机器学习入门【经典的CIFAR10分类】
模型
神经网络采用下图

我使用之后发现迭代多了之后一直最高是正确率65%左右,然后我自己添加了一些Relu激活函数和正则化,现在正确率可以有80%左右。
模型代码
import torch
from torch import nnclass YmModel(nn.Module):def __init__(self):super(YmModel, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 64),nn.ReLU(),nn.Dropout(0.5),nn.Linear(64, 10),)def forward(self, x):return self.model(x)训练
有一点要说明的是,数据集中并没有验证集,你可以从训练集扣个1w张出来
import torch
import torchvision
from torchvision import transformsfrom models.YMModel import YmModel
from torch.utils.data import DataLoadertransform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])# 数据集
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform_train, download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64)
print(len(train_loader), len(test_loader))print(len(train_dataset), len(test_dataset))model = YmModel()
#迭代次数
train_epochs = 300
#优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 损失函数
loss_fn = torch.nn.CrossEntropyLoss()train_epochs_step = 0
best_accuracy = 0.for epoch in range(train_epochs):model.train()print(f'Epoch is {epoch}')for images, labels in train_loader:outputs = model(images)loss = loss_fn(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if train_epochs_step % 100 == 0:print(f'Train_Epoch is {train_epochs_step}\t Loss is {loss.item()}')train_epochs_step += 1train_epochs_step = 0with torch.no_grad():loss_running_total = 0.acc_running_total = 0.for images, labels in test_loader:outputs = model(images)loss = loss_fn(outputs, labels)loss_running_total += loss.item()acc_running_total += (outputs.argmax(1) == labels).sum().item()acc_running_total /= len(test_dataset)if acc_running_total > best_accuracy:best_accuracy = acc_running_totaltorch.save(model.state_dict(), './best_model.pth')print('accuracy is {}'.format(acc_running_total))print('total loss is {}'.format(loss_running_total))print('best accuracy is {}'.format(best_accuracy))验证
import osimport numpy as np
import torch
import torchvision
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transformsfrom models.TestColor import TextColor
from models.YMModel import YmModeltest_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)classes = ('airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')
model = YmModel()model.load_state_dict(torch.load('best_model.pth'))model.eval()
with torch.no_grad():correct = 0.for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs, 1)correct += (predicted == labels).sum().item()print('Accuracy : {}'.format(100 * correct / len(test_dataset)))
folder_path = './images'
files_names = os.listdir(folder_path)
transform_test = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),
])for file_name in files_names:image_path = os.path.join(folder_path, file_name)image = Image.open(image_path)image = transform_test(image)image = np.reshape(image, [1, 3, 32, 32])output = model(image)_, predicted = torch.max(output, 1)source_name = os.path.splitext(file_name)[0]predicted_class = classes[predicted.item()]colors = TextColor.GREEN if predicted_class == source_name else TextColor.REDprint(f"Source is {TextColor.BLUE}{source_name}{TextColor.RESET}, and predicted is {colors}{predicted_class}{TextColor.RESET}")结果
TextColor是自定义字体颜色的类,
image中就是自己的图片。
结果如下:测试集的正确率有82.7%

相关文章:
机器学习入门【经典的CIFAR10分类】
模型 神经网络采用下图 我使用之后发现迭代多了之后一直最高是正确率65%左右,然后我自己添加了一些Relu激活函数和正则化,现在正确率可以有80%左右。 模型代码 import torch from torch import nnclass YmModel(nn.Module):def __init__(self):super(…...

01 安装
安装和卸载中,用户全部切换为root,一旦安装,普通用户也能使用 初期不进行用户管理,全部用root进行,使用mysql语句 1. 卸载内置环境 检查是否有mariadb存在,存在走a部分卸载 ps axj | grep mysql ps ajx |…...

AI 模型本地推理 - YYPOLOE - Python - Windows - GPU - 吸烟检测(目标检测)- 有配套资源直接上手实现
Python 运行 - GPU 推理 - windows 环境准备python 代码 环境准备 FastDeploy预编译库下载 conda config --add channels conda-forge && conda install cudatoolkit11.2 cudnn8.2 pip install fastdeploy_gpu_python-0.0.0-cp38-cp38-win_amd64.whlpython 代码 impo…...

全国媒体邀约,主流媒体到场出席采访报道
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 全国媒体邀约,确保主流媒体到场出席采访报道,可以带来一系列的好处,这些好处不仅能够增强活动的可见度,还能对品牌或组织的长期形象产生积…...

计算机视觉8 图像增广
图像增广(image augmentation)是通过对训练图像进行一系列随机改变,从而产生相似但又不同的训练样本的技术。 图像增广有以下两个主要作用: 扩大训练数据集的规模;随机改变训练样本可以降低模型对某些属性的依赖&#…...
Transformer中的自注意力是怎么实现的?
在Transformer模型中,自注意力(Self-Attention)是核心组件,用于捕捉输入序列中不同位置之间的关系。自注意力机制通过计算每个标记与其他所有标记之间的注意力权重,然后根据这些权重对输入序列进行加权求和,…...
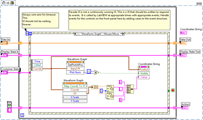
LabVIEW鼠标悬停在波形图上的曲线来自动显示相应点的坐标
步骤 创建事件结构: 打开LabVIEW,创建一个新的VI。 在前面板上添加一个Waveform Graph控件。 在后面板上添加一个While Loop和一个事件结构(Event Structure)。 配置事件结构,选择Waveform Graph作为事件源…...

操作系统发展简史(Unix/Linux 篇 + DOS/Windows 篇)+ Mac 与 Microsoft 之风云争霸
操作系统发展简史(Unix/Linux 篇) 说到操作系统,大家都不会陌生。我们天天都在接触操作系统 —— 用台式机或笔记本电脑,使用的是 windows 和 macOS 系统;用手机、平板电脑,则是 android(安卓&…...

钡铼分布式 IO 系统 OPC UA边缘计算耦合器BL205
深圳钡铼技术推出的BL205耦合器支持OPC UA Server功能,以服务器形式对外提供数据。符合IEC 62541工业自动化统一架构通讯标准,数据可以选择加密(X.509证书)、身份验证方式传送。 安全策略支持basic128rsa15、basic256、basic256s…...

实现了一个心理测试的小程序,微信小程序学习使用问题总结
1. 如何在跳转页面中传递参数 ,在 onLoad 方法中通过 options 接收 2. radio 如何获取选中的值? bindchange 方法 参数e, e.detail.value 。 如果想要获取其他属性,使用data-xx 指定,然后 e.target.dataset.xx 获取。 3. 不刷…...

vue是如何进行监听数据变化的?vue2和vue3分别是什么?vue3为什么要更换?
Vue如何进行监听数据变化的? Vue.js 通过其响应式系统来监听数据变化。这个系统允许你声明式地将数据和 DOM 绑定,一旦数据发生变化,相关的 DOM 将自动更新。Vue 使用以下机制来实现数据的监听和响应: 响应式数据:在 …...

数据结构day3
一、思维导图 二、 #include "seqlist.h"#include<myhead.h> int main(int argc, const char *argv[]) {//创建一个顺序表SeqListPtr L list_create();if(NULL L){return -1;}//调用添加函数list_add(L,123);list_add(L,435);list_add(L,856);list_add(L,65…...

免费的数字孪生平台助力产业创新,让新质生产力概念有据可依
关于新质生产力的概念,在如今传统企业现代化发展中被反复提及。 那到底什么是新质生产力?它与哪些行业存在联系,我们又该使用什么工具来加快新质生产力的发展呢?今天我将介绍一款为发展新质生产力而量身定做的数字孪生工具。 新…...

mtsys2 编译 qemu 记录
参考链接 下载 MSYS2 MSYS2 MSYS2 换源 进入目录\msys64\etc\pacman.d, 在文件mirrorlist.msys的前面插入 Server http://mirrors.ustc.edu.cn/msys2/msys/$arch在文件mirrorlist.mingw32的前面插入 Server http://mirrors.ustc.edu.cn/msys2/mingw/i686在…...

【Python数据分析】数据分析三剑客:NumPy、SciPy、Matplotlib中常用操作汇总
文章目录 NumPy常见操作汇总SciPy常见操作汇总Matplotlib常见操作汇总官方文档链接NumPy常见操作汇总 在Python的NumPy库中,有许多常用的知识点,这里列出了一些核心功能和常见操作: 类别函数或特性描述基础操作np.array创建数组np.shape获取数组形状np.dtype查看数组数据类…...

STM32智能家居电力管理系统教程
目录 引言环境准备智能家居电力管理系统基础代码实现:实现智能家居电力管理系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:电力管理与优化问题解决方案与优化收尾与总结 1. 引言 智能家居电…...

C# 邮件发送
创建邮件类 // 有static时候 类名,方法名// MyEmail.方法名/// <summary>/// 给目标发送邮箱/// </summary>/// <param name"maiTo"></param>/// <param name"title"></param>/// <param name"con…...

Kotlin 协程简化回调
suspend 和 suspendCoroutine 实现 suspendCoroutine函数必须在协程作用域或挂起函数中才能调用,它接收一个Lambda表达式参数,主要作用是将当前协程立即挂起,然后在一个普通的线程中执行Lambda表达式中的代码。Lambda表达式的参数列表上会传…...
及Python和MATLAB实现)
帝王蝶算法(EBOA)及Python和MATLAB实现
帝王蝶算法(Emperor Butterfly Optimization Algorithm,简称EBOA)是一种启发式优化算法,灵感来源于蝴蝶群体中的帝王蝶(Emperor Butterfly)。该算法模拟了帝王蝶群体中帝王蝶和其他蝴蝶之间的交互行为&…...

【学术会议征稿】第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024)
第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024) 2024 6th International Conference on Frontier Technologies of Information and Computer 第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024)将在中国青岛举行,会期是2024年11月8-10日,为…...
)
从90%到99%:实战提升Tesseract在C++项目中的识别准确率(附调参技巧)
从90%到99%:实战提升Tesseract在C项目中的识别准确率(附调参技巧) 在工业级文档处理系统中,我们常遇到这样的困境:测试集上的OCR识别准确率卡在90%左右,而业务部门要求必须达到99%以上才能上线。去年负责某…...

如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南
如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界…...
)
宠物领养|基于SprinBoot+vue的宠物领养管理系统(源码+数据库+文档)
宠物领养系统 目录 基于Spring Boot的宠物领养系统的设计与实现 一、前言 二、系统设计 三、系统功能设计 1前台 1.1 宠物领养 1.2 宠物认领 1.3 教学视频 2后台 2.1宠物领养管理 2.2 宠物领养审核管理 2.3 宠物认领管理 2.4 宠物认领审核管理 2.5 教学视频管理…...

从登录到支付:手把手教你用RSA签名验签保护Spring Boot API接口安全
从登录到支付:Spring Boot API接口的RSA签名验签实战指南 在数字化业务高速发展的今天,API接口安全已成为系统设计的核心议题。想象这样一个场景:用户通过移动端提交登录请求,黑客在传输过程中篡改了密码字段;或是支付…...

负载均衡器类型与配置
硬件负载均衡器硬件负载均衡器通常由专用设备提供,例如F5 BIG-IP、Citrix ADC等。这些设备提供高性能和稳定性,适合大型企业和高流量场景。软件负载均衡器软件负载均衡器包括Nginx、LVS、HAProxy、Kong和SLB等。它们分为L7层和L4层负载均衡器。L7层负载均…...

HTTP自适应流媒体技术解析:从HLS/DASH原理到实战部署
1. 流媒体技术演进:从“下载后播放”到“自适应缓冲”每天我们打开手机或电脑,点开一个视频,看到那个旋转的加载圈,心里总会咯噔一下。这个被称为“缓冲”的现象,早已成为数字生活的一部分。但你是否想过,为…...

老旧电视焕发新生:MyTV-Android开源直播应用完整指南
老旧电视焕发新生:MyTV-Android开源直播应用完整指南 【免费下载链接】mytv-android 使用Android原生开发的视频播放软件 项目地址: https://gitcode.com/gh_mirrors/my/mytv-android 你是否还在为家中老旧智能电视无法安装现代直播应用而烦恼?那…...

LDO噪声特性分析与测量优化指南
1. LDO噪声特性与测量基础低噪声线性稳压器(LDO)作为电源管理系统的核心器件,其噪声特性直接影响着精密模拟电路、射频系统和传感器等关键模块的性能表现。与开关电源不同,LDO通过线性调节方式工作,避免了高频开关噪声…...

CANN/ops-nn自适应层归一化算子
AdaLayerNorm 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DTAtlas A3 训练系列产品/Atlas A3 推理系列产品√…...

CANN/asc-devkit:设置单核输出形状API
SetSingleOutputShape 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://g…...