spark常用参数调优
目录
- 1.set spark.grouping.sets.reference.hive=true;
- 2.set spark.locality.wait.rack=0s
- 3.set spark.locality.wait=0s;
- 4.set spark.executor.memoryOverhead =2G;
- 5.set spark.sql.shuffle.partitions =1000;
- 6.set spark.shuffle.file.buffer =256k
- 7. set spark.reducer.maxSizeInFlight =96M
- 8.set spark.sql.files.maxPartitionBytes=3208864
1.set spark.grouping.sets.reference.hive=true;
在Spark中,设置spark.grouping.sets.reference.hive参数为true可以启用Hive引用的分组集功能。这个参数的作用是使Spark使用Hive的引用实现来处理GROUPING SETS语法。GROUPING SETS语法用于在GROUP BY子句中指定多个聚合级别,以便一次性计算多个聚合结果。启用这个参数可以让Spark使用Hive引用实现来执行这些操作,以确保与Hive兼容性。
2.set spark.locality.wait.rack=0s
在Spark中,spark.locality.wait.rack参数用于设置在任务启动之前等待数据本地性(locality)的时间阈值。数据本地性是指任务所需的数据是否已经在任务执行节点的本地存储介质上。在集群中,数据本地性可以分为PROCESS_LOCAL(数据在任务执行节点的内存中)、NODE_LOCAL(数据在任务执行节点的磁盘中)和RACK_LOCAL(数据在任务执行节点的同一机架上)。
通过设置spark.locality.wait.rack参数为0s,表示任务不会等待数据在同一机架上的本地性。这意味着Spark任务将不会等待数据在同一机架上可用,而会立即启动。这可能会提高任务的启动速度,但也可能导致更多的数据远程读取,因此需要根据具体情况进行权衡。
3.set spark.locality.wait=0s;
在Spark中,spark.locality.wait参数用于设置任务启动之前等待数据本地性的时间阈值。数据本地性是指任务所需的数据是否已经在任务执行节点的本地存储介质上。在集群中,数据本地性可以分为PROCESS_LOCAL(数据在任务执行节点的内存中)、NODE_LOCAL(数据在任务执行节点的磁盘中)、RACK_LOCAL(数据在任务执行节点的同一机架上)和ANY(任意位置)。
通过设置spark.locality.wait参数为0s,表示任务不会等待数据在任何本地性级别上可用,而会立即启动。这可能会提高任务的启动速度,但也可能导致更多的数据远程读取,因此需要根据具体情况进行权衡。
4.set spark.executor.memoryOverhead =2G;
在Spark中,spark.executor.memoryOverhead参数用于设置每个Executor的内存使用的额外空间。这个额外的空间用于Executor的内部结构和外部过程,例如任务执行和数据结构缓存。设置这个参数可以确保Executor有足够的内存用于执行任务和管理数据,同时避免内存溢出的情况发生。
5.set spark.sql.shuffle.partitions =1000;
在Spark中,spark.sql.shuffle.partitions参数用于设置在执行shuffle操作(例如group by或者join)时产生的分区数量。通过设置这个参数,可以控制shuffle操作的并行度,从而影响任务的性能和资源利用。
在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
比如:RDD有100个分区,那么计算的时候就会生成100个task,设置task间并行的参数是conf spark.sql.shuffle.partitions=100,你的资源配置为10个计算节点,(执行器excutor) --num-executors 10 默认为2一般设置在50-100之间,每个2个核,executor-cores 2 一般 2~4 为宜。同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。Task被执行的并发度 = Executor数目 * 每个Executor核数(=core总个数)。
6.set spark.shuffle.file.buffer =256k
在Spark中,spark.shuffle.file.buffer参数用于设置在执行shuffle操作时用于缓冲数据的大小。该参数指定了每个shuffle输出文件的缓冲区大小,以字节为单位。默认为32k;
7. set spark.reducer.maxSizeInFlight =96M
在Spark中,spark.reducer.maxSizeInFlight参数用于设置每个任务从每个map任务获取的最大数据量。这个参数可以帮助控制reduce任务从map任务获取数据的速度,从而避免在网络传输过程中发生内存溢出或网络拥塞等问题。默认48M;
8.set spark.sql.files.maxPartitionBytes=3208864
上述代码将spark.sql.files.maxPartitionBytes参数设置为33554432字节(即32MB)。这意味着在读取文件时,Spark会尝试将文件划分为每个分区大小不超过32MB的部分。根据实际情况,可以根据文件大小和集群资源情况来调整这个参数的值,以获得更好的性能表现。
相关文章:

spark常用参数调优
目录 1.set spark.grouping.sets.reference.hivetrue;2.set spark.locality.wait.rack0s3.set spark.locality.wait0s;4.set spark.executor.memoryOverhead 2G;5.set spark.sql.shuffle.partitions 1000;6.set spark.shuffle.file.buffer 256k7. set spark.reducer.maxSizeInF…...
C#/WinFrom TCP通信+ 网线插拔检测+客服端异常掉线检测
Winfor Tcp通信(服务端) 今天给大家讲一下C# 关于Tcp 通信部分,这一块的教程网上一大堆,不过关于掉网,异常断开连接的这部分到是到是没有多少说明,有方法 不过基本上最多的两种方式(1.设置一个超时时间,2.…...

一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80% Python爬虫 Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。 一、Python 爬虫…...

【用户会话信息在异步事件/线程池的传递】
用户会话信息在异步事件/线程池的传递 author:shengfq date:2024-07-29 version:1.0 背景: 同事写的一个代码功能,是在一个主线程中通过如下代码进行异步任务的执行,结果遇到了问题. 1.ThreadPool.execute(Runnable)启动一个子线程执行异步任务 2.applicationContext.publis…...

Java8: BigDecimal
Java8:BigDecimal 转两位小数的百分数-CSDN博客 BigDecimal 先做除法 然后取绝对值 在Java 8中,如果你想要对一个BigDecimal值进行除法操作,并随后取其绝对值,你可以通过组合divide方法和abs方法来实现这一目的。不过,需要注意的…...

苹果推送iOS 18.1带来Apple Intelligence预览
🦉 AI新闻 🚀 苹果推送iOS 18.1带来Apple Intelligence预览 摘要:苹果向iPhone和iPad用户推送iOS 18.1和iPadOS 18.1开发者预览版Beta更新,带来“Apple Intelligence”预览。目前仅支持M1芯片或更高版本的设备。Apple Intellige…...

testRigor-基于人工智能驱动的无代码自动化测试平台
1、testRigor介绍 简单来说,testRigor是一款基于人工智能驱动的无代码自动化测试平台,它能够通过分析应用的行为模式,智能地生成测试用例,并自动执行这些测试,无需人工编写测试脚本。可以用于Web、移动、API和本机桌面…...

hadoop学习(一)
一.hadoop概述 1.1hadoop优势 1)高可靠性:Hadoop底层维护多个数据副本,即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。 2)高扩展性:在集群间分配任务数据,可方便扩展数以千计…...
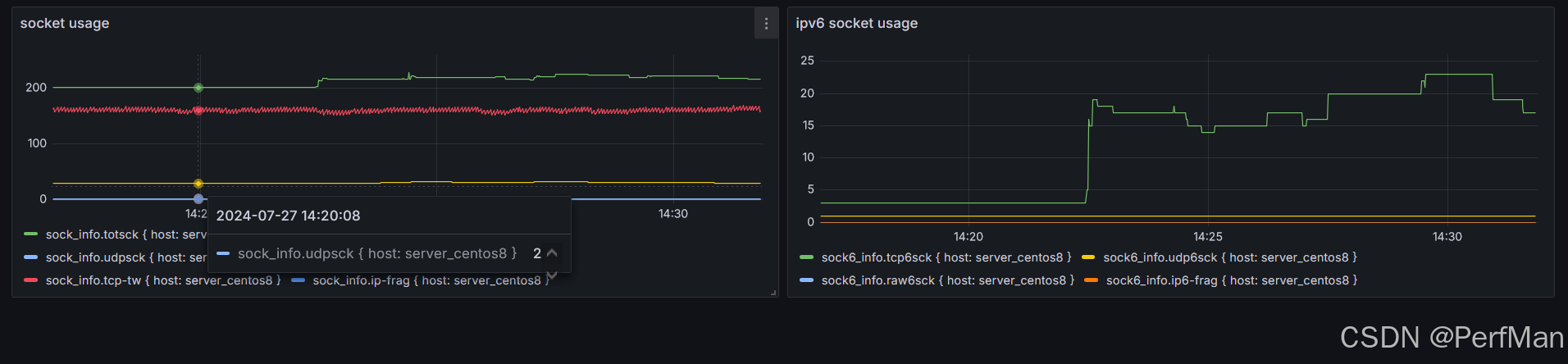
Linux性能监控:sar的可视化方案
在当今的IT环境中,系统性能监控是确保应用程序稳定运行和快速响应问题的关键。Linux作为一种广泛使用的操作系统,拥有多种性能监控工具,其中sar(System Activity Reporter)因其全面性和灵活性被广泛采用。然而…...

如何录制电脑屏幕视频,5招让您成为电脑录制高手
在今天,屏幕录制成为每个电脑使用者都应掌握的基础技能。不论是教学分享、会议记录还是游戏直播,屏幕录制都能帮你捕捉那些重要的瞬间,将无形的信息转化为有形的视频。那么,如何录制电脑屏幕视频呢?今天,我…...

AI届的新宠:小语言模型(SLM)?
大语言模型(LLM)在过去几年产生了巨大影响,特别是随着OpenAI的ChatGPT的出现,各种大语言模型如雨后春笋般出现,国内如KimiChat、通义千问、文心一言和智谱清言等。 然而,大语言模型通常拥有庞大的参数&…...

PMP模拟题错题本
模拟题A 错题整理 项目经理为一个具有按时完成盈利项目历史记录的组织工作。然而,由于缺乏相关方的支持以及他们未能提供信息,这些项目都经历过问题。若要避免这些问题,项目经理在新项目开始时应该做什么? A. 在启动阶段识别关键…...

Laravel Dusk:点亮自动化测试的明灯
Laravel Dusk:点亮自动化测试的明灯 在Web开发中,确保应用程序的用户体验和功能正确性至关重要。Laravel Dusk是一个强大的浏览器自动化测试工具,它允许开发者模拟用户与应用程序的交互,从而进行端到端的测试。本文将深入探讨Lar…...
Git、Gitlab以及分支管理
分布式版本控制系统 一、Git概述 Git是一种分布式版本控制系统,用于跟踪和管理代码的变更。它由Linus torvalds创建的,最初被设计用于Linux内核的开发。Git 允许开发人员跟踪和管理代码的版本,并且可以在不同的开发人员之间进行协作。 Githu…...

TCP/IP 协议栈介绍
TCP/IP 协议栈介绍 1. 引言 TCP/IP(传输控制协议/互联网协议)是一组用于数据网络中通信的协议集合,它是互联网的基础。本文将详细介绍TCP/IP协议栈的各个层次、工作原理以及其在网络通信中的作用。 2. TCP/IP 协议栈的层次结构 TCP/IP协议…...

香橙派orangepi系统没有apt,也没有apt-get,也没有yum命令,找不到apt、apt-get、yum的Linux系统
以下是一个关于如何在 Orange Pi 上的 Arch Linux 系统中发现缺失包管理器的问题并解决的详细教程。 发现问题 确认系统类型: 使用以下命令检查当前的 Linux 发行版: uname -a cat /etc/os-release如果你看到类似于 “Arch Linux” 的信息,说…...
在invidia jetpack4.5.1上运行c++版yolov8(tensorRT)
心路历程(可略过) 为了能在arm64上跑通yolov8,我试过很多很多代码,太多对库版本的要求太高了; 比如说有一个是需要依赖onnx库的,(https://github.com/UNeedCryDear/yolov8-opencv-onnxruntime-…...

Vue3 接入 i18n 实现国际化多语言
在 Vue.js 3 中实现网页的国际化多语言,最常用的包是 vue-i18n。 第一步,安装一个 Vite 下使用 <i18n> 标签的插件:unplugin-vue-i18n npm install unplugin-vue-i18n # 或 yarn add unplugin-vue-i18n 安装完成后,调整 v…...

深度学习环境坑。
前面装好了之后装pytorch之后老显示gpufalse。 https://www.jb51.net/article/247762.htm 原因就是清华源的坑。 安装的时候不要用conda, 用pip命令 我cuda12.6,4070s cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip cuda_12.5.1_555.85_windows.…...

LLM——10个大型语言模型(LLM)常见面试题以及答案解析
今天我们来总结以下大型语言模型面试中常问的问题 1、哪种技术有助于减轻基于提示的学习中的偏见? A.微调 Fine-tuning B.数据增强 Data augmentation C.提示校准 Prompt calibration D.梯度裁剪 Gradient clipping 答案:C 提示校准包括调整提示,尽量减少产生…...

能源监控项目避坑指南:为什么DLT645电表直连Modbus系统会失败?
能源监控项目避坑指南:为什么DLT645电表直连Modbus系统会失败? 在智慧能源项目的实施过程中,数据采集的可靠性直接关系到整个系统的运行效果。许多项目团队在遇到DLT645规约电表与Modbus系统对接时,往往会尝试直接连接,…...

OpenClaw硬件监控:nanobot定时报告系统资源使用情况
OpenClaw硬件监控:nanobot定时报告系统资源使用情况 1. 为什么需要自动化硬件监控 去年夏天,我的开发机因为内存泄漏问题突然宕机,导致一个重要的线上演示被迫推迟。当时我就意识到,手动检查系统资源的方式既不及时也不可靠。直…...

YOLOv5在边缘设备上部署实战:从Jetson Nano到树莓派,实现实时路面障碍检测
YOLOv5边缘计算部署实战:从Jetson Nano到树莓派的高性能路面检测方案 当自动驾驶小车需要识别前方突然出现的石块,或是智慧路侧单元要实时监控道路异常时,边缘设备上的AI推理能力就成为关键。本文将带您深入探索如何将YOLOv5模型部署到Jetson…...

Qwen3.5-4B-Claude-Opus部署教程:supervisor托管+健康检查全流程详解
Qwen3.5-4B-Claude-Opus部署教程:supervisor托管健康检查全流程详解 1. 模型介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,重点强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版本…...

背包问题Ⅱ与二分问题
今天我对背包问题有了更深的理解,我一定要写下来,巩固自己的思路并且,遇到新的难题二分,不管了,干就完了!!!完全背包以今天写的代码展开详细描述与解释,并附上题目#define N 1001 in…...

如何高效配置Unity插件框架:BepInEx完整实战指南
如何高效配置Unity插件框架:BepInEx完整实战指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专为Unity游戏设计的插件框架和补丁工具,能够…...

Wan2.2-I2V-A14B部署教程:系统盘50GB+数据盘40GB最小化配置实操
Wan2.2-I2V-A14B部署教程:系统盘50GB数据盘40GB最小化配置实操 1. 镜像概述与核心特性 Wan2.2-I2V-A14B是一款专为文生视频任务优化的私有部署镜像,特别针对RTX 4090D 24GB显存显卡进行了深度优化。这个镜像最大的特点是开箱即用,内置了完整…...

AI虚拟员工平台完整搭建教程:从源码获取到正式上线,全流程记录
温馨提示:文末有资源获取方式最近AI赛道又火了一个新方向,很多人都在讨论,但真正能用起来的没几个。技术门槛摆在那,普通用户想上手确实不容易。今天这篇教程,我把从源码部署到正式上线的完整过程整理出来,…...

从源码到上架:手把手教你用Android Studio打包绿豆TVBox APK,并修改Logo、启动图和包名
从零打造个性化TV应用:Android Studio深度定制指南 在流媒体内容消费爆发的时代,拥有一个专属的影视聚合平台成为许多技术爱好者的追求。绿豆TVBox这类开源项目为开发者提供了快速入门的跳板,但真正实现个性化部署需要跨越从源码编译到定制化…...

3个AI脚本让Illustrator设计效率提升300%:从重复劳动到创意爆发
3个AI脚本让Illustrator设计效率提升300%:从重复劳动到创意爆发 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 作为设计师,你是否每天花费40%以上时间在重复…...