MySQL查询优化:提升数据库性能的策略
在数据库管理和应用中,优化查询是提高MySQL数据库性能的关键环节。随着数据量的不断增长,如何高效地检索和处理数据成为了一个重要的挑战。本文将介绍一系列优化MySQL查询的策略,帮助开发者和管理员提升数据库的性能。
案例1: 使用索引优化查询
假设数据库表结构:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100),department_id INT,salary DECIMAL(10, 2),hire_date DATE,INDEX idx_department_id (department_id),INDEX idx_salary (salary)
);
原始查询(未使用索引):
SELECT * FROM employees WHERE department_id = 100;
优化后的查询(使用索引):
由于department_id列上已经有了索引,所以上面的查询已经相对优化。但是,如果查询只需要特定的列,那么应该只选择那些列,而不是使用SELECT *。
SELECT id, name, salary FROM employees WHERE department_id = 100;
案例2: 避免在WHERE子句中对列使用函数
原始查询(使用函数):
SELECT * FROM employees WHERE YEAR(hire_date) = 2020;
优化后的查询(避免使用函数):
在这个例子中,对hire_date列使用YEAR()函数会阻止MySQL使用索引(如果存在的话)。更好的做法是直接比较日期范围。
SELECT * FROM employees WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';
案例3: 优化JOIN查询
假设有两个表:
CREATE TABLE orders (order_id INT AUTO_INCREMENT PRIMARY KEY,customer_id INT,order_date DATE,total_amount DECIMAL(10, 2),INDEX idx_customer_id (customer_id)
);CREATE TABLE customers (customer_id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100),email VARCHAR(100)
);
原始JOIN查询(可能未优化):
SELECT orders.*, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id
WHERE customers.email LIKE '%example.com';
优化建议:
- 确保
customer_id列上有索引(在这个例子中已经有了)。 - 如果
email列上的搜索模式以通配符开头(如%example.com),则无法利用索引。如果可能,考虑将搜索模式调整为不以通配符开头,或者使用全文搜索功能(如果MySQL版本支持)。 - 如果经常需要根据
email域进行搜索,并且搜索模式不总是以通配符开头,那么可以考虑在email列上创建索引。但是,请注意,这可能会降低插入、更新和删除操作的性能。
案例4: 使用聚合和索引优化GROUP BY查询
原始GROUP BY查询(可能未优化):
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
优化建议:
- 确保
department_id列上有索引,因为MySQL在执行GROUP BY时可能会利用它。 - 如果查询经常执行,并且
department_id和salary列经常一起使用,那么考虑创建一个覆盖索引,该索引包含这两个列。
-- 假设的覆盖索引创建语句
CREATE INDEX idx_department_salary ON employees(department_id, salary);
请注意,实际的优化效果取决于多个因素,包括数据的大小、分布、MySQL的配置以及查询的具体模式。因此,在执行任何优化之前,最好使用EXPLAIN命令来分析查询的执行计划,并根据实际情况调整策略。
案例5: 使用LIMIT分页优化大数据集查询
原始查询(可能导致性能问题):
SELECT * FROM orders ORDER BY order_date DESC;
如果你尝试在UI中显示这个查询的结果,并且数据集非常大,那么一次性加载所有数据可能会导致性能问题。
优化后的查询(使用LIMIT和OFFSET进行分页):
SELECT * FROM orders ORDER BY order_date DESC LIMIT 10 OFFSET 20;
这个查询会返回从第21条记录开始的10条记录(假设OFFSET从0开始计数,但许多数据库实际上从1开始,这取决于具体的SQL方言)。这样可以有效地管理内存使用,并提高用户体验。
然而,需要注意的是,当OFFSET值非常大时,即使使用了LIMIT,查询性能也可能下降,因为数据库仍然需要扫描或处理OFFSET之前的所有行。在这种情况下,可以考虑使用基于游标的分页或键集分页(Keyset Pagination)来优化性能。
案例6: 优化子查询
原始查询(使用子查询):
SELECT * FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 10
);
优化建议:
- 确保子查询中的
location_id列上有索引。 - 如果子查询返回的结果集很小,上述查询通常已经足够优化。但是,如果子查询返回大量数据,那么可以考虑使用JOIN来重写查询,因为JOIN有时能更有效地利用索引。
优化后的查询(使用JOIN):
SELECT e.*
FROM employees e
JOIN departments d ON e.department_id = d.department_id
WHERE d.location_id = 10;
案例7: 优化复杂的JOIN操作
当涉及多个表的JOIN操作时,优化变得尤为重要。以下是一些优化复杂JOIN操作的策略:
- 确保所有JOIN条件上的列都有索引。
- 使用合适的JOIN类型(INNER JOIN、LEFT JOIN、RIGHT JOIN等),根据查询需求选择。
- 考虑JOIN的顺序。MySQL优化器通常会尝试不同的JOIN顺序来找到最有效的执行计划,但有时手动指定JOIN顺序(通过括号或JOIN…USING/ON语句的顺序)可以获得更好的性能。
- 减少JOIN中涉及的行数。通过在JOIN之前使用WHERE子句来过滤掉不必要的行,可以减少JOIN操作需要处理的数据量。
案例8: 使用EXISTS代替IN(在某些情况下)
原始查询(使用IN):
SELECT * FROM employees
WHERE id IN (SELECT manager_id FROM departments);
优化后的查询(使用EXISTS):
SELECT * FROM employees e
WHERE EXISTS (SELECT 1 FROM departments d WHERE d.manager_id = e.id
);
在某些情况下,使用EXISTS代替IN可以提高查询性能,特别是当子查询返回的结果集很大时。EXISTS在找到第一个匹配项时就会停止搜索,而IN可能需要扫描整个子查询结果集。然而,这并不是一个绝对的规则,具体效果取决于数据的实际分布和MySQL的优化器行为。
总结
优化SQL查询是一个复杂的过程,涉及多个方面,包括索引的使用、查询语句的编写、数据库表的设计以及MySQL服务器的配置。通过遵循最佳实践、使用工具(如EXPLAIN)来分析查询计划,并根据实际情况进行调整,可以显著提高数据库的性能。记住,优化是一个持续的过程,需要不断地监控、分析和调整。
相关文章:

MySQL查询优化:提升数据库性能的策略
在数据库管理和应用中,优化查询是提高MySQL数据库性能的关键环节。随着数据量的不断增长,如何高效地检索和处理数据成为了一个重要的挑战。本文将介绍一系列优化MySQL查询的策略,帮助开发者和管理员提升数据库的性能。 案例1: 使用索引优化查…...

vue-快速入门
Vue 前端体系、前后端分离 1、概述 1.1、简介 Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型,可以高效地开发用户界面。…...

【网络流】——初识(最大流)
网络流-最大流 基础信息引入一些概念基本性质 最大流定义 Ford–Fulkerson 增广Edmons−Karp算法Dinic 算法参考文献 基础信息 引入 假定现在有一个无限放水的自来水厂和一个无限收水的小区,他们之间有多条水管和一些节点构成。 每一条水管有三个属性:…...

【STM32嵌入式系统设计与开发---拓展】——1_10矩阵按键
这里写目录标题 1、矩阵按键2、代码片段分析 1、矩阵按键 通过将4x4矩阵按键的每一行依次设为低电平,同时保持其它行为高电平,然后读取所有列的电平状态,可以检测到哪个按键被按下。如果某列变为低电平,说明对应行和列的按键被按下…...

长期更新方法库推荐pmq-ui
# pmq-ui pmq-ui 好用方法库ui库, 欢迎您的使用 ## 安装 1. 克隆项目库到本地: 2. 进入项目目录:cd pmq-ui 3. 安装依赖:npm install pmq-ui ## 使用 <!-- 1. 启动应用: 2. 访问 [http://localhost:3000](http://localhost:300…...

<数据集>抽烟识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:4860张 标注数量(xml文件个数):4860 标注数量(txt文件个数):4860 标注类别数:1 标注类别名称:[smoking] 使用标注工具:labelImg 标注规则:对…...

SQL Server 端口设置教程
引言 你好,我是悦创。 在配置 SQL Server 的过程中,设置正确的端口非常关键,因为它影响到客户端如何连接到 SQL Server 实例。默认情况下,SQL Server 使用 TCP 端口 1433,但在多实例服务器上或出于安全考虑ÿ…...

【React1】React概述、基本使用、脚手架、JSX、组件
文章目录 1. React基础1.1 React 概述1.1.1 什么是React1.1.2 React 的特点声明式基于组件学习一次,随处使用1.2 React 的基本使用1.2.1 React的安装1.2.2 React的使用1.2.3 React常用方法说明React.createElement()ReactDOM.render()1.3 React 脚手架的使用1.3.1 React 脚手架…...

k8s部署kafka集群
k8s部署kafka集群 kafka(Kafka with KRaft) mkdir -p ~/kafka-ymlkubectl create ns kafkacat > ~/kafka-yml/kafka.yml << EOF apiVersion: v1 kind: Service metadata:name: kafka-headlessnamespace: kafkalabels:app: kafka spec:type: C…...
 组合)
(C++回溯01) 组合
77、组合 回溯题目三步走 1. 确定参数 2. 确定终止条件 3. for 循环横向遍历,递归纵向遍历 class Solution { public:vector<vector<int>> result;vector<int> path;void backtracking(int n, int k, int startIndex) {if(path.size() k) {…...

k8s学习笔记——安装istio的仪表盘之prometheus安装
接上一篇,继续安装istio的dashboard。 先到istio-1.22.0/samples/addons目录下,把yaml文件中的镜像仓库地址修改了,修改地址参考我之前写的CSDN里的镜像对照表。不然直接执行kubectl apply -f samples/addons这个命令后,依据会出…...

四、GD32 MCU 常见外设介绍 (7) 7.I2C 模块介绍
7.1.I2C 基础知识 I2C(Inter-Integrated Circuit)总线是一种由Philips公司开发的两线式串行总线,用于内部IC控制的具有多端控制能力的双线双向串行数据总线系统,能够用于替代标准的并行总线,连接各种集成 电路和功能模块。I2C器件能够减少电…...
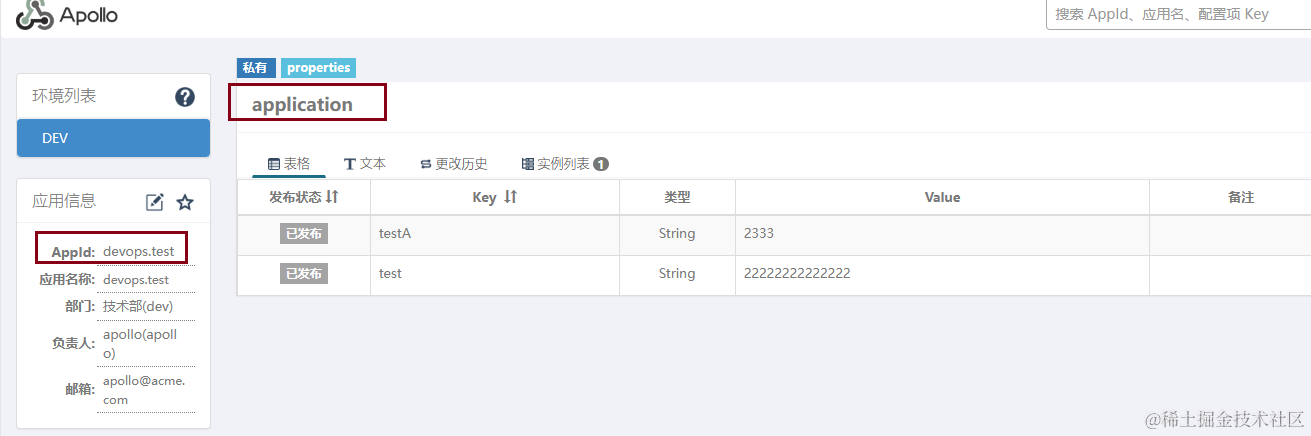
Apollo 配置中心的部署与使用经验
前言 Apollo(阿波罗)是携程开源的分布式配置管理中心。 本文主要介绍其基于 Docker-Compose 的部署安装和一些使用的经验 特点 成熟,稳定支持管理多环境/多集群/多命名空间的配置配置修改发布实时(1s)通知到应用程序支…...

Perl中的设计模式革新:命令模式的实现与应用
Perl中的设计模式革新:命令模式的实现与应用 在面向对象编程中,设计模式是解决特定问题的成熟模板。命令模式作为行为设计模式之一,它将请求封装为对象,从而允许用户根据不同的请求对客户进行参数化。本文将深入探讨如何在Perl中…...

Java8-求两个集合取交集
在Java8中,求两个集合的交集可以使用不同的三种方式:传统的循环遍历、使用Stream API的filter操作和使用Stream API的Collection操作。 方法一:传统的循环遍历 首先,我们创建两个集合list1和list2,并给它们添加一些元…...

爬虫学习4:爬取王者荣耀技能信息
爬虫:爬取王者荣耀技能信息(代码和代码流程) 代码 # 王者荣耀英雄信息获取 import time from selenium import webdriver from selenium.webdriver.common.by import By if __name__ __main__:fp open("./honorKing.txt", "…...

在Ubuntu 14.04上安装和使用Memcache的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 随着您的网站的增长和流量的增加,最快显示压力的组件之一是后端数据库。如果您的数据库没有分布式和配置来处理高负载…...

PCDN技术如何降低运营成本?
PCDN技术通过以下几种方式降低运营商的运营成本: 1.利用用户设备作为缓存节点: PCDN技术将用户设备纳入内容分发网络,利用这些设备的闲置带宽和存储资源来缓存和分发内容。这种方式不需要运营商投入大量的高成本服务器和带宽资源,从而降低了硬件和带宽…...

服务器数据恢复—V7000存储硬盘故障脱机的数据恢复案例
服务器存储数据恢复环境: 某品牌P740小型机AIXSybaseV7000磁盘阵列柜,磁盘阵列柜中有12块SAS机械硬盘(其中包括一块热备盘)。 服务器存储故障: 磁盘阵列柜中有一块磁盘出现故障,运维人员用新硬盘替换掉故障…...

BSV区块链在人工智能时代的数字化转型中的角色
发表时间:2024年6月13日 企业数字化转型已有约30年的历史,而人工智能(以下简称AI)将这种转型提升到了一个全新的高度。这并不难理解,因为AI终于使企业能够发挥其潜力,实现更宏大的目标。然而࿰…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍
Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中刷装备的漫长过程感到疲惫吗?Diablo Edit2这款免费…...