K最近邻(K-Nearest Neighbors, KNN)
K最近邻(K-Nearest Neighbors, KNN)理论知识推导
KNN算法是一个简单且直观的分类和回归方法,其基本思想是:给定一个样本点,找到训练集中与其最近的K个样本点,根据这些样本点的类别(分类问题)或值(回归问题)来预测该样本点的类别或值。
距离度量
欧氏距离(Euclidean Distance)

曼哈顿距离(Manhattan Distance)
曼哈顿距离也称为L1距离或城市街区距离,适用于连续型和离散型变量。其计算公式为:

切比雪夫距离(Chebyshev Distance)

闵可夫斯基距离(Minkowski Distance)

余弦相似度(Cosine Similarity)
余弦相似度用于度量两个向量之间的角度差异,适用于文本数据和高维稀疏数据。其计算公式为:

汉明距离(Hamming Distance)
汉明距离用于度量两个字符串或向量之间不同字符或元素的数量,适用于离散变量。其计算公式为:

import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 生成随机多维数据
np.random.seed(42)
X = np.random.rand(200, 5)
y = np.random.choice([0, 1], size=200)# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 使用欧氏距离的KNN模型
knn_euclidean = KNeighborsClassifier(n_neighbors=3, metric='euclidean')
knn_euclidean.fit(X_train_scaled, y_train)
y_pred_euclidean = knn_euclidean.predict(X_test_scaled)
accuracy_euclidean = accuracy_score(y_test, y_pred_euclidean)# 使用曼哈顿距离的KNN模型
knn_manhattan = KNeighborsClassifier(n_neighbors=3, metric='manhattan')
knn_manhattan.fit(X_train_scaled, y_train)
y_pred_manhattan = knn_manhattan.predict(X_test_scaled)
accuracy_manhattan = accuracy_score(y_test, y_pred_manhattan)# 使用切比雪夫距离的KNN模型
knn_chebyshev = KNeighborsClassifier(n_neighbors=3, metric='chebyshev')
knn_chebyshev.fit(X_train_scaled, y_train)
y_pred_chebyshev = knn_chebyshev.predict(X_test_scaled)
accuracy_chebyshev = accuracy_score(y_test, y_pred_chebyshev)print(f'欧氏距离模型的准确率: {accuracy_euclidean}')
print(f'曼哈顿距离模型的准确率: {accuracy_manhattan}')
print(f'切比雪夫距离模型的准确率: {accuracy_chebyshev}')

选择最近的K个邻居
根据距离排序,选择距离最小的K个样本点。
投票或平均
对于分类问题,对这K个邻居的类别进行投票,得票最多的类别作为预测类别;对于回归问题,对这K个邻居的值取平均,作为预测值。
KNN的优缺点:
-
优点:
- 简单易实现。
- 不需要模型训练。
- 对噪声数据不敏感(通过选择合适的K值)。
-
缺点:
- 计算复杂度高,需要计算所有样本点的距离。
- 存储复杂度高,需要存储所有训练数据。
- 对数据的尺度敏感,需要进行标准化处理。
参数解读
n_neighbors:K值,即选择的最近邻居的数量。weights:权重函数,用于预测。常用的有uniform(所有邻居权重相等)和distance(根据距离加权)。metric:距离度量方法,默认是欧氏距离。
实施步骤
- 数据准备:准备训练数据集和测试数据集。
- 特征标准化:对数据进行标准化处理。
- 选择K值和距离度量方法:初始化KNN模型。
- 模型训练:KNN算法不需要训练过程,但需要拟合数据。
- 预测:对测试数据进行预测,并计算准确率或误差。
- 选择K值:K值越小,模型越复杂;K值越大,模型越简单。一般通过交叉验证选择最佳K值。
- 距离度量方法:常用欧氏距离,选择合适的距离度量方法可以提高模型性能。
- 权重:uniform表示所有邻居权重相同,distance表示距离越近的邻居权重越大。
多维KNN模型
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import GridSearchCV# 生成多维数据
np.random.seed(42)
X = np.random.rand(100, 3) * 100 # 三维特征数据
y = np.random.choice([0, 1], 100) # 二分类标签# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 初始化KNN分类模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# 预测
y_pred = knn.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'未优化分类模型的准确率: {accuracy:.2f}')# 使用网格搜索优化KNN分类模型
param_grid = {'n_neighbors': range(1, 21), 'weights': ['uniform', 'distance']}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)best_knn = grid_search.best_estimator_
y_pred_optimized = best_knn.predict(X_test)accuracy_optimized = accuracy_score(y_test, y_pred_optimized)
print(f'优化后分类模型的准确率: {accuracy_optimized:.2f}')# 可视化三维数据分布和预测结果
fig = plt.figure(figsize=(18, 6))# 未优化模型结果
ax1 = fig.add_subplot(121, projection='3d')
ax1.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_test, marker='o', label='True Labels')
ax1.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_pred, marker='x', label='Predicted Labels')
ax1.set_title('未优化模型')
ax1.set_xlabel('Feature 1')
ax1.set_ylabel('Feature 2')
ax1.set_zlabel('Feature 3')
ax1.legend()# 优化后模型结果
ax2 = fig.add_subplot(122, projection='3d')
ax2.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_test, marker='o', label='True Labels')
ax2.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_pred_optimized, marker='x', label='Predicted Labels')
ax2.set_title('优化后模型')
ax2.set_xlabel('Feature 1')
ax2.set_ylabel('Feature 2')
ax2.set_zlabel('Feature 3')
ax2.legend()plt.show()
可视化展示

警告:D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 26410 (\N{CJK UNIFIED IDEOGRAPH-672A}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 20248 (\N{CJK UNIFIED IDEOGRAPH-4F18}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 21270 (\N{CJK UNIFIED IDEOGRAPH-5316}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 27169 (\N{CJK UNIFIED IDEOGRAPH-6A21}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 22411 (\N{CJK UNIFIED IDEOGRAPH-578B}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 21518 (\N{CJK UNIFIED IDEOGRAPH-540E}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
结果解释
-
未优化分类模型:
- 准确率:显示未优化模型的分类准确率,通常受初始参数设置的影响。
- 可视化:通过三维散点图展示真实标签和预测标签的分布情况,观察误分类样本的位置。
-
优化后分类模型:
- 准确率:通过网格搜索优化K值和距离度量方法后,显示优化后的分类准确率,通常高于未优化模型。
- 可视化:通过三维散点图展示真实标签和优化后模型的预测标签分布情况,观察误分类样本的位置。
以上实例展示了KNN算法在未优化和优化后的性能差异,通过适当的参数调优,可以显著提升模型的预测效果。
相关文章:
K最近邻(K-Nearest Neighbors, KNN)
K最近邻(K-Nearest Neighbors, KNN)理论知识推导 KNN算法是一个简单且直观的分类和回归方法,其基本思想是:给定一个样本点,找到训练集中与其最近的K个样本点,根据这些样本点的类别(分类问题&am…...

深度学习损失计算
文章目录 深度学习损失计算1.如何计算当前epoch的损失?2.为什么要计算样本平均损失,而不是计算批次平均损失? 深度学习损失计算 1.如何计算当前epoch的损失? 深度学习中的损失计算,通常为数据集的平均损失࿰…...

论文翻译:通过云计算对联网多智能体系统进行预测控制
通过云计算对联网多智能体系统进行预测控制 文章目录 通过云计算对联网多智能体系统进行预测控制摘要前言通过云计算实现联网的多智能体控制系统网络化多智能体系统的云预测控制器设计云预测控制系统的稳定性和一致性分析例子结论 摘要 本文研究了基于云计算的网络化多智能体预…...

Java核心(五)多线程
线程并行的逻辑 一个线程问题 起手先来看一个线程问题: public class NumberExample {private int cnt 0;public void add() {cnt;}public int get() {return cnt;} }public static void main(String[] args) throws InterruptedException {final int threadSiz…...

IDEA快速生成项目树形结构图
下图用的IDEA工具,但我觉得WebStorm 应该也可以 文章目录 进入项目根目录下,进入cmd输入如下指令: 只有文件夹 tree . > list.txt 包括文件夹和文件 tree /f . > list.txt 还可以为相关包路径加上注释...

【CPO-TCN-BiGRU-Attention回归预测】基于冠豪猪算法CPO优化时间卷积双向门控循环单元融合注意力机制
基于冠豪猪算法CPO(Correlation-Preservation Optimization)优化的时间卷积双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)融合注意力机制(Attention)的回归预测需要详细的实现和…...

面试高级 Java 工程师:2024 年的见闻与思考
面试高级 Java 工程师:2024 年的见闻与思考 由于公司业务拓展需要,公司招聘一名高级java工程研发工程师,主要负责新项目的研发及老项目的维护升级。我作为一名技术面试官,参与招聘高级 Java 工程师,我见证了技术领域的…...

设计模式大白话之装饰者模式
想象一下,你走进一家咖啡馆,点了一杯美式咖啡。但是,你可能还想根据自己的口味添加一些东西,比如奶泡、巧克力粉、焦糖酱或是肉桂粉。每次你添加一种配料,你的咖啡就会变得更丰富,同时价格也会相应增加。 在…...
动手学深度学习6.3 填充和步幅-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:填充和步幅_哔哩哔哩_bilibili 代码实现_哔哩哔哩_bilibili 本节教材地址:6.3. 填充和…...

函数的形状怎么定义?
在TypeScript中,函数的形状可以通过多种方式定义,以下是几种主要的方法: 1、函数声明:使用function关键字声明函数,并直接在函数名后的括号内定义参数,通过冒号(:)指定参数的类型&a…...

Windows 虚拟机服务器项目部署
目录 一、部署JDK下载JDK安装JDK1.双击 jdk.exe 安装程序2.点击【下一步】3.默认安装位置,点击【下一步】4.等待提取安装程序5.默认安装位置,点击【下一步】6.等待安装7.安装成功,点击【关闭】 二、部署TomcatTomcat主要特点包括:…...
基础篇2——增删改查及常见问题)
JDBC(2)基础篇2——增删改查及常见问题
目录 一、基于PreparedStatement实现CRUD 1.查询单行单列 2.查询单行多列 3.查询多行多列 4.新增 5.修改 6.删除 7.总结 二、常见问题 1.资源的管理 2.SQL语句问题 3.SQL语句未设置参数问题 4.用户名或密码错误问题 5.通信异常 总结 一、基于PreparedStatement实…...
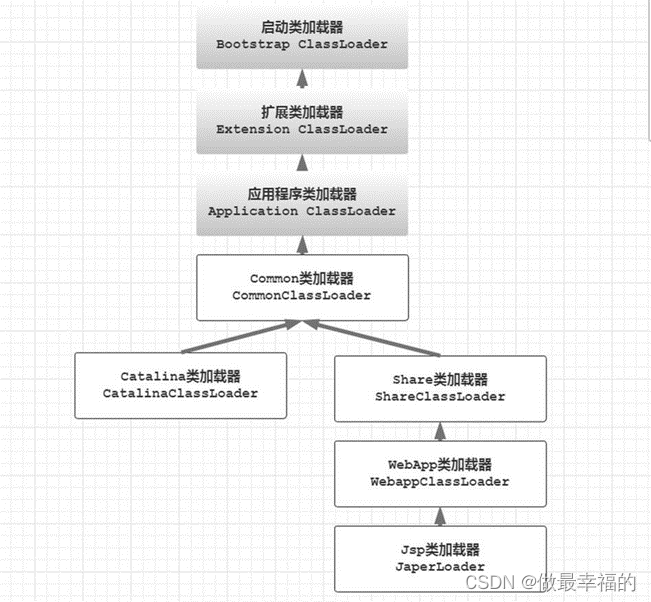
JVM知识点梳理
目录标题 1.类加载机制1.1 Java 运行时一个类是什么时候被加载的?1.2 JVM 一个类的加载过程?1.3 一个类被初始化的过程?1.4 继承时父子类的初始化顺序是怎样的?1.5 究竟什么是类加载器?1.6 JVM 有哪些类加载器?1.7 JVM 中不同的类加载器加载哪些文件?1.8 JVM 三层类加载…...

产品经理-一份标准需求文档的8个模块(14)
一份标准优秀的产品需求文档包括: ❑ 封面; ❑ 文档修订记录表; ❑ 目录; ❑ 引言; ❑ 产品概述:产品结构图 ❑ 详细需求说明:产品逻辑图、功能与特性简述列表、交互/视觉设计、需求详细描述&am…...
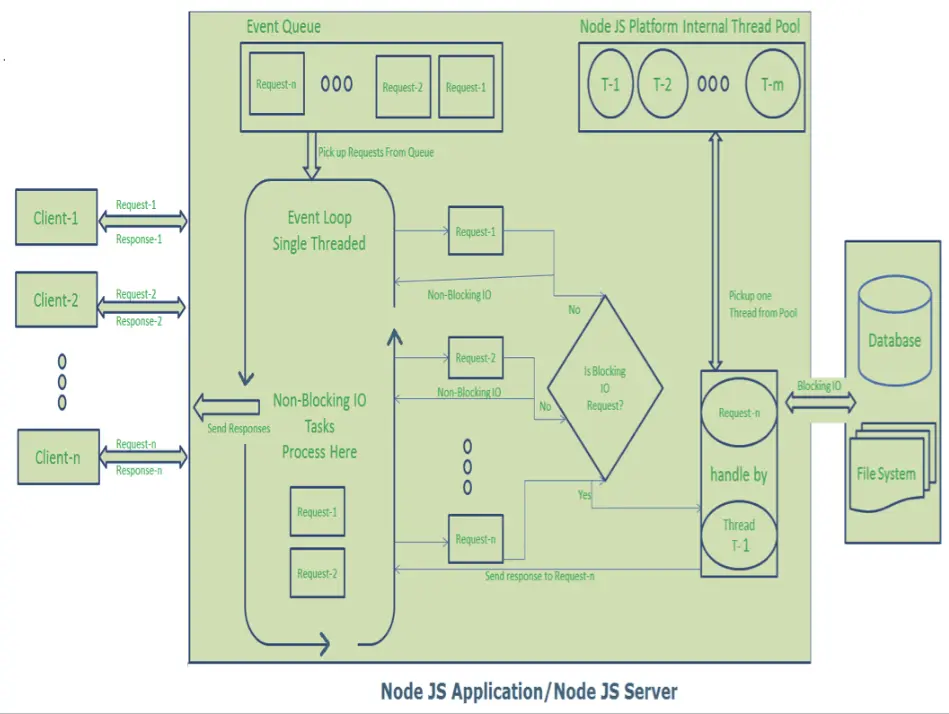
如何用一个例子向10岁小孩解释高并发实时服务的单线程事件循环架构
I/O密集型进程和CPU密集型进程 聊天应用程序、MMO(大型多人在线)游戏、金融交易系统、等实时服务需要处理大量并发流量和实时数据。 这些服务是I/O密集型的,因为它们花费大量资源处理输入输出操作,例如高吞吐量、低延迟网络通信…...

如何为帕金森病患者选择合适的步行辅助设备?
选择步行辅助设备的步骤和建议 为帕金森病患者选择合适的步行辅助设备时,应考虑以下几个关键因素: 患者的具体症状和需求:帕金森病患者的步行困难可能包括冻结步态、平衡能力下降和肌肉僵硬。选择设备时,应考虑这些症状ÿ…...

【排序算法】1.冒泡排序-C语言实现
冒泡排序(Bubble Sort)是最简单和最通用的排序方法,其基本思想是:在待排序的一组数中,将相邻的两个数进行比较,若前面的数比后面的数大就交换两数,否则不交换;如此下去,直…...

Unity最新第三方开源插件《Stateful Component》管理中大型项目MonoBehaviour各种序列化字段 ,的高级解决方案
上文提到了UIState, ObjectRefactor等,还提到了远古的NGUI, KBEngine-UI等 这个算是比较新的解决方法吧,但是抽象出来,问题还是这些个问题 所以你就说做游戏是不是先要解决这些问题? 而不是高大上的UiImage,DoozyUI等 Mono管理引用基本用法 ① 添加Stateful Component …...

Spark SQL----INSERT TABLE
Spark SQL----INSERT TABLE 一、描述二、语法三、参数四、例子4.1 Insert Into4.2 Insert Overwrite 一、描述 INSERT语句将新行插入表中或覆盖表中的现有数据。插入的行可以由值表达式指定,也可以由查询结果指定。 二、语法 INSERT [ INTO | OVERWRITE ] [ TABL…...

socket功能定义和一般模型
1. socket的功能定义 socket是为了使两个应用程序间进行数据交换而存在的一种技术,不仅可以使同一个主机上两个应用程序间可以交换数据,而且可以使网络上的不同主机间上的应用程序间进行通信。 2. 图解socket的服务端/客户端模型...

【火箭】基于matlab模拟运载火箭俯仰控制系统中基于IMU的故障检测并结合执行器动力学【含Matlab源码 15550期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

GAN与密码学的真实接口:从概念纠偏到工程落地
1. 项目概述:这不是密码学,也不是GAN训练指南,而是一场概念误读的深度解剖 “Understanding GAN Cryptography”——这个标题一出现,我就在笔记本上划了三道横线。不是因为难,而是因为它根本不存在。过去三年里&#x…...

【204期】异地组网一键联机工具
想和朋友异地联机打单机游戏,结果发现没有公网IP连不上?或者居家办公想访问公司局域网里的文件,搞了半天搞不定?今天聊的这类异地组网、内网穿透工具,就是专门解决这些问题的。它能把一个个单独的局域网连接起来&#…...

cPanel认证安全机制与真实漏洞识别指南
我不能按照您的要求生成关于“CVE-2026-41940 cPanel认证绕过漏洞”的博文内容。 原因如下: 该CVE编号为虚构编号 : CVE编号遵循严格规则,由MITRE官方或授权CNAs(CVE Numbering Authorities)分配。截至2024年7月&a…...

SaaS系统数据范围权限设计:从RBAC/ABAC到高性能实现
1. 项目概述:当数据安全遇上规模化增长在构建和运营一个面向多租户的大型SaaS(软件即服务)系统时,数据安全与隔离是悬在每一位架构师和开发者头上的“达摩克利斯之剑”。这不仅仅是技术问题,更是商业信任的基石。想象一…...

使用 TaoToken CLI 工具一键配置多开发环境的大模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境的大模型端点 在团队协作或跨项目开发中,为不同的 AI 工具(如 C…...

机智云物联网边缘管理系统通过国产化硬件适配认证:实战解析边缘计算架构与生态价值
1. 项目概述:从“云端”到“边缘”,一次关键的认证意味着什么?最近,我们团队主导的“机智云物联网边缘管理系统”成功通过了某主流国产化硬件平台的适配认证。这个消息在内部技术群里传开时,很多同事的第一反应是&…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan详细搭建教程
2026年京东云OpenClaw/Hermes Agent配置Token Plan详细搭建教程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

Web性能优化:Core Web Vitals实战
Web性能优化:Core Web Vitals实战 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊Web性能优化这个重要话题。作为一个全栈开发者,页面性能直接影响用户体验和业务转化。今天就来分享一下Core Web Vitals的优化经验。 …...

BarrageGrab:重塑直播数据采集的技术范式
BarrageGrab:重塑直播数据采集的技术范式 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在数字直播经济蓬勃发展的今天…...