Transformer!自注意力机制的高层级理解Attention Is All You Need!
背景
最近在不断深入学习LLM的相关内容,那么transformer就是一个绕不开的话题。然而对于一个NLP门外汉来说,论文看得是真头疼,总览全网,我们似乎缺少一个至高而下的高层级理解。所以本文就来弥补此方面的缺失~
本文并不讲解有关Transformer的任何详细的模型结构说明,而是从论文出发,为大家详细解释Transformer原理的高层级理解,希望大家即使不了解模型细节,也可以理解Transformer的算法原理,并在此基础上可以更快的入门Transformer!
算法背景介绍
- 序列建模:在处理语言建模和机器翻译等序列问题时,传统上我们使用循环神经网络(RNN)或长短时记忆网络(LSTM)等模型。这些模型通过递归地处理序列中的每个元素来捕捉序列的依赖关系。
在很久很久以前~~,大模型针对上下文的理解使用的是循环神经网络。
循环神经网络比普通的神经网络多了一个特殊的隐藏层,用以保存上一次运行的输出。针对于循环神经网络的每一次运行,输入有两个:
- 当前输入
- 之前的输出结果
此时相当于模型对于当前的运算会参考之前的输出结果……
类似的,也就可以用于NLP任务上,这样模型在预测当前单词的时候会参考之前的文本。
但是这种方式存在一个最大的弊端,会产生信息在不断丢失的问题。相当于,虽然每一次运行都会参考之前的输出,但是对于该算法来说,影响最大的上一次的运行、其次是上上次运行、其次是上上上次运行……也就是说越远的单词对于当前的预测的影响越低!
可以在我们实际的语言交流中,单词的相关性并非和单词位置绑定,有可能最开始的单词和最末尾的单词相关性很大呢!所以该算法在发展了几年之后很快就不适用了。
- 注意力机制:注意力机制允许模型在处理序列时,关注到与当前任务最相关的部分,而忽略其他不相关的信息。这有助于模型更好地捕捉长距离的依赖关系。
这是本文的重点也是后续LLM大预言模型的奠基!
Transformer模型介绍
- 核心思想:Transformer模型完全基于注意力机制,不使用任何递归或循环操作。它利用自注意力(Self-Attention)机制来捕捉序列内部的依赖关系。
循环递归方法的最大问题就在于对于长上下文的单词之间的相关性获取不清晰。
自注意力机制全部摒弃了上诉的方案,详细的原理请继续阅读~
- 模型架构:Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成。编码器和解码器都包含多个相同的层,每层都有自注意力机制和前馈神经网络(Feed Forward Neural Network)。
- 自注意力机制:自注意力机制允许模型在处理序列中的每个元素时,都考虑到序列中的其他所有元素。这使得模型能够捕捉到元素之间的长距离依赖关系。
- 多头注意力(Multi-Head Attention):为了提升模型的表达能力,Transformer使用了多头注意力机制。这相当于将输入分成多个部分,每个部分都经过一个自注意力机制的处理,然后将结果拼接起来。
模型的优势
- 并行化:由于Transformer不依赖于递归操作,因此可以实现更高的并行计算能力,加快训练速度。
- 长距离依赖:通过自注意力机制,Transformer能够更好地捕捉序列中的长距离依赖关系。
- 性能提升:实验结果显示,Transformer在机器翻译等任务上的性能优于传统的循环神经网络和卷积神经网络模型。
自注意力机制的高层级原理说明
自注意力机制(Self-Attention Mechanism)是一种允许模型在处理单个序列时,序列中的每个元素(如单词)都能关联到其他元素的方法,从而捕获元素间的依赖关系,无论这些元素在序列中的距离有多远。这种机制是Transformer模型的核心组成部分。
自注意力机制的原理可以概括为以下几点:
-
输入表示:首先,将输入序列(如句子中的单词)转换为一系列高维向量(称为嵌入向量)。这些向量既包含了单词本身的信息,也包含了位置信息,因为Transformer模型本身并不理解序列中元素的顺序,需要通过额外的位置编码来提供这一信息。
第一部分并不涉及自注意力机制的核心,主要是对输入进行了一次embedding操作,即文本转向量的操作。除此之外还额外添加了一个位置信息。对于本处嵌入向量不理解的同学,可以先暂时暂停此处,搜索一下文本嵌入的相关知识。此部分的理解对于后续的理解还是很重要的。
-
查询、键和值:在自注意力层中,每个嵌入向量被转换为三个向量:查询(Query)、键(Key)和值(Value)。这三个向量是通过将原始嵌入向量与三个不同的权重矩阵相乘得到的。查询向量用于与其他元素的键向量进行比较,键向量用于与查询向量进行相似度计算,而值向量则包含了实际要提取的信息。
查询(Query)、键(Key)和值(Value)是注意力机制(Attention Mechanism)中的核心概念,它们在Transformer模型中被广泛用于计算序列中的元素之间的关系,即相关性。
可能很多读者看到这里会有一个疑惑,那就是为什么要求这些相关性?
其实本质的原因在于模型在进行当前单词推理的时候,需要参考往期元素,那么谁来决定参考哪些往期元素呢?这就是原因,相关性越高的元素,被当前操作参考的权重越大。
-
相似度计算:使用点积(或缩放点积)计算每个查询向量与序列中所有键向量的相似度。这一步骤的目的是确定序列中哪些元素与当前元素(由查询向量表示)最相关。
查询(query)相当于当前需要处理的单词的嵌入向量,键(key)相当于和位置信息绑定的其他元素的嵌入向量,值(value)相当于关联性的程度。
-
权重分配:根据相似度得分(通常通过softmax函数进行归一化),为序列中的每个元素的值向量分配权重。相似度得分高的元素将获得更高的权重,这意味着它们对当前元素的表示贡献更大。
-
加权求和:将加权后的值向量进行求和,得到当前元素的自注意力输出。这个输出向量包含了序列中所有元素对当前元素的影响,从而能够捕获元素间的长期依赖关系。
-
并行处理:由于自注意力机制在计算每个元素的输出时,都是独立于序列中其他元素的计算的,因此可以实现高度的并行化。这使得Transformer模型在训练时能够比传统的循环神经网络(RNN)或卷积神经网络(CNN)更快。
-
多头自注意力:Transformer模型还采用了多头自注意力机制,即使用多个不同的自注意力层来并行地处理输入序列。每个头都可以学习到输入序列的不同方面的信息,然后通过拼接和线性变换将这些信息合并起来,以获得更丰富的表示。
查询(Query)、键(Key)和值(Value)
查询(Query)、键(Key)和值(Value)是注意力机制(Attention Mechanism)中的核心概念,它们在Transformer模型中被广泛用于计算序列中的元素之间的关系。以下是针对这三个概念的详细描述:
- 查询(Query):
- 定义:在注意力机制的上下文中,查询是一个向量,它代表了当前位置(如解码器中的当前时间步)对输入序列中其他位置信息的需求或关注点。
- 作用:查询用于与序列中所有位置的键(Key)进行比较,以决定哪些位置的信息对当前位置的输出有重要影响。
- 计算方式:查询通常是通过模型的某些层的输出得到的,这些层可能包括嵌入层、自注意力层或编码器的输出。
- 键(Key):
- 定义:键也是向量,它代表了序列中每个位置的信息,用于与查询进行比较,以决定该位置的信息是否应该被包含在最终的注意力权重中。
- 作用:键是序列中每个元素(或位置)的表示,它们与查询进行相似性比较,以计算注意力分数(Attention Scores)。
- 计算方式:键通常是通过将输入序列通过嵌入层或编码器层的输出得到的,与查询的计算方式相似,但在注意力机制中,键用于与查询进行比较。
- 值(Value):
- 定义:值同样是向量,它们包含了序列中每个位置的实际信息,这些信息将被用来根据注意力权重进行加权求和,以产生注意力机制的输出。
- 作用:值代表了序列中每个位置的实际内容,是最终注意力机制输出的重要信息来源。注意力权重决定了每个值向量对当前输出的贡献程度。
- 计算方式:值通常与键的计算方式相同,因为在实际实现中,键和值通常来自同一组输入(尽管在自注意力机制中,它们可以相同,也可以不同)。然而,在注意力机制的输出计算中,值会根据注意力权重进行加权求和。
在Transformer模型中,自注意力层(Self-Attention Layer)使用了这些概念来计算序列内部元素之间的依赖关系。通过查询、键和值的交互,模型能够学习到序列中哪些元素对于当前位置是重要的,并将这些信息以加权求和的形式融入到当前位置的输出中。
总结
在Transformer模型中,自注意力机制(Self-Attention Mechanism)扮演着至关重要的角色。它是Transformer模型架构的核心组成部分之一,负责处理序列数据中的依赖关系,特别是那些长距离依赖关系,这在自然语言处理(NLP)等任务中尤为重要。
相关文章:
Transformer!自注意力机制的高层级理解Attention Is All You Need!
背景 最近在不断深入学习LLM的相关内容,那么transformer就是一个绕不开的话题。然而对于一个NLP门外汉来说,论文看得是真头疼,总览全网,我们似乎缺少一个至高而下的高层级理解。所以本文就来弥补此方面的缺失~ 本文并不讲解有关…...

关于使用Postman在请求https网址没有响应,但是用浏览器有响应的问题解决
一、问题描述 使用postman调用正式环境的公共接口,无需鉴权,但是产生了返回状态码200,但是data中却无数据,如下 {"code": "200","message": "操作成功","data": {"qr_c…...

【React 】开发环境搭建详细指南
文章目录 一、准备工作1. 安装 Node.js 和 npm2. 选择代码编辑器 二、创建 React 项目1. 使用 Create React App2. 手动配置 React 项目 三、集成开发工具1. ESLint 和 Prettier2. 使用 Git 进行版本控制 在现代前端开发中,React 是一个非常流行的框架,用…...
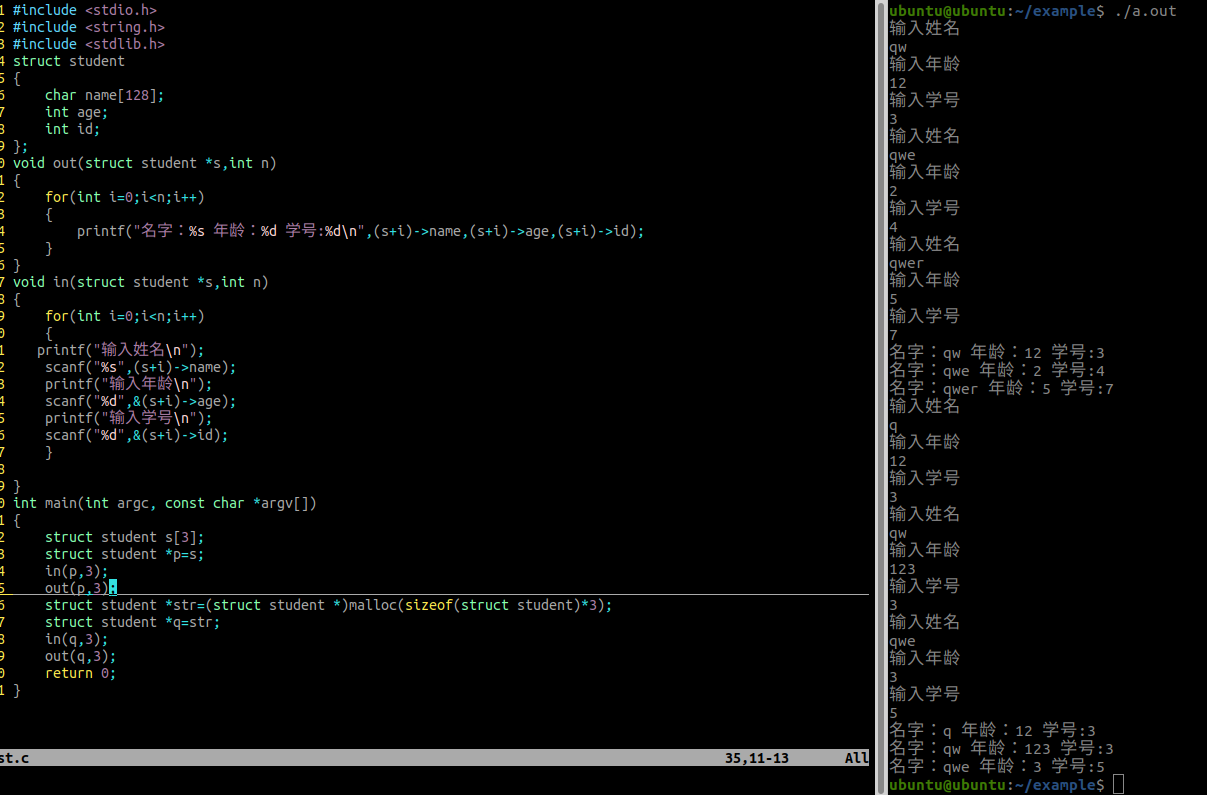
结构体笔记
结构体 C语言中的数据类型: 基本数据类型:char/int/short/double/float/long 构造数据类型:数组,指针,结构体,共用体,枚举 概念: 结构体是用户自定义的一种数据类型,…...

Elasticsearch:Golang ECS 日志记录 - zerolog
ECS 记录器是你最喜欢的日志库的格式化程序/编码器插件。它们可让你轻松地将日志格式化为与 ECS 兼容的 JSON。在本教程中,我将详述如何 编码器以 JSON 格式记录日志,并以 ECS 错误格式处理错误字段的记录。 默认情况下,会添加以下字段&…...

Ip2region - 基于xdb离线库的Java IP查询工具提供给脚本调用
文章目录 Pre效果实现git clone编译测试程序将ip2region.xdb放到指定目录使用改进最终效果 Pre OpenSource - Ip2region 离线IP地址定位库和IP定位数据管理框架 Ip2region - xdb java 查询客户端实现 效果 最终效果 实现 git clone git clone https://github.com/lionsou…...
研发管理革命:探索顶尖的工时系统选择
国内外主流的10款研发工时管理系统对比:PingCode、Worktile、无鱼项目工时系统、Toggl Track、泽众ALM、Asana、Jira、GitHub、Trello、TrackingTime。 在研发团队中,工时管理常常成为效率瓶颈,尤其是在资源分配和项目进度跟踪方面。选择合适…...

微服务-MybatisPlus下
微服务-MybatisPlus下 文章目录 微服务-MybatisPlus下1 MybatisPlus扩展功能1.1 代码生成1.2 静态工具1.3 逻辑删除1.4 枚举处理器1.5 JSON处理器**1.5.1.定义实体****1.5.2.使用类型处理器** **1.6 配置加密(选学)**1.6.1.生成秘钥**1.6.2.修改配置****…...

【python_将一个列表中的几个字典改成二维列表,并删除不需要的列】
def 将一个列表中的几个字典改成二维列表(original_list,headersToRemove_list):# 初始化一个列表用于存储遇到的键,保持顺序ordered_keys []# 遍历data中的每个字典,添加其键到ordered_keys,如果该键还未被添加for d in original_list:for …...

IDEA的pom.xml显示ignored 的解决办法
问题: idea中创建Maven module时,pom.xml出现ignored。 原因: 相同名称的module在之前被创建删除过,IDEA会误以为新的同名文件是之前删除掉的,将这个新的module的pom.xml文件忽略掉显示ignored. 解决: 在…...

2. 卷积神经网络无法绕开的神——LeNet
卷积神经网络无法绕开的大神——LeNet 1. 基本架构2. LeNet 53. LeNet 5 代码 1. 基本架构 特征抽取模块可学习的分类器模块 2. LeNet 5 LeNet 5: 5 表示的是5个核心层,2个卷积层,3个全连接层.核心权重层:卷积层、全连接层、循环层ÿ…...
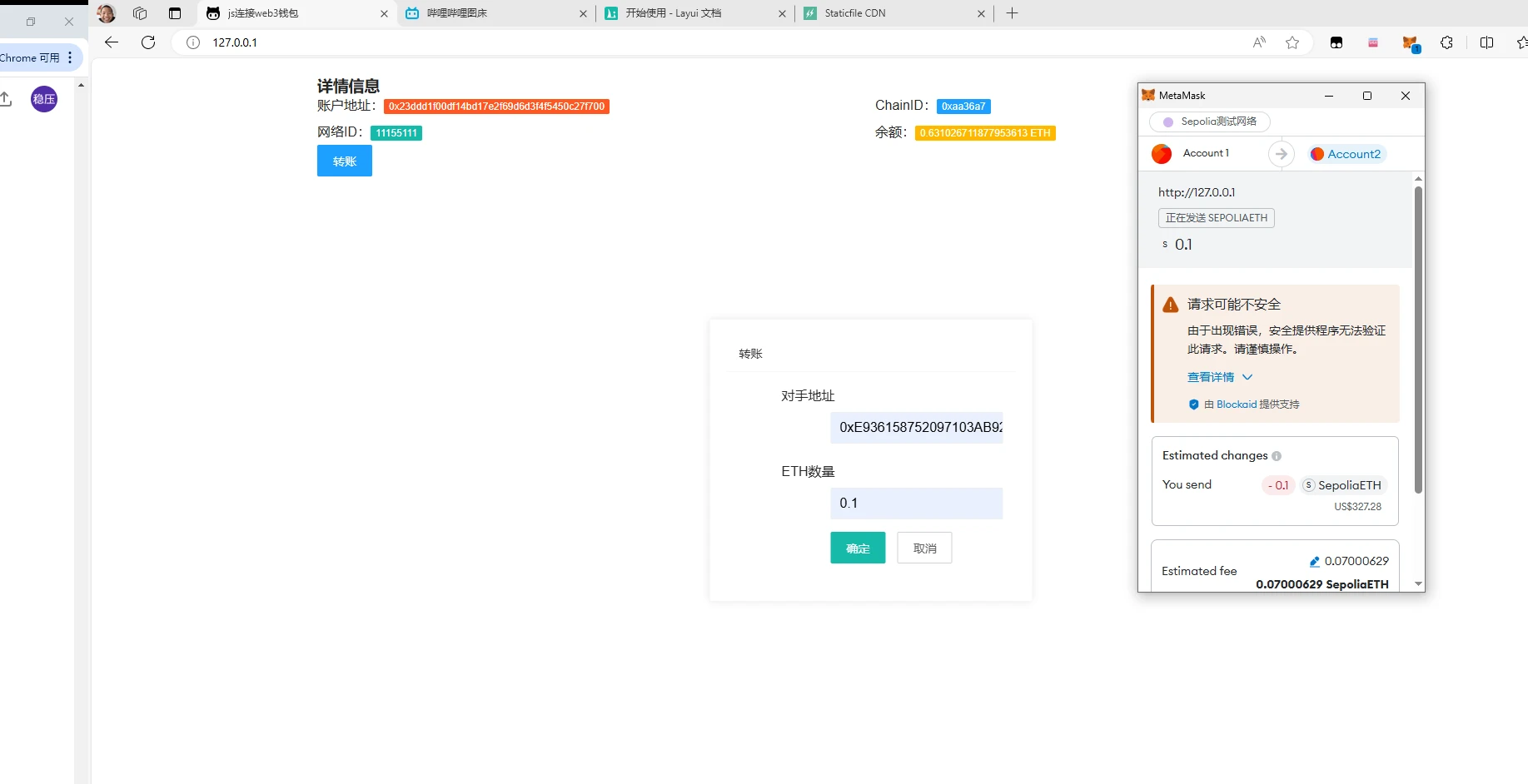
【区块链】JavaScript连接web3钱包,实现测试网络中的 Sepolia ETH余额查询、转账功能
审核看清楚了 ! 这是以太坊测试网络!用于学习的测试网络!!! 有关web3 和区块链的内容为什么要给我审核不通过? 别人凭什么可以发! 目标成果: 实现功能分析: 显示账户信…...

关于珞石机器人二次开发SDK的posture函数的算法RX RY RZ纠正 C#
在珞石SDK二次开发的函数钟,获取当前机器人位姿的函数posture函数在输出时会发现数据不正确,与示教器数据不一致。 其中第一个数据正确 第二三各数据为相反 第四五六各数据为弧度制 转换方法为(弧度/PI)*180度 然后发现第四个数据还要加上180度 第五…...

【Three.js基础学习】17.imported-models
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 课程回顾: 如何在three.js 中引入不同的模型? 1. 格式 (不同的格式) https://en.wikipedia.org/wiki/List_of_file_form…...

Spring Bean - xml 配置文件创建对象
类型: 1、值类型 2、null (标签) 3、特殊符号 (< -> < ) 4、CDATA <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/bea…...

uniapp map组件自定义markers标记点
需求是根据后端返回数据在地图上显示标记点,并且根据数据状态控制标记点颜色,标记点背景通过两张图片实现控制 <mapstyle"width: 100vw; height: 100vh;":markers"markers":longitude"locaInfo.longitude":latitude&…...

Windows:批处理脚本学习
目录 一、第一个批处理文件 1. &&和 | | 2. | 和 & 二、变量 1.传参变量%name 2.初始化变量set命令 3.变量的使用 4.局部变量与全局变量 5.使用环境变量 6.扩充变量语法 三、注释REM和 :: 四:函数 1.定义函数 2.…...

Dav_笔记10:Using SQL Plan Management之4
SQL管理库 SQL管理库(SMB)是驻留在SYSAUX表空间中的数据字典的一部分。它存储语句日志,计划历史记录,SQL计划基准和SQL配置文件。为了允许每周清除未使用的计划和日志,SMB使用自动空间管理。 您还可以手动将计划添加到SMB以获取一组SQL语句。从Oracle Database 11g之前的…...

通过json传递请求参数,如何处理动态参数和接口依赖
嗨,大家好,我是兰若姐姐,今天给大家讲一下如何通过json传递请求参数,如何处理动态参数和接口依赖 1. 使用配置文件和模板 在 test_data.json 中,你可以使用一些占位符或模板变量,然后在运行测试之前&…...

[240727] Qt Creator 14 发布 | AMD 推迟 Ryzen 9000芯片发布
目录 Qt Creator 14 发布Qt Creator 14 版本发布,带来一系列新功能和改进终端用户可通过命令行方式查看此新闻终端用户可通过命令行方式安装软件: AMD 推迟 Ryzen 9000芯片发布 Qt Creator 14 发布 Qt Creator 14 版本发布,带来一系列新功能…...

基于物理信息神经网络与降阶模型的文物数字孪生保护框架
1. 项目概述:当文化遗产保护遇上科学计算与人工智能最近几年,我一直在关注一个交叉领域:如何用前沿的计算科学和人工智能技术,去解决那些看似传统、实则充满挑战的文物保护难题。这次分享的“基于SciML与数字孪生的文化遗产保护框…...
)
别再手动造数据了!用Python的imgaug库5分钟搞定深度学习图像增强(附关键点/边界框处理避坑指南)
深度学习图像增强实战:用imgaug打造高效数据流水线 在计算机视觉项目中,数据增强是提升模型泛化能力的关键步骤。传统手动处理方式不仅耗时耗力,还难以保证处理一致性。本文将深入探讨如何利用Python的imgaug库快速构建自动化图像增强流程&am…...

实测:2026 年国内直连 AI 一站式平台,聊天 / 绘画 / 论文 / 视频全搞定,不用翻墙不花冤枉钱
最近 AI 圈真的太卷了。ChatGPT 5.4、Gemini 3.1、Claude Code 轮番上新,多模态、长文本、代码 Auto Mode 一个比一个强。但普通用户想用明白,真的太折腾。先说说我踩过的三大坑,句句大实话网络糟心到崩溃官网打不开、地区不可用、加载转圈、…...

基于STM32的数控恒流源:从硬件闭环到软件PD调节的工程实践
1. 数控恒流源的核心需求与设计思路 第一次接触数控恒流源是在三年前的一个工业检测设备项目中,当时需要为传感器阵列提供精确的电流激励。传统模拟恒流方案遇到温度漂移问题,最终选择了STM32数控方案。这种方案最大的优势在于:硬件闭环保证响…...

AI专著生成神器登场!快速输出20万字专著,写作不用愁!
学术专著写作困境与AI工具的崛起 对于许多学术研究者来说,撰写学术专著时面临的最大挑战,无疑是“有限的精力”和“无穷的需求”之间的矛盾。撰写专著通常需要三到五年,甚至更长时间,而研究者还需平衡教学、科研项目和学术交流等…...

基于OneBot协议与Go语言的QQ机器人框架Samantha开发实践
1. 项目概述:一个开源的QQ机器人框架 最近在折腾QQ机器人,想给自己的社群或者频道加点自动化功能,比如定时提醒、关键词回复、游戏查询什么的。市面上现成的机器人框架不少,但要么功能臃肿,要么配置复杂,要…...

Windows安卓应用安装神器:APK Installer完整使用指南
Windows安卓应用安装神器:APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法运行安卓应用而烦恼吗ÿ…...

某恶意软件样本逆向分析报告
1.概述样本来源:微步在线恶意软件名称:刘文博-关于北京体彩中心的问题反馈.exesha256:c28d23d8658abc1f5683c6b50239d5593eb7a274a3abec56124d7fb43fec1b642.行为分析该程序图标设为word文档图标,实际为exe文件,诱骗受…...

PCB高级工艺如何降本:盲孔、微孔与HDI设计的成本优化实战
1. 项目概述:当高级PCB技术成为降本利器在硬件研发圈子里待久了,总有一个根深蒂固的印象:但凡沾上“高级”、“高密度”这些词的技术,比如盲孔、埋孔和微孔,那成本肯定是蹭蹭往上涨。我刚开始接触HDI板设计时也是这么想…...
)
STM32实战:手把手教你用Cubemx配置交流充电桩的CP信号检测(附代码)
STM32实战:从零构建充电桩CP信号检测系统 充电桩作为新能源汽车基础设施的核心组件,其通信协议的可靠性直接关系到充电安全。在实际工程中,CP(Control Pilot)信号的检测往往是开发者的第一个技术拦路虎。我曾在一个海外…...