LLM-阿里 DashVector + langchain self-querying retriever 优化 RAG 实践【Query 优化】
文章目录
- 前言
- self querying 简介
- 代码实现
- 总结
前言
现在比较流行的 RAG 检索就是通过大模型 embedding 算法将数据嵌入向量数据库中,然后在将用户的查询向量化,从向量数据库中召回相似性数据,构造成 context template, 放到 LLM 中进行查询。
如果说将用户的查询语句直接转换为向量查询可能并不会得到很好的结果,比如说我们往向量数据库中存入了一些商品向量,现在用户说:“我想要一条价格低于20块的黑色羊毛衫”,如果使用传统的嵌入算法,该查询语句转换为向量查询就可能“失帧”,被转换为查询黑色羊毛衫。
针对这种情况我们就会使用一些优化检索查询语句方式来优化 RAG 查询,其中 langchain 的 self-querying 就是一种很好的方式,这里使用阿里云的 DashVector 向量数据库和 DashScope LLM 来进行尝试,优化后的查询效果还是挺不错的。
现在很多网上的资料都是使用 OpenAI 的 Embedding 和 LLM,但是个人角色现在国内阿里的 LLM 和向量数据库已经非常好了,而且 OpenAI 已经禁用了国内的 API 调用,国内的云服务又便宜又好用,真的不尝试一下么?关于 DashVector 和 DashScope 我之前写了几篇实践篇,大家感兴趣的可以参考下:
LLM-文本分块(langchain)与向量化(阿里云DashVector)存储,嵌入LLM实践
LLM-阿里云 DashVector + ModelScope 多模态向量化实时文本搜图实战总结
LLM-langchain 与阿里 DashScop (通义千问大模型) 和 DashVector(向量数据库) 结合使用总结
前提条件
- 确保开通了通义千问 API key 和 向量检索服务 API KEY
- 安装依赖:
pip install langchain
pip install langchain-community
pip install dashVector
pip install dashscope
self querying 简介
简单来说就是通过 self-querying 的方式我们可以将用户的查询语句进行结构化转换,转换为包含两层意思的向量化数据:
- Query: 和查询语义相近的向量查询
- Filter: 关于查询内容的一些 metadata 数据
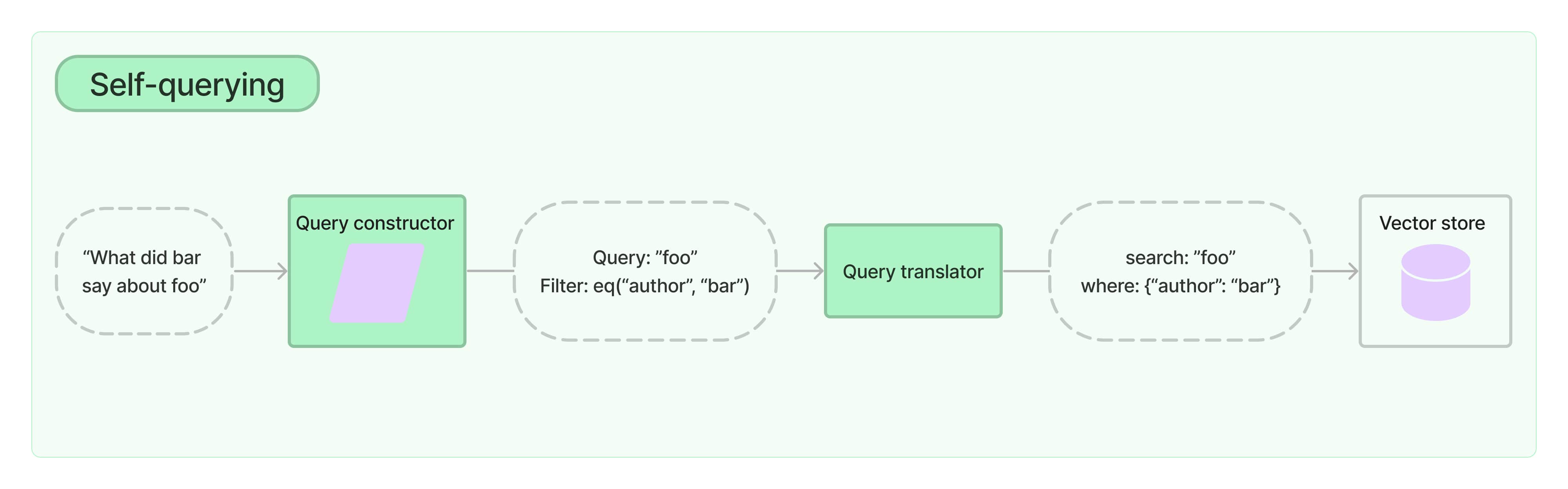
比如说上图中用户输入:“bar 说了关于 foo 的什么东西?”,self-querying 结构化转换后就变为了两层含义:
- 查询关于 foo 的数据
- 其中作者为 bar
代码实现
将DASHSCOPE_API_KEY, DASHVECTOR_API_KEY, DASHVECTOR_ENDPOINT替换为自己在阿里云开通的。
import osfrom langchain_core.documents import Document
from langchain_community.vectorstores.dashvector import DashVector
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.vectorstores import VectorStoreclass SelfQuerying:def __init__(self):# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEYos.environ["DASHSCOPE_API_KEY"] = ""os.environ["DASHVECTOR_API_KEY"] = ""os.environ["DASHVECTOR_ENDPOINT"] = ""self.llm = ChatTongyi(temperature=0)def handle_embeddings(self)->'VectorStore':docs = [Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},),Document(page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},),Document(page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},),Document(page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},),Document(page_content="Toys come alive and have a blast doing so",metadata={"year": 1995, "genre": "animated"},),Document(page_content="Three men walk into the Zone, three men walk out of the Zone",metadata={"year": 1979,"director": "Andrei Tarkovsky","genre": "thriller","rating": 9.9,},),]# 指定向量数据库中的 Collection namevectorstore = DashVector.from_documents(docs, DashScopeEmbeddings(), collection_name="langchain")return vectorstoredef build_querying_retriever(self, vectorstore: 'VectorStore', enable_limit: bool=False)->'SelfQueryRetriever':"""构造优化检索:param vectorstore: 向量数据库:param enable_limit: 是否查询 Top k:return:"""metadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",type="string",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),]document_content_description = "Brief summary of a movie"retriever = SelfQueryRetriever.from_llm(self.llm,vectorstore,document_content_description,metadata_field_info,enable_limit=enable_limit)return retrieverdef handle_query(self, query: str):"""返回优化查询后的检索结果:param query::return:"""# 使用 LLM 优化查询向量,构造优化后的检索retriever = self.build_querying_retriever(self.handle_embeddings())response = retriever.invoke(query)return responseif __name__ == '__main__':q = SelfQuerying()# 只通过查询属性过滤print(q.handle_query("I want to watch a movie rated higher than 8.5"))# 通过查询属性和查询语义内容过滤print(q.handle_query("Has Greta Gerwig directed any movies about women"))# 复杂过滤查询print(q.handle_query("What's a highly rated (above 8.5) science fiction film?"))# 复杂语义和过滤查询print(q.handle_query("What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"))上边的代码主要步骤有三步:
- 执行 embedding, 将带有 metadata 的 Doc 嵌入 DashVector
- 构造 self-querying retriever,需要预先提供一些关于我们的文档支持的元数据字段的信息以及文档内容的简短描述。
- 执行查询语句
执行代码输出查询内容如下:
# "I want to watch a movie rated higher than 8.5"
[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})]# "Has Greta Gerwig directed any movies about women"
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]# "What's a highly rated (above 8.5) science fiction film?"
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]# "What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
[Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]
总结
本文主要讲了如何使用 langchain 的 self-query 来优化向量检索,我们使用的是阿里云的 DashVector 和 DashScope LLM 进行的代码演示,读者可以开通下,体验尝试一下。
相关文章:
LLM-阿里 DashVector + langchain self-querying retriever 优化 RAG 实践【Query 优化】
文章目录 前言self querying 简介代码实现总结 前言 现在比较流行的 RAG 检索就是通过大模型 embedding 算法将数据嵌入向量数据库中,然后在将用户的查询向量化,从向量数据库中召回相似性数据,构造成 context template, 放到 LLM 中进行查询…...

【python】PyQt5的窗口界面的各种交互逻辑实现,轻松掌控图形化界面程序
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

DockerCompose介绍,安装,使用
DockerCompose 1、Compose介绍 将单机服务-通过Dockerfile 构建为镜像 -docker run 成为一个服务 user 8080 net 7000 pay 8181 admin 5000 监控 .... docker run 单机版、一个个容器启动和停止问题: 前面我们使用Docker的时候,定义 Dockerfil…...

N叉树的前序遍历
Problem: 589. N 叉树的前序遍历 文章目录 思路解题过程Code 思路 前序遍历,遇到空节点返回 解题过程 对每个节点进行遍历 Code /* // Definition for a Node. class Node { public:int val;vector<Node*> children;Node() {}Node(int _val) {val _val;}Nod…...

Linux C++ 054-设计模式之外观模式
Linux C 054-设计模式之外观模式 本节关键字:Linux、C、设计模式、外观模式 相关库函数: 概念 外观模式(Facade),亦称“过程模式”。主张按照描述和判断资料来评价课程,关键的活动是在课程实施的全过程中…...

Linux - 冯-诺依曼体系结构、初始操作系统
目录 冯•诺依曼体系 结构推导 内存提高效率的方法 数据的流动过程 体系结构相关知识 初始操作系统 定位 设计目的 操作系统之上之下分别有什么 管理精髓:先描述,再组织 冯•诺依曼体系 结构推导 计算机基本工作流程图大致如下: 输入设备&a…...

成功适配!极验设备指纹HarmonyOS 鸿蒙版官方下载
近日,华为开发者大会(HDC 2024)在东莞召开。在大会开幕日的首场主题演讲中,华为宣布当前已有TOP5000应用成为鸿蒙原生应用,350+SDK已适配HarmonyOS NEXT版本。其中,极验作为其重要伙伴ÿ…...

【C++】字符串学习 知识点+代码记录
一.知识点总结 1. C风格字符串(字符数组) 字符数组存储字符串:C风格的字符串实际上是字符数组,以空字符\0作为结尾标志。字符串字面量与字符数组:字符串字面量如"Hello"被编译器视为const char*类型&#…...

尝试理解docker网络通信逻辑
一、docker是什么 Docker本质是一个进程,宿主机通过namespace隔离机制提供进程需要运行基础环境,并且通过Cgroup限制进程调用资源。Docker的隔离机制包括 network隔离,此次主要探讨网络隔离mount隔离hostname隔离user隔离pid隔离进程通信隔离 二、doc…...
数据仓库哈哈
数据仓库 基本概念数据库(database)和数据仓库(Data Warehouse)的异同 整体架构分层架构方法论ER模型(建模理论)维度模型 何为分层第一层:数据源(ODS ER模型)设计要点日志…...

K最近邻(K-Nearest Neighbors, KNN)
K最近邻(K-Nearest Neighbors, KNN)理论知识推导 KNN算法是一个简单且直观的分类和回归方法,其基本思想是:给定一个样本点,找到训练集中与其最近的K个样本点,根据这些样本点的类别(分类问题&am…...

深度学习损失计算
文章目录 深度学习损失计算1.如何计算当前epoch的损失?2.为什么要计算样本平均损失,而不是计算批次平均损失? 深度学习损失计算 1.如何计算当前epoch的损失? 深度学习中的损失计算,通常为数据集的平均损失࿰…...

论文翻译:通过云计算对联网多智能体系统进行预测控制
通过云计算对联网多智能体系统进行预测控制 文章目录 通过云计算对联网多智能体系统进行预测控制摘要前言通过云计算实现联网的多智能体控制系统网络化多智能体系统的云预测控制器设计云预测控制系统的稳定性和一致性分析例子结论 摘要 本文研究了基于云计算的网络化多智能体预…...

Java核心(五)多线程
线程并行的逻辑 一个线程问题 起手先来看一个线程问题: public class NumberExample {private int cnt 0;public void add() {cnt;}public int get() {return cnt;} }public static void main(String[] args) throws InterruptedException {final int threadSiz…...

IDEA快速生成项目树形结构图
下图用的IDEA工具,但我觉得WebStorm 应该也可以 文章目录 进入项目根目录下,进入cmd输入如下指令: 只有文件夹 tree . > list.txt 包括文件夹和文件 tree /f . > list.txt 还可以为相关包路径加上注释...

【CPO-TCN-BiGRU-Attention回归预测】基于冠豪猪算法CPO优化时间卷积双向门控循环单元融合注意力机制
基于冠豪猪算法CPO(Correlation-Preservation Optimization)优化的时间卷积双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)融合注意力机制(Attention)的回归预测需要详细的实现和…...

面试高级 Java 工程师:2024 年的见闻与思考
面试高级 Java 工程师:2024 年的见闻与思考 由于公司业务拓展需要,公司招聘一名高级java工程研发工程师,主要负责新项目的研发及老项目的维护升级。我作为一名技术面试官,参与招聘高级 Java 工程师,我见证了技术领域的…...

设计模式大白话之装饰者模式
想象一下,你走进一家咖啡馆,点了一杯美式咖啡。但是,你可能还想根据自己的口味添加一些东西,比如奶泡、巧克力粉、焦糖酱或是肉桂粉。每次你添加一种配料,你的咖啡就会变得更丰富,同时价格也会相应增加。 在…...
动手学深度学习6.3 填充和步幅-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:填充和步幅_哔哩哔哩_bilibili 代码实现_哔哩哔哩_bilibili 本节教材地址:6.3. 填充和…...

函数的形状怎么定义?
在TypeScript中,函数的形状可以通过多种方式定义,以下是几种主要的方法: 1、函数声明:使用function关键字声明函数,并直接在函数名后的括号内定义参数,通过冒号(:)指定参数的类型&a…...

AI设计泳装,能颠覆今夏潮流?
AI设计泳装,能颠覆今夏潮流? 夏日临近,泳装市场硝烟再起。然而,海量款式与消费者挑剔审美的矛盾日益尖锐——设计周期长、打版成本高、爆款命中率低,让无数商家深陷库存泥潭。如何破局?北京先智先行科技有限…...

三分钟完成Taotoken的API Key配置与curl调用测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 三分钟完成Taotoken的API Key配置与curl调用测试 基础教程类,面向刚注册Taotoken并获取了API Key的开发者,…...

OpenClaw 本地部署避坑指南|环境配置 + 故障排查全流程
🦞 OpenClaw 本地部署避坑指南|环境配置 故障排查全流程 开源 AI 自动化工具OpenClaw(小龙虾) 凭借本地私有化部署、无侵入系统交互、全流程自动化执行等核心特性,在开发者社区快速普及。轻量化架构与高扩展性&#…...

《怕你忍不住》的传播入口:情绪临界点如何被记住
从内容传播角度看,《怕你忍不住》的入口不是猎奇,而是一个非常具体的情绪临界点:话快说出口、眼泪快掉下来、冲动快把人推着走。标题先完成识别,读者会知道这不是泛泛的伤感歌。这首歌适合连接很多高频场景。深夜准备发出一条消息…...

终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码
终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码 【免费下载链接】luajit-decompiler https://gitlab.com/znixian/luajit-decompiler 项目地址: https://gitcode.com/gh_mirrors/lu/luajit-decompiler 你是否曾面对编译后的LuaJIT字节码文件束手无策&…...

Adobe-GenP:5分钟解锁Adobe全家桶的终极方案
Adobe-GenP:5分钟解锁Adobe全家桶的终极方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为Adobe Creative Cloud的高昂订阅费用发愁吗ÿ…...

TurboVNC终极指南:如何快速搭建高性能远程桌面系统
TurboVNC终极指南:如何快速搭建高性能远程桌面系统 【免费下载链接】turbovnc Main TurboVNC repository 项目地址: https://gitcode.com/gh_mirrors/tu/turbovnc TurboVNC是一个专为高性能图形应用优化的远程桌面解决方案,特别适合3D渲染、视频处…...

终极macOS Windows启动盘制作工具:WinDiskWriter完整指南
终极macOS Windows启动盘制作工具:WinDiskWriter完整指南 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI & Legac…...

二代壳脱壳新思路:Hook CreateFromRawDexFile捕获原始DEX
1. 为什么“二代壳”让传统脱壳方法集体失效?——从Dex加载链路说起你有没有试过用经典的dumpdex脚本在Android 10设备上跑,结果dump出来的dex文件一打开就是满屏java.lang.ClassNotFoundException?或者用dex2oat反编译出的odex,反…...

协议转换网关与数据采集网关的区别与差异
摘要在工业自动化、物联网、智能建筑等领域中,“协议转换”和“数据采集网关”是两个常被提及但容易混淆的概念。它们虽有关联,却扮演着不同的角色。理解其核心差异对于构建高效、可靠的数据通信系统至关重要。1.核心定义:本质差异1.1协议转换…...