Redis与MySQL的双写一致性问题
Redis与MySQL的双写一致性问题
- 更新缓存? 删除缓存?
- 先更新缓存再更新数据库
- 先更新数据库,再更新缓存
- 先删除缓存再更新数据库
- 先更新数据库,再删除缓存
- 解决方案
- 1. 重试
- 2. 异步重试
- 2.1 使用消息队列实现重试
- 2.2 Binlog实现异步重试删除
- 3. 延时双删
- 总结
- 参考文章
Redis与MySQL双写一致性是指在使用缓存和数据库同时存储数据的场景下( 主要是存在高并发的情况),如何保证两者的数据一致性(内容相同或者尽可能接近)。
正常业务流程:
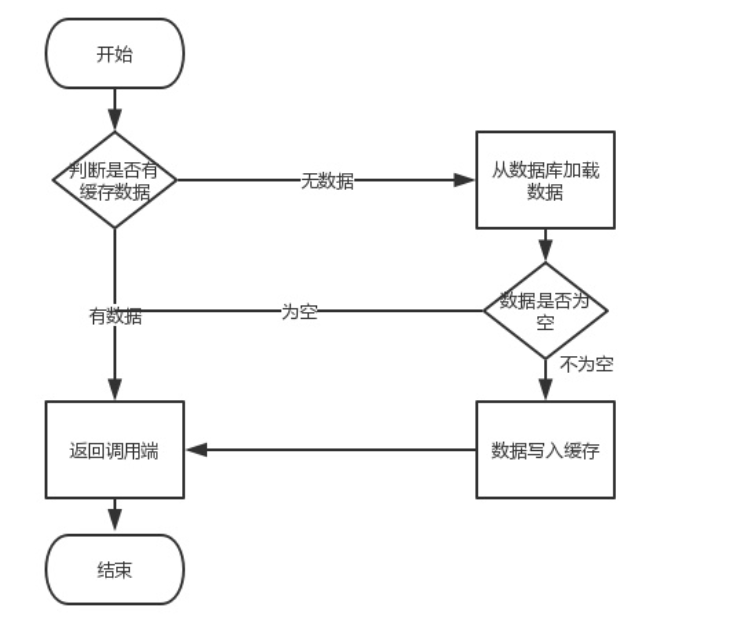
读没什么问题,关键就在于写(更新)操作,这就会出现几个问题了,这里是先更新数据库,然后对缓存操作。但对于缓存操作,是更新缓存还是删除缓存呢?或者为什么不是先操作(删除、更新)缓存在更新数据库呢?
总结一下就是到底先操作缓存再操作数据库,还是先操作数据库再操作缓存?
带着这几个问题接着往下讲。
首先讲一下操作缓存,包括两种:更新缓存和删除缓存,如何选择?
更新缓存? 删除缓存?
假设都先更新数据库(因为先操作缓存再操作数据库问题较大,后面会讲)
-
更新缓存
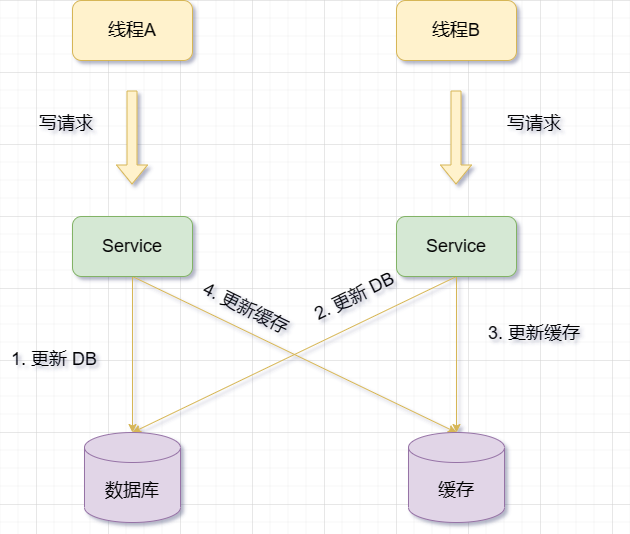
先更新数据库,再更新缓存。
如果两个请求同时对同一条数据进行修改,那么可能出现先后顺序颠倒,导致缓存中的数据是旧的。之后的读请求读到的都是旧数据,只有当缓存失效后,才能从数据库中得到正确的值。
-
删除缓存
先更新数据库,再删除缓存。
会有这样一种情况:缓存刚好失效,请求B从数据库中查询数据,得到旧值。此时请求A更新数据库,将新值写入数据库,并删除缓存。而请求B又将旧值写入缓存中,导致脏数据
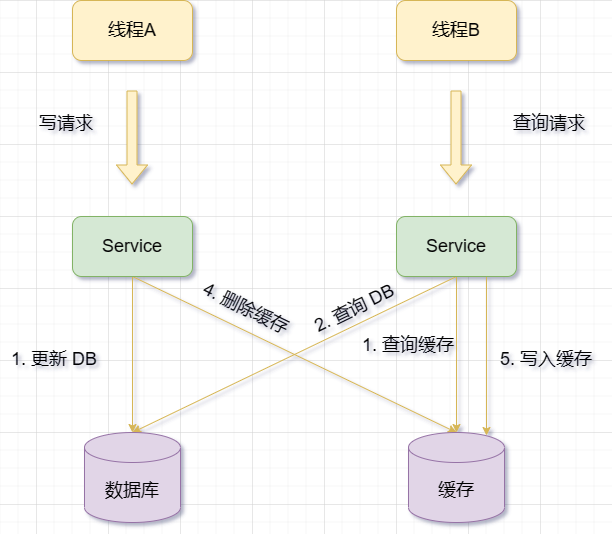
从上面看出现脏数据的要求要比更新缓存的要求更多,必须满足以下几个条件:
- 缓存失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间要比读数据库 + 写缓存时间短
前面两个很好满足,我们再看看第三点,这个真的会出现吗?
数据库在更新时一般是加锁的,读操作的速度远快于写操作的,所以第三点发生概率极低(当然也可能发生)
注:这里我其实不是很理解,单纯看确实发生概率低,但如果出现网络延迟等情况呢,不也会发生吗?希望好心人解惑,我反正没理解。
因此,在选择删除缓存时,还需要结合其他技术来优化性能和一致性。例如:
- 使用消息队列来异步地删除或更新缓存,避免阻塞主线程或者丢失消息。
- 使用延时双删来增加删除成功率和减少不一致时间窗口。即在更新数据库后立即删除一次缓存,并在一定时间间隔后再次删除一次。
对比
在更新缓存中, 每次去更新缓存,但是缓存中的数据不一定会被马上读取,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。而且很多情况下,写到缓存中的值,并不是与数据库中的值一一对应的,很有可能是先查询数据库,再经过一系列「计算」得出一个值,才把这个值才写到缓存中。
由此可见,这种更新缓存的方案,不仅缓存利用率不高,还会造成机器性能的浪费。所以我们一般考虑删除缓存
先更新缓存再更新数据库
在更新数据时,先将新数据写入缓存(Redis),再将新数据写入数据库(MySQL)
但其存在一下问题:
-
缓存更新成功,但数据库更新失败,导致数据不一致
例:用户修改了自己的昵称,系统先将新的昵称写入缓存,然后再更新数据库。但是在更新数据库的过程中,发生了网络故障或者数据库宕机等异常情况,导致数据库中的昵称没有被修改。这样就会出现缓存中的昵称和数据库中的昵称不一致的情况。
-
缓存更新成功,但数据库更新延迟,导致其他请求读取到旧的数据
例:用户下单了一个商品,系统先将订单状态写入缓存,然后再更新数据库。但是在更新数据库的过程中,由于并发量大或者其他原因,导致数据库的写入速度慢于缓存的写入速度。这样就会出现其他请求从缓存中读取到订单状态为已支付,而从数据库中读取到订单状态为未支付的情况。
-
缓存更新成功,但在数据库更新之前有其他请求查询了缓存和数据库,并将旧的数据写回缓存,覆盖了新的数据
例:用户A修改了自己的头像,并上传到服务器上。系统先将新的头像地址写入缓存,并返回给用户A显示。然后再将新的头像地址更新到数据库中。但是在这个过程中,用户B访问了用户A的个人主页,并从缓存中读取到了新的头像地址。由于缓存失效策略或者其他原因(比如重启),导致缓存被清空或者过期。这时候用户B再次访问用户A 的个人主页,并从数据库中读取到了旧的头像地址,并将其写回缓存中。这样就会出现缓存中 的头像地址和 数据库 中 的头像地址不一致 的情况。
上面说了一堆,其实总结就是缓存更新成功了,数据库没更新(更新失败),导致缓存存的是最新值,数据库存的是旧值。如果缓存失效了,就会拿到数据库中的旧值。
后面我自己也搞疑惑了,既然是因为数据库更新失败导致的问题,那我是不是只要保证数据库更新成功就可以解决数据不一致的问题,当数据库更新失败时,不停的重试更新数据库,直到数据库更新完成。
后面发现自己太天真,其中存在很多问题,比如:
- 如果数据库更新失败的原因是数据库宕机或者网络故障,那么你不停地重试更新数据库可能会造成更大的压力和延迟,甚至导致数据库恢复困难。
- 如果数据库更新失败的原因是数据冲突或者业务逻辑错误,那么你不停地重试更新数据库可能会导致数据丢失或者数据错乱,甚至影响其他用户的数据。
- 如果你不停地重试更新数据库,那么你需要考虑如何保证重试的幂等性和顺序性,以及如何处理重试过程中发生的异常情况。
所以,这种方法并不是一个很好的解决方案。
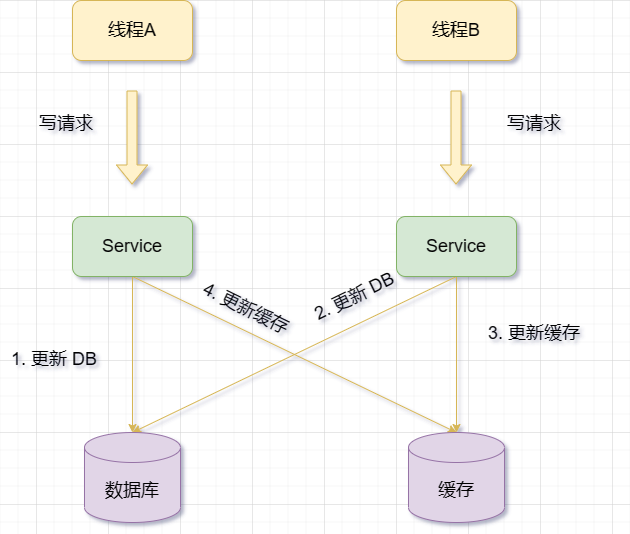
先更新数据库,再更新缓存
当有一个更新操作时,先更新数据库数据,然后再更新对应的缓存数据
但是,这种方案也有一些问题和风险,比如:
- 如果更新数据库成功了,但是更新缓存失败了,那么就会导致缓存中就会保留旧的数据,而数据库中已经是新的数据,即脏数据。
- 如果在更新数据库和更新缓存之间,有其他请求查询了同一个数据,并且发现缓存存在,那么就会从缓存中读取旧的数据。这样也会造成缓存和数据库之间的不一致性。
因此,在使用更新缓存操作时,无论谁先谁后,但凡后者发生异常,就会对业务造成影响。(还是上面那张图)
那么如何处理异常情况来保证数据一致性呢
这些问题的源头都是多线程并发所导致的,所以最简单的方法就是加锁(分布式锁)。两个线程要修改同一条数据,每个线程在改之前,先去申请分布式锁,拿到锁的线程才允许更新数据库和缓存,拿不到锁的线程,返回失败,等待下次重试。这么做的目的,就是为了只允许一个线程去操作数据和缓存,避免并发问题。
但加锁费时费力,肯定不推荐。并且,每次去更新缓存,但是缓存中的数据不一定会被马上读取,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。而且很多情况下,写到缓存中的值,并不是与数据库中的值一一对应的,很有可能是先查询数据库,再经过一系列「计算」得出一个值,才把这个值才写到缓存中。
由此可见,这种更新数据库 + 更新缓存的方案,不仅缓存利用率不高,还会造成机器性能的浪费。
所以此时我们需要考虑另外一种方案:删除缓存
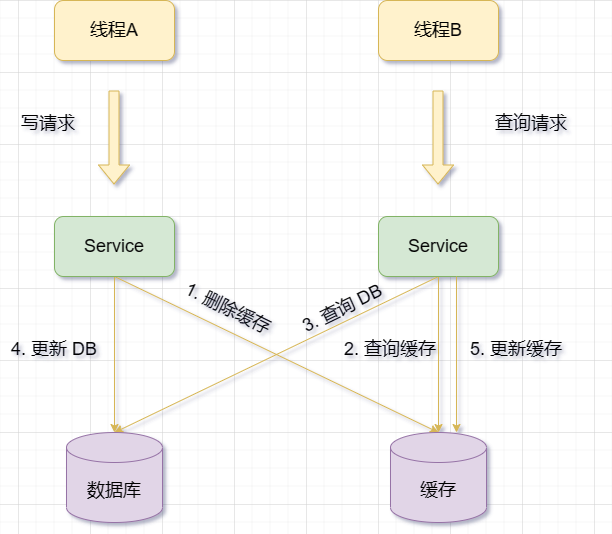
先删除缓存再更新数据库
当有一个更新操作时,先删除对应的缓存数据,然后再更新数据库数据
但是,这种方案也有一些问题和风险,比如:
- 如果删除缓存后,更新数据库失败了,那么就会导致缓存丢失,下次查询时需要重新从数据库加载数据,增加了数据库压力和响应时间。
- 如果在删除缓存和更新数据库之间,有其他请求查询了同一个数据,并且发现缓存不存在,那么就会从数据库中读取旧的数据,并写入到缓存中。这样就会造成缓存和数据库之间的不一致性。
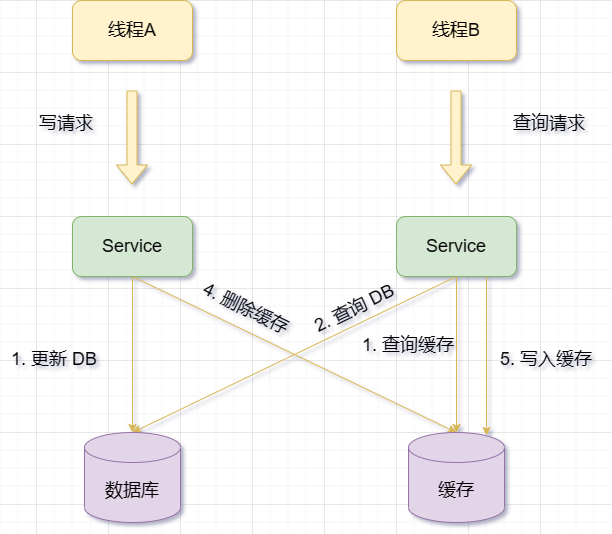
先更新数据库,再删除缓存
当有一个更新操作时,先更新数据库数据,再删除缓存
上面其实讲过了,我再重复一遍吧
会有这样一种情况:缓存刚好失效,请求B从数据库中查询数据,得到旧值。此时请求A更新数据库,将新值写入数据库,并删除缓存。而请求B又将旧值写入缓存中,导致脏数据
从上面看出现脏数据的要求要比更新缓存的要求更多,必须满足以下几个条件:
- 缓存失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间要比读数据库 + 写缓存时间短
前面两个很好满足,我们再看看第三点,这个真的会出现吗?
数据库在更新时一般是加锁的,读操作的速度远快于写操作的,所以第三点发生概率极低
所以,解决双写问题更适合的方法是先更新数据库,再删除缓存,当然具体场景具体分析,不定说一定就是这个。
讲解了这些操作后会出现的问题,那么为了避免这些问题,如何做呢?
- 先删除缓存再更新数据库,然后使用异步线程或消息队列来重建缓存。
- 先更新数据库再删除缓存,并设置一个合理的过期时间来保证缓存的有效性。
- 使用分布式锁或乐观锁来控制并发访问,并保证每次只有一个请求能够操作缓存和数据库
……
下面讲几种常见的方法以保证双写一致性
解决方案
1. 重试
上面也提到过,当第二步操作失败时,我就重试嘛,尽可能地补救,但重试的成本太大,上面讲过就不重复了。
2. 异步重试
既然重试方法占用资源,那我就做异步。在删除或更新缓存时,如果操作失败,不立即返回错误,而是通过一些机制(如消息队列、定时任务、订阅binlog等)来触发缓存的重试操作。这样可以避免同步重试缓存时的性能损耗和阻塞问题,但也可能导致缓存和数据库的数据不一致的时间较长。
2.1 使用消息队列实现重试
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的需求)
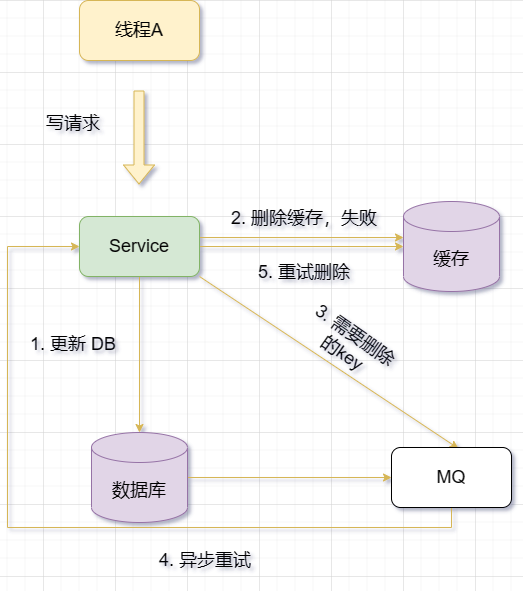
使用消息队列异步重试缓存的情况是指,当信息发生变化时,先更新数据库,然后删缓存,如果删除成功就皆大欢喜,如果删除失败,则将需要删除的key发送到消息队列。另外有一个消费者线程从消息队列中获取要删除的key,并根据key删除或更新Redis中的缓存。如果操作失败,则重新发送到消息队列中进行重试。
注:也可以不先尝试删除,直接发送给消息队列,让消息队列
举例来说,假设有一个用户信息表,需要将用户信息缓存在Redis中。如果采用使用消息队列异步重试缓存的方案,可以有以下几个步骤:
- 当用户信息发生变化时,先更新数据库,并返回成功结果给前端。
- 尝试去删除缓存,成功则结束操作,失败则将要删除或更新缓存的操作生成一个消息(比如包含key和操作类型),并发送到消息队列中(比如使用Kafka或RabbitMQ)。
- 另外有一个消费者线程从消息队列中订阅并获取这些消息,并根据消息内容删除或更新Redis中的对应信息。
- 如果删除或更新缓存成功,则把这个消息从消息队列中移除(丢弃),以免重复操作。
- 如果删除或更新缓存失败,则执行失败策略,比如设置一个延迟时间或者一个重试次数限制,然后重新发送这个消息到消息队列中进行重试。
- 如果重试超过一定次数仍然失败,则向业务层发送报错信息,并记录日志。
2.2 Binlog实现异步重试删除
使用binlog实现一致性的基本思路是利用binlog日志来记录数据库的变更操作,然后通过主从复制或者增量备份的方式来同步或者恢复数据。
举例来说,如果我们有一个主数据库和一个从数据库,我们可以在主数据库上开启binlog日志,并设置从数据库作为它的复制节点。这样,当主数据库上发生任何变更操作时,它会将对应的binlog日志发送给从数据库,从数据库则会根据binlog日志来执行相同的操作,从而保证数据一致性。
另外,如果我们需要恢复某个时间点之前的数据,我们也可以利用binlog日志来实现。首先,我们需要找到对应时间点之前的最近一个全量备份文件,并将其恢复到目标数据库。然后,我们需要找到对应时间点之前的所有增量备份文件(即binlog日志文件),并按照顺序将其应用到目标数据库。这样,我们就可以恢复出目标时间点之前的数据状态了。
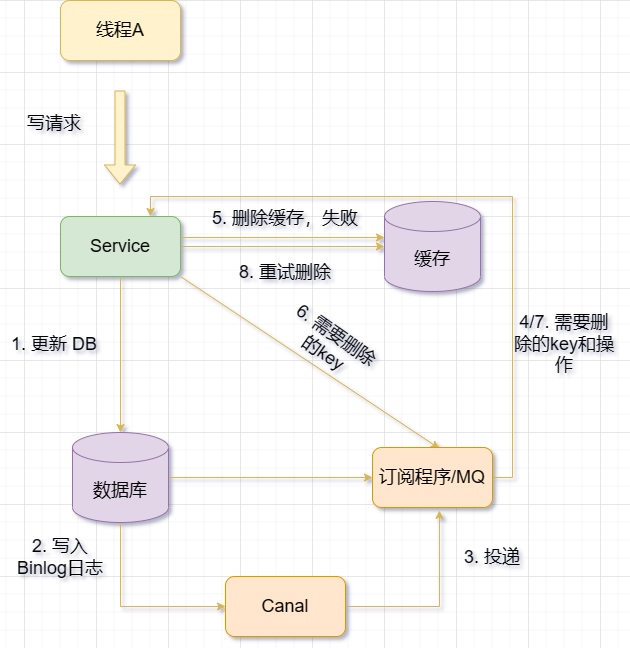
- 使用
Binlog实时更新/删除 Redis 缓存。利用Canal,即将负责更新缓存的服务伪装成一个 MySQL 的从节点,从 MySQL 接收 Binlog,解析 Binlog 之后,得到实时的数据变更信息,然后根据变更信息去更新/删除 Redis 缓存; - MQ+Canal 策略,将
Canal Server接收到的 Binlog 数据直接投递到 MQ 进行解耦,使用 MQ 异步消费 Binlog 日志,以此进行数据同步;
注:binlog日志是MySQL的二进制日志,它记录了对数据库的变更操作,比如插入、更新、删除等。 binlog日志有两个主要作用,一个是主从复制,另一个是增量备份。
主从复制是指在一个主数据库和一个或多个从数据库之间实现数据的同步。主数据库会将自己的binlog日志发送给从数据库,从数据库则会根据binlog日志来执行相同的操作,从而保证数据一致性。这样可以提高数据的可用性和可靠性,也可以实现负载均衡和故障转移。
增量备份是指在全量备份的基础上,定期备份数据库的变更操作。全量备份是指将整个数据库的数据完整地备份到一个文件中。增量备份则是指将每次变更操作对应的binlog日志文件备份到另一个文件中。这样可以减少备份所占用的空间和时间,也可以实现灵活地恢复数据到任意时间点。
至此,我们可以得出结论,想要保证数据库和缓存一致性,推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来做。
3. 延时双删
我们重点在将先更新数据库,在删除缓存。那如果我要先删除缓存,再更新数据库呢?
回顾之前讲的先删除缓存,再更新数据库,它会出现旧值覆盖缓存的问题,那好办,我们直接把这个旧值给删了不就完了吗,延时双删就是这个原理,它的基本思路是:
- 先删除缓存
- 再更新数据库
- 休眠一段时间(根据系统情况确定)
- 再次删除缓存
这样做的目的是为了防止在更新数据库后,有其他线程读取到旧的缓存数据,并将其写回缓存,导致数据不一致。
举个例子:假设有一个用户信息表,其中有一个字段是用户积分。现在有两个线程A和B同时对用户积分进行操作:
- 线程A要给用户增加100积分
- 线程B要给用户减少50积分
如果使用延时双删策略,那么线程A和B的执行过程可能如下:
-
线程A先删除缓存中的用户信息
-
线程A再从数据库中读取用户信息,发现用户积分为1000
-
线程A将用户积分加上100,变为1100,并更新到数据库中
-
线程A休眠5秒(假设这个时间足够让数据库同步)
-
线程A再次删除缓存中的用户信息
-
线程B先删除缓存中的用户信息
-
线程B再从数据库中读取用户信息,发现用户积分为1100(因为线程A已经更新了)
-
线程B将用户积分减去50,变为1050,并更新到数据库中
-
线程B休眠5秒(假设这个时间足够让数据库同步)
-
线程B再次删除缓存中的用户信息
这样最终结果就是:数据库中的用户积分为1050,缓存中没有该用户信息。当下次有请求查询该用户信息时,就会从数据库中读取并写入到缓存中。这样就保证了数据一致性。
延时双删适用于高并发场景,特别是对数据的修改操作比较频繁,而查询操作比较少的情况。这样可以减轻数据库的压力,提高性能,同时保证数据的最终一致性。延时双删也适用于数据库有主从同步延迟的场景,因为它可以避免在更新数据库后,从库还没有同步完成时,读取到旧的缓存数据,并将其写回缓存。
注: 这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
总结
好了,总结一下这篇文章的重点。
Redis与MySQL的双写一致性问题是指在使用缓存和数据库同时存储数据的场景下,如何保证两者的数据一致性。这个问题主要涉及到以下几个方面:
-
缓存更新策略:缓存更新策略有三种,分别是先更新缓存再更新数据库,先更新数据库再更新缓存,先删除缓存再更新数据库 和先更新数据库再删除缓存。每种策略都有可能导致数据不一致的情况。
-
数据库主从同步延迟:如果使用了主从复制模式来提高数据库的可用性和读写分离能力,那么就可能存在主从同步延迟的问题。也就是说,在主库上执行了写操作后,并不会立即同步到从库上。这样,在读取数据时,如果从主库读取,则可能获取到最新的数据;而如果从从库读取,则可能获取到旧的数据。这样也会导致与缓存中的数据不一致。
为了解决这些问题 , 可以采用以下几种方法 :
- 采用先删除缓存,再更新数据库方案,在并发场景下依旧有不一致问题,解决方案是延迟双删,但这个延迟时间很难评估。
- 采用先更新数据库,再删除缓存方案,为了保证两步都成功执行,需配合消息队列或订阅变更日志的方案来做,本质是通过重试的方式保证数据最终一致性。
- 采用先更新数据库,再删除缓存方案,读写分离 + 主从库延迟也会导致缓存和数据库不一致,缓解此问题的方案是延迟双删,凭借经验发送延迟消息到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率。
总之,根据场景选择适合自己的方案
参考文章
Redis与MySQL双写一致性方案解析 - 知乎 (zhihu.com)
美团二面:Redis与MySQL双写一致性如何保证? - 掘金 (juejin.cn)
缓存和数据库一致性问题,看这篇就够了 - 知乎 (zhihu.com)
终于水完了这篇文章,得去背面经了!!!
相关文章:
Redis与MySQL的双写一致性问题
Redis与MySQL的双写一致性问题更新缓存? 删除缓存?先更新缓存再更新数据库先更新数据库,再更新缓存先删除缓存再更新数据库先更新数据库,再删除缓存解决方案1. 重试2. 异步重试2.1 使用消息队列实现重试2.2 Binlog实现异步重试删除…...

Java基础:笔试题
文章目录Java 基础题目1. 如下代码输出什么?2. 当输入为2的时候返回值是多少?3. 如下代码输出值为多少?4. 给出一个排序好的数组:{1,2,2,3,4,5,6,7,8,9} 和一个数,求数组中连续元素的和等于所给数的子数组解析第一题第二题第三题第四题方案…...
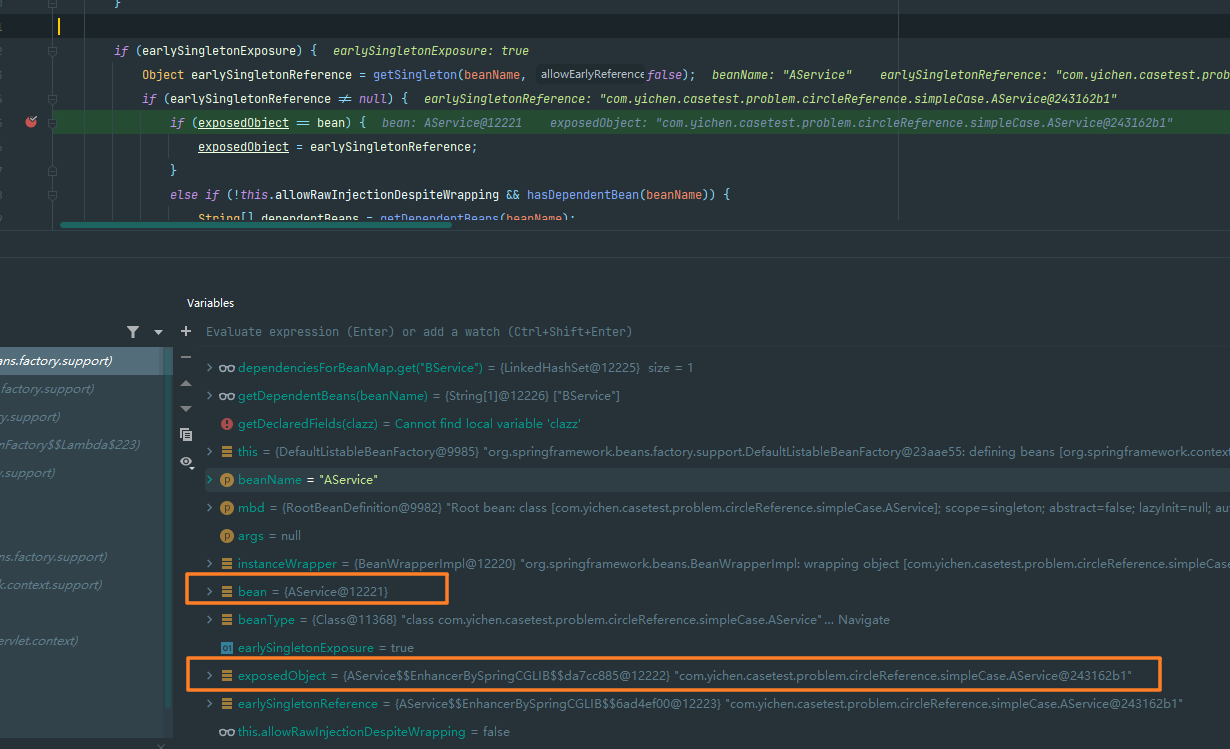
spring三级缓存以及@Async产生循环引用
spring三级缓存以及Async产生循环引用spring三级缓存介绍三级缓存解除循环引用原理源码对应1、获取A,从三级缓存中获取,没有获取到2、构造A,将A置入三级缓存构造A(创建A实例)置入缓存3、注入属性,构造B扫描缓存实例的相关信息注入…...
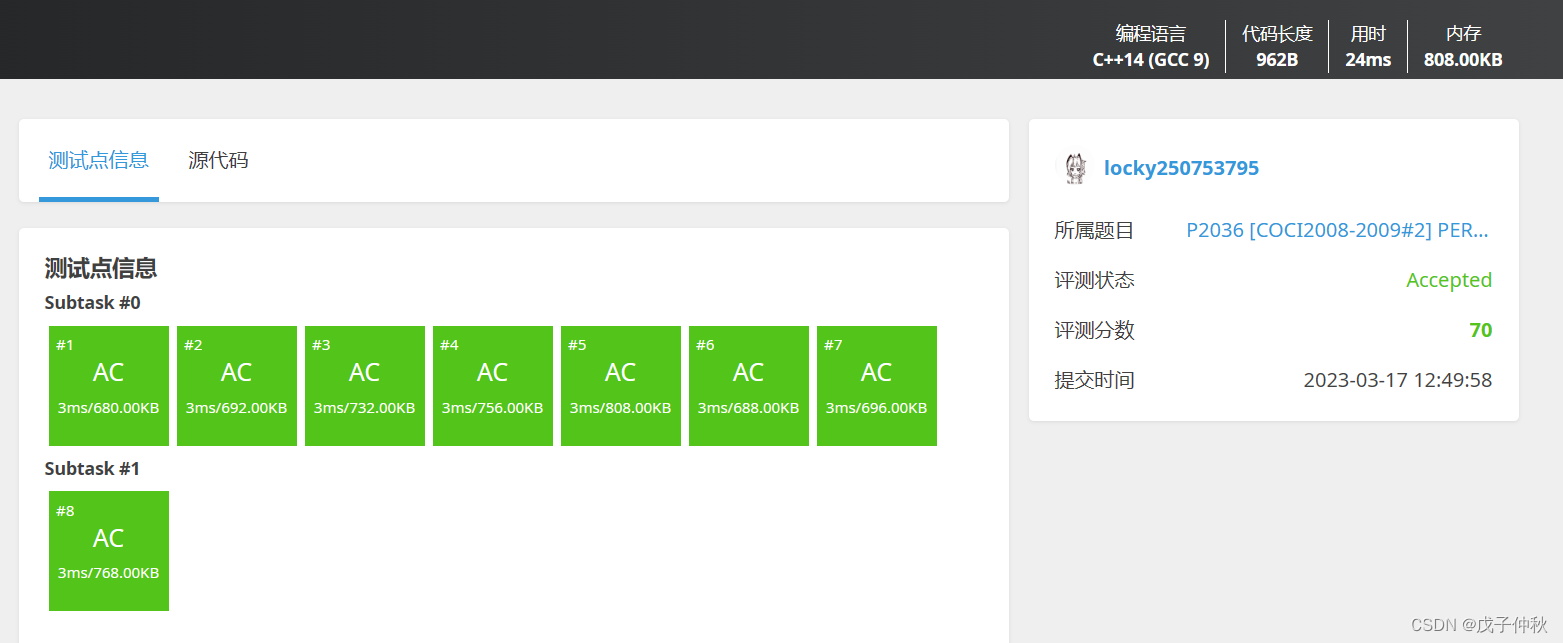
【洛谷刷题】蓝桥杯专题突破-深度优先搜索-dfs(5)
目录 写在前面: 题目:P2036 [COCI2008-2009#2] PERKET - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 解题思路: 代码…...

【Unity3D】Unity3D中在创建完项目后自动创建文件夹列表
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 随着项目开发的体量增大,要导入大量的素材、UI、模…...
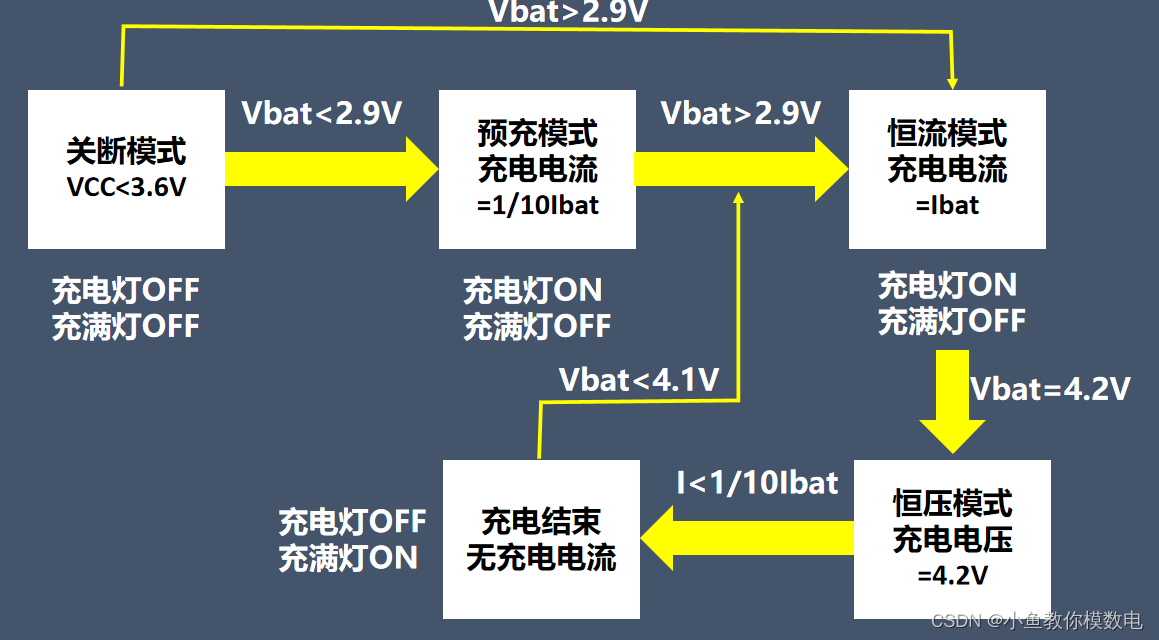
如何设计一个锂电池充电电路(TP4056)
这个是个单节18650锂电池的充电模块,这个是个18650的锂电池,18指的是它的直径是18mm,65指的是它的高度为65mm。这个18650电池的标称电压是3.7V,电池充满时电压为4.2V,一般电池电压越高也就代表它所剩的电量越大。这种锂…...

Spark了解
目录 1 概述 2 发展 3 Spark和Hadoop 4 Spark核心模块 1 概述 Apache Spark是一个快速、通用、可扩展的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发。 Spark可以处理大规模数据处理任务,包括批处理、迭代式算法、交互式查询和流处理等。Spa…...

c++STL急急急
文章目录cSTL急急急vector头文件扩容过程用法:size/emptyclear迭代器begin/endfront/backpush_back() 和 pop_back()queue头文件用法循环队列 queue用法优先队列 priority_queue用法stack头文件deque头文件deque中控器:用法set头文件用法迭代器begin/end…...
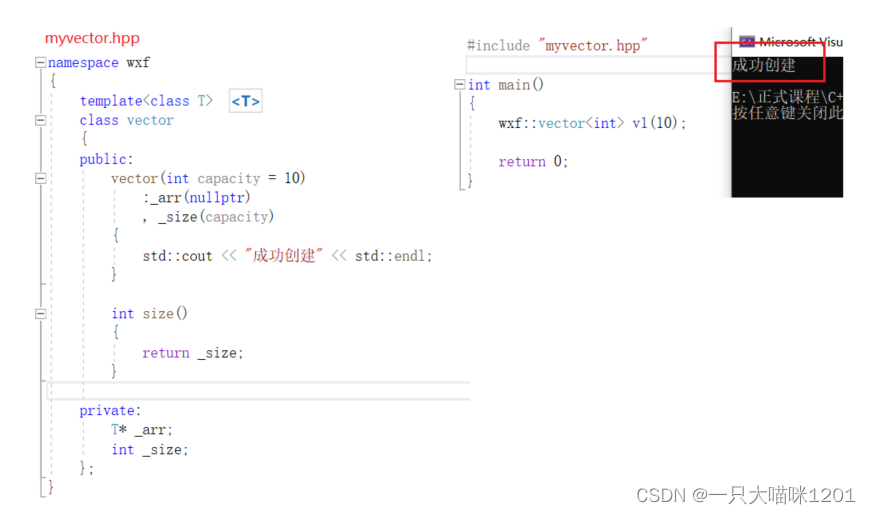
【C++学习】模板进阶——非类型模板参数 | 模板的特化 | 分离编译
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! 模板我们之前一直都在使用,尤其是在模拟STL容器的时候,可以说,模板…...

【C++】C++11新特性——可变参数模板|function|bind
文章目录一、可变参数模板1.1 可变参数的函数模板1.2 递归函数方式展开参数包1.3 逗号表达式展开参数包1.4 empalce相关接口函数二、包装器function2.1 function用法2.2 例题:逆波兰表达式求值2.3 验证三、绑定函数bind3.1 调整参数顺序3.2 固定绑定参数一、可变参数…...

ssm框架之spring:浅聊事务--JdbcTemplate
简介 JdbcTemplate 是 Spring 对 JDBC 的封装,目的是使JDBC更加易于使用,JdbcTemplate是Spring的一部分。JdbcTemplate 处理了资源的建立和释放,它帮助我们避免一些常见的错误,比如忘了总要关闭连接。他运行核心的JDBC工作流&…...

盘点Python那些简单实用的第三方库
文章目录前言关于本文使用 pip 命令下载第三方库1、phone 库(获取手机号码信息)2、geoip2 库(IP 检测功能)3、freegames 库(免费小游戏)4、jionlp 库(解析地址信息)5、pyqrcode 库&a…...

leetCode热题21-26 解题代码,调试代码和思路
前言 本文属于特定的六道题目题解和调试代码。 1 ✔ [160]相交链表 Easy 2023-03-17 171 2 ✔ [54]螺旋矩阵 Medium 2023-03-17 169 3 ✔ [23]合并K个排序链表 Hard 2022-12-08 158 4 ✔ [92]反转链表 II Medium 2023-03-01 155 5 ✔ [415]字符串相加 Easy 2023-03-14 150 6 …...

ChatGPT推出第四代GPT-4!不仅能聊天,还可以图片创作!
3月15日凌晨,OpenAI震撼发布了多模态预训练大模型 GPT-4。 根据官网发布的通告可以知道,GPT-4 实现了以下几个方面的飞跃式提升:强大的AI创作识图能力;文字输入限制提升至 2.5 万字;回答准确性显著提高;能够…...
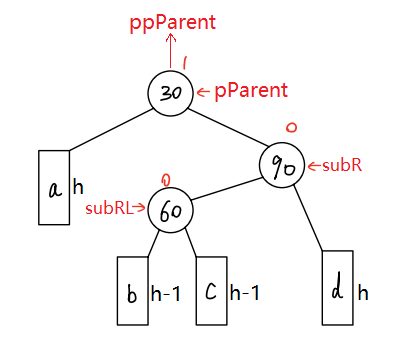
二叉搜索树:AVL平衡
文章目录一、 二叉搜索树1.1 概念1.2 操作1.3 代码实现二、二叉搜索树的应用K模型和KV模型三、二叉搜索树的性能分析四、AVL树4.1 AVL树的概念4.2 AVL树的实现原理4.3 旋转4.4 AVL树最终代码一、 二叉搜索树 1.1 概念 二叉搜索树( Binary Search Tree,…...
数据结构和算法(1):数组
目录概述动态数组二维数组局部性原理越界检查概述 定义 在计算机科学中,数组是由一组元素(值或变量)组成的数据结构,每个元素有至少一个索引或键来标识 In computer science, an array is a data structure consisting of a col…...
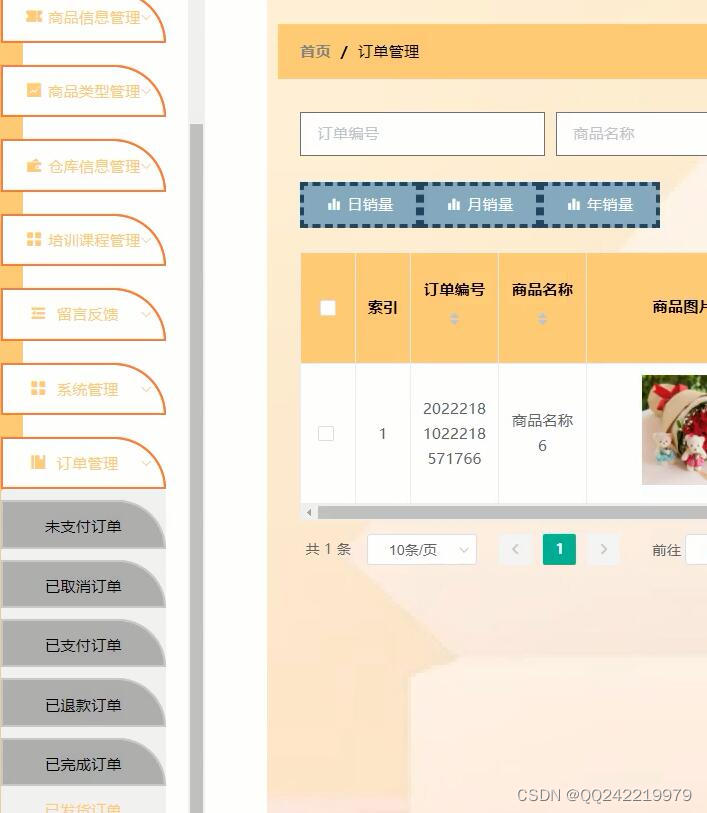
python+django+vue全家桶鲜花商城售卖系统
重点: (1) 网上花店网站中各模块功能之间的的串联。 (2) 网上花店网站前台与后台的连接与同步。 (3) 鲜花信息管理模块中鲜花的发布、更新与删除。 (4) 订单…...
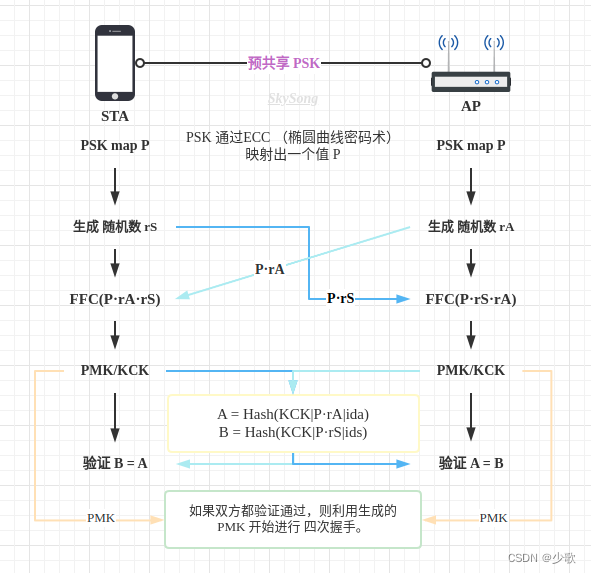
一文带你领略 WPA3-SAE 的 “安全感”
引入 WPA3-SAE也是针对四次握手的协议。 四次握手是 AP (authenticator) 和 (supplicant)进行四次信息交互,生成一个用于加密无线数据的秘钥。 这个过程发生在 WIFI 连接 的 过程。 为了更好的阐述 WPA3-SAE 的作用 …...
Python解题 - CSDN周赛第38期
又来拯救公主了。。。本期四道题还是都考过,而且后面两道问哥在以前写的题解里给出了详细的代码(当然是python版),直接复制粘贴就可以过了——尽管这样显得有失公允,考虑到以后还会出现重复的考题,所以现在…...
Android绘制——自定义view之onLayout
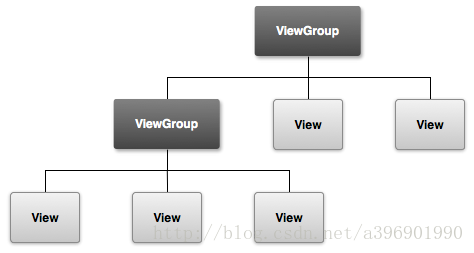
简介 在自定义view的时候,其实很简单,只需要知道3步骤: 测量——onMeasure():决定View的大小,关于此请阅读《Android自定义控件之onMeasure》布局——onLayout():决定View在ViewGroup中的位置绘制——onD…...

别再死记硬背MVC了!通过Unity连连看实战,我搞懂了数据与UI分离的5个真实好处
从连连看实战看数据与UI分离的五大工程化收益 在游戏开发领域,设计模式常常被视为"高级概念"而被初学者敬而远之。但当我真正在Unity中实现一个简单的连连看游戏时,才深刻体会到MVC模式中数据与UI分离带来的实际价值。这不是教科书上的理论说教…...

APRSPacketLib:嵌入式C库实现APRS协议编解码
1. APRSPacketLib 项目概述 APRSPacketLib 是一个专为业余无线电(Ham Radio)领域设计的轻量级嵌入式 C 语言库,核心目标是 在资源受限的微控制器平台上高效完成 APRS(Automatic Packet Reporting System)协议数据包的…...

STM32智能剪枝机:嵌入式系统与传感器集成实践
1. 项目背景与需求分析作为一名从事嵌入式开发多年的工程师,我最近完成了一个基于STM32的智能绿化带剪枝机项目。这个项目的初衷源于我在城市公园散步时的观察:园艺工人手持笨重的剪枝工具,在烈日下长时间弯腰作业,不仅效率低下&a…...
)
SEO_本地中小企业快速见效的SEO操作指南(345 )
SEO:本地中小企业快速见效的SEO操作指南 在当今数字化时代,本地中小企业如何在竞争激烈的市场中脱颖而出,是每一个企业主都需要面对的问题。本文将从多个角度为你详细解析如何通过SEO(搜索引擎优化)让本地中小企业迅速见效。 问…...

【笔试真题】- 招商银行-2026.03.30
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围在线刷题 bishipass.com 招商银行-2026.03.30 1. 术语接龙计分 问题描述 招商银行的培训平台里有一个简化版“术语接龙”小游戏。 系统维护了一份单词表,并给定一个当前单词。用户之…...

HunyuanVideo-Foley快速入门:VSCode远程开发与模型调试指南
HunyuanVideo-Foley快速入门:VSCode远程开发与模型调试指南 1. 前言:为什么选择VSCode远程开发? 如果你正在使用HunyuanVideo-Foley这类音效生成模型,可能会遇到这样的困扰:本地机器性能不足,而云服务器虽…...

数据仓库核心概念:事实表和维度表详解与实战应用
数据仓库核心概念:事实表和维度表详解与实战应用一、引言二、定义:什么是事实表?什么是维度表?2.1 事实表:定义2.2 维度表:定义三、结构流程图:事实表与维度表关联关系3.1 标准星型模型关联流程…...

【含文档+PPT+源码】基于SSM框架的农产品销售平台的设计与实现
项目介绍本课程演示的是一款 基于SSM框架的农产品销售平台的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料2.带你从零开始部署运行本套系统3.该项…...

千问3.5-2B轻量化部署教程:边缘设备适配可能性分析与CPU回退方案说明
千问3.5-2B轻量化部署教程:边缘设备适配可能性分析与CPU回退方案说明 1. 模型简介 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为边缘计算场景优化设计。这个2B参数量的版本在保持视觉理解能力的同时,大幅降低了硬件需求。 模型核心能力…...

C++vector迭代器失效全解析
深入讲解 C vector 的迭代器失效在 C 中,std::vector 是一个动态数组,它支持随机访问和高效的元素操作。迭代器是 C 中用于遍历容器元素的重要工具,类似于指针。但使用 vector 时,某些操作可能导致迭代器失效(iterator…...