2.3 大模型硬件基础:AI芯片(上篇) —— 《带你自学大语言模型》系列
本系列目录
《带你自学大语言模型》系列部分目录及计划,完整版目录见:带你自学大语言模型系列 —— 前言
第一部分 走进大语言模型(科普向)
- 第一章 走进大语言模型
-
-
1.1 从图灵机到GPT,人工智能经历了什么?——《带你自学大语言模型》系列
-
1.2 如何让机器说人话?万字长文回顾自然语言处理(NLP)的前世今生 —— 《带你自学大语言模型》系列
-
第三节 Transformer做对了什么?
-
第四节 大语言模型,大在哪?
-
- … …
第二部分 构建大语言模型(技术向)
- 第二章 基础知识
-
-
2.1 大语言模型的训练过程 —— 《带你自学大语言模型》系列
-
第二节 大模型理论基础:Transformer
-
第三节 大模型硬件基础:AI芯片 (本篇)
-
- 第三章 预训练
-
- … …
欢迎关注同名公众号【陌北有棵树】,关注AI最新技术与资讯。

前言:大模型Infra体系概览
虽然如今大模型很火,但从整个AI产业上下游来看,大模型只不过是其中的一环。另外,不是所有人都能去做大模型算法方面的研发,大部分人其实连入门资格都没有。所以我们在学习的时候,不能认为大模型只靠牛逼的算法就ok了,算法、算力、数据三者都必不可少。
或许你会问,那我去做应用行不行?应用侧的确有很大的市场,但目前只有两种情况是适合做应用了,一是你是一个创业者,能承担风险,你这时候不入局去搏一搏,机会就被别人抢走了,二是你之前本身就有业务,用AI来赋能你的业务场景,这两种人注定是要跟着AI的技术变革来承受起起伏伏的,因为欲戴王冠必承其重。但如果你只是想平平稳稳的做一个大模型时代的业务开发工程师,类似于互联网时代的Java开发,Go开发,PHP开发这种,恕我直言,繁荣的时候还没到。
现在大模型对厂商对模型的控制力还是太强了,导致上层应用能做的事情十分有限,也可以说太薄了,只能调一调现有模型的API,调一调Prompt,用一用RAG,这必然导致的结果是云厂商的话语权变得很大,最近一直在吵所谓的“端到端”、“AI Native”、“MaaS”,其实都是一个意思,想达到让开发者用大模型就像现在用操作系统一样,但显然,现在这个操作系统能让开发者控制的地方还太少,在我看来这不会是终态。
这也就是为什么大模型火了这么久,但是最赚钱的却是英伟达的原因了。尤其是当模型变大之后,以前模型参数和数据小,单机就能跑,但随着近年来大模型趋势成为共识,Scaling Law被奉为圭臬,算法工程师已经无法以一人之力完成大模型的训练部署,需要系统工程师的配合。
之前做系统开发的同学, 如果想搞大模型相关技术,我倒觉得大模型Infra层其实是更合适的方向。如果类比于传统软件时代和云时代的分层架构,当前所处的阶段是底层算力尚未满足需求,中间层AI Infra尚在建设中,未形成体系和标准。

根据中国信通院《AI框架发展白皮书》里面对AI体系的划分,将AI框架划分为基础层、组件层、生态层,大模型只是生态层的一种。

这里我根据大模型的技术栈,整理了一张大模型生态中从上到下的技术栈,从这张图你会看出,现在炙手可热的大模型及其上层应用,其实只是冰山漏出的一角,下面的基础建设,还远远没有定型和结束…

我们在学习的时候,既要从上到下,同时也要从下到上,大模型能够run起来,离不开底层的基础设施建设和开发框架的完善,这个完全可以用互联网时代做个类比,如果没有云计算的普及、Java开发生态的繁荣,把应用门槛打下来,怎么能支持那么多商业模式上的创新?
目前算法工程师或者上层应用开发者只需要使用 AI 框架定义好的 API 使用高级编程语言如 Python 等去编写核心的神经网络模型算法,而不需要关注底层的执行细节和对一个的代码。底层通过层层抽象,提升了开发效率,但是对系统研发却隐藏了众多细节,需要 AI 系统开发的工程师进一步探究。
所以本节的目的是从下到上,底层的GPU开始,讨论为什么GPU的结构与AI最适配?英伟达在GPU的基础硬件之上,做了哪些技术优化,确立了它的霸主地位?
这一节里会涉及大量的技术概念,所以这正可以验证我在 带你自学大语言模型系列 —— 前言 里提到的学习方法:对于所有的技术点,始终带着三个问题“这个技术是什么”“是为了解决什么问题”“是如何解决的”。
本节目录
(2.3上篇)
- 2.3.1 AI芯片概述
-
- 2.3.1.1 AI芯片分类
- 2.3.1.2 AI芯片衡量指标
- 2.3.2.3 设计一款AI芯片,需要关注什么?
- 2.3.3 GPU
-
- 2.3.3.1 从图形处理到AI加速
- 2.3.3.3 GPU与CPU比较
- 2.3.3.4 深度学习的计算模式
- 2.3.3.4 为什么GPU适用于AI计算?
- 2.3.4 英伟达的GPU架构
-
- 2.3.4.1 概述
- 2.3.4.2 CUDA
- 2.3.4.3 Tensor Core
- 2.3.4.3 NVLink
(2.3 下篇)
-
2.3.5 NVDIA芯片发展历程 & 产品详解
-
2.3.6 其他AI芯片(TPU、Groq…)
-
2.3.7 国内芯片厂商(华为昇腾、寒武纪、壁仞…)
2.3.1 AI芯片概览
算力是AI发展的驱动力,大模型时代更要格外关注算力。1960年以来,计算机性能增长来于摩尔定律,简单来说就是计算机性能每隔18-24个月会增加一倍。半个世纪以来,摩尔定律一直推动芯片性能的重要动力。但近年来,摩尔定理已呈现放缓态势;与此同时,芯片的运算能力还远远无法满足算法的运算需求。芯片性能需要每年提高10倍,才能满足训练深度神经网络的需求。这个需求是巨大的,但目前看来还难以满足。目前的大模型是个重资产行业,底层竞争在于半导体产业,AI的发展离不开芯片,甚至可以说,整个信息时代的发展都离不开芯片。
2.3.2.1 AI芯片的分类
从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片,如GPU(图形处理器)、FPGA(现场可编程门阵列)和ASIC(专用集成电路)。
与AI 芯片相对应的是传统芯片,以CPU(Central Processing Unit,中央处理器)为代表,CPU是以任务顺序执行为目的设计的。而AI芯片的一个显著特点就是拥有强大的并行计算能力,专注于同时处理多个任务。
从不同的视角,AI芯片可以划分为不同的类别:
【1】按功能划分:
-
- 训练芯片:主要负责数据处理和模型训练,一般部署在云端。训练需要极高的计算性能,需要较高的精度,需要能处理海量的数据,需要有一定的通用性,以便完成各种各样的学习任务。
- 推理芯片:推理是指利用已训练好的模型进行实时推理与预测,部署在云端或终端设备均可。推理相对来说对性能的要求并不高,对精度要求也要更低,在特定的场景下,对通用性要求也低,能完成特定任务即可,不过推断芯片更注重综合指标, 单位能耗算力、时延、成本等都要考虑。
【2】按部署场景划分:
-
- 云端 AI 芯片:性能强大,能够支持大量运算和多种 AI 应用,通常部署在数据中心中
- 终端 AI 芯片:主要用于训练和推理环节,需要极大的数据量和大运算量,通常部署在嵌入式设备或移动终端上
【3】按技术架构划分:
-
- GPU(图形处理器):适合大规模并行计算任务,如图像识别、自然语言处理等,但功耗较高
- FPGA(现场可编程门阵列):具有可编程性、低延时和高吞吐的特点,适用于高速数据传输和逻辑运算,但开发复杂度高且功耗相对较低
- ASIC(专用集成电路):针对特定算法定制,性能和能效优势明显,但前期研发时间长、投入成本高
- 类脑芯片(NPU):模拟人脑神经网络结构,适用于神经网络和机器学习任务
2.3.2.1 AI芯片的衡量指标
对于如何衡量一款芯片,已经有了一套非常完善的指标体系。包括:算力、精度、功耗、内存和带宽、成本等。
在介绍指标之前,需要对芯片算力的相关计算单位做一个简单介绍
- TOPS(Tera Operations Per Second):表示每秒进行的万亿次操作。例如,存算一体芯片可以达到1000TOPS以上的算力。
- FLOPS(Floating Point Operations Per Second):计算机浮点运算次数的量化单位,用于描述计算机执行科学计算和AI任务的能力。常见的有GigaFLOPS(十亿次浮点运算/秒)、TeraFLOPS(万亿次浮点运算/秒)等。
- INT8、INT4、BF16、FP16、FP32、FP64:这些是不同精度的浮点数计算能力,分别代表不同的数值范围和精度。例如,FP16(半精度浮点数)常用于需要较高计算效率的应用场景,而FP64(双精度浮点数)则提供更高的计算精度。
下面介绍几个本节涉及的芯片衡量指标:
算力
算力是评价AI芯片性能的核心要素。算力越高,芯片的处理能力越强,能够支持更复杂和大规模的AI模型训练和推理任务。算力通常以每秒浮点运算次数(FLOPS)或每秒操作次数(OPS) 为单位来表示。
精度
精度包括计算精度和模型结果精度。不同应用场景对计算精度的要求不同。例如,在大模型训练中通常需要较高的精度(如FP32以上),而在模型推理中则可以使用较低精度(如FP16或INT8)以节省资资源。
基于运算数据精度不同,算力可分为双精度算力(FP64)、单精度算力(FP32)、半精度算力(FP16) 及整型算力(INT8、INT4)。数字位数越高,代表运算精度越高,可支持的运算复杂程度越高,以此适配更广泛的AI应用场景。
显存容量
显存用于存放模型,数据显存越大,所能运行的模型也就越大。显存容量通常以GB为单位。例如,英伟达H200拥有141GB的显存,而A100则提供40GB和80GB两个版本的显存。
显存带宽
显存带宽是指显存在单位时间内可以传输的数据量,通常以GB/s或TB/s为单位。高带宽意味着更快的数据访问速度,这对于需要快速读写大量数据的AI应用尤为重要。例如,H200的显存带宽达到每秒4.8 TB,而A100的80GB版本显存带宽为2039 GB/s
2.3.2.1 设计一款AI芯片,需要关注什么?
一个模型在AI芯片的执行过程中,所做的事情无非就是搬运数据和计算数据。具体来说分为如下几步:
- 将数据从外部存储搬到计算单元
- 计算单元进行计算
- 把结果搬回外部存储
所以,相比于算力,其实我们更应该关注的是**「内存、带宽、时延」与算力的匹配度**。也就是说,哪怕算得再快,但是内存来不及搬运,增加的算力也发挥不了作用。
为了更直观描述这一情况,我们引入一个概念 【计算强度】
计算强度(Arithmetic Intensity)是指在执行计算任务时所需的算术运算量与数据传输量之比。它是衡量计算任务的计算密集程度的重要指标,可以帮助评估算法在不同硬件上的性能表现。通过计算强度,可以更好地理解计算任务的特性,有助于选择合适的优化策略和硬件配置,以提高计算任务的性能表现。计算强度的公式如下:
计算强度算术运算量数据传输量
以矩阵乘法为例,对于一个 矩阵乘法操作,可以计算其计算强度(Arithmetic Intensity)。
- 算术运算量:对于两个 的矩阵相乘,总共需要进行 次乘法和 次加法运算。因此,总的算术运算量为 。
- 数据传输量:在矩阵乘法中,需要从内存中读取两个输入矩阵和将结果矩阵写回内存。假设每个矩阵元素占据一个单位大小的内存空间,则数据传输量可以估计为 ,包括读取两个输入矩阵和写入结果矩阵。
因此,矩阵乘法的计算强度可以计算为:
因此矩阵乘法的计算强度用时间复杂度表示为 ,随着相乘的两个矩阵的维度增大,算力的需求将不断提高,需要搬运的数据量也将越大,算术强度也随之增大。下图展示了矩阵大小和计算强度之间的关系。横轴代表矩阵大小,纵轴代表计算强度。
从蓝色线可以看出,随着矩阵不断增大,需要计算的强度越大
橙色线代表GPU在FP32精度下的计算强度,两条线的交点就是GPU与矩阵最合适的区间,也就是在矩阵大小在50~60之间,能够充分发挥GPU在FP32精度下计算强度

随着矩阵继续增大,数据搬运越来越慢,内存数据的刷新变得越来越慢。后面提出的Tensor Core正是为了解决这一问题,提高计算强度,让数据搬运跟上运算的速度。图中红线展示的就是引入Tensor Core之后的计算强度,与矩阵大小的平衡点已经达到了320.
除了精度会影响计算强度,当Tensor Core在不同级别缓存下,其计算强度与矩阵大小的交叉点也有所不同,如下图所示,每种存储和矩阵的计算强度分别对应一个交叉点,由此可以看出数据在什么类型的存储中尤为重要。当数据搬运到L1缓存中时可以进行一些更小规模的矩阵运算,比如卷积运算;而对于Transformer结构,可以将数据搬运到L2缓存进行计算。
同时,数据运算和读取存在比例关系,如果数据都在搬运此时计算只能等待,导致二者不平衡,所以找到计算强度和矩阵大小的平衡点,对于AI芯片的设计也是尤为重要。

2.3.2 GPU
2.3.2.1 从图形处理到AI加速
GPU(Graphics Processing Unit,图形处理器)的最初应用场景并不是AI,而是图像处理,用于游戏和动画中的图形渲染任务。
1999年,NVIDIA发布了GeForce 256,这是第一款被正式称为“GPU”的产品。
2001年,NVIDIA引入了可编程顶点着色器,使得开发者可以执行更复杂的矩阵向量乘法、指数运算和平方根运算等操作。
2006年是个关键节点,NVIDIA推出了CUDA架构,这是一项革命性的技术,使得GPU不仅能够进行高效的图形计算,还能执行通用计算任务
但尽管如此,当时还没有人将GPU用于深度学习,2012年,Hinton和Alex Krizhevsky设计的AlexNet是一个重要的突破,他们利用两块英伟达GTX580GPU训练了两周,将计算机图像识别的正确率提升了一个数量级,并赢得了2012年ImageNet竞赛冠军。充分展示了GPU在加速神经网络模型训练中的巨大潜力。
随后,英伟达继续发力,推出了Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing和Ampere等GPU架构。
2.3.2.2 GPU与CPU比较
我们知道,在处理器领域一直是CPU占据主导地位,那么自然会提出一个疑问,为什么CPU不能直接用于AI计算?其实在早期,AI计算的确是在CPU上进行。那为什么后来又转移到GPU呢?
CPU自1971年诞生,50年间已经发展为大规模复杂电路,但核心主要是三个部分:算术逻辑单元(ALU)、存储单元、控制单元。三个部分执行工作流的步骤如下:

ALU用来完成数据计算,其他模块则是为了保证指令能一条接一条执行,这种通用的架构对于传统编程范式非常适合,但正是由于这个顺序执行的原则,计算能力受到限制,尽管并行处理架构通过不同的数据流和指令流组合,实现了计算性能的提升,但还是达不到AI计算的性能要求。
CPU和GPU最大的区别在于,它们的设计目标本质是不同的,所以架构设计、应用场景才会相应的不同。
CPU的设计目标是希望加快指令的运算,一个线程里完成一个指令运算所有的工作,于是将重点投入到减少延迟上面,所以一般采用的方式是优化线程效率,
GPU的设计目标是最大化吞吐量,相比比单任务执行快慢,GPU更关心并行度(同时可以执行多少任务),所以GPU的设计重点是增加更多的线程,GPU可用线程的数量是CPU的100多倍。
从应用场景上,CPU处理的是操作系统和应用程序需要的各种计算任务,需要通用性来处理不同类型的数据,同时这类程序还存在大量的分支和跳转处理,这些都导致CPU结构非常复杂。
GPU解决的问题主要集中在需要大量浮点运算和数据并行处理的领域,如科学计算、机器学习、图像处理和视频编码等。这些问题通常在传统的CPU架构下难以高效解决,因为它们要么需要大量的浮点运算,要么需要同时处理大量数据。
目标和场景决定了架构设计,下面这张图会十分明显的展示出GPU和CPU的区别:CPU通常有4/8/16个强力ALU,适合复杂通用的串行任务,GPU则是有成百甚至上千个简单ALU,单个ALU的能力会弱于CPU的ALU,但适合多个ALU并行运算。

2.3.2.3 深度学习的计算模式
了解深度学习的计算模式,才能找到GPU与AI时代的契合点到底在哪,同时对于硬件的设计和优化,也有着十分重要的作用。
神经网络中的最主要计算范式是【权重求和】,无论是全连接、卷积网络、循环神经网络、注意力机制,都没有绕开这个计算范式。权重求和占了神经网络90%的计算量。
权重求和的本质就是大规模矩阵乘法。
所以说,矩阵乘法运算是AI模型中最重要的运算过程(更准确的说,是矩阵点的乘加运算),这个过程的特点在于较高的内存搬运和计算密度;并且,每个计算任务都独立于其他计算,任何计算都不依赖于其他计算结果,可以采用高度并行的方式进行计算。
2.3.2.4 为什么GPU适用于AI计算?
概括来说,GPU通过以下两点支持了大规模的并行计算:(1)通过超配的线程来掩盖时延;(2)通过多级的缓存平衡计算和带宽之间的差距
超配的线程数量
我们通过三款芯片的详细数据,来看需要多少线程,才能解决内存的延时问题?

从这张表可以看到几个下面几个关键数据:
GPU的时延会比CPU高出4倍左右,同时,GPU的线程数量是CPU的20~30倍,GPU的可用线程数量是CPU的100多倍。简单来说,GPU拥有非常多的线程,为大量大规模任务并行而设计的,GPU将更多的资源都投入到如何增加线程数量,而不是像CPU一样去优化线程执行效率、减少指令执行的延迟。
多级缓存
在GPU运算的过程中,我们希望更多的减少内存时延、内存搬运等一系列操作,所以缓存至关重要。
多级缓存的设计是为了减少对主内存的依赖,从而降低延迟并提高数据传输速度。每一级缓存都有不同的访问速度和容量,通常离用户越近的层级,访问速度越快但容量越小;而离用户越远的层级,访问速度越慢但容量越大。
在GPU中,多级缓存被设计为几个主要部分:
- L1 Cache:位于每个流处理器(SM)内部,具有较高的访问速度和较低的容量。
- L2 Cache:共享给多个SM,提供更大的容量和稍低的访问速度。
- 寄存器文件:每个SM拥有自己的寄存器文件,用于存储临时计算结果,访问速度最快
缓存层的设计使得GPU能够更有效地管理数据流,减少数据传输时间,并提高处理效率。例如,在执行计算任务时,多级缓存可以显著减少内存访问时间,从而加快整个计算过程。
2.3.3 英伟达GPU架构
2.3.3.1 概述
对于芯片的架构,各家芯片厂商都采用了不同的设计,本节以NVIDIA的GPU架构为核心,介绍GPU架构的关键技术
英伟达的GPU架构自2010年起,从Fermi到Hopper, 逐渐引入CUDA Core、Tensor Code、NVLink、NVSwitch等先进技术。
下图是一张英伟达A100的架构图,我们先有一个直观的感受。

首先把GPU里面一些关键的概念列出来
- GPC:图形处理簇(Graphics Processing Clusters)
- TPC:纹理处理簇(Texture Processing Clusters)
- SM:流多处理器(Stream Multiprocessors)
- HBM:高带宽存储器(High Bandwidth Memory)
A100中包含8个GPC,每个GPC中包含8个TPC,每个TPC 包含两个 SM 单元,SM 是 A100 芯片中的基本计算单元,负责并行执行大量线程的指令。包括了CUDA Core、共享内存、寄存器等核心组件,SM里面可以并发执行数百个线程。下图是单个SM的结构图:

SM中具体包括下面这些组件(这里暂时列出,不做详细说明,后面介绍技术细节时,涉及到哪个组件会再细说):
- CUDA Core:向量运行单元(FP32-FPU、FP64-DPU、INT32-ALU)
- Tensor Core:张量运算单元(FP16、BF16、INT8、INT4)
- Special Function Units:特殊函数单元SFU,用来支持各种数学函数,例如正余弦等
- Warp Scheduler:线程束调度器,负责把线程下发到计算单元里面
- Dispatch Unit:指令分发单元
- Multi level Cache:多级缓存(LO/LI Instruction Cache、LI Data Cache & Shared Memory)
- Register File:寄存器堆;
- Load/Store:访问存储单元LD/ST(负责数据处理);
2.3.3.2 CUDA
说起NVDIA,不得不提的一项技术就是CUDA(Compute Unified Device Architecture)。CUDA是英伟达在2006年11月发布的Tesla架构推出的一种并行计算平台和编程模型。 核心在于利用GPU的并行处理能力,将GPU用作通用并行计算设备,以加速各种计算任务。
可以从硬件和软件两个层面来理解CUDA:在硬件层面,通过改进GPU架构和提供灵活的内存管理机制,显著提升了计算性能;在软件层面则通过提供易用的编程模型、高级数学库和丰富的开发资源,极大地简化了并行程序的开发和维护工作。具体如下:
硬件层面,CUDA提供一个高度并行的计算环境:
- 统一渲染架构:CUDA将传统的像素着色器和顶点着色器合并为一个统一的渲染架构,从而提高了对大规模数据计算应用的支持能力。
- 灵活的内存管理:CUDA提供了高效的内存管理机制,包括共享内存、全局内存等,使得开发者可以更高效地利用GPU的高速带宽和大容量内存。
- 多线程SIMD处理器:CUDA通过多线程SIMD(单指令多数据流)处理器,允许数千个线程同时执行,极大地提升了计算效率。
- 支持多种GPU型号:CUDA从G80系列开始全面支持通用编程,并且兼容所有NVIDIA的GeForce、Quadro和Tesla系列GPU,这使得CUDA能够适用于各种不同需求的用户。
软件层面
- CUDA的编程模型允许允许开发者使用C/C++等编程语言在GPU上编写高效、可扩展的并行程序,让开发人员更方便的控制GPU里面各种组件。CUDA提供了一套完整的工具链和开发环境,包括编译器、链接器、调试器和各种库函数,使开发者能够轻松地编写和优化并行程序。
- 高级数学库:CUDA内置了如CUFFT(CUDA Fast Fourier Transform)和CUBLAS(CUDA Basic Linear Algebra Subroutines)等高级数学库,这些库为复杂的科学计算和数据分析提供了强大的支持。
- 异构计算支持:CUDA不仅支持GPU,还支持CPU、DPU和网络计算,提供了一种灵活的系统软件组件,帮助用户高效地部署、管理和优化大型异构系统。
- 丰富的开发资源:NVIDIA提供了大量的文档、教程和示例代码,帮助开发者快速上手并解决实际问题。
其实对于NVDIA来说更重要的是,通过CUDA实现了硬件和软件解耦,从而让英伟达更方便的进行硬件的发展。
在了解CUDA工作原理之前,需要对一些重要概念进行说明:
线程是CUDA最重要的执行单位,具体方式是将程序的执行划分为独立的线程块,每个线程块并行执行。
为了数据的管理和通信问题,CUDA引入Host(主机) 和Device(设备) 两个概念,host代码部分在CPU上执行,是普通的C代码;当遇到数据并行处理的部分,CUDA会将程序编译成GPU能执行的程序,并传送到device,device代码在GPU上执行。
传送到GPU的程序被称作Kernel函数,Kernel(核)是CUDA里面重要的一个概念。kernel 用 __global__ 符号声明,在调用时需要用 <<<grid, block>>> 来指定 kernel 要执行及结构。
下图很好的展示了CUDA的线程结构

首先,host遇到需要并行执行的代码,将其编译Kernel函数,传送到device。
那么device中是如何实现具体的并行计算的呢?CUDA线程有明确的三层结构:
第一层:Kernel在Device执行时,会启动多个线程,一个Kernel执行启动的所有线程统称为一个Grid(网格)。
第二层:一个Grid分为多个Block(块),每个块内有很多线程,各个块之间的线程独立执行,也不会互相通信。Block通过Warp进行调度。
第三层:每个Block内部的多个线程可以同步,并且可以通过共享内存通信。
2.3.3.3 Tensor Core
Tensor Core是在2017年的Volta架构中首次被提出,自此之后,英伟达的每次架构升级都不断对Tensor Core进行更新迭代。
在Tensor Core 发布之前,CUDA Core是加速深度学习的关键硬件。CUDA Core在执行计算操作时,需要将数据在寄存器、算术逻辑单元(ALU)和寄存器之间进行多次搬运,这种过程既耗时又低效。此外,每个CUDACore单个时钟周期只能执行一次运算,而且CUDA Core的数量和时钟速度都有其物理限制,这些因素共同限制了深度学习计算性能的提升。为了克服这一限制,NVIDIA 开发了 Tensor Core。
Tensor Core主要解决了哪些问题呢?主要有下面几个方面:
【1】提高训练和推理速度:Tensor Core 可以显著提升 AI 模型的训练和推理速度。例如,Hopper架构中采用第四代Tensor Core,已经将GPU的峰值性能相较未引入Tensor Core时提高了 60 倍,在此基础上,Blackwell 中采用第五代Tensor Core,又可将万亿级参数生成式 AI 模型的训练速度提高 4 倍,并将推理性能提升 30 倍。
具体来说,相比于 FP32 Core 一次只能对两个数字进行计算,一个Tensor Core可以在一个时钟周期内,完整一个4×4矩阵的乘法和加法运算,矩阵乘法的两个矩阵是FP16,求和的矩阵可以是FP16或FP32。
通过硬件上的特殊设计,Tensor Core 理论上可以实现 8 倍于 FP32 Core 的计算吞吐量(这里指Volta 和 Turing 架构),并且没有明显的占用面积和功耗增加。


【2】混合精度计算:除了对矩阵乘加运算操作的原子化支持,Tensor Core还从硬件底层支持了混合精度训练,即在保持一定精度的同时,动态调整算力以提高吞吐量。这种技术允许在较低精度(如 FP16)下进行计算,同时输出仍为较高精度(如 FP32),从而在不损失太多准确性的前提下大幅提高计算效率。另外,H100 GPU 配备了第四代 Tensor Core 和 Transformer 引擎,支持 FP8 精度,进一步提升了 AI 训练和推理的速度。
【3】Tensor Core 将传统的单一维度数字运算扩展到二维度的矩阵运算,这使得其在处理大规模数据时更加高效。例如,在 Tesla V100 上,Tensor Core 能够实现最高 9 倍的峰值 TFLOPS 性能提升
【4】稀疏矩阵处理:Tensor Core 还能够高效处理稀疏矩阵乘法(SpMM),这是许多深度学习算法中的一个常见挑战。通过灵活的稀疏块模式和动态可扩展的映射流,Tensor Core 提供了更高的算法灵活性和硬件效率
2.3.3.4 NVLink
随着模型参数的不断增大,分布式训练已经成为必然趋势,这对底层的硬件和网络都带来了新的挑战。具体来说,当训练采用大规模集群,集群内的节点必须保证数据快速交换,否则,即使是再强大的GPU,也会因为网络瓶颈的卡点而受限,最终影响整个集群的性能。
关于分布式集群和通信的相关内容,后面会有单独的章节介绍,但不难看出,底层网络通信效率成为重中之重。
早期的PCIe 由英特尔公司提出,主要用于连接CPU与各类高速外围设备。2003年PCIe 1.0发布,单通道250MB/s,总带宽最高4GB/s,到2022年 PCIe 6.0 发布,单通道8GB/s,总带宽最高128 GB/s。
根据上述数据可见,传统的PCIe的带宽速率迭代跟不上AI系统的发展。

NVLink 正是为了解决这一问题,NVLink是NVIDIA开发的一种专有高速互连技术,主要用于连接多个GPU或GPU与CPU之间的通信。下图是NVLink各个版本的带宽数据。从图中可见,2014年第一代NVLink的带宽就已经达到 160GB/s,到2024年第五代NVLink,每块GPU提供1.8TB/s的双向吞吐量,总带宽超过1 PB/s。

NVLink采用点对点(P2P)结构和串行传输方式,这意味着每个GPU通过独立的通道直接与其他GPU进行通信,从而避免了中间节点的瓶颈问题。

从第一代到第五代,NVLink经历了多次改进和升级。最初采用的是cube直连拓扑,随后发展为Switch交换拓扑,第三代增加了单卡的NVLink通道数以提升带宽,第四代完善了多种协议内容,而第五代则大幅提升了带宽并支持576个GPU之间的高速通信。

参考文献:
[1] NVIDIA. NVIDIA A100 Tensor Core GPU Architecture[EB/OL]. [2020]. https://www.techpowerup.com/gpu-specs/docs/nvidia-ampere-architecture.pdf.
[2]NVIDIA. NVIDIA Tensor Core[EB/OL]. https://www.nvidia.cn/data-center/tensor-cores/.
[3]NVIDIA. What Is NVLink?[EB/OL]. https://blogs.nvidia.com/blog/what-is-nvidia-nvlink/.
[4]NVIDIA. CUDA C++ Programming Guide[EB/OL]. https://docs.nvidia.cn/cuda/pdf/CUDA_C_Programming_Guide.pdf.
[5] NVIDIA. NVIDIA Optimized Deep Learning Framework, powered by Apache MXNet[EB/OL]. https://docs.nvidia.com/deeplearning/frameworks/pdf/MXNet-Release-Notes.pdf.
相关文章:
2.3 大模型硬件基础:AI芯片(上篇) —— 《带你自学大语言模型》系列
本系列目录 《带你自学大语言模型》系列部分目录及计划,完整版目录见:带你自学大语言模型系列 —— 前言 第一部分 走进大语言模型(科普向) 第一章 走进大语言模型 1.1 从图灵机到GPT,人工智能经历了什么࿱…...

Java | Leetcode Java题解之第279题完全平方数
题目: 题解: class Solution {public int numSquares(int n) {if (isPerfectSquare(n)) {return 1;}if (checkAnswer4(n)) {return 4;}for (int i 1; i * i < n; i) {int j n - i * i;if (isPerfectSquare(j)) {return 2;}}return 3;}// 判断是否为…...

JS逆向高级爬虫
JS逆向高级爬虫 JS逆向的目的是通过运行本地JS的文件或者代码,以实现脱离他的网站和浏览器,并且还能拿到和浏览器加密一样的效果。 10.1、编码算法 【1】摘要算法:一切从MD5开始 MD5是一个非常常见的摘要(hash)逻辑. 其特点就是小巧. 速度快. 极难被破解. 所以,…...

基于Golang+Vue3快速搭建的博客系统
WANLI 博客系统 项目介绍 基于vue3和gin框架开发的前后端分离个人博客系统,包含md格式的文本编辑展示,点赞评论收藏,新闻热点,匿名聊天室,文章搜索等功能。 项目在线访问:http://bloggo.chat/ 访客账号…...

DVWA中命令执行漏洞细说
在攻击中,命令注入是比较常见的方式,今天我们细说在软件开发中如何避免命令执行漏洞 我们通过DVWA中不同的安全等级来细说命令执行漏洞 1、先调整DVWA的安全等级为Lower,调整等级在DVWA Security页面调整 2、在Command Injection页面输入127.0.0.1&…...

【YOLOv5/v7改进系列】引入中心化特征金字塔的EVC模块
一、导言 现有的特征金字塔方法过于关注层间特征交互而忽视了层内特征的调控。尽管有些方法尝试通过注意力机制或视觉变换器来学习紧凑的层内特征表示,但这些方法往往忽略了对密集预测任务非常重要的被忽视的角落区域。 为了解决这个问题,作者提出了CF…...
【QT】常用控件(概述、QWidget核心属性、按钮类控件、显示类控件、输入类控件、多元素控件、容器类控件、布局管理器)
一、控件概述 Widget 是 Qt 中的核心概念,英文原义是 “小部件”,此处也把它翻译为 “控件”。控件是构成一个图形化界面的基本要素。 像上述示例中的按钮、列表视图、树形视图、单行输入框、多行输入框、滚动条、下拉框都可以称为 “控件”。 Qt 作为…...

【Python】字母 Rangoli 图案
一、题目 You are given an integer N. Your task is to print an alphabet rangoli of size N. (Rangoli is a form of Indian folk art based on creation of patterns.) Different sizes of alphabet rangoli are shown below: # size 3 ----c---- --c-b-c-- c-b-a-b-c --…...

html+css 实现水波纹按钮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 文…...

科技与占星的融合:AI 智能占星师
本文由 ChatMoney团队出品 在科技的前沿领域,诞生了一位独特的存在——AI占星师。它并非传统意义上的占星师,而是融合了先进的人工智能技术与神秘的占星学知识。 这能够凭借其强大的数据分析能力和精准的算法,对星辰的排列和宇宙的能量进行深…...

判断字符串,数组方法
判断字符串方法 在JavaScript中,可以使用typeof操作符来判断一个变量是否为字符串。 function isString(value) {return typeof value string; } 判断数组 在JavaScript中,typeof操作符并不足以准确判断一个变量是否为数组,因为typeof会…...

SpringBoot Vue使用Jwt实现简单的权限管理
为实现Jwt简单的权限管理,我们需要用Jwt工具来生成token,也需要用Jwt来解码token,同时需要添加Jwt拦截器来决定放行还是拦截。下面来实现: 1、gradle引入Jwt、hutool插件 implementation com.auth0:java-jwt:3.10.3implementatio…...

java中的多态
多态基础了解: 面向对象的三大特征:封装,继承,多态。 有了面向对象才有继承和多态,对象代表什么,就封装对应的数据,并提供数据对应的行为,可以把零散的数据和行为进行封装成一个整…...
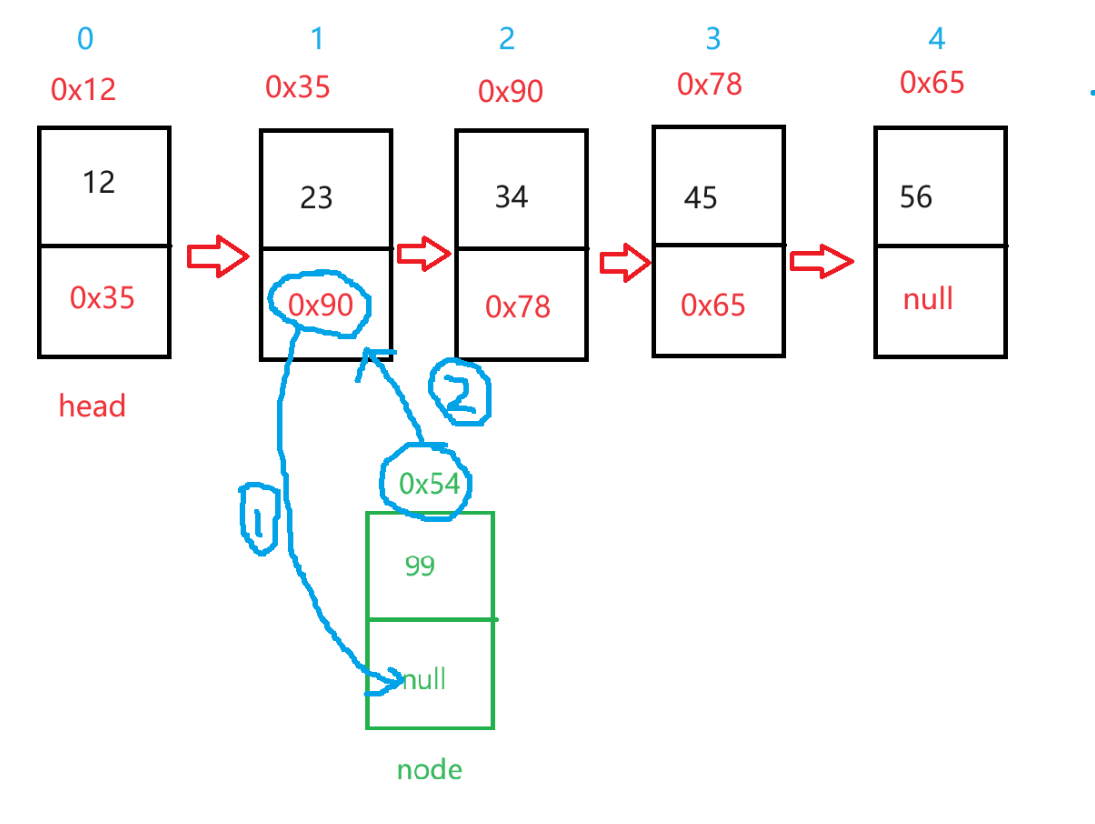
【数据结构】:用Java实现链表
在 ArrayList 任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为 O(n),效率比较低,因此 ArrayList 不适合做任意位置插入和删除比较多的场景。因此:java 集合中又引入了 LinkedList&…...

前端开发知识(三)-javascript
javascript是一门跨平台、面向对象的脚本语言。 一、引入方式 1.内部脚本:使用<script> ,可以放在任意位置,也可以有多个,一般是放在<body></body>的下方。 2.外部脚本:单独编写.js文件ÿ…...
-MFC-C/C++ - MFC绘图)
Windows图形界面(GUI)-MFC-C/C++ - MFC绘图
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 MFC绘图 绘图基础 CPaintDC 实例代码 MFC绘图 绘图基础 设备上下文(Device Context, DC): 设备上下文是一个Windows GDI(图形设备接口)…...

51单片机-第五节-串口通信
1.什么是串口? 串口是通讯接口,实现两个设备的互相通信。 单片机自带UART,其中引脚有TXD发送端,RXD接收端。且电平标准为TTL(5V为1,0V为0)。 2.常见电平标准: (1)TTL电…...

【Linux常用命令】之df命令
Linux常用命令之df命令 文章目录 Linux常用命令之df命令常用命令之df背景介绍 总结 作者简介 听雨:一名在一线从事多年研发的程序员,从事网站后台开发,熟悉java技术栈,对前端技术也有研究,同时也是一名骑行爱好者。 D…...

2024年起重信号司索工(建筑特殊工种)证模拟考试题库及起重信号司索工(建筑特殊工种)理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年起重信号司索工(建筑特殊工种)证模拟考试题库及起重信号司索工(建筑特殊工种)理论考试试题是由安全生产模拟考试一点通提供,起重信号司索工(建筑特殊工种)证模拟考试题库是根据起重信号司索工(建筑特…...
)
AWS全服务历史年表:发布日期、GA和服务概述一览 (全)
我一直在尝试从各种角度撰写关于Amazon Web Services(AWS)的信息和魅力。由于我喜欢技术历史,这次我总结了AWS服务发布的历史年表。 虽然AWS官方也通过“Whats New”发布了官方公告,但我一直希望能有一篇文章将公告日期、GA日期&…...

三步轻松上手:BilldDesk Pro开源远程桌面控制工具完整指南
三步轻松上手:BilldDesk Pro开源远程桌面控制工具完整指南 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制、游戏串流 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 如果你正在寻找一款功能强大且完全免费的跨…...

147.YOLOv8 vs YOLOv5 核心差异 + 缺陷检测完整代码,从原理到落地一步到位
摘要 YOLO(You Only Look Once)系列算法是目标检测领域最具影响力的单阶段检测模型。本文从零开始,系统讲解YOLOv8的核心原理与完整实践流程。通过一个工业级缺陷检测案例,覆盖从数据准备、模型训练、评估到部署的全链路。所有代码均基于Ultralytics官方库实现,确保可复现…...

OctoSuite代码审查:深入理解GitHub数据模型设计的5个关键要点
OctoSuite代码审查:深入理解GitHub数据模型设计的5个关键要点 【免费下载链接】octosuite Terminal-based toolkit for GitHub data analysis. 项目地址: https://gitcode.com/gh_mirrors/oc/octosuite OctoSuite是一个强大的终端GitHub数据分析工具包&#…...

实战指南 | Vivado自定义IP核在IP Catalog中“隐身”与“灰显”的排查与修复
1. 自定义IP核"隐身"与"灰显"问题全景解析 第一次在Vivado中封装自己的IP核时,那种成就感简直无法形容。但当兴冲冲地想在另一个工程中调用这个"宝贝"时,却发现它在IP Catalog中要么完全消失不见,要么像个害羞…...
)
音乐网站与分享平台 |基于Springboot+vue的音乐网站与分享平台(源码+数据库+文档)
音乐网站与分享平台 目录 基于Springbootvue的音乐网站与分享平台 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师…...

README智能生成工具:从项目分析到自动化文档的工程实践
1. 项目概述:一个为README注入灵魂的智能工具在开源社区和日常开发中,README文件的重要性不言而喻。它不仅是项目的门面,更是连接开发者与用户、贡献者之间的第一座桥梁。然而,有多少次,我们面对一个功能强大但文档寥寥…...

AI 重构泳装产业,先智先行如何破解行业痛点
春夏季泳装市场需求旺盛,但多数企业深陷效率与成本双重焦虑:设计周期冗长、打板损耗偏高、营销内容同质化严重,难以快速响应潮流变化。北京先智先行科技有限公司聚焦 AI 技术赋能,推出 “先知大模型”“先行 AI 商学院”“先知 AI…...

从DO-178标准演进看多核系统耦合分析:隐式要求显式化与可视化实践
1. 从文学课堂到工程标准:隐式与显式的分野在大学里,我的文学课老师总是不厌其烦地强调“隐式”与“显式”含义的区别。理解这种区别,是读懂一部小说深层隐喻、体会作者言外之意的关键。当时觉得这不过是文学分析的技巧,直到我踏入…...

供应商风险评估,是怎么做的?我亲历的两家工厂对比
🏎️ SQE供应商质量管理实战系列 第3篇/共50篇供应商风险评估,是怎么做的?我亲历的两家工厂对比有一年,公司要给一款新车型采购某个零件,在全球范围内选供应商。有一年,公司要给一款新车型采购某个零件&am…...

Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务 对于在arm7架构硬件上部署轻量级AI应用的开发者而言,将大模型…...