微调 Florence-2 - 微软的尖端视觉语言模型
Florence-2 是微软于 2024 年 6 月发布的一个基础视觉语言模型。该模型极具吸引力,因为它尺寸很小 (0.2B 及 0.7B) 且在各种计算机视觉和视觉语言任务上表现出色。
Florence 开箱即用支持多种类型的任务,包括: 看图说话、目标检测、OCR 等等。虽然覆盖面很广,但仍有可能你的任务或领域不在此列,也有可能你希望针对自己的任务更好地控制模型输出。此时,你就需要微调了!
本文,我们展示了一个在 DocVQA 上微调 Florence 的示例。尽管原文宣称 Florence 2 支持视觉问答 (VQA) 任务,但最终发布的模型并未包含 VQA 功能。因此,我们正好拿这个任务练练手,看看我们能做点什么!
预训练细节与模型架构
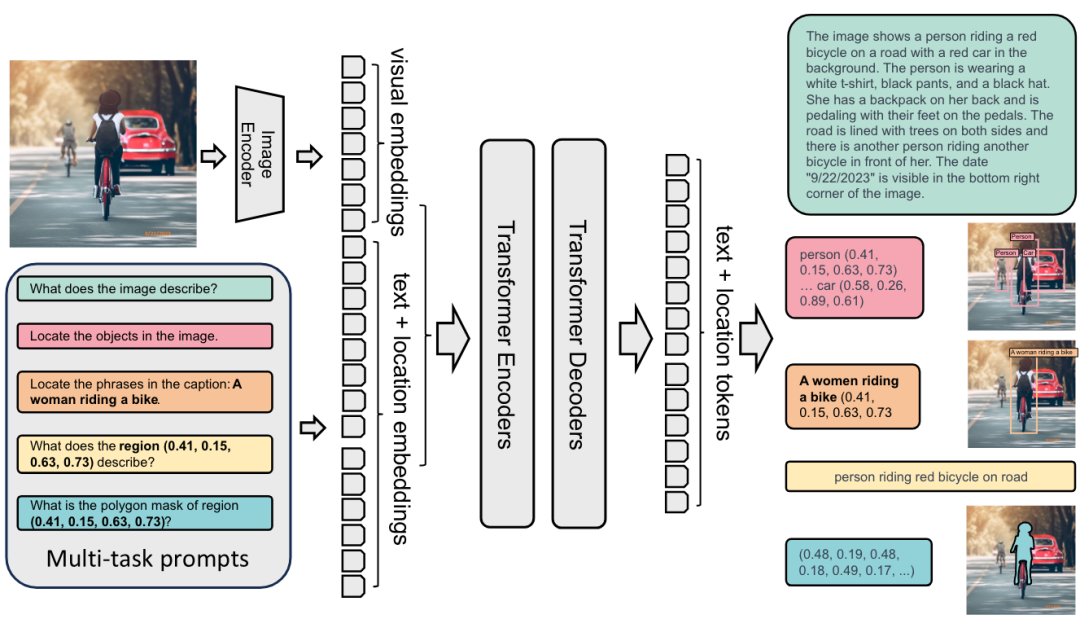
Florence-2 架构
无论执行什么样的计算机视觉任务,Florence-2 都会将其建模为序列到序列的任务。Florence-2 以图像和文本作为输入,并输出文本。模型结构比较简单: 用 DaViT 视觉编码器将图像转换为视觉嵌入,并用 BERT 将文本提示转换为文本和位置嵌入; 然后,生成的嵌入由标准编码器 - 解码器 transformer 架构进行处理,最终生成文本和位置词元。Florence-2 的优势并非源自其架构,而是源自海量的预训练数据集。作者指出,市面上领先的计算机视觉数据集通常所含信息有限 - WIT 仅有图文对,SA-1B仅有图像及相关分割掩码。因此,他们决定构建一个新的 FLD-5B 数据集,其中的每个图像都包含最广泛的信息 - 目标框、掩码、描述文本及标签。在创建数据集时,很大程度采用了自动化的过程,作者使用现成的专门任务模型,并用一组启发式规则及质检过程来清理所获得的结果。最终生成的用于预训练 Florence-2 模型的新数据集中包含了 1.26 亿张图像、超过 50 亿个标注。
SA-1Bhttps://ai.meta.com/datasets/segment-anything/
VQA 上的原始性能
我们尝试了各种方法来微调模型以使其适配 VQA (视觉问答) 任务的响应方式。迄今为止,我们发现最有效方法将其建模为图像区域描述任务,尽管其并不完全等同于 VQA 任务。看图说话任务虽然可以输出图像的描述性信息,但其不允许直接输入问题。
我们还测试了几个“不支持”的提示,例如 “<VQA>”、“<vqa>” 以及 “<Visual question answering>”。不幸的是,这些尝试的产生的结果都不可用。
微调后在 DocVQA 上的性能
我们使用 DocVQA 数据集的标准指标Levenshtein 相似度来测量性能。微调前,模型在验证集上的输出与标注的相似度为 0,因为模型输出与标注差异不小。对训练集进行 7 个 epoch 的微调后,验证集上的相似度得分提高到了 57.0。
Levenshtein 相似度https://en.wikipedia.org/wiki/Levenshtein_distance
我们创建了一个🤗 空间以演示微调后的模型。虽然该模型在 DocVQA 上表现良好,但在一般文档理解方面还有改进的空间。但我们仍然认为,它成功地完成了任务,展示了 Florence-2 对下游任务进行微调的潜力。我们建议大家使用The Cauldron数据集对 Florence-2 进行微调,大家可以在我们的 GitHub 页面上找到必要的代码。
🤗 空间https://hf.co/spaces/andito/Florence-2-DocVQA
The Cauldronhttps://hf.co/datasets/HuggingFaceM4/the_cauldron
我们的 GitHub 页面https://github.com/andimarafioti/florence2-finetuning
下图给出了微调前后的推理结果对比。你还可以至此处亲自试用模型。
模型试用地址https://hf.co/spaces/andito/Florence-2-DocVQA

微调前后的结果
微调细节
由原文我们可以知道,基础模型在预训练时使用的 batch size 为 2048,大模型在预训练时使用的 batch size 为 3072。另外原文还说: 与冻结图像编码器相比,使用未冻结的图像编码器进行微调能带来性能改进。
我们在低资源的情况下进行了多组实验,以探索模型如何在更受限的条件下进行微调。我们冻结了视觉编码器,并在Colab的分别使用单张 A100 GPU (batch size 6) 、单张 T4 (batch size 1) 顺利完成微调。
Colab 链接https://colab.research.google.com/drive/1hKDrJ5AH_o7I95PtZ9__VlCTNAo1Gjpf?usp=sharing
与此同时,我们还对更多资源的情况进行了实验,以 batch size 64 对整个模型进行了微调。在配备 8 张 H100 GPU 的集群上该训练过程花费了 70 分钟。你可以在这里找到我们训得的模型。
模型地址https://hf.co/HuggingFaceM4/Florence-2-DocVQA
我们都发现 1e-6 的小学习率适合上述所有训练情形。如果学习率变大,模型将很快过拟合。
遛代码
如果你想复现我们的结果,可以在此处找到我们的 Colab 微调笔记本。下面,我们遛一遍在DocVQA上微调Florence-2-base-ft模型。
Colab 地址https://colab.research.google.com/drive/1hKDrJ5AH_o7I95PtZ9__VlCTNAo1Gjpf?usp=sharing
DocVQAhttps://hf.co/datasets/HuggingFaceM4/DocumentVQA
Florence-2-base-fthttps://hf.co/microsoft/Florence-2-base-ft
我们从安装依赖项开始。
!pip install -q datasets flash_attn timm einops接着,从 Hugging Face Hub 加载 DocVQA 数据集。
import torch
from datasets import load_datasetdata = load_dataset("HuggingFaceM4/DocumentVQA")我们可以使用 transformers 库中的 AutoModelForCausalLM 和 AutoProcessor 类来加载模型和处理器,并设 trust_remote_code=True ,因为该模型尚未原生集成到 transformers 中,因此需要使用自定义代码。我们还会冻结视觉编码器,以降低微调成本。
from transformers import AutoModelForCausalLM, AutoProcessor
import torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-base-ft",trust_remote_code=True,revision='refs/pr/6'
).to(device)
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-base-ft",trust_remote_code=True, revision='refs/pr/6')for param in model.vision_tower.parameters():param.is_trainable = False现在开始微调模型!我们构建一个训练 PyTorch 数据集,并为数据集中的每个问题添加 <DocVQA> 前缀。
import torch from torch.utils.data import Datasetclass DocVQADataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):example = self.data[idx]question = "<DocVQA>" + example['question']first_answer = example['answers'][0]image = example['image'].convert("RGB")return question, first_answer, image接着,构建数据整理器,从数据集样本构建训练 batch,以用于训练。在 40GB 内存的 A100 中,batch size 可设至 6。如果你在 T4 上进行训练,batch size 就只能是 1。
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AdamW, get_schedulerdef collate_fn(batch):questions, answers, images = zip(*batch)inputs = processor(text=list(questions), images=list(images), return_tensors="pt", padding=True).to(device)return inputs, answerstrain_dataset = DocVQADataset(data['train'])
val_dataset = DocVQADataset(data['validation'])
batch_size = 6
num_workers = 0train_loader = DataLoader(train_dataset, batch_size=batch_size,collate_fn=collate_fn, num_workers=num_workers, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size,collate_fn=collate_fn, num_workers=num_workers)开始训练模型:
epochs = 7
optimizer = AdamW(model.parameters(), lr=1e-6)
num_training_steps = epochs * len(train_loader)lr_scheduler = get_scheduler(name="linear", optimizer=optimizer,num_warmup_steps=0, num_training_steps=num_training_steps,)for epoch in range(epochs):model.train()train_loss = 0i = -1for inputs, answers in tqdm(train_loader, desc=f"Training Epoch {epoch + 1}/{epochs}"):i += 1input_ids = inputs["input_ids"]pixel_values = inputs["pixel_values"]labels = processor.tokenizer(text=answers, return_tensors="pt", padding=True, return_token_type_ids=False).input_ids.to(device)outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=labels)loss = outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()train_loss += loss.item()avg_train_loss = train_loss / len(train_loader)print(f"Average Training Loss: {avg_train_loss}")model.eval()val_loss = 0with torch.no_grad():for batch in tqdm(val_loader, desc=f"Validation Epoch {epoch + 1}/{epochs}"):inputs, answers = batchinput_ids = inputs["input_ids"]pixel_values = inputs["pixel_values"]labels = processor.tokenizer(text=answers, return_tensors="pt", padding=True, return_token_type_ids=False).input_ids.to(device)outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=labels)loss = outputs.lossval_loss += loss.item()print(val_loss / len(val_loader))你可以分别对模型和处理器调用 save_pretrained() 以保存它们。微调后的模型在此处,你还可以在此处找到其演示。
模型链接https://hf.co/HuggingFaceM4/Florence-2-DocVQA
示例地址https://hf.co/spaces/andito/Florence-2-DocVQA
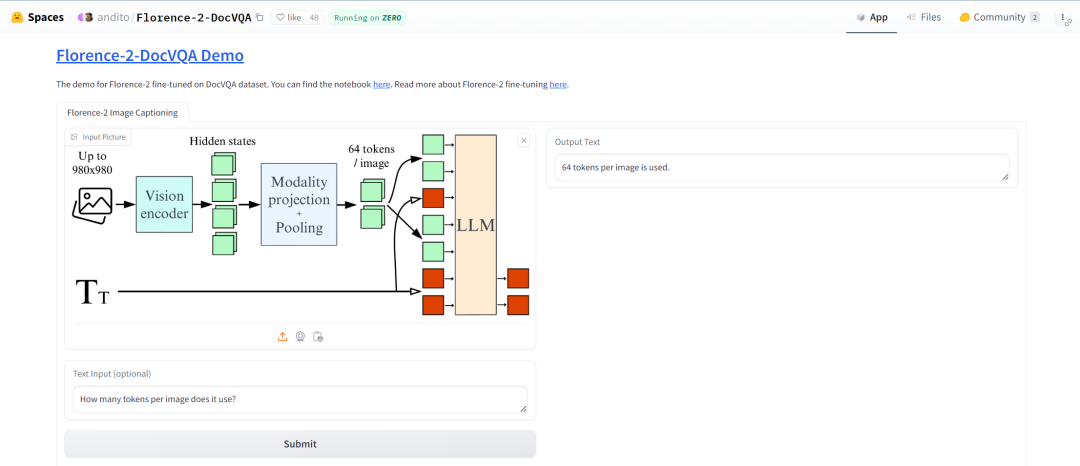
演示示例
总结
本文,我们展示了如何有效地针对自定义数据集微调 Florence-2,以在短时间内在全新任务上取得令人眼前一亮的性能。对于那些希望在设备上或在生产环境中经济高效地部署小模型的人来说,该做法特别有价值。我们鼓励开源社区利用这个微调教程,探索 Florence-2 在各种新任务中的巨大潜力!我们迫不及待地想在 🤗 Hub 上看到你的模型!
有用资源
视觉语言模型详解https://hf.co/blog/zh/vlms
微调 Colabhttps://colab.research.google.com/drive/1hKDrJ5AH_o7I95PtZ9__VlCTNAo1Gjpf?usp=sharing
微调 Github 代码库https://github.com/andimarafioti/florence2-finetuning
Florence-2 推理 Notebookhttps://hf.co/microsoft/Florence-2-large/blob/main/sample_inference.ipynb
Florence-2 DocVQA 演示https://hf.co/spaces/andito/Florence-2-DocVQA
Florence-2 演示https://hf.co/spaces/gokaygo
感谢 Pedro Cuenca 对本文的审阅。
英文原文: https://hf.co/blog/finetune-florence2
原文作者: Andres Marafioti,Merve Noyan,Piotr Skalski
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
相关文章:
微调 Florence-2 - 微软的尖端视觉语言模型
Florence-2 是微软于 2024 年 6 月发布的一个基础视觉语言模型。该模型极具吸引力,因为它尺寸很小 (0.2B 及 0.7B) 且在各种计算机视觉和视觉语言任务上表现出色。 Florence 开箱即用支持多种类型的任务,包括: 看图说话、目标检测、OCR 等等。虽然覆盖面…...

【数据结构】二叉树全攻略,从实现到应用详解
💎所属专栏:数据结构与算法学习 💎 欢迎大家互三:2的n次方_ 🍁1. 树形结构的介绍 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做…...

微信小程序加载动画文件
最近在做微信小程序的动画,调研了几种方案 PAG 腾讯自家的,分为完整版和lite版,对于矢量动画挺好的,但是位图会有问题 完整版会逐渐卡死,lite虽然不会卡死,但是很模糊,优点是动画文件很的很小。…...

[计算机网络] VPN技术
VPN技术 1. 概述 虚拟专用网络(VPN)技术利用互联网服务提供商(ISP)和网络服务提供商(NSP)的网络基础设备,在公用网络中建立专用的数据通信通道。VPN的主要优点包括节约成本和提供安全保障。 优…...

SQL 中的 EXISTS 子句:探究其用途与应用
目录 EXISTS 子句简介语法 EXISTS 与 NOT EXISTSEXISTS 子句的工作原理实际应用场景场景一:筛选存在关联数据的记录场景二:优化查询性能 EXISTS 与其他 SQL 结构的比较EXISTS vs. JOINEXISTS vs. IN 多重 EXISTS 条件在 UPDATE 语句中使用 EXISTS常见问题…...

OpenSearch分析WAF日志
Web应用防火墙(WAF)是保护web应用程序的重要工具,而分析WAF日志可以帮助我们更好地了解安全威胁并优化防护策略。本文将介绍15个使用OpenSearch分析WAF日志的实用例子,涵盖基础统计、安全分析、性能监控等多个方面。 准备工作 在开始之前,请确保: WAF日志已经被发送到OpenSea…...
【前端】零基础学会编写CSS
一、什么是CSS CSS (Cascading Style Sheets,层叠样式表)是一种是一种用来为结构化文档(如 HTML 文档)添加样式(字体、间距和颜色等)的计算机语言,能够对网页中元素位置的排版进行像素级别的精…...
Day07-ES集群加密,kibana的RBAC实战,zookeeper集群搭建,zookeeper基本管理及kafka单点部署实战
Day07-ES集群加密,kibana的RBAC实战,zookeeper集群搭建,zookeeper基本管理及kafka单点部署实战 0、昨日内容回顾:1、基于nginx的反向代理控制访问kibana2、配置ES集群TSL认证:3、配置kibana连接ES集群4、配置filebeat连接ES集群5、配置logsta…...

RK3568 V1.4.0 SDK,USB OTG端子不能被电脑识别出adb设备,解决
修改后的/usr/bin/usbdevice: #!/bin/sh # # Usage: # usbdevice [start|update|stop] # # Hookable stages: # usb_<pre|post>_<init|prepare|start|stop|restart>_hook # <usb function>_<pre|post>_<prepare|start|stop>_hook # # Example …...

如何在 Ubuntu 14.04 服务器上使用 Nginx 安装和保护 phpMyAdmin
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 介绍 像 MySQL 这样的关系型数据库管理系统在许多网站和应用程序中都是必不可少的。然而,并非所有用户都习惯通过命令行来管…...
使用Python举例)
redis存入hash,key=>value和key=>(key=>value)使用Python举例
在 Redis 中,HASH 数据结构(也称为 HMAP 或 Hash Map)允许你存储键值对集合,其中每个键值对都是字段(field)和值(value)的映射。在 Python 中,你可以使用 redis-py 库来与…...

Guava LocalCache源码分析:LocalCache的get、put、expand、refresh、remove、clear、cleanUp
Guava LocalCache源码分析:LocalCache的get、put、expand 前言一、get二、put三、expand 前言 上篇文章,详细描写了Guava LocalCache怎样如ConcurrentHashMap对缓存数据进行了分段存储。本章主要针对LocalCache重要的几个接口进行说明。 一、get CanIg…...

linux-arm ubuntu18.04 qmqtt5.12.6 编译部署
安装 qt 查看qt 版本 : qmake -v 下载对应版本 qmqtt 解压下载的mqtt文件 进入qmqtt xxx/src 目录 在qt 安装目录中创建QtMqtt文件夹, - x86平台qt 默认目录为 /usr/include/x86_64-linux-gnu/qt5 - arm平台qt 默认目录为/us…...

阿里ChatSDK使用,开箱即用聊天框
介绍: 效果:智能助理 ChatSDK,是在ChatUI的基础上,结合阿里云智能客服的最佳实践,沉淀和总结出来的一个开箱即用的,可快速搭建智能对话机器人的框架。它简单易上手,通过简单的配置就能搭建出对…...

LangChain —— Message —— How to trim messages
文章目录 一、概述二、获取最后的 max_tokens 令牌三、获取第一个 max_tokens 令牌四、编写自定义令牌计数器五、连成链六、使用 ChatMessageHistory 一、概述 所有模型都有 有限的 上下文窗口,这意味着它们可以作为输入的 token 数量是有限的。如果你有很长的消息&…...
-升本209天-星期二)
专升本-1.0.3(英语)-升本209天-星期二
自己要耐得住寂寞,守得住自己的初心,守得住自己的未来,然后不断地真实地面对自己,使自己不断地获得一个真实地成长,说真话办真事,自己总会有一条路了,说真话,办真事的那条路才是最为…...
集合媒体管理、分类、搜索于一体的开源利器:Stash
Stash:强大的媒体管理工具,让您的影音生活井井有条- 精选真开源,释放新价值。 概览 Stash是一个专为个人媒体管理而设计的开源工具,基于 Go 编写,支持自部署。它以用户友好的界面和强大的功能,满足了现代用…...
数仓工具—Hive语法之事务表更新Transactional Table Update
Hive事务表更新 众所周知,Apache Hive 是建立在 Hadoop HDFS 之上的数据仓库框架。由于它包含表,您可能希望根据数据的变化更新表记录。直到最近,Apache Hive 还不支持事务。从 Hive 0.14 及以上版本开始支持事务性表。您需要启用 ACID 属性才能在 Hive 查询中使用更新、删…...
)
系统架构师(每日一练2)
每日一练 1.为实现对象重用,COM支持两种形式的对象组装,在()重用形式下,一个外部对象拥有指向一个内部对象的唯一引用,外部对象只是把请求转发给内部对象;在()重用形式下,直接把内部对象的接口引用传给外部对象的客户…...
视图集-ViewSet)
Django REST Framework(十)视图集-ViewSet
视图集(ViewSet)是 Django REST framework 中的一个高级特性,它允许你使用更少的代码来实现标准的 CRUD(创建、读取、更新、删除)操作。ViewSet 类本质上是基于 GenericAPIView 的,但它们提供了更多的默认行…...

Pulover‘s Macro Creator:你的数字助手,让电脑学会“自己工作“
Pulovers Macro Creator:你的数字助手,让电脑学会"自己工作" 【免费下载链接】PuloversMacroCreator Automation Utility - Recorder & Script Generator 项目地址: https://gitcode.com/gh_mirrors/pu/PuloversMacroCreator 你是否…...

RNA-seq公司推荐
RNA-seq公司推荐 伯远生物是国内高通量测序综合性服务商,聚焦RNA-seq全场景服务,覆盖临床、科研、农业等领域,提供一站式测序与分析解决方案; 其临床转化与大样本服务市占率领先,依托自研平台实现高通量、成本可控&…...

SleeperX:macOS系统级电源管理架构解析与深度集成方案
SleeperX:macOS系统级电源管理架构解析与深度集成方案 【免费下载链接】SleeperX MacBook prevent idle/lid sleep! Hackintosh sleep on low battery capacity. 项目地址: https://gitcode.com/gh_mirrors/sl/SleeperX 在macOS生态系统中,电源管…...

十大榜单全覆盖,价值兑现引领:联想定义中国AI企业新高度
当前,全球 AI 产业已正式迈入规模化商业落地的关键周期,“技术炫技”让位于“价值兑现”,“算力筑基—技术创新—场景落地”的协同闭环成为高质量发展的核心逻辑。据《全球首席信息官(CIO)报告:企业级 AI 竞…...

别再只删node_modules了!npm run serve报错‘There is likely additional logging output above’的完整排查与修复手册
从日志溯源到根治:npm run serve报错的系统性排查指南 当你满怀期待地敲下npm run serve,却迎面撞上那句"There is likely additional logging output above"时,是否感到一阵无力?删除node_modules重装就像重启电脑——…...

供应链管理在管什么?终于有人把供应链管理讲明白了
我发现大家都把供应链管理想简单了,觉得它就是管采购砍价、或者管仓库理货,又或者是找物流发货。 你是不是也这么认为? 说白了,供应链管理根本不是单一环节的事,是从客户提出需求到最终签收的全流程的把控。这流程里…...

SSHFS-Win完整指南:如何在Windows上安全访问远程文件系统
SSHFS-Win完整指南:如何在Windows上安全访问远程文件系统 【免费下载链接】sshfs-win SSHFS For Windows 项目地址: https://gitcode.com/gh_mirrors/ss/sshfs-win 如果你需要在Windows系统中安全地访问远程Linux服务器的文件,SSHFS-Win正是你需要…...

Rufus系统兼容性架构升级:Windows 7支持终止的技术决策分析
Rufus系统兼容性架构升级:Windows 7支持终止的技术决策分析 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus Rufus作为业界领先的USB启动盘制作工具,在v4.5版本中做出了终止…...

Pure Live:你的纯净直播聚合解决方案,告别平台切换烦恼
Pure Live:你的纯净直播聚合解决方案,告别平台切换烦恼 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否曾为同时关注多个直播平台的主播而感到…...

【ChatGPT】基于李群、李代数与螺旋理论的 Tricept 并联加工机器人控制系统软硬件架构深度拆解、信息图10张、爆炸图10张、C++代码框架
希望还能够有机会去研究他们(前提是能够遇到好领导)深度拆解...