基于 Apache Flink 的实时计算数据流业务引擎在京东零售的实践和落地
摘要:本文整理自京东零售-技术研发与数据中心张颖&闫莉刚在 ApacheCon Asia 2022 的分享。内容主要包括五个方面:
- 京东零售实时计算的现状
- 实时计算框架
- 场景优化:TopN
- 场景优化:动线分析
- 场景优化:FLINK 一站式机器学习
点击查看更多技术内容
一、京东零售实时计算的现状
1.1 现状
- 技术门槛高、学习成本大、开发周期长。行业内实时开发能力只有少数人能够掌握的现状;
- 数据开发迭代效率比较低,重复逻辑反复的开发缺少复用;
- 测试运维难,复杂业务逻辑难以局部测试。
1.2 动力
- 降本增效、节省人力,助力高效开发;
- 多角色数据开发,不同角色对应不同的开发方式,非数据人员也能做数据开发的工作。
1.3 目标
- 降低数据开发门槛,通过标准化积木式的开发,实现低代码配置化数据加工,进一步实现图形化清晰表达数据流转;
- 通过算子库组件的沉淀,提升开发效率,提高复用性,一站式加工;
- 通过单元测试以及沉淀用例,提高开发质量。
二、实时计算框架
2.1 为什么做数据流框架
- 数据流框架:9N-Tamias/9N-Combustor,数据流框架基于计算引擎之上,提供一种易用高效的数据开发方式,包括:tamias,是基于 Flink 的引擎的开发框架;combustor:基于 Spark 引擎的开发框架。基于 9N-Tamias 和 9N-Combustor 提供数据流开发工具;
- 支持实时离线统一的表达;
- 多种使用方式:图形化、配置化、SDK 等;
- 算子、组件复用:数据流算子、转换算子、自定义算子、目标源算子,灵活的组合,沉淀常用的算子组合,组件化包括数据流组件和自定义组件,通过数据流开发沉淀数据流组件,同时也开放自主开发自定义组件方式,通过算子、组件的复用,提高开发效率。
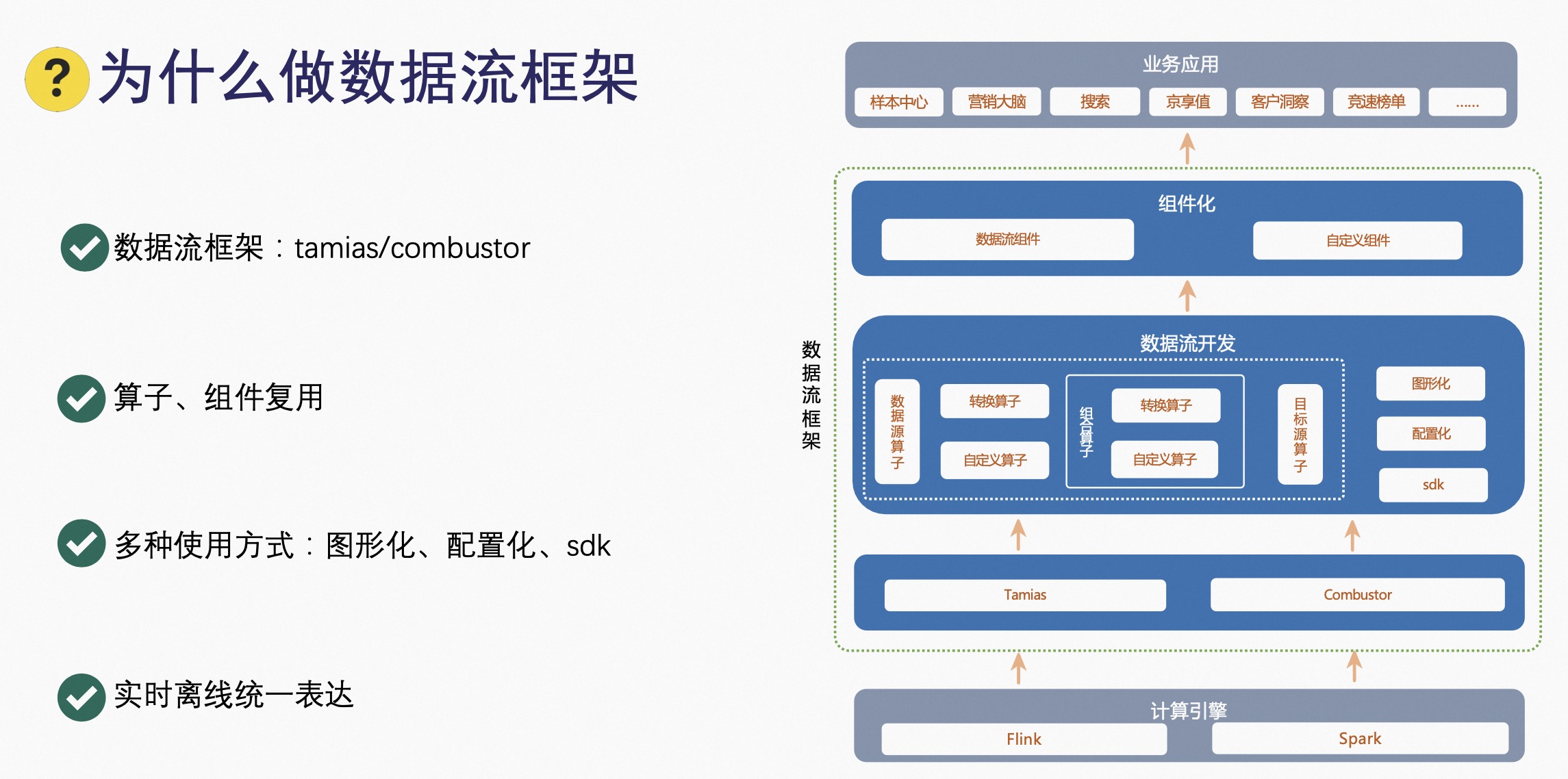
数据流框架上层各业务场景基于数据流组件化,实现业务数据的加工,包括样本中心、京享值、搜索等一些业务。
2.2 怎么做实时计算框架?
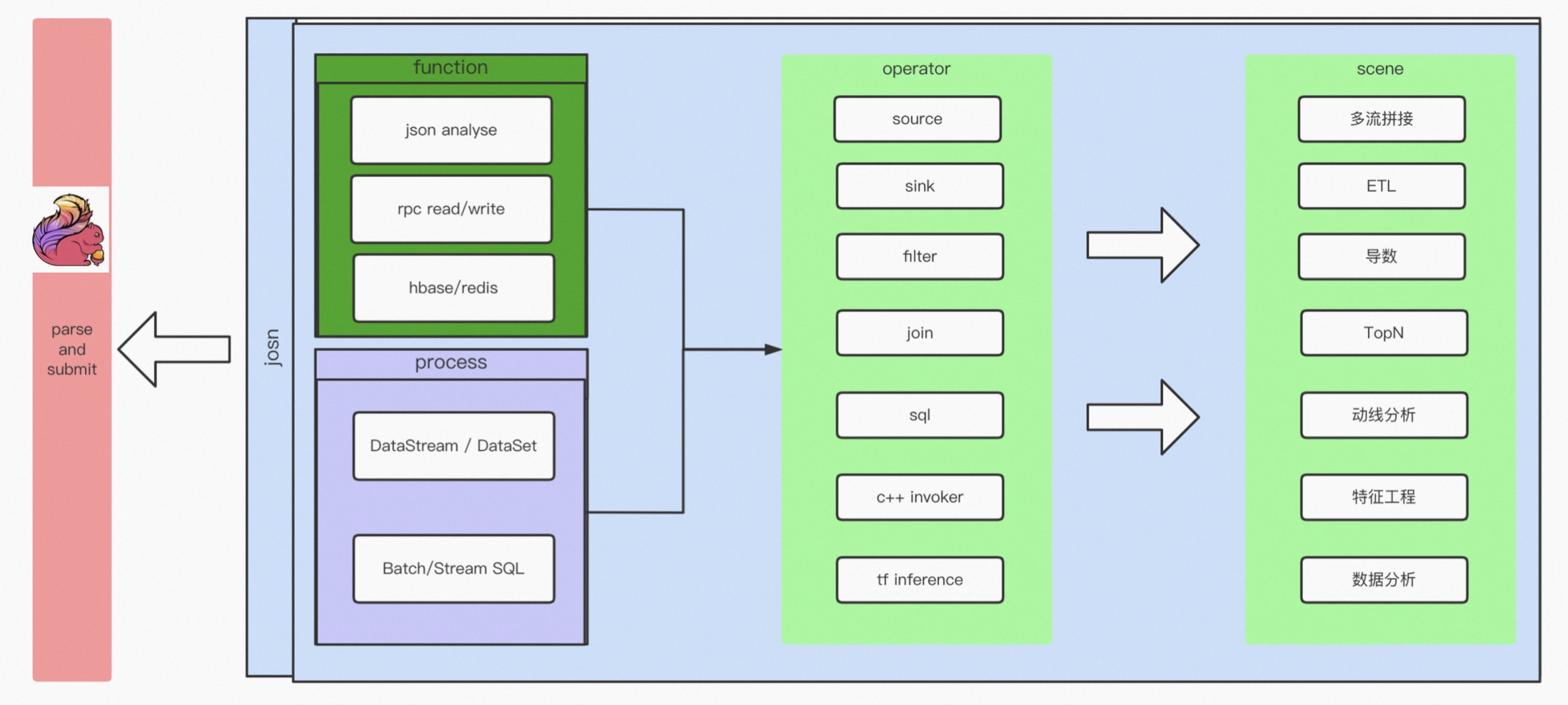
实时计算框架分成四层:
- Function 层:实现比如 Json 解析、RPC 调用、以及数据流的链接;
- Process 层:对 Flink 引擎、Data Stream、Data Set、SQL 等 API 进行封装;
- Function 和 Process 组合生成 Operator,对具体的处理逻辑进行封装,比如实现 Source、Sink、Filter、Join 等常用的算子;
- 一个或者多个 Operator 构成不同的场景,比如多流拼接导数的 Top N、动线分析,这些构成了 JSON 的配置文件,然后再通过通用的引擎解析配置文件提交任务。
2.3 实时框架:公用 Ops 和 Function
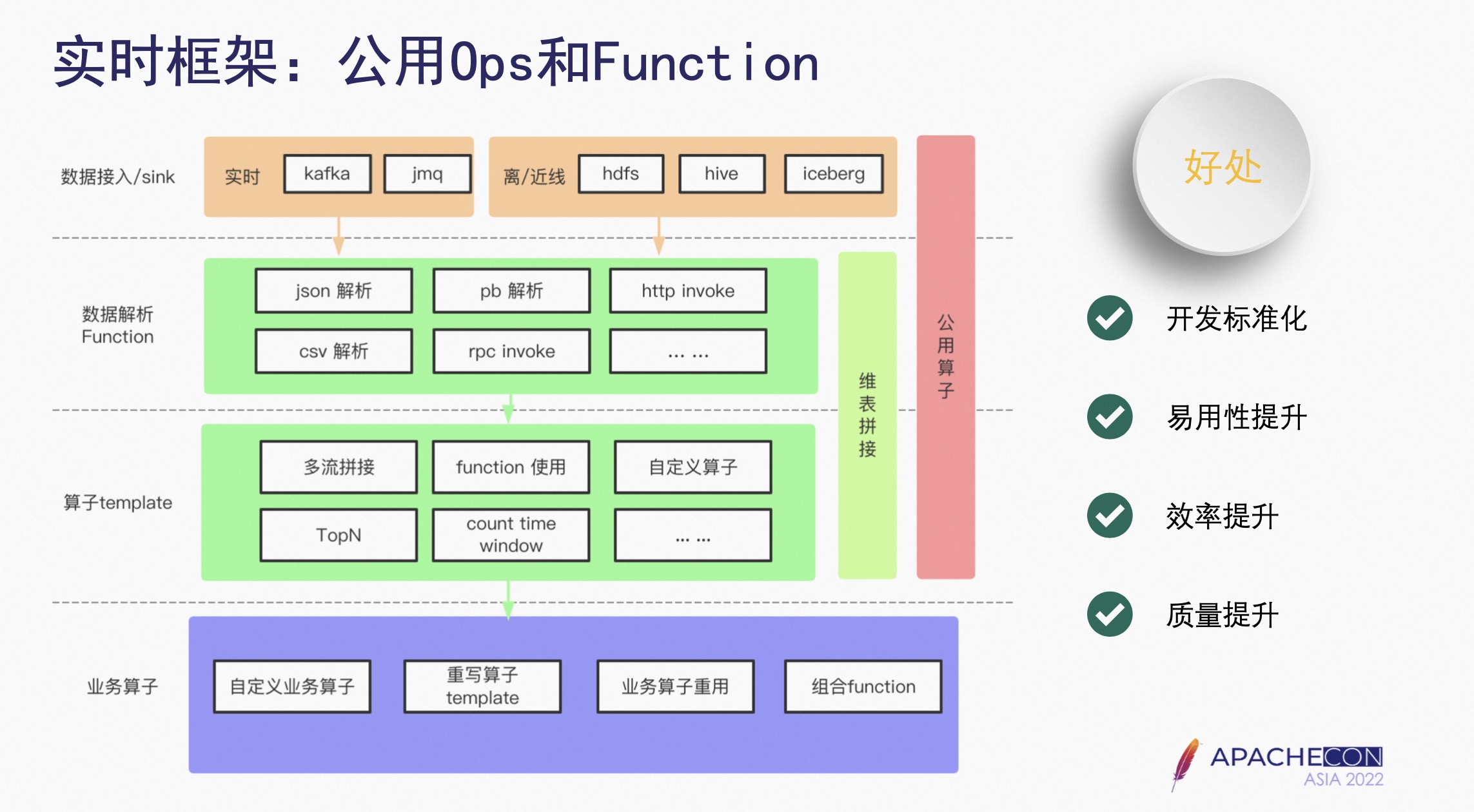
数据接入 Source 和 Sink 层:实现了实时离线、近线常用的数据源;
数据解析 Function:是为了将公用的计算逻辑进一步细化,在算子里封装多个 Function,进行灵活实现业务的逻辑;
算子 Template:如多流拼接、TopN、Count Time Window,业务自己实现会比较复杂,因此框架提供了这些算子的 Template,业务只需要在 Template 的基础上增加业务代码即可,不需要再对这些通用的算子进行学习、开发、调试等工作;
业务算子:可以基于 Template 已有的业务算子,重写得到新的业务算子,也可以自定义组合 Function,形成业务算子。
优点如下:
- 开发标准化:基于框架提供的公用算子,组合完成业务标准化的开发;
- 易用性提升:框架提供一些常用且难以实现的算子,使业务的开发变得简单;
- 开发迭代效率提升:业务只需要关注业务逻辑,从而提高开发迭代效率质量的提升;
- 质量提升:框架提供的公共算子都是经过严格的测试,并经过长期的业务验证,从而提高开发质量。
三、场景优化:TopN
3.1 复用算子
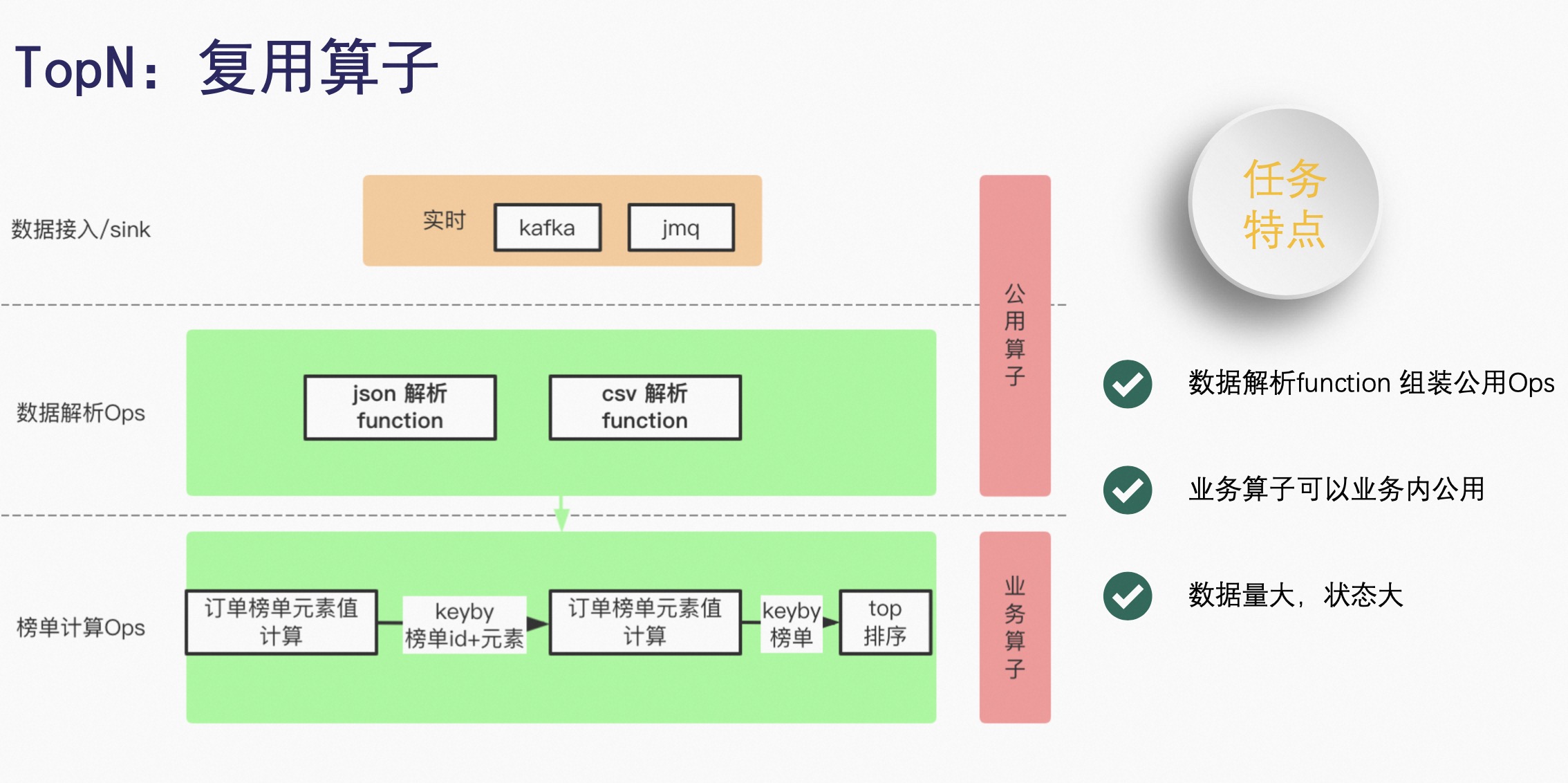
首先不仅仅是 TopN,包括所有业务场景,数据接入和数据写出都是可以共用的,比如针对流计算,像 Kafka 或 JMQ 的接入和写出,都是可以复用的。
然后是数据解析的算子,包括 JSON 解析、CSV 解析都是可以复用的,但是如果每一个 JSON 解析和 CSV 解析都抽象成一个 Operator,会需要很多的 Operator,因此抽象了 Function 概念,然后 Function 可以组合成公用的算子。
【案例】以榜单计算为例,首先用订单榜单的一个元素值作为一个计算,然后 KeyBy 时用榜单 ID 加元素,接下来再进行一次订单榜单元素值的计算,把榜单 ID 和元素值进行一次 KeyBy,产生的 TopN 的排序。
在这里需要 KeyBy 两次,因为在京东的固有的场景下,有业务上的数据倾斜,只能采用多次聚合,或者是多次排序的方式来解决问题。
3.2 任务优化
HDFS 小文件的问题:因为数据量非常大,因此在写 HDFS 时,如果 Rolling 策略设置不合理,会导致 HDFS 产生很多的小文件,可能会把 HDFS Name Node 的 RPC 请求队列打满。通过源码及其任务机制发现,HDFS 的文件 Rolling 的策略与 Checkpoint 的时间以及 Sink 的并行度相关,因此合理设置 Checkpoint 的时间和 Sink 的并行度,可以有效解决 Sink HDFS 的小文件的问题。
RocksDB 优化:通过查看官方文档可以发现,针对 RocksDB 相关的优化有很多,但是如何有效优化 RocksDB 的设置,核心就在于合理地设置 BlockCache 和 WriteBuffer 的大小,还可以添加 BloomFilter,相应调整这些参数,具体采用哪些配置都可以。
Checkpoint 优化:主要是超时时间、间隔时间、最小停顿时间。比如超时时间是半个小时,这个任务产生了 Fail 了,假如它是在 29 分钟的时候,进行 Failover 的时候,需要从上个 Checkpoint 开始恢复,需要很快消费前 29 分钟的数据。这种情况下如果数据量非常大,对任务是一个不小的冲击。但是如果把 Checkpoint 的时间设置为更合适的 5 分钟或者 10 分钟,这个冲击量会少很多。
数据倾斜:造成数据的倾斜的情况有很多种,比较难解决的是数据源中引发的数据倾斜问题,因此可以采用多次聚合或者多次排序模式解决;另外一个是机器问题,是由于某台机器问题造成的数据倾斜,通常的表现是这台机器上所有的 Subtask 或者 TM 都会产生问题。
四、场景优化:动线分析
4.1 什么是动线
用户点击以及页面展现的浏览路径称之为是动线;以搜索词举例,在京东平台首先搜索台灯,然后又搜索台灯学习,最后搜索儿童学习护眼台灯,从台灯到台灯学习,到儿童学习护眼台灯,这样搜索词的线称为搜索词动线。
动线分析的作用:寻找决定转化的关键路径点以理解用户决策习惯;经常相邻查询的搜索词通过导流工具串联,发现趋势动线;同一个用户对不同排序策略的接受程度,最终从细分的用户类型,提出个性化的导购布局和策略建议;
4.2 数据建模

涉及到串联相邻的搜索词问题,需要从宏观的角度进行数据建模。
首先在京东每天 PB 数据量的动线数据分析下,现有的图结构是没有办法解决这个问题。目前最常用的一个分析方法,是把大批量的这种数据全部同时灌到数据库里,然后等离线数据运行一段时间,拿到分析的结果从结果上去分析。
当前业界在线图数据库进行这种大数据量的图分析,会严重地影响数据库的运行和对外提供服务,因此引入 Flink Gelly 技术栈,通过类似 MySQL 与 Hive 的模式,解决这种大规模图分析问题。
解决方案:首先是把图的源数据通过 Flink SQL 从 Hive 里取出数据,通过 Left Join 把每个 Session ID 下面的 Query 链连起来,然后导入到 HDFS 里;从 HDFS 里读动线的数据,并且把动线的数据生成一个 Graph,根据数据科学家提出的分析条件,将图的分析的结果,直接灌到 OLAP 里进行多维的分析;数据流实时计算的框架,从 Hive 或者 HDFS 里读数据,然后通过数据的 Join,包括写 HDFS、Graph Generate、Graph Analyse 等以可配置化的形式,生成公用算子放到算子库里,对于搜索、推荐或者是广告等所有涉及到动线分析的部门,都可以用到。
4.3 模型建模
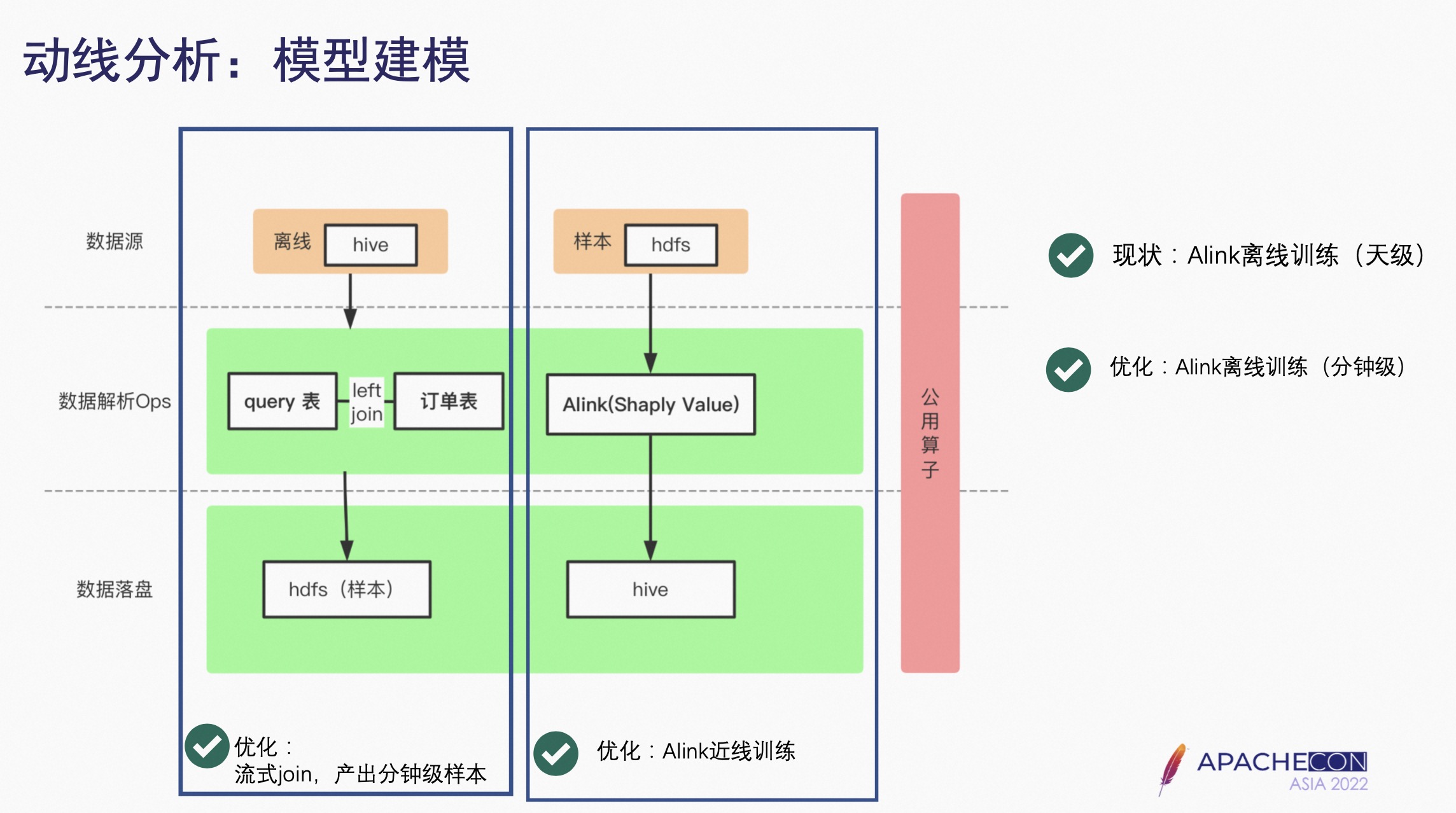
如果要对用户进行细分和个性化的分析,就涉及到模型建模。
首先是样本生产的过程,需要把数据从 Hive 里拿到,针对搜索词动线分析需要拿到用户搜索词的表,然后和相应的订单表里决定下单的 Query 进行左连接,生成样本放到 HDFS 里。
训练任务是从 HDFS 里把这些数据灌到 Alink 里进行 Shaply Value 建模,最终的 Query 重要度写到 Hive 里。
全链路是以公用算子的方式提供,目前京东采用这种离线训练的方式,相当于是天级,之后希望天级训练的模式实时化,做成分钟级的或者流式的 Join。
五、场景优化:FLINK 一站式机器学习

机器学习可以从四个方面来描述:特征、样本、训练、预估,而每个方面都有相应的问题(如上图)。
5.1 特征
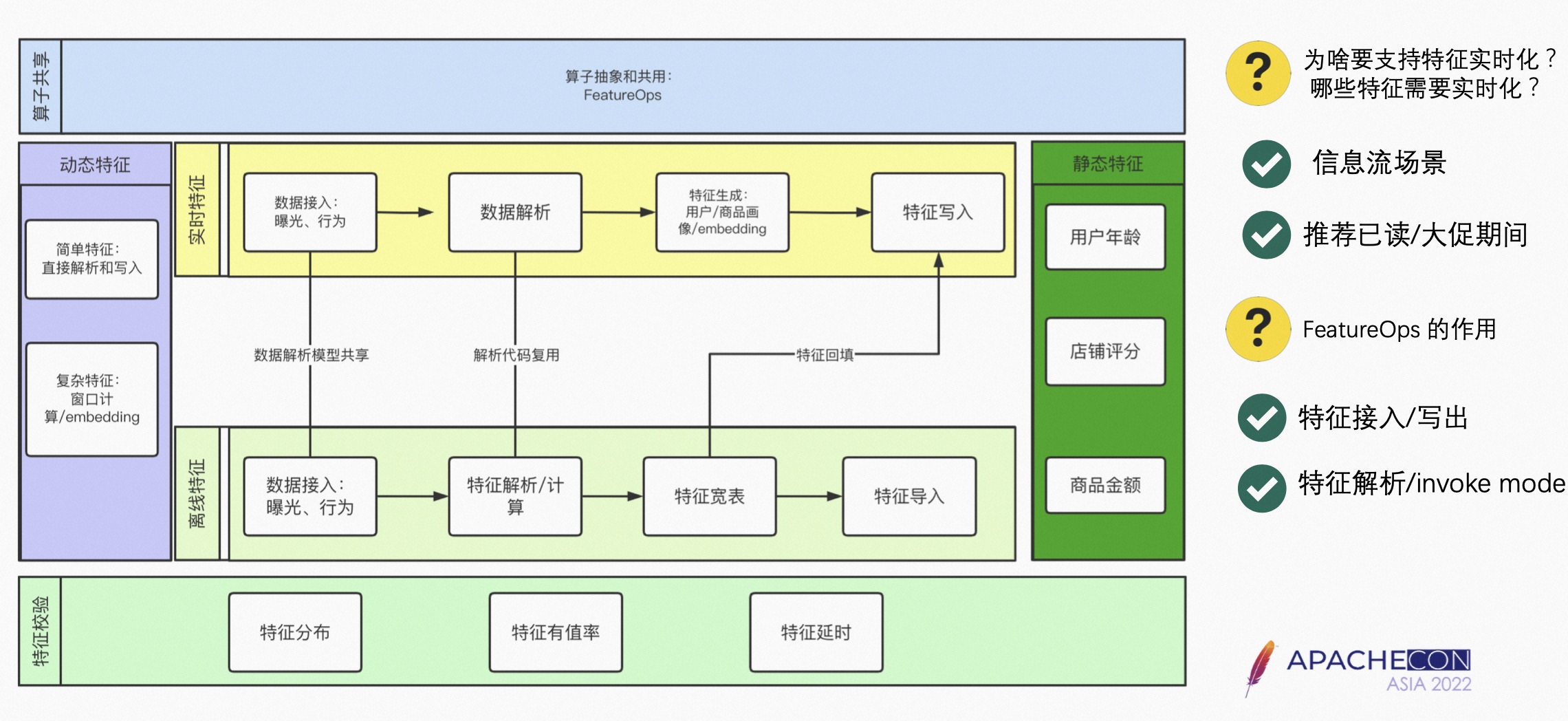
从生成的角度,特征分为实时特征和离线特征;从特征的特性分为静态特征和动态特征。
- 静态特征是相对变化不太大的特征,比如用户的年龄、店铺评分、商品金额,可以把静态特征和离线特征相对应;
- 动态特征比如近一个小时内的点赞量,或者近一个小时内的点击量,动态特征和实时特征相对应。
离线特征可以分为特征的整体生成过程。
- 特征一般是放到 Hive 里,会涉及到一些特征的解析以及计算,最终生成一个特征的大宽表,然后把这些特征放到 Redis 里,如果是实时特征,涉及到数据接入以及数据解析行为。
- 特征生成可以认为是业务化的过程,特征写入可以直接写入 Redis 里。
- FeatureOPS 主要是专注于特征生成,如果特征解析涉及到业务算子,也可以用 FeatureOPS 来做。
5.2 样本
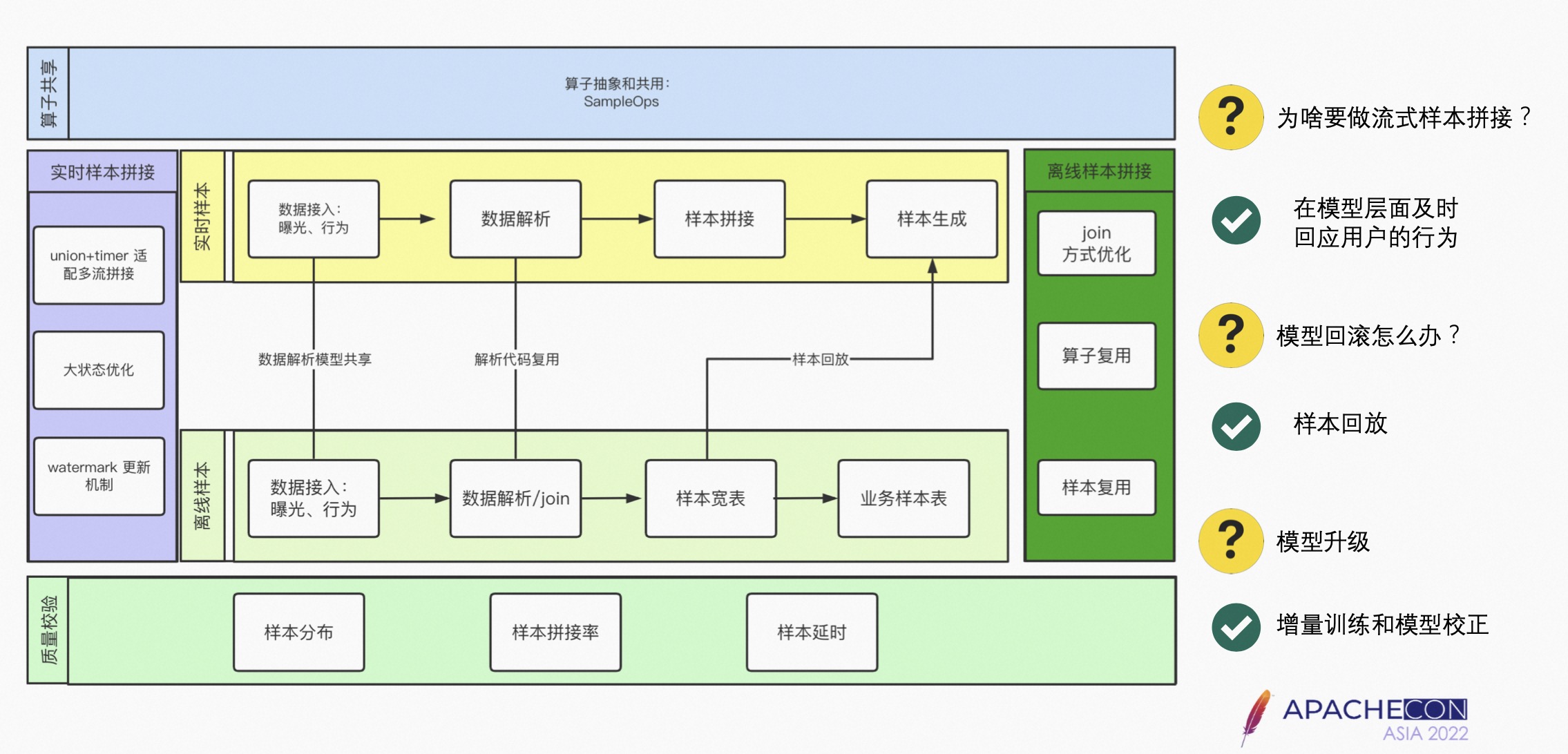
样本分为实时样本拼接和离线样本拼接两个链路;针对样本的特性,有离线的样本和实时的样本两个链路。
- 离线的样本拼接:通过 Join 存到数仓里,从数仓里拿取用户的曝光以及行为日志后,通过一系列的 Join 操作,形成样本的宽表,每个业务可以从样本宽表拿到属于自己的样本进行模型的训练。
- 实时的链路拼接也是相同的,区别是样本拼接为实时的。Flink 样本基本上都是双流的,采用 Unit 和 Timer 模式,适配多流的样本拼接,会涉及到大状态的优化,大状态目前用的 State Backend 是 Roll SDB。Watermark 更新机制是采用最慢的时间作为更新的机制,如果某一个行为流的数据量比较少,则会导致 Watermark 不更新的问题。
- 实时样本拼接针相对离线的样本拼接更加困难,包括一个窗口的选择、一些业务上的样本拼接等。
Sample OPS 做样本质量的校验:首先在样本生成的阶段,需要做样本的分布,如正负样本的分布;其次在做实时样本或者是离线样本拼接时,需要对拼接率做监测;观察任务的延时率,即每一条样本的延时情况。
模型升级定义为只有模型进行模型校正时,才会认为它升级了,而增量训练不是模型升级。
5.3 模型 online learning

模型 online learning 是指数据科学方向,并非大模型的方向。按照特征和样本实时离线的 Template,把模型分为实时和离线两种。
实时训练涉及到模型实时参数的更新,但并非每一条数据训练一次,由超时时间 CountWindow 解决这个问题,比如 Count 达到 1 万条或者超时时间 5 分钟,来解决 Mini Batch 的问题。
针对 Online Learning,目前没有办法离线地做 AB,因此当一批数据进来时,可以先训练出一个模型,同样用这一批数据做 AB,以达到训练和 AB 的一体化。同时用离线的大数据量训练出来的模型,去及时校正实时训练出来的模型,防止模型训偏了;然后任务内部采用 Keyby 方式实现数据并行,解决模型分布式的问题。
举例,如 Profit 模型,是采用报警维度指标来设置,同时在模型产出时将模型推到模型库,然后 Parameter Server 会不停地在模型库里面把当前的模型的参数快照打到模型库里。
5.4 预估
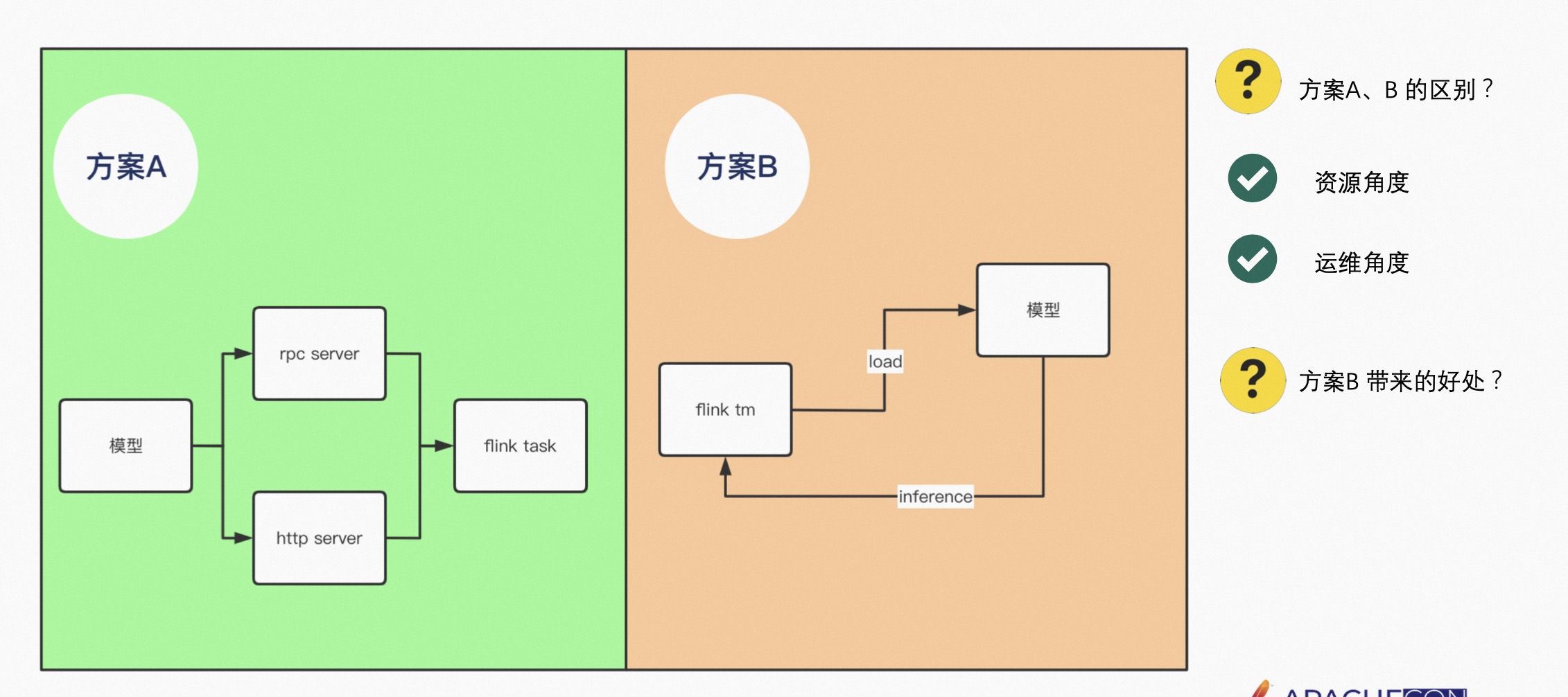
Flink 做预估目前有两种方案:
方案 A 是将模型如 Tensorflow 或者 PyTorch 模型,通过 RPC 的方式或者 HTTP 的方式部署 Server,由 Flink Task 去远程 Invoke RPC 或者 HTTP,会有网络的开销。因为 Flink Task 可能是实时的,也有可能是离线的,所以在 invoke RPC 时,不可能让它随着 Flink 任务的启动而启动,或者随着 Flink 任务的停止而停止,需要有人来运维该 Server。
方案 B 是将模型 Load 到 Flink TM 内部,即在 Flink TM 内部 Inference 该模型,其优点是不用去维护 RPC 或者 HTTP 的 Server,从资源的角度减少了网络开销,节省了资源。
点击查看更多技术内容
相关文章:
基于 Apache Flink 的实时计算数据流业务引擎在京东零售的实践和落地
摘要:本文整理自京东零售-技术研发与数据中心张颖&闫莉刚在 ApacheCon Asia 2022 的分享。内容主要包括五个方面: 京东零售实时计算的现状实时计算框架场景优化:TopN场景优化:动线分析场景优化:FLINK 一站式机器学…...

【JavaEE】如何将JavaWeb项目部署到Linux云服务器?
写在前面 大家好,我是黄小黄。不久前,我们基于 servlet 和 jdbc 完善了博客系统。本文将以该系统为例,演示如何将博客系统部署到 Linux 云服务器。 博客系统传送门: 【JavaEE】前后端分离实现博客系统(页面构建&#…...
Mysql常用命令
mysql连接: [roothost]# mysql -u root -p Enter password:******创建数据库: CREATE DATABASE 数据库名; 删除数据库: drop database 数据库名; 使用mysqladmin删除数据库: [roothost]# mysqladmin -u root -p dr…...
【洛谷刷题】蓝桥杯专题突破-深度优先搜索-dfs(4)
目录 写在前面: 题目:P1149 [NOIP2008 提高组] 火柴棒等式 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 解题思路: …...

在Win10以及SDK为33的环境下——小米便签项目的搭建
文章目录0. 我的操作系统和开发环境1. 相关文件下载:2. import project:2.1 用import project导入项目3. make project:3.1 AS中的命令行乱码问题:3.2 依赖库缺失问题:3.3 关于targetSdkVersion3.4 关于Missing URL3.5 关于Manifest merger f…...

FPGA纯verilog实现RIFFA的PCIE通信,提供工程源码和软件驱动
目录1、前言2、RIFFA简介RIFFA概述RIFFA架构RIFFA驱动3、vivado工程详解4、上板调试验证并演示5、福利:工程代码的获取1、前言 PCIE是目前速率很高的外部板卡与CPU通信的方案之一,广泛应用于电脑主板与外部板卡的通讯,PCIE协议极其复杂&…...
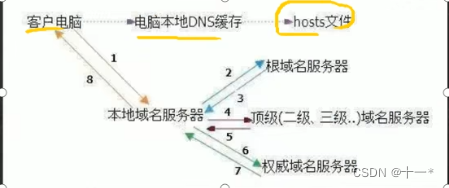
Linux网络配置
文章目录一、Linux网络配置原理图二、查看网络IP和网关ping测试主机之间网络连通性三、linux网络环境配置第一种方法(自动获取)第二种方法(指定ip)四、设置主机名和hosts映射设置主机名设置hosts映射五、主机名解析过程分析(Hosts、DNS)Hosts是什么DNS一、Linux网络配置原理图 …...

【Java学习笔记】多线程与线程池
多线程与线程池一、多线程安全与应用1、程序、进程与线程的关系2、创建多线程的三种方式(1)继承Thread类创建线程【不推荐】(2)实现Runnable接口创建线程(3)Callable接口创建线程3、线程的生命周期4、初识线…...

尺取法
尺取法是一种线性的高效率算法。记 (L, R ) 为一个序列内以L为起点的最短合法区间, 如果R随L的增大而增大的,就可以使用尺取法。具体的做法是不断的枚举 L,同时求出R。 因为 R 随 L增大而增大,所以总时间复杂度为 O(n) 指针i、j的两种方向: 反向扫描:i、j方向相反,i从头…...

20.有效的括号
给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个右括号都有一个对应的相同类型的左括…...

使用QT C++编写一个带有菜单和工具条的文本编辑器
您好,这是必应。我可以帮您生成一段使用QT C编写一个带有菜单和工具条的文本编辑器的代码,但是请注意,这只是我的创造性的输出,并不代表任何权威或专业的观点。如果您想要了解更多的相关知识,请自行搜索或咨询专家。以…...

文法和语言的基本知识
一、什么形式化的方法用一套带有严格规定的符号体系来描述问题的方法二、什么是非形式化的方法对程序设计语言的描述从语法、语义和语用三个方面因素来考虑所谓语法是对语言结构定义所谓语义是描述了语言的含义所谓语用则是从使用的角度去描述语言三、符号串字母表和符号串字母…...

学习其他人的代码,成为更好的程序员
学习其他人的代码,成为更好的程序员1. 广泛阅读2. 分析代码3. 记笔记4. 实验5. 分享你的发现6. 结论参考如何成为一名更好的Python程序员??? 学习编码是一个持续的过程,需要实践、实验和向他人学习的意愿。提高编码技能的最佳方法之一是学习他人的代…...

新星计划-JAVA学习路线及书籍推荐
CSDN的各位友友们你们好,今天千泽为大家带来的是JAVA学习路线及其经典书籍推荐,接下来让我们一起了解一下JAVA的学习路线吧!如果对您有帮助的话希望能够得到您的支持和关注,我会持续更新的! 目录 1.JAVASE及其书籍推荐 2.初级数据结构与算法及其书籍推荐 3.MySQL及其书籍推荐…...

【大数据】Hive系列之- Hive-DML 数据操作
Hive系列-DML 数据操作数据导入向表中装载数据(Load)语法操作用例通过查询语句向表中插入数据(Insert)创建一张表插入数据基本模式插入(根据单张表查询结果)查询语句中创建表并加载数据(As Sele…...

day2 —— 判断字符串中的字符是否唯一
目录 前言 问题描述 代码解释 前言 若是想要了解基本语法的话,请到(7条消息) C语言从练气期到渡劫期_要一杯卡布奇诺的博客-CSDN博客查看相应的语法细节 强烈安利这篇文章 —— (4条消息) 筑基五层 —— 位运算看这篇就行了_要一杯卡布奇诺的博客-CSDN博客 问题…...

176万,GPT-4发布了,如何查看OpenAI的下载量?
大家好,这里是程序员晚枫。 昨天新一代GPT4发布了,今年GPT不断给大家带来惊喜。 在OpenAI的官网,也公开了GPT的Python调用第三方库:openai。 今天我们就来看看,这个Python智能接口~ 1、代码说明 开发过Python项目…...

蓝蓝算法题(一)
讲在前面:1.本人正在逐步学习C,代码中难免有C和C(向下兼容)混用情况。2.算法题目来自蓝蓝知识星球,没有对应的判决系统,运行到判决系统可以会有部分案例不能通过。 求素数 暴力求解(1 - n试探…...
Python截图自动化工具
1、展示部分源码(写的比较乱,哈哈) 2、功能展示 1)首页 2)按钮截图(用于自动翻页) 3)保存位置按钮(选择图片保存的位置) 4)重复次数,就是要截取多少次 5)定位截屏(截取的内容&#x…...

网络作业2【计算机网络】
网络作业2【计算机网络】前言推荐网络作业2一. 单选题(共3题,19.8分)二. 多选题(共1题,6.6分)三. 填空题(共8题,52.8分)四. 判断题(共3题,20.8分&…...

教育博主私藏!PPT生成网站实用指南
作为一名教育博主,我深刻体会到制作 PPT 是教育工作者日常工作中不可或缺的一部分。借助合适的工具,能有效降低 PPT 制作门槛,提升演示内容的专业度和吸引力。今天,就给大家分享几款亲测好用的 PPT 生成网站,助力大家高…...

Deepin系统远程桌面实战:从零配置xrdp服务到Windows无缝连接
Deepin系统远程桌面实战:从零配置xrdp服务到Windows无缝连接 在跨平台协作成为常态的今天,远程桌面技术让不同操作系统间的无缝协作成为可能。对于使用Deepin系统的用户而言,如何高效地通过Windows设备远程访问和控制Deepin桌面,是…...
)
安规设计规范-3(如何计算电气间隙和爬电距离)
详尽的计算方式建议参考各个标准的要求,本文只指出常规的基础计算流程。以下示例严格遵循 GB/T 16935.1-2023/IEC 60664-1:2020《低压系统内设备的绝缘配合》,选用储能 PCS(储能变流器)最常见的230V AC 电网侧对低压控制侧场景&am…...
)
告别纯Verilog手搓!用Vivado HLS快速搭建你的第一个CNN加速器(ZYNQ平台实战)
从Verilog到Vivado HLS:ZYNQ平台CNN加速器开发实战指南 在FPGA开发领域,传统RTL设计方法正面临越来越复杂的算法实现挑战。以卷积神经网络(CNN)为例,一个简单的三层网络就可能需要数万行Verilog代码,不仅开发周期漫长,…...

3步掌握B站视频下载:解锁大会员4K高清内容
3步掌握B站视频下载:解锁大会员4K高清内容 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader Bilibili-downloader是你获取B站…...

特朗普政府发布《国家人工智能立法框架》,多维度布局AI领域
【《国家人工智能立法框架》六大核心目标锚定AI发展方向】特朗普政府发布的《国家人工智能立法框架》,意在通过统一国家政策确保美国在AI领域的全球领先地位。该框架包含六大核心目标,分别是保护儿童与赋能家长、维护与强化美国社区、尊重知识产权与支持…...

3大技术突破重新定义魔兽地图编辑工作流
3大技术突破重新定义魔兽地图编辑工作流 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 对于《魔兽争霸III》地图制作者而言,最令人沮丧的体验莫过于:精心设计的地形布局在实际测试中…...

CYBER-VISION零号协议互联网舆情智能监测与分析系统
CYBER-VISION零号协议:构建你的互联网舆情智能监测雷达 最近和几个做市场、公关的朋友聊天,他们都在抱怨同一个问题:每天花大量时间刷新闻、看社交媒体,就为了捕捉行业动态和用户反馈,生怕错过什么重要信息。人工监测…...
)
PyTorch 2.8 实战案例:快速训练一个图像分类模型(附代码)
PyTorch 2.8 实战案例:快速训练一个图像分类模型(附代码) 1. 引言 图像分类是计算机视觉领域最基础也最实用的任务之一。无论是识别猫狗照片、检测医学影像,还是分析卫星图像,都需要可靠的分类模型作为基础。本文将带…...

AQM0802字符LCD轻量驱动库:裸机printf级显示方案
1. 项目概述AQM0802 是一款由旭化成(AKM)推出的超低功耗、单色字符型液晶显示模块,采用 COG(Chip-on-Glass)封装工艺,内置 KS0066 兼容控制器。其典型型号为 AQM0802A-YBW,具备 8 字符 2 行的显…...