推荐系统的核心逻辑 MVP
我们将设计一个基于内容经济的推荐系统(Minimum Viable Product, MVP)。这个系统将通过收集用户行为数据,计算用户相似度,并生成个性化的推荐结果。推荐系统将包括数据收集、数据存储、数据处理和推荐服务几个关键部分。
MVP功能点概要
- 前端埋点数据收集:收集用户行为数据,如浏览、点击、购买等。
- 数据存储:将收集到的数据存储在ClickHouse数据库中。
- 离线计算用户相似度:使用Spark计算用户之间的相似度。
- 实时推荐服务:基于用户相似度,为用户提供实时推荐。
实现步骤
步骤一:前端埋点数据收集
- 设置前端埋点:在网站或应用中添加JavaScript代码,收集用户行为数据。
// 前端埋点示例(使用JavaScript)
document.addEventListener('DOMContentLoaded', (event) => {document.querySelectorAll('.trackable-item').forEach(item => {item.addEventListener('click', (e) => {let userId = getUserId(); // 获取用户IDlet itemId = e.target.dataset.itemId; // 获取项目IDlet actionType = 'click'; // 行为类型let actionTime = new Date().toISOString(); // 行为时间// 发送数据到后端fetch('/track', {method: 'POST',headers: {'Content-Type': 'application/json'},body: JSON.stringify({user_id: userId,item_id: itemId,action_type: actionType,action_time: actionTime})});});});
});function getUserId() {// 模拟获取用户ID的逻辑return '12345';
}
步骤二:数据存储
- 后端服务接收数据并存储到ClickHouse:
# 使用Flask作为后端服务
from flask import Flask, request
from clickhouse_driver import Clientapp = Flask(__name__)
client = Client(host='clickhouse_host', user='default', password='your_password', database='default')@app.route('/track', methods=['POST'])
def track():data = request.jsonuser_id = data['user_id']item_id = data['item_id']action_type = data['action_type']action_time = data['action_time']# 插入数据到ClickHouseclient.execute('''INSERT INTO user_behavior (user_id, item_id, action_type, action_time) VALUES (%s, %s, %s, %s)''', (user_id, item_id, action_type, action_time))return 'OK', 200if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
- 在ClickHouse中创建存储表:
CREATE TABLE user_behavior (user_id String,item_id String,action_type String,action_time DateTime
) ENGINE = MergeTree()
ORDER BY (user_id, action_time);
步骤三:离线计算用户相似度
- 使用Spark计算用户相似度:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.ml.recommendation import ALS# 创建Spark会话
spark = SparkSession.builder \.appName("UserSimilarityCalculation") \.getOrCreate()# 加载用户行为数据
user_behavior = spark.read \.format("jdbc") \.option("url", "jdbc:clickhouse://clickhouse_host:8123/default") \.option("dbtable", "user_behavior") \.option("user", "default") \.option("password", "your_password") \.load()# 训练ALS模型
als = ALS(userCol="user_id", itemCol="item_id", ratingCol="action_type", coldStartStrategy="drop")
model = als.fit(user_behavior)# 生成用户相似度矩阵
user_factors = model.userFactors
user_similarity = user_factors.alias("i").join(user_factors.alias("j"), col("i.id") != col("j.id")) \.select(col("i.id").alias("user1"), col("j.id").alias("user2"), cosine_similarity(col("i.features"), col("j.features")).alias("similarity"))# 保存用户相似度矩阵到ClickHouse
user_similarity.write \.format("jdbc") \.option("url", "jdbc:clickhouse://clickhouse_host:8123/default") \.option("dbtable", "user_similarity") \.option("user", "default") \.option("password", "your_password") \.mode("overwrite") \.save()
步骤四:实时推荐服务
- 构建推荐API服务:
from flask import Flask, request, jsonify
from clickhouse_driver import Clientapp = Flask(__name__)
client = Client(host='clickhouse_host', user='default', password='your_password', database='default')@app.route('/recommend', methods=['GET'])
def recommend():user_id = request.args.get('user_id')# 查询用户最近的行为数据user_behavior = client.execute('''SELECT item_id, COUNT(*) AS count FROM user_behavior WHERE user_id = %s GROUP BY item_id ORDER BY count DESC LIMIT 10''', (user_id,))# 查询用户相似度user_similarity = client.execute('''SELECT user2 AS similar_user, similarity FROM user_similarity WHERE user1 = %s ORDER BY similarity DESC LIMIT 10''', (user_id,))# 基于相似用户的行为推荐similar_users = [user[0] for user in user_similarity]recommendations = client.execute('''SELECT item_id, COUNT(*) AS count FROM user_behavior WHERE user_id IN %s AND item_id NOT IN (SELECT item_id FROM user_behavior WHERE user_id = %s) GROUP BY item_id ORDER BY count DESC LIMIT 10''', (tuple(similar_users), user_id))return jsonify(recommendations)if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
数据结构
用户行为数据表(user_behavior)
CREATE TABLE user_behavior (user_id String,item_id String,action_type String,action_time DateTime
) ENGINE = MergeTree()
ORDER BY (user_id, action_time);
用户相似度矩阵表(user_similarity)
CREATE TABLE user_similarity (user1 String,user2 String,similarity Float32
) ENGINE = MergeTree()
ORDER BY (user1, similarity DESC);
评估效果
使用离线评估指标(如精确度、召回率、NDCG)和在线评估指标(如点击率、转化率)来评估推荐系统的效果。可以通过模拟用户行为数据或在实际环境中进行A/B测试来验证推荐系统的性能。
以上实现步骤提供了一个完整的、最小可验证的推荐系统功能点,从数据收集、存储、处理到推荐服务。通过该MVP,可以验证推荐系统在内容经济中的实际效果,并在此基础上进行进一步优化和扩展。
相关文章:

推荐系统的核心逻辑 MVP
我们将设计一个基于内容经济的推荐系统(Minimum Viable Product, MVP)。这个系统将通过收集用户行为数据,计算用户相似度,并生成个性化的推荐结果。推荐系统将包括数据收集、数据存储、数据处理和推荐服务几个关键部分。 MVP功能…...

Java中的BIO,NIO与操作系统IO模型的区分
Java中的IO模型 Java中的BIO,NIO,AIO概念可以是针对输入输出流,文件,和网络编程等其他IO操作的。 但是主要还是在网络编程通信过程中比较重要,因为很多情况网络编程需要它们来提供更好的性能。 所以本篇文章偏向于网络…...

AI砸掉了这些人的饭碗
在一般打工人眼里,金融圈往往被认为是高端脑力工作者的聚集地,他们工资高,学历高,能力强,轻易无法被替代。 可最近,偏偏一个“非人类”的物种,要来抢他们的饭碗。相关报道称,华尔街…...

端口及对应服务
端口是计算机网络中用于区分不同服务的逻辑概念。每个端口号都是一个16位的数字,其取值范围从0到65535。端口号被分为以下几类: 公认端口(Well-known ports):范围从0到1023,这些端口通常被分配给常见的服务…...

剑指offer题解合集——Week7day1[滑动窗口的最大值]
滑动窗口的最大值 题目描述 给定一个数组和滑动窗口的大小,请找出所有滑动窗口里的最大值。 例如,如果输入数组 [2,3,4,2,6,2,5,1] 及滑动窗口的大小 3 ,那么一共存在 6 个滑动窗口,它们的最大值分别为 [4,4,6,6,6,5] 注意&am…...

深入解读财报,开启美股投资之旅
投资股票市场,尤其是美股市场,对于许多投资者来说是一项充满挑战的活动。然而,无论投资者是倾向于技术分析还是基本面分析,财报都是他们不可或缺的工具。本文将带领读者深入了解如何通过阅读和分析财报,发现潜在的投资…...

邦芒支招:成功找到工作要掌握的3个知识点
社会进步,企业商业竞争越来越激烈,不管身为一名职场小白或是想调换一下目前的工作的人,都想找到一个称心如意的好工作。拥有以下三点知识点,可以使我们找到工作。 1、迫不得已,别做这件事 拍桌子说“我不开了”的时候有…...

Educational Codeforces Round 168 (Rated for Div. 2)-7.30复盘
A. Strong Password 简单题,找到相同的两个相邻字母之间插一个跟他们不同的大写字母即可 inline void solve(){cin>>s;int id0;char hh ;for(int i1;i<s.size();i){if(s[i-1]s[i]){idi;break;}} for(int i0;i<26;i){if(s[id]!ai&&s[id1]!ai) …...

Web开发:小结Apache Echarts官网上常用的配置项(前端可视化图表)
目录 一、须知 二、Title 三、 Legend 四、Grid 一、须知 配置项官方文档:点此进入。 我总结了比较常用的功能,写进注释里面,附带链接分享和效果图展示。(更新中....) 二、Title option {title: {text: Weekl…...

B树的平衡性与性能优化
B树的平衡性与性能优化 B树(B-tree)是一种自平衡的树数据结构,广泛应用于数据库和文件系统中,用于保持数据的有序性并允许高效的插入、删除和查找操作。B树能够很好地处理大规模数据,并在磁盘I/O操作中表现出色。本文…...

llama3源码解读之推理-infer
文章目录 前言一、整体源码解读1、完整main源码2、tokenizer加载3、llama3模型加载4、llama3测试数据文本加载5、llama3模型推理模块1、模型推理模块的数据处理2、模型推理模块的model.generate预测3、模型推理模块的预测结果处理6、多轮对话二、llama3推理数据处理1、完整数据…...

【教程】Linux安装Redis步骤记录
下载地址 Index of /releases/ Downloads - Redis 安装redis-7.4.0.tar.gz 1.下载安装包 wget https://download.redis.io/releases/redis-7.4.0.tar.gz 2.解压 tar -zxvf redis-7.4.0.tar.gz 3.进入目录 cd redis-7.4.0/ 4.编译 make 5.安装 make install PREFIX/u…...

全球汽车线控制动系统市场规模预测:未来六年CAGR为17.3%
引言: 随着汽车行业的持续发展和对安全性能需求的增加,汽车线控制动系统作为提升车辆安全性和操控性的关键组件,正逐渐受到市场的广泛关注。本文旨在通过深度分析汽车线控制动系统行业的各个维度,揭示行业发展趋势和潜在机会。 【…...

Ubuntu运行深度学习代码,代码随机epoch中断没有任何报错
深度学习运行代码直接中断 文章目录 深度学习运行代码直接中断问题描述设备信息问题补充解决思路问题发现及正确解决思路新问题出现最终问题:ubuntu系统,4090显卡安装英伟达驱动535.x外的驱动会导致开机无法进入桌面问题记录 问题描述 运行深度学习代码…...

只有4%知道的Linux,看了你也能上手Ubuntu桌面系统,Ubuntu简易设置,源更新,root密码,远程服务...
创作不易 只因热爱!! 热衷分享,一起成长! “你的鼓励就是我努力付出的动力” 最近常提的一句话,那就是“但行好事,莫问前程"! 与辉同行的董工说:守正出奇。坚持分享,坚持付出,坚持奉献,…...
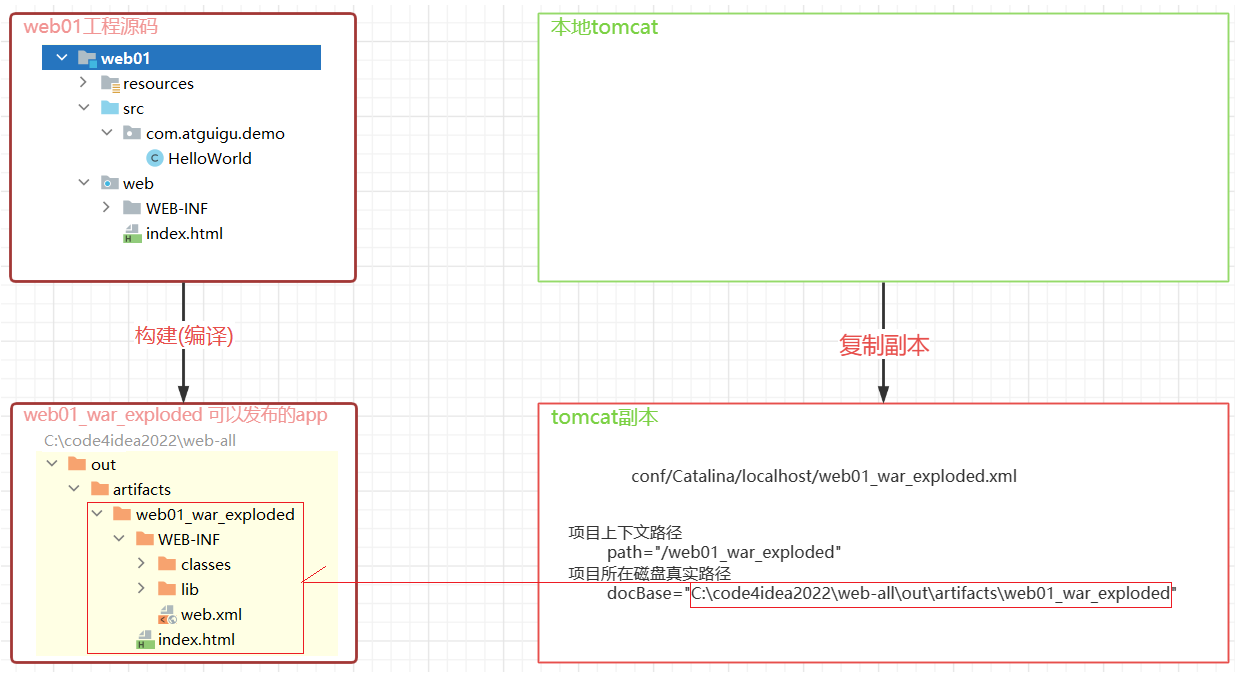
Tomcat部署——个人笔记
Tomcat部署——个人笔记 文章目录 [toc]简介安装配置文件WEB项目的标准结构WEB项目部署IDEA中开发并部署运行WEB项目 本学习笔记参考尚硅谷等教程。 简介 Apache Tomcat 官网 Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中…...

常见且重要的用户体验原则
以下是一些常见且重要的用户体验原则: 1. 以用户为中心 - 深入了解用户的需求、期望、目标和行为习惯。通过用户研究、调查、访谈等方法获取真实的用户反馈,以此来设计产品或服务。 - 例如,在设计一款老年手机时,充分考虑老年…...

web基础及nginx搭建
第四周 上午 静态资源 根据开发者保存在项目资源目录中的路径访问静态资源 html 图片 js css 音乐 视频 f12 ,开发者工具,网络 1 、 web 基本概念 web 服务器( web server ):也称 HTTP 服务器( HTTP …...

C++ 布隆过滤器
1. 布隆过滤器提出 我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉 那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用 户看过的所有历史…...

使用HTML创建用户注册表单
在当今数字化时代,网页表单对于收集用户信息和促进网站交互至关重要。无论您设计简单的注册表单还是复杂的调查表,了解HTML的基础知识可以帮助您构建有效的用户界面。在本教程中,我们将详细介绍如何使用HTML创建基本的用户注册表单。 第一步…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...
:从理论基石到信号分解实战)
经验小波变换(EWT):从理论基石到信号分解实战
1. 经验小波变换(EWT)的前世今生 我第一次接触EWT是在处理一段轴承振动信号时。当时用传统EMD方法分解出的IMF分量里,高频噪声和故障特征频率完全混在一起,就像把咖啡和牛奶搅成了拿铁——虽然都是白色液体,但根本分不…...

CQDs-PEG/Biotin/@SiO2/Polymer,PEG修饰碳量子点的特性
中英文名称: CQDs-PEG,PEG修饰碳量子点 CQDs-Biotin,生物素偶联碳量子点 CQDsSiO2,二氧化硅包覆碳量子点 CQDsPolymer,聚合物包覆碳量子点 碳量子点(Carbon Quantum Dots, CQDs)作为一类新型零维…...

别再乱接电源了!STM32的VDDA、VSSA、VBAT引脚,一个没接对,ADC采样全是噪声
STM32电源设计实战:VDDA、VSSA与VBAT的噪声抑制艺术 当你的STM32项目遇到ADC采样值跳变、RTC计时不准或程序下载失败时,电源引脚的设计往往是罪魁祸首。许多工程师在PCB布局时,对这些看似简单的电源引脚处理过于随意,结果在调试阶…...

深度相机三剑客:TOF、双目与结构光的场景化选型指南
1. 深度相机技术入门:从原理到应用 第一次接触深度相机时,我被各种技术名词搞得晕头转向。TOF、双目、结构光听起来都很高大上,但到底有什么区别?经过多年项目实战,我发现这三种技术就像不同的"眼睛"&#…...

服务器运维与DevOps融合:迈向智能化运维的新纪元
在数字化浪潮席卷全球的今天,企业对IT基础设施的依赖程度日益加深,服务器运维作为支撑业务连续性和系统稳定性的核心环节,正面临前所未有的挑战与机遇。传统运维模式依赖人工干预、响应滞后、效率低下,已难以满足现代业务快速迭代…...

【Midjourney水墨风创作终极指南】:20年AI视觉专家亲授7大不可外传的Ink Wash参数配方与避坑清单
更多请点击: https://intelliparadigm.com 第一章:水墨风AI创作的认知革命与历史语境 水墨艺术承载着东方哲学中“虚实相生”“气韵生动”的深层认知范式,而当生成式AI介入水墨风格建模时,其本质并非简单纹理迁移,而是…...

2026最权威的六大降AI率助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在把学术成果提交到知网平台以前,针对借助生成式AI辅助而产出的内容去进行合规化…...

Excel+ChatGPT函数实战:零代码实现语义理解与智能数据处理
1. 为什么说“在Excel里直接调用ChatGPT”不是噱头,而是真正在改写数据处理的工作流 你有没有过这样的时刻:盯着Excel表格里一列杂乱的客户反馈,想快速标出哪些是投诉、哪些是表扬,却卡在手动翻查、复制粘贴、反复试错公式上&…...

哪个降AI软件好?2026年4款主流降AI工具按场景对位横评!
哪个降AI软件好?2026年4款主流降AI工具按场景对位横评! 「哪个降 AI 软件好」没有标准答案。学生最常踩的坑是把这个问题简化成「哪款最便宜」或者「哪款最有效」——其实好不好用看你的场景。学校送知网严标准、送维普重灾区、自媒体被判 AI、本科双重问…...