一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80%
Python爬虫
Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。

一、Python 爬虫的基本概念
1. 什么是爬虫?
爬虫,也称为网络蜘蛛或网络机器人,是一种自动化脚本或程序,用于浏览和提取网站上的数据。爬虫会从一个初始网页开始,根据网页上的链接不断访问更多的网页,并将网页内容存储下来供后续分析。
2. 爬虫的工作流程
一般来说,一个爬虫的工作流程包括以下几个步骤:
1. 发送请求:使用HTTP库发送请求,获取网页内容。
2. 解析网页:使用解析库解析网页,提取所需数据。
3. 存储数据:将提取的数据存储到数据库或文件中。
4. 处理反爬机制:应对网站的反爬虫技术,如验证码、IP封禁等。
二、常用的Python爬虫库
1. Requests
Requests是一个简单易用的HTTP请求库,用于发送网络请求,获取网页内容。其主要特点是API简洁明了,支持各种HTTP请求方式。
import requestsresponse = requests.get('https://example.com')
print(response.text)2. BeautifulSoup
BeautifulSoup是一个用于解析HTML和XML的库,提供简便的API来搜索、导航和修改解析树。
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.string)3. Scrapy
Scrapy是一个功能强大的爬虫框架,适用于构建和维护大型爬虫项目。它提供了丰富的功能,如自动处理请求、解析、存储数据等。
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example'start_urls = ['https://example.com']def parse(self, response):title = response.css('title::text').get()yield {'title': title}4. Selenium
Selenium是一个自动化测试工具,也常用于爬取动态网页。它可以模拟浏览器行为,如点击、输入、滚动等。
from selenium import webdriverdriver = webdriver.Chrome()
driver.get('https://example.com')
print(driver.title)
driver.quit()三、核心技术
1. 处理反爬机制
反爬机制是网站为了防止数据被大量抓取而采取的措施。常见的反爬机制包括:
-
• User-Agent 伪装:模拟真实浏览器的请求头。
-
• IP 代理:使用代理服务器绕过IP封禁。
-
• 验证码:利用打码平台或人工识别。
-
• 动态内容:使用Selenium等工具处理JavaScript渲染的内容。
2. 数据解析
数据解析是将HTML内容转化为结构化数据的过程。除了BeautifulSoup,lxml和XPath也是常用的解析工具。
3. 数据存储
数据存储是将提取到的数据保存到本地或数据库中。常用的存储方式包括:
-
• 文件存储:如CSV、JSON、Excel文件。
-
• 数据库存储:如SQLite、MySQL、MongoDB。
四、实战案例
案例1:爬取网易新闻标题
下面是一个爬取网易新闻网站标题的简单示例:
import requests
from bs4 import BeautifulSoupdef fetch_netnews_titles(url):# 发送HTTP请求response = requests.get(url)# 使用BeautifulSoup解析响应内容soup = BeautifulSoup(response.text, 'html.parser')# 找到所有新闻标题的标签(此处假设它们在<h2>标签中)news_titles = soup.find_all('h2')# 提取标题文本titles = [title.text.strip() for title in news_titles]return titles# 网易新闻的URL
url = 'https://news.163.com'
titles = fetch_netnews_titles(url)
print(titles)案例2:使用Scrapy构建电商爬虫
Scrapy 可以用来构建复杂的电商网站爬虫,以下是一个简单的商品信息爬虫示例:
import scrapyclass EcommerceSpider(scrapy.Spider):name = 'ecommerce'start_urls = ['https://example-ecommerce.com/products']def parse(self, response):for product in response.css('div.product'):yield {'name': product.css('h2::text').get(),'price': product.css('span.price::text').get(),}五、深入解析爬虫原理
1. HTTP协议与请求头伪装
在爬虫的请求阶段,我们经常需要处理HTTP协议。理解HTTP协议的请求和响应结构是爬虫开发的基础。通过伪装请求头中的User-Agent,可以模拟不同浏览器和设备的访问行为,避免被目标网站识别为爬虫。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get('https://example.com', headers=headers)2. 使用代理IP绕过IP封禁
当网站对某一IP地址的访问频率进行限制时,我们可以使用代理IP来绕过封禁。通过轮换使用不同的代理IP,可以提高爬虫的稳定性和数据采集效率。
proxies = {'http': 'http://10.10.1.10:3128','https': 'http://10.10.1.10:1080',
}
response = requests.get('https://example.com', proxies=proxies)3. 处理动态网页
对于通过JavaScript加载数据的动态网页,传统的静态解析方法难以奏效。此时,我们可以使用Selenium来模拟用户操作,加载完整的网页内容后再进行解析。
from selenium import webdriveroptions = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get('https://example.com')
content = driver.page_source
driver.quit()soup = BeautifulSoup(content, 'html.parser')4. 数据清洗与存储优化
在爬取数据后,往往需要对数据进行清洗和格式化,以便后续的分析和使用。Pandas库是一个强大的数据处理工具,可以帮助我们高效地进行数据清洗和存储。
import pandas as pddata = {'name': ['Product1', 'Product2'],'price': [10.99, 12.99]
}
df = pd.DataFrame(data)
df.to_csv('products.csv', index=False)结语
掌握Python爬虫的核心技术和工具,可以大大提升数据采集的效率和质量。通过本文的介绍,希望你能对Python爬虫有一个全面的了解,并在实践中不断提高自己的爬虫技能。
相关文章:
一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80% Python爬虫 Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。 一、Python 爬虫…...

【用户会话信息在异步事件/线程池的传递】
用户会话信息在异步事件/线程池的传递 author:shengfq date:2024-07-29 version:1.0 背景: 同事写的一个代码功能,是在一个主线程中通过如下代码进行异步任务的执行,结果遇到了问题. 1.ThreadPool.execute(Runnable)启动一个子线程执行异步任务 2.applicationContext.publis…...

Java8: BigDecimal
Java8:BigDecimal 转两位小数的百分数-CSDN博客 BigDecimal 先做除法 然后取绝对值 在Java 8中,如果你想要对一个BigDecimal值进行除法操作,并随后取其绝对值,你可以通过组合divide方法和abs方法来实现这一目的。不过,需要注意的…...

苹果推送iOS 18.1带来Apple Intelligence预览
🦉 AI新闻 🚀 苹果推送iOS 18.1带来Apple Intelligence预览 摘要:苹果向iPhone和iPad用户推送iOS 18.1和iPadOS 18.1开发者预览版Beta更新,带来“Apple Intelligence”预览。目前仅支持M1芯片或更高版本的设备。Apple Intellige…...

testRigor-基于人工智能驱动的无代码自动化测试平台
1、testRigor介绍 简单来说,testRigor是一款基于人工智能驱动的无代码自动化测试平台,它能够通过分析应用的行为模式,智能地生成测试用例,并自动执行这些测试,无需人工编写测试脚本。可以用于Web、移动、API和本机桌面…...

hadoop学习(一)
一.hadoop概述 1.1hadoop优势 1)高可靠性:Hadoop底层维护多个数据副本,即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。 2)高扩展性:在集群间分配任务数据,可方便扩展数以千计…...
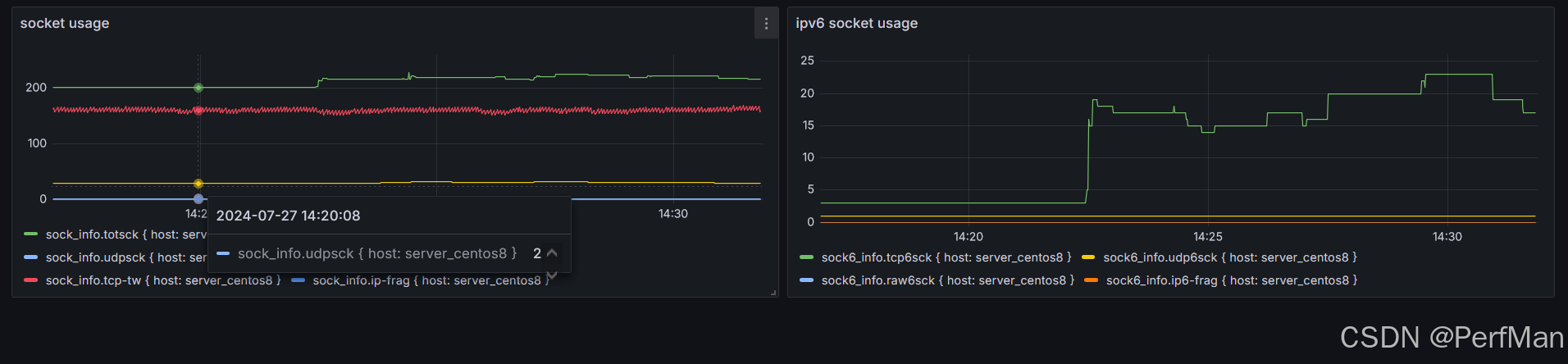
Linux性能监控:sar的可视化方案
在当今的IT环境中,系统性能监控是确保应用程序稳定运行和快速响应问题的关键。Linux作为一种广泛使用的操作系统,拥有多种性能监控工具,其中sar(System Activity Reporter)因其全面性和灵活性被广泛采用。然而…...

如何录制电脑屏幕视频,5招让您成为电脑录制高手
在今天,屏幕录制成为每个电脑使用者都应掌握的基础技能。不论是教学分享、会议记录还是游戏直播,屏幕录制都能帮你捕捉那些重要的瞬间,将无形的信息转化为有形的视频。那么,如何录制电脑屏幕视频呢?今天,我…...

AI届的新宠:小语言模型(SLM)?
大语言模型(LLM)在过去几年产生了巨大影响,特别是随着OpenAI的ChatGPT的出现,各种大语言模型如雨后春笋般出现,国内如KimiChat、通义千问、文心一言和智谱清言等。 然而,大语言模型通常拥有庞大的参数&…...

PMP模拟题错题本
模拟题A 错题整理 项目经理为一个具有按时完成盈利项目历史记录的组织工作。然而,由于缺乏相关方的支持以及他们未能提供信息,这些项目都经历过问题。若要避免这些问题,项目经理在新项目开始时应该做什么? A. 在启动阶段识别关键…...

Laravel Dusk:点亮自动化测试的明灯
Laravel Dusk:点亮自动化测试的明灯 在Web开发中,确保应用程序的用户体验和功能正确性至关重要。Laravel Dusk是一个强大的浏览器自动化测试工具,它允许开发者模拟用户与应用程序的交互,从而进行端到端的测试。本文将深入探讨Lar…...
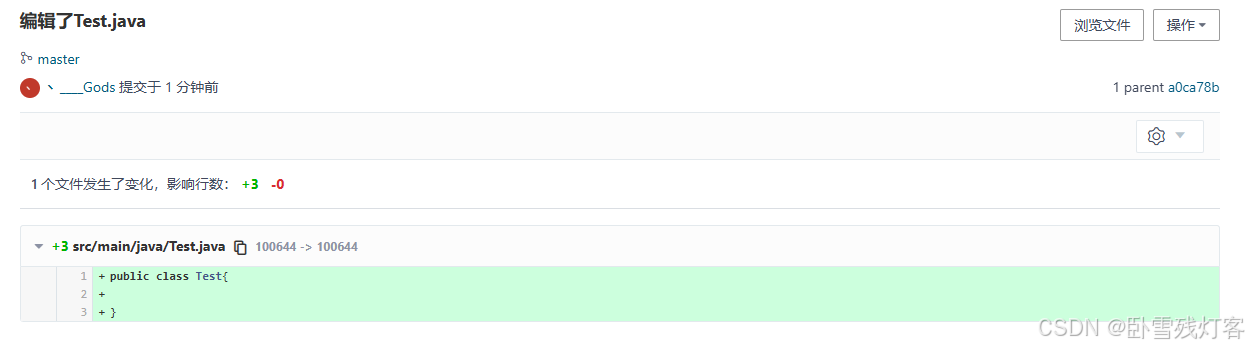
Git、Gitlab以及分支管理
分布式版本控制系统 一、Git概述 Git是一种分布式版本控制系统,用于跟踪和管理代码的变更。它由Linus torvalds创建的,最初被设计用于Linux内核的开发。Git 允许开发人员跟踪和管理代码的版本,并且可以在不同的开发人员之间进行协作。 Githu…...

TCP/IP 协议栈介绍
TCP/IP 协议栈介绍 1. 引言 TCP/IP(传输控制协议/互联网协议)是一组用于数据网络中通信的协议集合,它是互联网的基础。本文将详细介绍TCP/IP协议栈的各个层次、工作原理以及其在网络通信中的作用。 2. TCP/IP 协议栈的层次结构 TCP/IP协议…...

香橙派orangepi系统没有apt,也没有apt-get,也没有yum命令,找不到apt、apt-get、yum的Linux系统
以下是一个关于如何在 Orange Pi 上的 Arch Linux 系统中发现缺失包管理器的问题并解决的详细教程。 发现问题 确认系统类型: 使用以下命令检查当前的 Linux 发行版: uname -a cat /etc/os-release如果你看到类似于 “Arch Linux” 的信息,说…...
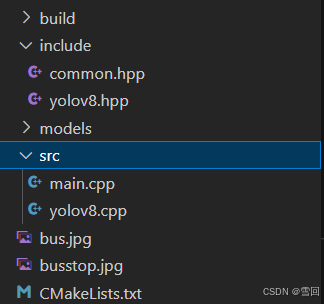
在invidia jetpack4.5.1上运行c++版yolov8(tensorRT)
心路历程(可略过) 为了能在arm64上跑通yolov8,我试过很多很多代码,太多对库版本的要求太高了; 比如说有一个是需要依赖onnx库的,(https://github.com/UNeedCryDear/yolov8-opencv-onnxruntime-…...

Vue3 接入 i18n 实现国际化多语言
在 Vue.js 3 中实现网页的国际化多语言,最常用的包是 vue-i18n。 第一步,安装一个 Vite 下使用 <i18n> 标签的插件:unplugin-vue-i18n npm install unplugin-vue-i18n # 或 yarn add unplugin-vue-i18n 安装完成后,调整 v…...

深度学习环境坑。
前面装好了之后装pytorch之后老显示gpufalse。 https://www.jb51.net/article/247762.htm 原因就是清华源的坑。 安装的时候不要用conda, 用pip命令 我cuda12.6,4070s cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip cuda_12.5.1_555.85_windows.…...

LLM——10个大型语言模型(LLM)常见面试题以及答案解析
今天我们来总结以下大型语言模型面试中常问的问题 1、哪种技术有助于减轻基于提示的学习中的偏见? A.微调 Fine-tuning B.数据增强 Data augmentation C.提示校准 Prompt calibration D.梯度裁剪 Gradient clipping 答案:C 提示校准包括调整提示,尽量减少产生…...

MongoDB - 聚合阶段 $count、$skip、$project
文章目录 1. $count 聚合阶段2. $skip 聚合阶段3. $project 聚合阶段1. 包含指定字段2. 排除_id字段3. 排除指定字段4. 不能同时指定包含字段和排除字段5. 排除嵌入式文档中的指定字段6. 包含嵌入式文档中的指定字段7. 添加新字段8. 重命名字段 1. $count 聚合阶段 计算匹配到…...
)
如何获取文件缩略图(C#和C++实现)
在C中,可以有以下两种办法 使用COM接口IThumbnailCache 文档链接:IThumbnailCache (thumbcache.h) - Win32 apps | Microsoft Learn 示例代码如下: VOID GetFileThumbnail(PCWSTR path) {HRESULT hr CoInitialize(nullptr);IShellItem* i…...

脉冲神经网络SAST训练方法:解决代理-硬件转换差距
1. 脉冲神经网络与传感器计算的挑战脉冲神经网络(SNNs)作为第三代神经网络模型,其核心特征是采用离散的脉冲信号进行信息传递和处理。这种事件驱动的计算方式与传统的连续激活神经网络(ANNs)有着本质区别。在传感器端计…...

OpenClaw:让 AI 从 “对话” 走向 “实干” 的开源智能体
在人工智能技术快速发展的今天,大语言模型的对话能力已日趋成熟,但 “能说不能做” 的痛点始终制约着 AI 的实际应用价值。2026 年,一款名为 OpenClaw(社区昵称 “小龙虾 AI”)的开源项目迅速走红,它以 “真…...

ExplorerPatcher:彻底改造你的Windows界面体验,打造个性化高效工作环境
ExplorerPatcher:彻底改造你的Windows界面体验,打造个性化高效工作环境 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher …...

研发交付管理:资源化与项目制的实践思考
说明(阅读前):本文系 方法论层面的归纳,依据常见软件研发组织实践整理,不涉及任何特定企业的内部制度、人数或薪酬细节;文中角色名称(如研发经理、项目发起人)为 通用称谓࿰…...

Go+SQLite构建极简自托管笔记共享平台:从原理到部署实战
1. 项目概述:一个极简、自托管的笔记共享平台最近在折腾个人知识管理工具时,我一直在寻找一个能让我快速分享单篇笔记或代码片段,同时又不想依赖第三方云服务的方案。市面上的Pastebin类工具很多,但要么功能臃肿,要么隐…...

技术Leader的困境:为什么你越努力,团队越依赖你?
在软件测试领域,我们比任何角色都更懂“依赖”这个词。测试环境依赖稳定、测试数据依赖真实、测试用例依赖需求文档。但有一种依赖,最致命却也最容易被忽视——团队对你的依赖。很多从一线测试骨干晋升为测试Leader的人,都会陷入一个怪圈&…...

别再傻傻分不清了!VB、VBS、VBA到底该用哪个?从Excel自动化到网页脚本的实战选择指南
VB、VBS与VBA实战指南:从Excel自动化到系统脚本的精准选择 每次打开Excel准备处理数据时,你是否纠结过该用VBA还是VBS?当需要批量重命名文件时,是否犹豫过VB和VBS哪个更高效?这三种看似相似的"VB系"语言&am…...

告别编译报错:解决Windows下QGC源码编译中C2220等常见错误的实战记录
告别编译报错:解决Windows下QGC源码编译中C2220等常见错误的实战记录 当你满怀期待地克隆完QGroundControl源码,配置好Visual Studio和Qt环境,却在编译阶段遭遇红色错误提示时,那种挫败感我深有体会。特别是看到QGCTileCacheWork…...

知网AI率80%降到15%教程,比话降AI知网算法专精+售后保障!
知网AI率80%降到15%教程,比话降AI知网算法专精售后保障! 如果你是硕博毕业生、学校送知网检测、答辩前查出 AI 率 80%——这篇文章直接给你完整操作教程。从「拿到 80% 报告」到「学校送审通过」的完整路径,每一步该做什么、花多少时间、花多…...

掌握智能游戏存档管理:实现高效跨平台游戏进度迁移
掌握智能游戏存档管理:实现高效跨平台游戏进度迁移 【免费下载链接】XGP-save-extractor Python script to extract savefiles out of Xbox Game Pass for PC games 项目地址: https://gitcode.com/gh_mirrors/xg/XGP-save-extractor 你是否曾在Xbox Game Pa…...