乘积量化pq:将高维向量压缩 97%
向量相似性搜索在处理大规模数据集时,往往面临着内存消耗的挑战。例如,即使是一个包含100万个密集向量的小数据集,其索引也可能需要数GB的内存。随着数据集规模的增长,尤其是高维数据,内存使用量会迅速增加,这可能导致内存管理问题。
乘积量化(PQ)是一种流行的方法,能够显著压缩高维向量,实现高达97%的内存节省,并在实际测试中将最近邻搜索的速度提高5.5倍。
更进一步,复合IVF(倒排文件索引)与PQ结合的索引方法,在不牺牲准确性的前提下,将搜索速度提高16.5倍。与非量化索引相比,整体性能提升了惊人的92倍。
本文将深入介绍PQ的各个方面,包括其工作原理、优势与局限、在Faiss中的实现方式,以及如何构建复合IVFPQ索引。还将探讨如何通过PQ实现速度和内存的优化,在处理大规模向量数据时,有效提升相似性搜索的性能。
量化是什么
量化通常是指将数据压缩到较小空间的方法。为了深入理解这一概念,需要区分量化与降维,虽然它们都旨在减少数据的存储需求,但方法和目的不同。
假设有一个高维向量,其维度为128,这些值是32位浮点数,范围在0.0到157.0之间(范围S)。通过降维,目标是产生一个更低维度的向量。
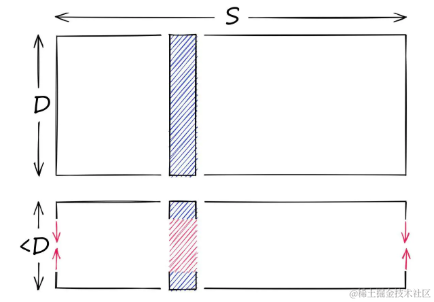
降维是降低向量的维度D,但并未改变范围S
另一方面,量化并不关心维度D,它针对潜在的值的范围,是减少S。
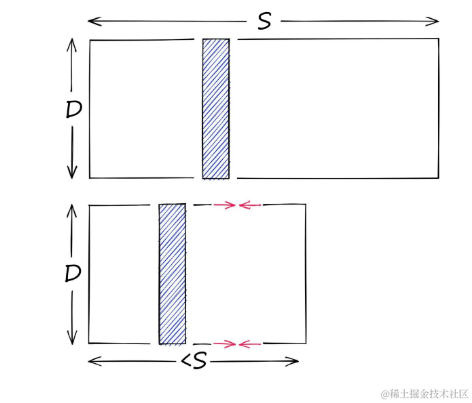
量化减少可能向量的范围S
降维:
- 降维的目标是减少高维向量的维度,例如将128维的向量转换为更低维度。
- 这一过程涉及将向量投影到更低维的空间,同时尽量保留原始数据的特征。
- 降维后,向量的数据范围(S)保持不变。
量化:
- 与降维不同,量化关注的是减少向量可能取值的范围,而不是维度。
- 量化通过将连续的数据范围映射到有限的离散值集来实现压缩。
量化可以通过多种方法实现,其中最常见的是聚类。在聚类过程中:
- 将一组向量通过聚类算法分组。
- 然后选择代表每个组的中心点,这些中心点构成了一个离散的符号集合。
- 通过上述方式,原始向量被映射到这些离散的符号上,从而显著减少可能值的范围。
量化操作将向量从具有无限可能值的连续空间转换到具有有限可能值的离散空间。这些离散值是对原始向量的符号表示。量化后的符号表示可以有多种形式,例如:
- 乘积量化(PQ) 中的聚类中心点
- 局部敏感哈希(LSH) 产生的二进制代码
这些表示方法都是将原始数据压缩的有效手段,同时保留足够的信息以进行高效的相似性搜索。
为什么使用乘积量化?
乘积量化(Product Quantization, PQ)主要用于减少索引的内存占用,这在处理大量向量时尤为重要,因为这些向量必须全部加载到内存中才能进行比较。
PQ并不是唯一的量化方法,但它在减少内存大小方面比其它方法如k-means更为有效。以下是PQ与其他方法的内存使用和量化操作复杂性的比较:
- k-means 的内存和复杂度计算公式为: k D kD kD
- PQ 的内存和复杂度计算公式为: m k ∗ D ∗ = k 1 / m D mk^*D^* = k^{1/m}D mk∗D∗=k1/mD
其中,D 代表输入向量的维度,k 表示用于表示向量的总中心点数量,m 表示将向量分割成子向量的数量。
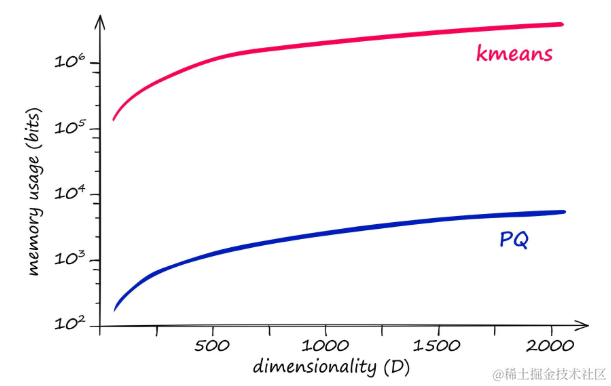
内存使用(和复杂度)与维度,使用 k = 2048 k=2048 k=2048和 m = 8 m=8 m=8
使用乘积量化时,需要一个较高的 k 值(例如 2048 或更高)来获得良好的结果。对于给定的向量维度 D,不使用PQ的聚类方法将导致非常高的内存需求和复杂度:
| 操作 | 内存和复杂度 |
|---|---|
| k-means | k D = 2048 × 128 = 262144 kD = 2048×128 = 262144 kD=2048×128=262144 |
| PQ | m k D = ( k 1 / m ) × D = ( 204 8 1 / 8 ) × 128 = 332 mkD = (k^{1/m})×D = (2048^{1/8})×128 = 332 mkD=(k1/m)×D=(20481/8)×128=332 |
通过将向量分割成子向量,并应用到这些较小维度的子量化过程,PQ显著降低了等效内存使用和分配复杂度。
第二个重要因素是量化器的训练。量化器需要一个比 k 大几倍的数据集来进行有效的训练。没有乘积量化,这将需要大量的训练数据。
使用子量化器,只需要k/m 的倍数,尽管这可能仍然是一个相当大的数字,但与k-means相比,它可以显著减少所需的训练数据量。
乘积量化是如何工作的
乘积量化是一种高效的数据压缩技术,特别适用于大规模向量数据集。以下是PQ的基本原理和步骤:
- 向量分割: 取一个大的高维向量,将其分割成等大小的块,这些块称为子向量
- 子空间聚类: 每个子向量空间分配一个独立的聚类集,对每个子空间进行聚类以确定中心点
- 中心点分配: 将每个子向量与最近的中心点进行匹配,并用该中心点的唯一ID替换原始子向量
- 向量ID化: 原始高维向量被转换为一系列中心点的ID,这些ID构成了量化后的向量
过程结束后,需要大量内存的高维向量会减少到一个需要很少内存的小向量。假设有一个长度为 D 的向量,将其分割成m 个子向量,每个子向量的长度为 D/m。
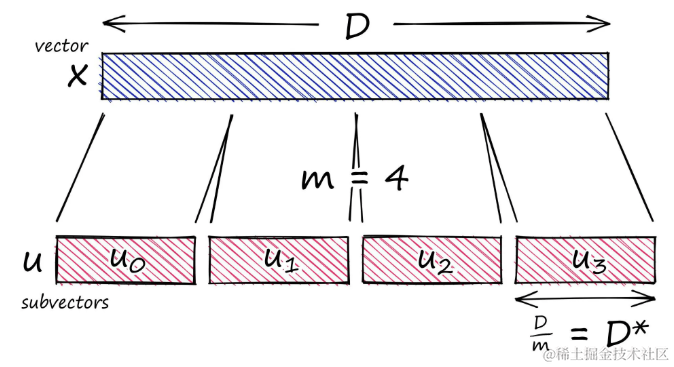
将高维向量
x分割成几个子向量 u j u_j uj
# 定义原始向量和分割参数
x = [1, 8, 3, 9, 1, 2, 9, 4, 5, 4, 6, 2]m = 4
D = len(x)assert D % m == 0D_ = int(D / m) # 每个子向量的长度u = [x[row:row+D_] for row in range(0, D, D_)] # 创建子向量
u# [[1, 8, 3], [9, 1, 2], [9, 4, 5], [4, 6, 2]]
在乘积量化(PQ)中,原始的高维向量首先被分解为多个子向量,每个子向量可以通过其位置 j 来引用。这个过程是实现有效量化的关键步骤。
接下来,采用聚类的方法来处理这些子向量。以一个简单的随机示例来说明,假设有一组数量庞大的向量集合,可以指定想要的聚类数量,比如说3个。然后,将通过优化这些聚类中心点来对原始向量进行分类,每个向量根据其与最近中心点的距离被分配到相应的类别中。
PQ的聚类过程与上述方法类似,但有一个关键的区别,在PQ中,不是对整个向量空间进行单一的聚类,而是每个子向量空间都拥有自己的聚类集。这意味着,实际上是在多个子空间上并行地应用聚类算法。
这种方法的优势在于:
- 并行处理:每个子空间的聚类可以独立进行,这有助于并行化计算,提高效率。
- 局部优化:每个子空间可以有自己的最优聚类中心点,这有助于捕捉局部特征。
k = 2**5
assert k % m == 0
k_ = int(k/m)
print(f"{k=}, {k_=}")
# k=32, k_=8from random import randintc = []
for j in range(m):c_j = [] # 每个j代表一个子矢量(因此也代表子量化器)位置for i in range(k_):# 每个i表示每个子空间j内的聚类/再现值位置c_ji = [randint(0, 9) for _ in range(D_)]c_j.append(c_ji) # 将聚类质心添加到子空间列表c.append(c_j) # 将质心的子空间列表添加到整体列表中
在乘积量化(PQ)中,每个子向量通过与特定的中心点匹配来实现量化。这些中心点在PQ中被称作复制值,用下标c[i]表示,其中:
i表示子向量在所有子向量中的索引。j表示子向量在特定子空间中的位置标识符。- 对于每个子向量空间
j,存在k*个可能的中心点,每个中心点都有一个唯一的标识。
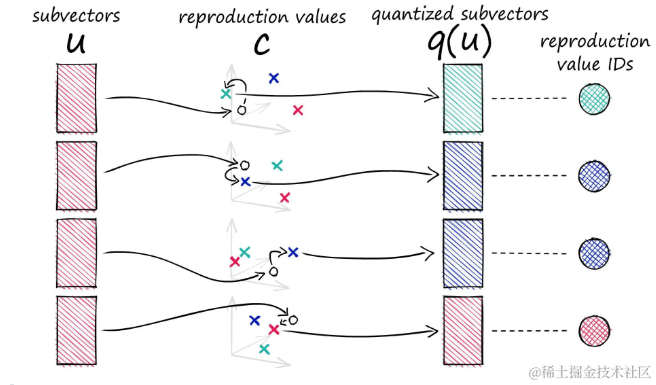
子向量被替换为特定的中心点向量,然后可以用特定于该中心点向量的唯一ID替换
def euclidean(v, u):distance = sum((x - y) ** 2 for x, y in zip(v, u)) ** .5return distancedef nearest(c_j, u_j):distance = 9e9for i in range(k_):new_dist = euclidean(c_j[i], u_j)if new_dist < distance:nearest_idx = idistance = new_distreturn nearest_idxids = []
for j in range(m):i = nearest(c[j], u[j])ids.append(i)
ids # [1, 1, 2, 1]
当采用乘积量化(PQ)处理向量时,会经历以下步骤:
- 向量分割:原始向量被分割为多个子向量。
- 子向量量化:每个子向量独立地被量化,即分配给最近的集群中心点(在PQ中称为复制值)
- 中心点ID分配:量化后,不直接存储子向量,而是用它们对应的中心点的ID来表示
在PQ中,每个中心点c[i]都有一个唯一的ID。这些ID用于后续将量化后的向量映射回原始的中心点值。这个过程不仅减少了存储需求,还便于进行快速的相似性比较。
q = []
for j in range(m):c_ji = c[j][ids[j]] # 根据中心点ID获取中心点坐标q.extend(c_ji) # 将中心点坐标添加到量化向量列表
q# [1, 7, 7, 6, 3, 6, 7, 4, 4, 3, 9, 6]
通过乘积量化(PQ)技术,能够显著压缩数据表示的大小,从而减少存储需求和提高处理效率。以一个简化的例子来说明,一个12维的向量被压缩成了一个4维的ID向量。虽然这里的维度较小,用于展示目的,但PQ技术的好处在更大规模的数据集上将更加明显。
考虑一个更实际的情况,从原始的128维8位整数向量转变为128维32位浮点数向量,这种转变模拟了真实世界数据的复杂性。当应用PQ技术,将这样的向量压缩到仅包含8个维度的8位整数向量时,可以看到显著的存储空间节省。
对比原始向量和量化后的向量所需的存储空间:
- 原始向量:128维 × 32位 = 4096位
- 量化向量:8维 × 8位 = 64位
这种压缩带来了64倍的存储空间减少,这是一个显著的差异。PQ技术不仅减少了存储需求,还可能提高搜索和处理速度,同时保持了数据的有用特征,为性能和压缩之间提供了良好的平衡。
PQ在Faiss中的实现
上述已经通过Python示例了解PQ的基本概念。在实际应用中,通常会采用优化过的库,如Faiss等来实现PQ。
数据获取
首先,获取数据。以Sift1M数据集为例,展示如何在Faiss中构建PQ索引,并将其与倒排文件(IVF)结合以提高搜索效率。
import shutil
import urllib.request as request
from contextlib import closing# 下载Sift1M数据集
with closing(request.urlopen('ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz')) as r:with open('sift.tar.gz', 'wb') as f:shutil.copyfileobj(r, f)import tarfile# 解压数据集
tar = tarfile.open('sift.tar.gz', "r:gz")
tar.extractall()import numpy as np# 读取Sift1M数据集的函数
def read_fvecs(fp):a = np.fromfile(fp, dtype='int32')d = a[0]return a.reshape(-1, d + 1)[:, 1:].copy().view('float32')# 加载数据
wb = read_fvecs('./sift/sift_base.fvecs') # 100万个样本
xq = read_fvecs('./sift/sift_query.fvecs') # 查询向量
xq = xq[0].reshape(1, xq.shape[1]) # 取第一个查询向量xq.shape # (1, 128)wb.shape # (1000000, 128)
接下来探讨如何在Faiss中构建PQ索引。
IndexPQ
在Faiss中,IndexPQ是一个实现乘积量化的索引,它用于高效地处理高维向量的近似最近邻搜索。
初始化IndexPQ
要初始化IndexPQ,需要定义三个关键参数:
D:向量的维度m:将完整向量分割成子向量的数量,需要保证D能被m整除nbits:每个子量化器的位数,决定了每个子空间的中心点数量, k = 2 n b i t s k_ = 2^{nbits} k=2nbits
import faissD = xb.shape[1] # 向量维度
m = 8 # 子向量数量
assert D % m == 0
nbits = 8 # 每个子量化器的位数
index = faiss.IndexPQ(D, m, nbits) # 初始化IndexPQ
训练IndexPQ
由于PQ依赖于聚类,需要使用数据集xb来训练索引。训练过程可能需要一些时间,特别是当使用较大的nbits时。
index.is_trained # 检查索引是否已训练index.train(xb) # 训练索引
搜索与性能评估
接下来,使用训练好的索引进行搜索,并评估其性能。
dist, I = index.search(xq, k) # 搜索k个最近邻 %%timeit
index.search(xq, k)# 1.49 ms ± 49.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
搜索操作返回最近邻的距离(dist)和索引(I),可以将IndexPQ的召回性能与平面索引(IndexFlatL2)进行比较。
l2_index = faiss.IndexFlatL2(D) # 初始化平面索引
l2_index.add(xb)%%time
l2_dist, l2_I = l2_index.search(xq, k) # 平面索引搜索# CPU times: user 46.1 ms, sys: 15.1 ms, total: 61.2 ms Wall time: 15 mssum([1 for i in I[0] if i in l2_I]) # 召回率比较
上述可以得到50%的召回率,如果愿意为了PQ降低内存使用而牺牲完美结果,这是一个合理的召回率,搜索时间也减少到只有平面搜索时间的18%,可以通过使用IVF进一步改善。
PQ的低召回率是一个主要缺点,这可以通过设置更大的nbits来部分抵消,但相应的搜索时间和构建索引的耗时都会变长。对于PQ和IVFPQ索引来说,非常高的召回率是无法实现的,如果需要更高的召回率,应该考虑其他索引。
内存使用评估
最后,评估IndexPQ与平面索引在内存使用上的差异。
import osdef get_memory(index):faiss.write_index(index, './temp.index') # 将索引写入文件file_size = os.path.getsize('./temp.index') # 获取文件大小os.remove('./temp.index') # 删除索引文件return file_size# 比较内存使用
get_memory(l2_index) # 平面索引的内存使用
get_memory(index) # IndexPQ的内存使用
IndexPQ在内存使用上表现出色,相比于平面索引,可以实现显著的内存减少98.4%。此外,通过结合倒排文件(IVF)和PQ,可以在保持较低内存占用的同时,进一步提高搜索速度。
IndexIVFPQ
为了进一步提升搜索速度,可以在PQ的基础上添加一个IVF(倒排文件)索引作为第一步,以减少搜索范围。
初始化IndexIVFPQ
初始化IVF+PQ索引需要定义几个参数:
vecs:基础的FlatL2索引。nlist:Voronoi单元格的数量,必须大于等于k*(2**nbits)。nbits:每个子量化器的位数。m:子向量的数量。
vecs = faiss.IndexFlatL2(D)nlist = 2048 # Voronoi单元格数量
nbits = 8 # 子量化器的位数
m = 8 # 子向量数量
index = faiss.IndexIVFPQ(vecs, D, nlist, m, nbits) # 初始化IVF+PQ索引
print(f"{2**nbits=}")# 2**nbits=256
新参数nlist定义了用来聚类已经量化的PQ向量的Voronoi单元格的数量。可视化一些2D的PQ向量:

2D图表显示重建的PQ向量。然而实际上永远不会使用PQ来处理2D向量,维度太低不足以将它们分割成子向量和子量化。
添加一些Voronoi单元格:
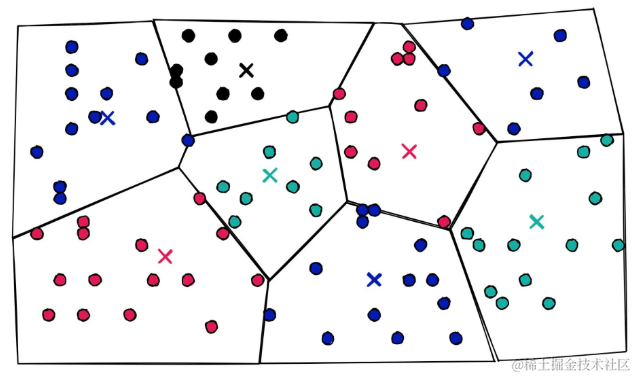
2D图表显示通过IVF分配到不同Voronoi单元格的量化PQ向量
在较高层次上,它们只是一组分区。相似的向量被分配到不同的分区(或细胞),当涉及到搜索时,将搜索限制在最近的细胞中:
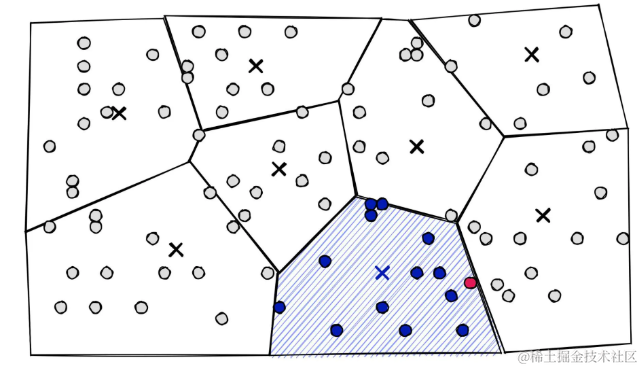
IVF允许将搜索限制在仅分配给附近细胞的向量上,粉红色点是查询向量xq
训练和搜索
训练索引并将数据添加到索引中,然后进行搜索。
index.train(xb) index.add(xb)dist, I = index.search(xq, k) # 搜索k个最近邻%%timeit
index.search(xq, k)# 86.3 µs ± 15 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)sum([1 for i in I[0] if i in l2_I]) # 34
搜索时间非常快,只有86.3μs,但召回率从IndexPQ的50%显著下降到34%。考虑到等效参数,IndexPQ和IndexIVFPQ都应该能够达到相同的召回性能。
提高召回率的秘诀是增加nprobe参数,它控制着要在搜索范围内包括多少个最近的Voronoi细胞。
在一种极端情况下,可以通过将nprobe设置为nlist值来包括所有细胞,这将返回最大可能的召回率。但在实际应用中,需要找到实现这种召回性能的最低nprobe值。
调整召回率
通过调整nprobe参数,可以控制搜索时考虑的Voronoi单元格数量,从而影响召回率。
index.nprobe = 2048 # 搜索所有Voronoi cells
dist, I = index.search(xq, k)
sum([1 for i in I[0] if i in l2_I]) # 52index.nprobe = 2
dist, I = index.search(xq, k)
sum([1 for i in I[0] if i in l2_I]) # 39index.nprobe = 48
dist, I = index.search(xq, k)
sum([1 for i in I[0] if i in l2_I]) # 52
通过将nprobe设置为48,实现了52%的最佳召回分数,同时最小化了搜索范围(因此最大化了搜索速度)。
性能和内存使用评估
最后,评估IndexIVFPQ的性能和内存使用
# 搜索速度和召回率
%%timeit
print("Search time:", index.search(xq, k))print("Recall rate:", sum([1 for i in I[0] if i in l2_I]))# 内存使用
memory_usage = get_memory(index)
print("Memory usage:", memory_usage, "bytes")
通过添加IVF步骤,搜索时间从IndexPQ的1.49ms大幅减少到IndexIVFPQ的0.09ms,内存使用量比平面索引低96%。
通过结合IVF和PQ,IndexIVFPQ在显著减少搜索时间的同时,保持了合理的召回率和极低的内存使用。这使得IndexIVFPQ成为处理大规模数据集时的理想选择。
总结
本文深入探讨了乘积量化(Product Quantization, PQ)及其在Faiss库中的实现,特别关注了IndexPQ和IndexIVFPQ两种索引的性能对比。
乘积量化的优势
乘积量化技术通过将高维向量映射到较低维的离散空间,显著降低了内存使用量。与传统的平面索引(FlatL2)相比,IndexPQ和IndexIVFPQ在内存使用上表现出色:
- FlatL2:使用256MB内存。
- PQ:仅使用6.5MB内存,压缩率达到了97%以上。
- IVFPQ:使用9.2MB内存,略高于PQ,但仍远低于FlatL2。
搜索性能
除了内存使用,还关注了搜索速度和召回率:
- FlatL2:提供了完美的召回率(100%),但搜索速度为8.26毫秒。
- PQ:搜索速度提升至1.49毫秒,但召回率降低至50%。
- IVFPQ:结合了IVF的PQ索引在保持52%召回率的同时,将搜索速度进一步降低至0.09毫秒。
通过将倒排文件(Inverted File, IVF)技术与PQ结合,IndexIVFPQ不仅提高了搜索速度,还略微提升了召回率。这种结合利用了IVF快速缩小搜索范围的优势,同时保持了PQ的内存效率。
| FlatL2 | PQ | IVFPQ | |
|---|---|---|---|
| Recall (%) | 100 | 50 | 52 |
| Speed (ms) | 8.26 | 1.49 | 0.09 |
| Memory (MB) | 256 | 6.5 | 9.2 |
测试结果表明,IndexIVFPQ在内存使用、搜索速度和召回率之间取得了良好的平衡。这项技术特别适合处理大规模数据集,能够在保持合理召回率的同时,实现快速的搜索性能和显著的内存压缩。
参考
- product-quantization
- https://youtu.be/t9mRf2S5vDI
- https://youtu.be/BMYBwbkbVec
- Product quantization for nearest neighbor search
- Jupyter Notebooks
相关文章:
乘积量化pq:将高维向量压缩 97%
向量相似性搜索在处理大规模数据集时,往往面临着内存消耗的挑战。例如,即使是一个包含100万个密集向量的小数据集,其索引也可能需要数GB的内存。随着数据集规模的增长,尤其是高维数据,内存使用量会迅速增加,…...

解决一下git clone失败的问题
1).不开梯子,我们用https克隆 git clone https://github.com 报错: Failed to connect to github.com port 443 after 2091 ms: Couldnt connect to server 解决办法: 开梯子,然后# 注意修改成自己的IP和端口号 gi…...

【 香橙派 AIpro评测】烧系统运行部署LLMS大模型跑开源yolov5物体检测并体验Jupyter Lab AI 应用样例(新手入门)
文章目录 一、引言⭐1.1下载镜像烧系统⭐1.2开发板初始化系统配置远程登陆💖 远程ssh💖查看ubuntu桌面💖 远程向日葵 二、部署LLMS大模型&yolov5物体检测⭐2.1 快速启动LLMS大模型💖拉取代码💖下载mode数据&#x…...

Azure Repos 仓库管理
从远端仓库克隆到本地 前提:本地要安装git,并且登录了账户 1.在要放这个远程仓库的路径下,打git 然后 git clone https://.. 如果要登录验证,那就验证下,点 generate git credentials,复制password 克隆完后,cd 到克隆的路径, 可以用 git branch -a //查看分…...

Day71 代码随想录打卡|回溯算法篇---全排列
题目(leecode T46): 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 方法:全排列是数学中的基础问题,也是回溯算法能解决的经典问题。全排列因为每个元素都会…...

开源科学工程技术软件
目录 0 参考链接 1 Silx 2 Klampt 3 参数化三维3D软件Dune 3D 4 GPS日志文件查看器GPXSee 5 三维3D软件Chili3D 6 集成电路设计软件XicTools 7 天文学软件Cosmonium 8 计算流体力学软件FluidX3D 9 点云处理软件CloudCompare 10 野外火灾建模软件WindNinja 11 电子设…...

甄选范文“论软件维护方法及其应用”软考高级论文,系统架构设计师论文
论文真题 软件维护是指在软件交付使用后,直至软件被淘汰的整个时间范围内,为了改正错误或满足 新的需求而修改软件的活动。在软件系统运行过程中,软件需要维护的原因是多种多样的, 根据维护的原因不同,可以将软件维护分为改正性维护、适应性维护、完善性维护和预防性 维护…...

【服务器】端口映射
文章目录 1.端口映射的概念1.1 端口映射的类型1.2 端口映射的应用场景1.3 示例 2.为什么要进行端口映射呢?3.原理3.1【大白话】原理解释3.2 原理图 4.代码 1.端口映射的概念 端口映射(Port Mapping),也称为端口转发(P…...

HTC 10 刷系统 LineageOS 19.1 Android 12
解锁手机 解锁或导致数据全部清除,注意保存 Bootloader解锁,S-ON可以不用解锁(好像可以绕过解锁安装twrp,暂时没尝试) HTC 官方 Unlock Bootloader HTC Desire 20 pro 可以不通过官方网站解锁 adb reboot bootload…...

访问者模式(Visitor Pattern)
访问者模式(Visitor Pattern) 定义 访问者模式(Visitor Pattern) 表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作。 该模式的主要思想是将作用于某种数据结构中的各…...

mac如何查看cpu和显卡温度
在Mac上查看CPU和显卡温度,你可以使用以下几种方法: 方法1:使用内建工具“活动监视器” 虽然“活动监视器”不能直接显示温度信息,但它可以显示CPU使用情况等信息。 打开“活动监视器”,可以通过以下路径找到&#…...

MongoDB教程(六):mongoDB复制副本集
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 文章目录 引言一、MongoD…...

牛客小白月赛98 (个人题解)(补全)
前言: 昨天晚上自己一个人打的小白月赛(因为准备数学期末已经写烦了),题目难度感觉越来越简单了(不在像以前一样根本写不了一点,现在看题解已经能看懂一点了),能感受到自己在不断进步…...

Ubuntu压缩解压各类型文件
在Ubuntu系统中,解压不同格式的压缩文件可能需要安装不同的工具。以下是一些常见的压缩格式和相应的安装命令: ZIP文件: 工具:unzip 安装命令: sudo apt install unzip 解压命令 unzip filename.zip 如果需要保留目录…...

昇思学习打卡-20-生成式/GAN图像生成
文章目录 网络介绍生成器和判别器的博弈过程数据集可视化模型细节训练过程网络优缺点优点缺点 网络介绍 GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。 GAN模型的核心在于提出了通过对抗过程来估计生成模型这一全新框架。在这个…...

javafx、node js、socket、OpenGL多线程
机器学习、算法、人工智能、汇编(mips、arm、8086)、操作系统、数据挖掘、编译原理、计算机网络、Arena软件、linux xv6、racket、shell、Linux、PHP、Haskell、Scala、spark、UML、mathematica、GUI、javafx、node js、socket、OpenGL、多线程、qt、数据…...

【学习笔记】无人机(UAV)在3GPP系统中的增强支持(七)-通过无人机实现无线接入的独立部署
引言 本文是3GPP TR 22.829 V17.1.0技术报告,专注于无人机(UAV)在3GPP系统中的增强支持。文章提出了多个无人机应用场景,分析了相应的能力要求,并建议了新的服务级别要求和关键性能指标(KPIs)。…...

模糊综合评价
对多因素影响的事务的评价(如人才,方案,成果),有时难以给出影响的确切表达,此时可以采取模糊综合评价的方法。 该方法可以对人,事,物进行比较全面而又定量化的评价。 实例1ÿ…...

系统测试-白盒测试学习
目录 1、语句覆盖法: 2、判定覆盖法: 3、条件覆盖法: 4、判定条件覆盖: 5、条件组合的覆盖: 6、路径覆盖: 黑盒:需求 白盒:主要用于单元测试 1、语句覆盖法: 程序…...

UI设计工具选择指南:Sketch、XD、Figma、即时设计
在数字产品设计产业链中,UI设计师往往起着连接前后的作用。产品经理从一个“需求”开始,制定一个抽象的产品概念原型。UI设计师通过视觉呈现将抽象概念具体化,完成线框图交互逻辑视觉用户体验,最终输出高保真原型,并将…...
)
IT工程/项目计划概要~项目结束表(模版)
项目计划概要Ⅰ)项目启动(PROJECT INITIATION)1.EXCO(Executive Committee)审批2.已确认的意向书(Consent Letter)3.预风险评估4.合同(Contract)签署确认5.行业合规(Compliance)文档6.项目启动表7.项目章程签署确认Ⅱ)项目计划8.业…...

深入解析Android ContentProvider:从基础到高级应用与面试准备
引言 在Android开发中,数据共享和访问控制是构建高效、安全应用的关键。ContentProvider作为Android四大组件之一,专门用于管理结构化数据的共享,提供标准化的接口供应用间安全访问数据。本文将以ContentProvider为核心领域,全面探讨其原理、实现、应用及面试常见问题。文…...
)
免费额度哪家强?ESP32玩家实测八大国产大模型API(含通义千问、Kimi、DeepSeek)
ESP32开发者指南:八大国产大模型API横向评测与实战选型 当ESP32遇上大语言模型,会擦出怎样的火花?在物联网设备上直接运行AI交互功能,已经成为越来越多开发者的新选择。但面对众多国产大模型API,如何选择最适合ESP32项…...

效率翻倍!OrCAD Capture CIS创建复杂元器件库的实战技巧:LM358与多Part器件管理
效率翻倍!OrCAD Capture CIS创建复杂元器件库的实战技巧:LM358与多Part器件管理 在电子设计领域,元器件库的管理水平直接影响设计效率。许多工程师在使用OrCAD Capture CIS时,面对LM358这类多Part器件或更复杂的异构元件时&#x…...

RT-Thread Studio开发RA2L1:从环境搭建到GPIO输入输出实战
1. 项目概述与核心价值最近在捣鼓瑞萨电子的RA2L1 MCU开发板,想基于RT-Thread Studio这个国产IDE快速上手。我发现很多朋友拿到一块新板子,第一步“点亮LED”或者“读取按键”这个看似简单的操作,往往就卡在了环境搭建上。网上的资料要么过于…...

别再纠结软件IIC了!用STM32硬件IIC驱动0.96寸OLED,实测代码稳定不掉线
从软件IIC到硬件IIC:STM32驱动OLED的终极稳定方案 在嵌入式开发中,OLED显示屏因其高对比度、低功耗和快速响应等优势,成为许多项目的首选显示设备。然而,许多开发者在使用STM32驱动OLED时,往往会遇到通信不稳定、显示闪…...

S32K3 FlexCAN驱动避坑指南:从波特率计算到邮箱锁定的实战心得
S32K3 FlexCAN驱动避坑指南:从波特率计算到邮箱锁定的实战心得 在嵌入式开发领域,CAN总线通信一直是工业控制、汽车电子等实时系统的核心命脉。NXP S32K3系列芯片集成的FlexCAN模块以其强大的功能和灵活性,成为许多高可靠性项目的首选方案。然…...
 ---- Memory(记忆))
Spring AI Alibaba零基础速成(5) ---- Memory(记忆)
大模型默认只能单轮对话,每次对话完成后就会丢失当前对话记忆,我们之前了解过可以通过AssistantMessage把大模型回复结果存储起来下次提问时在发送给大模型,不过使用过于麻烦和受限,Spring AI 和Spring AI Alibaba都实现了更好实现…...

Performance Fish深度解析:如何通过四级缓存架构实现《环世界》400%性能优化
Performance Fish深度解析:如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance Fish是一款专为《环世界》&#x…...

HC7251晨芯阳科技内置MOS开关降压型LED恒流驱动器
HC7251是一款内置60V功率MOS 高效率、高精度的开关降压型大功率LED 恒流驱动芯片。HC7251采用固定关断时间的峰值电流控制方式,关断时间可通过外部电容进行调节,工作频率可根据用户要求而改变。HC7251通过调节外置的电流采样电阻,能控制高亮度…...