MongoDB - 聚合阶段 $count、$skip、$project
文章目录
- 1. $count 聚合阶段
- 2. $skip 聚合阶段
- 3. $project 聚合阶段
- 1. 包含指定字段
- 2. 排除_id字段
- 3. 排除指定字段
- 4. 不能同时指定包含字段和排除字段
- 5. 排除嵌入式文档中的指定字段
- 6. 包含嵌入式文档中的指定字段
- 7. 添加新字段
- 8. 重命名字段
1. $count 聚合阶段
计算匹配到的文档数量:
db.collection.aggregate([// 匹配条件{ $match: { field: "value" } },// 其他聚合阶段// ...// 计算匹配到的文档数量{ $count: "total" }
])
首先使用 $match 阶段来筛选出满足条件的文档。然后可以添加其他的聚合阶段来进行进一步的数据处理。最后,使用 $count 阶段来计算匹配到的文档数量,并将结果存储在一个字段中(在示例中是 “total”)。
请注意,$count 阶段只返回一个文档,其中包含一个字段,表示匹配到的文档数量。如果没有匹配到任何文档,将返回一个文档,该字段的值为 0。
构造测试数据:
db.scores.drop()db.scores.insertMany([{ "_id" : 1, "subject" : "History", "score" : 88 },{ "_id" : 2, "subject" : "History", "score" : 92 },{ "_id" : 3, "subject" : "History", "score" : 97 },{ "_id" : 4, "subject" : "History", "score" : 71 },{ "_id" : 5, "subject" : "History", "score" : 79 },{ "_id" : 6, "subject" : "History", "score" : 83 }
])
$match阶段筛选 score 大于 80 的文档并计算匹配到的文档数量:
db.scores.aggregate([// 第一阶段{$match: {score: {$gt: 80}}},// 第二阶段{$count: "passing_scores"}]
)
{ "passing_scores" : 4 }
SpringBoot整合MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "scores")
public class Score {private int _id;private String subject;private int score;
}// 输出文档实体类
@Data
public class AggregationResult {private String passing_scores;
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void aggregateTest() {// $match 聚合阶段Criteria criteria = Criteria.where("score").gt(80);MatchOperation match = Aggregation.match(criteria);// $count 聚合阶段CountOperation count = Aggregation.count().as("passing_scores");// 组合聚合阶段Aggregation aggregation = Aggregation.newAggregation(match,count);// 执行聚合查询AggregationResults<AggregationResult> results= mongoTemplate.aggregate(aggregation, Score.class, AggregationResult.class);List<AggregationResult> mappedResults = results.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);//AggregationResult(passing_scores=4)}
}
2. $skip 聚合阶段
$skip 用于跳过指定数量的文档,并将剩余的文档传递给下一个聚合阶段。
{ $skip: <num> }
构造测试数据:
db.scores.drop()db.scores.insertMany([{ "_id" : 1, "subject" : "History", "score" : 88 },{ "_id" : 2, "subject" : "History", "score" : 92 },{ "_id" : 3, "subject" : "History", "score" : 97 },{ "_id" : 4, "subject" : "History", "score" : 71 },{ "_id" : 5, "subject" : "History", "score" : 79 },{ "_id" : 6, "subject" : "History", "score" : 83 }
])
db.scores.aggregate([{ $skip : 3 }
]);
// 1
{"_id": 4,"subject": "History","score": 71
}// 2
{"_id": 5,"subject": "History","score": 79
}// 3
{"_id": 6,"subject": "History","score": 83
}
$skip 跳过管道传递给它的前 3 个文档,并将剩余的文档传递给下一个聚合阶段。
// 输入文档实体类
@Data
@Document(collection = "scores")
public class Score {private int _id;private String subject;private int score;
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String subject;private int score;
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void aggregateTest() {// $skip 聚合阶段SkipOperation skip = Aggregation.skip(3);// 组合聚合阶段Aggregation aggregation = Aggregation.newAggregation(skip);// 执行聚合查询AggregationResults<AggregationResult> results= mongoTemplate.aggregate(aggregation, Score.class, AggregationResult.class);List<AggregationResult> mappedResults = results.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);//AggregationResult(_id=4, subject=History, score=71)//AggregationResult(_id=5, subject=History, score=79)//AggregationResult(_id=6, subject=History, score=83)}
}
3. $project 聚合阶段
将带所请求字段的文档传递至管道中的下个阶段。$project 返回的文档可以指定包含字段、排除 _id 字段、添加新字段以及计算现有字段的值。
$project 阶段具有以下原型形式:
{ $project: { <specification(s)> } }
1. 包含指定字段
默认情况下,_id 字段包含在输出文档中。要在输出文档中包含输入文档中的任何其他字段,必须在 $project指定,如果您指定包含的字段在文档中并不存在,那么 $project 将忽略该字段包含,同时不会将该字段添加到文档中。
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段输出文档中仅包含 _id、title 和 author 字段:
db.books.aggregate( [ { $project: { title: 1 , author: 1 } }
] )
{"_id": 1,"title": "abc123","author": {"last": "zzz","first": "aaa"}
}
SpringBoot 整合 MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String title;private Author author;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title", "author");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=abc123, author=AggregationResult.Author(last=zzz, first=aaa))}
}
2. 排除_id字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段输出文档中仅包含 title 和 author 字段:
db.books.aggregate( [ { $project: { _id: 0, title: 1, author: 1 } }
] )
{"title": "abc123","author": {"last": "zzz","first": "aaa"}
}
SpringBoot 整合 MongoDB实现:
// 输入文档实体类
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 输出文档实体类
@Data
public class AggregationResult {private int _id;private String title;private String isbn;private Author author;private int copies;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title", "author").andExclude("_id");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(title=abc123, author=AggregationResult.Author(last=zzz, first=aaa))}
}
3. 排除指定字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
在 $project 阶段中输出文档排除 title 和 isbn 字段:
db.books.aggregate( [ { $project: { title: 0, isbn: 0 } }
] )
// 1
{"_id": 1,"author": {"last": "zzz","first": "aaa"},"copies": 5,"lastModified": "2016-07-28"
}
SpringBoot 整合 MongoDB实现:
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project().andExclude("isbn","title");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=null, isbn=null, author=AggregationResult.Author(last=zzz, first=aaa), copies=5, lastModified=2016-07-28)}
}
4. 不能同时指定包含字段和排除字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
在 $project 阶段中输出文档排除 title 和 isbn 字段:
db.books.aggregate( [ { $project: { title: 0, isbn: 1 } }
] )
报错信息:
[Error] Bad projection specification, cannot include fields or add computed fields during an exclusion projection: { title: 0.0, isbn: 1.0 }
原因分析:在投影规范中,除_id字段外,不要在包含投影规范中使用排除操作。下面这样是可以的:
db.books.aggregate( [ { $project: { _id: 0, isbn: 1 } }
] )
5. 排除嵌入式文档中的指定字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5,lastModified: "2016-07-28"}
)
以下 $project 阶段中输出文档排除 author.first 和 lastModified 字段:
db.books.aggregate( [ { $project: { "author.first": 0, lastModified: 0 } }
] )
{"_id": 1,"title": "abc123","isbn": "0001122223334","author": {"last": "zzz"},"copies": 5
}
6. 包含嵌入式文档中的指定字段
构造测试数据:
db.books.drop()db.books.insertMany([{ _id: 1, user: "1234", stop: { title: "book1", author: "xyz", page: 32 } },{_id: 2, user: "7890", stop: [ { title: "book2", author: "abc", page: 5 }, { title: "book3", author: "ijk", page: 100 } ] }]
)
以下 $project 阶段仅包含嵌入式文档中的 title 字段:
db.books.aggregate( [ { $project: { "stop.title": 1 } }
] )
// 1
{"_id": 1,"stop": {"title": "book1"}
}// 2
{"_id": 2,"stop": [{"title": "book2"},{"title": "book3"}]
}
7. 添加新字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段添加新字段 isbn、lastName 和 copiesSold:
db.books.aggregate([{$project: {title: 1,isbn: {prefix: { $substr: [ "$isbn", 0, 3 ] },group: { $substr: [ "$isbn", 3, 2 ] },publisher: { $substr: [ "$isbn", 5, 4 ] },title: { $substr: [ "$isbn", 9, 3 ] },checkDigit: { $substr: [ "$isbn", 12, 1] }},lastName: "$author.last",copiesSold: "$copies"}}]
)
{"_id": 1,"title": "abc123","isbn": {"prefix": "000","group": "11","publisher": "2222","title": "333","checkDigit": "4"},"lastName": "zzz","copiesSold": 5
}
8. 重命名字段
构造测试数据:
db.books.drop()db.books.insertOne({"_id" : 1,title: "abc123",isbn: "0001122223334",author: { last: "zzz", first: "aaa" },copies: 5}
)
以下 $project 阶段将字段 copies重命名为 copiesSold :
db.books.aggregate([{$project: {title: 1,copiesSold: "$copies"}}]
)
{"_id": 1,"title": "abc123","copiesSold": 5
}
SpringBoot 整合MongoDB实现:
// 输入文档
@Data
@Document(collection = "books")
public class Book {private int _id;private String title;private String isbn;private Author author;private int copies;private String lastModified;@Datapublic static class Author {private String last;private String first;}
}// 输出文档
@Data
public class AggregationResult {private int _id;private String title;private String isbn;private Author author;private int copiesSold;private String lastModified;@Datapublic static class Author {private String last;private String first;}
}// 聚合操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class BeanLoadServiceTest {@Autowiredprivate MongoTemplate mongoTemplate;@Testpublic void testAggregate(){// project 阶段ProjectionOperation project = Aggregation.project("title").and("copies").as("copiesSold");// 组合阶段Aggregation aggregation = Aggregation.newAggregation(project);// 执行聚合AggregationResults<AggregationResult> aggregationResults = mongoTemplate.aggregate(aggregation, Book.class, AggregationResult.class);List<AggregationResult> mappedResults = aggregationResults.getMappedResults();// 打印结果mappedResults.forEach(System.out::println);// AggregationResult(_id=1, title=abc123, isbn=null, author=null, copiesSold=5, lastModified=null)}
}
相关文章:

MongoDB - 聚合阶段 $count、$skip、$project
文章目录 1. $count 聚合阶段2. $skip 聚合阶段3. $project 聚合阶段1. 包含指定字段2. 排除_id字段3. 排除指定字段4. 不能同时指定包含字段和排除字段5. 排除嵌入式文档中的指定字段6. 包含嵌入式文档中的指定字段7. 添加新字段8. 重命名字段 1. $count 聚合阶段 计算匹配到…...
)
如何获取文件缩略图(C#和C++实现)
在C中,可以有以下两种办法 使用COM接口IThumbnailCache 文档链接:IThumbnailCache (thumbcache.h) - Win32 apps | Microsoft Learn 示例代码如下: VOID GetFileThumbnail(PCWSTR path) {HRESULT hr CoInitialize(nullptr);IShellItem* i…...

create-vue项目的README中文版
使用方法 要使用 create-vue 创建一个新的 Vue 项目,只需在终端中运行以下命令: npm create vuelatest[!注意] (latest 或 legacy) 不能省略,否则 npm 可能会解析到缓存中过时版本的包。 或者,如果你需要支持 IE11,你…...
Centos 7系统(最小化安装)安装Git 、git-man帮助、补全git命令-详细文章
安装之前由于是最小化安装centos7安装一些开发环境和工具包 文章使用国内阿里源 cd /etc/yum.repos.d/ && mkdir myrepo && mv * myrepo&&lscurl -O https://mirrors.aliyun.com/repo/epel-7.repo;curl -O https://mirrors.aliyun.com/repo/Centos-7…...
Golang零基础入门课_20240726 课程笔记
视频课程 最近发现越来越多的公司在用Golang了,所以精心整理了一套视频教程给大家,这个只是其中的第一部,后续还会有很多。 视频已经录制完成,完整目录截图如下: 课程目录 01 第一个Go程序.mp402 定义变量.mp403 …...

杂记-镜像
-i https://pypi.tuna.tsinghua.edu.cn/simple 清华 pip intall 出现 error: subprocess-exited-with-error 错误的解决办法———————————pip install --upgrade pip setuptools57.5.0 ————————————————————————————————————…...

如何将WordPress文章中的外链图片批量导入到本地
在使用采集软件进行内容创作时,很多文章中的图片都是远程链接,这不仅会导致前端加载速度慢,还会在微信小程序和抖音小程序中添加各种域名,造成管理上的麻烦。特别是遇到没有备案的外链,更是让人头疼。因此,…...

primetime如何合并不同modes的libs到一个lib文件
首先,用primetime 抽 timing model 的指令如下。 代码如下(示例): #抽lib时留一些margin, setup -max/hold -min set_extract_model_margin -port [get_ports -filter "!defined(clocks)"] -max 0.1 #抽lib extract_mod…...
【运维笔记】数据库无法启动,数据库炸后备份恢复数据
事情起因 在做docker作业的时候,把卷映射到了宿主机原来的mysql数据库目录上,宿主机原来的mysql版本为8.0,docker容器版本为5.6,导致翻车。 具体操作 备份目录 将/var/lib/mysql备份到~/mysql_backup:cp /var/lib/…...
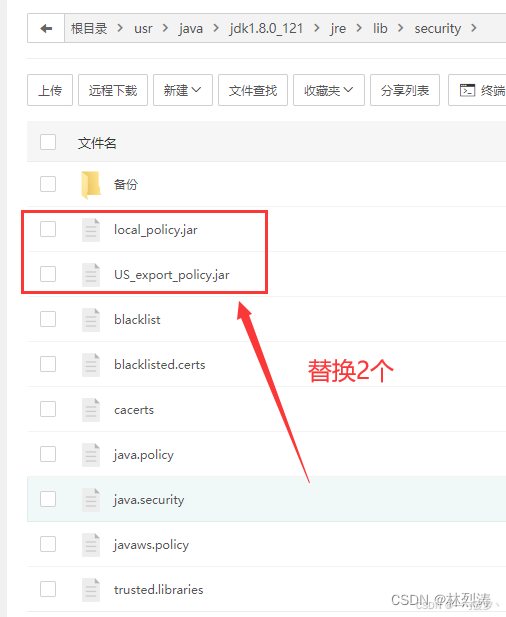
成功解决:java.security.InvalidKeyException: Illegal key size
在集成微信支付到Spring Boot项目时,可能会遇到启动报错 java.security.InvalidKeyException: Illegal key size 的问题。这是由于Java加密扩展(JCE)限制了密钥的长度。幸运的是,我们可以通过简单的替换文件来解决这个问题。 解决…...
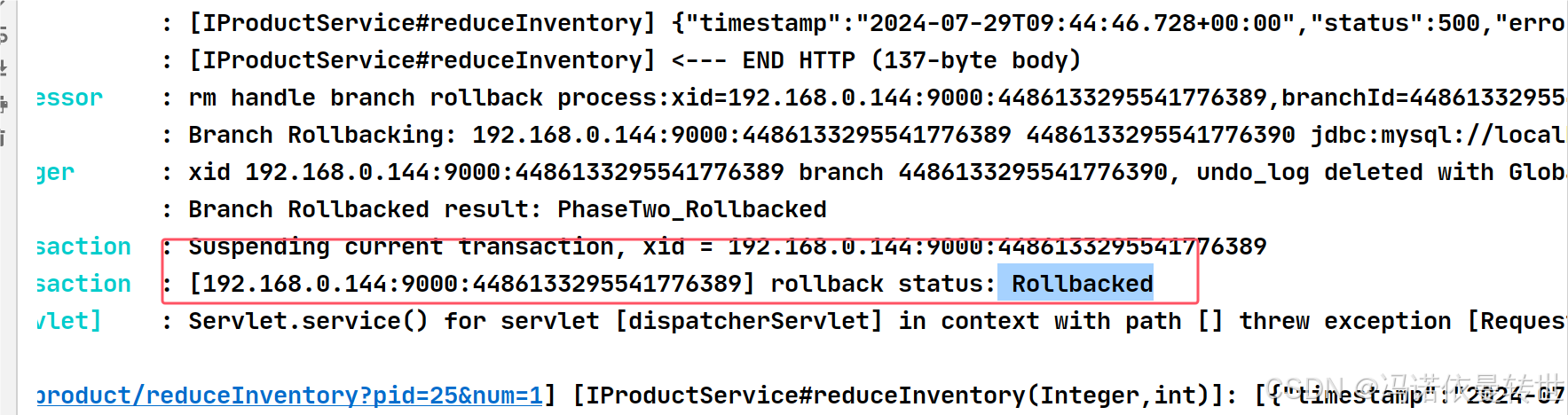
微服务事务管理(分布式事务问题 理论基础 初识Seata XA模式 AT模式 )
目录 一、分布式事务问题 1. 本地事务 2. 分布式事务 3. 演示分布式事务问题 二、理论基础 1. CAP定理 1.1 ⼀致性 1.2 可⽤性 1.3 分区容错 1.4 ⽭盾 2. BASE理论 3. 解决分布式事务的思路 三、初识Seata 1. Seata的架构 2. 部署TC服务 3. 微服务集成Se…...
—— fiddler的工作原理)
测试面试宝典(三十五)—— fiddler的工作原理
Fiddler 是一款强大的 Web 调试工具,其工作原理主要基于代理服务器的机制。 首先,当您在计算机上配置 Fiddler 为系统代理时,客户端(如浏览器)发出的所有 HTTP 和 HTTPS 请求都会被导向 Fiddler。 Fiddler 接收到这些…...

旷野之间32 - OpenAI 拉开了人工智能竞赛的序幕,而Meta 将会赢得胜利
他们通过故事做到了这一点(Snapchat 是第一个)他们用 Reels 实现了这个功能(TikTok 是第一个实现这个功能的)他们正在利用人工智能来实现这一点。 在人工智能竞赛开始时,Meta 的人工智能平台的表现并没有什么特别值得…...
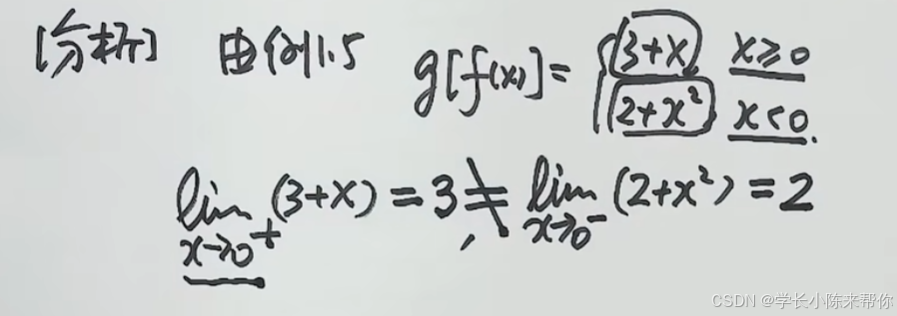
机械学习—零基础学习日志(高数15——函数极限性质)
零基础为了学人工智能,真的开始复习高数 这里我们将会学习函数极限的性质。 唯一性 来一个练习题: 再来一个练习: 这里我问了一下ChatGPT,如果一个值两侧分别趋近于正无穷,以及负无穷。理论上这个极限值应该说是不存…...

树 形 DP (dnf序)
二叉搜索子树的最大键值 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(null…...

React的生命周期?
React的生命周期分为三个主要阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting)。 1、挂载(Mounting) 当组件实例被创建并插入 DOM 时调用的生命周期方法&#x…...
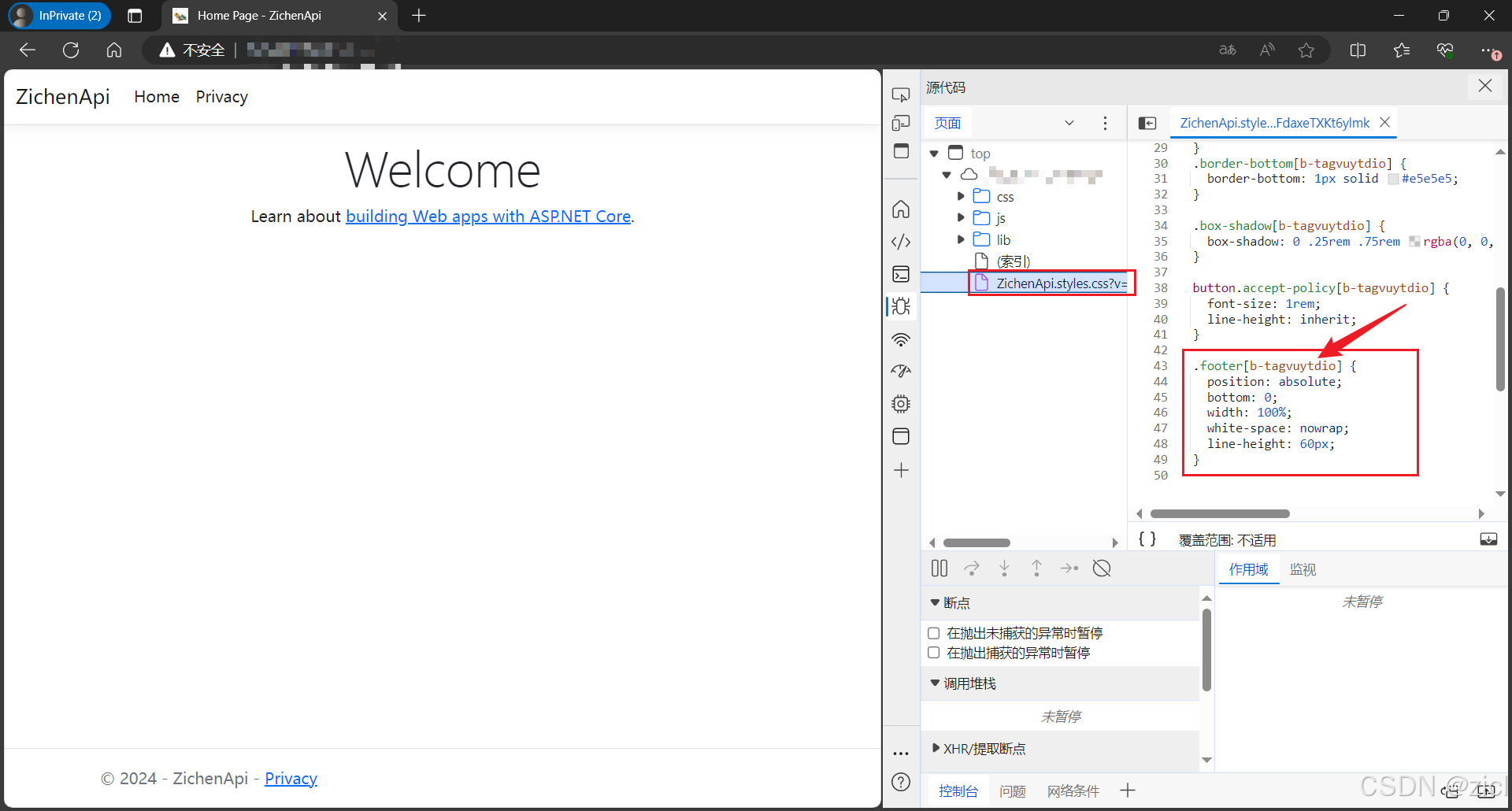
c# - - - ASP.NET Core 网页样式丢失,样式不对
c# - - - ASP.NET Core 网页样式丢失,样式不对 问题 正常样式是这样的。 修改项目名后,样式就变成这样了。底部的内容跑到中间了。 解决 重新生成解决方案,然后发布网站。 原因: 修改项目名之前的 div 上有个这个自定义属…...

Cannot find module ‘html-webpack-plugin
当你在使用Webpack构建项目时遇到Cannot find module html-webpack-plugin这样的错误,这意味着Webpack在构建过程中找不到html-webpack-plugin模块。要解决这个问题,你需要确保已经正确安装了html-webpack-plugin模块,并且在Webpack配置文件中…...

vue、react部署项目的 hashRouter 和 historyRouter模式
Vue 项目 使用 hashRouter 如果你使用的是 hashRouter,通常不需要修改 base,因为 hashRouter 使用 URL 的哈希部分来管理路由,这部分不会被服务器处理。你只需要确保 publicPath 设置正确即可。 使用 historyRouter 如果你使用的是 histo…...

Qt 实现抽屉效果
1、实现效果和UI设计界面 2、工程目录 3、mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QToolButton> #include <QPushButton> #include <vector> using namespace std;QT_BEGIN_NAMESPACE namespace…...
)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战) 当用户在地图应用中频繁缩放拖拽却遭遇卡顿、白屏时,体验会瞬间崩塌。作为前端开发者,我们该如何从底层机制入手解决这些问题?本文…...
)
别再只装软件了!TIA Portal Openness安装后必做的用户组配置(Win10避坑指南)
别再只装软件了!TIA Portal Openness安装后必做的用户组配置(Win10避坑指南) 当你兴冲冲地安装完TIA Portal和Openness组件,准备大展拳脚时,突然弹出一个"CAx操作无法启动"的错误提示——这种挫败感…...
)
Arduino Uno R3 bootloader烧写避坑全记录:从USBasp驱动安装到熔丝位设置(Win10/11实测)
Arduino Uno R3 bootloader烧写实战指南:从驱动配置到熔丝位安全操作 当一块全新的Atmega328P芯片静静躺在工作台上时,它就像一张白纸,等待着被赋予生命。作为硬件开发者,我们常常需要为这些空白芯片注入灵魂——烧写bootloader。…...

BaiduPCS-Go深度解析:从原理到实践的性能调优进阶指南
BaiduPCS-Go深度解析:从原理到实践的性能调优进阶指南 【免费下载链接】BaiduPCS-Go iikira/BaiduPCS-Go原版基础上集成了分享链接/秒传链接转存功能 项目地址: https://gitcode.com/GitHub_Trending/ba/BaiduPCS-Go BaiduPCS-Go作为一款功能强大的命令行百度…...

量子机器学习在网络安全中的应用与性能分析
1. 量子机器学习在网络安全中的应用现状量子机器学习(Quantum Machine Learning, QML)近年来在网络安全领域引起了广泛关注。作为一名长期从事网络安全与量子计算交叉研究的从业者,我见证了这项技术从理论探讨到实际验证的发展历程。量子计算…...

半导体设备投资热潮:千亿美元流向、产业逻辑与工程师应对策略
1. 从百亿投资狂潮看半导体制造的底层逻辑最近和几个在晶圆厂和Fab设备商工作的老朋友聊天,话题总绕不开一个词:投资。无论是台积电、三星的先进制程军备竞赛,还是中芯国际、联电的成熟制程扩产,背后都是一台台价值数千万甚至上亿…...

【研报 A110】物理AI时代的具身数据采集需求研究:国家级训练场落地,开源生态加速建设
摘要:物理AI时代,具身智能与世界模型的发展,推动具身数据采集成为下一代数据基建的核心浪潮。具身大模型对数据有着EB级的海量需求,同时对多模态、异构性与质量要求极高,当前数据缺口成为制约具身智能发展的核心瓶颈&a…...

003、LVGL与其他GUI库对比
LVGL与其他GUI库对比:从一次内存泄漏调试说起 去年做一款智能家居中控屏,选了某款轻量级GUI库,跑了两周发现系统每隔几小时就卡死一次。用FreeRTOS的任务栈监控一看,某个绘图任务栈溢出——查了三天,发现是字体缓存没释放,每次切换界面都偷偷吃掉几百字节。后来换成LVGL…...

深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验
深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch作为《Honey Select 2》最全…...

从Distributed到Lumped:三种SPEF寄生模型,你的芯片时序分析该选哪一个?
芯片时序分析中的SPEF模型选择:精度与效率的终极权衡 在28nm以下工艺节点,互连线寄生效应导致的时序偏差可能占到整体时钟周期的30%以上。面对动辄数千万个net的现代SoC设计,工程师们不得不在模型精度与运行时间之间做出艰难抉择。就像一位资…...