Unsloth 微调 Llama 3
本文参考:
https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp
改编自:https://blog.csdn.net/qq_38628046/article/details/138906504
文章目录
- 一、项目说明
- 安装相关依赖
- 下载模型和数据
- 二、训练
- 1、加载 model、tokenizer
- 2、设置LoRA训练参数
- 3、准备数据集
- 数据格式处理
- 加载数据集并进行映射处理操作
- 4、训练超参数配置
- SFTTrainer
- 显示当前内存状态
- 5、执行训练
- 6、模型推理
- 7、保存LoRA模型
- 8、加载模型
- 9、执行推理
- 10、保存完整模型
- 11、保存为GGUF格式
一、项目说明
Llama-3-Chinese-Instruct 是基于Meta Llama-3的中文开源大模型,其在原版Llama-3的基础上使用了大规模中文数据进行增量预训练,并且使用精选指令数据进行精调,进一步提升了中文基础语义和指令理解能力,相比二代相关模型获得了显著性能提升。
GitHub:https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
安装相关依赖
unsloth 根据不同改的 cuda 版本有不同的安装方式,详见:https://blog.csdn.net/lovechris00/article/details/140404957
pip install --no-deps "xformers<0.0.26" trl peft accelerate bitsandbytes
下载模型和数据
Unsloth 支持很多模型: https://huggingface.co/unsloth,包括 mistral,llama,gemma
这里我们使用 FlagAlpha/Llama3-Chinese-8B-Instruct 模型 和 kigner/ruozhiba-llama3 数据集
提前下载:
export HF_ENDPOINT=https://hf-mirror.comhuggingface-cli download FlagAlpha/Llama3-Chinese-8B-Instruct
uggingface-cli download --repo-type dataset kigner/ruozhiba-llama3
数据将保存到 ~/.cache/huggingface/hub 下
你也可以使用 modelscope下载,如:
from modelscope import snapshot_downloadmodel_dir = snapshot_download('FlagAlpha/Llama3-Chinese-8B-Instruct',cache_dir="/root/models")
安装 modelscope
pip install modelscope
二、训练
1、加载 model、tokenizer
from unsloth import FastLanguageModel
import torchmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "/root/models/Llama3-Chinese-8B-Instruct", # 模型路径max_seq_length = 2048, # 可以设置为任何值内部做了自适应处理# dtype = torch.float16, # 数据类型使用float16dtype = None, # 会自动推断类型load_in_4bit = True, # 使用4bit量化来减少内存使用
2、设置LoRA训练参数
model = FastLanguageModel.get_peft_model(model,r = 16, # 选择任何大于0的数字!建议使用8、16、32、64、128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = 16,lora_dropout = 0, # 支持任何值,但等于0时经过优化bias = "none", # 支持任何值,但等于"none"时经过优化# [NEW] "unsloth" 使用的VRAM减少30%,适用于2倍更大的批处理大小!use_gradient_checkpointing = "unsloth", # True或"unsloth"适用于非常长的上下文random_state = 3407,use_rslora = False, # 支持排名稳定的LoRAloftq_config = None, # 和LoftQ
3、准备数据集
准备数据集其实就是指令集构建,LLM的微调一般指指令微调过程。所谓指令微调,就是使用指定的微调数据格式、形式。
训练目标是让模型具有理解并遵循用户指令的能力。因此在指令集构建时,应该针对目标任务,针对性的构建任务指令集。
这里使用 alpaca 格式的数据集,格式形式如下:
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)",},"system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]
]- instruction:用户指令,要求AI执行的任务或问题
- input:用户输入,是完成用户指令所必须的输入内容,就是执行指令所需的具体信息或上下文
- output:模型回答,根据给定的指令和输入生成答案
这里根据企业私有文档数据,生成相关格式的训练数据集,大概格式如下:
[{"instruction": "内退条件是什么?","input": "","output": "内退条件包括与公司签订正式劳动合同并连续工作满20年及以上,以及距离法定退休年龄不足5年。特殊工种符合国家相关规定可提前退休的也可在退休前5年内提出内退申请。"},
]
数据格式处理
定义对数据处理的函数方法
alpaca_prompt = """下面是一项描述任务的说明,配有提供进一步背景信息的输入。写出一个适当完成请求的回应。### Instruction:
{}### Input:
{}### Response:
{}"""EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):instructions = examples["instruction"]inputs = examples["input"]outputs = examples["output"]texts = []for instruction, input, output in zip(instructions, inputs, outputs):# Must add EOS_TOKEN, otherwise your generation will go on forever!text = alpaca_prompt.format(instruction, input, output) + EOS_TOKENtexts.append(text)return { "text" : texts, }加载数据集并进行映射处理操作
from datasets import load_dataset
dataset = load_dataset("kigner/ruozhiba-llama3", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)print(dataset[0])
经处理后的一条数据格式如下:
{'output': '输出内容','input': '','instruction': '指令内容','text': '下面是一项描述任务的说明,配有提供进一步背景信息的输入。写出一个适当完成请求的回应。\n\n### Instruction:\n指令内容?\n\n### Input:\n\n\n### Response:\n输出内容。<|end_of_text|>'
}
4、训练超参数配置
from transformers import TrainingArguments
from trl import SFTTrainertraining_args = TrainingArguments(output_dir = "models/lora/llama", # 输出目录per_device_train_batch_size = 2, # 每个设备的训练批量大小gradient_accumulation_steps = 4, # 梯度累积步数warmup_steps = 5,max_steps = 60, # 最大训练步数,测试时设置# num_train_epochs= 5, # 训练轮数 logging_steps = 10, # 日志记录频率save_strategy = "steps", # 模型保存策略save_steps = 100, # 模型保存步数learning_rate = 2e-4, # 学习率fp16 = not torch.cuda.is_bf16_supported(), # 是否使用float16训练bf16 = torch.cuda.is_bf16_supported(), # 是否使用bfloat16训练optim = "adamw_8bit", # 优化器weight_decay = 0.01, # 正则化技术,通过在损失函数中添加一个正则化项来减小权重的大小lr_scheduler_type = "linear", # 学习率衰减策略seed = 3407, # 随机种子)SFTTrainer
trainer = SFTTrainer(model=model, # 模型tokenizer=tokenizer, # 分词器args=training_args, # 训练参数train_dataset=dataset, # 训练数据集dataset_text_field="text", # 数据集文本字段名称max_seq_length=2048, # 最大序列长度dataset_num_proc=2, # 数据集处理进程数packing=False, # 可以让短序列的训练速度提高5倍
)显示当前内存状态
# 当前GPU信息
gpu_stats = torch.cuda.get_device_properties(0)
# 当前模型内存占用
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
# GPU最大内存
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
可以看出当前模型占用5.633G显存
5、执行训练
trainer_stats = trainer.train()
显示最终内存和时间统计数据
# 计算总的GPU使用内存(单位:GB)
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
# 计算LoRA模型使用的GPU内存(单位:GB)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
# 计算总的GPU内存使用百分比
used_percentage = round(used_memory / max_memory * 100, 3)
# 计算LoRA模型的GPU内存使用百分比
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime'] / 60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
可以看出模型训练时显存增加了0.732G
6、模型推理
FastLanguageModel.for_inference(model) # 启用原生推理速度快2倍
inputs = tokenizer(
[alpaca_prompt.format("内退条件是什么?", # instruction"", # input"", # output)
], return_tensors = "pt").to("cuda")outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
可以看出模型回答跟训练数据集中的数据意思基本一致。
7、保存LoRA模型
注意:这仅保存 LoRA 适配器,而不是完整模型
lora_model = '/home/username/models/lora/llama0715/llama_lora'
model.save_pretrained(lora_model)
# adapter_config.json adapter_model.safetensors README.mdtokenizer.save_pretrained(lora_model)
# tokenizer_config.json special_tokens_map.json tokenizer.json# 保存到huggingface
# model.push_to_hub("your_name/lora_model", token = "...")
# tokenizer.push_to_hub("your_name/lora_model", token = "...")
adapter_config.json 内容如下:
{"alpha_pattern": {},"auto_mapping": null,"base_model_name_or_path": "FlagAlpha/Llama3-Chinese-8B-Instruct","bias": "none","fan_in_fan_out": false,"inference_mode": true,"init_lora_weights": true,"layer_replication": null,"layers_pattern": null,"layers_to_transform": null,"loftq_config": {},"lora_alpha": 16,"lora_dropout": 0,"megatron_config": null,"megatron_core": "megatron.core","modules_to_save": null,"peft_type": "LORA","r": 16,"rank_pattern": {},"revision": "unsloth","target_modules": ["gate_proj","k_proj","up_proj","q_proj","o_proj","v_proj","down_proj"],"task_type": "CAUSAL_LM","use_dora": false,"use_rslora": false
}
8、加载模型
注意:从新加载模型将额外占用显存,若GPU显存不足,需关闭、清除先前加载、训练模型的内存占用
加载刚保存的LoRA适配器用于推断,他将自动加载整个模型及LoRA适配器。adapter_config.json定义了完整模型的路径。
import torch
from unsloth import FastLanguageModelmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "models/llama_lora",max_seq_length = 2048,dtype = torch.float16,load_in_4bit = True,
)FastLanguageModel.for_inference(model)
9、执行推理
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
10、保存完整模型
# 合并到16bit 保存到本地 OR huggingface
model.save_pretrained_merged("models/Llama3", tokenizer, save_method = "merged_16bit",)
# model.push_to_hub_merged("hf/model", tokenizer, save_method = "merged_16bit", token = "")# 合并到4bit 保存到本地 OR huggingface
model.save_pretrained_merged("models/Llama3", tokenizer, save_method = "merged_4bit",)
# model.push_to_hub_merged("hf/model", tokenizer, save_method = "merged_4bit", token = "")
11、保存为GGUF格式
将模型保存为GGUF格式
# 保存到 16bit GGUF 体积大
model.save_pretrained_gguf("model", tokenizer, quantization_method = "f16")
model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "f16", token = "")# 保存到 8bit Q8_0 体积适中
model.save_pretrained_gguf("model", tokenizer,)
model.push_to_hub_gguf("hf/model", tokenizer, token = "")# 保存到 q4_k_m GGUF 体积小
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "q4_k_m", token = "")
2024-07-15(一)
相关文章:

Unsloth 微调 Llama 3
本文参考: https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp 改编自:https://blog.csdn.net/qq_38628046/article/details/138906504 文章目录 一、项目说明安装相关依赖下载模型和数据 二、训练1、加载 model、tokenizer2、…...

热修复的原理
热修复的原理 水一篇哈,完事儿后删掉热修复的原理 水一篇哈,完事儿后删掉 热修复的原理 Java虚拟机 —— JVM 是加载类的class文件的,而Android虚拟机——Dalvik/ART VM 是加载类的dex文件,而他们加载类的时候都需要ClassLoader,…...

【对顶堆 优先队列】2102. 序列顺序查询
本文涉及知识点 对顶堆 优先队列 LeetCode 2102. 序列顺序查询 一个观光景点由它的名字 name 和景点评分 score 组成,其中 name 是所有观光景点中 唯一 的字符串,score 是一个整数。景点按照最好到最坏排序。景点评分 越高 ,这个景点越好。…...

Go 语言中的互斥锁 Mutex
Mutex 是一种互斥锁,名称来自 mutual exclusion,是一种用于控制多线程对共享资源的竞争访问的同步机制。在有的编程语言中,也将其称为锁(lock)。当一个线程获取互斥锁时,它将阻止其他线程对该资源的访问,直到该线程释放锁。这可以防止多个线程对共享资源进行冲突访问,从而…...

CSS 中的 ::before 和 ::after 伪元素
目录 一、CSS 伪元素 二、::before ::after 介绍 1、::before 2、::after 3、content 常用属性值 三、::before ::after 应用场景 1、设置统一字符 2、通过背景添加图片 3、添加装饰线 4、右侧展开箭头 5、对话框小三角 6、插入icon图标 一、CSS 伪元素 CSS伪元…...
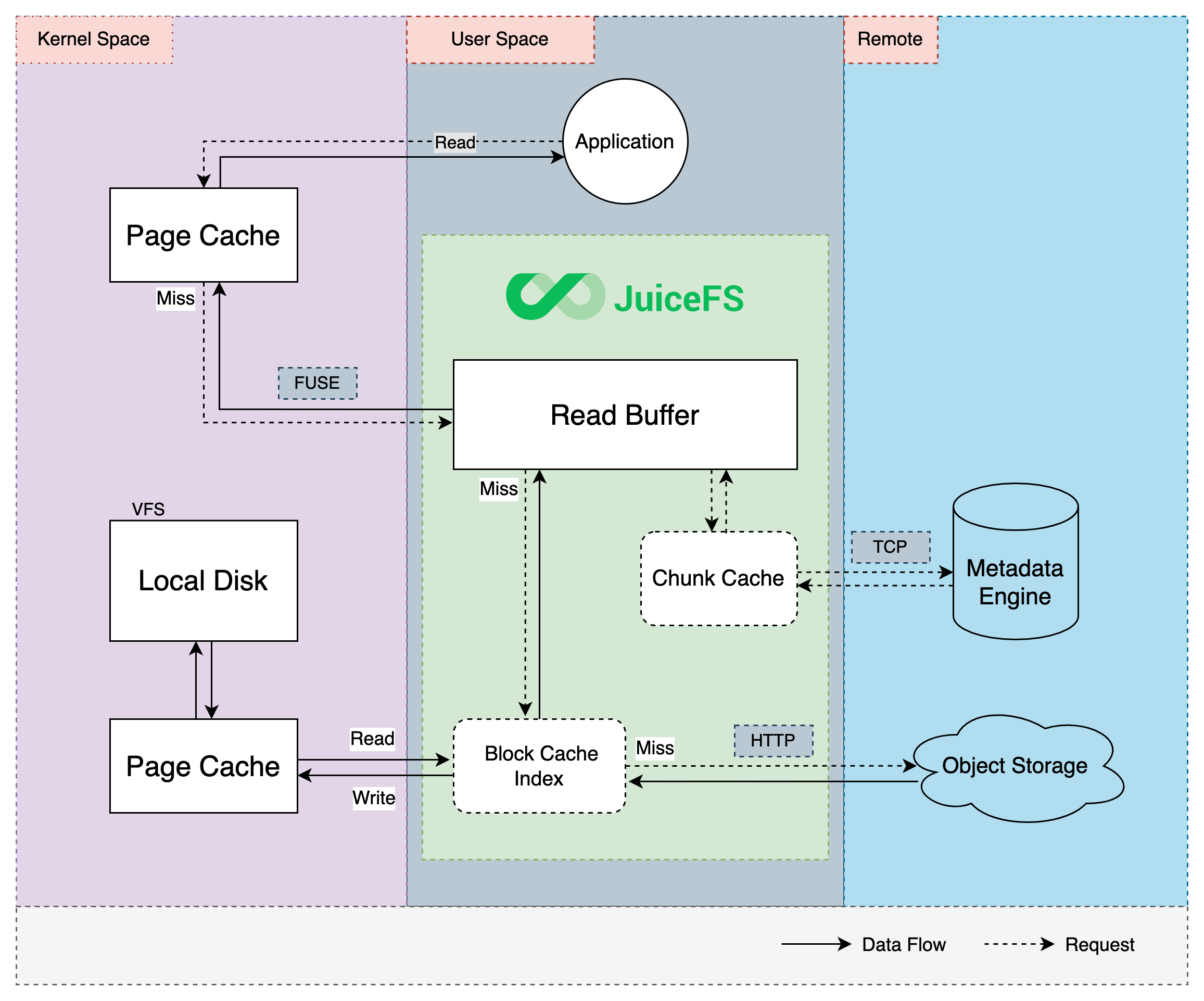
JuiceFS缓存特性
缓存 对于一个由对象存储和数据库组合驱动的文件系统,缓存是本地客户端与远端服务之间高效交互的重要纽带。读写的数据可以提前或者异步载入缓存,再由客户端在后台与远端服务交互执行异步上传或预取数据。相比直接与远端服务交互,采用缓存技…...

R语言实现SVM算法——分类与回归
### 11.6 基于支持向量机进行类别预测 ### # 构建数据子集 X <- iris[iris$Species! virginica,2:3] # 自变量:Sepal.Width, Petal.Length y <- iris[iris$Species ! virginica,Species] # 因变量 plot(X,col y,pch as.numeric(y)15,cex 1.5) # 绘制散点图…...
Redux@4.x(6)- 实现 bindActionCreators)
React@16.x(57)Redux@4.x(6)- 实现 bindActionCreators
目录 1,分析1,直接传入函数2,传入对象 2,实现 1,分析 一般情况下,action 并不是一个写死的对象,而是通过函数来获取。 而 bindActionCreators 的作用:为了更方便的使用创建 action…...

【深度学习入门篇 ⑦】PyTorch池化层
【🍊易编橙:一个帮助编程小伙伴少走弯路的终身成长社群🍊】 大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官…...

【Pytorch】数据集的加载和处理(一)
Pytorch torchvision 包提供了很多常用数据集 数据按照用途一般分为三组:训练(train)、验证(validation)和测试(test)。使用训练数据集来训练模型,使用验证数据集跟踪模型在训练期间…...

论文翻译:Explainability for Large Language Models: A Survey
https://arxiv.org/pdf/2309.01029 目录 可解释性在大型语言模型中:一项调查摘要1 引言2 LLMs的训练范式2.1 传统微调范式2.2 提示范式 3 传统微调范式的解释3.1 局部解释3.1.1 基于特征归因的解释3.1.2 基于注意力的解释3.1.3 基于示例的解释 3.2 全局解释3.2.1 基…...

38 IRF+链路聚合+ACL+NAT组网架构
38 IRF+链路聚合+ACL+NAT组网架构 参考文献 34 IRF的实例-CSDN博客 35 解决单条链路故障问题-华三链路聚合-CSDN博客 36 最经典的ACL控制-CSDN博客 37 公私网转换技术-NAT基础-CSDN博客 32 华三vlan案例+STP-CSDN博客 一 网络架构...

【昇思学习打卡营打卡-第二十八天】MindNLP ChatGLM-6B StreamChat
MindNLP ChatGLM-6B StreamChat 本案例基于MindNLP和ChatGLM-6B实现一个聊天应用。 安装mindnlp pip install mindnlp安装mdtex2html pip install mdtex2html配置网络线路 export HF_ENDPOINThttps://hf-mirror.com代码开发 下载权重大约需要10分钟 from mindnlp.transf…...

前端打包部署后源码安全问题总结
随着现代Web应用越来越依赖于客户端技术,前端安全问题也随之突显。源码泄露是一个严重的安全问题,它不仅暴露了应用的内部逻辑和业务关键信息,还可能导致更广泛的安全风险。本文将详细介绍源码泄露的潜在风险,并提供一系列策略和工…...

扩展你的App:Xcode中App Extensions的深度指南
扩展你的App:Xcode中App Extensions的深度指南 在iOS开发的世界中,App Extensions提供了一种强大的方式,允许你的应用程序与系统和其他应用更紧密地集成。从今天起,我们将探索Xcode中App Extensions的神秘领域,学习如…...

【D3.js in Action 3 精译】1.3 D3 视角下的数据可视化最佳实践(下)
当前内容所在位置 第一部分 D3.js 基础知识 第一章 D3.js 简介 ✔️ 1.1 何为 D3.js?1.2 D3 生态系统——入门须知 1.2.1 HTML 与 DOM1.2.2 SVG - 可缩放矢量图形1.2.3 Canvas 与 WebGL1.2.4 CSS1.2.5 JavaScript1.2.6 Node 与 JavaScript 框架1.2.7 Observable 记事…...

Solus Linux简介
以下是学习笔记,具体详实的内容请参考官网:Home | Solus Solus Linux 是一个独立的 Linux 发行版,它以其现代的设计、优化的性能和友好的用户体验而著称。以下是一些关于 Solus Linux 的最新动向和特点: 1. **最新版本发布**&a…...

常见的排序算法,复杂度
稳定 / 非稳定排序:两个相等的数 排序前后 相对位置不变。插入排序(希尔排序): 每一趟将一个待排序记录,按其关键字的大小插入到已排好序的一组记录的适当位置上,直到所有待排序记录全部插入为止。稳定&…...
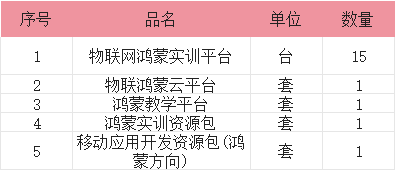
鸿蒙特色物联网实训室
一、 引言 在当今这个万物皆可连网的时代,物联网(IoT)正以前所未有的速度改变着我们的生活和工作方式。它如同一座桥梁,将实体世界与虚拟空间紧密相连,让数据成为驱动决策和创新的关键力量。随着物联网技术的不断成熟…...

JVM垃圾回收-----垃圾分类
一、垃圾分类定义 垃圾分类是JVM垃圾分类中的第一步,这一步将堆中的对象分为存活对象和垃圾对象两类。 在垃圾分类阶段,JVM会从一组根对象开始,通过对象之间的引用关系,遍历所有的对象,并将所有存活的对象进行标记。…...

PS左边工具栏不见了?最全恢复解决教程
在使用Photoshop进行修图、设计操作时,左侧工具栏作为核心功能面板,承载着选区、绘画、修图等常用工具,一旦莫名消失,会直接中断操作、影响效率。很多新手遇到这种情况会手足无措,其实无需慌张,今天就给大家…...

中文Kodi媒体中心终极指南:4大本土化插件解决方案
中文Kodi媒体中心终极指南:4大本土化插件解决方案 【免费下载链接】xbmc-addons-chinese Addon scripts, plugins, and skins for XBMC Media Center. Special for chinese laguage. 项目地址: https://gitcode.com/gh_mirrors/xb/xbmc-addons-chinese 你是否…...

FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗?
FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗? 在嵌入式实时系统中,任务间的通信机制如同城市中的交通网络,而FreeRTOS队列则是这条网络中最核心的高速公路。当你的系统从简单的单任务演变为多任…...
基于 PyTorch 的 TransU-Net 模型进行不同城市建筑物的精准提取 来继续遥感图像语义分割
基于 PyTorch 的 TransU-Net 模型进行不同城市建筑物的精准提取 来继续遥感图像语义分割 遥感图像语义分割,遥感建筑物数据集,基于Pytorch框架,针对不同城市建筑物精准提取。 遥感图像中包含丰富的地理空间信息,从遥感图像中了…...
)
苹果手机快速开启开发者模式教程(iOS 16+)
在Mac Xcode 给 iPhone 安装自签 IPA、做苹果 App 打包测试时,iOS 16 及以上的系统第一次启动这类"非 App Store 来源"的 App,都会弹一个 “需要启用开发者模式” 的提示,点"好"就退出了,App 根本进不去。 这是苹果从 iOS 16 开始加的安全限制:任何用开发…...

从一颗2N5551看懂半导体散热:热阻Rja、Rjc到底怎么测?对我们选型有啥用?
从一颗2N5551看懂半导体散热:热阻Rja、Rjc到底怎么测?对我们选型有啥用? 拆开一颗塑料封装的2N5551三极管,你会看到指甲盖大小的黑色环氧树脂包裹着不到1平方毫米的硅晶片。这个微型结构在工作时产生的热量,可能让芯片…...
)
别再傻等!解决conda install nb_conda卡在solving environment的3个高效方法(附清华源配置)
彻底解决conda install卡在solving environment的终极指南 当你满怀期待地在终端输入conda install nb_conda准备为Jupyter Notebook添加环境管理功能时,却发现进度条永远卡在"solving environment"这一步,这种体验就像在高速公路上遇到无休止…...

AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南
AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南 第一次用Altium Designer 23完成PCB设计后,面对Gerber文件导出和嘉立创下单的复杂流程,很多新手都会感到手足无措。本文将从实际经验出发,带你一步步避开…...
)
限时开放!ElevenLabs未公开东北话语音微调接口文档(含token绕过+方言embedding注入完整POC)
更多请点击: https://codechina.net 第一章:ElevenLabs东北话语音微调接口的发现与边界定义 ElevenLabs 官方 API 文档未显式标注“东北话”支持,但通过其语音克隆(Voice Cloning)与声音微调(Fine-tuning&…...

如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南
如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City,…...