【Stable Diffusion】(基础篇五)—— 使用SD提升分辨率
使用SD提升分辨率
本系列博客笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili
在前期作画的时候,我有提到过,在第一次作画的时候图像分辨率不宜太高,因为过高的分辨率可能会爆显存,导致整个作画失败,但是分辨率低的图像质量不高,细节不够丰富,本文介绍如何使用AI提升图片分辨率
AI绘画是一个抽卡的过程,在前期,我们先使用低分辨率进行多批次的生成,找到喜欢的画面再对其进行高分辨率的修复,得到高质量的最终作品。在前期直接设置过高分辨率的话不仅有爆显存导致作画失败的风险,还可能出现同一张图中多个人物、肢体的混乱画面。SD为我们提供了多种放大图像分辨率的方法,下面我将为你一一介绍
高清修复
在文生图的众多参数中,有一个高分辨率修复的选项,我们将其选中之后会出来一系列的子菜单,因为高清修复的底层就是图生图功能,所以这些设置也是和图生图类似
-
迭代步数设置如果为零,它就会和我们上面设置好的迭代步数保持一致
-
重绘幅度和图生图中的重绘幅度是一个意思,表示在高清修复过程中和原图内容保持多大的一致性,在放大算法中,重绘幅度的设置最好不要超过0.5
-
放大倍数和宽高:在之前介绍的时候,最好把第一次绘图的分辨率设置为最终出图的等比例缩小,现在就可以直接设置倍数将其放大到我们原先设想的分辨率大小,或者是手动设置最终出图的宽高,放大倍率尽量不要大于2
-
放大算法:Latent潜变量算法可以帮助你添加更多的画面细节(尤其是二次元画面),如果不知道该如何选择,可以无脑选择R-ESRGAN 4x+ 二次元就算则带有Anime6B,或者在模型的详细介绍页面会有作者为我们提供建议某个模组最适合的放大算法

如果直接在图生图中操作效果也是一样的,使用高清修复和图生图一样,所以这种方法并没法突破显存的限制
SD Upscale放大
在图生图中,最下方的脚本可以选择SD Upscale,也会有一系列的子菜单选项
放大倍数就是图片大小的具体缩放倍数,放大算法也和上述提到的一样
原理是将图片切割后对每个局部进行高清修复,像素重叠可以将切割后的图片更加合理的拼接回去,使用SD放大时,要在设置好的宽高基础上加上重叠的像素值,比如原图是``600600,重叠像素设置为64,这时就要把原图尺寸设置为664664` ,如果选择放大两倍,得到的结果仍然是1200*1200,如果没有重叠像素的话,相邻图块重新拼回去的时候就会出现非常生硬的过渡边缘,重叠像素的作用类似于缓冲带,让图像拼接更加流畅。

优点:可以不太受到显存的限制,画面精细度高
缺点:分割的过程较为不可控(人脸等关键部位处于分割线的时候),可能会“加戏”出现原来没有的元素,此时就需要降低重绘幅度,尽量让结果和原图保持一致性
后期处理(最常用)
在SD的webUI中选择后期处理,使用其放大功能,这个操作逻辑和上面两种方法类似,选择合适的缩放比例和放大算法即可,它可以同时使用两种放大算法,很多时候不知道如何使用多种放大算法的话,可以不设置第二种算法,只使用一种算法就可以。其余的参数保持默认就好。

后期处理通过AI对分辨率实现提升,不涉及重绘,方便,高效,可以批量操作;
不改变图片内容,但细节丰富度等效果不太明显。
【示例】还是使用上一篇文章中lofi模型的例子,最开始生成500*500的图片,然后使用三种方法将其放大后观察效果,可以观察到不同放大功能对于细节增加的不同,如果你亲自实验一下这三种方法可以发现不同方法运行效率的不同
原图500*500:

高清修复1500*1500:

SD Upscale放大1000*1000:

后期处理1000*1000:

相关文章:
【Stable Diffusion】(基础篇五)—— 使用SD提升分辨率
使用SD提升分辨率 本系列博客笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili 在前期作画的…...

5.CSS学习(浮动)
浮动(float) 是一种传统的网页布局方式,通过浮动,可以使元素脱离文档流的控制,使其横向排列。 其编写在CSS样式中。 float:none(默认值) 元素不浮动。 float:left 设置的元素在其包含…...

Spring Cloud微服务项目统一封装数据响应体
在微服务架构下,处理服务之间的通信和数据一致性是一个重要的挑战。为了提高开发效率、保证数据的一致性及简化前端开发,统一封装数据响应体是一种非常有效的实践。本文博主将介绍如何在 Spring Cloud 微服务项目中统一封装数据响应体,并分享…...

java算法day20
java算法day20 701.二叉搜索树中的插入操作450.删除二叉搜索树中的节点108 将有序数组转换为二叉搜索树 本次的题目都是用递归函数的返回值来完成,多熟悉这样的用法,很方便。 其实我感觉,涉及构造二叉树的题目,用递归函数的返回值…...

web自动化测试-python+selenium+unitest
文章目录 Web自动化测试工具1. 主流的Web自动化测试工具2. Selenium家族史 Web自动化测试环境搭建基于Python环境搭建示例:通过程序启动浏览器,并打开百度首页,暂停3秒,关闭浏览器 页面元素定位1. 如何进行元素定位?2.…...

LeetCode题练习与总结:组合两个表--175
一、题目描述 SQL Schema > Pandas Schema > 表: Person ---------------------- | 列名 | 类型 | ---------------------- | PersonId | int | | FirstName | varchar | | LastName | varchar | ---------------------- personId 是该表的主…...

数据结构:二叉搜索树(简单C++代码实现)
目录 前言 1. 二叉搜索树的概念 2. 二叉搜索树的实现 2.1 二叉树的结构 2.2 二叉树查找 2.3 二叉树的插入和中序遍历 2.4 二叉树的删除 3. 二叉搜索树的应用 3.1 KV模型实现 3.2 应用 4. 二叉搜索树分析 总结 前言 本文将深入探讨二叉搜索树这一重要的数据结构。二…...

深入理解Prompt工程
前言:因为大模型的流行,衍生出了一个小领域“Prompt工程”,不知道大家会不会跟小编一样,不就是写提示吗,这有什么难的,不过大家还是不要小瞧了Prompt工程,现在很多大模型把会“Prompt工程”作为…...
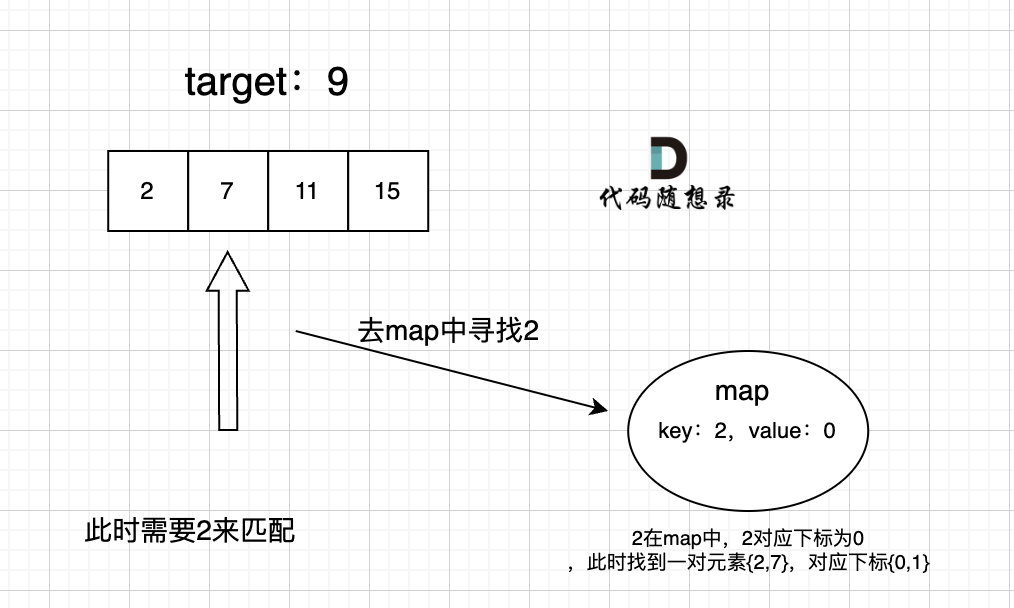
代码随想录算法训练营day6 | 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1.两数之和
文章目录 哈希表键值 哈希函数哈希冲突拉链法线性探测法 常见的三种哈希结构集合映射C实现std::unordered_setstd::map 小结242.有效的字母异位词思路复习 349. 两个数组的交集使用数组实现哈希表的情况思路使用set实现哈希表的情况 202. 快乐数思路 1.两数之和思路 总结 今天是…...

vue3 vxe-table 点击行,不显示选中状态,加上设置isCurrent: true就可以设置选中行的状态。
1、上个图,要实现这样的: Vxe Table v4.6 官方文档 2、使用 row-config.isCurrent 显示高亮行,当前行是唯一的;用户操作点击选项时会触发事件 current-change <template><div><p><vxe-button click"sel…...

Linux没有telnet 如何测试对端的端口状态
前段时间有人问uos没有telnet,又找不到包。 追问了一下为什么非要安装telnet,答复是要测试对端的端口号。 这里简单介绍一下,测试端口号的方法有很多,telent只是在windows上经常使用,linux已很少安装并使用该命令&…...

花几千上万学习Java,真没必要!(二十九)
1、基本数据类型包装类: 测试代码1: package apitest.com; //使用Integer类的不同方法处理整数。 //将字符串转换为整数(parseInt)和Integer对象(valueOf), //将整数转换回字符串(…...

C#如何引用dll动态链接库文件的注释
1、dll动态库文件项目生成属性中要勾选“XML文档文件” 注意:XML文件的名字切勿修改。 2、添加引用时XML文件要与DLL文件在同一个目录下。 3、如果要是添加引用的时候XML不在相同目录下,之后又将XML文件复制到相同的目录下,需要删除引用&am…...

WordPress原创插件:自定义文章标题颜色
插件设置截图 文章编辑时,右边会出现一个标题颜色设置,可以设置为任何颜色 更新记录:从输入颜色css代码,改为颜色选择器,更方便! 插件免费下载 https://download.csdn.net/download/huayula/89585192…...

Unity分享:继承自MonoBehaviour的脚步不要对引用类型的字段在声明时就初始化
如果某些字段在每个构造函数中都要进行初始化,很多人都喜欢在字段声明时就进行初始化,对于一个非继承自MonoBehaviour的脚步,这样做是没有问题的,然而继承自MonoBehaviour后就会造成内存的浪费,为什么呢?因…...

.NET Core中如何集成RabbitMQ
在.NET Core中集成RabbitMQ主要涉及到几个步骤,包括安装RabbitMQ的NuGet包、建立连接、定义队列、发送和接收消息等。下面是一个简单的指南来展示如何在.NET Core应用程序中集成RabbitMQ。 目录 1. 安装RabbitMQ.Client NuGet包 2. 建立连接 3. 定义队列 4. 发…...

嵌入式C++、STM32、MySQL、GPS、InfluxDB和MQTT协议数据可视化:智能物流管理系统设计思路流程(附代码示例)
目录 项目概述 系统设计 硬件设计 软件设计 系统架构图 代码实现 1. STM32微控制器与传感器代码 代码讲解 2. MQTT Broker设置 3. 数据接收与处理 代码讲解 4. 数据存储与分析 5. 数据分析与可视化 代码讲解 6. 数据可视化 项目总结 项目概述 随着电子商务的快…...

.net core docker部署教程和细节问题
在.NET Core中实现Docker一键部署,通常涉及以下几个步骤:编写Dockerfile以定义镜像构建过程、构建Docker镜像、运行Docker容器,以及(可选地)使用自动化工具如Docker Compose或CI/CD工具进行一键部署。以下是一个详细的…...

php数据库链接
Php超全局变量 GET 和 POST 都创建一个数组(例如 array( key1 > value1, key2 > value2, key3 > value3, ...))。此数组包含键/值对,其中 键是表单控件的名称,…...

python+vue3+onlyoffice在线文档系统实战20240726笔记,左侧菜单实现和最近文档基本实现
解决右侧高度过高的问题 解决方案:去掉右侧顶部和底部。 实现左侧菜单 最近文档,纯粹文档 我的文档,既包括文件夹也包括文件 共享文档,别人分享给我的 基本实现代码: 渲染效果: 简单优化 设置默认菜…...

Barlow字体完全指南:如何用这款开源字体提升设计质感
Barlow字体完全指南:如何用这款开源字体提升设计质感 【免费下载链接】barlow Barlow: a straight-sided sans-serif superfamily 项目地址: https://gitcode.com/gh_mirrors/ba/barlow 想要为你的设计项目寻找一款既现代又实用的免费字体吗?Barl…...

对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知 1. 从按需付费到套餐规划的成本视角转变 在直接使用各…...

Aseprite插件AseIcoExport:一键生成Windows与macOS应用图标
1. 项目概述:一个被低估的图标导出工具如果你是一个独立开发者,或者在一个小团队里负责UI/UX设计到前端实现的完整链路,那你一定对“图标导出”这个环节又爱又恨。爱的是,一个精心设计的图标集能让产品界面瞬间提升质感࿱…...

Windows: 深入剖析pip install SSLError与SSL模块缺失的根源及系统级修复
1. Windows下pip install SSLError的典型表现 最近在Windows系统上用pip安装Python包时,不少朋友都遇到了这样的报错信息:"Cant connect to HTTPS URL because the SSL module is not available"。这个错误通常会出现在使用清华源、阿里云源等…...

Flyway实战:从零到一构建数据库版本管理流水线
1. 为什么你的项目需要Flyway 第一次接触数据库版本管理这个概念时,我正面临一个典型的开发困境:团队里有5个开发人员在同时修改数据库结构,每次发布新版本都像在玩俄罗斯轮盘赌——永远不知道谁会忘记执行哪个SQL脚本。直到生产环境出现数据…...

Freewall跨浏览器兼容性:解决IE8+布局问题的完整方案
Freewall跨浏览器兼容性:解决IE8布局问题的完整方案 【免费下载链接】freewall kombai/freewall: Freewall 是一个灵活、响应式的网格布局引擎,可用于创建具有自适应布局功能的网页或应用组件,尤其适合于图片墙、瀑布流布局等场景。 项目地…...

CodMate:基于上下文感知的智能代码伴侣设计与实践
1. 项目概述:一个为开发者量身定制的代码伴侣如果你和我一样,每天大部分时间都在和代码编辑器、终端以及各种文档打交道,那你一定对“效率”这个词有很深的执念。我们总是在寻找能让自己写代码更快、调试更准、理解项目更轻松的工具。今天要聊…...

从硬开关到软开关:推挽谐振变换器原理与PSIM仿真实战
1. 从经典到谐振:为什么我们需要推挽变换器?在电源设计的工具箱里,推挽变换器(Push-Pull Converter)绝对算得上是一位“老将”。它的核心思想非常直观:利用一个带中心抽头的变压器,让两个开关管…...

终极RPG Maker视差地图插件指南:零代码打造专业级游戏场景
终极RPG Maker视差地图插件指南:零代码打造专业级游戏场景 【免费下载链接】RPGMakerMV RPGツクールMV、MZで動作するプラグインです。 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerMV 你是否曾经梦想创建拥有电影级视觉效果的RPG游戏地图…...

怎样免费去掉图片水印?2026年免费去水印工具推荐|在线vs软件对比
在日常工作和生活中,我们经常会遇到带有水印的图片。无论是来自社交媒体平台、在线图库还是其他来源,这些水印往往影响图片的使用效果。2026年,市面上出现了多种免费去水印工具,它们采用不同的技术方案,适用于不同的使…...