Meta 发布 Llama3.1,一站教你如何推理、微调、部署大模型
最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
《大模型面试宝典》(2024版) 发布!
《AIGC 面试宝典》圈粉无数!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,欢迎交流
文章目录
- 模型推理
- 模型微调
- 模型部署
- Llama3.1 工具调用服务实战
近日,Meta正式发布Llama 3.1,包含8B、70B 和405B三个规模,最大上下文提升到了128k。Llama系列模型是目前开源领域中用户最多、性能最强的大型模型系列之一。
本次Llama 3.1的要点有:
1.共有8B、70B及405B三种版本,其中405B版本是目前最大的开源模型之一;
2.该模型最大参数规模达到4050亿参数,在性能上超越了现有的顶级AI模型;
3.模型引入了更长的上下文窗口(最长可达128K tokens),能够处理更复杂的任务和对话;
4. 支持多语言输入和输出,增强了模型的通用性和适用范围;
5.提高了推理能力,特别是在解决复杂数学问题和即时生成内容方面表现突出。
为大家带来的一站式模型体验、下载、推理、微调、部署实战教程!
模型推理
以Llama-3.1-8B-Instruct为例:
import transformers
import torch
from modelscope import snapshot_downloadmodel_id = snapshot_download("LLM-Research/Meta-Llama-3.1-8B-Instruct")pipeline = transformers.pipeline("text-generation",model=model_id,model_kwargs={"torch_dtype": torch.bfloat16},device_map="auto",
)messages = [{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},{"role": "user", "content": "Who are you?"},
]outputs = pipeline(messages,max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
模型微调
我们介绍使用ms-swift对llama3_1-8b-instruct进行古文翻译腔微调,并对微调前后模型进行推理。swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和50+多模态大模型的微调、推理、量化、评估和部署。
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
微调脚本:(如果出现OOM,请降低max_length)
# 实验环境: 3090/A10
# 显存占用: 24GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model_type llama3_1-8b-instruct \--sft_type lora \--output_dir output \--dataset classical-chinese-translate \--num_train_epochs 1 \--max_length 2048 \--gradient_checkpointing true \--batch_size 1 \--gradient_accumulation_steps 16 \--warmup_ratio 0.1 \--eval_steps 100 \--save_steps 100 \--save_total_limit -1 \--logging_steps 10# 实验环境: 4 * 3090/A10
# 显存占用: 4 * 24GB
# DDP + ZeRO2
nproc_per_node=4NPROC_PER_NODE=$nproc_per_node \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \--model_type llama3_1-8b-instruct \--sft_type lora \--output_dir output \--dataset classical-chinese-translate \--num_train_epochs 1 \--max_length 2048 \--gradient_checkpointing true \--batch_size 1 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--warmup_ratio 0.1 \--eval_steps 100 \--save_steps 100 \--save_total_limit -1 \--logging_steps 10 \--deepspeed default-zero2
微调显存消耗:
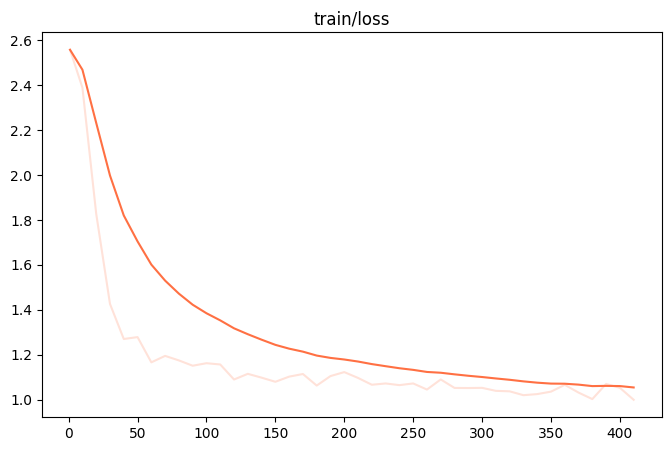
微调过程的loss可视化:
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。我们可以使用vLLM对merge后的checkpoint进行推理加速。
pip install vllm -U # vllm>=0.5.3.post1# Experimental environment: A10, 3090, V100, ...
CUDA_VISIBLE_DEVICES=0 swift export \--ckpt_dir output/llama3_1-8b-instruct/vx-xxx/checkpoint-xxx \--merge_lora true# 使用vLLM进行推理加速
CUDA_VISIBLE_DEVICES=0 swift infer \--ckpt_dir output/llama3_1-8b-instruct/vx-xxx/checkpoint-xxx-merged \--infer_backend vllm --max_model_len 4096
微调后模型对验证集进行推理的示例:

模型部署
使用vLLM部署Llama3.1-70B-Instruct
部署Llama3.1-70B-Instruct需要至少2卡80GiB A100 GPU,部署方式如下:
服务端:
# 请确保已经安装了git-lfs
git lfs installGIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3.1-70B-Instruct.git
cd Meta-Llama-3.1-70B-Instruct
git lfs pull# 实验环境:2 * A100
# <local_path>传入本地路径
CUDA_VISIBLE_DEVICES=0,1 vllm serve <local_path> \--dtype bfloat16 --served-model-name llama3_1-70b-instruct \--gpu_memory_utilization 0.96 --tensor_parallel_size 2 \--max_model_len 50000# or 实验环境:4 * A100
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve <local_path> \--dtype bfloat16 --served-model-name llama3_1-70b-instruct \--tensor_parallel_size 4
客户端:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3_1-70b-instruct",
"messages": [{"role": "user", "content": "晚上睡不着觉怎么办?"}],
"max_tokens": 1024,
"temperature": 0
}'
模型输出:
{"id":"chat-d1b12066eedf445bbee4257a8c3a1b30","object":"chat.completion","created":1721809149,"model":"llama3_1-70b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"答:如果你晚上睡不着觉,可以尝试以下方法:1. 保持卧室安静、黑暗和凉爽。2. 避免在睡前使用电子设备。3. 不要在睡前饮用含有咖啡因的饮料。4. 尝试放松技巧,如深呼吸、冥想或瑜伽。5. 如果问题持续,可以咨询医生或睡眠专家。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":19,"total_tokens":128,"completion_tokens":109}}
Llama3.1 工具调用服务实战
环境准备
Llama3.1部署依赖vllm 最新补丁版本 0.5.3.post1
# speed up if needed
# pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple
# pip config set install.trusted-host mirrors.cloud.aliyuncs.com
pip install https://github.com/vllm-project/vllm/releases/download/v0.5.3.post1/vllm-0.5.3.post1+cu118-cp310-cp310-manylinux1_x86_64.whl
依赖modelscope-agent项目下的modelscope-agent-server进行tool calling能力调用
git clone https://github.com/modelscope/modelscope-agent.git
cd modelscope-agent
服务调用
利用modelscope-agent-server的能力,允许用户在本地拉起一个支持openai SDK调用的chat/completions服务,并且赋予该模型tool calling 的能力。这样子可以让原本仅支持prompt调用的模型,可以通过modelscope的服务快速进行tool calling的调用。
服务curl调用
于此同时, 服务启动以后,可以通过以下方式curl 使用带有tool的信息调用服务。
curl -X POST 'http://localhost:31512/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{"tools": [{"type": "function","function": {"name": "amap_weather","description": "amap weather tool","parameters": [{"name": "location","type": "string","description": "城市/区具体名称,如`北京市海淀区`请描述为`海淀区`","required": true}]}}],"tool_choice": "auto","model": "meta-llama/Meta-Llama-3.1-8B-Instruct","messages": [{"content": "海淀区天气", "role": "user"}]
}'
返回如下结果:
{"request_id": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43","message": "","output": null,"id": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43","choices": [{"index": 0,"message": {"role": "assistant","content": "工具调用\nAction: amap_weather\nAction Input: {\"location\": \"北京市\"}\n","tool_calls": [{"type": "function","function": {"name": "amap_weather","arguments": "{\"location\": \"北京市\"}"}}]},"finish_reason": "tool_calls"}],"created": 1721803228,"model": "meta-llama/Meta-Llama-3.1-8B-Instruct","system_fingerprint": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43","object": "chat.completion","usage": {"prompt_tokens": -1,"completion_tokens": -1,"total_tokens": -1}
}
相关文章:
Meta 发布 Llama3.1,一站教你如何推理、微调、部署大模型
最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解…...

XSSFWorkbook 和 SXSSFWorkbook 的区别
在现代办公环境中,处理 Excel 文件是一个常见的任务。Apache POI 是一个流行的 Java 库,能够读写 Microsoft Office 文档。对于处理 Excel 文件,Apache POI 提供了 XSSFWorkbook 和 SXSSFWorkbook 两个类。本文将详细介绍这两个类的特点和适用…...

会议主题:NICE Seminar|神经组合优化方法的大规模泛化研究(南方科技大学王振坤副研究员)
数据增强 获得更多解 TSP问题 最优解与序列无关,数据增强 ICML 2024 Position Rethinking Post-Hoc Search-Based Neural Approaches for Solving Large-Scale Traveling Salesman Problems...

昇思25天学习打卡营第22天|CycleGAN图像风格迁移互换
相关知识 CycleGAN 循环生成网络,实现了在没有配对示例的情况下将图像从源域X转换到目标域Y的方法,应用于域迁移,也就是图像风格迁移。上章介绍了可以完成图像翻译任务的Pix2Pix,但是Pix2Pix的数据必须是成对的。CycleGAN中只需…...

《Java初阶数据结构》----6.<优先级队列之PriorityQueue底层:堆>
前言 大家好,我目前在学习java。之前也学了一段时间,但是没有发布博客。时间过的真的很快。我会利用好这个暑假,来复习之前学过的内容,并整理好之前写过的博客进行发布。如果博客中有错误或者没有读懂的地方。热烈欢迎大家在评论区…...
)
Matrix Equation(高斯线性异或消元+bitset优化)
题目: 登录—专业IT笔试面试备考平台_牛客网 思路: 我们发现对于矩阵C可以一列一列求。 mod2,当这一行相乘1的个数为奇数时,z(i,j)为1,偶数为0,是异或消元。 对于b[i,j]*c[i,j],b[i,j]可以…...

【一图学技术】2.API测试9种方法图解
9种API测试方法 冒烟测试:冒烟测试是一种快速的表面级测试,用于验证软件的基本功能是否正常工作,以确定是否值得进行更详细的测试。功能测试:功能测试是验证软件是否符合预期功能要求的测试类型。它涉及对每个功能进行测试&#…...

力扣刷题----42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图…...

【论文精读】 | 基于图表示的视频抑郁症识别的两阶段时间建模框架
文章目录 0、Description1、Introduction2、Related work2.1 Relationship between depression and facial behaviours2.2 Video-based automatic depression analysis2.3 Facial graph representation 3、The proposed two-stage approach3.1 Short-term depressive behaviour…...

采集PCM,将base64片段转换为wav音频文件
需求 开始录音——监听录音数据——结束录音 在监听录音数据过程中:客户端每100ms给前端传输一次数据(pcm数据转成base64),前端需要将base64片段解码、合并、添加WAV头、转成File、上传到 OSS之后将 url 给到服务端处理。 {num…...

eclipse ui bug
eclipse ui bug界面缺陷,可能项目过多,特别maven项目过多,下载,自动编译,加载更新界面异常 所有窗口死活Restore不回去了 1)尝试创建项目,还原界面,失败 2)关闭所有窗口&…...

前端获取blob文件格式的两种格式
第一种,后台传递给前台是base64格式的JSON数据 这时候前台拿到base64格式的数据可以通过内置的atob解码方法结合new Uint8Array和new Blob方法转换成blob类型的数据格式,然后可以使用blob数据格式进行操作,虽然base64转换成blob要经过很多步骤,但幸运的是这些步骤都是固定的,因…...

向日葵RCE复现(CNVD-2022-10270/CNVD-2022-03672)
一、环境 1.1 网上下载低版本的向日葵<2022 二、开始复现 2.1 在目标主机上打开旧版向日葵 2.2 首先打开nmap扫描向日葵主机端口 2.3 在浏览器中访问ip端口号cgi-bin/rpc?actionverify-haras (端口号:每一个都尝试,直到获取到session值…...

Postman中的负载均衡测试:确保API的高可用性
Postman中的负载均衡测试:确保API的高可用性 在微服务架构和分布式系统中,API的负载均衡是确保系统高可用性和可扩展性的关键技术之一。Postman作为一个多功能的API开发和测试平台,提供了多种工具来帮助测试人员模拟高负载情况下的API表现。…...

anaconda+tensorflow+keras+jupyter notebook搭建过程(CPU版)
AnacondaTensorFlowKeras 环境搭建教程...

LitCTF2024赛后web复现
复现要求:看wp做一遍,自己做一遍,第二天再做一遍。(一眼看出来就跳过) 目录 [LitCTF 2024]浏览器也能套娃? [LitCTF 2024]一个....池子? [LitCTF 2024]高亮主题(划掉)背景查看器 [LitCTF 2…...

Elasticsearch:跨集群使用 ES|QL
警告:ES|QL 的跨集群搜索目前处于技术预览阶段,可能会在未来版本中更改或删除。Elastic 将努力解决任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 约束。 使用 ES|QL,你可以跨多个集群执行单个查询。 前提: …...

学习笔记4:docker和k8s选择简述
docker和 k8s 占用资源 使用客户体量Docker 和 Kubernetes(K8s)都是流行的容器化技术,但它们在资源管理和使用上有一些不同。以下是关于两者资源占用和使用客户体量的详细比较,基于具体数据和信息: Docker 资源占用…...

关于锁策略
在Java中对于多线程来说,锁是一种重要且必不可少的东西,那么我们将如何使用以及在什么时候使用什么样的锁呢?请各位往下看 悲观锁VS乐观锁 悲观锁: 在多线程环境中,冲突是非常常见的,所以在执行操作之前…...

昇思25天学习打卡营第3天|基础知识-数据集Dataset
目录 环境 环境 导包 数据集加载 数据集迭代 数据集常用操作 shuffle map batch 自定义数据集 可随机访问数据集 可迭代数据集 生成器 MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transfor…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...

紫光同创PGL22G开发板DDR3读写实验:从IP核安装到上板验证的保姆级避坑指南
紫光同创PGL22G开发板DDR3读写实验全流程实战解析 第一次接触国产FPGA平台进行DDR3内存控制实验时,很多开发者都会遇到各种"坑"。本文将基于紫光同创PGL22G开发板,从IP核安装到最终上板验证,手把手带你避开那些容易出错的关键环节。…...

Windows和Office激活难题?3分钟永久激活的智能方案
Windows和Office激活难题?3分钟永久激活的智能方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只读模…...

STM32篇-12.指针函数和函数指针
指针函数是什么指针函数是指返回值类型为指针的函数 比如:int* open(void) { return (an addr); }该函数返回的地址或者变量;函数指针是什么函数指针其实类似变量的指针; 比如下面:#include <stdio.h>void open(void) {prin…...

Next.js 14全栈样板工程解析:集成Prisma与NextAuth的现代Web开发实践
1. 项目概述:一个为现代Web应用量身定制的启动器如果你正在寻找一个能让你跳过繁琐的初始化配置,直接进入核心业务逻辑开发的Next.js项目起点,那么nemanjam/nextjs-prisma-boilerplate这个项目很可能就是你需要的。这不是一个简单的“Hello W…...

开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由
开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否厌倦了在多个阅读应用间来回切换?是否对层出不穷的广告…...

书成紫微动律定凤凰驯:抛开网络臆想歪论正视海棠山铁哥的大道凰标之道
——褪去网络流言,正视正统文脉网络世间众说纷纭,流言四起,诸多无根揣测、片面臆想肆意流传。 不少人未曾静心品读深意,仅凭只言片语便妄加评判,或是跟风曲解本意,或是刻意附会杂论,更有甚者凭空…...

3个常见视频下载难题,猫抓扩展如何帮你一键解决?浏览器资源嗅探实战指南
3个常见视频下载难题,猫抓扩展如何帮你一键解决?浏览器资源嗅探实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你…...

Cursor AI编程助手扩展包:定制化规则提升代码生成质量与效率
1. 项目概述:一个为 Cursor 编辑器量身定制的 AI 编程助手扩展包如果你和我一样,日常重度依赖 Cursor 这款“AI 驱动的代码编辑器”来提升开发效率,那你肯定不止一次地想过:能不能让 Cursor 更懂我?能不能让它在我写特…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...