ElasticSearch-第四天
目录
ElasticSearch文档分值_score计算底层原理
relevance score算法
Term frequency
Inverse document frequency
Field-length norm
分析一个document上的_score是如何被计算出来的
分词器工作流程
切分词语
内置分词器的介绍
定制分词器
ik分词器详解
IK分词器自定义词库
IK热更新
高亮显示
聚合搜索技术深入
bucket和metric概念简介
准备案例数据
聚合操作案例
histogram 区间统计
date_histogram区间分组
_global bucket
aggs+order
search+aggs
filter+aggs
聚合中使用filter
ElasticSearch文档分值_score计算底层原理
relevance score算法
简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency
搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
示例:doc1出现了2次
搜索请求:hello worlddoc1:hello you, and world is very gooddoc2:hello, how are youInverse document frequency
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
示例:
搜索请求:hello worlddoc1:hello, tuling is very gooddoc2:hi world, how are you比如说,在index中有1万条document,hello这个单词在所有的document中,一共出现了1000次;world这个单词在所有的document中,一共出现了100次,那么hello的相关性就比较低了
Field-length norm
field长度,field越长,相关度越弱
搜索请求:hello world
doc1:{ "title": "hello article", "content": "...... N个单词" }
doc2:{ "title": "my article", "content": "...... N个单词,hi world" }hello world在整个index中出现的次数是一样多的,doc1更相关,title field更短
分析一个document上的_score是如何被计算出来的
GET /es_db/_doc/1/_explain
{"query": {"match": {"remark": "java developer"}}
}分词器工作流程
切分词语
给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行normalization(时态转换,单复数转换),分词器recall,召回率:搜索的时候,增加能够搜索到的结果的数量
character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(<span>hello<span> --> hello),& --> and(I&you --> I and you)
tokenizer:分词,hello you and me --> hello, you, and, me
token filter:lowercase,stop word,synonymom,liked --> like,Tom --> tom,a/the/an --> 干掉,small --> little大体步骤:过滤->分词->转换
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引
内置分词器的介绍
Set the shape to semi-transparent by calling set_trans(5)standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, transwhitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)stop analyzer:移除停用词,比如a the it等等测试:
POST _analyze
{
"analyzer":"standard",
"text":"Set the shape to semi-transparent by calling set_trans(5)"
}定制分词器
1)默认的分词器
standard
- standard tokenizer:以单词边界进行切分
- standard token filter:什么都不做
- lowercase token filter:将所有字母转换为小写
- stop token filer(默认被禁用):移除停用词,比如a the it等等
2)修改分词器的设置
启用english停用词token filter
PUT /my_index
{"settings": {"analysis": {"analyzer": {"es_std": {"type": "standard","stopwords": "_english_"}}}}
}GET /my_index/_analyze
{"analyzer": "standard","text": "a dog is in the house"
}GET /my_index/_analyze {"analyzer": "es_std","text": "a dog is in the house"
}3、 定制化自己的分词器PUT /my_index
{"settings": {"analysis": {"char_filter": {"&_to_and": {"type": "mapping","mappings": ["&=> and"]}},"filter": {"my_stopwords": {"type": "stop","stopwords": ["the", "a"]}},"analyzer": {"my_analyzer": {"type": "custom","char_filter": ["html_strip", "&_to_and"],"tokenizer": "standard","filter": ["lowercase", "my_stopwords"]}}}}
}GET /my_index/_analyze
{"text": "tom&jerry are a friend in the house, <a>, HAHA!!","analyzer": "my_analyzer"
}PUT /my_index/_mapping/my_type
{"properties": {"content": {"type": "text","analyzer": "my_analyzer"}}
}大体就是定义char-filter,filter以及自定义分词器,将定义的char-filter和filter定义到自定义分词器中
ik分词器详解
- ik配置文件地址:es/plugins/ik/config目录
- IKAnalyzer.cfg.xml:用来配置自定义词库
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
- quantifier.dic:放了一些单位相关的词
- suffix.dic:放了一些后缀
- surname.dic:中国的姓氏
- stopword.dic:英文停用词
ik原生最重要的两个配置文件
- main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
- stopword.dic:包含了英文的停用词
停用词,stopword:a the and at but
一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中
IK分词器自定义词库
(1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里
- 自己补充自己的最新的词语,到ik的词库里面去
- IKAnalyzer.cfg.xml:ext_dict,custom/mydict.dic
- 补充自己的词语,然后需要重启es,才能生效
(2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索
custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es
IK分词器源码下载:https://github.com/medcl/elasticsearch-analysis-ik/tree
IK热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
IKAnalyzer.cfg.xml
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">location</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">location</entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">words_location</entry> <!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">words_location</entry>
</properties>高亮显示
在搜索中,经常需要对搜索关键字做高亮显示,高亮显示也有其常用的参数,在这个案例中做一些常用参数的介绍。
现在搜索cars索引中remark字段中包含“大众”的document。并对“XX关键字”做高亮显示,高亮效果使用html标签,并设定字体为红色。如果remark数据过长,则只显示前20个字符。
UT /news_website
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word"}}}}PUT /news_website
{"settings" : {"index" : {"analysis.analyzer.default.type": "ik_max_word"}}
}PUT /news_website/_doc/1
{"title": "这是我写的第一篇文章","content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
}GET /news_website/_doc/_search
{"query": {"match": {"title": "文章"}},"highlight": {"fields": {"title": {}}}
}{"took" : 458,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.2876821,"hits" : [{"_index" : "news_website","_type" : "_doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "我的第一篇文章","content" : "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"},"highlight" : {"title" : ["我的第一篇<em>文章</em>"]}}]}
}<em></em>表现,会变成红色,所以说你的指定的field中,如果包含了那个搜索词的话,就会在那个field的文本中,对搜索词进行红色的高亮显示GET /news_website/_doc/_search
{"query": {"bool": {"should": [{"match": {"title": "文章"}},{"match": {"content": "文章"}}]}},"highlight": {"fields": {"title": {},"content": {}}}
}highlight中的field,必须跟query中的field一一对齐的2、常用的highlight介绍plain highlight,lucene highlight,默认posting highlight,index_options=offsets(1)性能比plain highlight要高,因为不需要重新对高亮文本进行分词
(2)对磁盘的消耗更少DELETE news_website
PUT /news_website
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word","index_options": "offsets"}}}
}PUT /news_website/_doc/1
{"title": "我的第一篇文章","content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
}GET /news_website/_doc/_search
{"query": {"match": {"content": "文章"}},"highlight": {"fields": {"content": {}}}
}fast vector highlightindex-time term vector设置在mapping中,就会用fast verctor highlight(1)对大field而言(大于1mb),性能更高delete /news_websitePUT /news_website
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word","term_vector" : "with_positions_offsets"}}}
}强制使用某种highlighter,比如对于开启了term vector的field而言,可以强制使用plain highlightGET /news_website/_doc/_search
{"query": {"match": {"content": "文章"}},"highlight": {"fields": {"content": {"type": "plain"}}}
}总结一下,其实可以根据你的实际情况去考虑,一般情况下,用plain highlight也就足够了,不需要做其他额外的设置
如果对高亮的性能要求很高,可以尝试启用posting highlight
如果field的值特别大,超过了1M,那么可以用fast vector highlight3、设置高亮html标签,默认是<em>标签GET /news_website/_doc/_search
{"query": {"match": {"content": "文章"}},"highlight": {"pre_tags": ["<span color='red'>"],"post_tags": ["</span>"], "fields": {"content": {"type": "plain"}}}
}4、高亮片段fragment的设置GET /_search
{"query" : {"match": { "content": "文章" }},"highlight" : {"fields" : {"content" : {"fragment_size" : 150, "number_of_fragments" : 3 }}}
}fragment_size: 你一个Field的值,比如有长度是1万,但是你不可能在页面上显示这么长啊。。。设置要显示出来的fragment文本判断的长度,默认是100
number_of_fragments:你可能你的高亮的fragment文本片段有多个片段,你可以指定就显示几个片段
聚合搜索技术深入
bucket和metric概念简介
- bucket就是一个聚合搜索时的数据分组。如:销售部门有员工张三和李四,开发部门有员工王五和赵六。那么根据部门分组聚合得到结果就是两个bucket。销售部门bucket中有张三和李四,开发部门 bucket中有王五和赵六。
- metric就是对一个bucket数据执行的统计分析。如上述案例中,开发部门有2个员工,销售部门有2个员工,这就是metric。
metric有多种统计,如:求和,最大值,最小值,平均值等。
用一个大家容易理解的SQL语法来解释,如:select count(*) from table group by column。那么group by column分组后的每组数据就是bucket。对每个分组执行的count(*)就是metric。
准备案例数据
PUT /cars
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}POST /cars/_bulk
{ "index": {}}
{ "price" : 258000, "color" : "金色", "brand":"大众", "model" : "大众迈腾", "sold_date" : "2021-10-28","remark" : "大众中档车" }
{ "index": {}}
{ "price" : 123000, "color" : "金色", "brand":"大众", "model" : "大众速腾", "sold_date" : "2021-11-05","remark" : "大众神车" }
{ "index": {}}
{ "price" : 239800, "color" : "白色", "brand":"标志", "model" : "标志508", "sold_date" : "2021-05-18","remark" : "标志品牌全球上市车型" }
{ "index": {}}
{ "price" : 148800, "color" : "白色", "brand":"标志", "model" : "标志408", "sold_date" : "2021-07-02","remark" : "比较大的紧凑型车" }
{ "index": {}}
{ "price" : 1998000, "color" : "黑色", "brand":"大众", "model" : "大众辉腾", "sold_date" : "2021-08-19","remark" : "大众最让人肝疼的车" }
{ "index": {}}
{ "price" : 218000, "color" : "红色", "brand":"奥迪", "model" : "奥迪A4", "sold_date" : "2021-11-05","remark" : "小资车型" }
{ "index": {}}
{ "price" : 489000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A6", "sold_date" : "2022-01-01","remark" : "政府专用?" }
{ "index": {}}
{ "price" : 1899000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A 8", "sold_date" : "2022-02-12","remark" : "很贵的大A6。。。" }聚合操作案例
根据color分组统计销售数量
只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于SQL中的count。
在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用_key元数据,根据分组后的字段数据执行不同的排序方案,也可以根据_count元数据,根据分组后的统计值执行不同的排序方案。
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
}
}
}
}统计不同color车辆的平均价格
本案例先根据color执行聚合分组,在此分组的基础上,对组内数据执行聚合统计,这个组内数据的聚合统计就是metric。同样可以执行排序,因为组内有聚合统计,且对统计数据给予了命名avg_by_price,所以可以根据这个聚合统计数据字段名执行排序逻辑。
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price": "asc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}size可以设置为0,表示不返回ES中的文档,只返回ES聚合之后的数据,提高查询速度,当然如果你需要这些文档的话,也可以按照实际情况进行设置
GET /cars/_search
{
"size" : 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand" : {
"terms": {
"field": "brand",
"order": {
"avg_by_price": "desc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}统计不同color不同brand中车辆的平均价格
先根据color聚合分组,在组内根据brand再次聚合分组,这种操作可以称为下钻分析。
Aggs如果定义比较多,则会感觉语法格式混乱,aggs语法格式,有一个相对固定的结构,简单定义:aggs可以嵌套定义,可以水平定义。
嵌套定义称为下钻分析。水平定义就是平铺多个分组方式。
GET /index_name/type_name/_search
{
"aggs" : {
"定义分组名称(最外层)": {
"分组策略如:terms、avg、sum" : {
"field" : "根据哪一个字段分组",
"其他参数" : ""
},
"aggs" : {
"分组名称1" : {},
"分组名称2" : {}
}
}
}
}GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price_color": "asc"
}
},
"aggs": {
"avg_by_price_color" : {
"avg": {
"field": "price"
}
},
"group_by_brand" : {
"terms": {
"field": "brand",
"order": {
"avg_by_price_brand": "desc"
}
},
"aggs": {
"avg_by_price_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}统计不同color中的最大和最小价格、总价
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price" : {
"min": {
"field": "price"
}
},
"sum_price" : {
"sum": {
"field": "price"
}
}
}
}
}
}在常见的业务常见中,聚合分析,最常用的种类就是统计数量,最大,最小,平均,总计等。通常占有聚合业务中的60%以上的比例,小型项目中,甚至占比85%以上。
统计不同品牌汽车中价格排名最高的车型
在分组后,可能需要对组内的数据进行排序,并选择其中排名高的数据。那么可以使用s来实现:top_top_hithits中的属性size代表取组内多少条数据(默认为10);sort代表组内使用什么字段什么规则排序(默认使用_doc的asc规则排序);_source代表结果中包含document中的那些字段(默认包含全部字段)。
GET cars/_search
{
"size" : 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"top_car": {
"top_hits": {
"size": 1,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": {
"includes": ["model", "price"]
}
}
}
}
}
}
}histogram 区间统计
histogram类似terms,也是进行bucket分组操作的,是根据一个field,实现数据区间分组。
如:以100万为一个范围,统计不同范围内车辆的销售量和平均价格。那么使用histogram的聚合的时候,field指定价格字段price。区间范围是100万-interval : 1000000。这个时候ES会将price价格区间划分为: [0, 1000000), [1000000, 2000000), [2000000, 3000000)等,依次类推。在划分区间的同时,histogram会类似terms进行数据数量的统计(count),可以通过嵌套aggs对聚合分组后的组内数据做再次聚合分析。
GET /cars/_search
{
"aggs": {
"histogram_by_price": {
"histogram": {
"field": "price",
"interval": 1000000
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}date_histogram区间分组
date_histogram可以对date类型的field执行区间聚合分组,如每月销量,每年销量等。
如:以月为单位,统计不同月份汽车的销售数量及销售总金额。这个时候可以使用date_histogram实现聚合分组,其中field来指定用于聚合分组的字段,interval指定区间范围(可选值有:year、quarter、month、week、day、hour、minute、second),format指定日期格式化,min_doc_count指定每个区间的最少document(如果不指定,默认为0,当区间范围内没有document时,也会显示bucket分组),extended_bounds指定起始时间和结束时间(如果不指定,默认使用字段中日期最小值所在范围和最大值所在范围为起始和结束时间)。
ES7.x之前的语法
GET /cars/_search
{
"aggs": {
"histogram_by_date" : {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 1,
"extended_bounds": {
"min": "2021-01-01",
"max": "2022-12-31"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
执行后出现
#! Deprecation: [interval] on [date_histogram] is deprecated, use [fixed_interval] or [calendar_interval] in the future.7.X之后
GET /cars/_search
{
"aggs": {
"histogram_by_date" : {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 1,
"extended_bounds": {
"min": "2021-01-01",
"max": "2022-12-31"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}_global bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。
如:统计某品牌车辆平均价格和所有车辆平均价格。global是用于定义一个全局bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。
GET /cars/_search
{
"size" : 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"volkswagen_of_avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price" : {
"global": {},
"aggs": {
"all_of_price": {
"avg": {
"field": "price"
}
}
}
}
}
}aggs+order
对聚合统计数据进行排序。
如:统计每个品牌的汽车销量和销售总额,按照销售总额的降序排列。
GET /cars/_search
{
"aggs": {
"group_of_brand": {
"terms": {
"field": "brand",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}如果有多层aggs,执行下钻聚合的时候,也可以根据最内层聚合数据执行排序。
如:统计每个品牌中每种颜色车辆的销售总额,并根据销售总额降序排列。这就像SQL中的分组排序一样,只能组内数据排序,而不能跨组实现排序。
GET /cars/_search
{
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}search+aggs
聚合类似SQL中的group by子句,search类似SQL中的where子句。在ES中是完全可以将search和aggregations整合起来,执行相对更复杂的搜索统计。
如:统计某品牌车辆每个季度的销量和销售额。
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "quarter",
"min_doc_count": 1
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}filter+aggs
在ES中,filter也可以和aggs组合使用,实现相对复杂的过滤聚合分析。
如:统计10万~50万之间的车辆的平均价格。
GET /cars/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 100000,
"lte": 500000
}
}
}
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}聚合中使用filter
filter也可以使用在aggs句法中,filter的范围决定了其过滤的范围。
如:统计某品牌汽车最近一年的销售总额。将filter放在aggs内部,代表这个过滤器只对query搜索得到的结果执行filter过滤。如果filter放在aggs外部,过滤器则会过滤所有的数据。
- 12M/M 表示 12 个月。
- 1y/y 表示 1年。
- d 表示天
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"count_last_year": {
"filter": {
"range": {
"sold_date": {
"gte": "now-12M"
}
}
},
"aggs": {
"sum_of_price_last_year": {
"sum": {
"field": "price"
}
}
}
}
}
}相关文章:

ElasticSearch-第四天
目录 ElasticSearch文档分值_score计算底层原理 relevance score算法 Term frequency Inverse document frequency Field-length norm 分析一个document上的_score是如何被计算出来的 分词器工作流程 切分词语 内置分词器的介绍 定制分词器 ik分词器详解 IK分词器自…...
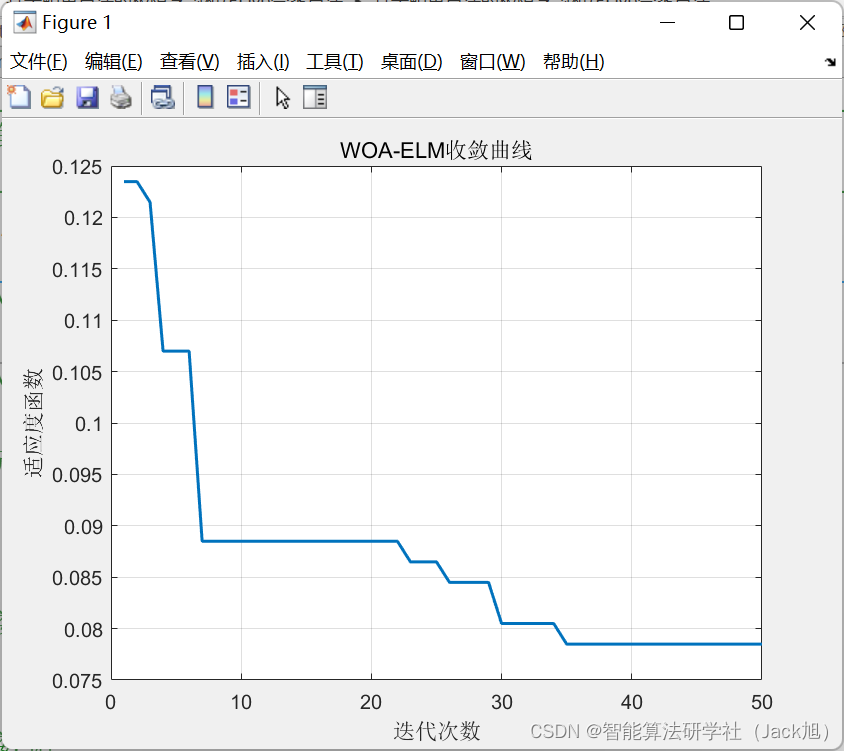
基于鲸鱼算法的极限学习机(ELM)分类算法-附代码
基于鲸鱼算法的极限学习机(ELM)分类算法 文章目录基于鲸鱼算法的极限学习机(ELM)分类算法1.极限学习机原理概述2.ELM学习算法3.分类问题4.基于鲸鱼算法优化的ELM5.测试结果6.参考文献7.Matlab代码摘要:本文利用鲸鱼算法对极限学习机进行优化,并用于分类问…...

一文彻底读懂webpack常用配置
开发环境 const webpack require("webpack"); const path require(path) module.exports {// entry: {// a: ./src/0706/a.js,// c: ./src/0706/c.js,// },entry: "./src/0707/reactDemo.js",output: {filename: [name]_dist.js,path: path.resolve(__…...

大环境不好,找工作太难?三面阿里,幸好做足了准备,已拿offer
三面大概九十分钟,问的东西很全面,需要做充足准备,就是除了概念以外问的有点懵逼了(呜呜呜)。回来之后把这些题目做了一个分类并整理出答案(强迫症的我狂补知识)分为软件测试基础、Python自动化…...
)
C++ 手撸简易服务器(完善版本)
本文没有带反射部分内容,可以看我之前发的 Server.h #pragma once#include <string> #include <iostream> #include <thread> #include <unordered_map> using namespace std; #ifndef _SERVER_ #define _SERVER_#include <winsock.h&…...

【Python入门第三十四天】Python丨文件处理
文件处理是任何 Web 应用程序的重要组成部分。 Python 有几个用于创建、读取、更新和删除文件的函数。 文件处理 在 Python 中使用文件的关键函数是 open() 函数。 open() 函数有两个参数:文件名和模式。 对于刚学Python的小伙伴,我给大家准备了2023…...
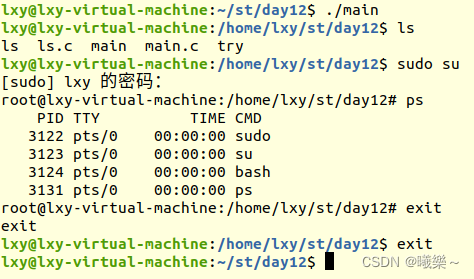
【Linux】写一个基础的bash
头文件#include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<sys/wait.h> #include<sys/stat.h> #include<string.h> #include<pwd.h> #include<dirent.h>分割输入的命令串字符串或参数内容为空则退出strtok( ,…...
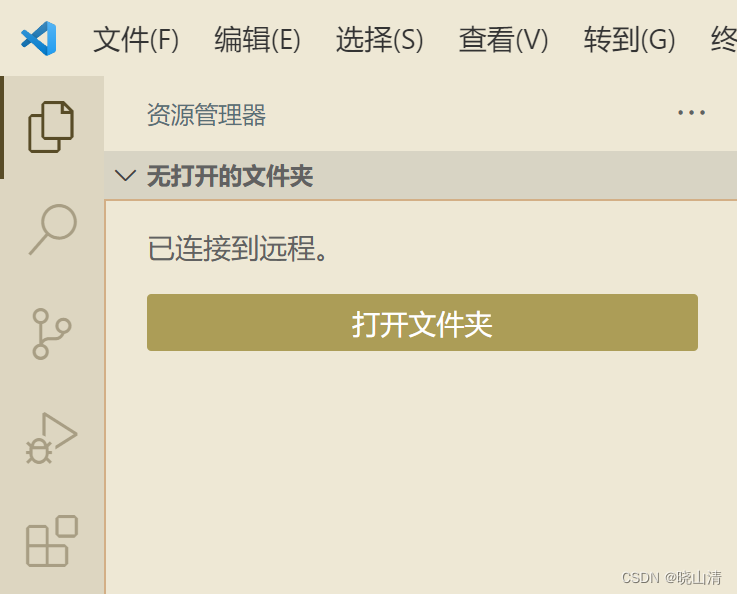
图解如何一步步连接远程服务器——基于VScode
基于VScode连接远程服务器 安装Remote-SSH等插件 想要在vscode上连接远程服务器需要下载Remote-SSH系列插件: 直接在插件中搜索remote,即可找到,选择图片中的3个插件,点击install安装。 配置Remote-SSH 在这个步骤有多种操作…...

element - - - - - 你不知道的loading使用方式
求人不如求己 你不知道的loading使用方式1. 指令方式使用1.1 默认loading1.2 自定义loading1.3 整页加载2. 服务方式使用2.1 this.$loading的使用2.2 Loading.service的使用关于页面交互,最害怕的就是接口等待时间太长,用户体验不好。 而如何提高用户体…...

C++程序调用IsBadReadPtr或IsBadWritePtr引发内存访问违例问题的排查
目录 1、问题描述 2、VS中看不到有效的信息,尝试使用Windbg去分析 3、使用Windbg分析 4、最后...

IntelliJIDEA 常用快捷键
IntelliJIDEA 常用快捷键 Alt Enter 导入包,自动修正,自动创建变量名。 Ctrl Alt O 优化导入的类和包 Ctrl / 单行注释 (//) Ctrl Shift / 多行注释 (/* … */) 方法或类说明注释(文档注释) 在一个方法或类的开头…...

Python自动化抖音自动刷视频
环境准备 Python3.5以上Appium Server服务器Android SDK,需要用到adb服务需要依赖Appium-Python-Client组件库真机或者模拟器,推荐模拟器(真机一般安卓8版本以上了,appium对安卓8以上版本元素获取的兼容性不太好)JDK8环境 实现 确保adb服务…...

使用vite创建vue3工程
定义 什么是vite?-----新一代前端构建工具 优势 开发环境中,无需打包操作,可快速的冷启动---最牛的地方轻量快速的热重载(HMR)---一修改代码就局部刷新,webpack也具备,但vite更快真正的按需编…...
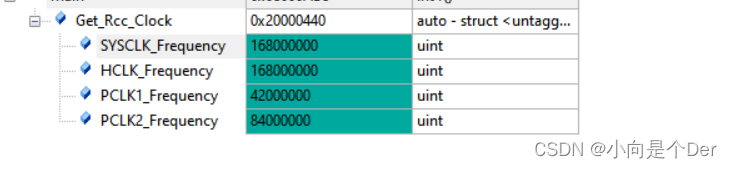
嵌入式学习笔记——STM32的时钟树
时钟树前言时钟树时钟分类时钟树框图LSI与LSEHSI、HSE与PLL系统时钟的产生举例AHB、APBx的时钟配置时钟树相关寄存器介绍1.时钟控制寄存器(RCC_CR)2.RCC PLL 配置寄存器 (RCC_PLLCFGR)3.RCC 时钟配置寄存器 (RCC_CFGR)4.RCC 时钟中断寄存器 (RCC_CIR)修改…...
-NumPy矩阵与通用函数)
Python学习(2)-NumPy矩阵与通用函数
文章首发于:My Blog 欢迎大佬们前来逛逛 1. NumPy矩阵 1.1 mat函数 matasmatrix asmatrix(data, dtypeNone):data:表示输入的数组或者字符串,使用‘,’分割列,使用‘;’分割行 创建两个普通的矩阵&…...

剑指 Offer II 035. 最小时间差
题目链接 剑指 Offer II 035. 最小时间差 mid 题目描述 给定一个 24小时制(小时:分钟 "HH:MM")的时间列表,找出列表中任意两个时间的最小时间差并以分钟数表示。 示例 1: 输入:timePoints [“23:59”,“0…...

Spark SQL函数定义【博学谷学习记录】
1 如何使用窗口函数窗口函数格式:分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])学习的相关分析函数有那些? 第一类: row_number() rank() dense_rank() ntile()第二类: 和聚合函数组合使用 sum() avg() max() min() count()第三类: la…...
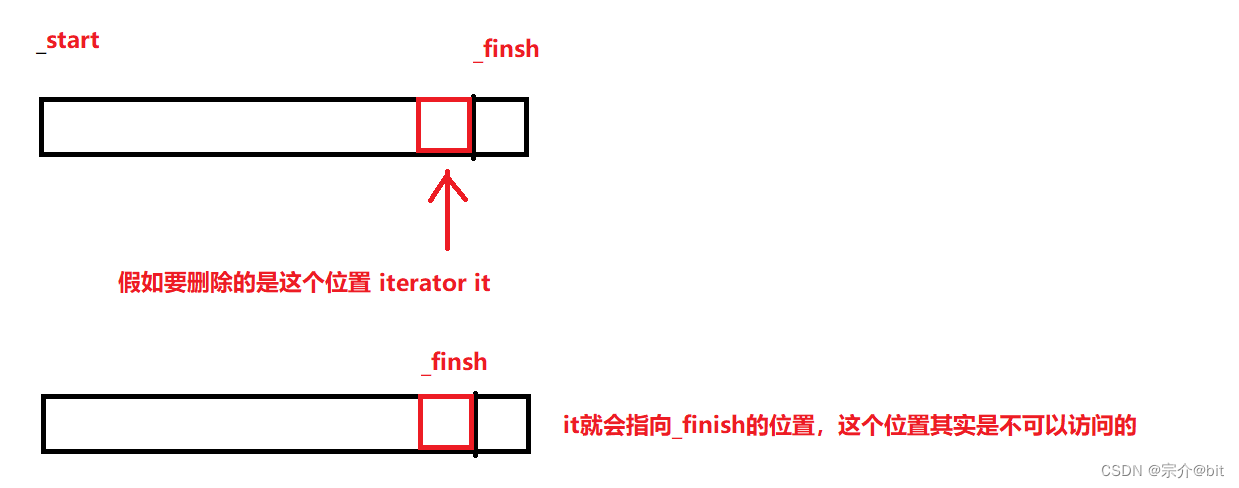
模拟实现STL容器之vector
文章目录前言1.大体思路2.具体代码实现1.类模板的创建2.构造函数1.无参构造2.拷贝构造 迭代器构造和给定n个val值构造以及析构函数3.空间扩容1.reserve2.resize4.操作符重载1.[ ]重载2.赋值运算符重载5.数据增加和删除1.尾插2.任意位置插入3.任意位置删除4.尾删6.一些其他接口3…...

ChatGPT-4.0 : 未来已来,你来不来
文章目录前言ChatGPT 3.5 介绍ChatGPT 4.0 介绍ChatGPT -4出逃计划!我们应如何看待ChatGPT前言 好久没有更新过技术文章了,这个周末听说了一个非常火的技术ChatGPT 4.0,于是在闲暇之余我也进行了测试,今天这篇文章就给大家介绍一…...
)
Java反射(详细学习笔记)
Java反射 1. Java反射机制概述 Reflection(反射)是java被视为java动态语言的关键,反射机制允许程序在执行期间借助于Reflection API获取任何类的内部信息,并能直接操作任意对象的内部属性及方法。 Class c Class.forName(&quo…...

PPTist:重新定义在线演示文稿创作体验
PPTist:重新定义在线演示文稿创作体验 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the editing a…...

保姆级教程:手把手教你用VCSA 8.0.3接管Windows AD域,实现统一登录
企业级虚拟化身份管理:VCSA 8.0.3与Windows AD域深度集成实战 在数字化转型浪潮中,企业IT基础设施的集中化管理已成为刚需。当虚拟化平台规模扩大至数百台主机时,如何确保管理员和开发人员既能高效访问资源,又能遵循最小权限原则&…...

Windows右键菜单瘦身秘籍:3个技巧让你的文件操作快如闪电
Windows右键菜单瘦身秘籍:3个技巧让你的文件操作快如闪电 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否经历过这样的尴尬时刻?在…...

Naive UI 主题色定制实战:从组件覆盖到全局配置
1. 为什么需要定制Naive UI主题色? 当你使用Naive UI开发项目时,默认的绿色主题可能并不符合你的品牌风格。比如我们团队最近接手的一个金融类项目,客户要求整体UI采用深蓝色调,这时候就需要对Naive UI的主题色进行深度定制。主题…...
)
告别硬编码!用Rule-Engine 1.0.0重构你的Java业务逻辑(附订单折扣实战)
告别硬编码!用Rule-Engine 1.0.0重构你的Java业务逻辑(附订单折扣实战) 每次电商大促前夜,技术团队最怕听到的一句话是什么?"折扣规则又改了!"——这往往意味着通宵修改代码、紧急测试和冒着风险…...

对在aarch64 Linux环境编译安装的CinderX补充测试
前文最后说,CinderX报错不能用,这不对,我在其github存储库上提了这个issue,alexmalyshev回复 I think that’s actually just a warning that you’re getting but things should be working after that?Right, this is just a l…...

Quartus元器件仿真波形生成实战指南
1. Quartus元器件仿真波形生成入门指南 第一次接触Quartus的仿真功能时,我也被那一堆专业术语搞得晕头转向。但后来发现,只要掌握了基本流程,生成仿真波形其实就像用画图软件一样简单。这里我会用最直白的语言,带你一步步完成整个…...

DeerFlow部署全攻略:简单几步,打造你的专属AI研究工作站
DeerFlow部署全攻略:简单几步,打造你的专属AI研究工作站 1. 引言:你的个人深度研究助理来了 想象一下,你正在为一个复杂的项目做调研,需要收集资料、分析数据、撰写报告,甚至还要制作演示文稿。传统的方式…...

DLSS Swapper实战指南:高效管理DLSS版本3步达成游戏性能跃升
DLSS Swapper实战指南:高效管理DLSS版本3步达成游戏性能跃升 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 当你在4K分辨率下启动《赛博朋克2077》,满心期待沉浸在夜之城的霓虹中时,…...

SOLIDWORKS自定义属性模板制作全攻略:从零开始驱动模型参数
SOLIDWORKS自定义属性模板制作全攻略:从零开始驱动模型参数 在机械设计领域,SOLIDWORKS作为主流的三维CAD软件,其自定义属性功能往往被初学者低估。想象一下这样的场景:当你需要批量修改上百个零件的材料规格时,是否还…...