大数据采集工具——Flume简介安装配置使用教程
Flume简介&安装配置&使用教程
1、Flume简介
一:概要
Flume 是一个可配置、可靠、高可用的大数据采集工具,主要用于将大量的数据从各种数据源(如日志文件、数据库、本地磁盘等)采集到数据存储系统(主要为Hadoop HDFS)中,用来处理日志数据,并支持在数据流中可靠、高效地移动数据。
二:Flume的基础架构
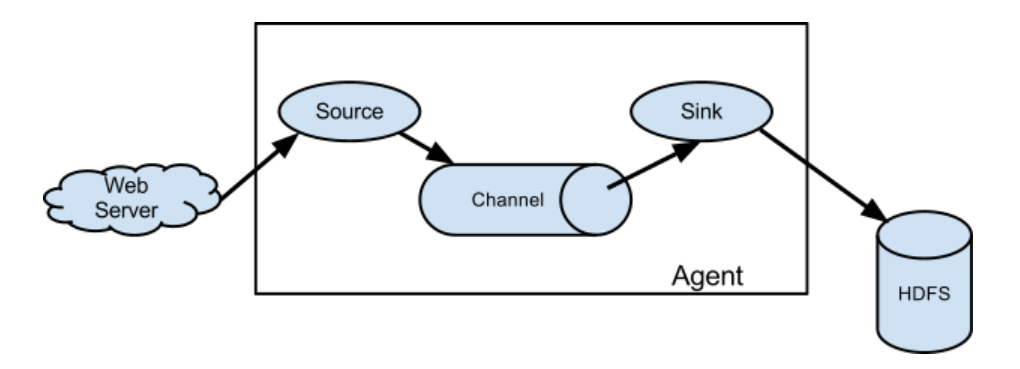
详细讲解:
Flume主要由三部分组成:Source,Channel,Sink。
1.Source:负责接收数据至 Flume Agent 组件中【入口】,常见的数据源主要有TailDir,SpoolingDir。
- SpoolingDir和TailDir都是Flume中的一个文件型数据源,可以实时监控指定目录下的新增和修改文件,并将这些文件的内容传输至Flume中。
- TailDir适用于实时监控日志文件并传输到其他系统的场景,特别是处理持续追加内容的日志文件情景,支持正则表达式匹配文件名。
- SpoolingDir适用于同步新文件(完整且不变)到Flume Sink的场景,不支持直接通过正则表达式匹配文件名。
2.Channel:位于 Source 和 Sink 之间的【缓冲区】。通常是Memory【内存中的队列】,File,Kafka。
3.Sink:负责从Channel缓冲区中获取数据并将其存储到目标存储系统中【出口】。目标存储系统一般有HDFS,Hive,Hbase,Kafka,通常将数据存放于HDFS中。
2、Flume安装配置
# 1、将安装包放置虚拟机中的/opt/download目录下# 2、解压缩至/opt/software目录下,并改名为flume-1.9.0
解压:cd /opt/downloadtar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/software/
重命名:cd /opt/softwaremv apache-flume-1.9.0-bin/ flume-1.9.0# 3、复制相关依赖操作
进入flume的lib目录中:cd /opt/software/flume-1.9.0/lib/# 复制 hadoop 相关依赖到flume的lib目录下cp /opt/software/hadoop-3.1.3/share/hadoop/*/*.jar ./# 复制 hive hcatelog 相关依赖到flume的lib目录下cp /opt/software/hive-3.1.2/hcatalog/share/hcatalog/*.jar ./# 复制 hive 相关依赖到flume的lib目录下cp /opt/software/hive-3.1.2/lib/hive-*.jar ./cp /opt/software/hive-3.1.2/lib/antlr*.jar ./# 4、放大堆内存
进入flume的bin目录下:cd /opt/software/flume-1.9.0/bin/vim flume-ng--------- 修改配置 -----------JAVA_OPTS="-Xmx1024m"-----------------------------# 结束!
3、Flume使用教程——交易行为日志采集
一:创建ebs_act_log目录存放源数据【入口】
此处我们的数据源是与交易相关的数据。因此,在ebs_act_log目录下创建一个transaction_log目录,用于存放与交易数据相关的文件。此处的transaction_log目录将作为【数据来源】使用,今后只需将相关数据文件放置在该目录下即可,主要用于【上传数据】
mkdir ebs_act_log
cd ebs_act_log
mkdir transaction_log
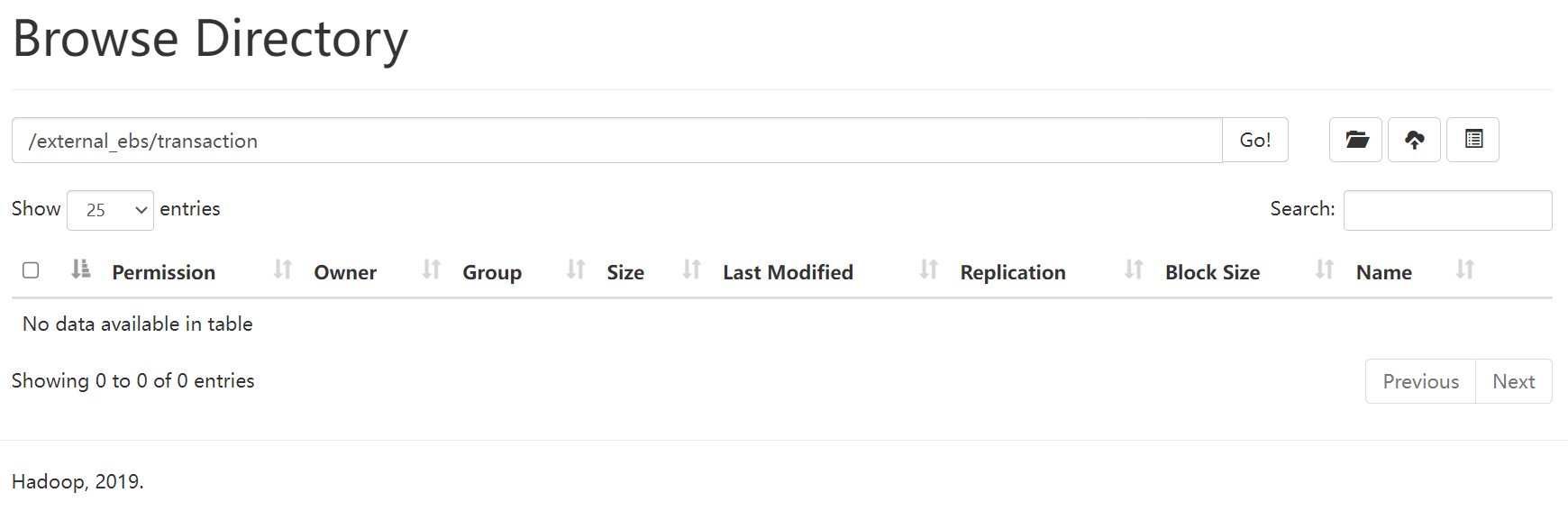
二:需在HDFS上提前创建好存放数据的目录【出口】
此处,我们将数据存放在**/external_ebs/transaction**目录下,如图所示:
三:Flume相关需求配置
为了使得构建时目录结构清晰,同时为我们之后做数仓更为便利,我将Flume相关配置统一放置在了project_ebs目录中的act_log_extract/flume_config目录下。
在flume_config目录中我们需要构建四个基本目录,分别是channel-checkpoint、channel-data、conf-file、position-file。先介绍这四个目录分别所起到的作用:
- channel-checkpoint和channel-data目录是存放任务过程文件;
- position-file目录是存放位置记录相关文件,便于下次读取数据时无需重复读取相同内容;
- conf-file目录是用于存放flume相关的配置文件。
在position-file目录中可以创建一个文件transaction_pos.log,内部可先进行以下操作:

然后,在conf-file目录下创建transaction.cnf文件【其中配置源文件source,目标文件sink,以及channel相关信息】,Flume数据采集就是通过读取此配置来实现实时监控。【◉:可修改处】
vim transaction.cnf
-----------------------------------------------------------------------
a1.sources = r1
a1.channels = c1
a1.sinks = s1 a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /root/project_ebs/act_log_extract/flume_config/position-file/transaction_pos.log # 采集数据的相关位置记录:标志读取数据位置,便于下次操作时不重复读取相同内容 ◉
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/ebs_act_log/transaction_log/part-.* # 数据来源【数据名不可相同,否则会覆盖】◉
a1.sources.r1.fileHeader = false # 数据没有表头,只需填写 false 即可;若有,则true
# a1.sources.r1.headers.f1.headerKey1 = store # 数据没有表头,就无需配置a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/project_ebs/act_log_extract/flume_config/channel-checkpoint # 检查点
a1.channels.c1.dataDirs = /root/project_ebs/act_log_extract/flume_config/channel-data # 管道数据a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.fileType = DataStream # 不会压缩输出文件,若不配置会进行序列化操作
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.path = hdfs://single:9000/external_ebs/transaction # 将数据存放到hdfs中目录下【目录路径】◉
a1.sinks.s1.hdfs.filePrefix = event-
a1.sinks.s1.hdfs.fileSuffix = .json # 结果出来文件的后缀名
a1.sinks.s1.hdfs.rollInterval = 180 # 180s溢写一次
a1.sinks.s1.hdfs.rollSize = 134217728 # 128M溢写一次
a1.sinks.s1.hdfs.rollCount = 0# 关联sources,channels,sinks
a1.sinks.s1.channel = c1
a1.sources.r1.channels = c1
-----------------------------------------------------------------------
四:启动Flume检测
说明:其中--name a1中名为a1是因为在配置中都是以a1开头进行配置的,--conf指向flume中conf文件,--conf-file指向我们所配置的transaction.cnf文件。
/opt/software/flume-1.9.0/bin/flume-ng agent \
--name a1 \
--conf /opt/software/flume-1.9.0/conf/ \
--conf-file /root/project_ebs/act_log_extract/flume_config/conf-file/transaction.cnf \ # ◉
-Dflume.root.logger=INFO,console
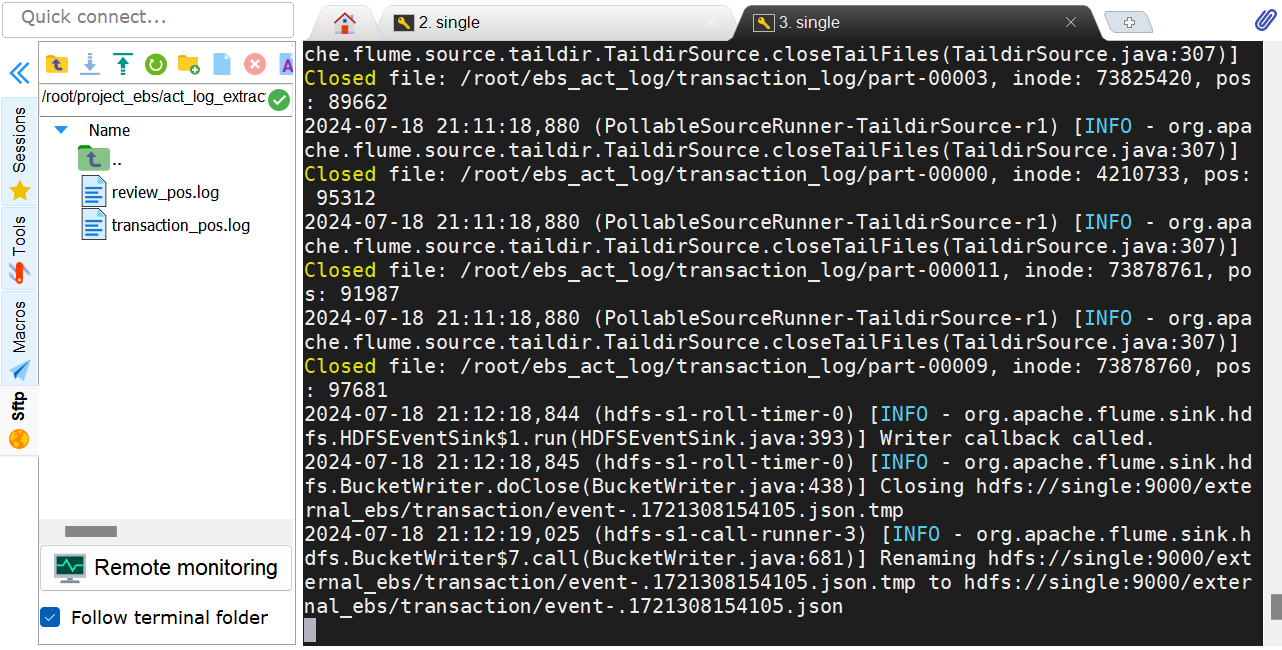
HDFS存储结果:

五:定期处理
由于channel-checkpoint和channel-data中存放与过程相关数据,可以对其进行定期的处理。
rm -rf channel-checkpoint/*
rm -rf channel-data/*
相关文章:
大数据采集工具——Flume简介安装配置使用教程
Flume简介&安装配置&使用教程 1、Flume简介 一:概要 Flume 是一个可配置、可靠、高可用的大数据采集工具,主要用于将大量的数据从各种数据源(如日志文件、数据库、本地磁盘等)采集到数据存储系统(主要为Had…...

C语言 #具有展开功能的排雷游戏
文章目录 前言 一、整个排雷游戏的思维梳理 二、整体代码分布布局 三、游戏主体逻辑实现--test.c 四、整个游戏头文件的引用以及函数的声明-- game.h 五、游戏功能的具体实现 -- game.c 六、老六版本 总结 前言 路漫漫其修远兮,吾将上下而求索。 一、整个排…...

npm publish出错,‘proxy‘ config is set properly. See: ‘npm help config‘
问题:使用 npm publish发布项目依赖失败,报错 proxy config is set properly. See: npm help config 1、先查找一下自己的代理 npm config get proxy npm config get https-proxy npm config get registry2、然后将代理和缓存置空 方式一: …...
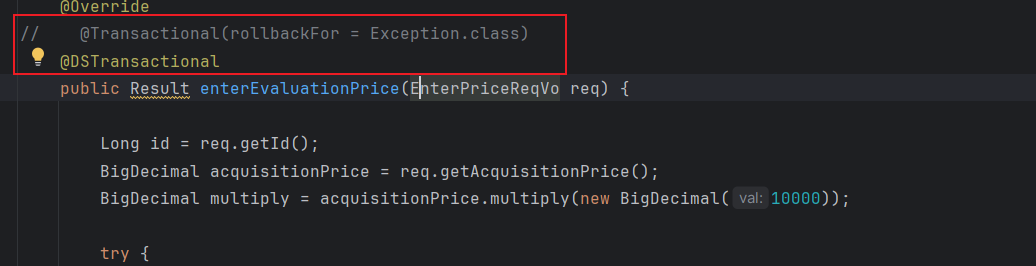
Springboot 多数据源事务
起因 在一个service方法上使用的事务,其中有方法是调用的多数据源orderDB 但是多数据源没有生效,而是使用的primaryDB 原因 spring 事务实现的方式 以 Transactional 注解为例 (也可以看 TransactionTemplate, 这个流程更简单一点)。 入口:ProxyTransa…...

Python每日学习
我是从c转来学习Python的,总感觉和c相比Python的实操简单,但是由于写c的代码多了,感觉Python的语法好奇怪 就比如说c的开头要有库(就是类似于#include <bits/stdc.h>)而且它每一项的代码结束之后要有一个表示结…...

数据库 执行sql添加删除字段
添加字段: ALTER TABLE 表明 ADD COLUMN 字段名 类型 DEFAULT NULL COMMENT 注释 AFTER 哪个字段后面; 效果: 删除字段: ALTER TABLE 表明 DROP COLUMN 字段;...

前端开发:HTML与CSS
文章目录 前言1.1、CS架构和BS架构1.2、网页构成 HTML1.web开发1.1、最简单的web应用程序1.2、HTTP协议1.2.1 、简介1.2.2、 http协议特性1.3.3、http请求协议与响应协议 2.HTML概述3.HTML标准结构4.标签的语法5.基本标签6.超链接标签6.1、超链接基本使用6.2、锚点 7.img标签8.…...

ctfshow解题方法
171 172 爆库名->爆表名->爆字段名->爆字段值 -1 union select 1,database() ,3 -- //返回数据库名 -1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema库名 -- //获取数据库里的表名 -1 union select 1,group_concat(…...

探索 Blockly:自定义积木实例
3.实例 3.1.基础块 无输入 , 无输出 3.1.1.json var textOneJson {"type": "sql_test_text_one","message0": " one ","colour": 30,"tooltip": 无输入 , 无输出 };javascriptGenerator.forBlock[sql_test_te…...

MongoDB教程(二十三):关于MongoDB自增机制
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 文章目录 引言一、MongoD…...

展馆导览系统架构解析,从需求分析到上线运维
在物质生活日益丰富的当下,人们对精神世界的追求愈发强烈,博物馆、展馆、纪念馆等场所成为人们丰富知识、滋养心灵的热门选择。与此同时,人们对展馆的导航体验也提出了更高要求,展馆导览系统作为一种基于室内外地图相结合的位置引…...

Servlet详解(超详细)
Servlet详解 文章目录 Servlet详解一、基本概念二、Servlet的使用1、创建Servlet类2、配置Servleta. 使用web.xml配置b. 使用注解配置 3、部署Web应用4、处理HTTP请求和生成响应5、处理表单数据HTML表单Servlet 6、管理会话 三、servlet生命周期1、加载和实例化2、初始化3、 请…...

Meta AI引入Imagine Me功能,上传图片输入提示词即可实现个性化照片
AITOP100平台获悉,Meta 公司在 AI 领域再次迈出了重要的步伐,其发布的 Llama 3.1 开源 AI 模型以及对 Meta AI 功能的更新扩充引发了广泛关注。 其中,新引入的“Imagine Me”功能尤为引人注目。在这一功能下,美国地区的用户只需上…...

常用自启设置
一、开机自启动 1、编辑 vi /lib/systemd/system/nginx.service 文件,没有创建一个 touch nginx.service 然后将如下内容根据具体情况进行修改后,添加到nginx.service文件中: [Unit] Descriptionnginx Afternetwork.target remote-fs.targ…...

模块与组件、模块化与组件化的理解
在React或其他现代JavaScript框架中,模块与组件、模块化与组件化是核心概念,它们对于提高代码的可维护性、复用性和开发效率具有重要意义。以下是对这些概念的理解: 模块与组件 模块(Module) 定义:模块是…...

Rust:cargo的常用命令
1.查看版本 $ cargo --version cargo 1.79.0 (ffa9cf99a 2024-06-03) 2.创建新的项目 $ cargo new hello 创建后的目录结构为 $ tree hello/ hello/ ├── Cargo.toml └── src └── main.rs 3.运行项目 $ cd hello $ cargo run Compiling hello v0.1.0 (/home/c…...
)
LeetCode 3106.满足距离约束且字典序最小的字符串:模拟(贪心)
【LetMeFly】3106.满足距离约束且字典序最小的字符串:模拟(贪心) 力扣题目链接:https://leetcode.cn/problems/lexicographically-smallest-string-after-operations-with-constraint/ 给你一个字符串 s 和一个整数 k 。 定义函…...

Elasticsearch 与 MySQL 在查询和插入性能上的深度剖析
在当今的数据处理领域,选择合适的数据库对于应用的性能和效率至关重要。Elasticsearch 和 MySQL 作为两款常用的数据库,它们在查询和插入操作上的性能表现各有千秋。本文将对这两款数据库在这两个关键操作上进行详细的对比分析。 一、引言 随着数据量的…...

day4 vue2以及ElementUI
创建vue2项目 可能用到的命令行们 vue create 项目名称 // 创建项目 cd 项目名称 // 只有进入项目下,才能运行 npm run serve // 运行项目 D: //切换盘符 cd .. // 返回到上一级目录 clear // 清空终端 更改 Vue项目的端口配置 基础语法 项目创建完成之后&#…...

把redis用在Java项目
1. Java连接redis Java连接redis的方式是通过jedis,连接redis需要遵循jedis协议。 1.1 引入依赖 <!--引入java连接redis的驱动--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version&…...

如何在手机上免费播放任何视频格式?VLC for Android给你答案!
如何在手机上免费播放任何视频格式?VLC for Android给你答案! 【免费下载链接】vlc-android VLC for Android, Android TV and ChromeOS 项目地址: https://gitcode.com/gh_mirrors/vl/vlc-android 你是否曾经遇到过这样的情况:下载了…...
如何解决你的‘时变混杂’难题)
从临床试验到互联网AB测试:边缘结构模型(MSM)如何解决你的‘时变混杂’难题
从临床试验到互联网AB测试:边缘结构模型如何破解动态混杂困局 当我们在互联网产品中测试一个新功能对用户留存率的影响时,常常会遇到一个棘手的问题:用户的行为会随着时间不断变化。比如,早期接触新功能的用户可能因为新鲜感而产生…...

Nevis‘22基准:评估持续学习模型的计算效率与知识迁移能力
1. 项目概述:为什么我们需要一个全新的终身学习基准?在计算机视觉乃至整个机器学习领域,我们正面临一个日益尖锐的矛盾:一方面,我们希望模型能够像人类一样,在漫长的时间里持续学习新知识,不断进…...
)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1) 刚拿到ZCU102开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为Xilinx旗下的高端FPGA开发平台,ZCU102强大的性能和丰富的接口让它成为…...

无需写代码!用 PackSoft 做数字展厅大屏
前言 做过展厅项目的朋友都懂这种痛—— 客户参观来了,讲解员打开浏览器,地址栏、书签栏、收藏夹全暴露在屏幕上,旁边还挂着一个没关的 QQ 弹窗……高端大气的数字展厅,体验瞬间拉低一个档次。 更麻烦的是:大屏全屏…...

基于MCP架构构建营销数据管道:打通Google Ads、Meta Ads与GA4的数据孤岛
1. 项目概述:打通营销数据孤岛的“瑞士军刀” 如果你在数字营销领域摸爬滚打过几年,尤其是在同时操盘谷歌广告和Meta广告,并且数据后台用的是Google Analytics 4,那你一定对下面这个场景深恶痛绝:老板或客户要一份整体…...

深耕落地,精准破局——应用型人工智能专业建设的实践路径
在人工智能产业快速迭代、人才需求持续升级的当下,应用型人工智能专业已成为高校布局新工科、服务区域产业的核心抓手。然而,作为一线专业带头人及授课教师,多数从业者都面临着一个共同的困惑:即便投入大量时间与精力优化培养方案…...

XXMI启动器终极指南:一站式管理原神、星穹铁道等热门游戏模组
XXMI启动器终极指南:一站式管理原神、星穹铁道等热门游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为多个游戏模组安装繁琐而烦恼吗?XXMI启…...

从内核恐慌到系统恢复:一次NMI watchdog触发的soft lockup深度诊断
1. 当服务器突然卡死:从NMI watchdog错误说起 那天下午3点,机房警报突然响起。我冲到服务器前,屏幕上赫然显示着刺眼的红色错误:"NMI watchdog: BUG: soft lockup - CPU#2 stuck for 23s!"。这台承载着核心业务的服务器…...

关于python中打开文件,以及可能错误,介绍
**该mode是基于open()函数里参数的调整** 错误代码 f r"C:\dj\dw1.txt" b f.read(c) print(b) f.close() 正确代码 f open(r"C:\dj\dw1.txt") s f.read() print(s) f.close()open()函数需要后面的打开路径,r/R表示该代码的的原意 mode…...