Vector的扩容机制
到需要扩容的时候,Vector会根据需要的大小,创建一个新数组,然后把旧数组的元素复制进新数组。
我们可以看到,扩容后,其实是一个新数组,内部元素的地址已经改变了。所以扩容之后,原先的迭代器会失效:
插一嘴,为什么要用迭代器而不用指针。
Iterator(迭代器)用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。
所以原因1:更安全。
第二,迭代器不是指针,它是类模板。它只是通过重载了指针的一些操作符(如“++”、“->”、“ * ”等)来模拟了指针的功能。也因此,它的功能比指针更加智能,他可以根据不同的数据类型实现不同的“++”等操作。
所以原因2:更智能。
int main() {std::vector<int> arr;arr.emplace_back(1);auto it = arr.begin();auto it2 = arr.end();std::cout << *it << "\t" << *(--it2) << std::endl;arr.emplace_back(2);std::cout << *it << "\t" << *(--it2) << std::endl;return 0;
}
执行后,只有第一个cout输出了结果,第二个cout没有输出,直接程序结束。
因为一开始没有声明大小,所以默认cap为0(这里cap指的是vector.capacity(),是可以调用的函数,返回当前vector的实际容量,超过了就要扩容);插入1之后,cap变为1;再插入2,因为size超过了cap,所以要扩容。
如前文所叙,扩容之后,元素的位置都变了,所以原先的迭代器失效了。
问题:元素的位置都变了?那头元素的位置变了吗?
答案是:变了。
有的人在这个时候会有疑问:那我还怎么找到原来的vector?
实际上,vector的头元素地址,与vector的地址并不相同。我们日常将vector叫做数组,但至少在这一点上,它不同于真正的数组。
以下是我做的实验出来的结果:
声明: std::vector<int> vector1 = { 1 };
&vector1: 00EFF824
&vector1[0]: 011B04D0声明: int* p1 = &vector1[0];*p1: 1
指针p1的值(指向的地址): 011B04D0扩容后*p1: -572662307
扩容后,指针p1的值(指向的地址): 011B04D0
扩容后,&vector1: 00EFF824
扩容后,&vector1[0]: 011C0C40声明: int array2[] = { 1 };
&array2: 00EFF7D4
&array2[0]: 00EFF7D4
从第三部分可以看到,对于一个数组array2,它的地址就是它的头元素的地址。而第一部分中,vector1的地址,与它的头元素地址并不相同。
扩容之后,&vector1 地址还是不变,但是头元素的地址已经变了。
如果你在扩容前,使用一个指针指向头元素,扩容后,指针指向的地址不变,但是这个地方已经变成了野值。
最后,扩容有两种机制,2倍扩容和1.5倍扩容。这个机制随编译器的不同而不同。
VS2017使用的是1.5倍扩容,g++编译器用的是2倍扩容。
在大部分情况下,1.5倍扩容要好一些。因为随着内存的增长,可以实现一定程度上的内存复用。
下面展示两种编译器具体的扩容情况。
以下内容来源于链接。
测试代码:
#include <stdio.h>
#include <vector>
int main() {std::vector<double> v;printf("size:%d capacity:%d max_size:%llu\n",v.size(),v.capacity(),v.max_size());int last_capacity = -1;for (int i = 0; i < v.max_size(); ++i) {v.push_back(1.0*i);if (last_capacity!=v.capacity()) {printf("size:%10d capacity:%10d c/l:%d max_size:%llu\n",v.size(),v.capacity(),v.capacity()/last_capacity,v.max_size());}last_capacity = v.capacity();}return 0;
}上面是vs2017的1.5倍扩容,下面是g++的2倍扩容:
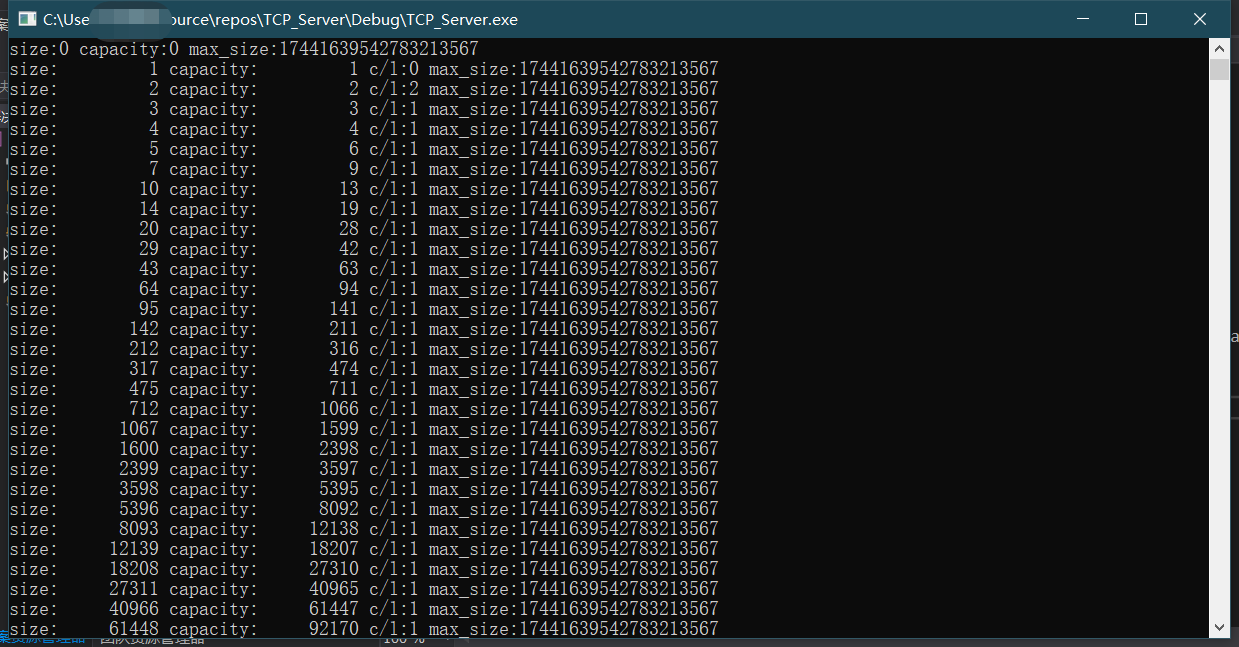
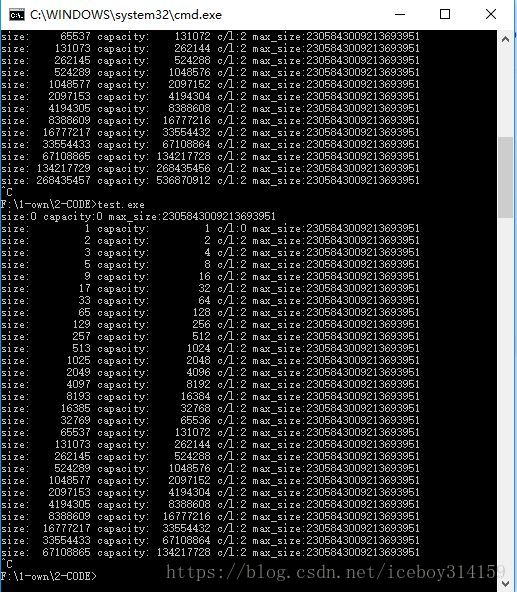
vector的capacity,是指当前状态下(未重新向操作系统申请内存前)的最大容量。
这个值如果不指定,则开始是0,加入第一个值时,由于capacity不够,向操作系统申请了长度为1的内存。在这之后每次capacity不足时,都会重新向操作系统申请长度为原来两倍的内存。
回到刚才的话题:为什么1.5倍扩容要好一些?
以下内容来源于链接。
- 两倍扩容
假设我们一开始申请了 16Byte 的空间。
当需要更多空间的时候,将首先申请 32Byte,然后释放掉之前的 16Byte。这释放掉的16Byte 的空间就闲置在了内存中。
当还需要更多空间的时候,你将首先申请 64Byte,然后释放掉之前的 32Byte。这将在内存中留下一个48Byte 的闲置空间(假定之前的 16Byte 和此时释放的32Byte 合并)
当还需要更多空间的时候,你将首先申请128Byte,然后释放掉之前的 64 Byte。这将在内存中留下一个112Byte 的闲置空间(假定所有之前释放的空间都合并成了一个块)
扩容因子为2时,上述例子表明:每次扩容,我们释放掉的内存连接起来的大小,都小于即将要分配的内存大小。
- 1.5倍扩容
假设我们一开始申请了 16Byte 的空间。
当需要更多空间的时候,将申请 24 Byte ,然后释放掉 16 ,在内存中留下 16Byte 的空闲空间。
当需要更多空间的时候,将申请 36 Byte,然后释放掉 24,在内存中留下 40Byte (16 + 24)的空闲空间。
当需要更多空间的时候,将申请 54 Byte,然后释放 36,在内存中留下 76Byte。
当需要更多空间的时候,将申请 81 Byte,然后释放 54, 在内存中留下 130Byte。
当需要更多空间的时候,将申请 122 Byte 的空间(复用内存中闲置的 130Byte)
由此可见,1.5倍扩容在一定程度上可以实现内存的复用。当然,每次扩容的大小更小,也意味着时间效率的降低,看取舍了。
相关文章:
Vector的扩容机制
到需要扩容的时候,Vector会根据需要的大小,创建一个新数组,然后把旧数组的元素复制进新数组。 我们可以看到,扩容后,其实是一个新数组,内部元素的地址已经改变了。所以扩容之后,原先的迭代器会…...
22讲MySQL有哪些“饮鸩止渴”提高性能的方法
短连接风暴 是指数据库有很多链接之后只执行了几个语句就断开的客户端,然后我们知道数据库客户端和数据库每次连接不仅需要tcp的三次握手,而且还有mysql的鉴权操作都要占用很多服务器的资源。话虽如此但是如果连接的不多的话其实这点资源无所谓的。 但是…...
10.0自定义SystemUI下拉状态栏和通知栏视图(六)之监听系统通知
1.前言 在进行rom产品定制化开发中,在10.0中针对systemui下拉状态栏和通知栏的定制UI的工作开发中,原生系统的下拉状态栏和通知栏的视图UI在产品开发中会不太满足功能, 所以根据产品需要来自定义SystemUI的下拉状态栏和通知栏功能,首选实现的就是下拉通知栏左滑删除通知的部…...
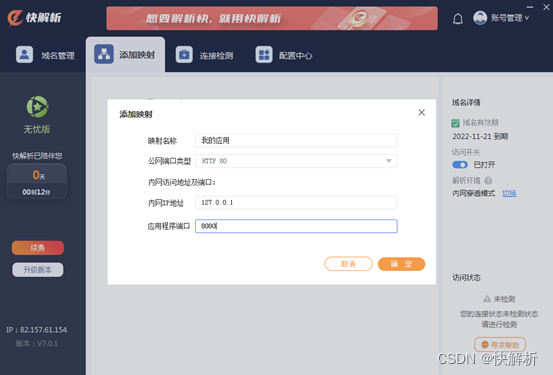
怎样在外网登录访问CRM管理系统?
一、什么是CRM管理系统? Customer Relationship Management,简称CRM,指客户关系管理,是企业利用信息互联网技术,协调企业、顾客和服务上的交互,提升管理服务。为了企业信息安全以及使用方便,企…...
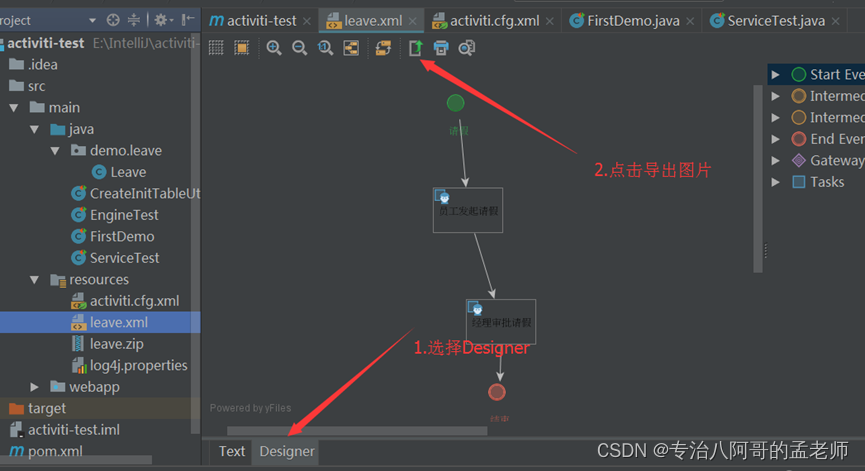
Activity工作流(三):Service服务
3. Service服务 所有的Service都通过流程引擎获得。 3.1 RepositoryService 仓库服务是存储相关的服务,一般用来部署流程文件,获取流程文件(bpmn和图片),查询流程定义信息等操作,是引擎中的一个重要的服务。…...

算法--最长回文子串--java--python
这个算法题里面总是有 暴力解法 把所有字串都拿出来判断一下 这里有小小的优化: 就是当判断的字串小于等于我们自己求得的最长回文子串的长度,那么我们就不需要在进行对这个的判断这里的begin,还可以用来取得最小回文子串是什么 java // 暴…...
ElasticSearch-第二天
目录 文档批量操作 批量获取文档数据 批量操作文档数据 DSL语言高级查询 DSL概述 无查询条件 叶子条件查询 模糊匹配 match的复杂用法 精确匹配 组合条件查询(多条件查询) 连接查询(多文档合并查询) 查询DSL和过滤DSL 区别 query DSL filter DSL Query方式查…...
【AI大比拼】文心一言 VS ChatGPT-4
摘要:本文将对比分析两款知名的 AI 对话引擎:文心一言和 OpenAI 的 ChatGPT,通过实际案例让大家对这两款对话引擎有更深入的了解,以便大家选择合适的 AI 对话引擎。 亲爱的 CSDN 朋友们,大家好!近年来&…...

美团笔试-3.18
1、捕获敌人 小美在玩一项游戏。该游戏的目标是尽可能抓获敌人。 敌人的位置将被一个二维坐标 (x, y) 所描述。 小美有一个全屏技能,该技能能一次性将若干敌人一次性捕获。 捕获的敌人之间的横坐标的最大差值不能大于A,纵坐标的最大差值不能大于B。 现在…...

【12】SCI易中期刊推荐——计算机信息系统(中科院4区)
🚀🚀🚀NEW!!!SCI易中期刊推荐栏目来啦 ~ 📚🍀 SCI即《科学引文索引》(Science Citation Index, SCI),是1961年由美国科学信息研究所(Institute for Scientific Information, ISI)创办的文献检索工具,创始人是美国著名情报专家尤金加菲尔德(Eugene Garfield…...

好不容易约来了一位程序员来面试,结果人家不做笔试题
感觉以后还是不要出面试题这环节好了。好不容易约来了一位程序员来面试。刚递给他一份笔试题,他一看到要做笔试题,说不做笔试题,有问题面谈就好了,搞得我有点尴尬,这位应聘者有3年多工作经验。关于程序员岗位ÿ…...

这几个过时Java技术不要再学了
Java 已经发展了近20年,极其丰富的周边框架打造了一个繁荣稳固的生态圈。 Java现在不仅仅是一门语言,而且还是一整个生态体系,实在是太庞大了,从诞生到现在,有无数的技术在不断的推出,也有很多技术在不断的…...

EEPROM芯片(24c02)使用详解(I2C通信时序分析、操作源码分析、原理图分析)
1、前言 (1)本文主要是通过24c02芯片来讲解I2C接口的EEPROM操作方法,包含底层时序和读写的代码; (2)大部分代码是EEPROM芯片通用的,但是其中关于某些时间的要求,是和具体芯片相关的,和主控芯片和外设芯片都有关系&…...
Django4.0新特性-主要变化
Django 4.0于2021年12月正式发布,标志着Django 4.X时代的来临。参考Django 4.0 release notes | Django documentation | Django Python 兼容性 Django 4.0 将支持 Python 3.8、3.9 与 3.10。强烈推荐并且仅官方支持每个系列的最新版本。 Django 3.2.x 系列是最后…...

MySQL高级面试题整理
1. 执行流程 mysql客户端先与服务器建立连接Sql语句通过解析器形成解析树再通过预处理器形成新解析树,检查解析树是否合法通过查询优化器将其转换成执行计划,优化器找到最适合的执行计划执行器执行sql 2. MYISAM和InNoDB的区别 MYISAM:不支…...

【Java】面向对象三大基本特征
【Java】面向对象三大基本特征 1.封装 On Java 8:研发程序员开发一个工具类,该工具类仅向应用程序员公开必要的内容,并隐藏内部实现的细节。这样可以有效地避免该工具类被错误的使用和更改,从而减少程序出错的可能。彼此职责划分清晰&#x…...
蓝桥杯C++组怒刷50道真题(填空题)
🌼深夜伤感网抑云 - 南辰Music/御小兮 - 单曲 - 网易云音乐 🌼多年后再见你 - 乔洋/周林枫 - 单曲 - 网易云音乐 18~22年真题,50题才停更,课业繁忙,有空就更,2023/3/18/23:01写下 目录 👊填…...

Shell自动化管理 for ORACLE DBA
1.自动收集每天早上9点到晚上8点之间的AWR报告。 auto_awr.sh #!/bin/bash# Set variables ORACLE_HOME/u01/app/oracle/product/12.1.0/dbhome_1 ORACLE_SIDorcl AWR_DIR/home/oracle/AWR# Set date format for file naming DATE$(date %Y%m%d%H%M%S)# Check current time - …...
Unity学习日记13(画布相关)
目录 创建画布 对画布的目标图片进行射线检测 拉锚点 UI文本框使用 按钮 按钮导航 按钮触发事件 输入框 实现单选框 下拉菜单 多选框选项加图片 创建画布 渲染模式 第一个,保持画布在最前方,画布内的内容显示优先级最高。 第二个,…...

初阶C语言:冒泡排序
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。1.冒泡排序关于冒泡排序我们在讲…...

Maxwell Fields Calculator双模式切换指南:堆栈与代数表达式输入实战解析
Maxwell Fields Calculator双模式切换指南:堆栈与代数表达式输入实战解析 在电磁仿真领域,Maxwell Fields Calculator一直是工程师进行后处理分析的利器。随着2025 R1版本的推出,一项革命性的功能——双模式表达式输入,彻底改变了…...

VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战
VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战 最近在折腾一些屏幕录像的后期处理,特别是那些4K分辨率、高帧率的超高清素材。说实话,直接处理这种级别的视频,对硬件和软件都是不小的考验。我试用了…...
,适配不同需求。)
摒弃固定显示界面,程序根据使用场景,自动切换显示界面(简洁版/详细版),适配不同需求。
一、 实际应用场景描述 (Scenario)假设你正在开发一台高精度光谱分析仪。这台设备有三种典型的使用者:1. 研发工程师(R&D):在实验室调试光路和算法。他们需要看到原始 ADC 值、温度漂移曲线、信噪比等详细数据。2. 质检员&…...

开源工具技术解析与实践指南:突破游戏性能限制的完整方案
开源工具技术解析与实践指南:突破游戏性能限制的完整方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 一、问题溯源:帧率限制背后的技术债务分析 当高端显卡在…...

小程序对商家私域运营到底有多重要?
小程序对商家私域运营到底有多重要?在企业持续获取客户成本不断上升的背景下,越来越多商家开始关注“私域运营”,而小程序也逐渐成为这一体系中的核心工具。小程序对商家私域运营的重要性,本质上体现在“用户沉淀能力与转化效率的…...

Zotero中文文献管理终极指南:茉莉花插件一键解决三大痛点
Zotero中文文献管理终极指南:茉莉花插件一键解决三大痛点 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 如果你正在使…...

nuScenes多传感器融合:毫米波雷达点云与图像时空对齐实战
1. 多传感器融合的核心挑战 自动驾驶系统就像一位全天候工作的司机,需要同时处理来自不同"感官"的信息。毫米波雷达擅长测距和测速,摄像头则能识别颜色和纹理,但要让它们像人类感官一样协同工作,首先要解决时空对齐的问…...

用STM32F103C8T6和F9P模组DIY一台RTK无人车:从蓝牙遥控到自主导航的保姆级教程
用STM32F103C8T6和F9P模组打造高精度RTK无人车:从零构建到自主导航全流程解析 在创客圈子里,能够自主导航的智能小车一直是热门项目。但传统基于普通GPS的方案定位精度往往在米级徘徊,难以实现真正的精准控制。而将RTK(实时动态定…...

Overleaf项目本地化实战:用VS Code插件管理、Git版本控制,再搭配Copilot提效
Overleaf项目本地化实战:用VS Code插件管理、Git版本控制,再搭配Copilot提效 对于经常使用LaTeX撰写学术论文或技术文档的用户来说,Overleaf无疑是一个强大的云端协作平台。然而,当项目规模扩大、需要更精细的版本控制时ÿ…...

探秘书匠策AI:毕业论文创作的“全能助手”大揭秘
在学术探索的征途中,毕业论文如同一座巍峨的山峰,让无数学生既心怀憧憬又倍感压力。从选题迷茫到文献海捞,从结构搭建到内容雕琢,每一步都充满了挑战。但别怕,今天我们就来揭秘一位学术界的“全能助手”——书匠策AI&a…...