stack_queue | priority_queue | 仿函数
文章目录
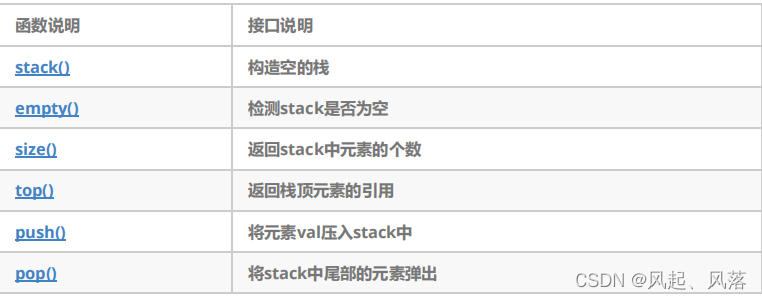
- 1. stack 的使用
- 2. stack的模拟实现
- 3. queue的使用
- 4. queue的模拟实现
- 5. deque ——双端队列
- deque优缺点
- 6. priority_queue ——优先级队列
- 1. priority_queue的使用
- 2. priority_queue的模拟实现
- push——插入
- pop ——删除
- top —— 堆顶
- 仿函数问题
- 完整代码实现
1. stack 的使用
栈不在是一个容器,而是一个容器适配器 ,
stack的模板中第二个deque暂时不知道干什么的,后面会说

说明stack是一个容器适配器,并且为了保证严格的先进后出,所以不存在迭代器
#include<iostream>
#include<stack>
using namespace std;int main()
{stack<int>v;v.push(1);v.push(2);v.push(3);v.push(4);while (!v.empty())//后进先出的原则{cout << v.top() << " ";//4 3 2 1v.pop();}return 0;
}
2. stack的模拟实现
#include<iostream>
#include<vector>
#include<list>
#include<stack>
#include<queue>
using namespace std;
namespace yzq
{//适配器模式template<class T, class Container = deque<T>>//给与缺省值//deque 作为一个双端队列,可以非常适用与大量 头插 头删 尾插 尾删 的情况class stack{public:void push(const T& x)//插入{_con.push_back(x);//尾插}void pop()//删除栈顶元素{_con.pop_back(); }const T& top()//栈顶{return _con.back();}size_t size()//大小{return _con.size();}bool empty()//判空{return _con.empty();}private:Container _con;//Container 是一个符合要求的容器};//适配器模式void test(){yzq::stack<int>v;v.push(1);v.push(2);v.push(3);v.push(4);while (!v.empty()){cout << v.top() << " ";v.pop();}cout << endl;}}这里假设我们不认识 deque,那么如果stack频繁使用pop尾删,将vector< T >设置成缺省值也是非常适合的
3. queue的使用

队列同样不在是一个容器,而是一个容器适配器

说明queue为了保证严格的先进先出,所以不存在迭代器

#include<iostream>
#include<stack>
#include<queue>
using namespace std;int main()
{queue<int>v;v.push(1);v.push(2);v.push(3);v.push(4);while (!v.empty())//符合先进先出的原则{cout << v.front() << " ";//1 2 3 4v.pop();}return 0;
}
4. queue的模拟实现
#pragma once
namespace yzq
{template<class T, class Container=deque<T>>//给与缺省值,默认使用list<T>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front(); //vector没有头删,强行使用erase 效率太低}const T& front(){return _con.front();}const T& back(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;//Container 是一个符合要求的容器};
}这里假设我们不认识 deque,那么如果stack频繁使用pop头删,将 list< T >设置成缺省值也是非常适合的
5. deque ——双端队列
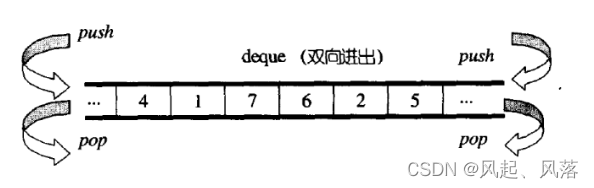
可以在头尾双端进行插入和删除的操作,且时间复杂度为O(1),与vetcor比较,头插效率高,不需要移动元素,
与list比较,空间利用比较高

而deque就是要综合两者的优点 (想法很美好)
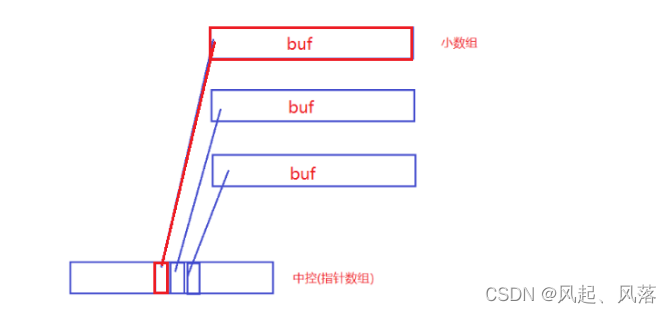
deque并不是真正的连续的空间,而是由一段段连续的小空间拼接而成的
一段段的小数组,若满了不扩容,在开辟一块空间,通过中控(指针数组)的方式将一个个小数组管理起来
第一个buf数组,开的是中控指针数组中间的位置
头插:
尾插:
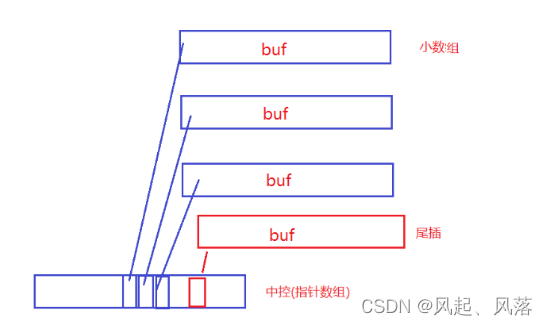
若中控满了,就要扩容,但是扩容代价低
若为vector,本来为100个int空间,需要200个空间,就需要扩容2倍
而 中控是一个指针数组,里面都是指针,可能只需要20个指针就搞定了,所以扩容代价相对于低一些
deque优缺点
优点:
1.相比于vector,扩容代价低
2. 头插 头删,尾插尾删效率高
3. 支持随机访问
缺点:
1.中间插入删除很难搞
若中间插入删除效率高,会影响随机访问的效率,牺牲中间插入删除的效率,随机访问效率就变高了
2.没有vector和list优点极致
deque你说它跟vector比随机访问,速度不如vector,跟list比任意位置插入删除,效率没list高 ,这种就搞的很难啦,哪一项都不突出,但是都会一点
栈和队列都是需要大量的头插头删,尾插尾删的,而deque在这个场景下效率很高,所以deque被当作栈和队列的默认适配容器
6. priority_queue ——优先级队列
1. priority_queue的使用

底层是一个堆,默认容器使用vector, 最后一个模板参数代表仿函数 默认使用 less 代表小于 (后面会讲)

#include<iostream>
#include<queue>
#include<functional>
using namespace std;
int main()
{priority_queue<int, vector<int>>v;//默认为大堆,数据大的优先级高v.push(4);v.push(8);v.push(6);v.push(2);while (!v.empty()){cout << v.top() << " "; //8 6 4 2v.pop();}return 0;
}
正常来说,默认建立大堆,所以数据大的优先级高
#include<iostream>
#include<queue>
#include<functional>
int main()
{priority_queue<int,vector<int>,greater<int>>v;//greater作为仿函数//设置小堆,让小的优先级高v.push(4);v.push(8);v.push(6);v.push(2);while (!v.empty()){cout << v.top() << " "; //2 4 6 8v.pop();}return 0;
}
但若加入仿函数 greater 后,则会建立小堆,所以数据小的优先级高
2. priority_queue的模拟实现
由于是自己实现的所以要加上命名空间,避免冲突
push——插入
void adjustup(int child)//向上调整算法{Compare com;int parent = (child - 1) / 2;while (child > 0){//建大堆if (com(_con[parent] ,_con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}
void push(const T&x){_con.push_back(x);adjustup(_con.size() - 1);//向上调整算法}
由于是堆的插入,而堆本身也是由数组的数据构成的,所以数组加入一个数据相当于在堆最后插入一个数据,在通过向上调整算法依次交换, 不懂向上调整算法的点击这里
pop ——删除
void adjustdown(int parent)//向下调整算法{Compare com;int child = parent * 2+1;//假设为左孩子while (child<_con.size()){//建大堆if (child+1 < _con.size()&&com(_con[child],_con[child + 1]))//child+1是防止右孩子不存在导致越界{child++;}if (com(_con[parent] ,_con[child]))//将两者换一种说法,使之能=能够调用<即可{swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}
void pop(){swap(_con[0], _con[_con.size() - 1]);//首尾交换_con.pop_back();//尾删adjustdown(0);//向下调整算法}
由于要删除堆顶的数据,所以交换堆尾与堆顶数据,在删除堆尾数据,默认容器为vector,所以有pop_back 尾删的功能,而此时堆顶的数据不符合当前的位置,所以需要借助向下调整算法把该数据调整到合适的位置 不懂向下调整算法的点击这里
top —— 堆顶
const T& top(){return _con[0];}
堆是借助数组来实现的,所以堆顶的数据就是当前的第一个数据
仿函数问题
template <class T>struct Less{bool operator()(const T& x, const T& y){return x < y;}};template <class T>struct greater{bool operator()(const T& x, const T& y){return x > y;}};
仿函数主要是借助两个类 来重载 运算符 ( ) ,
而 Less ( x<y) 用于 建立大堆 ,greater (x>y) 用于建立小堆
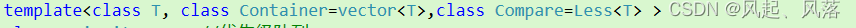
Less / greater 分别都是类名 ,而模板参数 Compare 需要类型
所以 都需要加上 ,即 Less< T> / greater < T >
通过该类型在向上/向下调整算法中分别建立对象,通过对象调用对应类less/greater的重载()从而达到目的

若为默认类型Less,则调用x <y ,从而建大堆
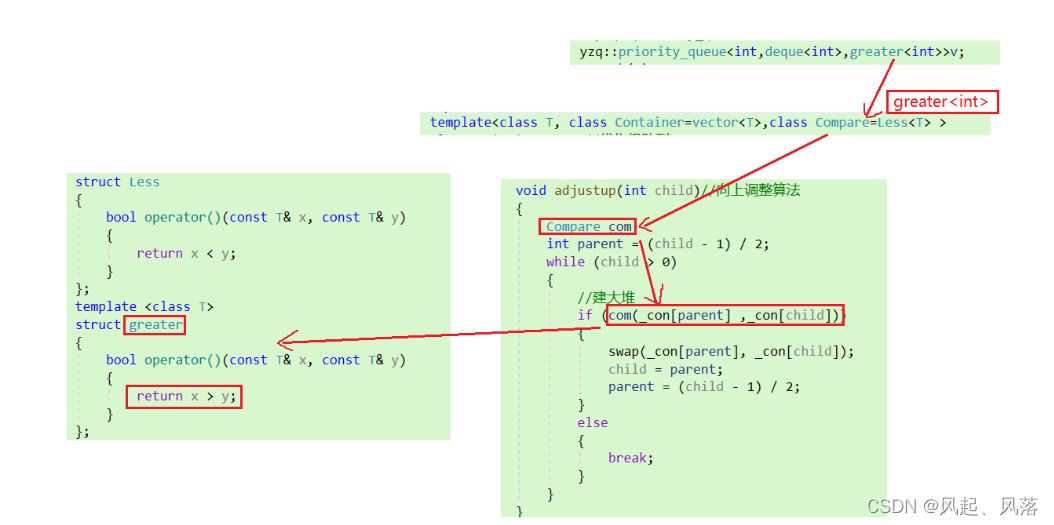
当传入greater< T >类型后,调用对象,找到对应greater类型的重载() ,调用 x >y ,从而建小堆
完整代码实现
#include<iostream>
#include<queue>
using namespace std;
namespace yzq
{template <class T>struct Less{bool operator()(const T& x, const T& y){return x < y;}};template <class T>struct greater{bool operator()(const T& x, const T& y){return x > y;}};template<class T, class Container=vector<T>,class Compare=Less<T> >class priority_queue//优先级队列{public:void adjustup(int child)//向上调整算法{Compare com;int parent = (child - 1) / 2;while (child > 0){//建大堆if (com(_con[parent] ,_con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjustdown(int parent)//向下调整算法{Compare com;int child = parent * 2+1;//假设为左孩子while (child<_con.size()){//建大堆if (child+1 < _con.size()&&com(_con[child],_con[child + 1]))//child+1是防止右孩子不存在导致越界{child++;}if (com(_con[parent] ,_con[child]))//将两者换一种说法,使之能=能够调用<即可{swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void push(const T&x){_con.push_back(x);adjustup(_con.size() - 1);//向上调整算法}void pop(){swap(_con[0], _con[_con.size() - 1]);//首尾交换_con.pop_back();//尾删adjustdown(0);//向下调整算法}const T& top(){return _con[0];}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;//使用vector实现};
}int main()
{//yzq::priority_queue<int>v;yzq::priority_queue<int,deque<int>,greater<int>>v;v.push(1);v.push(5);v.push(8);v.push(4);while (!v.empty()){cout << v.top() << " ";v.pop();}return 0;
}
相关文章:
stack_queue | priority_queue | 仿函数
文章目录1. stack 的使用2. stack的模拟实现3. queue的使用4. queue的模拟实现5. deque ——双端队列deque优缺点6. priority_queue ——优先级队列1. priority_queue的使用2. priority_queue的模拟实现push——插入pop ——删除top —— 堆顶仿函数问题完整代码实现1. stack 的…...
第十四届蓝桥杯三月真题刷题训练——第 14 天
目录 第 1 题:组队 题目描述 运行限制 代码: 第 2 题:不同子串 题目描述 运行限制 代码: 思路: 第 3 题:等差数列 题目描述 输入描述 输出描述 输入输出样例 运行限制 代码: 思…...
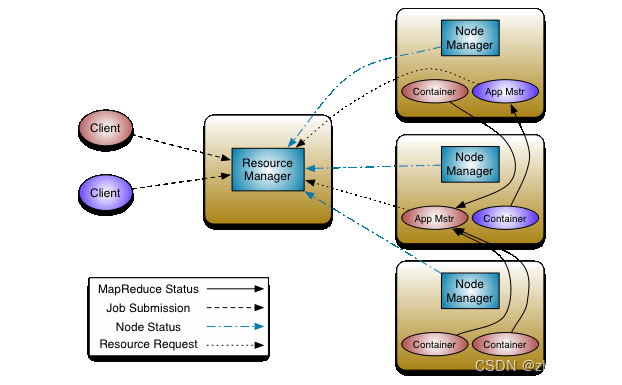
【Hadoop-yarn-01】大白话讲讲资源调度器YARN,原来这么好理解
YARN作为Hadoop集群的御用调度器,在整个集群的资源管理上立下了汗马功劳。今天我们用大白话聊聊YARN存在意义。 有了机器就有了资源,有了资源就有了调度。举2个很鲜活的场景: 在单台机器上,你开了3个程序,分别是A、B…...
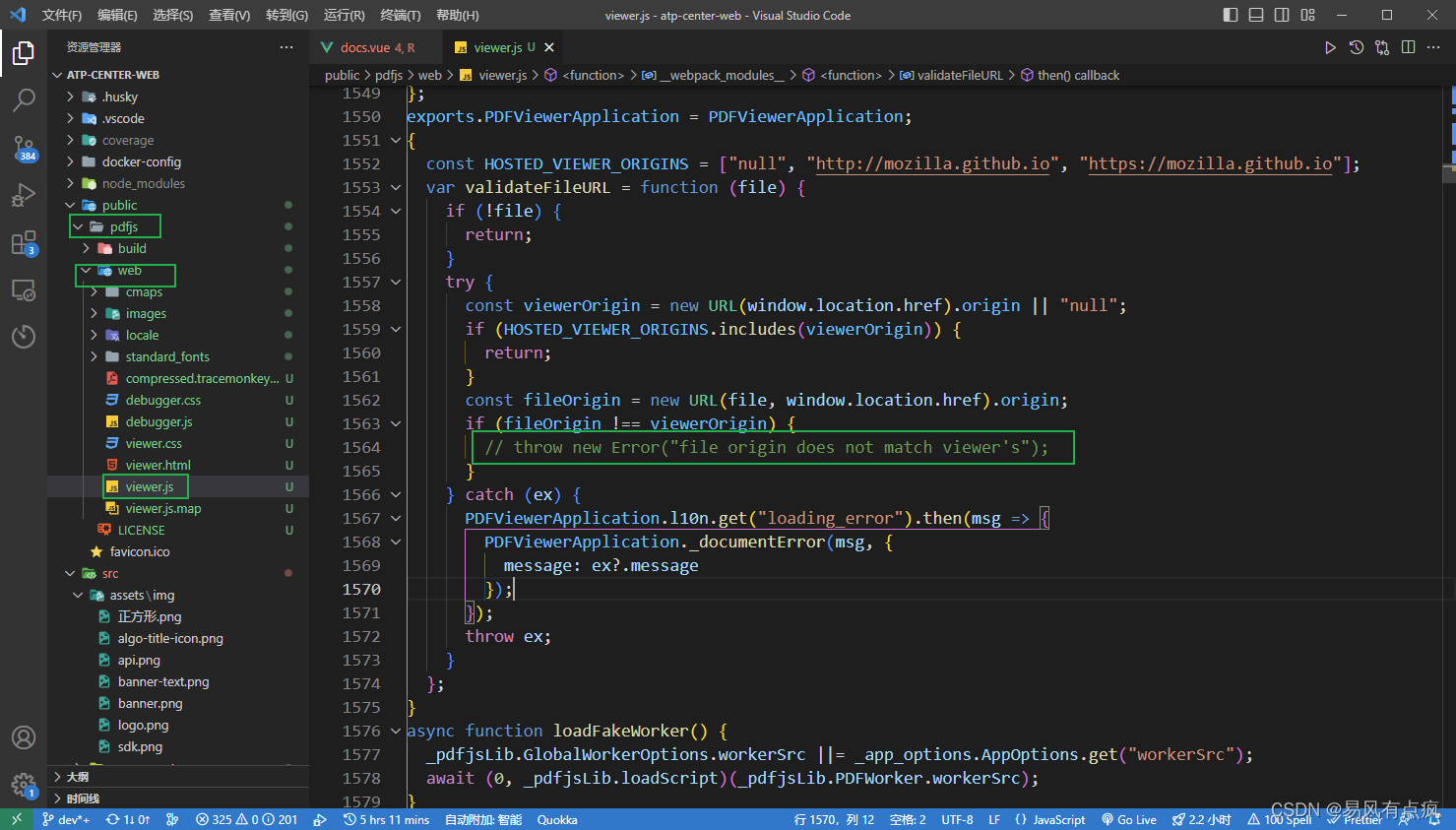
技术掉:PDF显示,使用pdf.js
PDF 显示 场景: 其实直接显示 pdf 可以用 iframe 标签,但产品觉得浏览器自带的 pdf 预览太丑了,而且无法去除那些操作栏。 解决方案:使用 pdf.js 进行显示 第一步:引入 pdf.js 去官网下载稳定版的 pdf.js 文件 然后…...
有关pytorch的一些总结
Tensor 含义 张量(Tensor):是一个多维数组,它是标量、向量、矩阵的高维拓展。 创建 非随机创建 1.用数组创建 将数组转化为tensor np.ones([a,b]) 全为1 #首先导入PyTorch import torch#数组创建 import numpy as np anp.arr…...
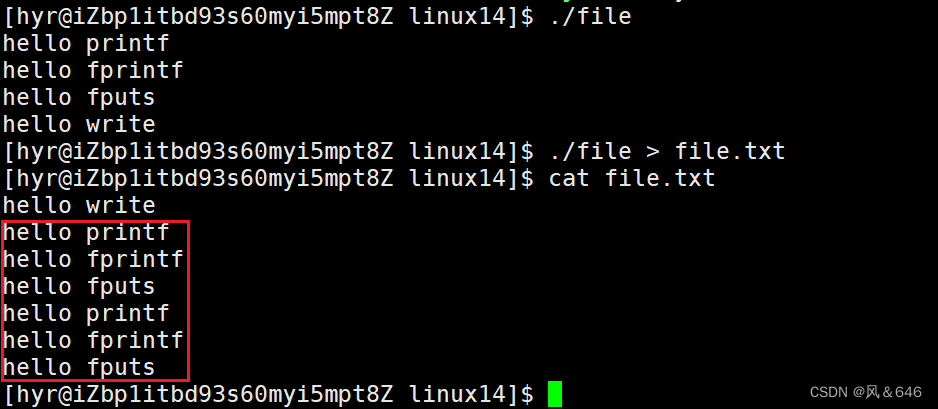
基础IO【Linux】
文章目录:文件相关知识C语言文件IOstdin & stdout & stderr系统文件 IOopenclosewriteread文件描述符文件描述符的分配规则重定向dup2系统调用FILEFILE中的文件描述符FILE中的缓冲区理解文件相关知识 文件 文件内容 文件属性(每一个已经存在的…...
Vue3——自定义封装上传图片样式
自定义封装上传图片样式 一、首先需要新建一个自组建完善基础的结构,我这里起名为ImgUpload.vue <el-upload name"file" :show-file-list"false" accept".png,.PNG,.jpg,.JPG,.jpeg,.JPEG,.gif,.GIF,.bmp,.BMP" :multiple"…...
ChatGLM-6B (介绍以及本地部署)
中文ChatGPT平替——ChatGLM-6BChatGLM-6B简介官方实例本地部署1.下载代码2.通过conda创建虚拟环境3.修改代码4.模型量化5.详细代码调用示例ChatGLM-6B 简介 ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构&…...
react的基础使用
react中为什么使用jsxReact 认为渲染逻辑本质上与其他 UI 逻辑内在耦合,比如,在 UI 中需要绑定处理事件、在某些时刻状态发生变化时需要通知到 UI,以及需要在 UI 中展示准备好的数据。react认为将业务代码和数据以及事件等等 需要和UI高度耦合…...

letcode 4.寻找两个正序数组的中位数(官方题解笔记)
题目描述 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 1.二分查找 1.1思路 时间复杂度:O(log(mn)) 空间复杂度:O(1) 给定…...
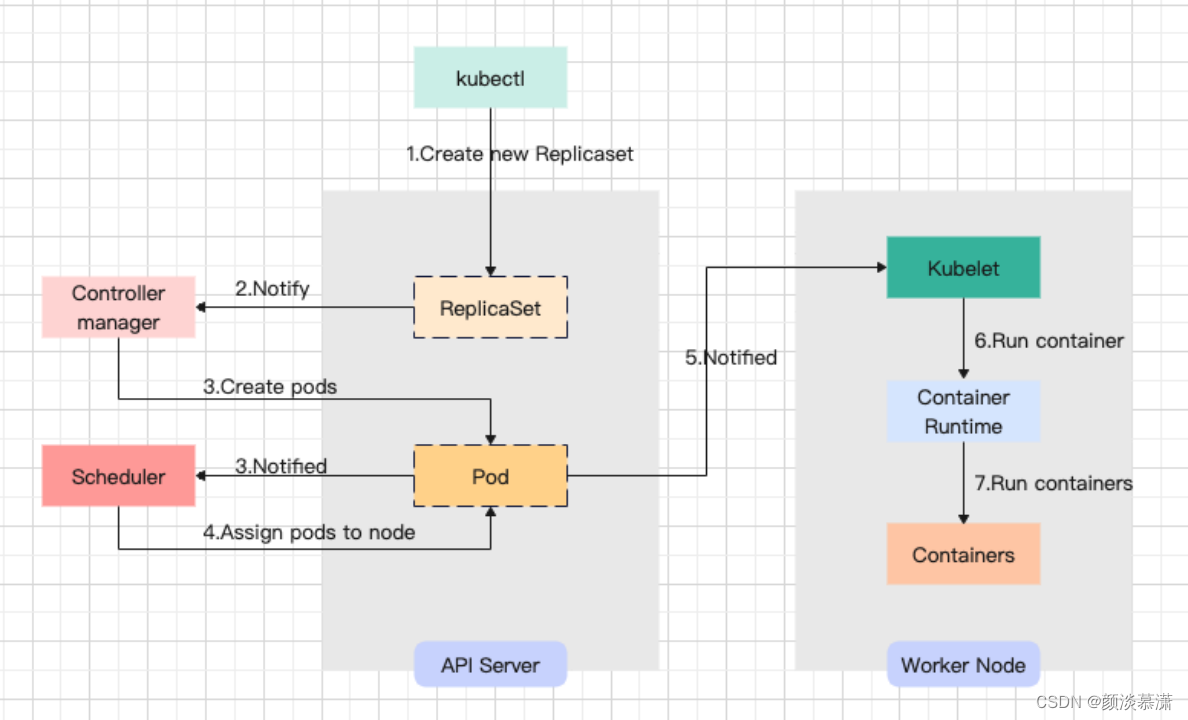
【面试题系列】K8S常见面试题
目录 序言 问题 1. 简单说一下k8s集群内外网络如何互通的吧 2.描述一下pod的创建过程 3. 描述一下k8s pod的终止过程 4.Kubernetes 中的自动伸缩有哪些方式? 5.Kubernetes 中的故障检测有哪些方式? 6.Kubernetes 中的资源调度有哪些方式ÿ…...

字符函数和字符串函数(上)-C语言详解
CSDN的各位友友们你们好,今天千泽为大家带来的是C语言中字符函数和字符串函数的详解,掌握了这些内容能够让我们更加灵活的运用字符串,接下来让我们一起走进今天的内容吧!写这篇文章需要在cplusplus.com上大量截图,十分不易!如果对您有帮助的话希望能够得到您的支持和帮助,我会持…...
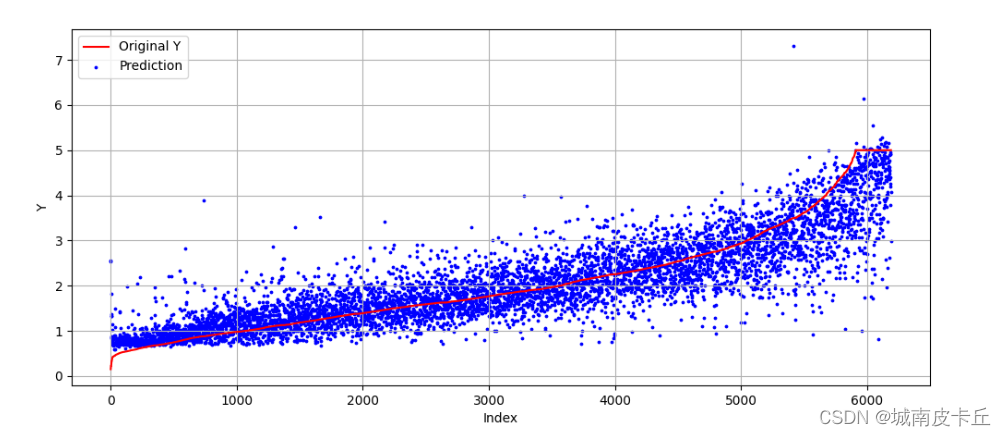
全连接神经网络
目录 1.全连接神经网络简介 2.MLP分类模型 2.1 数据准备与探索 2.2 搭建网络并可视化 2.3 使用未预处理的数据训练模型 2.4 使用预处理后的数据进行模型训练 3. MLP回归模型 3.1 数据准备 3.2 搭建回归预测网络 1.全连接神经网络简介 全连接神经网络(Multi-Layer Percep…...
深度学习目标检测ui界面-交通标志检测识别
深度学习目标检测ui界面-交通标志检测识别 为了将算法封装起来,博主尝试了实验pyqt5的上位机界面进行封装,其中遇到了一些坑举给大家避开。这里加载的训练模型参考之前写的博客: 自动驾驶目标检测项目实战(一)—基于深度学习框架yolov的交通…...

ubuntu不同版本的源(换源)(镜像源)(lsb_release -c命令,显示当前系统的发行版代号(Codename))
文章目录查看unbuntu版本名(lsb_release -c命令)各个版本源代号(仅供参考,具体代号用上面命令查)各版本软件源Ubuntu20.10阿里源:清华源:Ubuntu20.04阿里源:清华源:Ubunt…...

linux入门---程序翻译的过程
我们在vs编译器中写的代码按下ctrl f5就可以直接运行起来,并且会将运行的结果显示到显示器上,这里看上去只有一个步骤但实际上这里会存在很多的细节,比如说生成结果在这里插入代码片之前我们的代码会经过预处理,编译,汇…...
springboot复习(黑马)
学习目标基于SpringBoot框架的程序开发步骤熟练使用SpringBoot配置信息修改服务器配置基于SpringBoot的完成SSM整合项目开发一、SpringBoot简介1. 入门案例问题导入SpringMVC的HelloWord程序大家还记得吗?SpringBoot是由Pivotal团队提供的全新框架,其设计…...

C++指针详解
旧文更新:两三年的旧文了,一直放在电脑里,现在直接传上CSDN 一、指针的概念 1.1 指针 程序运行时每个变量都会有一块内存空间,变量的值就存放在这块空间中。程序可以通过变量名直接访问这块空间内的数据,这种访问方…...
tauri+vite+vue3开发环境下创建、启动运行和打包发布
目录 1.创建项目 2.安装依赖 3.启动项目 4.打包生成windows安装包 5.安装打包生成的安装包 1.创建项目 运行下面命令创建一个tauri项目 pnpm create tauri-app 我创建该项目时的node版本为16.15.0 兼容性注意 Vite 需要 Node.js 版本 14.18,16。然而&#x…...

安卓进阶系列-系统基础
文章目录计算机结构冯诺依曼结构哈弗结构冯诺依曼结构与哈弗结构对比安卓采用的架构安卓操作系统进程间通讯(IPC)内存共享linux内存共享安卓内存共享管道Unix Domain Socket同步常见同步机制信号量Mutex管程安卓同步机制安卓中的Mutex安卓中的ConditionB…...

RedBox容器编排工具:在Docker与K8s间的轻量级生产实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫Jamailar/RedBox。乍一看这个名字,你可能会联想到一个红色的盒子,或者某种特定的工具。实际上,它确实是一个“盒子”,一个用于构建、管理和部署容器化应用的…...

基于LLM的风格化内容生成:从提示工程到系统化实践
1. 项目概述:一个基于AI的创意内容生成工具最近在折腾AI应用开发,发现了一个挺有意思的项目,叫“jasonkneen/vibeclaw”。乍一看这个名字,可能会有点摸不着头脑,但简单来说,它是一个利用大型语言模型&#…...

基于物联网的泵车远程运维与主动服务解决方案
某设备制造商拥有大量在役泵车,分布在全国各地的基建工地和商混站。长期以来,售后服务团队面临着严峻的挑战:由于泵车多在户外流动作业、分布范围广,设备一旦发生故障,售后工程师需要千里奔波到现场才能判断问题&#…...

AD9361快速切频点秘籍:不用复杂计算,一张2400-2480MHz的查表配置表直接拿去用
AD9361射频芯片极速切频实战:2400-2480MHz预计算配置表与查表法优化 在Wi-Fi 6E和蓝牙5.3设备爆发式增长的今天,射频工程师每天需要处理数百次频段切换测试。传统AD9361配置流程中,每次切换频点都要重新计算VCO分频比、电荷泵电流等12个关键参…...
)
分享!关于虚拟机性能优化实战的技术文(进击篇 学习资料自提取)
一、 综述与基础理论类文献 (帮助构建背景和原理部分大纲) 虚拟化技术综述: 查找标题包含“虚拟化技术综述”、“虚拟化原理与发展”等关键词的中文学术论文或书籍章节。这些文献通常会涵盖CPU虚拟化、内存虚拟化、I/O虚拟化等核心技术,为理解性能瓶颈和…...

告别RAM焦虑:手把手教你用MicroBlaze BootLoader把大程序塞进QSPI Flash和DDR3
突破FPGA内存瓶颈:MicroBlaze大型程序加载实战指南 当你的MicroBlaze项目从简单的控制逻辑升级到需要文件系统、网络协议栈甚至实时操作系统时,代码体积的膨胀速度往往超出预期。那些曾经足够用的BRAM资源突然变得捉襟见肘——这就像试图在智能手机上运行…...

HubSpot如何通过联盟计划快速增长?内容驱动型联盟营销的成功案例解析
在 SaaS 获客成本(CAC)不断攀升的今天,HubSpot 的增长奇迹始终是行业研究的焦点。除了教科书级的「集客营销(Inbound Marketing)」,其 HubSpot Affiliate Program(联盟营销计划)更是…...

工业微功率DC-DC选型性能对比解析:钡特电源 DH1-24S05LS 与 H2405S-1WR3 封装对照互通
在工业控制、仪器仪表、通信设备等中低功率供电场景,1W 级隔离工业 DC-DC 模块电源凭借小体积、高可靠、易集成的特性,成为硬件工程师选型的核心品类。直流电源模块作为电子系统的供电核心,其性能稳定性、环境耐受性与长期可靠性直接决定设备…...

ARM微服务器与异构计算:从欧洲实验室到现代数据中心的演进
1. 项目概述:欧洲实验室里的微服务器“新酿”最近在整理资料时,翻到一篇2014年EE Times的老报道,讲的是当时欧洲几个由欧盟资助的微服务器项目。虽然时间过去快十年了,但里面探讨的一些架构思路和设计哲学,在今天看来依…...

从‘一片蓝’到‘五彩斑斓’:手把手教你美化Matlab三维柱状图,让论文图表脱颖而出
从‘一片蓝’到‘五彩斑斓’:科研级Matlab三维柱状图视觉优化全攻略 当审稿人翻开一篇论文时,图表往往是他们最先注意到的元素。我曾参与过多次学术期刊的评审工作,那些配色考究、细节精致的图表总能在第一时间抓住眼球——这不仅仅是审美问题…...