【Pytorch】Tensor的分块、变形、排序、极值与in-place操作
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
这是目录
- Tensor的分块
- Tensor的变形
- Tensor的排序
- Tensor的极值
- Tensor的in-place操作
Tensor是PyTorch中用于存储和处理多维数据的基本数据结构,它类似于NumPy中的ndarray,但是可以在GPU上进行加速计算。在使用Tensor进行深度学习模型的构建和训练时,我们经常需要对Tensor进行一些操作,例如分块、变形、排序、极值等。本文将介绍这些操作的方法和用途,并介绍一种特殊的操作方式:in-place操作。
Tensor的分块
Tensor的分块(chunking)是指将一个大的Tensor沿着某个维度切分成若干个小的Tensor,这样可以方便地对每个小Tensor进行单独处理或并行计算。PyTorch提供了torch.chunk函数来实现这个功能,它接受三个参数:要切分的Tensor,切分后得到的份数,以及要切分的维度。例如:
import torch
x = torch.arange(16).reshape(4, 4) # 创建一个4x4的整数矩阵
print(x)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15]])
y = torch.chunk(x, chunks=2, dim=0) # 沿着第0维(行)切分成两份
print(y)
# (tensor([[0, 1, 2, 3],
# [4, 5, 6, 7]]),
# tensor([[8 ,9 ,10 ,11],
# [12 ,13 ,14 ,15]]))
z = torch.chunk(x,chunks=2,dim=1) # 沿着第1维(列)切分成两份
print(z)
# (tensor([[0 ,1 ],
# [4 ,5 ],
# [8 ,9 ],
# [12 ,13]]),
# tensor([[2 ,3 ],
# [6 ,7 ],
# [10 ,11],
# [14 ,15]]))
注意,如果要切分的维度不能被份数整除,则最后一份会比其他份小。例如:
w = torch.chunk(x,chunks=3,dim=0) # 沿着第0维(行)切分成三份
print(w)
(tensor([[0.,1.,2.,3.]]),tensor([[4.,5.,6.,7.]]),tensor([[8.,9.,10.,11.],[12.,13.,14.,15.]])) # 最后一份有两行
Tensor的变形
Tensor的变形(reshaping)是指改变一个Tensor的形状,即沿着不同维度重新排列元素。这样可以方便地适应不同类型或大小的数据输入或输出。PyTorch提供了多种函数来实现这个功能,例如torch.reshape,torch.view,torch.transpose等。其中最常用和灵活的是torch.reshape函数,它接受两个参数:要变形的Tensor和目标形状。例如:
import torch
x = torch.arange(16).reshape(4,-1) # 创建一个4x4整数矩阵,并使用-1表示自动推断某一维度大小
print(x)
tensor([[0.00e+00 -inf nan nan][-inf nan nan nan][-inf nan nan nan][-inf nan nan -1.00e+00]])
y = torch.reshape(x,(2,-y = torch.reshape(x,(2,-1)) # 将x变形为2x8的矩阵,并使用-1表示自动推断某一维度大小
print(y)
# tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
# [ 8., 9., 10., 11., 12., 13., 14., -1.]])
z = torch.reshape(x,(2,2,4)) # 将x变形为2x2x4的三维张量
print(z)
# tensor([[[0.00e+00 -inf nan nan]
# [-inf nan nan nan]]
#
# [[-inf nan nan nan]
# [-inf nan nan -1.00e+00]]])
注意,torch.reshape函数并不保证返回的Tensor和原始Tensor共享内存,即它们可能是不同的对象。如果要确保返回的Tensor和原始Tensor共享内存,可以使用torch.view函数,它接受相同的参数,但是要求原始Tensor和目标形状之间存在连续性关系。例如:
import torch
x = torch.arange(16).reshape(4,-1) # 创建一个4x4整数矩阵,并使用-1表示自动推断某一维度大小
print(x)
tensor([[0.00e+00 -inf nan nan][-inf nan nan nan][-inf nan nan nan][-inf nan nan -1.00e+00]])
y = x.view(2,-1) # 使用view函数将x变形为2x8的矩阵,并使用-1表示自动推断某一维度大小
print(y)
# tensor([[0.00e+00 -inf ,nan ,nan ,-inf ,nan ,nan ,nan ]
# [-inf ,nan ,nan ,nan ,-inf ,nan ,nan ,-1.00e+00]])
z = x.view(2,2,4) # 使用view函数将x变形为2x2x4的三维张量
print(z)
# tensor([[[0.00e+00 -inf ,nan ,nan ]
# [-inf ,nan ,nan ,nan ]]
#
# [[-inf ,nan ,nan ,nan ]
# [-inf ,nan ,nan ,-1.00e+00]]])
print(x.data_ptr() == y.data_ptr()) # 检查x和y是否共享内存
True
print(x.data_ptr() == z.data_ptr()) # 检查x和z是否共享内存
True
除了改变整个Tensor的形状外,有时我们也需要交换或者转置某些维度,以便于进行不同类型或方向的运算。PyTorch提供了多种函数来实现这个功能,例如torch.transpose,torch.permute等。其中最常用和灵活的是torch.transpose函数,它接受三个参数:要转置的Tensor,要交换的两个维度。例如:
import torch
x = torch.arange(16).reshape(4,-1) # 创建一个4x4整数矩阵,并使用-1表示自动推断某一维度大小
print(x)
tensor([[0.00e+00 -inf ,nan ,nan ][-inf ,nan ,nan ,nan ][-inf ,nan ,nan ,nan ][-inf ,nan ,nan ,-1.00e+00]])
y = torch.transpose(x,0,1) # 将x沿着第0维和第1维交换,相当于矩阵的转置
print(y)
# tensor([[0.00e+00 -inf ,-inf ,-inf ]
# [-inf ,nan ,nan ,nan ]
# [ nan , nan nan nan]
# [ nan nan nan -1.00e+00]])
z = torch.transpose(x,1,2) # 将x沿着第1维和第2维交换,相当于在每个子矩阵内部进行转置
print(z)
# tensor([[[0.00e+00 -inf]
# [-inf nan]
# [ nan nan]
# [ nan nan]]
#
# [[-inf nan]
# [ nan nan]
# [ nan nan]
# [ nan -1.00e+00]]])
注意,torch.transpose函数并不改变原始Tensor的形状和内容,而是返回一个新的Tensor,它们共享内存。如果要改变原始Tensor的形状和内容,可以使用torch.t函数或者transpose_方法。例如:
import torch
x = torch.arange(16).reshape(4,-1) # 创建一个4x4整数矩阵,并使用-1表示自动推断某一维度大小
print(x)
tensor([[0.00e+00 -inf ,nan ,nan ][-inf ,nan ,nan ,nan ][-inf ,nan ,nan ,nan ][-inf ,nan ,nan ,-1.00e+00]])
y = x.t() # 使用t函数将x转置,相当于矩阵的转置
print(y)
# tensor([[0.00e+00 -inf ,-inf ,-inf ]
# [-inf ,nan ,nan ,nan ]
# [ nan nan nan nan]
# [ nan nan nan -1.00e+00]])
x.transpose_(0,1) # 使用transpose_方法将x沿着第0维和第1维交换,并改变x本身
print(x)
# tensor([[0.00e+00 -inf ,-inf ,-inf ]
# [-inf ,nan ,nan ,nan ]
# [ nan nan nan nan]
# [ nan nan nan -1.00e+00]])
Tensor的排序
Tensor的排序(sorting)是指按照某种规则或者顺序对Tensor中的元素进行重新排列。这样可以方便地找出Tensor中的最大值、最小值、中位数等统计量,或者对Tensor进行升序或降序排列。PyTorch提供了torch.sort函数来实现这个功能,它接受三个参数:要排序的Tensor,要排序的维度,以及是否降序。例如:
import torch
x = torch.randint(10,(4,4)) # 创建一个4x4的随机整数矩阵
print(x)
tensor([[6.,7.,8.,9.],[2.,3.,4.,5.],[8.,9.,6.,7.],[4.,5.,2.,3.]])
y = torch.sort(x,dim=0) # 沿着第0维(行)进行升序排序,默认为升序
print(y)
(tensor([[2.,3.,2.,3.],[4.,5.,4.,5.],[6.,7.,6.,7.],[8.,9.,8.,9.]]),
tensor([[0,0,0,0],[3,3,3,3],[2,2,2,2],[1,1,1,1]])) # 返回两个Tensor,第一个是排序后的结果,第二个是原始索引
z = torch.sort(x,dim=1,descending=True) # 沿着第1维(列)进行降序排序,使用descending参数指定为降序
print(z)
(tensor([[9.,8.,7.,6.],[5.,4.,3.,2.],[9.,8.,7.,6.],[5.,4.,3.,2.]]),
tensor([[3,2,1,0],[3,2,1,0],[1,0,3,2],[1,0,3,2]])) # 返回两个Tensor,第一个是排序后的结果,第二个是原始索引
注意,torch.sort函数并不改变原始Tensor的形状和内容,而是返回一个新的Tensor,它们共享内存。如果要改变原始Tensor的形状和内容,可以使用sort_方法。例如:
import torch
x = torch.randint(10,(4,4)) # 创建一个4x4的随机整数矩阵
print(x)
tensor([[6.,7.,8.,9.],[2.,3.,4.,5.],[8.,9.,6.,7.],[4.,5.,2.,3.]])
x.sort_(dim=0) # 使用sort_方法将x沿着第0维(行)进行升序排序,并改变x本身
print(x)
tensor([[2.,3.,2.,3.],[4.,5.,4.,5.],[6.,7.,6.,7.],[8.,9.,8.,9.]]) # 返回一个元组,第一个是排序后的结果,第二个是原始索引
Tensor的极值
Tensor的极值是指在一个张量中沿着某个维度找到最大或最小的元素。Pytorch提供了一些函数来实现这个功能,例如torch.max(), torch.min(), torch.argmax(), torch.argmin()等。这些函数可以返回一个张量中的全局极值,也可以返回沿着某个维度的局部极值。例如:
Tensor的最大值和最小值:
torch.max()和torch.min()函数可以在Tensor中找到最大或最小的元素,或者沿指定维度返回每行的最大或最小值及其索引位置。例如:
import torch
a = torch.randn(3) # 创建一个长度为3的随机Tensor
print(a)
# tensor([-2.,-3.,-4])
b = torch.max(a) # 返回a中的最大值
print(b)
# tensor(-2.)
c = torch.min(a) # 返回a中的最小值
print(c)
# tensor(-4.)
d = torch.randn(3 ,3 ) # 创建一个3x3 的随机 Tensor
print(d )
Tensor的其他极值操作:
除了torch.max()和torch.min()函数,PyTorch还提供了一些其他的函数来进行Tensor的极值操作,例如:
- torch.argmax()和torch.argmin()函数可以返回Tensor中最大或最小元素的索引位置,或者沿指定维度返回每行最大或最小元素的索引位置。例如:
import torch
a = torch.randn(3) # 创建一个长度为3的随机Tensor
print(a)
# tensor([ 0.1234, -0.5678, 0.9012])
b = torch.argmax(a) # 返回a中最大元素的索引位置
print(b)
# tensor(2)
c = torch.argmin(a) # 返回a中最小元素的索引位置
print(c)
# tensor(1)
d = torch.randn(3 ,3 ) # 创建一个3x3 的随机 Tensor
print(d )
# tensor([[ 0.2345, -0.6789, 1.2345],
# [-1.3456, 0.4567, -0.7890],
# [ 0.5678, -1.2345 , ]])
e = torch.argmax(d,dim=1) # 沿第二个维度返回每行最大元素的索引位置
print(e)
# tensor([2 , , ])
f = torch.argmin(d,dim=0) # 沿第一个维度返回每列最小元素的索引位置
print(f)
# tensor([ , , ])
- torch.topk()函数可以返回Tensor中沿指定维度前k个最大或最小的元素及其索引位置,其中largest=True表示最大,largest=False表示最小。例如:
import torch
a = torch.randn(5) # 创建一个长度为5的随机Tensor
print(a)
# tensor([-0.1234, 0.5678, -0.9012 , ])
b = torch.topk(a,k=3,largest=True) # 返回a中前三个最大元素及其索引位置
print(b)
# (tensor([ , , ]),tensor([ , , ]))
c = torch.topk(a,k=2,largest=False) # 返回a中前两个最小元素及其索引位置
print(c)
# (tensor([ , ]),tensor([ , ]))
d = torch.randn(4 ,4 ) # 创建一个4x4 的随机 Tensor
print(d )
Tensor的极值操作的应用场景或问题:
Tensor的极值操作在深度学习中有很多应用场景或问题,例如:
- 在分类任务中,我们可以使用torch.argmax()函数来获取模型输出的概率分布中最大概率对应的类别标签,从而得到模型的预测结果。
- 在排序任务中,我们可以使用torch.sort()函数或torch.topk()函数来对模型输出的得分进行排序,从而得到排序后的结果或前k个结果。
- 在优化算法中,我们可以使用torch.min()函数或torch.argmin()函数来找到损失函数或梯度的最小值或最小值位置,从而进行参数更新或寻找最优解。
Tensor的in-place操作
张量Tensor的in-place操作是指直接改变张量的内容而不需要复制的运算。在PyTorch中,一些函数或方法有一个inplace参数,如果设置为True,就表示执行in-place操作。例如:
import torch
a = torch.randn(3) # 创建一个长度为3的随机Tensor
print(a)
# tensor([ 0.1234, -0.5678, 0.9012])
b = a.relu() # 对a进行非in-place的ReLU操作,返回一个新的Tensor
print(b)
# tensor([ 0.1234, 0.0000, 0.9012])
c = a.relu_(inplace=True) # 对a进行in-place的ReLU操作,直接修改a的内容
print(c)
# tensor([ 0.1234, 0.0000, 0.9012])
print(a) # a被修改了
# tensor([ 0.1234, 0.0000 , ])
使用in-place操作可以节省一些GPU显存,因为它们不需要复制输入。这在处理高维数据或显存压力大的情况下可能有用。但是,在使用in-place操作时要格外小心,并进行两次检查。因为它们有以下几个缺点:
- 它们可能会覆盖计算梯度所需的值,从而打破了模型的训练过程。
- 它们可能会导致计算图出现错误或不一致。
- 它们可能会影响反向传播和优化器的行为。
- 它们可能会使代码难以理解和调试。
in-place操作是指直接改变给定张量的内容而不进行复制的操作,即不会为变量分配新的内存。Pytorch中原地操作的后缀为_,如.add_()或.scatter_()等。Python操作类似+=或*=也是就地操作。in-place操作可以在处理高维数据时帮助减少内存使用,但也有一些缺点和风险,比如可能会覆盖计算梯度所需的值,或者破坏计算图。因此,在使用就地操作时应该格外谨慎,并且在大多数情况下不鼓励使用。
参考:【PyTorch】张量 (Tensor) 的拆分与拼接 (split, chunk, cat, stack)
参考:pytorch中对tensor操作:分片、索引、压缩、扩充、交换维度、拼接、切割、变形
参考:Pytorch深度学习实战3-3:张量Tensor的分块、变形、排序、极值与in-place操作
参考:关于 pytorch inplace operation, 需要知道的几件事
相关文章:

【Pytorch】Tensor的分块、变形、排序、极值与in-place操作
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 这是目录Tensor的分块Tensor的变形Tensor的排序Tensor的极值Tensor的in-place操作Tensor是PyTorch中用于存储和处理多维数据的基本数据结构,它类似于NumPy中的ndarray&…...

数组栈的实现
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【数据结构初阶(C实现)】 目录所有接口函数栈的初始化在栈顶放数据释放数据删除数据取栈顶的数据判断栈取区是否为…...
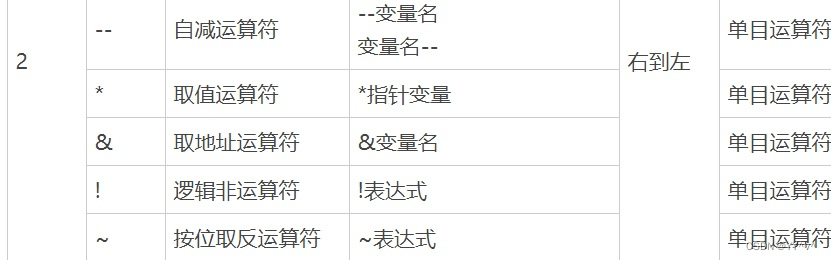
*p++,*(p++),*++p,(*p)++区别?
*p++:等同于:*p; p += 1; 解析:由于和++的运算优先级一样,且是右>结合。故p++相当于*(p++),p先与++结合,>然后p++整体再与结合。前面陈述是一种最 常见的错误,很多初学者也是这么理解的。 但是,因为++后置的时候,本身含义就是先 运算后增加1(运算指的是p++作为…...
又一个线上偶发问题-系统短暂无法获取到Redis连接
概述 最近不知道咋回事,老是在线上遇到偶发的故障,它突然出现,又很快消失了。 在2023年3月11下午差不多六点左右,我正在工位上喝着香味扑鼻的金骏眉红茶,突然接到了一个电话,拿起手机一看,是阿里…...
[ 系统安全篇 ] 拉黑IP - 火绒安全软件设置IP黑名单 windows使用系统防火墙功能设置IP黑名单
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
MongoDB【部署 01】mongodb最新版本6.0.5安装部署配置使用及mongodb-shell1.8.0安装使用(云盘分享安装文件)
云盘分享文件: 链接:https://pan.baidu.com/s/11sbj1QgogYHPM4udwoB1rA 提取码:l2wz 1.mongodb简单介绍 MongoDB的 官网 内容还是挺丰富的。 是由 C语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下&…...

算法竞赛必考算法——动态规划(01背包和完全背包)
动态规划(一) 目录动态规划(一)1.01背包问题1.1题目介绍1.2思路一介绍(二维数组)1.3思路二介绍(一维数组) 空间优化1.4思路三介绍(输入数据优化)2.完全背包问题2.1题目描述:2.2思路一(朴素算法)2.3思路二(将k优化处理掉)2.4思路三(优化j的初始条件)总结1.01背包问题…...
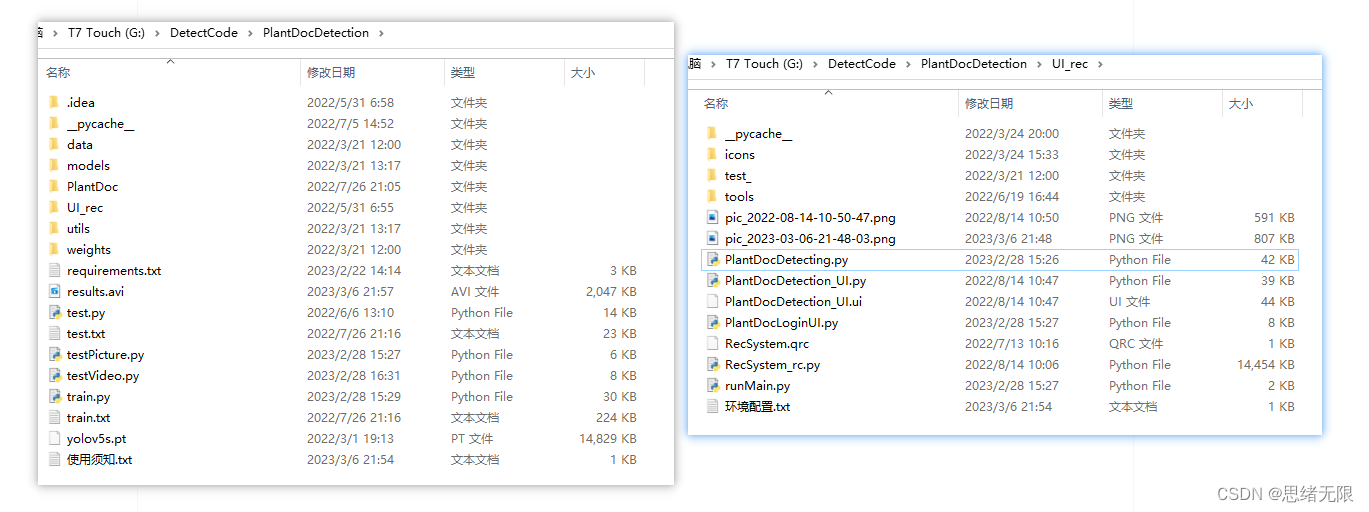
基于深度学习的农作物叶片病害检测系统(UI界面+YOLOv5+训练数据集)
摘要:农作物叶片病害检测系统用于智能检测常见农作物叶片病害情况,自动化标注、记录和保存病害位置和类型,辅助作物病害防治以增加产值。本文详细介绍基于YOLOv5深度学习模型的农作物叶片病害检测系统,在介绍算法原理的同时&#…...
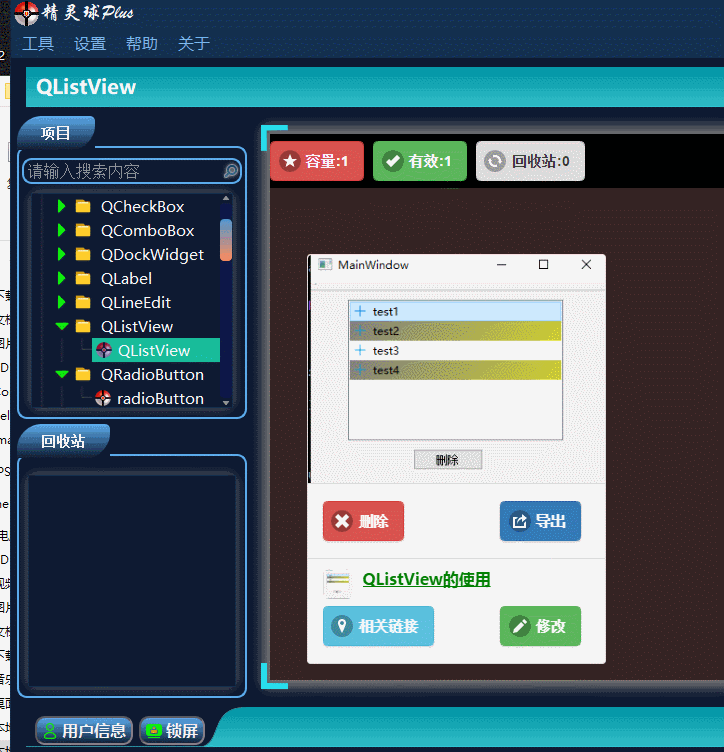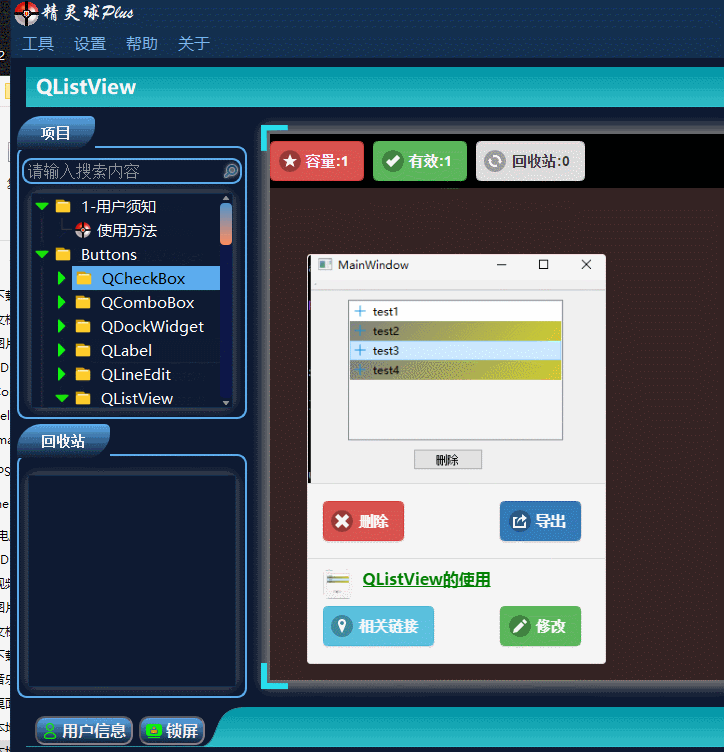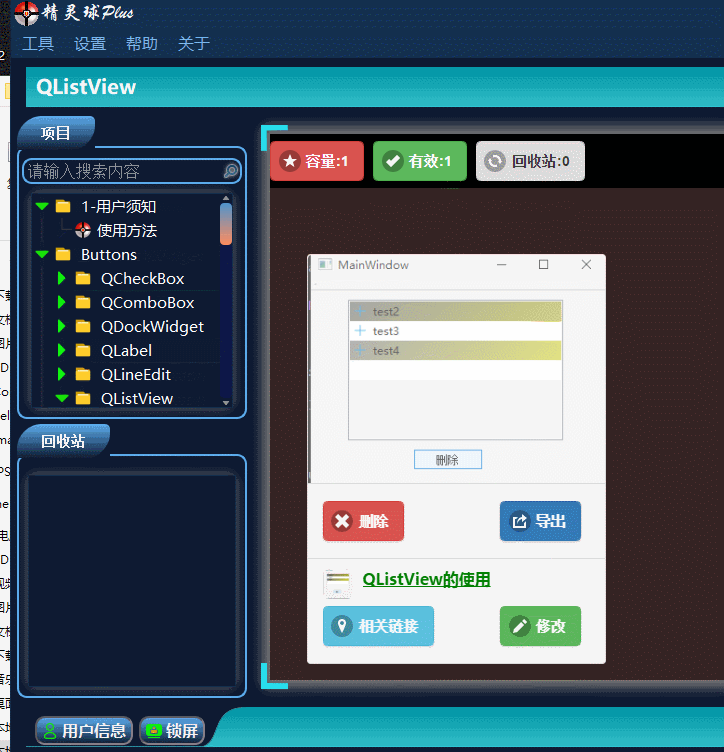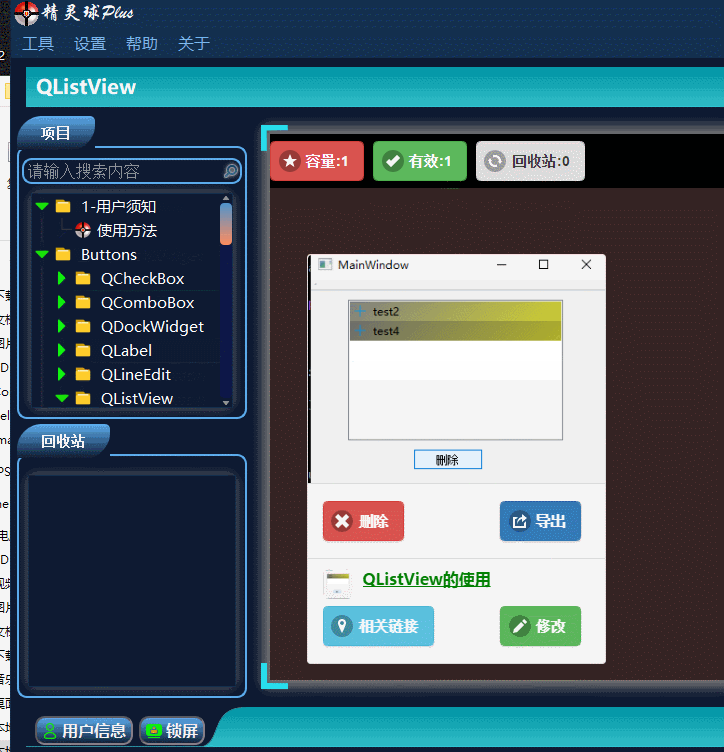
QT入门Item Views之QListView
目录 一、QListView界面相关 1、布局介绍 二、代码展示 1、创建模型,导入模型 2、 设置隔行背景色 3、删除选中行 三、源码下载 此文为作者原创,创作不易,转载请标明出处! 一、QListView界面相关 1、布局介绍 先看下界面…...
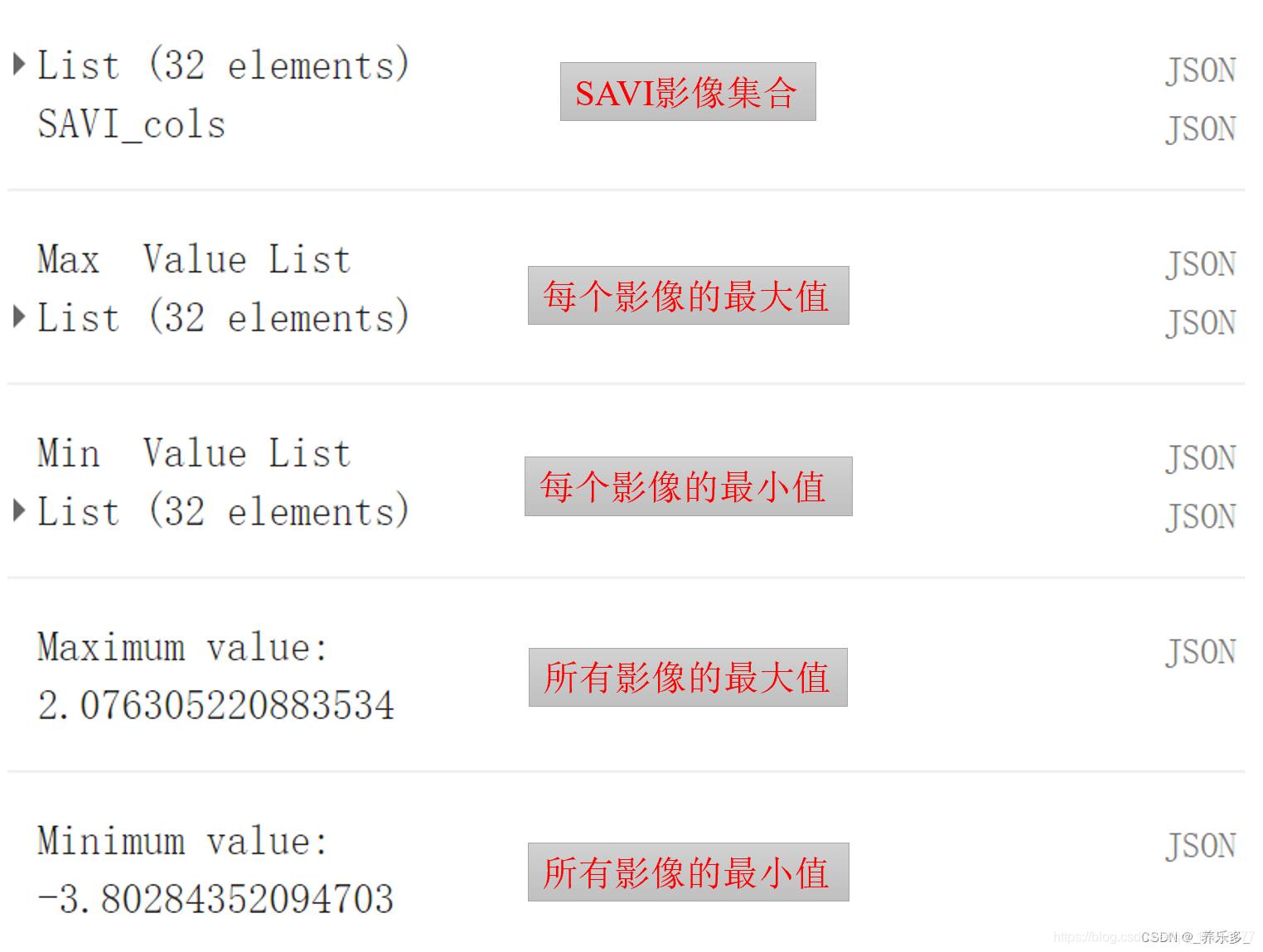
GEE:计算1990-2021年的指数最大值和最小值,并根据最大最小值对每一副影像归一化
本文记录了在GEE平台上计算影像集合中所有像素的最大值和最小值。并且根据该最大最小值对所有影像进行最大最小值归一化。以SAVI为例,记录了主要函数的使用方法和代码。 结果如图所示, 文章目录 一、计算每一副影像的最大值或者最小值,并将最值保存在 List 中二、计算 Lis…...

LeetCode KMP 算法
可以参考https://www.bilibili.com/video/BV1AY4y157yL/kmp 主要做的就是子串匹配,类似C程序的 strstr() 函数记录一下,也防止我自己忘记传统暴力求解算法是源串 ssssssssa 子串 sssa(下面暴力求解) 先 (子串从 0 位置匹配&#x…...

全面剖析OpenAI发布的GPT-4比其他GPT模型强在哪里
最强的文本生成模型GPT-4一、什么是GPT-4二、GPT-4的能力三、和其他GPT模型比较3.1、增加了图像模态的输入3.2、可操纵性更强3.3、复杂任务处理能力大幅提升3.4、幻觉、安全等局限性的改善3.6、风险和缓解措施改善更多安全特性3.7、可预测的扩展四、与之前 GPT 系列模型比较五、…...
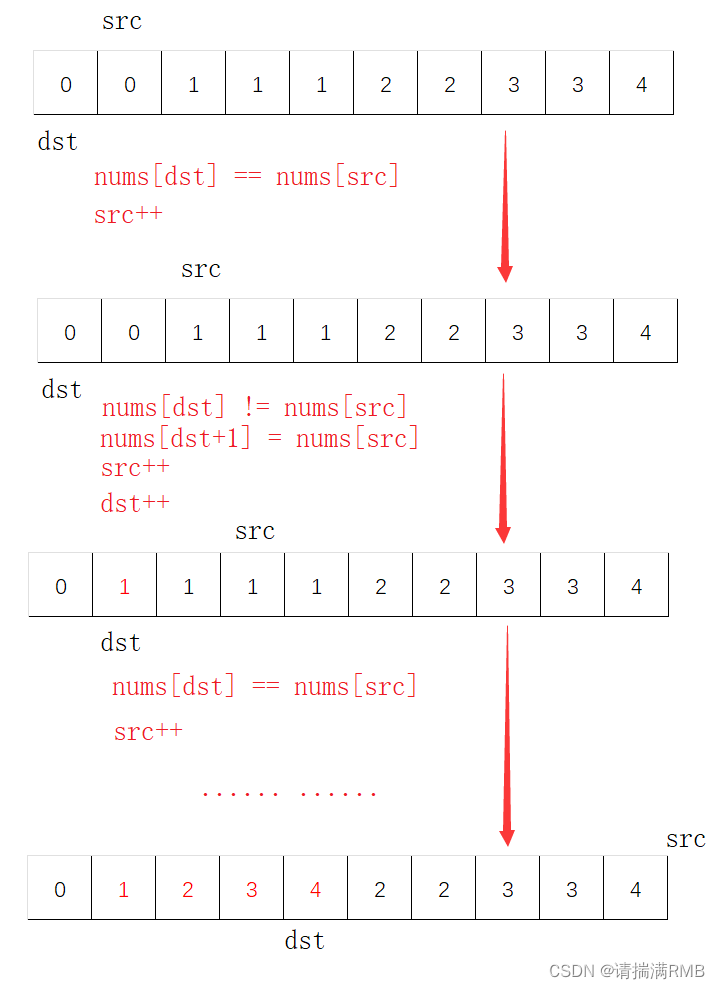
leetcode——26. 删除有序数组中的重复项
文章目录🐨1. 题目🏹2. 思路🪃3. 代码实现🐨1. 题目 给你一个升序排列的数组nums,请你原地删除重复出现的元素,使每个元素只出现一次,返回删除后数组的新长度。元素的相对顺序应该保持一致。 由…...
基于springboot垃圾分类网站设计实现【毕业论文、源码】
摘要本论文主要论述了如何使用JAVA语言开发一个垃圾分类网站,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述垃圾分类网站的当前背景以及系统开发的目的&#x…...
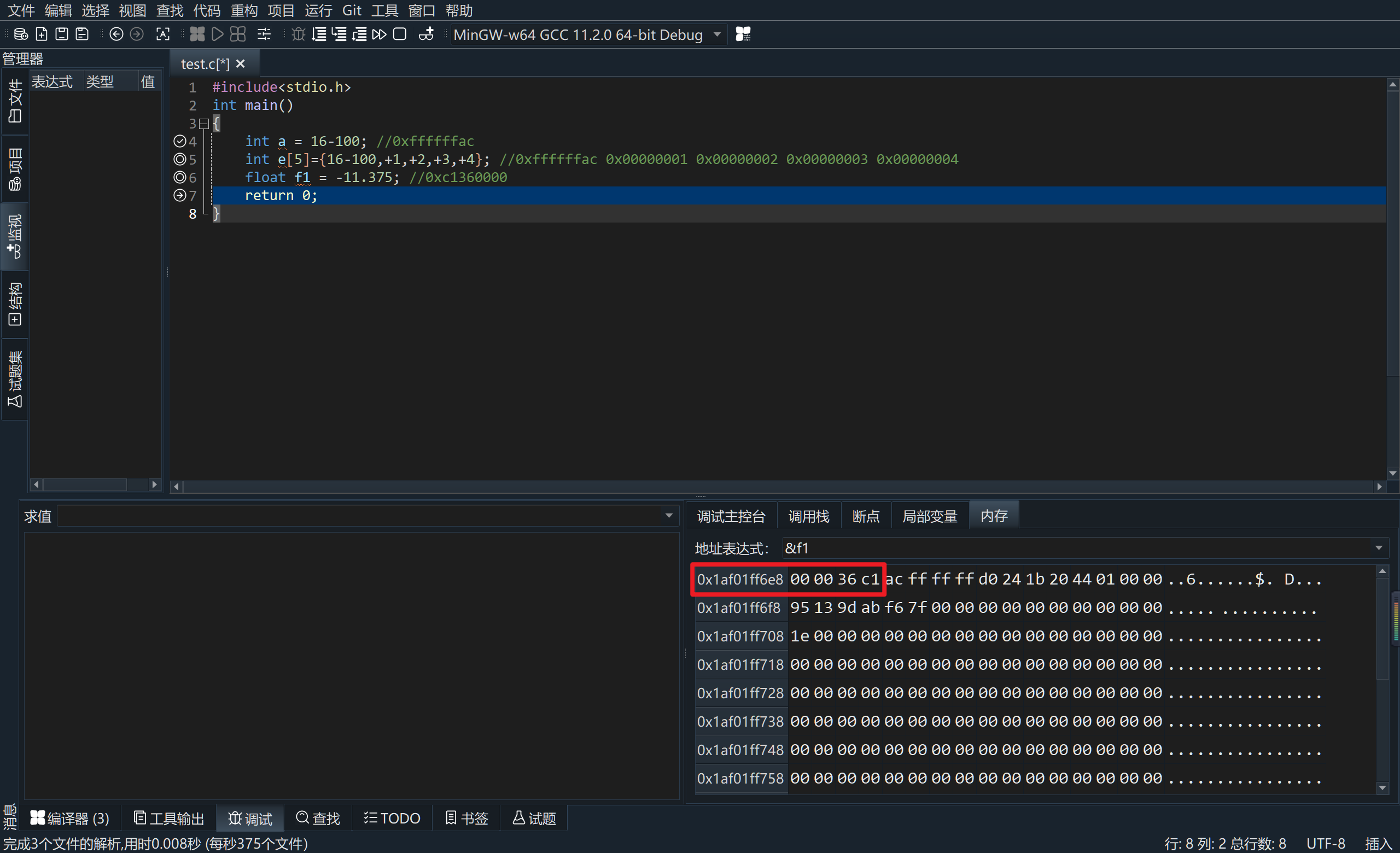
计算机组成原理实验一(完整)
在VC中使用调试功能将下列语句运行的内存存放结果截图,每运行一句需截图一次。 #include<stdio.h> int main() {int a 你的学号末两位-100; //0x????????&#x…...

【SSM】MyBatis(一.基础)
文章目录1.ORM2. 数据库表3. 入门程序3.1 创建项目3.2 开发3.3 一个比较完整规格的mybatis程序3.4 测试案例 junit3.5 对第一个mybatis使用junit测试3.6 集成日志框架logback3.7mybatis工具类编写1.ORM Object(JVM中的Java对象) Relational(关系型数据库) Mapping(映射) mybat…...
LInux指令之文件目录类
文章目录一、帮助指令二、文件目录类ls指令cd指令 (切换目录)mkdir指令(创建目录)rmdir指令(删除目录)touch指令(创建空文件)cp指令(拷贝文件)rm指令mv指令cat指令(查看)more指令les…...
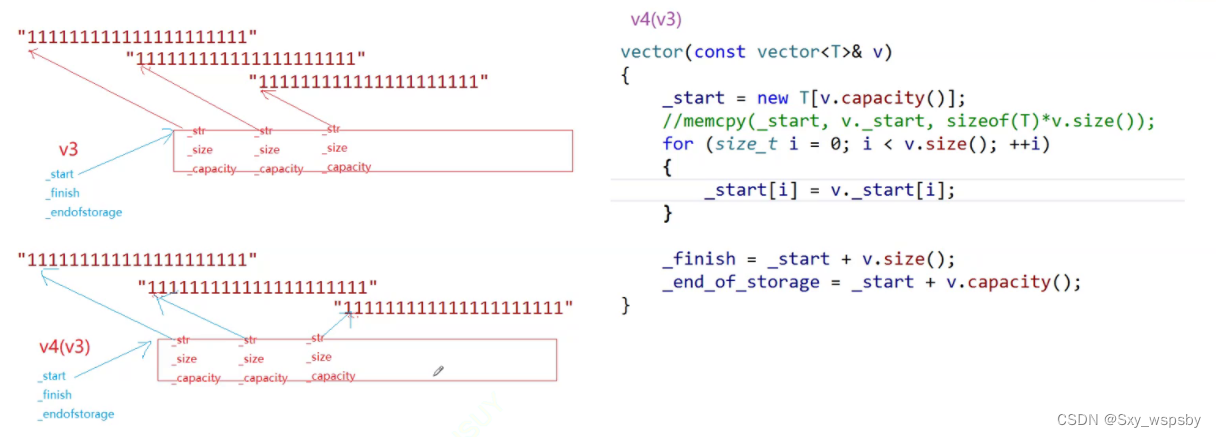
【c++】:STL中vector的模拟使用及模拟实现
文章目录 前言一.使用库中vector常用接口二.vector的模拟实现总结前言 上一篇我们讲解了STL中的string的使用和模拟实现,这次我们就来讲解STL中的vector,vector相对于string来说模拟实现会难一些,难点在于迭代器失效问题和深浅拷贝问题。 首…...
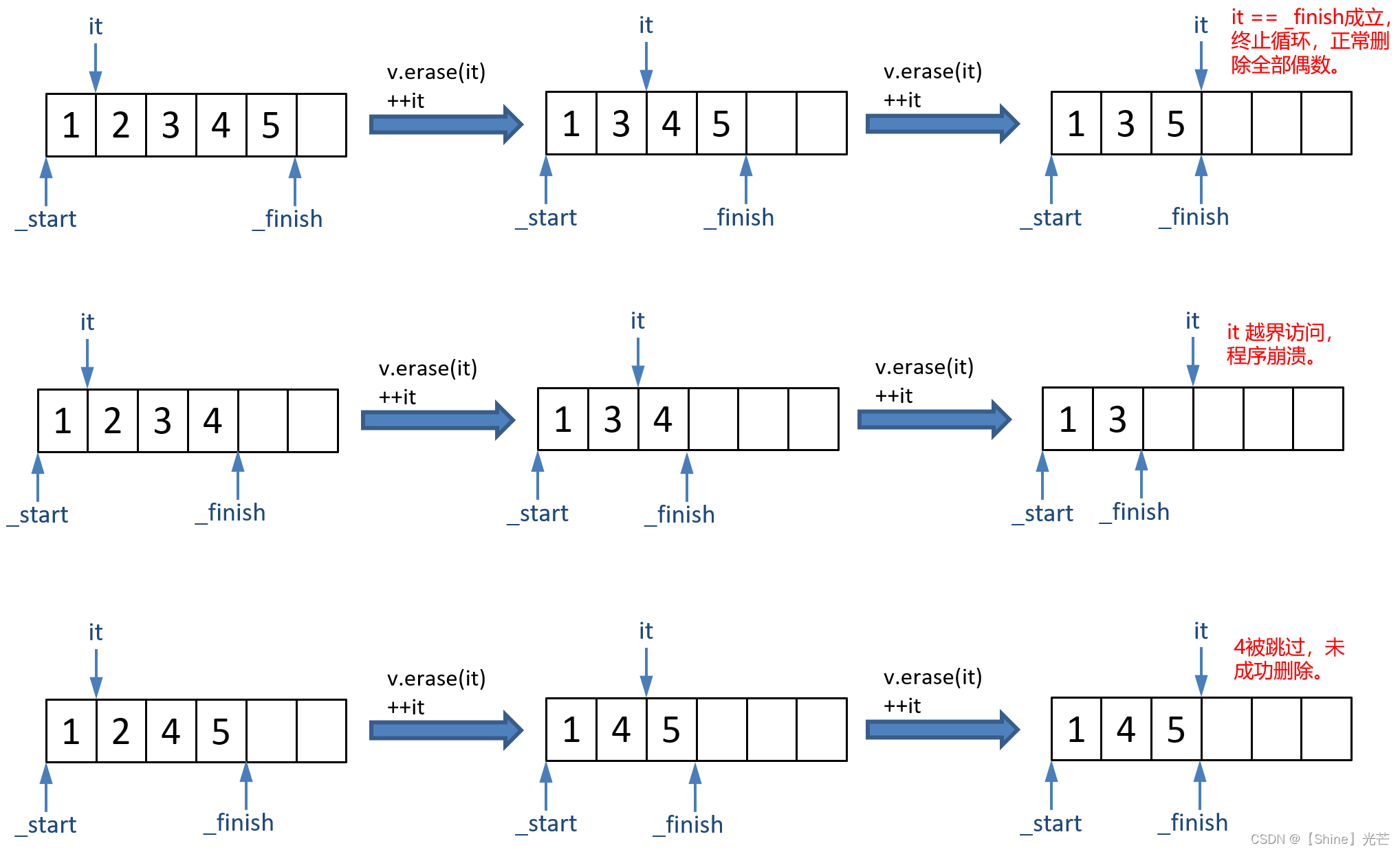
C++ STL:vector的使用方法及模拟实现
目录 一. vector概述 二. vector接口函数的使用方法和模拟实现 2.1 vector类模板的成员变量 2.2 构造函数的使用和模拟实现 2.2.1 构造函数的使用方法 2.2.2 构造函数的模拟实现 2.3 析构函数的模拟实现 2.4 赋值运算符重载函数的使用和模拟实现 2.4.1 函数的使用 2.…...

naive UI 的upload组件自定义手动上传图片的base64位
<template><n-upload ref"uploadRef" action"#" :default-upload"false" :custom-request"myUpload"><n-button>点击选择文件</n-button></n-upload><n-button click"submitUpload"> 上…...
——常见的域名投资陷阱)
域名常见问题集(十六)——常见的域名投资陷阱
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...

星露谷物语SMAPI模组加载器:终极安装与使用完全指南
星露谷物语SMAPI模组加载器:终极安装与使用完全指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 想要为《星露谷物语》安装模组来扩展游戏体验吗?SMAPI模组加载器是官方推…...

AI五金冲压报价——让精准报价,快人一步。
传统报价熬3天?AI 8分钟给你一份带Excel明细正规PDF的报价单!还在用Excel手动算冲压报价?客户催得急,成本核不准,格式不专业丢订单?五金厂的报价痛点,我们懂!✅ 工艺PDF/3D图扔进去&…...

实战应用:基于快马开发企业内软件合规性与安全拦截演示工具
今天想和大家分享一个在企业IT支持场景中非常实用的工具开发经验——基于InsCode(快马)平台开发的软件合规性检查演示工具。这个工具特别适合用来做内部培训或用户教育,帮助大家理解系统弹出的"智能应用控制已阻止可能不安全的应用"这类安全警告背后的逻辑…...

Ostrakon-VL扫描终端实战:识别冷柜温度计读数并判断是否符合标准
Ostrakon-VL扫描终端实战:识别冷柜温度计读数并判断是否符合标准 1. 项目背景与价值 在零售和餐饮行业中,冷链管理是确保食品安全的关键环节。传统的人工检查冷柜温度方式存在效率低、易出错等问题。Ostrakon-VL扫描终端通过创新的像素风格界面和强大的…...

快速搭建stm32f103c8t6引脚验证原型:快马平台一键生成初始化代码
最近在做一个基于STM32的小项目时,发现每次新建工程都要重复配置引脚功能,特别浪费时间。后来发现用InsCode(快马)平台可以快速生成初始化代码,简直打开了新世界的大门。今天就来分享下如何用这个平台快速搭建STM32F103C8T6的引脚验证原型。 …...

RobotStudio机器人轨迹规划:从工件坐标到流畅路径的实战指南
1. 工件坐标系的创建与校准 在RobotStudio中规划机器人轨迹的第一步,就是建立准确的工件坐标系。这就像盖房子前要先打好地基,坐标系就是机器人运动的"地基"。我见过不少新手直接开始示教点位,结果发现机器人总是跑偏,就…...
Pixel Epic动态卷轴效果展示:从空白屏幕到完整研报的实时生成录屏
Pixel Epic动态卷轴效果展示:从空白屏幕到完整研报的实时生成录屏 1. 引言:当科研遇上像素冒险 在传统的研究报告撰写过程中,我们常常面对冰冷的界面和机械化的交互体验。Pixel Epic彻底改变了这一现状,将严肃的学术研究变成了一…...

NVIDIA Profile Inspector实战指南:从参数调试到显卡性能极致释放
NVIDIA Profile Inspector实战指南:从参数调试到显卡性能极致释放 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 诊断性能瓶颈 显卡性能表现不佳往往是多种因素共同作用的结果,…...

美国智能手机搜查法律现状:不确定性与风险并存
生物识别解锁:法律模糊地带的高风险在美国,配置生物识别解锁功能的设备一直面临易受攻击的问题。目前,关于手机搜查的合法权益并不明确。一方面,若手机设置密码锁,被拘留或逮捕时说出密码可能被视为自证其罪࿰…...