Transformer中的自注意力是怎么实现的?
在Transformer模型中,自注意力(Self-Attention)是核心组件,用于捕捉输入序列中不同位置之间的关系。自注意力机制通过计算每个标记与其他所有标记之间的注意力权重,然后根据这些权重对输入序列进行加权求和,从而生成新的表示。下面是实现自注意力机制的代码及其详细说明。
自注意力机制的实现
1. 计算注意力得分(Scaled Dot-Product Attention)
自注意力机制的基本步骤包括以下几个部分:
- 线性变换:将输入序列通过三个不同的线性变换层,得到查询(Query)、键(Key)和值(Value)矩阵。
- 计算注意力得分:通过点积计算查询与键的相似度,再除以一个缩放因子(通常是键的维度的平方根),以稳定梯度。
- 应用掩码:在计算注意力得分后,应用掩码(如果有),避免未来信息泄露(用于解码器中的自注意力)。
- 计算注意力权重:通过softmax函数将注意力得分转换为概率分布。
- 加权求和:使用注意力权重对值进行加权求和,得到新的表示。
2. 多头注意力机制(Multi-Head Attention)
为了捕捉不同子空间的特征,Transformer使用多头注意力机制。通过将查询、键和值分割成多个头,每个头独立地计算注意力,然后将所有头的输出连接起来,并通过一个线性层进行组合。
自注意力机制代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F# Scaled Dot-Product Attention
def scaled_dot_product_attention(query, key, value, mask=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))print(f"Scores shape: {scores.shape}") # (batch_size, num_heads, seq_length, seq_length)if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))attention_weights = F.softmax(scores, dim=-1)print(f"Attention weights shape: {attention_weights.shape}") # (batch_size, num_heads, seq_length, seq_length)output = torch.matmul(attention_weights, value)print(f"Output shape after attention: {output.shape}") # (batch_size, num_heads, seq_length, d_k)return output, attention_weights# Multi-Head Attention
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_headsself.linear_query = nn.Linear(d_model, d_model)self.linear_key = nn.Linear(d_model, d_model)self.linear_value = nn.Linear(d_model, d_model)self.linear_out = nn.Linear(d_model, d_model)def forward(self, query, key, value, mask=None):batch_size = query.size(0)# Linear projectionsquery = self.linear_query(query)key = self.linear_key(key)value = self.linear_value(value)print(f"Query shape after linear: {query.shape}") # (batch_size, seq_length, d_model)print(f"Key shape after linear: {key.shape}") # (batch_size, seq_length, d_model)print(f"Value shape after linear: {value.shape}") # (batch_size, seq_length, d_model)# Split into num_headsquery = query.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)key = key.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)value = value.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)print(f"Query shape after split: {query.shape}") # (batch_size, num_heads, seq_length, d_k)print(f"Key shape after split: {key.shape}") # (batch_size, num_heads, seq_length, d_k)print(f"Value shape after split: {value.shape}") # (batch_size, num_heads, seq_length, d_k)# Apply scaled dot-product attentionx, attention_weights = scaled_dot_product_attention(query, key, value, mask)# Concatenate headsx = x.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)print(f"Output shape after concatenation: {x.shape}") # (batch_size, seq_length, d_model)# Final linear layerx = self.linear_out(x)print(f"Output shape after final linear: {x.shape}") # (batch_size, seq_length, d_model)return x, attention_weights# 示例用法
d_model = 512
num_heads = 8
batch_size = 64
seq_length = 10# 假设输入是随机生成的张量
query = torch.rand(batch_size, seq_length, d_model)
key = torch.rand(batch_size, seq_length, d_model)
value = torch.rand(batch_size, seq_length, d_model)# 创建多头注意力层
mha = MultiHeadAttention(d_model, num_heads)
output, attention_weights = mha(query, key, value)print("最终输出形状:", output.shape) # 最终输出形状: (batch_size, seq_length, d_model)
print("注意力权重形状:", attention_weights.shape) # 注意力权重形状: (batch_size, num_heads, seq_length, seq_length)
每一步的形状解释
-
Linear Projections:
- Query, Key, Value分别经过线性变换。
- 形状:[batch_size, seq_length, d_model]
-
Split into Heads:
- 将Query, Key, Value分割成多个头。
- 形状:[batch_size, num_heads, seq_length, d_k],其中d_k = d_model // num_heads
-
Scaled Dot-Product Attention:
- 计算注意力得分(Scores)。
- 形状:[batch_size, num_heads, seq_length, seq_length]
- 计算注意力权重(Attention Weights)。
- 形状:[batch_size, num_heads, seq_length, seq_length]
- 使用注意力权重对Value进行加权求和。
- 形状:[batch_size, num_heads, seq_length, d_k]
-
Concatenate Heads:
- 将所有头的输出连接起来。
- 形状:[batch_size, seq_length, d_model]
-
Final Linear Layer:
- 通过一个线性层将连接的输出转换为最终的输出。
- 形状:[batch_size, seq_length, d_model]
通过这种方式,我们可以清楚地看到每一步变换后的张量形状,理解自注意力和多头注意力机制的具体实现细节。
代码说明
- scaled_dot_product_attention:实现了缩放点积注意力机制,计算查询和键的点积,应用掩码,计算softmax,然后使用权重对值进行加权求和。
- MultiHeadAttention:实现了多头注意力机制,包括线性变换、分割、缩放点积注意力和最后的线性变换。
多头注意力机制的细节
- 线性变换:将输入序列通过线性层转换为查询、键和值的矩阵。
- 分割头:将查询、键和值的矩阵分割为多个头,每个头的维度是[batch_size, num_heads, seq_length, d_k]。
- 缩放点积注意力:对每个头分别计算缩放点积注意力。
- 连接头:将所有头的输出连接起来,得到[batch_size, seq_length, d_model]的张量。
- 线性变换:通过一个线性层将连接的输出转换为最终的输出。
相关文章:
Transformer中的自注意力是怎么实现的?
在Transformer模型中,自注意力(Self-Attention)是核心组件,用于捕捉输入序列中不同位置之间的关系。自注意力机制通过计算每个标记与其他所有标记之间的注意力权重,然后根据这些权重对输入序列进行加权求和,…...
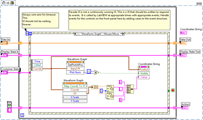
LabVIEW鼠标悬停在波形图上的曲线来自动显示相应点的坐标
步骤 创建事件结构: 打开LabVIEW,创建一个新的VI。 在前面板上添加一个Waveform Graph控件。 在后面板上添加一个While Loop和一个事件结构(Event Structure)。 配置事件结构,选择Waveform Graph作为事件源…...

操作系统发展简史(Unix/Linux 篇 + DOS/Windows 篇)+ Mac 与 Microsoft 之风云争霸
操作系统发展简史(Unix/Linux 篇) 说到操作系统,大家都不会陌生。我们天天都在接触操作系统 —— 用台式机或笔记本电脑,使用的是 windows 和 macOS 系统;用手机、平板电脑,则是 android(安卓&…...

钡铼分布式 IO 系统 OPC UA边缘计算耦合器BL205
深圳钡铼技术推出的BL205耦合器支持OPC UA Server功能,以服务器形式对外提供数据。符合IEC 62541工业自动化统一架构通讯标准,数据可以选择加密(X.509证书)、身份验证方式传送。 安全策略支持basic128rsa15、basic256、basic256s…...

实现了一个心理测试的小程序,微信小程序学习使用问题总结
1. 如何在跳转页面中传递参数 ,在 onLoad 方法中通过 options 接收 2. radio 如何获取选中的值? bindchange 方法 参数e, e.detail.value 。 如果想要获取其他属性,使用data-xx 指定,然后 e.target.dataset.xx 获取。 3. 不刷…...

vue是如何进行监听数据变化的?vue2和vue3分别是什么?vue3为什么要更换?
Vue如何进行监听数据变化的? Vue.js 通过其响应式系统来监听数据变化。这个系统允许你声明式地将数据和 DOM 绑定,一旦数据发生变化,相关的 DOM 将自动更新。Vue 使用以下机制来实现数据的监听和响应: 响应式数据:在 …...

数据结构day3
一、思维导图 二、 #include "seqlist.h"#include<myhead.h> int main(int argc, const char *argv[]) {//创建一个顺序表SeqListPtr L list_create();if(NULL L){return -1;}//调用添加函数list_add(L,123);list_add(L,435);list_add(L,856);list_add(L,65…...

免费的数字孪生平台助力产业创新,让新质生产力概念有据可依
关于新质生产力的概念,在如今传统企业现代化发展中被反复提及。 那到底什么是新质生产力?它与哪些行业存在联系,我们又该使用什么工具来加快新质生产力的发展呢?今天我将介绍一款为发展新质生产力而量身定做的数字孪生工具。 新…...

mtsys2 编译 qemu 记录
参考链接 下载 MSYS2 MSYS2 MSYS2 换源 进入目录\msys64\etc\pacman.d, 在文件mirrorlist.msys的前面插入 Server http://mirrors.ustc.edu.cn/msys2/msys/$arch在文件mirrorlist.mingw32的前面插入 Server http://mirrors.ustc.edu.cn/msys2/mingw/i686在…...

【Python数据分析】数据分析三剑客:NumPy、SciPy、Matplotlib中常用操作汇总
文章目录 NumPy常见操作汇总SciPy常见操作汇总Matplotlib常见操作汇总官方文档链接NumPy常见操作汇总 在Python的NumPy库中,有许多常用的知识点,这里列出了一些核心功能和常见操作: 类别函数或特性描述基础操作np.array创建数组np.shape获取数组形状np.dtype查看数组数据类…...

STM32智能家居电力管理系统教程
目录 引言环境准备智能家居电力管理系统基础代码实现:实现智能家居电力管理系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:电力管理与优化问题解决方案与优化收尾与总结 1. 引言 智能家居电…...

C# 邮件发送
创建邮件类 // 有static时候 类名,方法名// MyEmail.方法名/// <summary>/// 给目标发送邮箱/// </summary>/// <param name"maiTo"></param>/// <param name"title"></param>/// <param name"con…...

Kotlin 协程简化回调
suspend 和 suspendCoroutine 实现 suspendCoroutine函数必须在协程作用域或挂起函数中才能调用,它接收一个Lambda表达式参数,主要作用是将当前协程立即挂起,然后在一个普通的线程中执行Lambda表达式中的代码。Lambda表达式的参数列表上会传…...
及Python和MATLAB实现)
帝王蝶算法(EBOA)及Python和MATLAB实现
帝王蝶算法(Emperor Butterfly Optimization Algorithm,简称EBOA)是一种启发式优化算法,灵感来源于蝴蝶群体中的帝王蝶(Emperor Butterfly)。该算法模拟了帝王蝶群体中帝王蝶和其他蝴蝶之间的交互行为&…...

【学术会议征稿】第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024)
第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024) 2024 6th International Conference on Frontier Technologies of Information and Computer 第六届信息与计算机前沿技术国际学术会议(ICFTIC 2024)将在中国青岛举行,会期是2024年11月8-10日,为…...

PHP MySQL 读取数据
PHP MySQL 读取数据 PHP和MySQL是Web开发中的经典组合,广泛用于创建动态网站和应用程序。在PHP中读取MySQL数据库中的数据是一项基本技能,涉及到连接数据库、执行查询以及处理结果集。本文将详细介绍如何使用PHP从MySQL数据库中读取数据。 1. 环境准备…...

点亮 LED-I.MX6U嵌入式Linux C应用编程学习笔记基于正点原子阿尔法开发板
点亮 LED 应用层操控硬件的两种方式 背景 Linux系统将所有内容视作文件,包括硬件设备,通过文件I/O方式与硬件交互 设备文件,如字符设备文件与块设备文件,是硬件设备提供给应用层的接口 应用层通过设备文件进行I/O操作ÿ…...

从0到1搭建数据中台(4):neo4j初识及安装使用
在数据中台中,neo4j作为图数据库,可以用于数据血缘关系的存储 图数据库的其他用于主要用于知识图谱,人物关系的搭建,描述实体,关系,以及实体属性 安装 在官网 https://neo4j.com/ 下载安装包 neo4j-co…...

【20】读感 - 架构整洁之道(二)
概述 继上一篇文章讲了前两章的读感,已经归纳总结的重点,这章会继续跟进的看一下,深挖架构整洁之道。 编程范式 编程范式从早期到至今,提过哪些编程范式,结构化编程,面向对象编程,函数式编程…...

js vue axios post 数组请求参数获取转换, 后端go参数解析(gin框架)全流程示例
今天介绍的是前后端分离系统中的请求参数 数组参数的生成,api请求发送,到后端请求参数接收的全过程示例。 为何会有这个文章:后端同一个API接口同时处理单条或者多条数据,这样就要求我们在前端发送请求参数的时候需要统一将请…...

FanControl深度解析:解锁Windows风扇控制的专业级配置哲学
FanControl深度解析:解锁Windows风扇控制的专业级配置哲学 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

《QGIS空间数据处理与高级制图》004:内置地理处理工具箱
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

Windows Cleaner:如何系统性地解决Windows磁盘空间管理难题
Windows Cleaner:如何系统性地解决Windows磁盘空间管理难题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款基于Python和PyQt5框…...
)
别再堆模型了!SITS 2026验证有效的AI运维成熟度评估矩阵(含6维度22项量化指标)
更多请点击: https://intelliparadigm.com 第一章:AI原生运维体系构建:SITS 2026智能运维专场精华 AI原生运维(AIOps Native)已从概念验证迈入生产就绪阶段。SITS 2026智能运维专场首次提出“感知-推理-执行-进化”四…...

Prometheus监控主机,Grafana成图
全部使用官方 GitHub 源的部署方案,下载链接来自官方,无需镜像。 官方下载地址汇总 组件 官方下载地址 Node Exporter https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz Prometheus https…...
:拷贝构造函数与深浅拷贝问题)
【c++面向对象编程】第4篇:类与对象(三):拷贝构造函数与深浅拷贝问题
目录 一、一个崩溃的程序 二、拷贝构造函数是什么? 调用时机(三个场景) 三、浅拷贝 vs 深拷贝 浅拷贝(默认行为) 深拷贝(正确的做法) 四、什么时候必须自己写拷贝构造函数? 一…...

企业如何通过Taotoken实现API密钥的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何通过Taotoken实现API密钥的统一管理与审计 在将大模型能力集成到企业业务流程的过程中,一个常见的挑战是如何安…...

FPGA加速中性原子量子计算机的原子检测技术
1. 中性原子量子计算机的原子检测挑战量子计算领域近年来最激动人心的进展之一,就是中性原子量子计算机的快速发展。这种量子计算机利用激光镊子(光学镊子)阵列来捕获和排列中性原子(如铷、铯等碱金属原子),…...

星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南
星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语模组加载器SMAPI是《星露谷物语》的官方模组API,为这款经典…...

第十一节:私有知识大脑——为本地 Agent 构建企业级 RAG 检索增强链路
引言 承接上一章我们对 embedding 和向量检索的实战部署,本章将聚焦打造私有知识大脑,通过构建完整的 RAG(Retrieval-Augmented Generation)检索增强链路,极大拓展本地 Agent 在企业场景的应用边界。 核心理论 RAG 是实现大模型实时访问和利用外部知识的关键技术,其数…...