Spark了解
目录
1 概述
2 发展
3 Spark和Hadoop
4 Spark核心模块
1 概述
Apache Spark是一个快速、通用、可扩展的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发。
Spark可以处理大规模数据处理任务,包括批处理、迭代式算法、交互式查询和流处理等。Spark支持多种编程语言,包括Java、Scala、Python和R等。Spark的核心概念是弹性分布式数据集(Resilient Distributed Dataset,简称RDD),它是一个分布式的内存抽象,可以让开发者在内存中高效地处理数据。
Spark还提供了许多高级工具,包括Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图处理库),这些工具可以让开发者更方便地处理数据和构建分布式应用程序。
- Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了 Spark 最基础与最核心的功能
- Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
2 发展
- 2009 年,Spark 诞生于伯克利大学的AMPLab 实验室
- 2010 年,伯克利大学正式开源了 Spark 项目
- 2013 年 6 月,Spark 成为了 Apache 基金会下的项目
- 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目
- 2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark
3 Spark和Hadoop
Hadoop 的 MR 框架和Spark 框架都是数据处理框架,那么我们在使用时如何选择?
- Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以 Spark 应运而生,Spark 就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD 计算模型。
- 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。
- Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
- Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
- Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互
- Spark 的缓存机制比HDFS 的缓存机制高效。
经过上面的比较,可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce 更有优势。但是Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
4 Spark核心模块

- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
- Spark SQL
Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
- Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
相关文章:
Spark了解
目录 1 概述 2 发展 3 Spark和Hadoop 4 Spark核心模块 1 概述 Apache Spark是一个快速、通用、可扩展的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发。 Spark可以处理大规模数据处理任务,包括批处理、迭代式算法、交互式查询和流处理等。Spa…...

c++STL急急急
文章目录cSTL急急急vector头文件扩容过程用法:size/emptyclear迭代器begin/endfront/backpush_back() 和 pop_back()queue头文件用法循环队列 queue用法优先队列 priority_queue用法stack头文件deque头文件deque中控器:用法set头文件用法迭代器begin/end…...
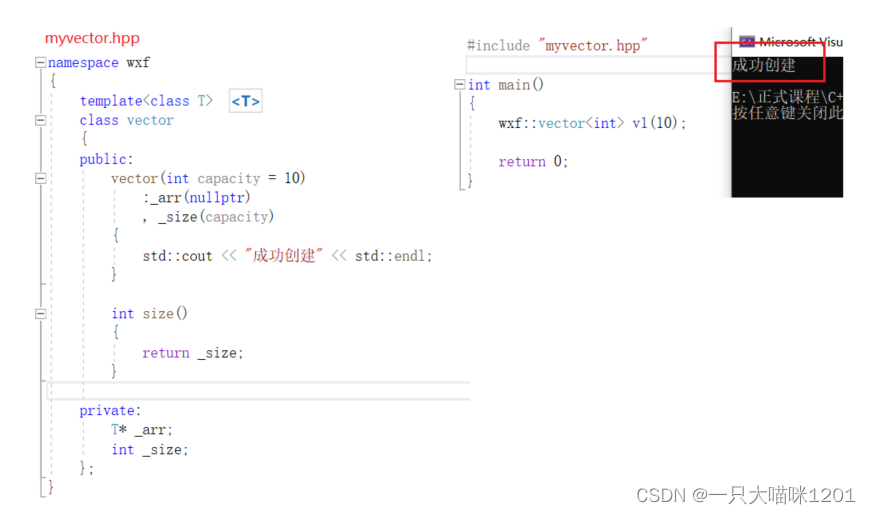
【C++学习】模板进阶——非类型模板参数 | 模板的特化 | 分离编译
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! 模板我们之前一直都在使用,尤其是在模拟STL容器的时候,可以说,模板…...

【C++】C++11新特性——可变参数模板|function|bind
文章目录一、可变参数模板1.1 可变参数的函数模板1.2 递归函数方式展开参数包1.3 逗号表达式展开参数包1.4 empalce相关接口函数二、包装器function2.1 function用法2.2 例题:逆波兰表达式求值2.3 验证三、绑定函数bind3.1 调整参数顺序3.2 固定绑定参数一、可变参数…...

ssm框架之spring:浅聊事务--JdbcTemplate
简介 JdbcTemplate 是 Spring 对 JDBC 的封装,目的是使JDBC更加易于使用,JdbcTemplate是Spring的一部分。JdbcTemplate 处理了资源的建立和释放,它帮助我们避免一些常见的错误,比如忘了总要关闭连接。他运行核心的JDBC工作流&…...

盘点Python那些简单实用的第三方库
文章目录前言关于本文使用 pip 命令下载第三方库1、phone 库(获取手机号码信息)2、geoip2 库(IP 检测功能)3、freegames 库(免费小游戏)4、jionlp 库(解析地址信息)5、pyqrcode 库&a…...

leetCode热题21-26 解题代码,调试代码和思路
前言 本文属于特定的六道题目题解和调试代码。 1 ✔ [160]相交链表 Easy 2023-03-17 171 2 ✔ [54]螺旋矩阵 Medium 2023-03-17 169 3 ✔ [23]合并K个排序链表 Hard 2022-12-08 158 4 ✔ [92]反转链表 II Medium 2023-03-01 155 5 ✔ [415]字符串相加 Easy 2023-03-14 150 6 …...

ChatGPT推出第四代GPT-4!不仅能聊天,还可以图片创作!
3月15日凌晨,OpenAI震撼发布了多模态预训练大模型 GPT-4。 根据官网发布的通告可以知道,GPT-4 实现了以下几个方面的飞跃式提升:强大的AI创作识图能力;文字输入限制提升至 2.5 万字;回答准确性显著提高;能够…...
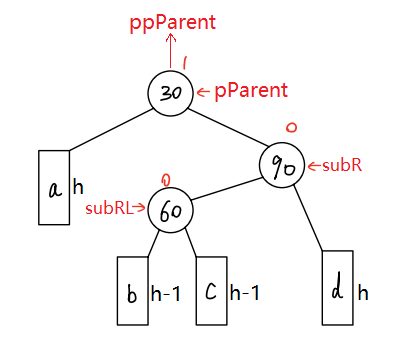
二叉搜索树:AVL平衡
文章目录一、 二叉搜索树1.1 概念1.2 操作1.3 代码实现二、二叉搜索树的应用K模型和KV模型三、二叉搜索树的性能分析四、AVL树4.1 AVL树的概念4.2 AVL树的实现原理4.3 旋转4.4 AVL树最终代码一、 二叉搜索树 1.1 概念 二叉搜索树( Binary Search Tree,…...
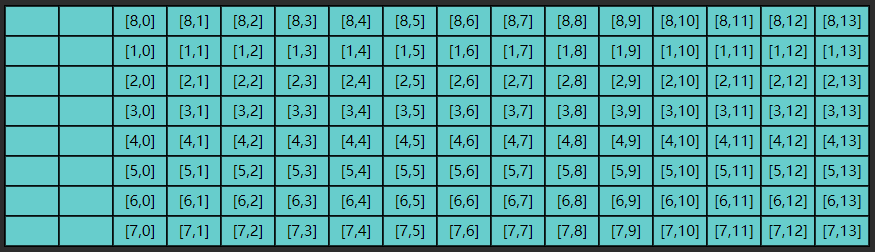
数据结构和算法(1):数组
目录概述动态数组二维数组局部性原理越界检查概述 定义 在计算机科学中,数组是由一组元素(值或变量)组成的数据结构,每个元素有至少一个索引或键来标识 In computer science, an array is a data structure consisting of a col…...
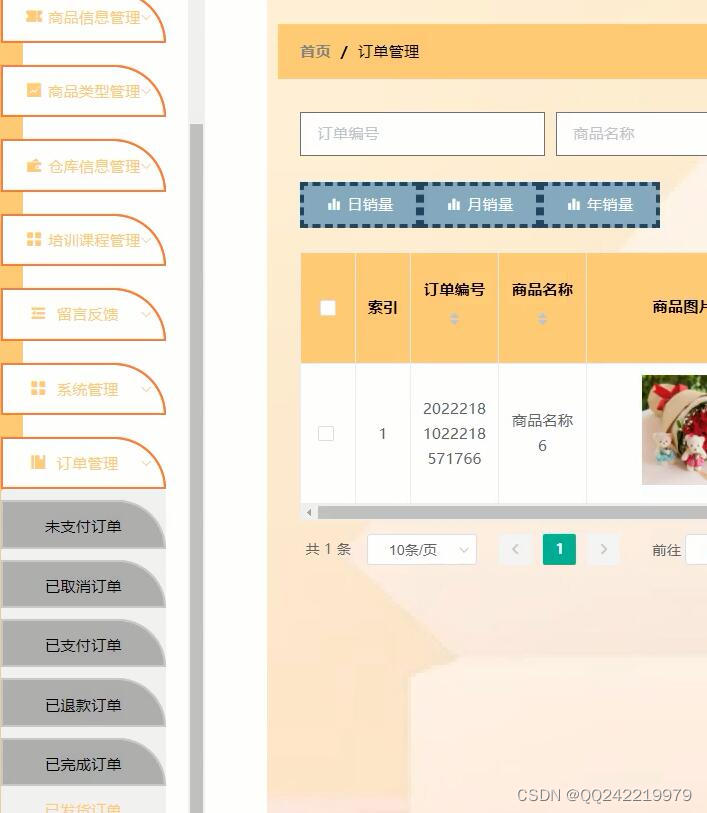
python+django+vue全家桶鲜花商城售卖系统
重点: (1) 网上花店网站中各模块功能之间的的串联。 (2) 网上花店网站前台与后台的连接与同步。 (3) 鲜花信息管理模块中鲜花的发布、更新与删除。 (4) 订单…...
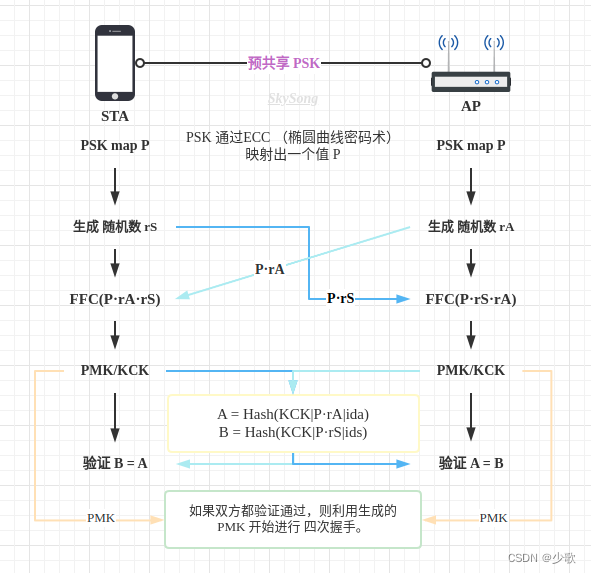
一文带你领略 WPA3-SAE 的 “安全感”
引入 WPA3-SAE也是针对四次握手的协议。 四次握手是 AP (authenticator) 和 (supplicant)进行四次信息交互,生成一个用于加密无线数据的秘钥。 这个过程发生在 WIFI 连接 的 过程。 为了更好的阐述 WPA3-SAE 的作用 …...
Python解题 - CSDN周赛第38期
又来拯救公主了。。。本期四道题还是都考过,而且后面两道问哥在以前写的题解里给出了详细的代码(当然是python版),直接复制粘贴就可以过了——尽管这样显得有失公允,考虑到以后还会出现重复的考题,所以现在…...
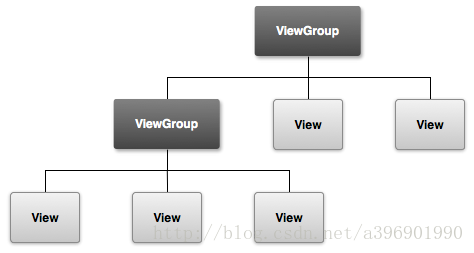
Android绘制——自定义view之onLayout
简介 在自定义view的时候,其实很简单,只需要知道3步骤: 测量——onMeasure():决定View的大小,关于此请阅读《Android自定义控件之onMeasure》布局——onLayout():决定View在ViewGroup中的位置绘制——onD…...

用Qt画一个温度计
示例1 以下是用Qt绘制一个简单的温度计的示例代码: #include <QPainter> #include <QWidget> #include <QApplication> class Thermometer : public QWidget { public:Thermometer(QWidget *parent 0); protected:void paintEvent(QPaintEvent …...
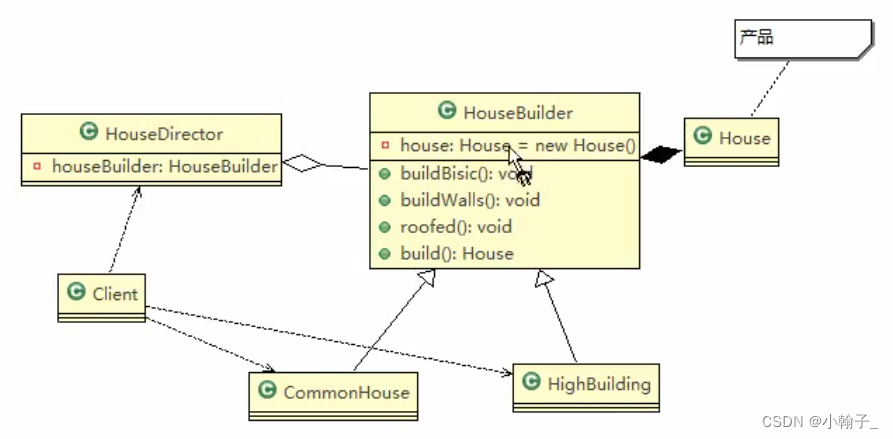
Java设计模式 04-建造者模式
建造者模式 一、 盖房项目需求 1)需要建房子:这一过程为打桩、砌墙、封顶 2)房子有各种各样的,比如普通房,高楼,别墅,各种房子的过程虽然一样,但是要求不要相同的. 3)请编写程序,完成需求. …...

安语未公告于2023年3月20日发布
因一些特殊原因,凡事都是有开始,高潮和结束三大过程,做出以下决定: 所有对 安语未文章 为之热爱、鞭策、奉献,和支持过的开发者: 注:所有资源以及资料都会正常下载和查看 如需联系࿱…...

进销存是什么?如何选择进销存系统?
什么是进销存?进销存软件概念起源于上世纪80年代,由于电算化的普及,计算机管理的推广,不少企业对于仓库货品的进货,存货,出货管理,有了强烈的需求,进销存软件的发展从此开始。 进入…...

基于BP神经网络的图像跟踪,基于BP神经网络的细胞追踪识别
目录 摘要 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络激活函数及公式 基于BP神经网络的细胞识别追踪 matab编程代码 效果 结果分析 展望 摘要 智能驾驶,智能出行是现代社会发展的趋势之一,其中,客量预测对智能出行至关重要,…...
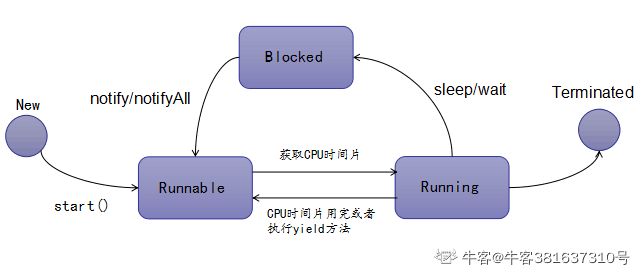
Java面试总结篇
引用介绍 1.线程安全不安全的概念 线程安全: 指多个线程在执行同一段代码的时候采用加锁机制,使每次的执行结果和单线程执行的结果都是一样的,不存在执行程序时出现意外结果。 线程不安全: 是指不提供加锁机制保护,有可能出现多个线程先后更改数据造成所得到的数据是脏…...

JSW-8016GM4 加固交换机
■ 三层交换机,功能强大 ■ 支持16个10/100/1000M 以太网接口 ■ 支持4个10G光纤接口 ■ 支持IEEE802相关协议 ■ 2U高度,可在方舱上架安装 ■ 满足电磁兼容要求 ■ 整机加固设计,满足国军标相关要求主要参数产品类型:千兆以太网交…...

汇智信科-机场数字孪生系统
机场数字孪生系统以数字化孪生技术构建机场全要素虚拟映射,精准还原机场、跑道、塔台等设施及飞机运行状态,支持多维度动态监测与可视化管控;通过模拟飞机调度、跑道滑行等全流程作业场景,覆盖机场多角色业务协同,同时…...

Qwen3.5-9B多场景应用:心理咨询对话记录分析+情绪倾向识别案例
Qwen3.5-9B多场景应用:心理咨询对话记录分析情绪倾向识别案例 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。该模型特别适合处理心理咨询对话记录分析任务,能够准确识别对话中的…...

从Simulink模型到神经网络:一个完整的数据驱动建模与验证实践
1. 为什么需要从Simulink模型转向神经网络? 在控制系统工程领域,Simulink模型一直是建模和仿真的黄金标准。但最近几年,越来越多的工程师开始尝试用神经网络来替代传统模型。这背后有几个关键原因: 首先,传统物理模型在…...

ubuntu秘钥生成PKCS1 格式秘钥
openssl genrsa -out key 2048 openssl rsa -in key -out key2 -traditional...

新手福音:在快马平台开启你的云端代码编程第一课
作为一名刚接触编程的新手,我最近发现了一个特别适合入门的学习方式——云端代码编程。以前总觉得学编程要先装一堆软件、配置环境,光是这些准备工作就能劝退不少人。但在InsCode(快马)平台上,这些烦恼都不存在了。 零门槛的编程初体验 打开平…...

485总线硬件设计必看:电平匹配、TVS防护,还有exmodbus库快速上手
RS485是工业物联网的标配通信接口。合宙Air780EHV系列Cat.1模组凭借强大外设扩展能力(LCD、摄像头、以太网、CAN等)和LuatOS高效开发环境,支持TCP/MQTT/HTTP/Modbus等主流协议,是工业场景的高性价比之选。 本文聚焦RS485实战&…...

2026最权威的AI写作神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术研究范畴之内,人工智能技术的深度交融催生出了多种具备专业性的学术辅助平…...

Excel也能搞定GRR!不用买昂贵软件,这份保姆级模板和计算指南请收好
Excel也能搞定GRR!不用买昂贵软件,这份保姆级模板和计算指南请收好 在制造业质量管理中,测量系统分析(MSA)是确保数据可靠性的基石。但现实情况是,许多中小企业和初创团队面对动辄上万元的专业统计软件只能…...

【测试之道】第四篇:分层测试论 —— 金字塔、奖杯与蜂巢:构建你的质量防御阵型
专栏进度:04 / 10 (测试理论专题) 在不同的架构(单体、微服务、前端驱动)下,测试资源的分配比例是完全不同的。盲目套用模板是测试经理最容易犯的错误。 一、 经典模型:测试金字塔 (Testing Pyramid) 由 Mike Cohn 提出…...