Spark SQL函数定义【博学谷学习记录】
1 如何使用窗口函数
窗口函数格式:
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
学习的相关分析函数有那些?
第一类: row_number() rank() dense_rank() ntile()
第二类: 和聚合函数组合使用 sum() avg() max() min() count()
第三类: lag() lead() first_value() last_value()
SQL中: 与HIVE中应用基本没啥区别, 更多关注的是DSL写法
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql import Window as win
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("演示: 如何在Spark SQL中使用窗口函数...")# 1- 创建SparkSession对象spark = SparkSession.builder.appName('df_write').master('local[*]').getOrCreate()# 2-读取外部文件的数据df = spark.read.csv(path='file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/pv.csv',header=True,inferSchema=True)df.createTempView('t1')# 3- 执行相关的操作# 需要: 统计每个cookie中, pv数量排名前二内容是哪些? (分组TOPN 问题)# SQLspark.sql("""with t2 as(select*,row_number() over (partition by cookieid order by pv desc) as rank1from t1 )select * from t2 where rank1 <=2""").show()# DSL:df.select('*',F.row_number().over(win.partitionBy('cookieid').orderBy(F.desc('pv'))).alias('rank1')).where('rank1 <= 2').show()2 SQL函数的分类说明
整个SQL函数, 主要是分为以下三大类:
UDF函数: 用户自定义函数
表示: 一进一出
整个函数中, 大多数的函数都是属于一进一出的函数: split() substr()
UDAF函数: 用户自定义聚合函数
表示: 多进一出
例如: sum() avg() count() ….
UDTF函数: 用户自定义表生成函数
表示: 一进多出
指的: 进去一行数据, 最终产生多行 或者多列的数据
例如: explode
在SQL中提供的内置函数, 都是属于以上三类中某一类函数
思考: 提供了那么多的函数, 为啥还需要自定义函数呢?
扩充函数. 在实际使用中, 并不能保证所有的操作可能用的函数都已经提前的内置好, 尤其是很多具有特殊业务处理功能, 其实并没有相对应函数 , 提供的函数更多是以公共的功能为主函数, 此时需要进行自定义, 从而扩充新的功能
在Spark SQL中, 对于自定义函数, 原生支持的粒度并不是特别好, 目前原生的PY方案仅支持自定义UDF函数, 无法自定义UDAF函数和UDTF函数, 在1.6版本之后, Java 和scala语言支持了自定义UDAF函数,但是Python并不支持,Spark官方提供了解决的方案: 基于pandas来自定义UDF 和 UDAF函数. 但是对于UDTF函数, Spark是不支持自定义,但是Spark支持HIVE的函数定义, 所以可以通过HIVE自定义函数来解决
虽然Python支持自定义UDF函数, 但是其效率并不是特别的高效, 因为在使用的时候, 传递一行处理一行, 返回一行的操作, 这样会带来非常大的序列化开销问题, 以及网络开销问题, 导致原生UDF函数效率不好
早期解决方案: 基于 scala/Java来编写自定义UDF函数, 然后基于Python使用即可
目前主要解决方案: 引入Arrow框架, 可以基于内存来完成数据传输工作, 可以大大降低了序列化开销问题, 提供传输的效率, 解决了原生问题, 同时还可以基于pandas的自定义函数, 利用pandas函数优势, 完成各种处理操作
所以后期主推的方案: 基于pandas 自定义函数, 然后底层基于arrow完成数据传输工作
3 Spark SQL原生自定义函数
第一步: 在Python中创建一个python的函数, 在这个函数中书写自定义函数的功能逻辑代码即可
第二步: 将Python函数注册到Spark SQL中, 成为Spark SQL的函数
注册方式一: udf对象 = sparkSession.udf.register(参数1,参数2,参数3)
参数1: UDF函数的名称, 此名称用于后续在SQL语法中使用 , 可以任意定义名称, 但是要符合定义名称规范
参数2: python函数的名称, 表示将哪个python的函数注册为Spark SQL的函数
参数3: 返回值的类型, 用于表示当前这个Python的函数返回的类型对应的Spark SQL的数据类型
udf对象: 此对象主要是用于DSL中
注册方式二: udf对象 = F.udf(参数1,参数2)
参数1: python函数的名称, 表示将哪个python的函数注册为Spark SQL的函数
参数2: 返回值的类型, 用于表示当前这个Python的函数返回的类型对应的Spark SQL的数据类型
udf对象: 此对象主要是用于DSL中
说明: 此种方式还支持语法糖写法: @F.udf(returnType=返回值类型) 需要放置到对应函数上面
第三步: 在Spark SQL的DSL/SQL中进行使用即可
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("演示原生的自定义函数:")# 1- 创建SparkSession对象spark = SparkSession.builder.appName('df_write').master('local[*]').getOrCreate()# 2- 初始化一些数据df = spark.createDataFrame(data=[(1,'张三','北京'),(2,'李四','上海'),(3,'王五','广州'),(4,'赵六','深圳'),(5,'田七','杭州')],schema='id int,name string,address string')df.createTempView('t1')# 3- 执行相关的操作:# 请自定义一个函数, 完成对数据统一添加一个后缀名的操作# 3.1 定义一个Python的函数, 接收一个数据, 给数据添加一个后缀返回@F.udf(returnType=StringType())def add_post(data):return data+'_boxuegu'# 3.2 对函数进行注册操作# 注册方式一# 当采用注解方式注册函数的使用, 如果依然想在SQL中使用, 可以再次使用方式一注册,但是不需要设置返回值类型了spark.udf.register('add_post_sql',add_post)# 注册方式二: 还有一种语法糖模式#add_post_dsl = F.udf(add_post,StringType())# 3.3 使用自定义函数# SQLspark.sql("""select*,add_post_sql(address) as r1from t1""").show()# DSLdf.select('*',add_post('address').alias('r1')).show()相关文章:

Spark SQL函数定义【博学谷学习记录】
1 如何使用窗口函数窗口函数格式:分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])学习的相关分析函数有那些? 第一类: row_number() rank() dense_rank() ntile()第二类: 和聚合函数组合使用 sum() avg() max() min() count()第三类: la…...
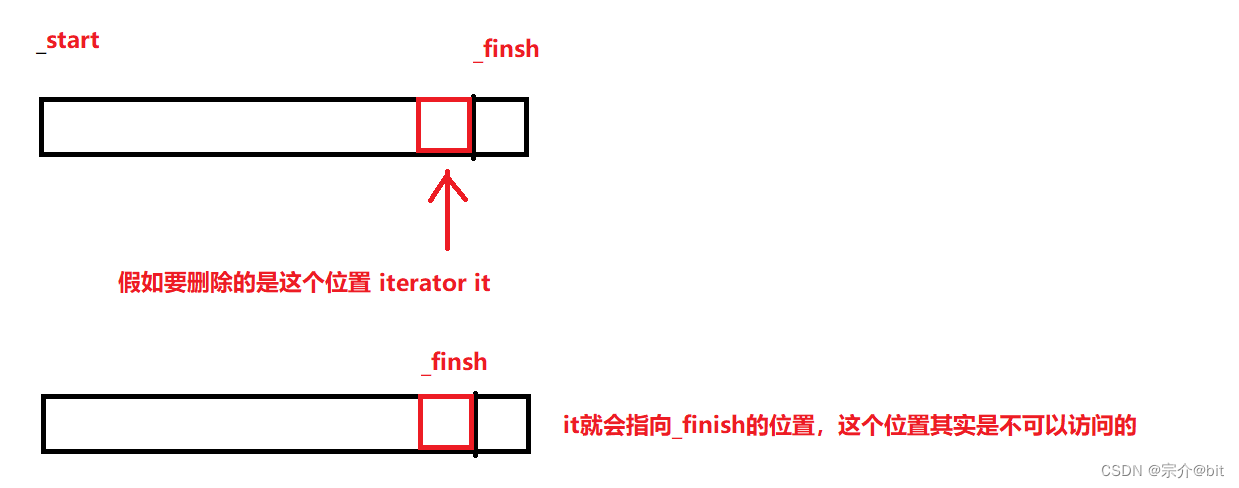
模拟实现STL容器之vector
文章目录前言1.大体思路2.具体代码实现1.类模板的创建2.构造函数1.无参构造2.拷贝构造 迭代器构造和给定n个val值构造以及析构函数3.空间扩容1.reserve2.resize4.操作符重载1.[ ]重载2.赋值运算符重载5.数据增加和删除1.尾插2.任意位置插入3.任意位置删除4.尾删6.一些其他接口3…...

ChatGPT-4.0 : 未来已来,你来不来
文章目录前言ChatGPT 3.5 介绍ChatGPT 4.0 介绍ChatGPT -4出逃计划!我们应如何看待ChatGPT前言 好久没有更新过技术文章了,这个周末听说了一个非常火的技术ChatGPT 4.0,于是在闲暇之余我也进行了测试,今天这篇文章就给大家介绍一…...
)
Java反射(详细学习笔记)
Java反射 1. Java反射机制概述 Reflection(反射)是java被视为java动态语言的关键,反射机制允许程序在执行期间借助于Reflection API获取任何类的内部信息,并能直接操作任意对象的内部属性及方法。 Class c Class.forName(&quo…...
学习 Python 之 Pygame 开发魂斗罗(十二)
学习 Python 之 Pygame 开发魂斗罗(十二)继续编写魂斗罗1. 修改玩家扣减生命值2. 解决玩家下蹲子弹不会击中玩家而是直接让玩家死亡的问题3. 完善地图4. 增加产生敌人函数,解决一直产生敌人的问题5. 给玩家类增加计算玩家中心的方法继续编写魂…...

Linux下字符设备驱动开发以及流程介绍
文章目录1 - 字符设备介绍2 - 字符设备开发流程图3 - 字符设备开发流程具体讲解(1)设备编号的定义与申请【1】Linux主次设备号介绍【2】分配设备编号【3】释放主次设备号(2)定义file_operations结构体-初始化接口函数(…...

Web自动化框架断言方法实现
前言1、设计用例方法关键字1.1、获取元素属性值2.1、断言2、代码实现2.1、实现获取元素属性值2.1.1 函数实现2.1.2 方法配置2.1.2 用例调试2.1.3 html属性2.2、实现断言2.2.1 函数2.2.2 方法配置2.2.3 用例调试1)断言结果成功2)断言结果失败前言 本文的…...

8大核心语句,带你深入python
人生苦短 我用python 又来给大家整点好东西啦~ 咱就直接开练噜!内含大量代码配合讲解 python 安装包资料:点击此处跳转文末名片获取 1. for - else 什么?不是 if 和 else 才是原配吗? No,你可能不知道, else 是个…...

【批处理】- 批处理自动安装Mysql与Redis
前言 在全新环境中安装MySQL与Redis操作是挺麻烦的,于是就想使用脚本来自动安装,使用批处理进行一步到位的安装,后面还能使用工具进行打包成exe可执行文件,一键安装,最后能够更好的部署项目到windows系统的服务器。 …...

聊聊华为的工作模式
目录 一、试用期与加班工资 二、招聘 三、月度答辩和转正答辩 四、可信考试认证 五、接口人 六、问题缺陷单 七、代码检视 八、功能开发 九、出征海外 一、试用期与加班工资 一般而言,试用期持续的时间为3-6个月,工资、奖金都按正式员工的标准…...

燕山大学-面向对象程序设计实验-实验6 派生与继承:多重派生-实验报告
CSDN的各位友友们你们好,今天千泽为大家带来的是燕山大学-面向对象程序设计实验-实验5 派生与继承:单重派生-实验报告,接下来让我们一起进入c的神奇小世界吧,相信看完你也能写出自己的 实验报告!本系列文章收录在专栏 燕山大学面向对象设计报告中 ,您可以在专栏中找…...

分割两个字符串得到回文串[抽象--去除具体个性取共性需求]
抽象前言一、分割两个字符串得到回文串二、双指针总结参考文献前言 抽象去个性留共性,是因为具体个性对于解决问题是个累赘。少了累赘,直击需求,才能进行问题转换或者逻辑转换。 一、分割两个字符串得到回文串 二、双指针 // 限定死了&…...

【LeetCode】1609. 奇偶树、1122. 数组的相对排序
作者:小卢 专栏:《Leetcode》 喜欢的话:世间因为少年的挺身而出,而更加瑰丽。 ——《人民日报》 1609. 奇偶树 1609. 奇偶树 题目描述: 如果一棵二叉树满足下述几个条件&#x…...

【C++初阶】4. Date类的实现
如果下面博客有不理解的地方,可以查看源码:代码提交:日期类的实现 1. 构造函数的实现 由于系统实现的默认构造函数即便采用默认值的形式也只能存在1个固定的默认日期(例如:1997-1-1)。所以,构…...

ES6新特性--变量声明
可以使用let关键字来声明变量let a;let b,c;//同时声明多个变量let stu = 张三;let name =李四,age = 12;//声明变量的同时赋值 let关键字使用的注意事项(1).变量在声明的时候不可以重复,这也符合其他语言的变量声明规范 let name = 李四; let name = 张三;//这里开始报错,但…...

【Django】缓存机制
文章目录缓存的介绍Django的6种缓存方式开发调试缓存dummy.DummyCache内存缓存locmem.LocMemCache文件缓存filebased.FileBasedCache⭐️数据库缓存db.DatabaseCacheMemcache缓存memcached.MemcachedCacheMemcache缓存memcached.PyLibMCCacheDjango缓存的应用内存缓存cache_pag…...
我的创作纪念日——一年的时间可以改变很多
机缘 不知不觉来到CSDN已经创作一年了。打心底讲,对于在CSDN开始坚持创作的原因,我用一句话来概括最合适不过了——“无心插柳柳成荫” 为什么这么说呢? 这要从我的一篇博客说起——《输入命令Javac报错详解》: 那也是我第一次…...
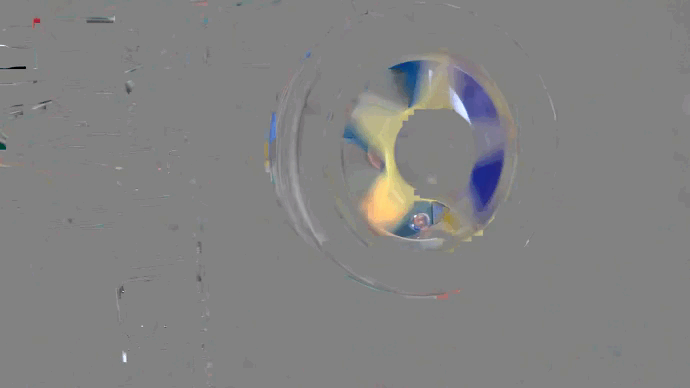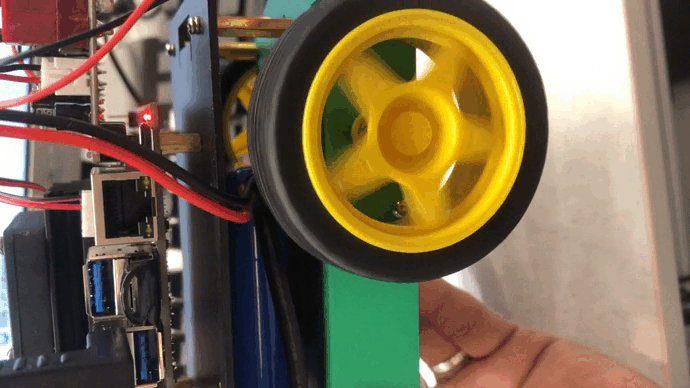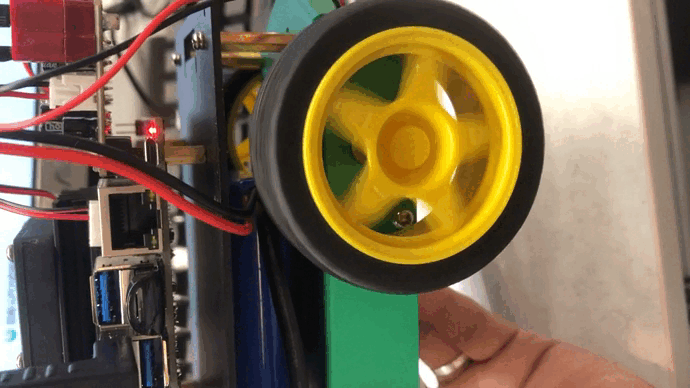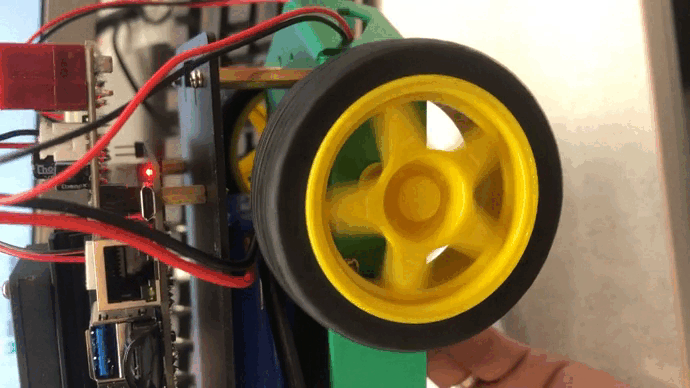
Jetson Nano驱动机器人的左右两路电机
基于Jetson Nano板子搭建一个无人车,少不了减速电机驱动轮子滚动,那如何驱动呢?从Jetson.GPIO库文件来说,里面没有支持产生PWM的引脚,也就意味着Jetson nano没有硬件产生PWM的能力,所以我们不得不使用别的方…...

如何通过openssl生成公钥和私钥?
1、生成RSA秘钥的方法 生成RSA秘钥的方法: openssl genrsa -des3 -out privkey.pem 2048 注:建议用2048位秘钥,少于此可能会不安全或很快将不安全。 这个命令会生成一个2048位的秘钥,同时有一个des3方法加密的密码,…...
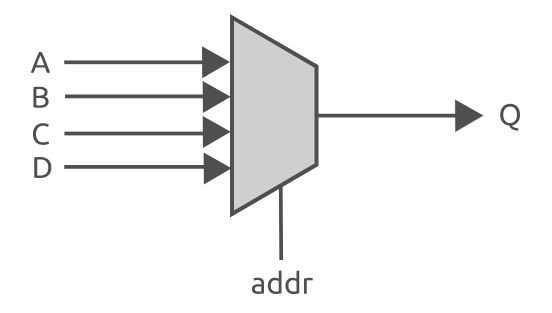
Verilog的If语句和Case语句
这篇文章将讨论 verilog 中两个最常用的结构----if语句和case语句。在之前的文章中学习了如何使用过程块(例如always块)来编写按顺序执行的verilog 代码。此外还可以在过程块中使用许多语句----统称为顺序语句,如case 语句和 if 语句。这篇文…...

5个专业级步骤:DriverStore Explorer驱动管理工具解决Windows系统稳定性难题
5个专业级步骤:DriverStore Explorer驱动管理工具解决Windows系统稳定性难题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 问题剖析:为什么常规方法无法解决驱…...
为啥是5G/雷达系统的核心)
从MIMO到相控阵:深入浅出聊聊RFSoC的MTS(多片同步)为啥是5G/雷达系统的核心
从MIMO到相控阵:深入浅出聊聊RFSoC的MTS(多片同步)为啥是5G/雷达系统的核心 在5G Massive MIMO基站的天线阵列背后,或是军用雷达的相控阵天线系统中,数以百计的射频收发通道需要像精密交响乐团般协同工作——任何微小的…...
)
Flowable6.4实战:如何优雅处理并行网关驳回与多实例加减签(附完整代码)
Flowable 6.4实战:并行网关驳回与多实例加减签的工程化解决方案 在企业级流程审批系统中,并行任务处理和多实例任务动态调整是高频需求场景。当某部门采购申请需要同时经过财务审核、法务审核和业务负责人审核时,传统串行审批模式会导致效率…...
)
保姆级教程:在若依框架里给你的系统加个AI客服(通义千问+流式响应)
企业级智能客服系统集成实战:若依框架与通义千问的完美结合 1. 智能客服系统架构设计 在当今数字化转型浪潮中,智能客服已成为企业提升服务效率、降低人力成本的关键工具。基于若依框架与通义千问构建的智能客服系统,能够无缝集成到现有企业应…...
:5天打造跨平台Galgame播放器《Galplayer》——从脚本解析到电影式体验)
【游戏引擎之路】极速狂飙(一):5天打造跨平台Galgame播放器《Galplayer》——从脚本解析到电影式体验
1. 极速开发背后的技术选型 开发《Galplayer》最疯狂的地方在于,我只用了5天就完成了从零到可运行版本的开发。这听起来像天方夜谭,但合理的工具链选择让这一切成为可能。我选择了WPFPythonUnity这个"三件套"组合,每个工具都发挥了…...

TX12 + ExpressLRS 915MHz RC链路优化与EdgeTX固件升级实战
1. 为什么选择TX12搭配ExpressLRS 915MHz系统 玩无人机的朋友都知道,遥控链路就像风筝线,距离和稳定性直接决定飞行体验。我之前用2.4GHz的RadioLink套装,飞到500米就开始心跳加速——信号时断时续,每次返航都像在赌运气。换成TX1…...

IP离线库每周更新一次够用吗?企业风控建议多久更新?
在风控体系中,IP数据的时效性直接决定了拦截效果。当攻击者使用秒拨IP或住宅代理发起攻击时,IP地址的轮换速度可以达到分钟级。如果依赖的IP库更新周期过长,就等于在防御上留下了数天的空窗期。 周更不够用。秒拨IP平均存活3-5分钟ÿ…...

AI率降完又反弹原因在这里解决方案也在
论文AI率降到15%,隔了一周再测,又变成了24%。 这个情况不是你的错,也不是工具骗你,而是有几个实际原因导致的。这篇文章解释清楚原因,然后给解决方案。 AI率反弹的3个真实原因 原因一:检测系统更新了 这…...

Radiant Player媒体键集成:揭秘硬件控制背后的技术
Radiant Player媒体键集成:揭秘硬件控制背后的技术 【免费下载链接】radiant-player-mac :notes: Turn Google Play Music into a separate, beautiful application that integrates with your Mac. 项目地址: https://gitcode.com/gh_mirrors/ra/radiant-player-…...

关于爬虫源影视资源设置
1.首先目前的omnibox的版本已更新到2.0.3版本,之前的配置会丢失,原本的资源都会无法使用,这里以新版本增加数据源,看完以下教程再下载脚本。 2.添加爬虫源,这里以猫眼资源为主测试: 增加脚本之后,点击保存即可! 复制以下脚本,修复改site_api即可,一般公用的资源都是正…...