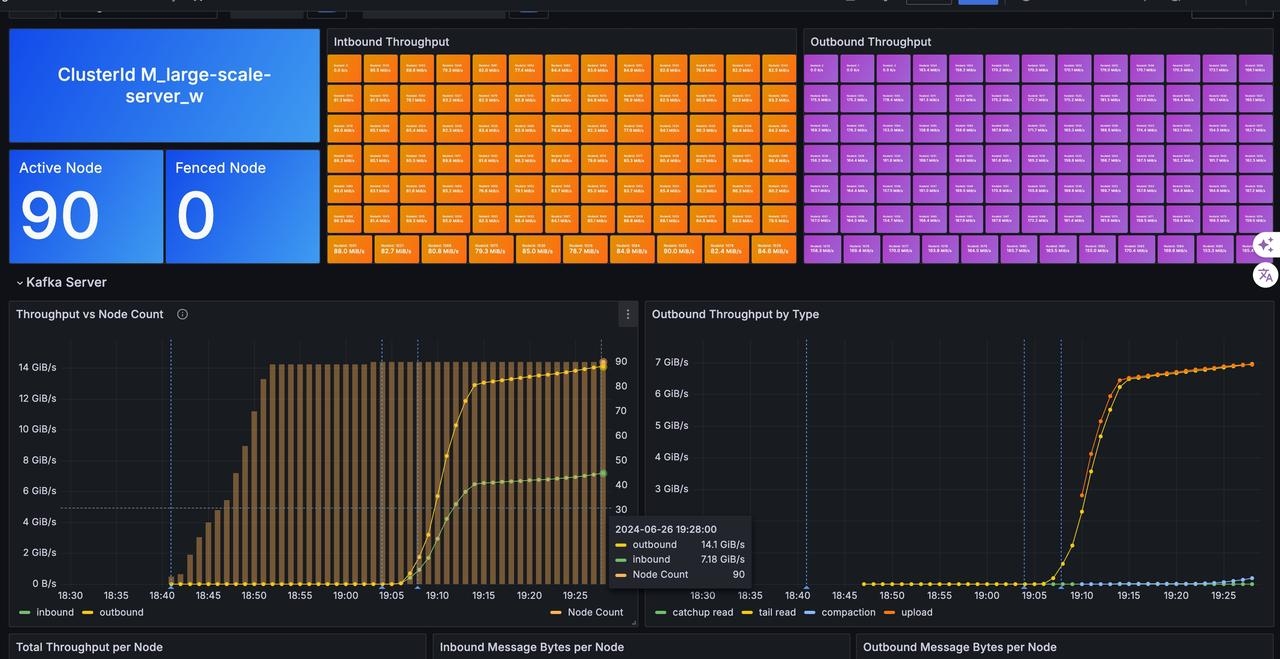
AutoMQ 社区双周精选第十二期(2024.06.29~2024.07.12)
本期概要 欢迎来到 AutoMQ 第十一期双周精选!在过去两周里,主干动态方面,AutoMQ 跟进了 Apache Kafka 3.4.x BUG 修复,并进行了CPU & GC 性能优化,另外,AutoBalancing 的 Reporter 和 Retriever 也将支…...

Web开发:<div>标签作用
div作用 介绍基本用法特点和用途样式化示例嵌套示例与其他标签的对比总结 介绍 在Web开发中,<div> 标签是一个通用的容器元素,用于将HTML文档中的内容分组。它是一个块级元素,通常用于布局目的,因为它可以包含其他块级元素…...

如何使用unittest框架来编写和运行单元测试
Python 的 unittest 框架是用于编写和运行可重复的测试的一个强大工具。它允许你定义测试用例、测试套件、测试运行器和测试固件(fixtures),从而系统化地测试你的代码。以下是如何使用 unittest 框架来编写和运行单元测试的基本步骤ÿ…...

2024最新超详细SpringMvc常用注解总结
SpringMVC常用注解 控制器(Controller)相关注解: 1.Controller Controller 注解用于标识一个类为 Spring MVC 的控制器,它能够处理用户的请求并返回相应的视图或数据。通常与 RequestMapping 注解一起使用,以定义请求…...
的基础知识)
Linux硬件中断(IRQ)的基础知识
目录 一、中断的概念1.1 什么是硬件中断1.2 中断类型二、中断处理的工作原理2.1 中断请求2.2 中断向量2.3 中断服务例程(ISR)2.4 上下文切换2.5 中断处理2.6 任务恢复三、中断处理的编程3.1 注册中断处理函数3.2 注销中断处理函数四、中断和系统性能4.1 中断风暴4.2 IRQ亲和性…...

DP讨论——适配器模式
学而时习之,温故而知新。 敌人出招(使用场景) 说是自己的程序对接第三方的库,但是自己的代码的接口设计完毕了,如何对接上? 你出招 适配器模式就是为此而生的——我觉得应该是该解决方法被命名为了适配…...

window下tqdm进度条
原代码是linux下运行,修改后可在window下运行。 #ifndef TQDM_H #define TQDM_H#include <chrono> #include <ctime> #include <numeric> #include <ios> #include <string> #include <cstdlib> #include <iostream> #i…...
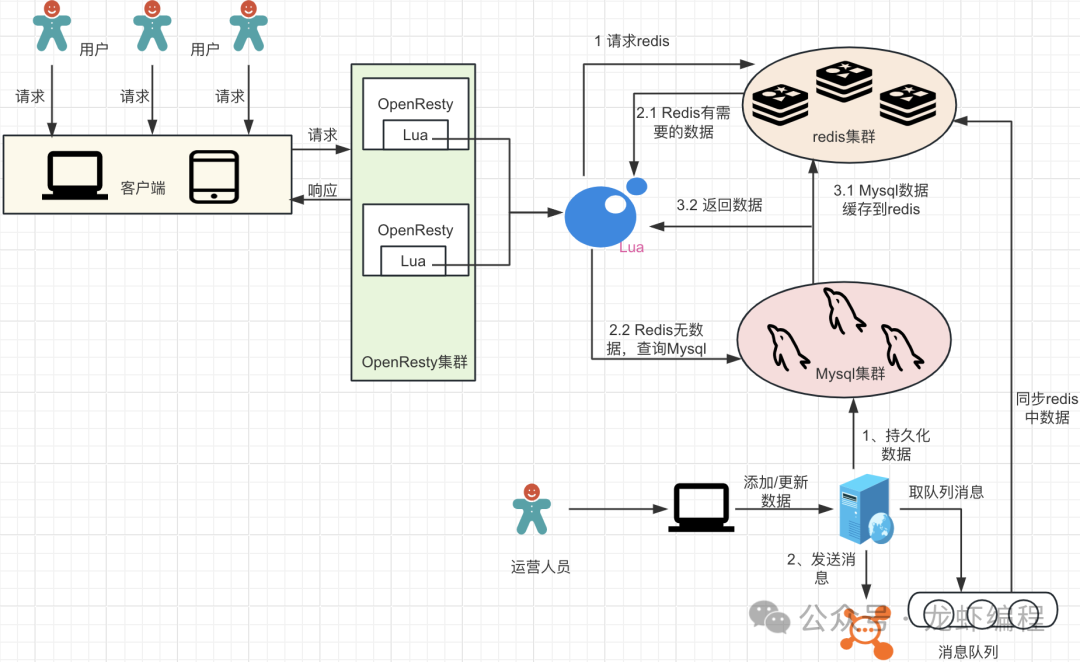
记录些Redis题集(1)
Redis内存淘汰触发条件的相关配置如下: Redis通过配置项maxmemory来设定其允许使用的最大内存容量。当Redis实际占用的内存达到这一阈值时,将触发内存淘汰机制,开始删除部分数据以释放内存空间,防止服务因内存溢出而异常。 Redi…...

防火墙双机热备带宽管理综合实验
一、实验拓扑 二、实验要求 12,对现有网络进行改造升级,将当个防火墙组网改成双机热备的组网形式,做负载分担模式,游客区和DMZ区走FW3,生产区和办公区的流量走FW1 13,办公区上网用户限制流量不超过100M&am…...

【Redis】哨兵(sentinel)
文章目录 一、哨兵是什么?二、 哨兵sentinel文件参数三、 模仿主机redis宕机四、哨兵运行流程和选举原理SDOWN主观下线ODOWN客观下线 五、 使用建议 以下是本篇文章正文内容 一、哨兵是什么? 哨兵巡查监控后台master主机是否故障,如果故障了…...
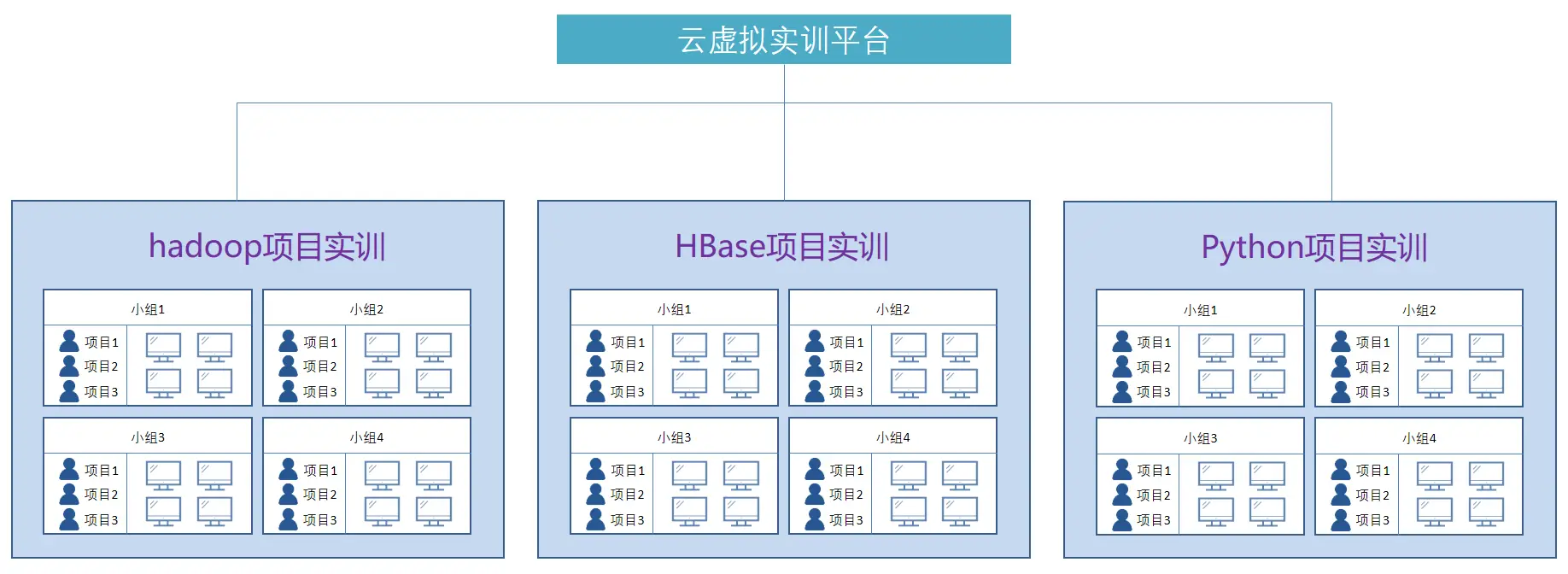
2024年高职云计算实验室建设及云计算实训平台整体解决方案
随着云计算技术的飞速发展,高职院校亟需构建一个与行业需求紧密结合的云计算实验室和实训平台。以下是针对2024年高职院校云计算实验室建设的全面解决方案。 1、在高职云计算实验室的建设与规划中,首要任务是立足于云计算学科的精准定位,紧密…...

入门实战篇,利用PADS Layout画电阻电容电感的封装
大家好,我是山羊君Goat。 不管怎么设计,怎么学习硬件知识,都需要实战,硬件工程师设计PCB是必不可少的(大部分来说),本篇主要从最基本的电阻电容电感的PCB设计封装来说起,算是最基础…...

桌面图标变白纸别慌!手把手教你用右键属性+路径复制,5分钟找回所有软件图标
桌面图标异常修复指南:从白纸图标到完整恢复的实战解析 电脑桌面上那些熟悉的图标突然变成白纸,这种看似小问题却让人倍感困扰。不必惊慌,这通常是系统图标缓存更新不及时或软件关联异常导致的常见现象。本文将带你深入理解图标显示机制&…...

告别重复配置!我如何用自定义Debian Live镜像实现5分钟快速部署测试环境
5分钟极速部署:打造你的专属Debian Live镜像全攻略 每次面对新机器部署测试环境时,你是否也厌倦了重复安装Docker、配置SSH、调试网络这些机械操作?作为一名常年奔波于客户现场的安全工程师,我曾花费无数个下午在咖啡厅里等待apt-…...

Netlify CLI 部署完全指南:从零到生产环境的10个步骤
Netlify CLI 部署完全指南:从零到生产环境的10个步骤 【免费下载链接】cli Netlify Command Line Interface 项目地址: https://gitcode.com/gh_mirrors/cli16/cli Netlify CLI 是一款功能强大的命令行工具,能帮助开发者轻松实现从本地开发到生产…...

SpringBoot+Vue房屋买卖平台源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

如何选择最佳视频播放器?Awesome Video推荐15款跨平台解决方案
如何选择最佳视频播放器?Awesome Video推荐15款跨平台解决方案 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video …...

Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案
Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下这样的场景:您坐在客厅沙发上…...
:仅支持至2024年Q3 API v2退役前)
【限时开放】ElevenLabs波斯文语音调试秘钥包(含Persian SSML扩展标签库、RTL音频波形对齐工具、实时音素诊断CLI):仅支持至2024年Q3 API v2退役前
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs波斯文语音支持的演进与技术边界 ElevenLabs自2022年推出多语言TTS服务以来,波斯文(Farsi)长期处于实验性支持阶段。早期版本仅能通过自定义音色音素级微调…...

ViMax 为什么会冲上 GitHub Trending:AI 视频生成开始从“出片”转向“制片”
今天刷 GitHub Trending 时,ViMax 这项目很难不注意到。它挂着 674 stars today 的当日热度,标题写得也很直接:Agentic Video Generation,导演、编剧、制片、视频生成一体化。真正让我觉得它值得写,不只是因为它又是一…...

免费在线去水印软件怎样选择?2026 优缺点对比及推荐指南
随着内容创作和素材收集的日常化,去水印的需求越来越普遍。一张素材上的水印、一段视频中的平台标志,都可能影响二次创作或个人使用的体验。市面上的去水印方案从专业软件到在线工具五花八门,选择合适的工具需要了解各自的特点和适用场景。本…...

鸿蒙生鲜电商页面构建:商品网格与配送档期模块详解
鸿蒙生鲜电商页面构建:商品网格与配送档期模块详解 前言 在 HarmonyOS 6.0 应用开发中,生鲜电商页面的商品展示和配送服务是两个直接影响转化率的核心模块。本文将以“鲜选菜篮”应用中的“精选货架”商品网格和“配送档期”时间选择模块为例,…...