Bubbliiiing 的 Retinaface rknn python推理分析
Bubbliiiing 的 Retinaface rknn python推理分析
项目说明
使用的是Bubbliiiing的深度学习教程-Pytorch 搭建自己的Retinaface人脸检测平台的模型,下面是项目的Bubbliiiing视频讲解地址以及源码地址和博客地址;
作者的项目讲解视频:https://www.bilibili.com/video/BV1yK411K79y/?p=1&vd_source=7fc00062d9cd78f73503c26f05fad664
项目源码地址:https://github.com/bubbliiiing/retinaface-pytorch
作者博客地址:https://blog.csdn.net/weixin_44791964/article/details/106872072
本文的内容相当于是对Bubbliiiing大佬的教程做一个简易的总结!!!
RKNN模型输出
使用Netron观察此网络的输入和输出,如下所示:

这里模型的输入为:1 x 3 x 640 x 640 (NCHW)
输出结果分为三个,分别是框的回归预测结果(output),分类预测结果(output1)和人脸关键点的回归预测结果(output2),共计输出16800个先验框的三个相关信息;
16800是什么?
首先RetinaFace在特征金字塔上有3个检测分支,分别对应3个stride: 32, 16和8。
- 在stride32上一个feature map对应的原图的32 X 32的感受野即 stride32 对应的feature map的一个格子可以看到原图32 x 32的区域,可以用来检测较大的区域人脸,stride32 对应的feature map的大小为20 × 20,这是因为640 / 32 = 20 ;stride32是最深的有效特征层,其经过不断的卷积后小物体的特征便会消失,从这一方面来看也是它更适合取检测大物体的原因;
- 同理stride16可用于中等人脸区域的检测stride16对应的feature map大小为40 X 40;
- stride8用于较小人脸区域的检测stride8对应的feature map大小为80 X 80
其次需要明确的是在retinafce模型上的每个像素点对应的原图位置上生成的anchor个数是两个;
- stride32对应的feature map的每个位置会在原图上生成两个anchor box,即输入大小640 × 640尺寸的图像, stride32 对应的feature map大小为20 × 20 (640 / 32),那么在stride32对应的feature map上一共可以得到 20 × 20 × 2 = 800个anchor
- stride16对应的feature map大小为40 × 40(640 / 16),共生成40 × 40 × 2 = 3200个anchor
- stride8对应的feature map大小为80 x 80(640 / 8),共生成80 × 80 × 2 = 12800个anchor,
因此3个尺寸总共可以生成800 + 3200 + 12800 = 16800个anchor
anchor的三个相关信息的解释:
-
框的回归预测结果output用于对先验框进行调整获得预测框,输出为1 x 16800 x 4 x 1,我们需要使用输出的四个参数对先验框进行调整来获得真实的人脸预测框。输出为num_anchors x 4
-
分类预测结果output1用于判断先验框内部是否包含物体,用于代表每个先验框内部包含人脸的概率,其有两个输出,第一个输出为先验框内部为背景的概率,第二个输出为先验框内部为人脸的概率;输出为num_anchors x 2
-
人脸关键点的回归预测结果output2用于对先验框进行调整获得人脸关键点,每一个人脸关键点需要两个调整参数,一共有五个人脸关键点,故需要10个参数去调整。输出为num_anchors x 10(num_anchors x 5 x 2),用于代表每个先验框的每个人脸关键点的调整。
模型推理前处理
模型前处理与rockchip的yolov5 rknn python推理分析前处理相同,可以参考其讲解
参考作者源码的额外处理
在作者的源码中进行推理测试的时候出现了如下操作:
image = torch.from_numpy(preprocess_input(image).transpose(2, 0, 1)).unsqueeze(0).type(torch.FloatTensor)def preprocess_input(image):image -= np.array((104, 117, 123),np.float32)return image
我们将对img经过letterbox和色彩空间转换后也同样进行此操作
img = img.astype(dtype = np.float32)
img -= np.array((104,117,123), np.float32)
上面的操作会使得图像数据的分布会变得更加标准化
两个图像
在代码中出现了两个图像分别为img和or_img,img经过一系列处理后最终用于模型推理而or_img用于画人脸框和人脸关键点信息
# img为模型输入
img = cv2.imread(img_path)
img = letterbox(img, (IMG_SIZE,IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# or_img用于画人脸框
or_img = np.array(img, np.uint8)
or_img = cv2.cvtColor(or_img, cv2.COLOR_RGB2BGR)img = img.astype(dtype = np.float32)
img -= np.array((104,117,123), np.float32)
模型推理
执行rknn模型推理,inference的时间目前处于:0.04S-0.05S之间
outputs = rknn.inference(inputs=[img])
模型输出的outputs为一个列表,这个列别里面分别装了三个数组,三个数组的维度为:(1, 16800, 4, 1)、(1, 16800, 2, 1)、(1, 16800, 10,1)
使用numpy的.squeeze()方法去除数组中所有长度为1的维度,结果维度如下所示:
output_1 = outputs[0].squeeze() # (16800, 4)
output_2 = outputs[1].squeeze() # (16800, 2)
output_3 = outputs[2].squeeze() # (16800, 10)
模型后处理
Anchor先验框详解
作者关于Anchor的讲解视频:https://www.bilibili.com/video/BV1yK411K79y?p=8&vd_source=7fc00062d9cd78f73503c26f05fad664
先验框:就是网络预先设定好的,在图像上的框,网络的预测结果只是对这些先验框进行判断并调整
前面我们讲过3个检测分支的对应的feature map的每个像素点对应的原图位置上生成两个anchor,同时每个检测分支的生成的anchor尺寸是不同的;对于比较深的特征层stride32对应anchor的尺寸大,因为经过不断的卷积,小物体的特征会消失,它更适合取检测大物体,它对应的两个anchor尺寸分别为512 × 512和256 × 256;stride16对应的feature map生成的anchor尺寸大小分别为128 × 128和64 × 64;stride8对应的feature map可以生成的anchor大小为32 × 32 和 16 × 16;
在代码中的体现如下所示:
# 计算生成先验框anchor
anchors = Anchors(cfg_mnet, image_size=(640, 640)).get_anchors()
cfg_mnet={'min_sizes': [[16, 32], [64, 128], [256, 512]], 'steps': [8, 16, 32],'variance': [0.1, 0.2],
}
# 得到anchor
class Anchors(object):def __init__(self, cfg, image_size=None):super(Anchors, self).__init__()# Anchors先验框基础的边长 self.min_sizes = cfg['min_sizes']# 指向了三个有效特征层对输入进来的图片 长和宽压缩的倍数 对于比较浅的输入特征层 长和宽压缩了三次8=2^3 ,即长和宽变为了原来的1/8 对于最深的有效特征层 会对输入进去的图片进行5次长和宽的压缩 self.steps = cfg['steps']# 输入进来的图片的尺寸 根据图片的大小生成先验框self.image_size = image_size# 三个有效特征层高和宽self.feature_maps = [[ceil(self.image_size[0]/step), ceil(self.image_size[1]/step)] for step in self.steps]def get_anchors(self): # 获得先验框anchors = []for k, f in enumerate(self.feature_maps): # 首先对所有的特征层进行循环min_sizes = self.min_sizes[k] # 取出每一个特征层对应的先验框# 对特征层的高和宽网格进行循环迭代for i, j in product(range(f[0]), range(f[1])):for min_size in min_sizes:# 将先验框映射到网格点上s_kx = min_size / self.image_size[1]s_ky = min_size / self.image_size[0]dense_cx = [x * self.steps[k] / self.image_size[1] for x in [j + 0.5]]dense_cy = [y * self.steps[k] / self.image_size[0] for y in [i + 0.5]]for cy, cx in product(dense_cy, dense_cx):# 把获得的先验框添加到anchors列表中anchors += [cx, cy, s_kx, s_ky] # 先验框的形式是中心宽高的形式output_np=np.array(anchors).reshape(-1,4)return output_np
在作者关于Anchor的讲解视频中,作者在最深的有效特征层20 x 20的特征图上绘制了先验框(其对应的先验框的尺寸为:[256, 512]),并以20 x 20特征图的左上角点为例,其先验框如下所示:

在获取先验框后,retinaface的网络预测结果会判断先验框内部是否包含人脸,还会对先验框进行调整获得最终的预测框,还会对中心进行调整获得五个先验点
解码-先验框的调整
作者解码的讲解视频:https://www.bilibili.com/video/BV1yK411K79y?p=9&vd_source=7fc00062d9cd78f73503c26f05fad664
先验框的解码过程就是对先验框的中心和宽高进行调整,获得调整后的先验框
# 人脸框解码
boxes = decode(output_1, anchors, cfg_mnet['variance'])
# 五个人脸关键点解码
landms = decode_landm(output_3, anchors, cfg_mnet['variance'])
# 人脸框坐标解码
def decode(loc, priors, variances):boxes = np.concatenate((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],priors[:, 2:] * np.exp(loc[:, 2:] * variances[1])), 1)boxes[:, :2] -= boxes[:, 2:] / 2boxes[:, 2:] += boxes[:, :2]return boxes# 人脸关键点解码
def decode_landm(pre, priors, variances):landms = np.concatenate((priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:],priors[:, :2] + pre[:, 2:4] * variances[0] * priors[:, 2:],priors[:, :2] + pre[:, 4:6] * variances[0] * priors[:, 2:],priors[:, :2] + pre[:, 6:8] * variances[0] * priors[:, 2:],priors[:, :2] + pre[:, 8:10] * variances[0] * priors[:, 2:],), 1)return landms
- decode函数会对先验框进行调整,获得最终的预测框
中心调整
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
取出网络回归结果loc中的前两个值乘上一个常数variances[0] (值)进行标准化,然后将结果再乘上先验框的宽和高priors[:, 2:],之后再加上先验框的中心priors[:, :2],便获得了调整后的先验框中心即为预测框的中心点;loc[:, :2] * variances[0] * priors[:, 2:]相当于先验框中心偏移的部分
宽高调整
priors[:, 2:] * np.exp(loc[:, 2:] * variances[1])
取出网络回归结果loc中的后两个值乘上一个常数variances[1] (0.2)进行标准化,然后将结果取一个指数,再乘上先验框的宽和高priors[:, 2:],便获地了调整后的先验框的宽高
boxes[:, :2] -= boxes[:, 2:] / 2
boxes[:, 2:] += boxes[:, :2]
最后将调整后的先验框形式,转化为左上角坐标点和右下角坐标点的形式,并返回;
下面为作者解码的讲解视频中对先验框调整后的结果进行的演示:

对比两边发现右边的图中的蓝色点即为两个先验框调整时,两个anchor的中心点的调整情况,同时发现右边的先验框的宽和高也发生了变化;
- decode_landm函数会对先验框的中心进行调整,获得五个人脸关键点
priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:]
人脸关键点的解码过程与先验框中心点调整的过程一样
取出相应序号的人脸关键点结果pre[:, :2]为人脸关键点中心点的预测结果
取出关键点的结果*variances[0] (归一化),再乘上先验框的宽和高priors[:, 2:],最后再加上先验框的中心priors[:, :2]即可;
先验框调整后,再进行得分的筛选和非极大值抑制便得到了最终的结果
过滤无用的框
在进行过滤无用框的操作前需要对前面先验框的解码和人脸关键点的解码和人脸的概率合并到一起
conf = output_2[:, 1:2] # 置信度序号为0的内容为先验框为背景的概率 序号为1的内容为先验框为人脸的概率#非极大抑制,得到最终输出
boxs_conf = np.concatenate((boxes, conf, landms), -1)
合并后boxs_conf的维度为:(16800, 15)
15的组成为:
- 0-3:预测框位置信息,左上角坐标点和右下角坐标点
- 4:预测框包含人脸的概率
- 5-14:人脸的十个关键点坐标
过滤掉无用的框
boxs_conf = filter_box(boxs_conf, 0.5, 0.45) # 0.5为置信度阈值conf_thres 0.45为非极大值抑制的iou阈值
filter_box代码实现如下所示:
def filter_box(org_box, conf_thres, iou_thres): #过滤掉无用的框conf = org_box[..., 4] > conf_thres #删除置信度小于conf_thres的BOXbox = org_box[conf == True] output = []curr_cls_box = np.array(box)curr_cls_box[:,:4]=curr_cls_box[:,:4]*640curr_cls_box[:,5:]=curr_cls_box[:,5:]*640curr_out_box = pynms(curr_cls_box, iou_thres) #经过非极大抑制后输出的BOX下标for k in curr_out_box:output.append(curr_cls_box[k]) #利用下标取出非极大抑制后的BOXoutput = np.array(output)return output
首先根据包含人脸的概率进行筛选,保留概率大于conf_thres的人脸框
conf = org_box[..., 4] > conf_thres
box = org_box[conf == True]
它返回16800个预测框的是否大于conf_thres的布尔值,根据布尔值保留满足要求的预测框
将预测框的位置信息和关键点信息,共计7个点,尺寸上乘上640
curr_cls_box[:,:4]=curr_cls_box[:,:4]*640
curr_cls_box[:,5:]=curr_cls_box[:,5:]*640
进行非极大值抑制,返回经过非极大抑制后输出的剩余满足要求的预测框的下标,将其保存到output中
curr_out_box = pynms(curr_cls_box, iou_thres)
for k in curr_out_box:output.append(curr_cls_box[k]) #利用下标取出非极大抑制后的BOX
最后返回剩余的预测框;
非极大值抑制
非极大值抑制的代码与rockchip的yolov5 rknn python推理分析所讲述的非极大值抑制代码相同,可以去参考,这里不做重复讲述
def pynms(dets, thresh): '''非极大抑制'''x1 = dets[:, 0]y1 = dets[:, 1]x2 = dets[:, 2]y2 = dets[:, 3]areas = (y2 - y1) * (x2 - x1)scores = dets[:, 4]keep = []index = scores.argsort()[::-1] #置信度从大到小排序的索引while index.size > 0:i = index[0]keep.append(i)# 计算相交面积# 求相交区域的左上角坐标x11 = np.maximum(x1[i], x1[index[1:]]) y11 = np.maximum(y1[i], y1[index[1:]])、# 求相交区域的右下角坐标x22 = np.minimum(x2[i], x2[index[1:]])y22 = np.minimum(y2[i], y2[index[1:]])# 当两个框不想交时x22 - x11或y22 - y11 为负数,则将两框不相交时把相交面积置0w = np.maximum(0, x22 - x11 ) h = np.maximum(0, y22 - y11 ) # 计算相交面积overlaps = w * h# 计算IOUious = overlaps / (areas[i] + areas[index[1:]] - overlaps)# IOU小于thresh的框保留下来idx = np.where(ious <= thresh)[0] index = index[idx + 1]return keep
结果绘制
经过置信度过滤和非极大值抑制之后得到预测框的信息为boxs_conf
boxs_conf = filter_box(boxs_conf, 0.5, 0.45)
在boxs_conf中前四个参数为人脸预测框框的位置信息,左上角和右下角的坐标;第五个参数为人脸的概率;剩下的参数为人脸关键点的位置信息:按顺序分别为
左眼、右眼、鼻子、左脸、右脸,将boxs_conf传递给draw_img绘制结果
#画出人类框和5个人脸关键并保存图片
if boxs_conf is not None:draw_img(boxs_conf, or_img)
draw_img函数的代码如下所示:
# 画人脸框和5个关键点
def draw_img(boxes_conf_landms,old_image):for b in boxes_conf_landms:text = "{:.4f}".format(b[4])b = list(map(int, b))# b[0]-b[3]为人脸框的坐标,b[4]为得分cv2.rectangle(old_image, (b[0], b[1]), (b[2], b[3]), (0, 0, 255), 2) cx = b[0]cy = b[1] + 12cv2.putText(old_image, text, (cx, cy),cv2.FONT_HERSHEY_DUPLEX, 0.5, (255, 255, 255))# b[5]-b[14]为人脸关键点的坐标cv2.circle(old_image, (b[5], b[6]), 1, (0, 0, 255), 4)cv2.circle(old_image, (b[7], b[8]), 1, (0, 255, 255), 4)cv2.circle(old_image, (b[9], b[10]), 1, (255, 0, 255), 4)cv2.circle(old_image, (b[11], b[12]), 1, (0, 255, 0), 4)cv2.circle(old_image, (b[13], b[14]), 1, (255, 0, 0), 4)return old_image
结果展示如下所示:

相关文章:
Bubbliiiing 的 Retinaface rknn python推理分析
Bubbliiiing 的 Retinaface rknn python推理分析 项目说明 使用的是Bubbliiiing的深度学习教程-Pytorch 搭建自己的Retinaface人脸检测平台的模型,下面是项目的Bubbliiiing视频讲解地址以及源码地址和博客地址; 作者的项目讲解视频:https:…...

Web前端-Web开发HTML基础8-nav
一. 基础 1. 写一个导航标签,里面是两个超链接,分别指向https://baidu.com和https://huawei.com/cn; 2. 写一个导航标签,里面是三个超链接,分别指向https://baidu.com、https://huawei.com/cn和https://www.nowcoder.c…...

如何建设和维护数据仓库:深入指南
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: V: LAF20151116 进行更多交流学习 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来ÿ…...

海思arm-hisiv400-linux-gcc 交叉编译rsyslog 记录心得
需要编译rsyslog,参考海思3536平台上rsyslog交叉编译、使用-CSDN博客和rsyslog移植(亲测成功)_rsyslog交叉编译-CSDN博客 首先下载了要用到的一些库的源码,先交叉编译这些库 原来是在centos6上交叉编译的,结果编译时报缺少软件要…...

IDEA工具中Java语言写小工具遇到的问题
一:读取excel时遇到 org/apache/poi/ss/usermodel/WorkbookProvider 解决办法: 在pom.xml中把poi的引文包放在最前面即可(目前就算放在最后面也不报错了,不知道为啥) 二:本地maven打包时,没有…...

2-38 基于matlab的蚁群算法优化无人机uav巡检
基于matlab的蚁群算法优化无人机uav巡检,巡检位置坐标可根据需求设置,从基地出发,返回基地,使得路径最小。可设置蚁群数量,信息素系数。输出最佳路线长度。程序已调通,可直接运行。 2-38 蚁群算法优化无人…...

解决selenium打印保存为PDF时图片未加载成功的问题
使用selenium打印网页时,如果程序运行很快的话,可能会导致图片没有加载成功即进行了保存,出现这个问题最初的思考是在执行打印任务时使用js进行强制等待,后发现实现效果并不好。在加载页面时使用自动下滑的方式将网页拉到底&#…...
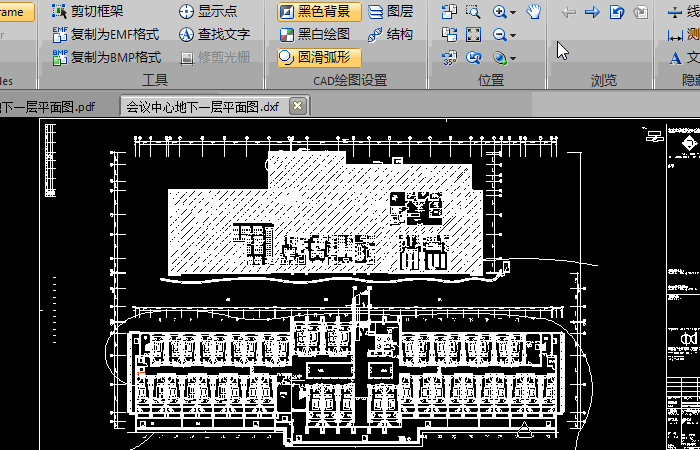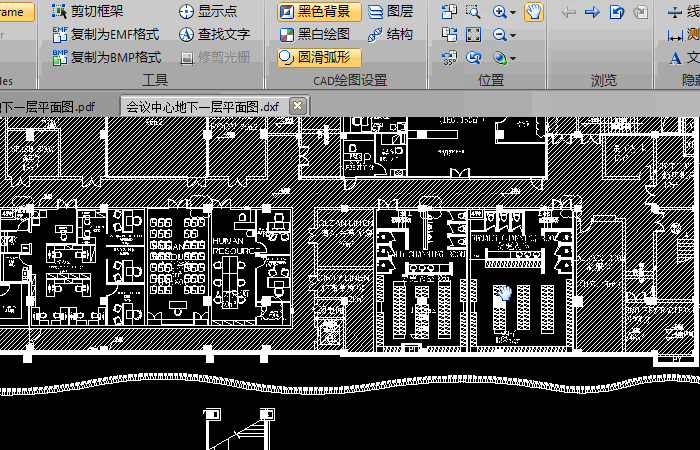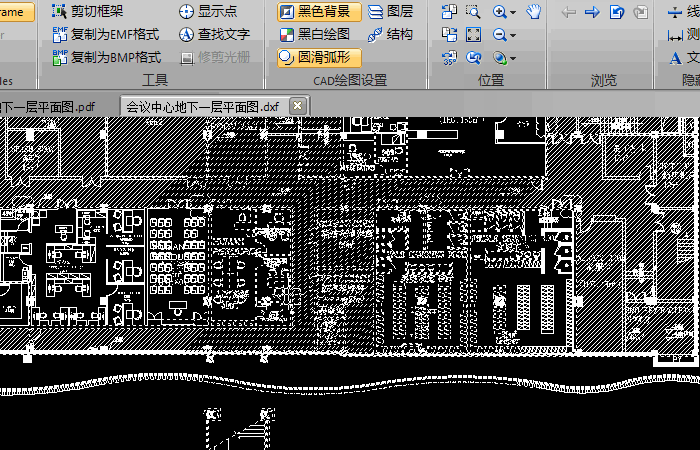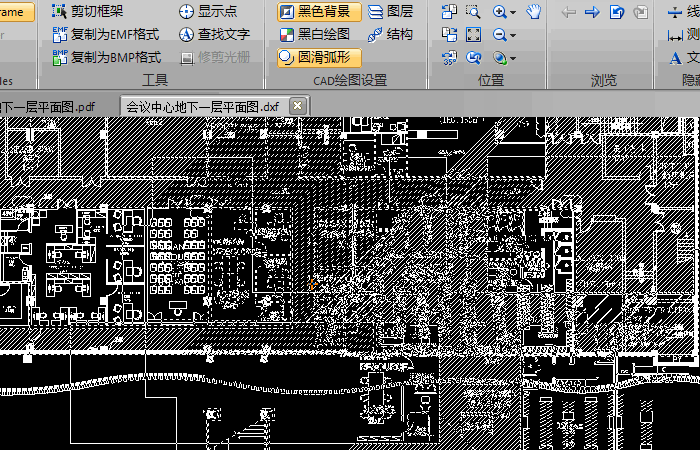
如何将PDF转换成可以直接编辑的CAD图纸?
PDF图纸是为了让用户更好的阅览CAD文件,但是,当我们想要对其进行编辑的时候,PDF图纸就是一个麻烦了。那么PDF转换成CAD后可以编辑吗?如何将PDF转换成可以直接编辑的CAD图纸呢?本篇给你答案。 1、启动迅捷CAD编辑器&…...

【STM32】理解时钟树(图示分析)
文章目录 时钟系统什么是时钟时钟树简化图示类比示例时钟树详解时钟源系统时钟配置各总线时钟外设时钟 时钟系统 什么是时钟 时钟在电子和计算机系统中指的是生成周期性信号的电路或设备,这种周期性信号用于同步系统内的各种操作。时钟信号通常是方波,…...

动态内存四个函数
文章目录 1. malloc2. calloc3. realloc4. free 在C语言中,malloc、calloc、realloc 和 free 是用于动态内存管理的标准库函数,它们定义在 <stdlib.h> 头文件中。以下是这些函数的用法: 1. malloc malloc 函数用于在堆区分配指定大小…...
DevExpress WPF中文教程 - 为项目添加GridControl并将其绑定到数据
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...
高性能分布式IO系统BL205 OPC UA耦合器
边缘计算是指在网络的边缘位置进行数据处理和分析,而不是将所有数据都传送到云端或中心服务器,这样可以减少延迟、降低带宽需求、提高响应速度并增强数据安全性。 钡铼BL205耦合器就内置边缘计算功能,它不依赖上位机和云平台,就能…...

live555 rtsp服务器实战之doGetNextFrame
live555关于RTSP协议交互流程 live555的核心数据结构值之闭环双向链表 live555 rtsp服务器实战之createNewStreamSource live555 rtsp服务器实战之doGetNextFrame live555搭建实时播放rtsp服务器 注意:该篇文章可能有些绕,最好跟着文章追踪下源码&…...

Nginx系列-3 servername优先级和location优先级和常用正则表达式
1.正则表达式和分组 由于Nginx配置文件中经常出现正则表达式,因此本章节专门对常见的正则表达式进行简单介绍。 [1] 开始与结束 ^表示匹配输入字符串的开始 $表示匹配输入字符串的结束[2] 匹配次数 ?表示匹配0次或者1次 表示匹配1次或多次 *表示匹配0从或多次…...

python—爬虫爬取电影页面实例
下面是一个简单的爬虫实例,使用Python的requests库来发送HTTP请求,并使用lxml库来解析HTML页面内容。这个爬虫的目标是抓取一个电影网站,并提取每部电影的主义部分。 首先,确保你已经安装了requests和lxml库。如果没有安装&#x…...

实现图片拖拽和缩小放大功能。
1. 前言 不知道各位前端小伙伴蓝湖使用的多不多,反正我是经常在用,ui将原型图设计好后上传至蓝湖,前端开发人员就可以开始静态页面的的编写了。对于页面细节看的不是很清楚可以使用滚轮缩放后再拖拽查看,还是很方便的。于是就花了…...

昇思25天学习打卡营第18天|munger85
DCGAN生成漫画头像 首先肯定是下载训练数据,而这些训练数据就是一些卡通头像。后来我们会看到这个具体的头像 就像其他的数据集目录一样,它是由一些目录和这个目录下面的文件组成的数据集。 有相当多的图片。所以可以训练出来比较好的效果。 图片的处理…...

nginx配置文件说明
Nginx的配置文件说明 Nginx配置文件的主要配置块可以分为三个部分:全局配置块(events和http块),events块和http块。这三个部分共同定义了Nginx服务器的整体行为和处理HTTP请求的方式。 全局配置块: 包含了影响Nginx服…...

用不同的url头利用Python访问一个网站,把返回的东西保存为txt文件
这个需要调用requests模块(相当于c的头文件) import requests 还需要一个User-Agent头(这个意思就是告诉python用的什么系统和浏览器) Google Chrome(Windows): Mozilla/5.0 (Windows NT 10.0; Win64; x64…...

一文掌握Prometheus实现页面登录认证并集成grafana
一、接入方式 以保护Web站点的访问控制,如HTTP 服务器配置中实现安全的加密通信和身份验证,保护 Web 应用程序和用户数据的安全性。 1.1 加密密码 通过httpd-tools工具包来进行Web站点加密 yum install -y httpd-tools方式一:通过htpasswd生…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...