LLM模型与实践之基于MindSpore的GPT2文本摘要
前言
安装环境
!pip install tokenizers==0.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行`!pip install mindnlp==0.3.1`
!pip install mindnlp数据加载
from mindnlp.utils import http_get# download dataset
url = 'https://download.mindspore.cn/toolkits/mindnlp/dataset/text_generation/nlpcc2017/train_with_summ.txt'
path = http_get(url, './')数据预处理
原始数据格式:
article: [CLS] article_context [SEP]
summary: [CLS] summary_context [SEP]
预处理后的数据格式:
[CLS] article_context [SEP] summary_context [SEP]import json
import numpy as np# preprocess dataset
def process_dataset(dataset, tokenizer, batch_size=6, max_seq_len=1024, shuffle=False):def read_map(text):data = json.loads(text.tobytes())return np.array(data['article']), np.array(data['summarization'])def merge_and_pad(article, summary):# tokenization# pad to max_seq_length, only truncate the articletokenized = tokenizer(text=article, text_pair=summary,padding='max_length', truncation='only_first', max_length=max_seq_len)return tokenized['input_ids'], tokenized['input_ids']dataset = dataset.map(read_map, 'text', ['article', 'summary'])# change column names to input_ids and labels for the following trainingdataset = dataset.map(merge_and_pad, ['article', 'summary'], ['input_ids', 'labels'])dataset = dataset.batch(batch_size)if shuffle:dataset = dataset.shuffle(batch_size)return dataset
模型构建
from mindspore import ops
from mindnlp.transformers import GPT2LMHeadModelclass GPT2ForSummarization(GPT2LMHeadModel):def construct(self,input_ids = None,attention_mask = None,labels = None,):outputs = super().construct(input_ids=input_ids, attention_mask=attention_mask)shift_logits = outputs.logits[..., :-1, :]shift_labels = labels[..., 1:]# Flatten the tokensloss = ops.cross_entropy(shift_logits.view(-1, shift_logits.shape[-1]), shift_labels.view(-1), ignore_index=tokenizer.pad_token_id)return loss模型训练

模型推理
def process_test_dataset(dataset, tokenizer, batch_size=1, max_seq_len=1024, max_summary_len=100):def read_map(text):data = json.loads(text.tobytes())return np.array(data['article']), np.array(data['summarization'])def pad(article):tokenized = tokenizer(text=article, truncation=True, max_length=max_seq_len-max_summary_len)return tokenized['input_ids']dataset = dataset.map(read_map, 'text', ['article', 'summary'])dataset = dataset.map(pad, 'article', ['input_ids'])dataset = dataset.batch(batch_size)return dataset
总结
使用mindnlp库实现GPT2模型进行文本摘要,采用BertTokenizer进行分词, 使用线性预热和衰减的学习率策略进行模型训练. 通过多种数据预处理和模型优化技术, 训练并部署模型进行文本摘要推理.
相关文章:
LLM模型与实践之基于MindSpore的GPT2文本摘要
前言 安装环境 !pip install tokenizers0.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple # 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行!pip install mindnlp0.3.1 !pip install mindnlp 数据加…...
【Android】使用视图绑定ViewBinding来代替findViewById
文章目录 介绍作用用法开启ViewBinding功能自动生成绑定类在Activity中使用访问视图控件 区别 介绍 ViewBinding 是 Android 开发中的一个功能,它简化了访问视图的过程,避免了使用 findViewById 的繁琐步骤。它通过生成与布局文件相对应的绑定类…...

字符的统计——423、657、551、696、467、535
423. 从英文中重建数字 最初思路 首先要有一个指针,对于3/4/5为一组地跳跃。起初想的是后瞻性,如果符合0-9任意,则更换index、跳跃。此时写了一个函数,用来判断s的截取段和0-9中有无符合。这个思路并没有进行下去,虽然…...

pytest+allure
安装 下载:github win环境下载zip 环境变量: pycharm: pip install allure-pytest 验证安装 生成结果: if __name__ __main__:pytest.main([-s,test_createTag2.py,--alluredir,result]) 生成报告: allure gener…...

【数据结构】AVL树(平衡二叉搜索树)
文章目录 1.AVL树1.1 AVL树的概念1.2 AVL树节点的定义1.3 AVL树的插入1.4 AVL树的旋转1.4.1 左单旋1.4.2 右单旋1.4.3 右左双旋1.4.4 左右双旋 1.5 AVL树的平衡验证1.6 AVL树的删除1.7 AVL树的性能 1.AVL树 在前面,我们已经介绍过了二叉搜索树,也了解到…...

ASP.NET Web Api 使用 EF 6,DateTime 字段如何取数据库服务器当前时间
前言 在做数据库设计时,为了方便进行数据追踪,通常会有几个字段是每个表都有的,比如创建时间、创建人、更新时间、更新人、备注等,在存储这些时间时,要么存储 WEB 服务器的时间,要么存储数据库服务器的时间…...

【HarmonyOS】应用设置屏幕常亮
【HarmonyOS】应用设置屏幕常亮 一、问题背景: 金融类或钱包场景的应用APP,对于付款码,扫一扫等场景都会对屏幕设置常亮。防止屏幕长时间不操作,自动息屏。 目前这种场景的需求也是非常有必要的,也是行业内默认的处理…...

Docker部署Elasticsearch8.6.0 Kibana8.6.0
(1)Docker部署Elasticsearch8.5.3(失败…) 为了匹配springboot3.0.x,安装Elasticsearch:8.5.3 拉取镜像,遇到问题! [rootserver01 ~]# docker pull elasticsearch:8.5.3 8.5.3: Pulling from…...

第四篇论文小记
一、第一次投稿 期刊:《Remote Sensing》 研究方向:人工智能应用 投稿结果:已投被拒 投稿周期:3天 最后更新时间:19 July 2024 投稿流程: 状态时间Pending review16 July 2024Reject by editor19 July …...

python使用 tkinter 生成随机颜色
先看效果: 只要不停点击底部的按钮,每次都会生成新的颜色。炫酷啊。 import random import tkinter import tkinter.messagebox from tkinter import Button# todo """ 1. 设置一个按钮,来让用户选择是否显示颜色值 2. 把按钮换成 Label…...

【Linux学习 | 第1篇】Linux介绍+安装
文章目录 Linux1. Linux简介1.1 不同操作系统1.2 Linux系统版本 2. Linux安装2.1 安装方式2.2 网卡设置2.3 安装SSH连接工具2.4 Linux和Windows目录结构对比 Linux 1. Linux简介 1.1 不同操作系统 桌面操作系统 Windows (用户数量最多)MacOS ( 操作体验好,办公人…...
设计模式-抽象工厂
抽象工厂属于创建型模式。 抽象工厂和工厂设计模式的区别: 工厂模式的是设计模式中最简单的一种设计模式,主要设计思想是,分离对象的创建和使用,在Java中,如果需要使用一个对象时,需要new Class()ÿ…...

Ubunton-24.04 简单配置使用
目录 1.设置 root 密码 2. 防火墙设置 1. 安装防火墙 2. 开启和关闭防火墙 3. 开放端口和服务规则 4. 关闭端口和删除服务规则 5 查看防火墙状态 3. 设置网络 1.设置 root 密码 1. 切换到 root 用户,并输入当前登录账号的密码 sudo -i 2. 设置新密码…...
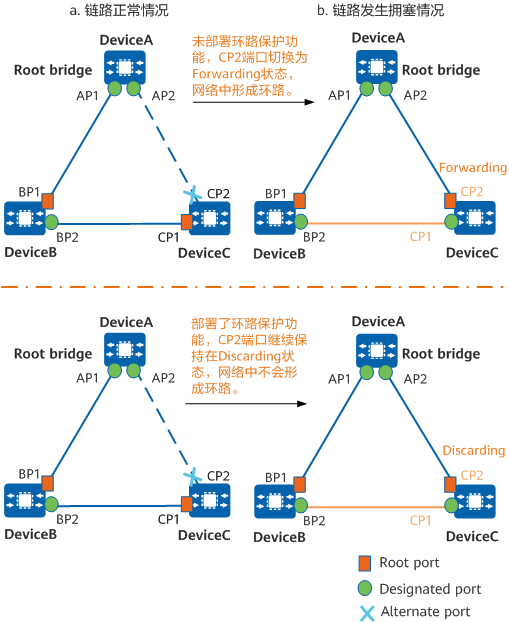
什么是STP环路保护
在运行生成树协议的网络中,根端口和其他阻塞端口状态是依靠不断接收来自上游设备的BPDU维持。当由于链路拥塞或者单向链路故障导致这些端口收不到来自上游交换设备的BPDU时,设备会重新选择根端口。原先的根端口会转变为指定端口,而原先的阻塞…...

Python算法基础:解锁冒泡排序与选择排序的奥秘
在数据处理和算法设计中,排序是一项基础且重要的操作。本文将介绍两种经典的排序算法:冒泡排序(Bubble Sort)和选择排序(Selection Sort)。我们将通过示例代码来演示这两种算法如何对列表进行升序排列。 一…...

QtCMake工程提升类后找不到头文件
链接: QtCMake工程提升类后找不到头文件_qt提升类找不到头文件-CSDN博客 重点: 1.原因:出现问题的原因是Qt creator通过ui文件生成的程序和存放头文件的目录不在一起,但是生成的程序里会在生成目录下找头文件,所以肯…...

Docker核心技术:Docker原理之Cgroups
云原生学习路线导航页(持续更新中) 本文是 Docker核心技术 系列文章:Docker原理之Cgroups,其他文章快捷链接如下: 应用架构演进容器技术要解决哪些问题Docker的基本使用Docker是如何实现的 Docker核心技术:…...

union的特性和大小端
一、union在c和c语言中的特性 1.共享内存空间:union的所有成员共享同一块内存空间。意味着在同一时刻,union 只能存储其成员 中的一个值。当你修改了union中的一个成员,那么其它成员的值也会被改变,因为它们实际上都是指向同一块…...

个性化IT服务探索实践
探索和实践个性化IT服务,可以为用户提供更优质、定制化的解决方案,从而提升用户体验和满意度。以下是一些具体的步骤和建议,帮助自己在未来探索和实践个性化IT服务。 一、了解用户需求 用户调研和反馈: 进行用户调研,了解用户的需求和痛点。收集用户反馈,通过问卷、采访…...

UE4-打包游戏,游戏模式,默认关卡
一.打包游戏 注意windows系统无法打包苹果系统的执行包,只能使用苹果系统打包。 打包完之后是一个.exe文件。 打包要点: 1.确定好要操控的角色和生成位置。 2.设置默认加载的关卡和游戏模式。 在这个界面可以配置游戏的默认地图和游戏的模式,…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...
)
告别复杂模型:用Python+OpenCV+dlib实现简易驾驶员疲劳监测(附完整代码)
轻量级驾驶员疲劳监测系统:PythonOpenCVdlib实战指南 在长途驾驶或夜间行车时,疲劳是导致交通事故的重要因素之一。传统基于嵌入式设备的疲劳监测系统往往需要专用硬件,增加了开发成本和部署难度。本文将介绍如何利用Python生态中的OpenCV和d…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

MFCC与可解释机器学习:构建可解释的L2发音AI诊断系统
1. 项目概述:当语音技术遇见二语教学 作为一名在语音技术和教育技术交叉领域摸爬滚打了十多年的从业者,我常常思考一个问题:我们能用算法“听”出一个人说外语时,他的母语口音吗?更进一步,我们能否不仅“听…...