存储引擎MySQL和InnoDB(数据库管理与高可用)
1、存储引擎
存储引擎是核心组成部分,
是构成数据库最基础最底层的部件,
利用这个部件,你的Mysql能够对数据进行查询、创建、更新、删除等操作,
也就是说,用户所输入的一系列的mysql语句,是由存储引擎来执行的,
2、存储引擎的分类

注:innodb支持行级锁定
不同的存储引擎,它们在生成相关表的时候,都对应的有一个相关文件,

上图中的蓝色的三个文件是系统自带的,
然后,cd到mysql里面,ls查看一下,

注:上图圈中的三个文件共同构成了mysql中的一个表,
user.frm——存储了数据表表的结构(比如这个表有多少列,每个列有什么名字等)
user.MYD——存储了表里的每一行记录(数据)
user.MYI——存储了这个表的索引信息
上图的这种构成方式是由MyISAM引擎生成的文件,是有一个单独存放索引的文件的(这一点与Innodb引擎是不同的)
因为在安装mysql时,在它的配置文件里面指定的默认引擎是使用InnoDB,那就意味着
先登录进mysql里面,创建一个表,
![]()

use进这个auth库中,创建一个表,

然后退出mysql,在data里面查看一下,

注:在mysql里面,每一个库都是一个独立的目录,如果到这个库里面ls查看一下的话,
每一个表都会对应两个文件,既users.frm和users.ibd,而实际上ls查看到的是三个文件:

只要把库创建出来,上图中的opt这个文件就有了,
如果说,此时再去登录mysql里面创建一个表的话,
use进auth里面,创建001这个表:
![]()
然后退出mysql,再去使用ls查看一下:

而前面的opt文件还是那一个,没有多出来,
注:只要把库创建出来,opt这个文件就已经有了,
每一次创建表的时候会多出两个文件(.ibd和.ifm的文件)
opt文件(该库里所有的表共用的)存放的是该库的配置信息、编码、规则等,
.frm——存放的是元数据,即表的相关结构等信息,
.ibd——存放的是核心数据、索引信息,即表里的每一行记录是存放在.ibd里面的
上图中的这种结构是由InnoDB生成的文件,
小结:当想要去看一个库用的是什么存储引擎的时候,可以先cd到这个库的目录里面用ls查看一下都有哪些文件,大致就知道它用的是什么存储引擎了,因为每一种存储引擎所生成的文件是不一样的
在选择存储引擎的时候,如果说程序有事物的需求,就只能用InnoDB的引擎
3、修改存储引擎
(1)如何修改存储引擎?
同一个数据库里的不同的表,能否设置不同的存储引擎?
可以,存储引擎是针对表的,可以针对不同的表去设置不同的存储引擎,
方式一:
先use到库里面,

alter是修改表结构的语句,

然后可以去查看一下,现有的存储引擎变了没有,

修改完之后,退出mysql,再去ls一下这个auth目录,

方式二:还可以在配置文件/etc/my.cnf里面修改它的存储引擎的参数,改完之后再去重启一下mysqld服务,
(2)设置完引擎之后,如何查看当前的存储引擎?

注:\G表示格式化输出的意思,
在显示出来的页面里,找一下存储引擎是什么?

(3)如果想要在创建表的时候,就指定存储引擎呢?

所以,在创建表的时候,默认指定的存储引擎就是Innodb了,
如果你想要Innodb的存储引擎——那就在创建该表的时候,什么都不指定,就可以了
如果你想要用MyIsm的存储引擎——那就需要在创建表的时候,指定存储引擎,

注:在去设置存储引擎的时候,myisam的大小写是没有影响的
设置完之后,再去查看一下设置成功了没:

然后再去看一下,表t3的存储引擎是什么:
(4)如何在mysql里面,临时设置默认的存储引擎呢?
即不必去修改配置文件来设置存储引擎,也不必在创建表的时候去指定存储引擎,

然后再去创建一个表t3的时候,就不必在后面指定存储引擎了,


因为此时我们在配置文件里,指定的默认存储引擎是Inondb,那刚刚设置的临时默认存储引擎是否永久生效呢?
先退出mysql数据库,再登录进mysql里面,先use进auth这个库里面,


注:临时设置的默认存储引擎,只在mysql的命令行生效,一旦退出了连接,再登录进去的话,临时设置的就失效了
4、比较Innodb和Myisam这两种存储引擎,在处理数据方面的速度
测试读、写的速度:
需要创建出两个使用不同存储引擎的表,
先创建出测试所要用到的库,然后use到该库中:


创建两个结构相同的表,但是它们各自的存储引擎是不同的,
第一个表,用Myisam做存储引擎,

然后,用相同的语句把第二个表创建出来,
第二个表使用Innodb的存储引擎,

然后,可分别查看一下这两个表中的信息,是否设置成功了,


因为这两个表中,都给它们设置了id这一列为主键,那测试读的时候,就可以用索引去读,
然后,需要先在这两个表里面添加一些信息,
注:在表中数据量很少的情况下,测试读或写的性能,都没有任何可比性,需要写入大量数据才能测试出读、写的性能好坏,
这里可以使用一个脚本往这两个表里面,写数据
如何用脚本快速插入几百万行、上千万行的数据量?
即创建一个存储过程,然后利用这个存储过程去快速地执行这个存储过程所包含的脚本,
存储过程——存放在数据库服务器里面的一个脚本,只需要吊用这个脚本的名字就可以执行该脚本所有的语句了,
注:不要在创建存储过程的时候,用分号做结束符,
所以要先把存储过程的结束标识给改了,比如可以用$做Mysql语句的结束,

改好了之后,在用mysql去编辑存储过程的时候,编辑语句中,末尾就可以用$表示结束了,

create procedure insertm()
begin
set @i=1;
while @i
do
insert into tm(name) values(concat("zhangsan",@i));
set @i=@i+1;
end while;
end
$
利用上面的这个存储过程,就可以在tm这个表中添加1千万行记录,

create procedure inserti()
begin
set @i=1;
while @i
do
insert into ti(name) values(concat("zhangsan",@i));
set @i=@i+1;
end while;
end
$
先把上面的两个脚本复制一下,然后来到mysql的命令行里面,先把第一个存储过程给创建出来,给粘贴过来,

然后再把第二个存储过程给粘贴过来,

然后,就可以利用存储过程向两个表添加1千万行存储记录,

这时候,会消耗一段时间,但过程中不要Ctrl+C,只需要等,

然后来调用第二个存储过程,


注:从上图的结果耗费的时间去看的话,

下面要比较一下,两种存储引擎读的性能,
比较读(搜索)性能的时候,就要分为有索引和没索引两种情况了:

上面创建的这两个表都是以id那一列作为索引的,
(1)没索引的情况(不按id去搜索,按照name名字去搜索):
注:读的时候,要尽量确保读的量更大一些,才有可比性,


所以,无索引时,读取的性能里,myisam会更快一点,
(2)用带有索引去读的时候(拿id去搜索)


同样的量级别,再去搜索一下tm这个表,


所以,带索引的搜索时,innodb会更快一些,










相关文章:
存储引擎MySQL和InnoDB(数据库管理与高可用)
1、存储引擎 存储引擎是核心组成部分, 是构成数据库最基础最底层的部件, 利用这个部件,你的Mysql能够对数据进行查询、创建、更新、删除等操作, 也就是说,用户所输入的一系列的mysql语句,是由存储引擎来…...

探索局域网传输新境界 | 闪电藤 v2.2.7
在这个数字化时代,文件的快速、安全传输是我们日常工作中不可或缺的一部分。今天,电脑天空向大家介绍一款革命性的局域网文件传输工具——闪电藤,它将彻底改变你的文件传输体验。 🎨 界面设计 —— 极简之美 闪电藤采用极简的设…...

Tiling Window Management
我主要说一下windows版的 下面这个链接用的人比较多 GitHub - LGUG2Z/komorebi: A tiling window manager for Windows 🍉 建议搭配 GitHub - da-rth/yasb: A highly configurable cross-platform (Windows) status bar written in Python. GitHub - amnweb/ya…...

9. kubernetes资源——pv/pvc持久卷
kubernetes资源——pv/pvc持久卷 一、volume数据卷1、hostPath2、挂载nfs实现持久化 二、pv/pvc 持久卷/持久卷声明1、pv/pvc介绍2、pv/pvc的使用流程2.1 创建pv2.2 创建pvc2.3 创建pod,使用pv做持久化 一、volume数据卷 用于pod中的数据的持久化存储 支持很多的卷…...

2024西安铁一中集训DAY27 ---- 模拟赛((bfs,dp) + 整体二分 + 线段树合并 + (扫描线 + 线段树))
文章目录 前言时间安排及成绩题解A. 倒水(bfs dp)B. 让他们连通(整体二分 按秩合并并查集 / kruskal重构树)C. 通信网络(线段树合并 二分)D. 3SUM(扫描线 线段树) 前言 T1没做出…...

STM32F401VET6 PROTEUS8 ILI9341 驱动显示及仿真
stm32cubemx新建工程代码,并生成工程 设置gpio 设置SPI 其他的参考stm32默认设置 然后编辑驱动代码 ili9341.h #ifndef ILI9341_H #define ILI9341_H#include <stdbool.h> #include <stdint.h>#include "glcdfont.h" #include "stm32…...

抖音视频素材网站有哪些?非常好用的5个抖音视频素材库分享
在打造引人入胜的抖音视频时,选择高品质的视频素材至关重要。优选的素材不仅能够显著提升视频的吸引力,还能让你的作品在众多视频中突出重围。对于抖音创作者而言,让我们探索一些备受推崇的视频素材平台,帮助你制作出既专业又引人…...

【数据结构】链式二叉树的实现和思路分析及二叉树OJ
【数据结构】链式二叉树的实现和思路分析及二叉树OJ 🔥个人主页:大白的编程日记 🔥专栏:数据结构 文章目录 【数据结构】链式二叉树的实现和思路分析及二叉树OJ前言一.链式二叉树的定义及结构二.链式二叉树的遍历2.1前序遍历2.2中…...
项目成功秘诀:工单管理系统如何加速进程
国内外主流的10款项目工单管理系统对比:PingCode、Worktile、浪潮云工单管理系统、华为企业智能工单系统、金蝶云苍穹、紫光软件管理系统、Jira、Asana、ServiceNow、Smartsheet。 在管理日益复杂的个人项目时,找到一款能够真正符合需求的管理软件&#…...

OpenGauss和GaussDB有何不同
OpenGauss和GaussDB是两个不同的数据库产品,它们都具有高性能、高可靠性和高可扩展性等优点,但是它们之间也有一些区别和相似之处。了解它们之间的关系、区别、建议、适用场景和如何学习,对于提高技能和保持行业敏感性非常重要。本文将深入探…...
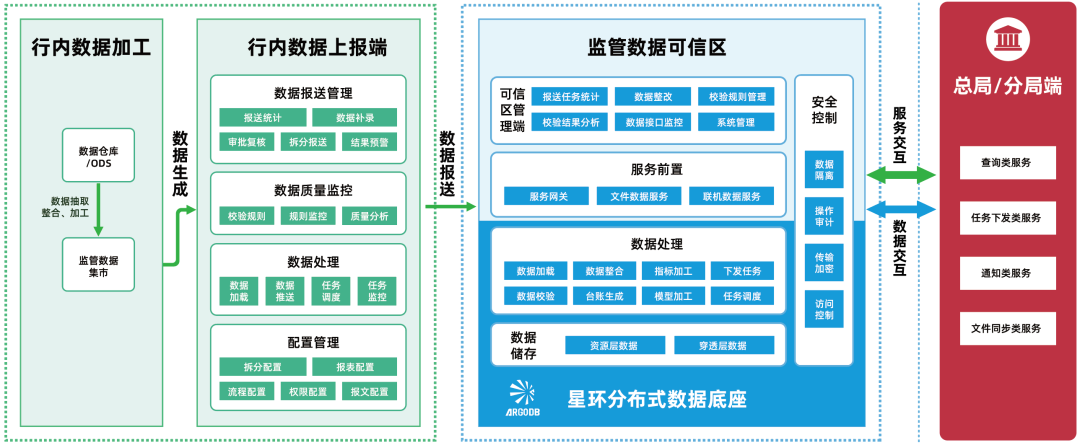
星环科技携手东华软件推出一表通报送联合解决方案
随着国家金融监督管理总局“一表通”试点工作的持续推进,星环科技携手东华软件推出了基于星环科技分布式分析型数据库ArgoDB和大数据基础平台TDH的一表通报送联合解决方案,并已在多地实施落地中得到充分验证。 星环科技与东华软件作为战略合作伙伴&…...

YOLOv10环境搭建、训练自己的目标检测数据集、实际验证和测试
1 环境搭建 1.1 在官方仓库的给定的使用python3.9版本,则使用conda创建对应虚拟环境。 conda create -n yolov10 python3.9 1.2 切换到对应虚拟环境 conda activate yolov10 1.3 在指定目录下克隆yolov10官方仓库代码 git clone https://github.com/THU-MIG/yo…...

Harmony Next -- 通用标题栏:高度自定义,可设置沉浸式状态,正常状态下为:左侧返回、居中标题,左中右均可自定义视图。
hm_common_title_bar OpenHarmony三方库中心仓:https://ohpm.openharmony.cn/#/cn/detail/common_title_bar 介绍 一款通用标题栏,支持高度自定义,可设置沉浸式状态,正常状态下为:左侧返回、居中标题,左…...

甄选范文“论数据分片技术及其应用”软考高级论文,系统架构设计师论文
论文真题 数据分片就是按照一定的规则,将数据集划分成相互独立、正交的数据子集,然后将数据子集分布到不同的节点上。通过设计合理的数据分片规则,可将系统中的数据分布在不同的物理数据库中,达到提升应用系统数据处理速度的目的。 请围绕“论数据分片技术及其应用”论题…...

【elementui】记录el-table设置左、右列固定时,加大滚动条宽度至使滚动条部分被固定列遮挡的解决方法
当前elementui版本:2.8.2 现象:此处el-table__body-wrapper默认的滚动条宽度为8px,我加大到10px,如果不设置fixed一切正常,设置fixed后会被遮挡一点 el-table__fixed-right::before, .el-table__fixed::before 设置…...

Python人工智能:一、语音合成和语音识别
在Python中,语音合成(Text-To-Speech, TTS)和语音识别(Speech-To-Text, STT)是两个非常重要的功能,它们在人工智能、自动化、辅助技术以及许多其他领域都有广泛的应用。下面将分别介绍这两个领域在Python中…...

C/C++进阶 (8)哈希表(STL)
个人主页:仍有未知等待探索-CSDN博客 专题分栏:C 本文着重于模拟实现哈希表,并非是哈希表的使用。 实现的哈希表的底层用的是线性探测法,并非是哈希桶。 目录 一、标准库中的哈希表 1、unordered_map 2、unordered_set 二、模…...
2024电赛H题参考方案(+视频演示+核心控制代码)——自动行驶小车
目录 一、题目要求 二、参考资源获取 三、TI板子可能用到的资源 1、环境搭建及工程移植 2、相关模块的移植 四、控制参考方案 1、整体控制方案视频演示 2、视频演示部分核心代码 五、总结 一、题目要求 小编自认为:此次控制类类型题目的H题,相较于往年较…...

设计模式14-享元模式
设计模式14-享元模式 由来动机定义与结构代码推导特点享元模式的应用总结优点缺点使用享元模式的注意事项 由来动机 在很多应用中,可能会创建大量相似对象,例如在文字处理器中每个字符对象。在这些场景下,如果每个对象都独立存在,…...

Javascript中canvas与svg详解
Canvas 在JavaScript中,<canvas> 元素用于在网页上绘制图形,如线条、圆形、矩形、图像等。它是一个通过JavaScript和HTML的<canvas>元素来工作的绘图表面。<canvas> 元素自身并不具备绘图能力,它仅仅提供了一个绘图环境&a…...

Taotoken API密钥的精细化权限管理与审计日志价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API密钥的精细化权限管理与审计日志价值 在将大模型能力集成到实际业务的过程中,API密钥的管理往往从一个简单…...

Codeforces Round 1055
codeforces1055实况 https://www.bilibili.com/video/BV1MdxnzdErn/ Codeforces-1055 jiangly 许淇文 StarSilk tourist 王茂骅 排名演变 https://www.bilibili.com/video/BV1CyxJz5EBB/ Codeforces Round 1055 (Div. 12) A~E 思路代码讲解 https://www.bilibili.com/video/BV1…...
)
告别OnlyOffice限制!用Alist+KkFileView搭建全能文件预览中心(支持CAD/PSD/ZIP)
突破文件预览瓶颈:AlistKkFileView全格式支持实战指南 你是否曾因AlistOnlyOffice无法预览CAD图纸而焦头烂额?或是面对团队发来的PSD设计稿只能干瞪眼?这套组合方案虽能解决基础办公文档需求,但遇到专业格式就束手无策。本文将带你…...

FSearch技术深度解析:如何用C语言和GTK3实现毫秒级文件搜索
FSearch技术深度解析:如何用C语言和GTK3实现毫秒级文件搜索 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 在Linux生态系统中,文件搜索一直是…...

3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南
3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?每次重装系统或安装Office…...

Creality Print:从新手到专家的完整3D打印切片软件指南
Creality Print:从新手到专家的完整3D打印切片软件指南 【免费下载链接】CrealityPrint 项目地址: https://gitcode.com/gh_mirrors/cr/CrealityPrint 在3D打印的世界里,切片软件是连接数字模型与物理实体的关键桥梁。无论您刚刚接触3D打印&…...

HCIP-Datacom Core Technology V1.0_18 IGMP原理与配置
IGMP用于接收者和直连组播路由之间,建立和维护组播成员关系的组播协议,本章课程将介绍IGMP的原理,以及它不同版本的区别,还有一些其它特性。IGMP介绍组播网络的转发困境正常情况下,组播源将组播报文推送给第一跳路由器…...

Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用
Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款基于hidapi库开发的开源手柄控制框架,专为任天堂Jo…...

魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题
魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还记得那个曾经风靡全球的《魔…...

终极指南:macOS百度网盘限速破解与SVIP解锁完整教程
终极指南:macOS百度网盘限速破解与SVIP解锁完整教程 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否厌倦了在macOS上使用百度网盘时那…...