如何用自己的数据训练YOLOv5
如何训练YOLOv5
1. Clone the YOLOv5 repository and install dependencies:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt2. 整理数据,使其适配YOLO训练
Step1:Organize your dataset in the following format:
dataset
│
└───train
│ └───images
│ │ │ img1.jpg
│ │ │ img2.jpg
│ │ │ ...
│ └───labels
│ │ img1.txt
│ │ img2.txt
│ │ ...
│
└───valid└───images│ │ img1.jpg│ │ img2.jpg│ │ ...└───labels│ img1.txt│ img2.txt│ ...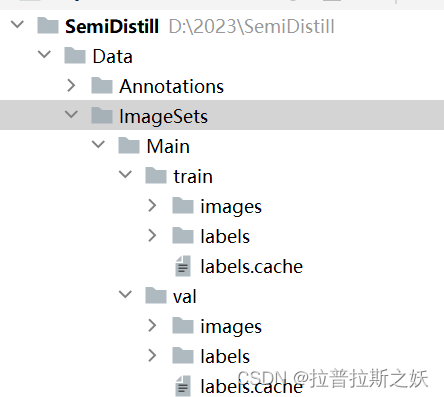
Step 2: 将xml格式的label转化为txt格式(适配)
# -*- coding: utf-8 -*-
# 需要修改的地方:1. dirpath 2. newdir 3. dict_info
import os
import xml.etree.ElementTree as ETdirpath = r'D:\2023\SemiDistill\Data\Annotations' # 原来存放xml文件的目录
newdir = r'D:\2023\SemiDistill\Data\labels' # 修改label后形成的txt目录if not os.path.exists(newdir):os.makedirs(newdir)dict_info = {'pocket': 0} # 有几个 类别 填写几个label namesfor fp in os.listdir(dirpath):if fp.endswith('.xml'):root = ET.parse(os.path.join(dirpath, fp)).getroot()xmin, ymin, xmax, ymax = 0, 0, 0, 0sz = root.find('size')width = float(sz[0].text)height = float(sz[1].text)filename = root.find('filename').textfor child in root.findall('object'): # 找到图片中的所有框sub = child.find('bndbox') # 找到框的标注值并进行读取label = child.find('name').textlabel_ = dict_info.get(label)if label_:label_ = label_else:label_ = 0xmin = float(sub[0].text)ymin = float(sub[1].text)xmax = float(sub[2].text)ymax = float(sub[3].text)try: # 转换成yolov3的标签格式,需要归一化到(0-1)的范围内x_center = (xmin + xmax) / (2 * width)x_center = '%.6f' % x_centery_center = (ymin + ymax) / (2 * height)y_center = '%.6f' % y_centerw = (xmax - xmin) / widthw = '%.6f' % wh = (ymax - ymin) / heighth = '%.6f' % hexcept ZeroDivisionError:print(filename, '的 width有问题')with open(os.path.join(newdir, fp.split('.xml')[0] + '.txt'), 'a+') as f:f.write(' '.join([str(label_), str(x_center), str(y_center), str(w), str(h) + '\n']))
print('ok')
3. Create a YAML file:
Create a YAML file (e.g., my_data.yaml) to describe your dataset:
# 需要修改的地方:train、val、names, nc
train: D:\\2023\\SemiDistill\\Data\\ImageSets\\Main\\train # train文件夹路径
val: D:\\2023\\SemiDistill\\Data\\ImageSets\\Main\\val # val文件夹路径
# number of classes
nc: 1
# class names
names: ["pocket"]4. Train YOLOv5s
python train.py --img <img_size> --batch <batch_size> --epochs <num_epochs> --data <my_data.yaml> --cfg models/yolov5s.yaml --weights <yolov5s.pt> --name yolov5s_results
在yolov5文件夹下terminal执行以上命令,注意修改<>内数据,其中<my_data.yaml>为自己创建的yaml文件路径,<yolov5s.pt>是下载的yolov5s.pt(预权重)文件路径。
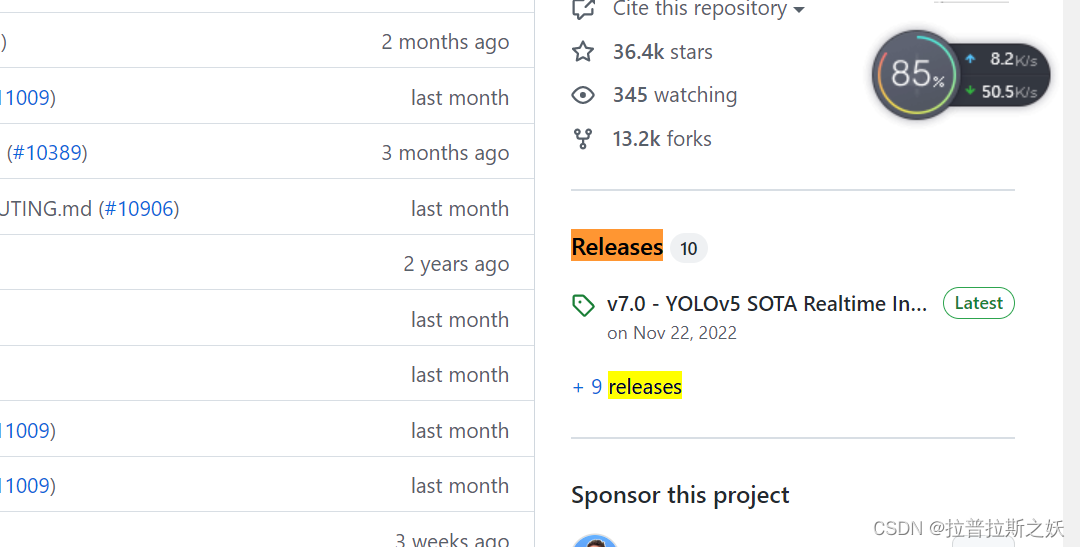
pt文件下载方法:
Here are the steps to download the YOLOv5s.pt file:
-
Go to the official YOLOv5 GitHub repository: https://github.com/ultralytics/yolov5
-
Click on the “Releases” tab.
-
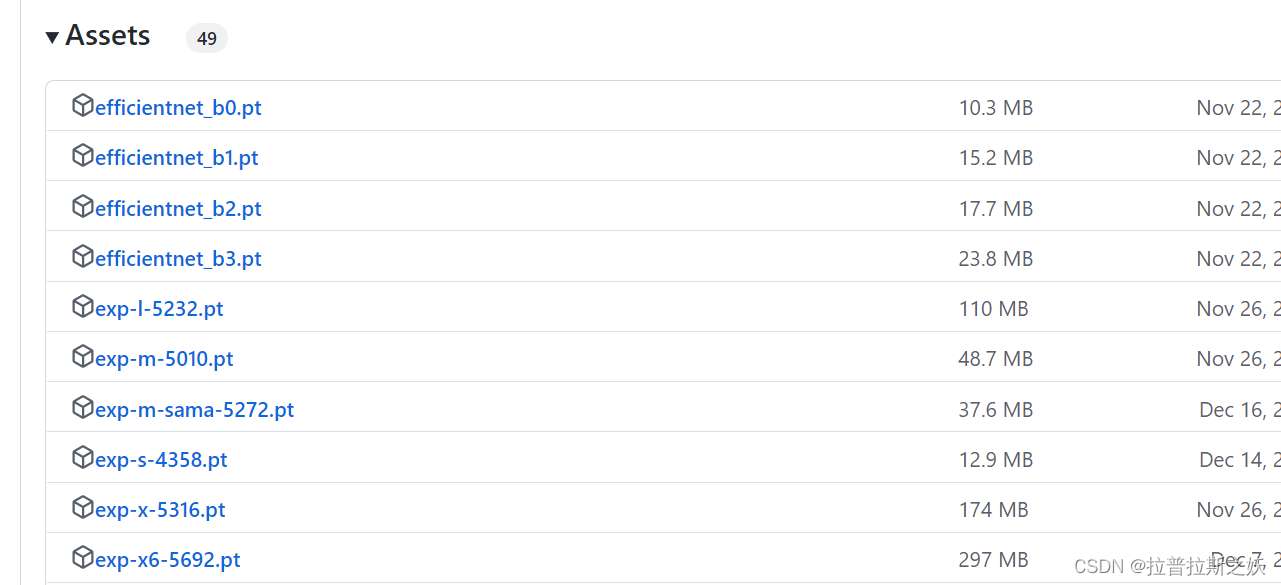
In the “Assets” section, you will find the pre-trained weights for YOLOv5s in the form of a .pt file. The filename is “yolov5s.pt”.
5. Evaluate your trained model
After training, you will find the model weights in the runs/train/yolov5s_results/weights folder. To test the trained model on your validation dataset, you can use the test.py script.
python test.py --weights runs/train/yolov5s_results/weights/best.pt --data my_data.yaml --img <img_size> --iou-thres 0.65 --conf-thres 0.001
After running the test, you will find the results in the runs/test folder. The results will include metrics such as precision, recall, and mAP (mean average precision).
相关文章:
如何用自己的数据训练YOLOv5
如何训练YOLOv5 1. Clone the YOLOv5 repository and install dependencies: git clone https://github.com/ultralytics/yolov5.git cd yolov5 pip install -r requirements.txt2. 整理数据,使其适配YOLO训练 Step1:Organize your dataset in the fo…...

【基础算法】数组相关题目
系列综述: 💞目的:本系列是个人整理为了秋招算法的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于代码随想录进行的,每个算法代码参考leetcode高赞回答和…...

MatBox—基于PyQt快速入门matplotlib的教程库
MatBox—基于PyQt快速入门matplotlib的教程库 __ __ _ _ _ _ _ _ _______ _ _ _ | \/ | | | | | | | | |(_)| | |__ __| | | (_) | || \ / | __ _ |…...

go channel使用
go语言中有一句名言: 不要通过共享内存来通信,而应该通过通信来共享内存。 channel实现了协程间的互相通信。 目录 一、channel声明 二、向channel发送数据 三、从channel读取数据 1. i, ok : <-c 2. for i : range c(常用)…...
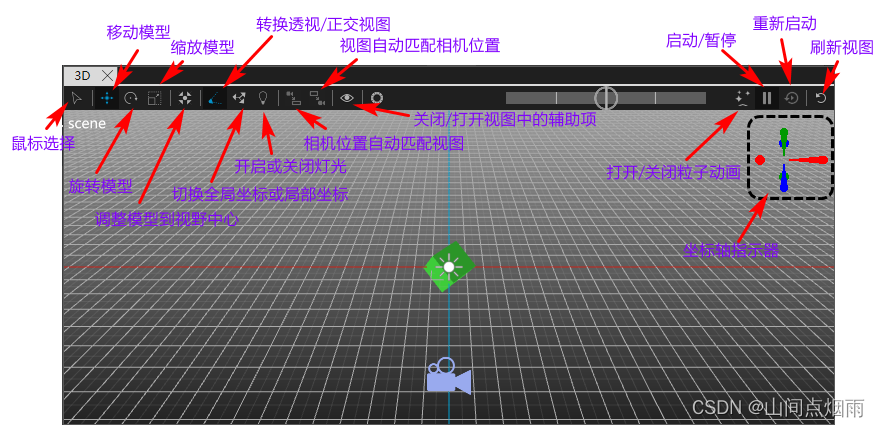
5. QtDesignStudio中的3D场景
1. 说明: 三维渲染开发是Design Studio的重要功能,且操作方便,设计效率非常高,主要用到的控件是 View3D ,可以在3D窗口中用鼠标对模型直接进行旋转/移动/缩放等操作,也可以为模型设置各种动画,执行一系列的…...

人工智能的几个研究方向
人工智能主要研究内容是:分布式人工智能与多智能主体系统、人工思维模型、知识系统、知识发现与数据挖掘、遗传与演化计算、人工生命、人工智能应用等等。 其中热门研究有以下几种。 一、计算机视觉 就包括图像识别,视频识别,具体应用有人…...
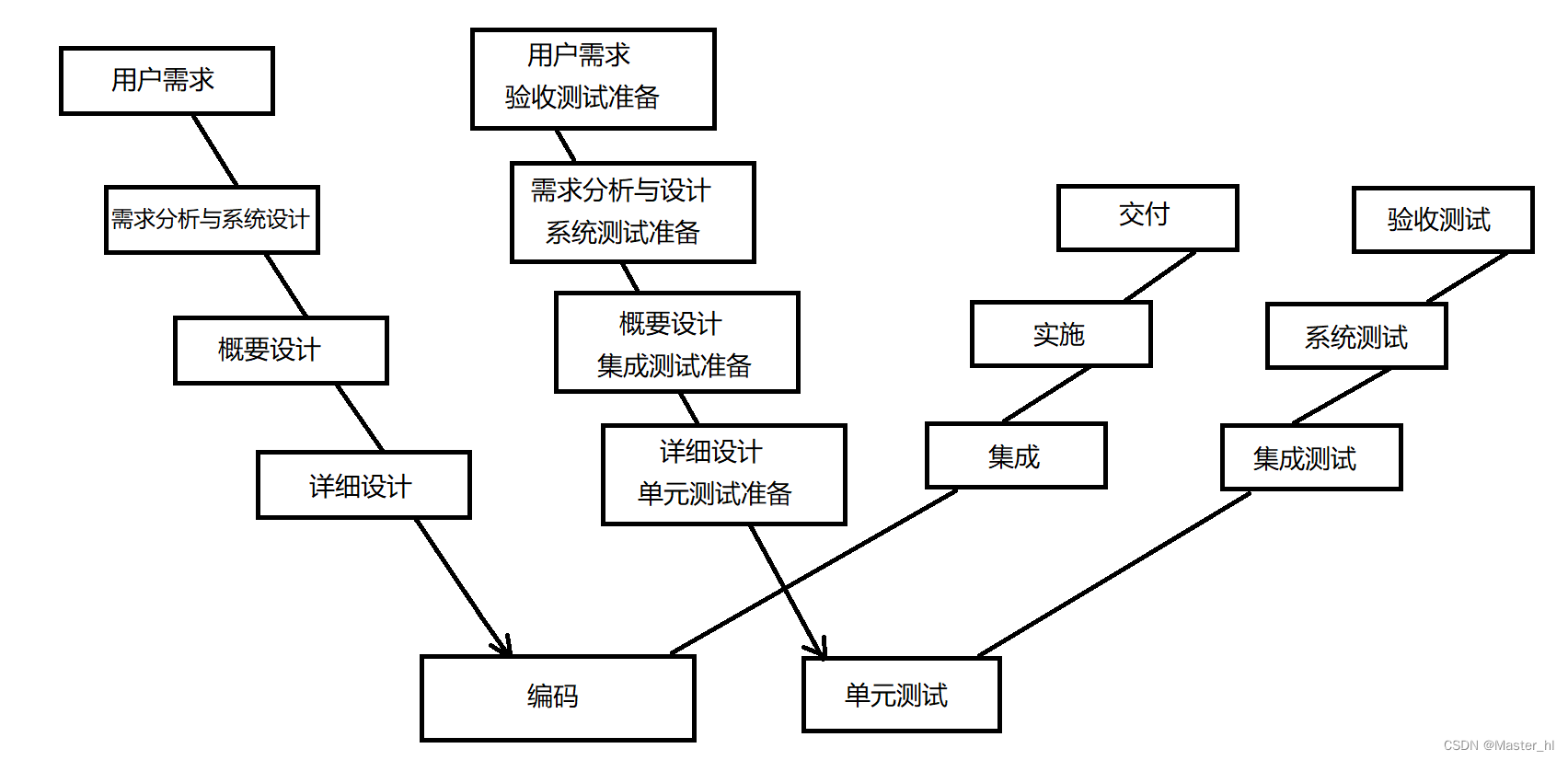
软件测试 - 常见的开发模型和测试模型
1.瀑布模型优点强调开发的阶段性, 强调早期计划及需求调查, 强调产品测试;缺点1. 由于瀑布模型是一种线型结构的模型, 也就意味着前一个阶段结束, 后一个阶段才能开始, 这就导致了风险往往会迟至后期的测试阶段才显露, 因而失去了及早纠正的机会.2. 瀑布模型中测试被后置, 导致…...
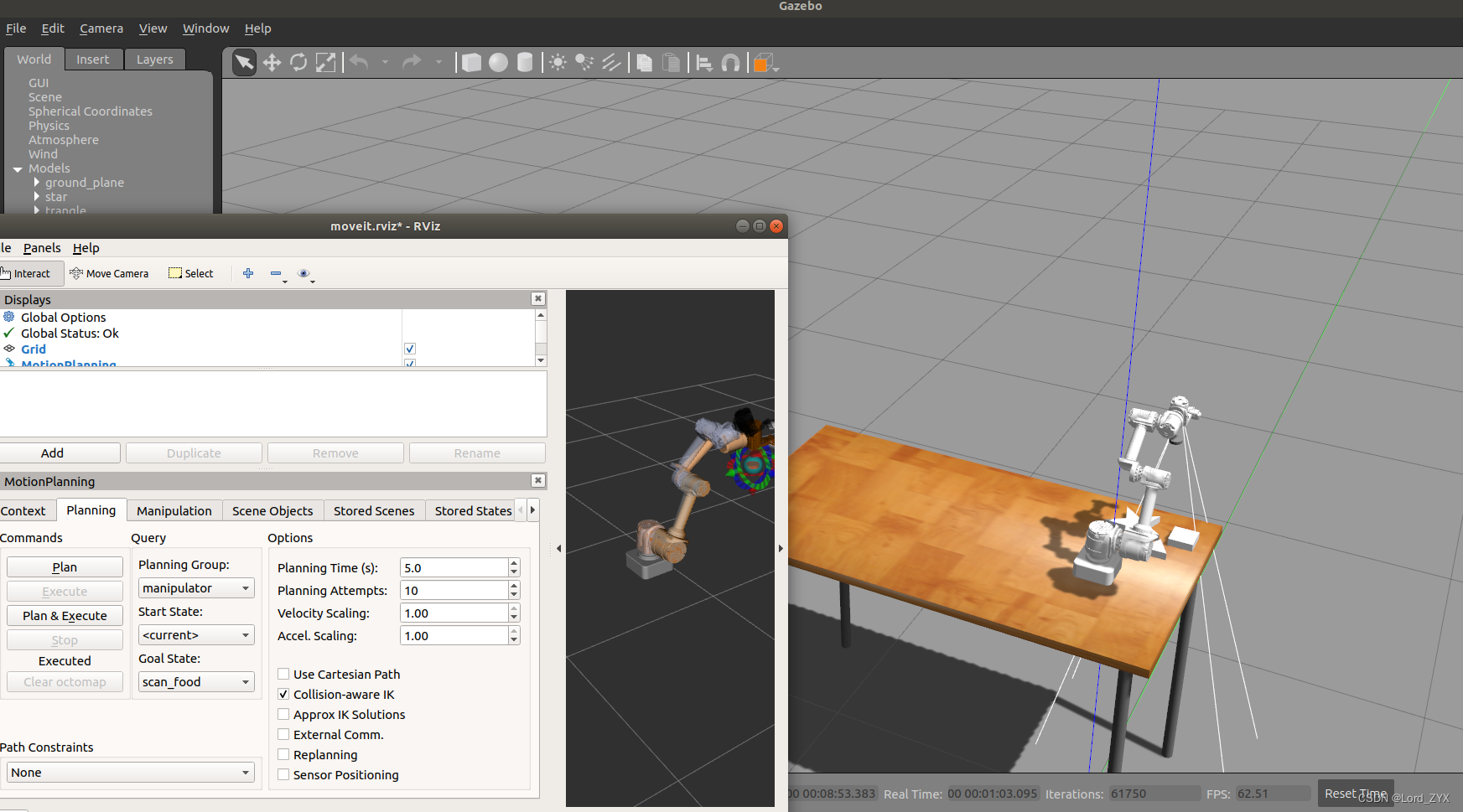
从零开始的机械臂yolov5抓取gazebo仿真(四)
Moveit与Gazebo联合仿真 上一篇博客已经将moveit!配置完毕,然而想要让moveit!控制gazebo中的机械臂,还需要进行一些接口的配置。现在我们有的功能包为sunday_description、sunday_moveit_config这两个功能包。且已经配置好xacro文件,本篇内容…...
C++修炼之筑基期第一层——认识类与对象
文章目录🌷专栏导读🌷什么是面向对象?🌷类的引入🌷什么是类🌷类的定义方式🌷类的访问限定符与封装🌺访问限定符🌺封装🌷类的作用域🌷类的实例化&a…...

IT 运营监控工具
在技术复杂性日益增加、业务竞争激烈的挑战以及消费者对服务中断接受度降低的世界中,IT 运营效率已成为增长、利润和成功的关键。IT 宕机的影响在几十年前威胁较小,现在意味着价值数百万美元的损失,有时甚至会损失各种规模的组织的业务和声誉…...
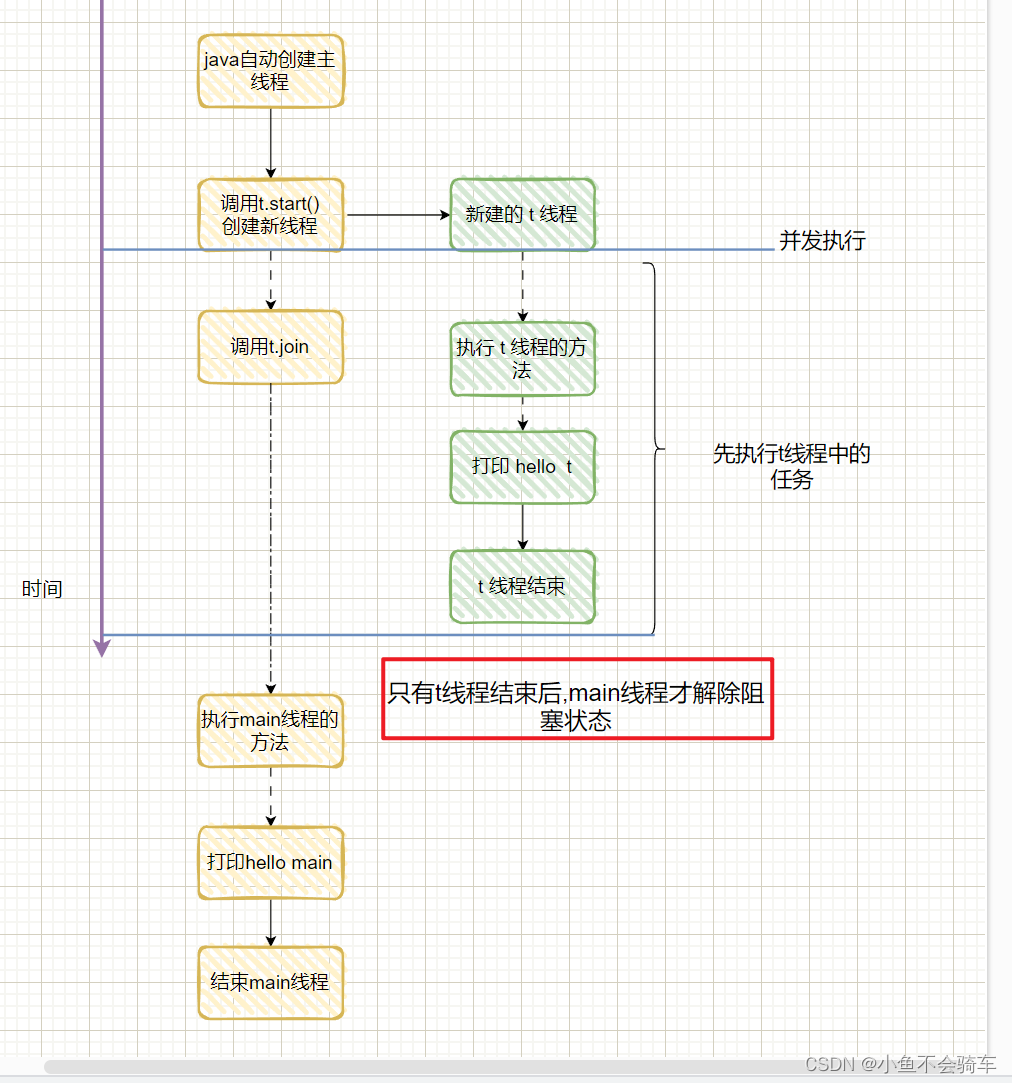
java线程之Thread类的基本用法
Thread类的基本用法1. Thread类的构造方法2. Thread的几个常见属性常见属性线程中断等待一个线程小鱼在上一篇博客详细的讲解了如何创建线程,java使用Thread类来创建多线程,但是对于好多没有相关经验的人来说,比较不容易理解的地方在于操作系统调度的执行过程. 我们通过下面代码…...

【js】多分支语句练习(2)
个人名片: 😊作者简介:一名大一在校生,web前端开发专业 🤡 个人主页:python学不会123 🐼座右铭:懒惰受到的惩罚不仅仅是自己的失败,还有别人的成功。 🎅**学习…...
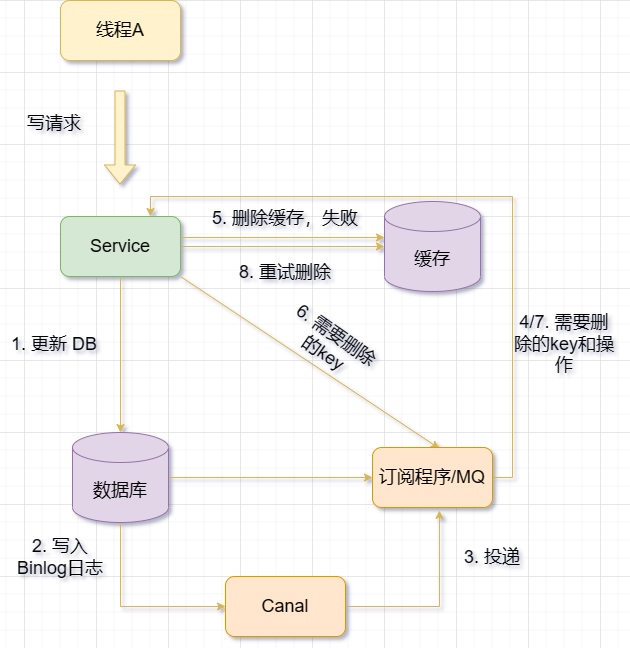
Redis与MySQL的双写一致性问题
Redis与MySQL的双写一致性问题更新缓存? 删除缓存?先更新缓存再更新数据库先更新数据库,再更新缓存先删除缓存再更新数据库先更新数据库,再删除缓存解决方案1. 重试2. 异步重试2.1 使用消息队列实现重试2.2 Binlog实现异步重试删除…...

Java基础:笔试题
文章目录Java 基础题目1. 如下代码输出什么?2. 当输入为2的时候返回值是多少?3. 如下代码输出值为多少?4. 给出一个排序好的数组:{1,2,2,3,4,5,6,7,8,9} 和一个数,求数组中连续元素的和等于所给数的子数组解析第一题第二题第三题第四题方案…...
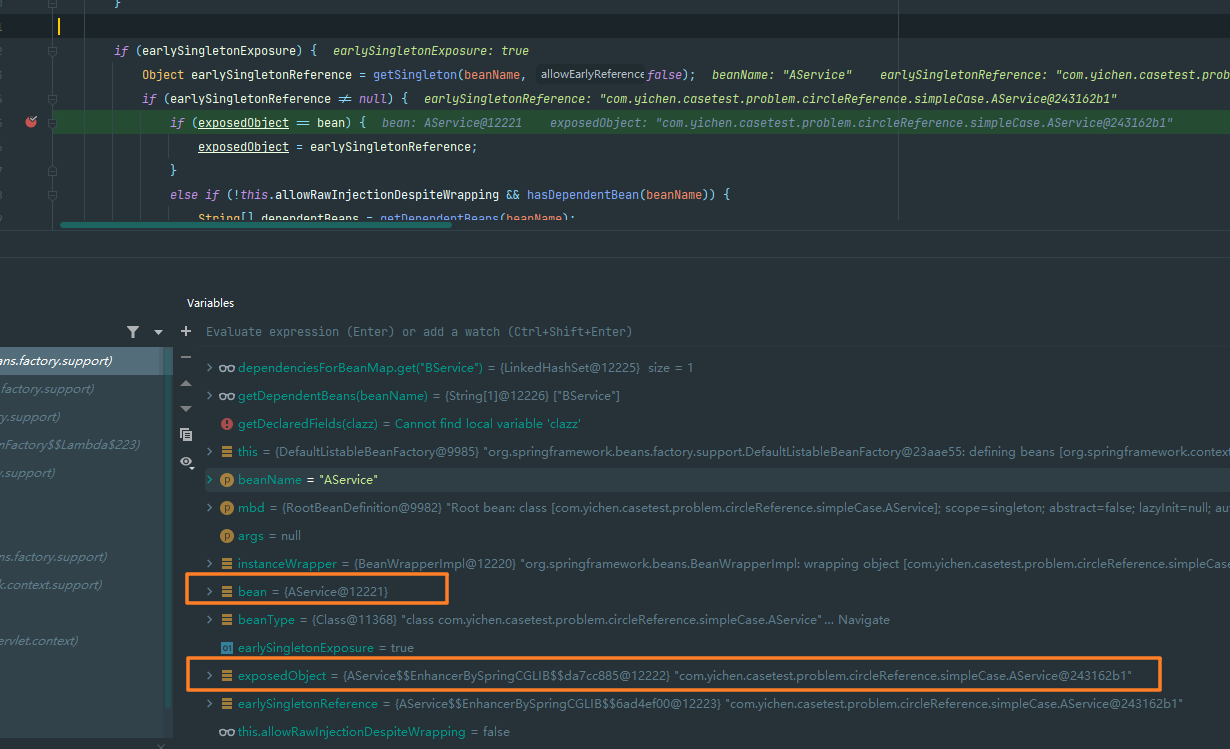
spring三级缓存以及@Async产生循环引用
spring三级缓存以及Async产生循环引用spring三级缓存介绍三级缓存解除循环引用原理源码对应1、获取A,从三级缓存中获取,没有获取到2、构造A,将A置入三级缓存构造A(创建A实例)置入缓存3、注入属性,构造B扫描缓存实例的相关信息注入…...
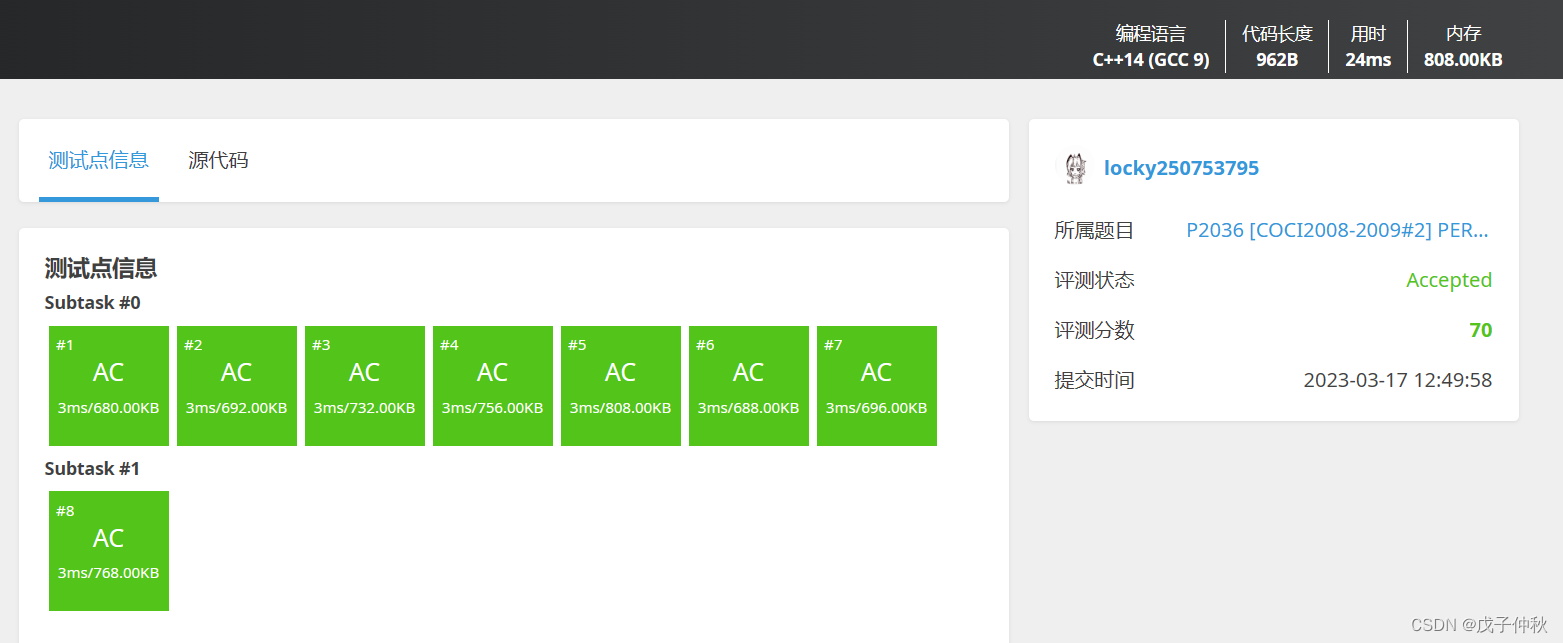
【洛谷刷题】蓝桥杯专题突破-深度优先搜索-dfs(5)
目录 写在前面: 题目:P2036 [COCI2008-2009#2] PERKET - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 解题思路: 代码…...

【Unity3D】Unity3D中在创建完项目后自动创建文件夹列表
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 随着项目开发的体量增大,要导入大量的素材、UI、模…...
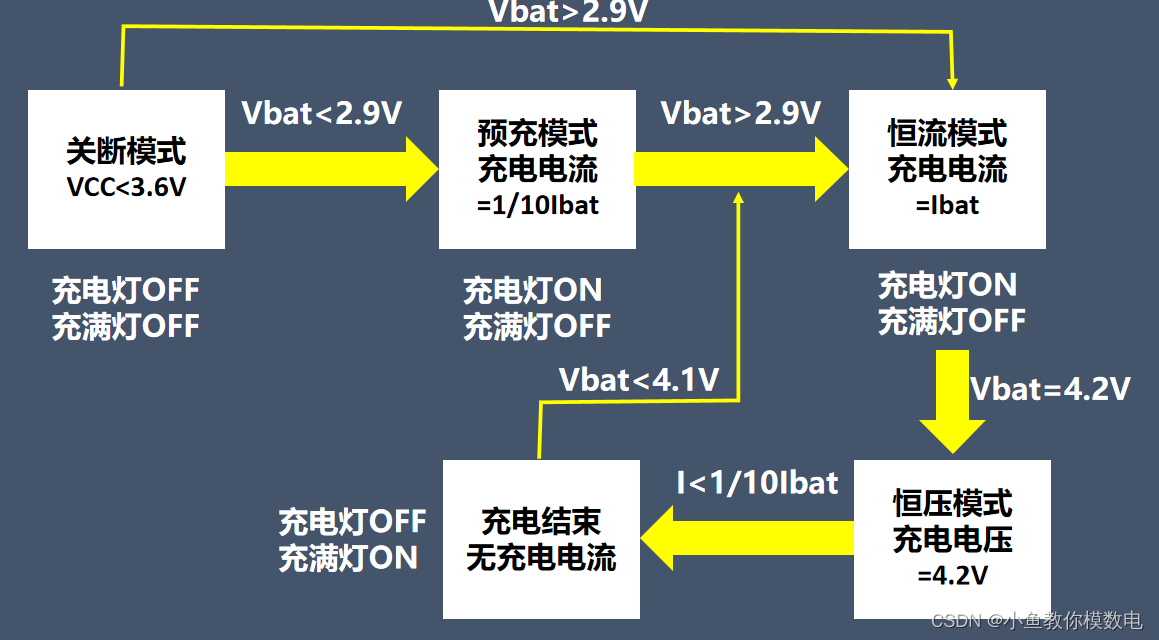
如何设计一个锂电池充电电路(TP4056)
这个是个单节18650锂电池的充电模块,这个是个18650的锂电池,18指的是它的直径是18mm,65指的是它的高度为65mm。这个18650电池的标称电压是3.7V,电池充满时电压为4.2V,一般电池电压越高也就代表它所剩的电量越大。这种锂…...

Spark了解
目录 1 概述 2 发展 3 Spark和Hadoop 4 Spark核心模块 1 概述 Apache Spark是一个快速、通用、可扩展的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发。 Spark可以处理大规模数据处理任务,包括批处理、迭代式算法、交互式查询和流处理等。Spa…...

c++STL急急急
文章目录cSTL急急急vector头文件扩容过程用法:size/emptyclear迭代器begin/endfront/backpush_back() 和 pop_back()queue头文件用法循环队列 queue用法优先队列 priority_queue用法stack头文件deque头文件deque中控器:用法set头文件用法迭代器begin/end…...

Go性能剖析pprof工具使用
Go语言凭借其高效的并发模型和简洁的语法,成为众多开发者的首选。随着项目规模扩大,性能问题逐渐显现。如何快速定位性能瓶颈?Go内置的pprof工具正是解决这一问题的利器。本文将带你深入了解pprof的核心功能,助你轻松优化代码性能…...
构建Pixel Couplet Gen的微信小程序:让AI春联触手可及
构建Pixel Couplet Gen的微信小程序:让AI春联触手可及 1. 项目背景与价值 春节贴春联是中国传统文化的重要组成部分,但现代人往往缺乏时间和书法技能来创作个性化春联。Pixel Couplet Gen作为一款AI春联生成模型,能够根据用户输入自动生成像…...

终极RPA档案解析指南:unrpa工具的专业实现与优化策略
终极RPA档案解析指南:unrpa工具的专业实现与优化策略 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 在RenPy视觉小说游戏开发与逆向工程领域,RPA档案格式…...

Ubuntu 22.04上,用Cephadm 17.2.0搭建单节点Ceph集群的保姆级避坑指南
Ubuntu 22.04单节点Ceph集群实战:从零到生产级部署的17个关键细节 当你在Ubuntu 22.04上尝试用Cephadm搭建单节点Ceph集群时,是否遇到过这些场景:bootstrap卡在某个步骤超过半小时、OSD设备明明存在却显示"no available devices"、…...

3种方法永久解决IDM激活弹窗问题 开源工具全解析
3种方法永久解决IDM激活弹窗问题 开源工具全解析 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM)作为一款…...

AirPods Pro 3 与 Bose QC Ultra Earbuds 2:无线耳机市场的激烈较量
AirPods Pro 3 与 Bose QC Ultra Earbuds 2:新功能大比拼最新款的 AirPods Pro 3 引入了一系列新功能,提升了音频效果,增强了降噪能力,还具备助听模式、实时翻译、自动切换、空间音频、心率监测等附加功能。而 Bose QuietComfort …...

Deep-Live-Cam实时换脸诊断指南:从启动失败到流畅运行的快速修复方案
Deep-Live-Cam实时换脸诊断指南:从启动失败到流畅运行的快速修复方案 【免费下载链接】Deep-Live-Cam real time face swap and one-click video deepfake with only a single image 项目地址: https://gitcode.com/GitHub_Trending/de/Deep-Live-Cam Deep-L…...

Fish-Speech 1.5效果展示:双自回归Transformer架构,语音质量惊艳
Fish-Speech 1.5效果展示:双自回归Transformer架构,语音质量惊艳 你听过那种一听就知道是机器人的AI语音吗?生硬、刻板,每个字都像从模板里抠出来的,毫无生气。再听听这个:“今天天气真好,适合…...
WSL + NFS 网络启动踩坑记:从挂载失败到成功启动的完整历程)
2026年正点原子开发板移植方案——从0开始的Rootfs之路(5)WSL + NFS 网络启动踩坑记:从挂载失败到成功启动的完整历程
2026年正点原子开发板移植方案——从0开始的Rootfs之路(5)WSL NFS 网络启动踩坑记:从挂载失败到成功启动的完整历程项目已经开源!尝试使用IMX-Forge给你的开发板跑新的Linux 7.0内核:https://github.com/Awesome-Embe…...

Postman实战指南:深入解析CORS预检请求与响应头配置
1. 为什么CORS会成为开发者的噩梦? 第一次遇到CORS问题时,我盯着浏览器控制台那个鲜红的报错信息整整发呆了十分钟。"Access-Control-Allow-Origin"这个看起来人畜无害的响应头,竟然能让整个前端应用瘫痪。后来才发现,这…...