Python爬虫技术 第16节 XPath
XPath是一种在XML文档中查找信息的语言,尽管XML和HTML在语法上有区别,但XPath同样适用于HTML文档的解析,尤其是在使用如lxml这样的库时。XPath提供了一种强大的方法来定位和提取XML/HTML文档中的元素和属性。
XPath基础
XPath表达式由路径表达式组成,它们指定了文档中的位置。下面是一些基本的XPath语法:
-
根节点:
/表示绝对路径的开始,指向文档的根节点。//表示从当前位置到文档的任意位置。
-
元素选择:
elementName选择该名称下的所有子节点。@attributeName选择指定的属性。
-
路径操作:
child/选择当前节点的直接子节点。..移动到父节点。.当前节点。
-
位置路径:
last()返回集合中的最后一个节点的位置。position()返回节点在其父节点中的位置。
-
过滤器:
[condition]过滤节点,如[contains(text(), 'keyword')]。[1]选择第一个节点。[last()]选择最后一个节点。[position()=odd]选择位置为奇数的节点。
-
轴:
ancestor::*选择所有祖先节点。following-sibling::*选择当前节点之后的所有同级节点。preceding-sibling::*选择当前节点之前的所有同级节点。
使用Python和lxml库
假设你有以下HTML文档:
<div id="container"><h1>Title</h1><div class="content"><p>Paragraph 1</p><p>Paragraph 2</p></div><div class="sidebar"><ul><li>Item 1</li><li>Item 2</li></ul></div>
</div>
使用lxml库解析和提取数据:
from lxml import etreehtml = '''
<div id="container"><h1>Title</h1><div class="content"><p>Paragraph 1</p><p>Paragraph 2</p></div><div class="sidebar"><ul><li>Item 1</li><li>Item 2</li></ul></div>
</div>
'''root = etree.fromstring(html)# 获取标题
title = root.xpath('//h1/text()')
print("Title:", title[0])# 获取所有段落
paragraphs = root.xpath('//div[@class="content"]/p/text()')
print("Paragraphs:", paragraphs)# 获取列表项
items = root.xpath('//div[@class="sidebar"]/ul/li/text()')
print("Items:", items)
使用Scrapy框架
Scrapy是一个用于Web爬取的框架,内置支持XPath和CSS选择器。下面是如何在Scrapy项目中使用XPath:
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):# 获取标题title = response.xpath('//h1/text()').get()yield {'title': title}# 获取所有段落paragraphs = response.xpath('//div[@class="content"]/p/text()').getall()yield {'paragraphs': paragraphs}# 获取列表项items = response.xpath('//div[@class="sidebar"]/ul/li/text()').getall()yield {'items': items}
XPath与CSS选择器的比较
虽然XPath提供了更强大的查询能力,但CSS选择器通常在HTML文档中更直观易读。XPath更适合处理复杂的查询,尤其是在需要跨层级或根据条件过滤节点的情况下。然而,对于简单的结构化文档,CSS选择器往往足够使用,而且代码更为简洁。
在实际应用中,可以根据具体需求和文档结构选择使用XPath或CSS选择器。大多数现代的Python Web爬取库都同时支持这两种选择器。
当然,可以考虑以下几个方面:增加错误处理、处理更复杂的HTML结构、提取嵌套数据以及执行多次请求来处理动态加载的内容。下面我将展示如何使用Python和lxml库来实现这些功能。
错误处理和异常管理
在使用XPath进行网页爬取时,应考虑到可能发生的错误,如网络问题、无效的XPath表达式、找不到期望的元素等。这里是一个带有错误处理的示例:
from lxml import etree
import requestsdef fetch_html(url):try:response = requests.get(url)response.raise_for_status()return response.textexcept requests.RequestException as e:print(f"Request error: {e}")return Nonedef parse_html(html):if html is None:print("Failed to fetch HTML")returntry:tree = etree.HTML(html)title = tree.xpath('//h1/text()')if title:print("Title:", title[0])else:print("Title not found")paragraphs = tree.xpath('//div[@class="content"]/p/text()')if paragraphs:print("Paragraphs:", paragraphs)else:print("No paragraphs found")items = tree.xpath('//div[@class="sidebar"]/ul/li/text()')if items:print("Items:", items)else:print("No items found")except etree.XPathEvalError as e:print(f"XPath evaluation error: {e}")def main():url = "http://example.com"html = fetch_html(url)parse_html(html)if __name__ == "__main__":main()
处理更复杂的HTML结构
有时网页结构可能包含嵌套的元素,或者有多个相似的元素。XPath允许你使用更复杂的表达式来处理这些情况。例如,如果每个列表项都有额外的信息,可以使用如下XPath表达式:
items_with_details = tree.xpath('//div[@class="sidebar"]/ul/li')
for item in items_with_details:item_text = item.xpath('./text()')item_link = item.xpath('.//a/@href')print("Item:", item_text, "Link:", item_link)
处理动态加载的内容
如果网站使用JavaScript动态加载内容,单次请求可能无法获取全部数据。在这种情况下,可以使用Selenium或Requests-HTML库来模拟浏览器行为。以下是使用Requests-HTML的示例:
from requests_html import HTMLSessionsession = HTMLSession()def fetch_and_render(url):r = session.get(url)r.html.render(sleep=1) # Wait for JavaScript to executereturn r.html.raw_html.decode('utf-8')def main():url = "http://example.com"html = fetch_and_render(url)tree = etree.HTML(html)# Now you can use XPath on the rendered HTML...if __name__ == "__main__":main()
请注意,使用像Selenium这样的工具可能会显著增加你的爬虫脚本的资源消耗和运行时间,因为它模拟了一个完整的浏览器环境。
通过这些扩展,你的XPath代码将更加健壮,能够处理更复杂和动态的网页结构。在开发爬虫时,始终记得遵守网站的robots.txt规则和尊重网站的使用条款,避免过度请求导致的服务压力。
接下来,我们可以引入一些最佳实践,比如:
- 模块化:将代码分解成多个函数,提高可读性和可维护性。
- 参数化:使函数接受参数,以便于复用和配置。
- 日志记录:记录关键步骤和潜在的错误信息,便于调试和监控。
- 并发处理:利用多线程或多进程处理多个URL,提高效率。
- 重试机制:在网络不稳定时自动重试失败的请求。
- 数据存储:将提取的数据保存到文件或数据库中。
下面是一个使用上述最佳实践的代码示例:
import logging
import requests
from lxml import etree
from time import sleep
from concurrent.futures import ThreadPoolExecutor, as_completedlogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')def fetch_html(url, max_retries=3, delay=1):"""Fetch HTML from a given URL with retry mechanism."""for attempt in range(max_retries):try:response = requests.get(url)response.raise_for_status()return response.textexcept requests.RequestException as e:logging.error(f"Error fetching URL: {url}, attempt {attempt + 1}/{max_retries}. Error: {e}")if attempt < max_retries - 1:sleep(delay * (attempt + 1)) # Exponential backoffreturn Nonedef parse_html(html, xpath_expression):"""Parse HTML using provided XPath expression."""if html is None:logging.error("Failed to fetch HTML")return Nonetry:tree = etree.HTML(html)result = tree.xpath(xpath_expression)return resultexcept etree.XPathEvalError as e:logging.error(f"XPath evaluation error: {e}")return Nonedef save_data(data, filename):"""Save data to a file."""with open(filename, 'w') as f:f.write(str(data))def process_url(url, xpath_expression, output_filename):"""Process a single URL by fetching, parsing, and saving data."""logging.info(f"Processing URL: {url}")html = fetch_html(url)data = parse_html(html, xpath_expression)if data:save_data(data, output_filename)logging.info(f"Data saved to {output_filename}")def main(urls, xpath_expression, output_dir):"""Main function to process multiple URLs concurrently."""with ThreadPoolExecutor(max_workers=5) as executor:futures = []for url in urls:output_filename = f"{output_dir}/data_{url.split('/')[-1]}.txt"future = executor.submit(process_url, url, xpath_expression, output_filename)futures.append(future)for future in as_completed(futures):future.result()if __name__ == "__main__":urls = ["http://example1.com", "http://example2.com"]xpath_expression = '//div[@class="content"]/p/text()' # Example XPath expressionoutput_dir = "./output"main(urls, xpath_expression, output_dir)
在这个例子中,我们定义了以下几个关键函数:
fetch_html:负责从URL获取HTML,具有重试机制。parse_html:使用提供的XPath表达式解析HTML。save_data:将数据保存到文件。process_url:处理单个URL,包括获取HTML、解析数据并保存。main:主函数,使用线程池并行处理多个URL。
这种结构允许你轻松地扩展爬虫的功能,比如添加更多的URL或XPath表达式,同时保持代码的清晰和可维护性。
相关文章:

Python爬虫技术 第16节 XPath
XPath是一种在XML文档中查找信息的语言,尽管XML和HTML在语法上有区别,但XPath同样适用于HTML文档的解析,尤其是在使用如lxml这样的库时。XPath提供了一种强大的方法来定位和提取XML/HTML文档中的元素和属性。 XPath基础 XPath表达式由路径表…...

本地部署,Whisper: 开源语音识别模型
目录 简介 特点 应用 使用方法 总结 GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak SupervisionRobust Speech Recognition via Large-Scale Weak Supervision - openai/whisperhttps://github.com/openai/whisper 简介 Whisper 是一个由 O…...

history,hash缓存那些事
vue-router 中的 createWebHistory,createWebHashHistory两种模式 createWebHistory 是基于 window.history 对象是HTML5提供的用于维护当前标签页浏览历史的对象,主要功能是前进后退和在不刷新页面的情况下,修改地址栏里的URL地址。histor…...

Spring Boot的Web开发
目录 Spring Boot的Web开发 1.静态资源映射规则 第一种静态资源映射规则 2.enjoy模板引擎 3.springMVC 3.1请求处理 RequestMapping DeleteMapping 删除 PutMapping 修改 GetMapping 查询 PostMapping 新增 3.2参数绑定 一.支持数据类型: 3.3常用注解 一.Request…...

Spark 解析嵌套的 JSON 文件
1、什么是嵌套的JSON文件? 嵌套的JSON文件是指文件中包含了嵌套的JSON对象或数组。例如,以下是一个嵌套的JSON文件的示例: {"name": "John","age": 30,"address": {"street": "123…...
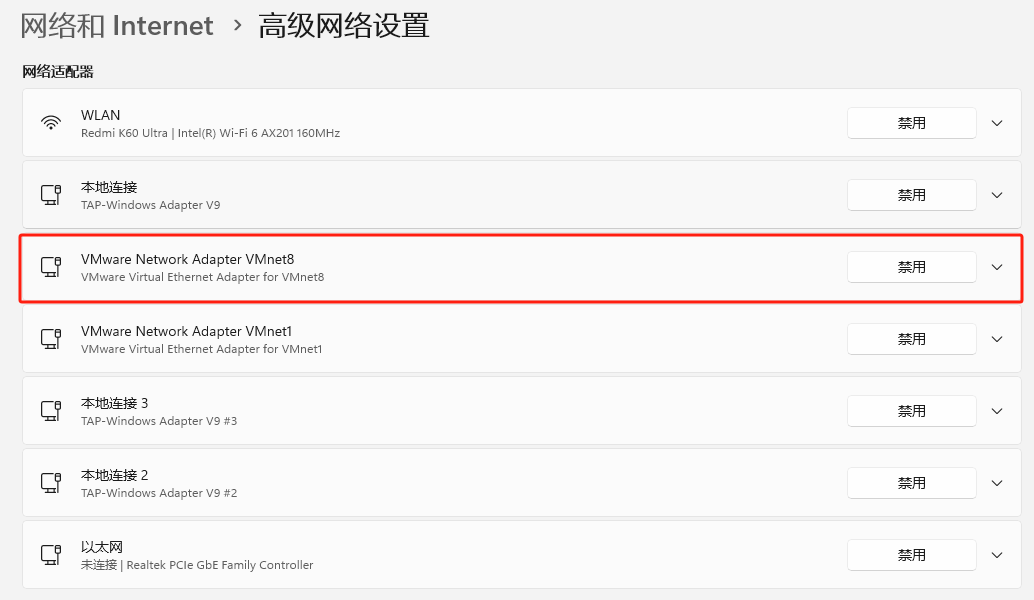
VMware虚拟机中CentOS7自定义ip地址并且固定ip
配置固定ip(虚拟机) 前提:虚拟机网络配置成,自定义网络并选择VMnet8(NAT 模式) 操作(如下图):点击虚拟机–》设置–》–》硬件–》网络适配器–》自定义:特定虚拟网络–》选择:VMnet8(NAT 模式) 虚拟机网络设置 需要记…...

CCS(Code Composer Studio 10.4.0)编译软件中文乱码怎么解决
如果是所有文件都出现了中文乱码这时建议直接在窗口首选项中修改:选择"Window" -> "Preferences",找到"General" -> "Workspace",将"Text file encoding"选项设置为"Other&quo…...

Flutter 3 完全支持网页端
Flutter 3 可以用于开发网页端应用。自 Flutter 2.0 起,Flutter 就已经支持 Web 平台,并且在 Flutter 3 中得到了进一步的改进和优化。以下是使用 Flutter 3 开发网页端的一些优势和特点: Flutter 3 开发网页端的优势: 跨平台一致…...

vue.js入门
目录 一. 框架概述 二. vue常用命令 2.1 插值表达式 2.2 v-text 2.3 v-html 2.4 v-on 2.5 v-model 2.6 v-show 2.7 v-if 2.8 v-else 2.9 v-bind 2.10 v-for 三. vue生命周期函数 目录 一. 框架概述 二. vue常用命令 2.1 插值表达式 2.2 v-text 2.3 v-html 2…...

API签名认证
前言(项目背景): 这个API签名认证是API开放平台得一个重要环节,我们知道,这个API开发平台,用处就是给客户去调用现成得接口来完成某些事情得。 在讲API签名认证之前,我们先模拟一个场景并且介绍…...
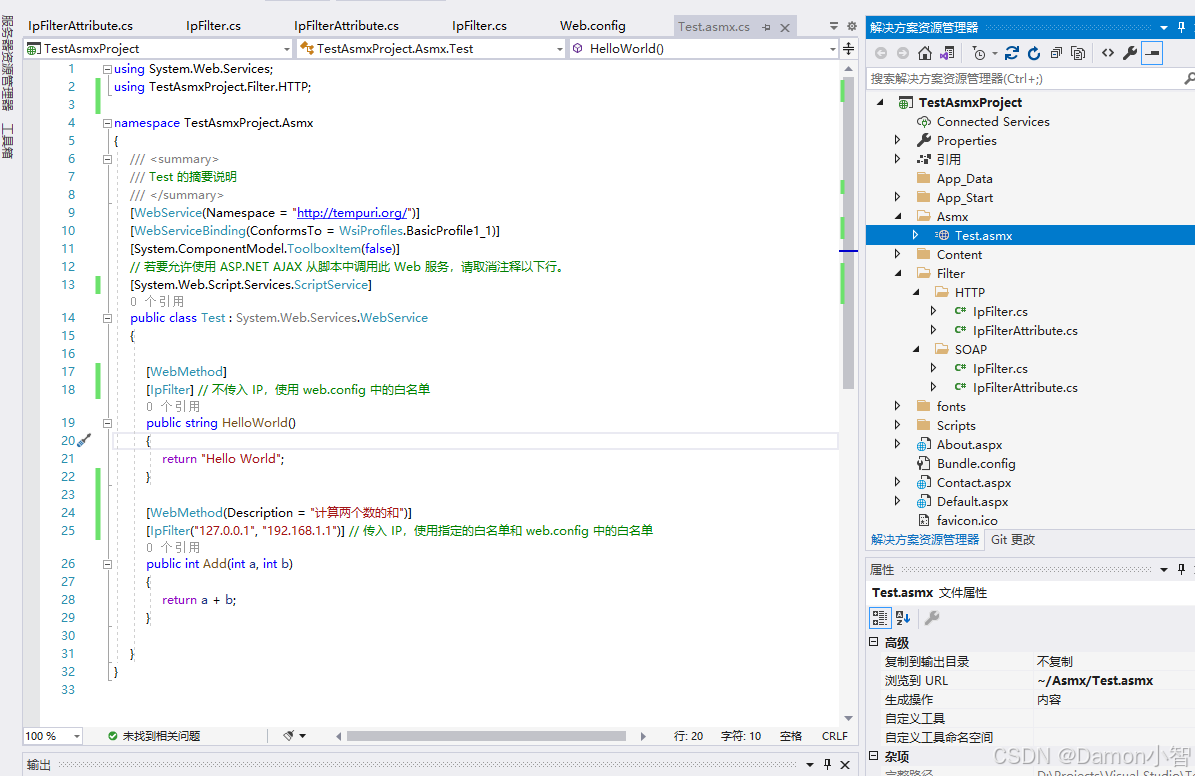
C#进阶-基于.NET Framework 4.x框架实现ASP.NET WebForms项目IP拦截器
在这篇文章中,我们将探讨如何在 ASP.NET WebForms 中实现IP拦截器,以便在 ASMX Web 服务方法 和 HTTP 请求 中根据IP地址进行访问控制。我们将使用自定义的 SoapExtension 和 IHttpModule 来实现这一功能,并根据常用的两种文本传输协议&#…...

前端(1)HTML
1、标签 创建1.html文件,浏览器输入E:/frontheima/1.html,可以访问页面 页面展示 在VSCODE安装IDEA的快捷键,比如ctld复制一行、ctrlx剪切 <p id"p1" title"标题1">Hello,world!</p> <p id"p2"…...

【北京迅为】《i.MX8MM嵌入式Linux开发指南》-第三篇 嵌入式Linux驱动开发篇-第五十三章 设备树下的platform驱动
i.MX8MM处理器采用了先进的14LPCFinFET工艺,提供更快的速度和更高的电源效率;四核Cortex-A53,单核Cortex-M4,多达五个内核 ,主频高达1.8GHz,2G DDR4内存、8G EMMC存储。千兆工业级以太网、MIPI-DSI、USB HOST、WIFI/BT…...

Java正则表达式判断有无特殊字符
//^代表否定,匹配除了数字、字母、下划线的特殊字符。 private static final String SPECIAL_CHAR_PATTERN "[^a-zA-Z0-9_]"; Pattern pattern Pattern.compile(SPECIAL_CHAR_PATTERN); Matcher matcher pattern.matcher(userAccount); // 如果 find(…...

使用Java和Spring AMQP构建消息驱动应用
使用Java和Spring AMQP构建消息驱动应用 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 消息驱动应用程序在现代系统架构中扮演着重要角色,特别是在处理高并发和异步任务时。Spring AMQ…...

【NLP】提升文本生成多样性的实用方法
比如用T5模型,训练数据是inputText-outputText格式,预测时do_sample=False # 预测代码from transformers import TFAutoModelForSeq2SeqLM from transformers import AutoTokenizercheckpoint_local = "./path/" tokenizer = AutoTokenizer.from_pretrained(check…...

鸿蒙(HarmonyOS)下拉选择控件
一、操作环境 操作系统: Windows 11 专业版、IDE:DevEco Studio 3.1.1 Release、SDK:HarmonyOS 3.1.0(API 9) 二、效果图 三、代码 SelectPVComponent.ets Component export default struct SelectPVComponent {Link selection: SelectOption[]priva…...

Java类加载器实现机制详细笔记
1. 类加载器的基本概念 类加载器(ClassLoader):在Java中,类加载器负责将Java类动态加载到JVM中。它是实现动态类加载机制的核心组件,对于开发复杂应用程序(如插件系统、模块化设计等)至关重要。…...

Git之repo sync -l与repo forall -c git checkout用法区别(四十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

【公式解释】《系统论》《控制论》《信息论》的共同重构:探索核心公式与深度解析
《系统论》《控制论》《信息论》的共同重构:探索核心公式与深度解析 关键词:系统论、控制论、信息论、状态空间方程、系统矩阵。 Keywords: System theory, Control theory, Information theory, State-space equations, System matrices. 核心公式与三论共同之处 在系统…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览
跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 想象一下,当你浏览外文网页时…...

LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南
LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

基于BLE与CircuitPython的无线8-bit音乐合成器DIY全攻略
1. 项目概述与核心思路想不想亲手做一个能揣在口袋里,随时随地弹奏出复古8-bit音乐的小玩意儿?不是那种手机App模拟的,而是实实在在的、有物理按键、能无线连接、还会发光的小合成器。今天分享的这个项目,就是基于两块小巧但功能强…...

【模块化设计-10】UART1 驱动 + 环形 FIFO 实现高效串口数据收发
在嵌入式开发中,串口(UART)是最常用的通信接口之一,而直接采用中断 缓冲区的方式处理串口数据,能有效避免数据丢失、提升收发效率。本文将基于实际项目代码,详解UART1 驱动与环形 FIFO(ring_fi…...

260513实训:路由器连接
路由器工作原理: 转发动作:路由器收到数据后,根据目的IP地址查路由器路由表(地图)转发 路由表:路由器默认会将直连网段加入路由表 查看IP路由表:display ip routing-table 127.0.0.0/8 本地环…...

Java程序员必看:收藏这份2026大模型转型攻略,小白也能轻松入行高薪赛道!
Java程序员必看:收藏这份2026大模型转型攻略,小白也能轻松入行高薪赛道! 随着大模型(LLMs)成为IT行业新质生产力的核心引擎,2026年国内大模型核心市场规模将突破700亿元,人才缺口达200万。本文专…...

【最新 v2.7.1 版本】5 分钟搞定 OpenClaw Windows 环境部署配置
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...
)
避开这3个坑,你的MAX30102心率数据才准确(Arduino实测经验)
避开这3个坑,你的MAX30102心率数据才准确(Arduino实测经验) 在可穿戴设备和健康监测领域,MAX30102传感器因其集成度高、体积小巧而广受欢迎。但许多开发者在使用过程中常遇到数据不稳定、读数漂移等问题。本文将基于实际项目经验&…...

回溯52-59
52. 全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 class Solution(object):def fun(self,nums,path):if len(path)len(nums):self.res.append(path[:])for i in range(len(nums)):if self.visit[i]0:self.vi…...