【对顶堆 优先队列】2102. 序列顺序查询
本文涉及知识点
对顶堆 优先队列
LeetCode 2102. 序列顺序查询
一个观光景点由它的名字 name 和景点评分 score 组成,其中 name 是所有观光景点中 唯一 的字符串,score 是一个整数。景点按照最好到最坏排序。景点评分 越高 ,这个景点越好。如果有两个景点的评分一样,那么 字典序较小 的景点更好。
你需要搭建一个系统,查询景点的排名。初始时系统里没有任何景点。这个系统支持:
添加 景点,每次添加 一个 景点。
查询 已经添加景点中第 i 好 的景点,其中 i 是系统目前位置查询的次数(包括当前这一次)。
比方说,如果系统正在进行第 4 次查询,那么需要返回所有已经添加景点中第 4 好的。
注意,测试数据保证 任意查询时刻 ,查询次数都 不超过 系统中景点的数目。
请你实现 SORTracker 类:
SORTracker() 初始化系统。
void add(string name, int score) 向系统中添加一个名为 name 评分为 score 的景点。
string get() 查询第 i 好的景点,其中 i 是目前系统查询的次数(包括当前这次查询)。
示例:
输入:
[“SORTracker”, “add”, “add”, “get”, “add”, “get”, “add”, “get”, “add”, “get”, “add”, “get”, “get”]
[[], [“bradford”, 2], [“branford”, 3], [], [“alps”, 2], [], [“orland”, 2], [], [“orlando”, 3], [], [“alpine”, 2], [], []]
输出:
[null, null, null, “branford”, null, “alps”, null, “bradford”, null, “bradford”, null, “bradford”, “orland”]
解释:
SORTracker tracker = new SORTracker(); // 初始化系统
tracker.add(“bradford”, 2); // 添加 name=“bradford” 且 score=2 的景点。
tracker.add(“branford”, 3); // 添加 name=“branford” 且 score=3 的景点。
tracker.get(); // 从好带坏的景点为:branford ,bradford 。
// 注意到 branford 比 bradford 好,因为它的 评分更高 (3 > 2) 。
// 这是第 1 次调用 get() ,所以返回最好的景点:“branford” 。
tracker.add(“alps”, 2); // 添加 name=“alps” 且 score=2 的景点。
tracker.get(); // 从好到坏的景点为:branford, alps, bradford 。
// 注意 alps 比 bradford 好,虽然它们评分相同,都为 2 。
// 这是因为 “alps” 字典序 比 “bradford” 小。
// 返回第 2 好的地点 “alps” ,因为当前为第 2 次调用 get() 。
tracker.add(“orland”, 2); // 添加 name=“orland” 且 score=2 的景点。
tracker.get(); // 从好到坏的景点为:branford, alps, bradford, orland 。
// 返回 “bradford” ,因为当前为第 3 次调用 get() 。
tracker.add(“orlando”, 3); // 添加 name=“orlando” 且 score=3 的景点。
tracker.get(); // 从好到坏的景点为:branford, orlando, alps, bradford, orland 。
// 返回 “bradford”.
tracker.add(“alpine”, 2); // 添加 name=“alpine” 且 score=2 的景点。
tracker.get(); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。
// 返回 “bradford” 。
tracker.get(); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。
// 返回 “orland” 。
提示:
name 只包含小写英文字母,且每个景点名字互不相同。
1 <= name.length <= 10
1 <= score <= 105
任意时刻,调用 get 的次数都不超过调用 add 的次数。
总共 调用 add 和 get 不超过 4 * 104
对顶堆
小根堆m_big记录最大的m_cnt的数,大根堆m_other记录余下的数。
m_cnt 初始为1,每get一次就+1。
get函数:
如果m_big的数量小于m_cnt,从m_other移到m_big。
m_cnt++
return m_big.top。
Add函数:
将当前数加到m_big中,如果m_big的数量大于m_cnt,移数据到m_other。
确保m_big的数大于m_other的数。
为了不重写小于号,可以直接将name倒序,利用pair自带的<。 结果此方法错误,比如:a z,倒序后,字典序没变。
将a,b,c ⋯ \cdots ⋯ 变成 z y x ⋯ \cdots ⋯ 也不性。
aa aac,转化后字典序没变。
最终还是重写了小于。
可以用笨方法(聪明方法):将分数乘以-1,然后小根堆换大根堆。
代码
核心代码
class CName {
public:CName(const std::string& str) {m_str = str;}bool operator<(const CName& n) const{return m_str > n.m_str;}std::string m_str;
};
class SORTracker {
public:SORTracker() {}void add(string name, int score) {m_big.emplace(make_pair(score, CName(name)));if (m_big.size() > m_cnt) {m_other.emplace(m_big.top());m_big.pop();}while (m_big.size() && m_other.size() && (m_big.top()< m_other.top())) {const auto b1 = m_big.top();const auto o1 = m_other.top();m_big.pop();m_other.pop();m_big.emplace(o1);m_other.emplace(b1);}}string get() {if (m_big.size() < m_cnt) {m_big.emplace(m_other.top());m_other.pop();}m_cnt++;return m_big.top().second.m_str;}int m_cnt = 1;priority_queue<pair<int, CName>, vector<pair<int, CName>>, greater<>> m_big;priority_queue < pair<int, CName>> m_other;
};
单元测试
template<class T1, class T2>
void AssertEx(const T1& t1, const T2& t2)
{Assert::AreEqual(t1, t2);
}template<class T>
void AssertEx(const vector<T>& v1, const vector<T>& v2)
{Assert::AreEqual(v1.size(), v2.size());for (int i = 0; i < v1.size(); i++){Assert::AreEqual(v1[i], v2[i]);}
}template<class T>
void AssertV2(vector<vector<T>> vv1, vector<vector<T>> vv2)
{sort(vv1.begin(), vv1.end());sort(vv2.begin(), vv2.end());Assert::AreEqual(vv1.size(), vv2.size());for (int i = 0; i < vv1.size(); i++){AssertEx(vv1[i], vv2[i]);}
}namespace UnitTest
{int k;vector<int> arrival,load;TEST_CLASS(UnitTest){public:TEST_METHOD(TestMethod00){SORTracker tracker; // 初始化系统tracker.add("bradford", 2); // 添加 name="bradford" 且 score=2 的景点。tracker.add("branford", 3); // 添加 name="branford" 且 score=3 的景点。AssertEx(string("branford"),tracker.get()); // 从好带坏的景点为:branford ,bradford 。// 注意到 branford 比 bradford 好,因为它的 评分更高 (3 > 2) 。// 这是第 1 次调用 get() ,所以返回最好的景点:"branford" 。tracker.add("alps", 2); // 添加 name="alps" 且 score=2 的景点。AssertEx(string("alps"), tracker.get()); ; // 从好到坏的景点为:branford, alps, bradford 。// 注意 alps 比 bradford 好,虽然它们评分相同,都为 2 。// 这是因为 "alps" 字典序 比 "bradford" 小。// 返回第 2 好的地点 "alps" ,因为当前为第 2 次调用 get() 。tracker.add("orland", 2); // 添加 name="orland" 且 score=2 的景点。AssertEx(string("bradford"), tracker.get()); // 从好到坏的景点为:branford, alps, bradford, orland 。// 返回 "bradford" ,因为当前为第 3 次调用 get() 。tracker.add("orlando", 3); // 添加 name="orlando" 且 score=3 的景点。AssertEx(string("bradford"), tracker.get()); // 从好到坏的景点为:branford, orlando, alps, bradford, orland 。// 返回 "bradford".tracker.add("alpine", 2); // 添加 name="alpine" 且 score=2 的景点。AssertEx(string("bradford"), tracker.get()); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。// 返回 "bradford" 。AssertEx(string("orland"), tracker.get()); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。// 返回 "orland" 。}TEST_METHOD(TestMethod01){SORTracker tracker; // 初始化系统tracker.add("a", 10000);tracker.add("z", 1);AssertEx(string("a"), tracker.get());tracker.add("b", 10000);AssertEx(string("b"), tracker.get());AssertEx(string("z"), tracker.get());}};
}
简洁代码
class SORTracker {
public:SORTracker() {}void add(string name, int score) {m_big.emplace(make_pair(score, CName(name)));m_other.emplace(m_big.top());m_big.pop();}string get() {m_big.emplace(m_other.top());m_other.pop();return m_big.top().second.m_str;} priority_queue<pair<int, CName>, vector<pair<int, CName>>, greater<>> m_big;priority_queue < pair<int, CName>> m_other;
};
用set模拟
class SORTracker {
public:SORTracker() {m_other.emplace(0, "");m_it = m_other.begin();}void add(string name, int score) {auto tmp = make_pair(score, CName(name));m_other.emplace(tmp);if (tmp > *m_it) {m_it--;}}string get() {return (m_it++)->second.m_str;} set < pair<int, CName>, greater<>>::iterator m_it;set < pair<int, CName>,greater<>> m_other;
};

扩展阅读
视频课程
先学简单的课程,请移步CSDN学院,听白银讲师(也就是鄙人)的讲解。
https://edu.csdn.net/course/detail/38771
如何你想快速形成战斗了,为老板分忧,请学习C#入职培训、C++入职培训等课程
https://edu.csdn.net/lecturer/6176
相关推荐
| 我想对大家说的话 |
|---|
| 《喜缺全书算法册》以原理、正确性证明、总结为主。 |
| 按类别查阅鄙人的算法文章,请点击《算法与数据汇总》。 |
| 有效学习:明确的目标 及时的反馈 拉伸区(难度合适) 专注 |
| 闻缺陷则喜(喜缺)是一个美好的愿望,早发现问题,早修改问题,给老板节约钱。 |
| 子墨子言之:事无终始,无务多业。也就是我们常说的专业的人做专业的事。 |
| 如果程序是一条龙,那算法就是他的是睛 |
测试环境
操作系统:win7 开发环境: VS2019 C++17
或者 操作系统:win10 开发环境: VS2022 C++17
如无特殊说明,本算法用**C++**实现。

相关文章:
【对顶堆 优先队列】2102. 序列顺序查询
本文涉及知识点 对顶堆 优先队列 LeetCode 2102. 序列顺序查询 一个观光景点由它的名字 name 和景点评分 score 组成,其中 name 是所有观光景点中 唯一 的字符串,score 是一个整数。景点按照最好到最坏排序。景点评分 越高 ,这个景点越好。…...

Go 语言中的互斥锁 Mutex
Mutex 是一种互斥锁,名称来自 mutual exclusion,是一种用于控制多线程对共享资源的竞争访问的同步机制。在有的编程语言中,也将其称为锁(lock)。当一个线程获取互斥锁时,它将阻止其他线程对该资源的访问,直到该线程释放锁。这可以防止多个线程对共享资源进行冲突访问,从而…...

CSS 中的 ::before 和 ::after 伪元素
目录 一、CSS 伪元素 二、::before ::after 介绍 1、::before 2、::after 3、content 常用属性值 三、::before ::after 应用场景 1、设置统一字符 2、通过背景添加图片 3、添加装饰线 4、右侧展开箭头 5、对话框小三角 6、插入icon图标 一、CSS 伪元素 CSS伪元…...
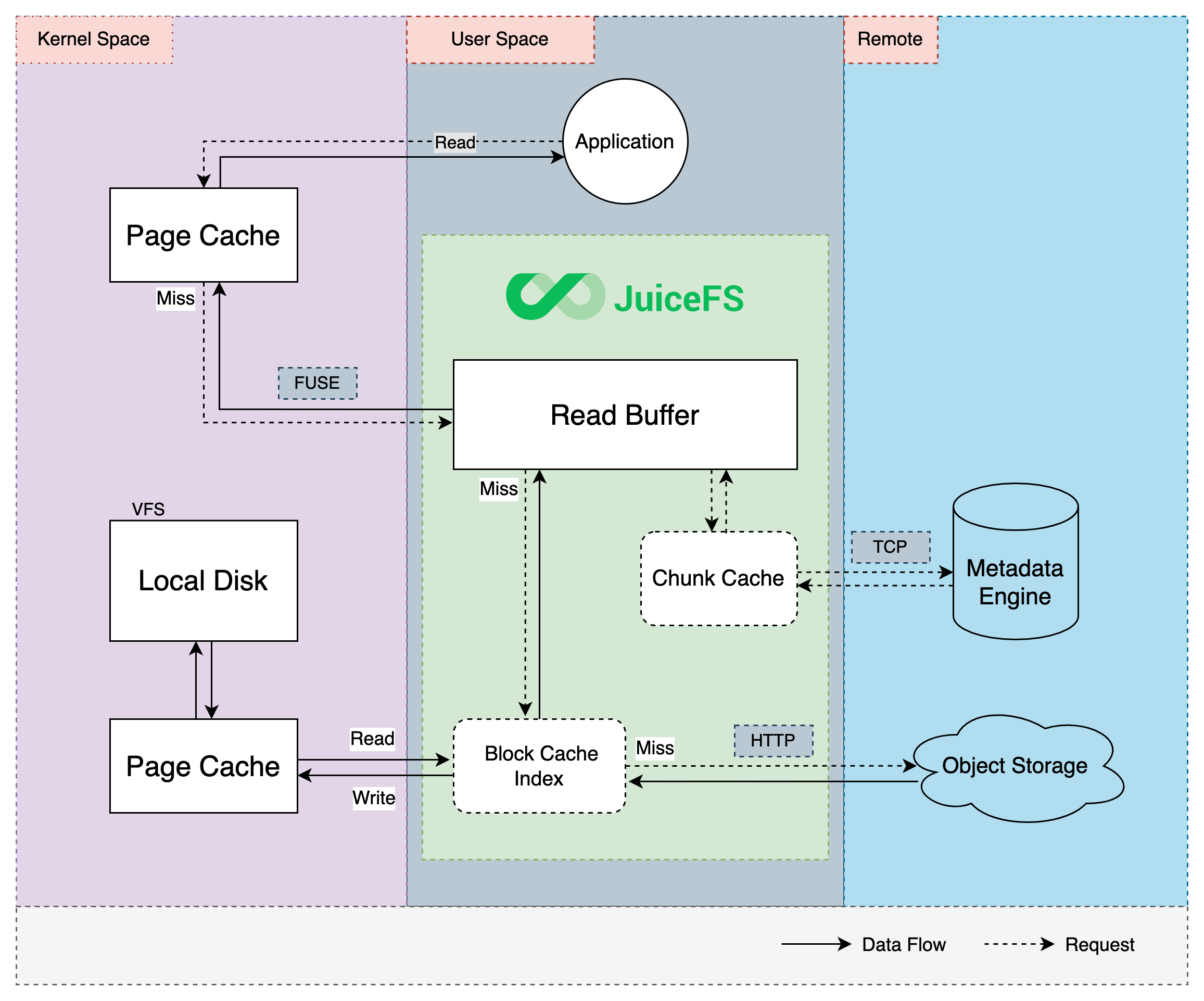
JuiceFS缓存特性
缓存 对于一个由对象存储和数据库组合驱动的文件系统,缓存是本地客户端与远端服务之间高效交互的重要纽带。读写的数据可以提前或者异步载入缓存,再由客户端在后台与远端服务交互执行异步上传或预取数据。相比直接与远端服务交互,采用缓存技…...

R语言实现SVM算法——分类与回归
### 11.6 基于支持向量机进行类别预测 ### # 构建数据子集 X <- iris[iris$Species! virginica,2:3] # 自变量:Sepal.Width, Petal.Length y <- iris[iris$Species ! virginica,Species] # 因变量 plot(X,col y,pch as.numeric(y)15,cex 1.5) # 绘制散点图…...
Redux@4.x(6)- 实现 bindActionCreators)
React@16.x(57)Redux@4.x(6)- 实现 bindActionCreators
目录 1,分析1,直接传入函数2,传入对象 2,实现 1,分析 一般情况下,action 并不是一个写死的对象,而是通过函数来获取。 而 bindActionCreators 的作用:为了更方便的使用创建 action…...

【深度学习入门篇 ⑦】PyTorch池化层
【🍊易编橙:一个帮助编程小伙伴少走弯路的终身成长社群🍊】 大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官…...

【Pytorch】数据集的加载和处理(一)
Pytorch torchvision 包提供了很多常用数据集 数据按照用途一般分为三组:训练(train)、验证(validation)和测试(test)。使用训练数据集来训练模型,使用验证数据集跟踪模型在训练期间…...

论文翻译:Explainability for Large Language Models: A Survey
https://arxiv.org/pdf/2309.01029 目录 可解释性在大型语言模型中:一项调查摘要1 引言2 LLMs的训练范式2.1 传统微调范式2.2 提示范式 3 传统微调范式的解释3.1 局部解释3.1.1 基于特征归因的解释3.1.2 基于注意力的解释3.1.3 基于示例的解释 3.2 全局解释3.2.1 基…...

38 IRF+链路聚合+ACL+NAT组网架构
38 IRF+链路聚合+ACL+NAT组网架构 参考文献 34 IRF的实例-CSDN博客 35 解决单条链路故障问题-华三链路聚合-CSDN博客 36 最经典的ACL控制-CSDN博客 37 公私网转换技术-NAT基础-CSDN博客 32 华三vlan案例+STP-CSDN博客 一 网络架构...

【昇思学习打卡营打卡-第二十八天】MindNLP ChatGLM-6B StreamChat
MindNLP ChatGLM-6B StreamChat 本案例基于MindNLP和ChatGLM-6B实现一个聊天应用。 安装mindnlp pip install mindnlp安装mdtex2html pip install mdtex2html配置网络线路 export HF_ENDPOINThttps://hf-mirror.com代码开发 下载权重大约需要10分钟 from mindnlp.transf…...

前端打包部署后源码安全问题总结
随着现代Web应用越来越依赖于客户端技术,前端安全问题也随之突显。源码泄露是一个严重的安全问题,它不仅暴露了应用的内部逻辑和业务关键信息,还可能导致更广泛的安全风险。本文将详细介绍源码泄露的潜在风险,并提供一系列策略和工…...

扩展你的App:Xcode中App Extensions的深度指南
扩展你的App:Xcode中App Extensions的深度指南 在iOS开发的世界中,App Extensions提供了一种强大的方式,允许你的应用程序与系统和其他应用更紧密地集成。从今天起,我们将探索Xcode中App Extensions的神秘领域,学习如…...

【D3.js in Action 3 精译】1.3 D3 视角下的数据可视化最佳实践(下)
当前内容所在位置 第一部分 D3.js 基础知识 第一章 D3.js 简介 ✔️ 1.1 何为 D3.js?1.2 D3 生态系统——入门须知 1.2.1 HTML 与 DOM1.2.2 SVG - 可缩放矢量图形1.2.3 Canvas 与 WebGL1.2.4 CSS1.2.5 JavaScript1.2.6 Node 与 JavaScript 框架1.2.7 Observable 记事…...

Solus Linux简介
以下是学习笔记,具体详实的内容请参考官网:Home | Solus Solus Linux 是一个独立的 Linux 发行版,它以其现代的设计、优化的性能和友好的用户体验而著称。以下是一些关于 Solus Linux 的最新动向和特点: 1. **最新版本发布**&a…...

常见的排序算法,复杂度
稳定 / 非稳定排序:两个相等的数 排序前后 相对位置不变。插入排序(希尔排序): 每一趟将一个待排序记录,按其关键字的大小插入到已排好序的一组记录的适当位置上,直到所有待排序记录全部插入为止。稳定&…...
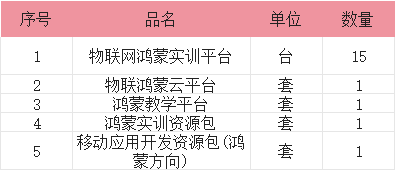
鸿蒙特色物联网实训室
一、 引言 在当今这个万物皆可连网的时代,物联网(IoT)正以前所未有的速度改变着我们的生活和工作方式。它如同一座桥梁,将实体世界与虚拟空间紧密相连,让数据成为驱动决策和创新的关键力量。随着物联网技术的不断成熟…...

JVM垃圾回收-----垃圾分类
一、垃圾分类定义 垃圾分类是JVM垃圾分类中的第一步,这一步将堆中的对象分为存活对象和垃圾对象两类。 在垃圾分类阶段,JVM会从一组根对象开始,通过对象之间的引用关系,遍历所有的对象,并将所有存活的对象进行标记。…...

前端基础之JavaScript学习——变量、数据类型、类型转换
大家好,我是来自CSDN的博主PleaSure乐事,今天我们开始有关JS的学习,希望有所帮助并巩固有关前端的知识。 我使用的编译器为vscode,浏览器使用为谷歌浏览器,使用webstorm或其他环境效果几乎一样,使用系统自…...

SQL常用数据过滤---IN操作符
在SQL中,IN操作符常用于过滤数据,允许在WHERE子句中指定多个可能的值。如果列中的值匹配IN操作符后面括号中的任何一个值,那么该行就会被选中。 以下是使用IN操作符的基本语法: SELECT column1, column2, ... FROM table_name WH…...

chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南
chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南 chatgpt-web-midjourney-proxy项目是一个强大的AI工具集成平台,将ChatGPT、Midjourney绘图和GPTs功能统一在一个界面中。通过PWA技术,这个项目可以轻松转换为移动端离线应用…...

WZLBadge高级定制:从颜色位置到字体半径的完全自定义
WZLBadge高级定制:从颜色位置到字体半径的完全自定义 【免费下载链接】WZLBadge //An one-line tool to show styles of badge for UIView 项目地址: https://gitcode.com/gh_mirrors/wz/WZLBadge WZLBadge是一款功能强大的iOS徽章工具,能够帮助开…...

树突状细胞相关细胞因子的功能及疾病关联
树突状细胞作为免疫系统中核心的抗原呈递细胞,其分泌的多种细胞因子(IL-1α、IL-1β、IL-6、TNFα、IL-10)在免疫反应的启动、调控及稳态维持中发挥着核心作用。这些细胞因子具有双重调控特性,既是机体抵御病原体入侵的重要屏障&a…...

避开这些坑!国产电池管理AFE芯片DVC1124的I2C驱动开发实战指南
避开这些坑!国产电池管理AFE芯片DVC1124的I2C驱动开发实战指南 在BMS(电池管理系统)开发中,AFE(模拟前端)芯片的稳定通信是确保电池数据准确采集的基础。DVC1124作为国产高性能电池监测芯片,其I…...

为内容生成平台构建支持多模型备选的 AI 中台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内容生成平台构建支持多模型备选的 AI 中台 在内容创作领域,无论是自媒体运营还是营销团队,对文本生成的…...

2026 年 Haskell 基金会大变革:执行董事卸任、组织重组、董事会人员调整!
执行董事卸任过去几年担任执行董事的 Jos 决定在 2026 年 6 月卸任。Jos 是 Haskell 基金会任职时间最长的执行董事,他花费大量时间与社区互动并提供支持,很多工作都是在幕后默默完成的。Jos 做出了个人牺牲,让 Haskell 基金会度过了艰难时期…...
OpenAvatarChat终极指南:5分钟打造你的专属AI数字人
OpenAvatarChat终极指南:5分钟打造你的专属AI数字人 【免费下载链接】OpenAvatarChat 项目地址: https://gitcode.com/gh_mirrors/op/OpenAvatarChat 想象一下,你正在开发一个智能客服系统,需要让数字人能够自然流畅地与用户对话。传…...

AI设计泳装,能颠覆今夏潮流?
AI设计泳装,能颠覆今夏潮流? 夏日临近,泳装市场硝烟再起。然而,海量款式与消费者挑剔审美的矛盾日益尖锐——设计周期长、打版成本高、爆款命中率低,让无数商家深陷库存泥潭。如何破局?北京先智先行科技有限…...

tRPC-Go 框架 01:tRPC-Go 总览与核心架构
tRPC-Go 框架 01:tRPC-Go 总览与核心架构 tRPC 是腾讯开源的多语言 RPC 框架,tRPC-Go 是其 Go 语言实现,已在腾讯内部支撑了海量服务(视频、音乐、新闻、广告等),日均调用量万亿级。本篇我们站高一点&…...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...