LangChain —— Message —— How to trim messages
文章目录
- 一、概述
- 二、获取最后的 max_tokens 令牌
- 三、获取第一个 max_tokens 令牌
- 四、编写自定义令牌计数器
- 五、连成链
- 六、使用 ChatMessageHistory
一、概述
所有模型都有 有限的 上下文窗口,这意味着它们可以作为输入的 token 数量是有限的。如果你有很长的消息,或者一个 chain 或 agent 累积了很长的 历史消息,你需要管理你传递给模型的消息的长度。
trim_messages util 提供了一些基本策略,用于将消息列表修剪为特定的 token 长度。
二、获取最后的 max_tokens 令牌
为了获取消息列表中的最后一个 max_tokens,我们可以设置 strategy=“last”。请注意,对于我们的 token_counter,我们可以将其传入到一个函数 (下面将详细介绍) 或一个语言模型 (因为语言模型有一个消息令牌计数方法) 中。当调整消息以适应特定模型的上下文窗口时,将其传入到模型是有意义的:
# pip install -U langchain-openai
from langchain_core.messages import (AIMessage,HumanMessage,SystemMessage,trim_messages,
)
from langchain_openai import ChatOpenAImessages = [SystemMessage("you're a good assistant, you always respond with a joke."),HumanMessage("i wonder why it's called langchain"),AIMessage('Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'),HumanMessage("and who is harrison chasing anyways"),AIMessage("Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!"),HumanMessage("what do you call a speechless parrot"),
]trim_messages(messages,max_tokens=45,strategy="last",token_counter=ChatOpenAI(model="gpt-4o"),
)
如果我们想始终保留初始系统消息,我们可以指定 include_system=True:
如果我们想允许拆分消息的内容,我们可以指定 allow_partial=True:
如果我们需要确保我们的第一条消息 (不包括 SystemMessage) 始终是特定类型的,我们可以指定 start_on:
trim_messages(messages,max_tokens=60,strategy="last",token_counter=ChatOpenAI(model="gpt-4o"),include_system=True,start_on="human",
)
三、获取第一个 max_tokens 令牌
我们可以通过指定 strategy=“first” 来执行获取第一个 max_tokens 的翻转操作:
trim_messages(messages,max_tokens=45,strategy="first",token_counter=ChatOpenAI(model="gpt-4o"),
)
四、编写自定义令牌计数器
我们可以编写一个自定义令牌计数器函数,该函数接收消息列表并返回一个整数。
from typing import List
# pip install tiktoken
import tiktoken
from langchain_core.messages import BaseMessage, ToolMessagedef str_token_counter(text: str) -> int:enc = tiktoken.get_encoding("o200k_base")return len(enc.encode(text))def tiktoken_counter(messages: List[BaseMessage]) -> int:"""Approximately reproduce https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynbFor simplicity only supports str Message.contents."""num_tokens = 3 # every reply is primed with <|start|>assistant<|message|>tokens_per_message = 3tokens_per_name = 1for msg in messages:if isinstance(msg, HumanMessage):role = "user"elif isinstance(msg, AIMessage):role = "assistant"elif isinstance(msg, ToolMessage):role = "tool"elif isinstance(msg, SystemMessage):role = "system"else:raise ValueError(f"Unsupported messages type {msg.__class__}")num_tokens += (tokens_per_message+ str_token_counter(role)+ str_token_counter(msg.content))if msg.name:num_tokens += tokens_per_name + str_token_counter(msg.name)return num_tokenstrim_messages(messages,max_tokens=45,strategy="last",token_counter=tiktoken_counter,
)
- 定义 str_token_counter 函数
- 该函数接受一个字符串 text 并返回该字符串的令牌数量。
- 使用 tiktoken.get_encoding(“o200k_base”) 获取编码器,然后使用 enc.encode(text) 将文本编码为令牌,并返回令牌的长度。
- 定义 tiktoken_counter 函数:
- 该函数接受一个 BaseMessage 类型的消息列表 messages 并返回总的令牌数量。
- 由于每个回复都以 <|start|>assistance<|message|> 开头,所以每个消息列表初始都默认有 3 个 token,每个消息有一个基本的令牌数 tokens_per_message,每个 name 属性预设的固定令牌数 tokens_per_name,假设其值为 1。
- 函数通过迭代消息列表,并根据消息的角色 (如 user、assistant、tool、system) 计算令牌数量。
- 根据消息的 tokens_per_message、role、content,计算总的令牌数。
- 如果遇到不支持的消息类型,会引发 ValueError。
- 对于每个消息,如果消息对象 msg 有 name 属性 (即 msg.name 不为 None 或空),那么就要计算该 name 属性所包含的令牌数量,并将其加入到总令牌数 num_tokens 中。
- 调用 trim_messages 函数 (假设定义在其他地方):
- messages:要处理的消息列表。
- max_tokens=45:最大允许的令牌数。
- strategy=“last”:修剪策略 (假设修剪最后的消息)。
- token_counter=tiktoken_counter:用于计算令牌数的函数。
五、连成链
trim_message可以以命令式(如上所述)或声明式的方式使用,从而便于与链中的其他组件组合。
llm = ChatOpenAI(model="gpt-4o")# Notice we don't pass in messages. This creates
# a RunnableLambda that takes messages as input
trimmer = trim_messages(max_tokens=45,strategy="last",token_counter=llm,include_system=True,
)chain = trimmer | llm
chain.invoke(messages)
查看 LangSmith 跟踪,我们可以看到,在消息传递到模型之前,它们首先被修剪。
如果只看 trimer,我们可以看到它是一个Runnable对象,可以像所有Runnables一样被调用:
trimmer.invoke(messages)
六、使用 ChatMessageHistory
在处理聊天历史记录时,修剪消息特别有用,因为聊天历史记录可能会变得任意长:
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistorychat_history = InMemoryChatMessageHistory(messages=messages[:-1])def dummy_get_session_history(session_id):if session_id != "1":return InMemoryChatMessageHistory()return chat_historyllm = ChatOpenAI(model="gpt-4o")trimmer = trim_messages(max_tokens=45,strategy="last",token_counter=llm,include_system=True,
)chain = trimmer | llm
chain_with_history = RunnableWithMessageHistory(chain, dummy_get_session_history)
chain_with_history.invoke([HumanMessage("what do you call a speechless parrot")],config={"configurable": {"session_id": "1"}},
)
- 第四行,创建一个 InMemoryChatMessageHistory 对象 chat_history,并初始化它的消息历史为 messages 列表 (除了最后一个消息)。
- 第六行,定义一个函数 dummy_get_session_history,根据 session_id 返回相应的聊天历史记录:
- 如果 session_id 不等于 “1”,则返回一个新的空的 InMemoryChatMessageHistory 对象。
- 如果 session_id 等于 “1”,则返回之前定义的 chat_history。
- 倒数第五行,创建一个 RunnableWithMessageHistory 对象 chain_with_history,将 chain 和 dummy_get_session_history 结合在一起,使其能够处理带有历史记录的消息。
- 倒数第四行,调用 chain_with_history 对象的 invoke 方法,传入一个包含 HumanMessage(“what do you call a speechless parrot”) 的列表,和配置 {“configurable”: {“session_id”: “1”}}:
- 该方法将根据 session_id 为 “1” 调用 dummy_get_session_history 返回相应的历史记录。
- 将消息传递给链 chain,先修剪再由 llm 处理。
查看 LangSmith 跟踪,我们可以看到我们检索了所有消息,但在将消息传递给模型之前,它们被修剪成只有系统消息和最后一条人类消息。
相关文章:

LangChain —— Message —— How to trim messages
文章目录 一、概述二、获取最后的 max_tokens 令牌三、获取第一个 max_tokens 令牌四、编写自定义令牌计数器五、连成链六、使用 ChatMessageHistory 一、概述 所有模型都有 有限的 上下文窗口,这意味着它们可以作为输入的 token 数量是有限的。如果你有很长的消息&…...
-升本209天-星期二)
专升本-1.0.3(英语)-升本209天-星期二
自己要耐得住寂寞,守得住自己的初心,守得住自己的未来,然后不断地真实地面对自己,使自己不断地获得一个真实地成长,说真话办真事,自己总会有一条路了,说真话,办真事的那条路才是最为…...
集合媒体管理、分类、搜索于一体的开源利器:Stash
Stash:强大的媒体管理工具,让您的影音生活井井有条- 精选真开源,释放新价值。 概览 Stash是一个专为个人媒体管理而设计的开源工具,基于 Go 编写,支持自部署。它以用户友好的界面和强大的功能,满足了现代用…...
数仓工具—Hive语法之事务表更新Transactional Table Update
Hive事务表更新 众所周知,Apache Hive 是建立在 Hadoop HDFS 之上的数据仓库框架。由于它包含表,您可能希望根据数据的变化更新表记录。直到最近,Apache Hive 还不支持事务。从 Hive 0.14 及以上版本开始支持事务性表。您需要启用 ACID 属性才能在 Hive 查询中使用更新、删…...
)
系统架构师(每日一练2)
每日一练 1.为实现对象重用,COM支持两种形式的对象组装,在()重用形式下,一个外部对象拥有指向一个内部对象的唯一引用,外部对象只是把请求转发给内部对象;在()重用形式下,直接把内部对象的接口引用传给外部对象的客户…...
视图集-ViewSet)
Django REST Framework(十)视图集-ViewSet
视图集(ViewSet)是 Django REST framework 中的一个高级特性,它允许你使用更少的代码来实现标准的 CRUD(创建、读取、更新、删除)操作。ViewSet 类本质上是基于 GenericAPIView 的,但它们提供了更多的默认行…...

sping总览
一、spring体系 1. spring是什么? 轻量级的开源的J2EE框架。它是一个容器框架,主要实现了ioc,同时又通过aop实现了面向切面编程,它又是一个中间层框架(万能胶)可以起一个连接作用,比如说把myba…...

【Godot4.2】MLTag类:HTML、XML通用标签类
概述 HTML和XML采用类似的标签形式。 之前在Godot中以函数库形式实现了网页标签和内容生成。能用,但是缺点也很明显。函数之间没有从属关系,但是多有依赖,而且没有划分出各种对象和类型。 如果以完全的面向对象形式来设计标签类或者元素类…...

美式键盘 QWERTY 布局的起源
注:机翻,未校对。 The QWERTY Keyboard Is Tech’s Biggest Unsolved Mystery QWERTY 键盘是科技界最大的未解之谜 It’s on your computer keyboard and your smartphone screen: QWERTY, the first six letters of the top row of the standard keybo…...

【JavaEE】HTTP(2)
🤡🤡🤡个人主页🤡🤡🤡 🤡🤡🤡JavaEE专栏🤡🤡🤡 🤡🤡🤡下一篇文章:【JavaEE】HTTP协议(…...

LinuxShell编程2——shell搭建Discuzz论坛网站
目录 一、环境准备 ①准备一台虚拟机 ②初始化虚拟机 1、关闭防火墙 2、关闭selinux 3、配置yum源 4、修改主机名 二、搭建LAMP环境 ①安装httpd(阿帕奇apache)服务器 查看是否安装过httpd 启动httpd 设置开机启动 查看状态 安装网络工具 测试 ②安装…...

.NET MAUI开源架构_1.学习资源分享
最近需要开发Android的App,想预研下使用.NET开源架构.NET MAUI来开发App程序。因此网上搜索了下相关资料,现在把我查询的结果记录下,方便后面学习。 1.官方文档 1.1MAUI官方学习网站 .NET Multi-Platform App UI 文档 - .NET MAUI | Micro…...

Unsloth 微调 Llama 3
本文参考: https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp 改编自:https://blog.csdn.net/qq_38628046/article/details/138906504 文章目录 一、项目说明安装相关依赖下载模型和数据 二、训练1、加载 model、tokenizer2、…...

热修复的原理
热修复的原理 水一篇哈,完事儿后删掉热修复的原理 水一篇哈,完事儿后删掉 热修复的原理 Java虚拟机 —— JVM 是加载类的class文件的,而Android虚拟机——Dalvik/ART VM 是加载类的dex文件,而他们加载类的时候都需要ClassLoader,…...

【对顶堆 优先队列】2102. 序列顺序查询
本文涉及知识点 对顶堆 优先队列 LeetCode 2102. 序列顺序查询 一个观光景点由它的名字 name 和景点评分 score 组成,其中 name 是所有观光景点中 唯一 的字符串,score 是一个整数。景点按照最好到最坏排序。景点评分 越高 ,这个景点越好。…...

Go 语言中的互斥锁 Mutex
Mutex 是一种互斥锁,名称来自 mutual exclusion,是一种用于控制多线程对共享资源的竞争访问的同步机制。在有的编程语言中,也将其称为锁(lock)。当一个线程获取互斥锁时,它将阻止其他线程对该资源的访问,直到该线程释放锁。这可以防止多个线程对共享资源进行冲突访问,从而…...

CSS 中的 ::before 和 ::after 伪元素
目录 一、CSS 伪元素 二、::before ::after 介绍 1、::before 2、::after 3、content 常用属性值 三、::before ::after 应用场景 1、设置统一字符 2、通过背景添加图片 3、添加装饰线 4、右侧展开箭头 5、对话框小三角 6、插入icon图标 一、CSS 伪元素 CSS伪元…...
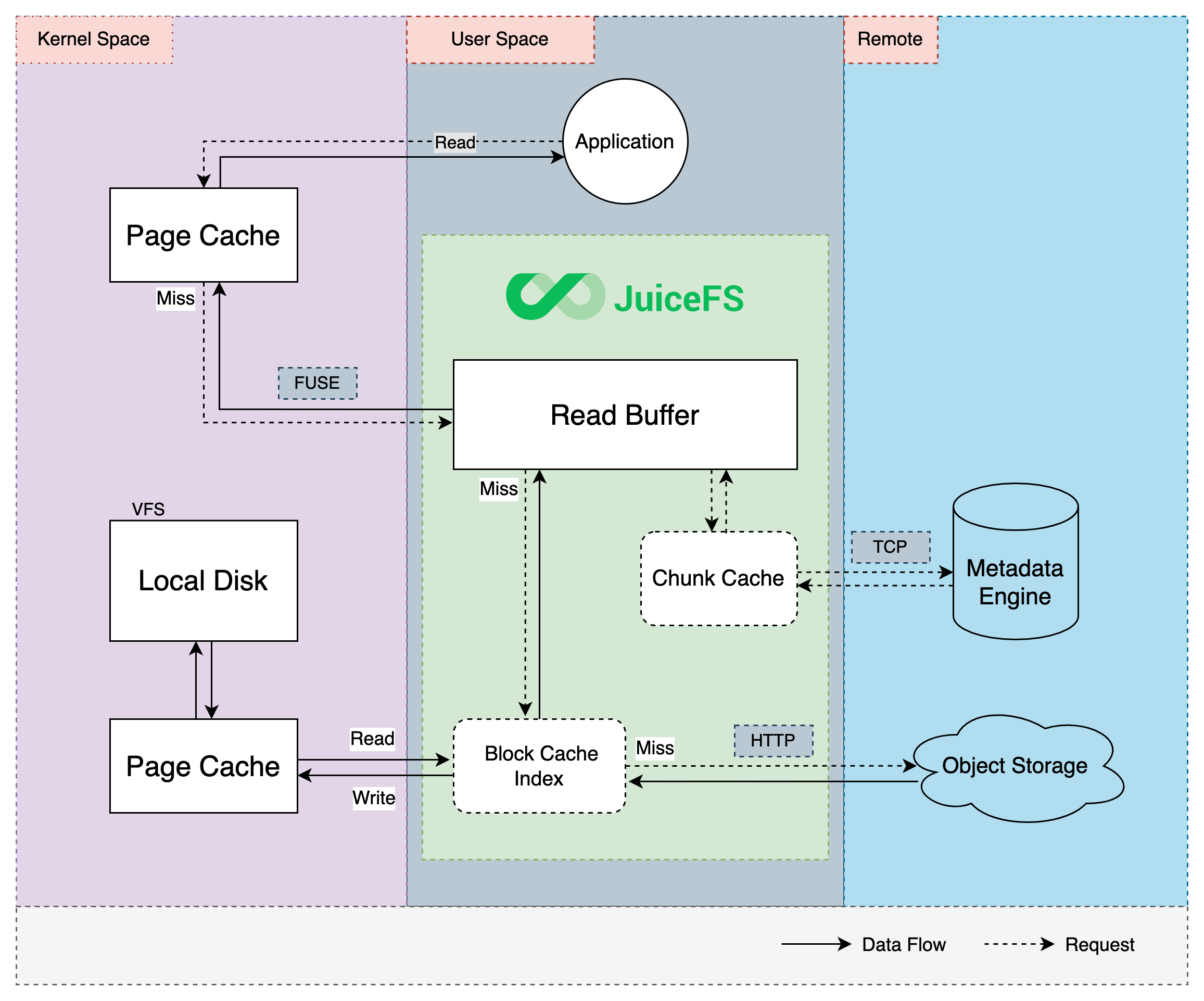
JuiceFS缓存特性
缓存 对于一个由对象存储和数据库组合驱动的文件系统,缓存是本地客户端与远端服务之间高效交互的重要纽带。读写的数据可以提前或者异步载入缓存,再由客户端在后台与远端服务交互执行异步上传或预取数据。相比直接与远端服务交互,采用缓存技…...

R语言实现SVM算法——分类与回归
### 11.6 基于支持向量机进行类别预测 ### # 构建数据子集 X <- iris[iris$Species! virginica,2:3] # 自变量:Sepal.Width, Petal.Length y <- iris[iris$Species ! virginica,Species] # 因变量 plot(X,col y,pch as.numeric(y)15,cex 1.5) # 绘制散点图…...
Redux@4.x(6)- 实现 bindActionCreators)
React@16.x(57)Redux@4.x(6)- 实现 bindActionCreators
目录 1,分析1,直接传入函数2,传入对象 2,实现 1,分析 一般情况下,action 并不是一个写死的对象,而是通过函数来获取。 而 bindActionCreators 的作用:为了更方便的使用创建 action…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》019、TimeSformer-DEIM与SlowFast-DEIM
CVPR2025-DEIM创新改进项目实战:TimeSformer-DEIM与SlowFast-DEIM 一、从一次诡异的显存爆炸说起 去年年底,我在调试一个视频行为识别模型时遇到了一个让人抓狂的问题。模型用的是TimeSformer,输入是32帧224x224的视频片段,batch size设了8,按理说A100 80G应该绰绰有余。…...

如何免费获取百度文库文档:三步实现纯净打印保存的实用技巧
如何免费获取百度文库文档:三步实现纯净打印保存的实用技巧 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要…...

对比按需计费与 Token Plan 套餐哪种方式更适合长期项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与 Token Plan 套餐哪种方式更适合长期项目 在长期且用量稳定的开发项目中,如何选择成本模型是技术决策的…...

为什么你需要英雄联盟Akari助手:3个步骤提升游戏效率的完整指南
为什么你需要英雄联盟Akari助手:3个步骤提升游戏效率的完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁…...

抖音批量下载器终极指南:3步轻松搞定无水印视频下载
抖音批量下载器终极指南:3步轻松搞定无水印视频下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

Vue.js 版本全解析与 nvm 环境管理完全指南
前言:为什么需要了解这些?在前端开发的世界里,Vue.js 已经成为最受欢迎的框架之一。但在实际工作中,我们常常会面临两个问题:项目 A 需要用 Vue 2(为了兼容 IE11),项目 B 想用 Vue 3…...

利用 QiWe API 实现企业微信机器人消息双向交互
1. 什么是企微机器人的“多模态”交互? 早期的微信机器人大多只能处理简单的纯文本对话。然而,在真实的商业客服场景中,客户往往会发送商品图片、发票PDF文件、产品操作视频甚至是语音消息。一个合格的企业级机器人,必须具备处理和…...

BMS工程师必看:用南京集澈DVC1006做外部被动均衡,这几点时序和奇偶机制千万别搞错
BMS工程师实战指南:DVC1006被动均衡设计的五大关键陷阱与解决方案 在新能源汽车和储能系统井喷式发展的今天,电池管理系统(BMS)的可靠性直接决定了整个电池包的安全边界。作为国内AFE芯片的标杆产品,南京集澈DVC1006凭借其高集成度与稳定性&…...

FPGA通信系统设计避坑指南:Costas环载波同步的Verilog实现与常见问题排查
FPGA通信系统设计避坑指南:Costas环载波同步的Verilog实现与常见问题排查 在无线通信接收机设计中,载波同步是确保数据正确解调的关键环节。Costas环作为一种经典的载波同步方案,广泛应用于BPSK、QPSK等相位调制系统。然而,从理论…...

Graphviz 高级技巧:如何优化复杂图形的布局与渲染
Graphviz 高级技巧:如何优化复杂图形的布局与渲染 【免费下载链接】graphviz Simple Python interface for Graphviz 项目地址: https://gitcode.com/gh_mirrors/gr/graphviz Graphviz 是一款强大的图形可视化工具,通过其简单的 Python 接口&…...