Activiti 工作流简介
1、什么是工作流
工作流(Workflow),就是通过计算机对业务流程自动化执行管理。它主要解决的是“使在多个参与者之间按照某种预定义的规则自动进行传递文档、信息或任务的过程,从而实现某个预期的业务目标,或者促使此目标的实现”。
1.2、工作流系统
一个软件系统中具有工作流的功能,我们把它称为工作流系统,一个系统中工作流的功能是什么?就是对系统的业务流程进行自动化管理,所以工作流是建立在业务流程的基础上,所以一个软件的系统核心根本上还是系统的业务流程,工作流只是协助进行业务流程管理。即使没有工作流业务系统也可以开发运行,只不过有了工作流可以更好的管理业务流程,提高系统的可扩展性。
1.3、Activiti概述
Activiti是一个工作流引擎, activiti可以将业务系统中复杂的业务流程抽取出来,使用专门的建模语言BPMN2.0进行定义,业务流程按照预先定义的流程进行执行,实现了系统的流程由activiti进行管理,减少业务系统由于流程变更进行系统升级改造的工作量,从而提高系统的健壮性,同时也减少了系统开发维护成本。
1.4、BPM
BPM即业务流程管理,是一种规范化的构造端到端的业务流程,以持续的提高组织业务效率。 idea插件安装:https://plugins.jetbrains.com/plugin/7429-actibpm/versions 将下载的jar包插件直接整到idea当中,在settings当中的插件当中,导入本地插件,导入插件之后重启idea即可。
2、Activiti工作流环境搭建
引入相关依赖:(主要MySQL的版本和自己本地需要一致)
<properties>
<slf4j.version>1.6.6</slf4j.version>
<log4j.version>1.2.12</log4j.version>
<activiti.version>7.0.0.Beta1</activiti.version>
</properties>
<dependencies>
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-engine</artifactId>
<version>${activiti.version}</version>
</dependency>
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-spring</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- bpmn 模型处理 -->
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-bpmn-model</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- bpmn 转换 -->
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-bpmn-converter</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- bpmn json数据转换 -->
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-json-converter</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- bpmn 布局 -->
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-bpmn-layout</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- activiti 云支持 -->
<dependency>
<groupId>org.activiti.cloud</groupId>
<artifactId>activiti-cloud-services-api</artifactId>
<version>${activiti.version}</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!-- mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.5</version>
</dependency>
<!-- 链接池 -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- log start -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
使用log4j日志,直接在resources下创建log4j.properties:日志文件路径根据实际路径修改
# Set root category priority to INFO and its only appender to CONSOLE.
#log4j.rootCategory=INFO, CONSOLE debug info warn error fatal
log4j.rootCategory=debug, CONSOLE, LOGFILE
# Set the enterprise logger category to FATAL and its only appender to CONSOLE.
log4j.logger.org.apache.axis.enterprise=FATAL, CONSOLE
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r[%15.15t] %-5p %30.30c %x - %m\n
# LOGFILE is set to be a File appender using a PatternLayout.
log4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File=E:\\workFile\\log4jLog\\activiti.log
log4j.appender.LOGFILE.Append=true
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=%d{ISO8601} %-6r[%15.15t] %-5p %30.30c %x - %m\n
添加activiti配置文件,使用activiti提供的默认方式来创建mysql的表。默认方式是在 resources 下创建 activiti.cfg.xml 文件,注意:默认方式目录和文件名不能修改,因为activiti的源码中已经设置,到固定的目录读取固定文件名的文件。默认要在在activiti.cfg.xml中bean的名字叫processEngineConfiguration,名字不可修改,在这里直接连接到本地数据库activiti这个库。
![]()
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:tx="http://www.springframework.org/schema/tx"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/contex
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd"><!-- 默认id对应的值 为processEngineConfiguration --><!-- processEngine Activiti的流程引擎 -->
<!-- <bean id="processEngineConfiguration"-->
<!-- class="org.activiti.engine.impl.cfg.StandaloneProcessEngineConfiguration">-->
<!-- <property name="jdbcDriver" value="com.mysql.cj.jdbc.Driver"/>-->
<!-- <property name="jdbcUrl" value="jdbc:mysql:///activiti?autoReconnect=true"/>-->
<!-- <property name="jdbcUsername" value="root"/>-->
<!-- <property name="jdbcPassword" value="123456"/>-->
<!-- <property name="databaseSchemaUpdate" value="true"/>-->
<!-- </bean>--><!-- 这里可以使用 链接池 dbcp--><bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"><property name="driverClassName" value="com.mysql.cj.jdbc.Driver" /><property name="url" value="jdbc:mysql:///activiti?autoReconnect=true" /><property name="username" value="root" /><property name="password" value="123456" /><property name="maxActive" value="3" /><property name="maxIdle" value="1" /></bean><bean id="processEngineConfiguration"class="org.activiti.engine.impl.cfg.StandaloneProcessEngineConfiguration"><!-- 引用数据源 上面已经设置好了--><property name="dataSource" ref="dataSource" /><!-- activiti数据库表处理策略 --><property name="databaseSchemaUpdate" value="true"/></bean></beans>
创建一个测试类,调用activiti的工具类,生成acitivti需要的数据库表。直接使用activiti提供的工具类ProcessEngines,会默认读取classpath下的activiti.cfg.xml文件,读取其中的数据库配置,创建 ProcessEngine,在创建ProcessEngine 时会自动创建表。代码执行完成之后在数据库当中进行查看对应的表是否都创建出来了。
import org.activiti.engine.ProcessEngine;
import org.activiti.engine.ProcessEngineConfiguration;
import org.activiti.engine.ProcessEngines;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
class SpringbootHelloApplicationTests {@Testvoid contextLoads() {//使用classpath下的activiti.cfg.xml中的配置创建processEngineProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();System.out.println(processEngine);// 而除了使用默认配置进行创建工作流引擎对象,还可以通过自定义的方式进行创建。// 自定义配置文件名ProcessEngineConfiguration processEngineConfigurationFromResource = ProcessEngineConfiguration.createProcessEngineConfigurationFromResource("activiti.cfg.xml");System.out.println(processEngineConfigurationFromResource);// 自定义配置文件名 bean对象idProcessEngineConfiguration processEngineConfigurationFromResource1 = ProcessEngineConfiguration.createProcessEngineConfigurationFromResource("activiti.cfg.xml", "processEngineConfiguration");System.out.println(processEngineConfigurationFromResource1);}}
执行完数据库生成25张表。

3、Activiti 类、配置文件之间的关系
3.1、activiti.cfg.xml
activiti的引擎配置文件,包括:ProcessEngineConfiguration的定义、数据源定义、事务管理器等,此文件其实就是一个spring配置文件。
3.2、流程引擎配置类
流程引擎的配置类(ProcessEngineConfiguration),通过ProcessEngineConfiguration可以创建工作流引擎ProceccEngine,常用的两种方法如下:
3.2.1、StandaloneProcessEngineConfiguration
使用StandaloneProcessEngineConfigurationActiviti可以单独运行,来创建ProcessEngine,Activiti会自己处理事务。配置文件方式:通常在activiti.cfg.xml配置文件中定义一个id为 processEngineConfiguration 的bean,见环境搭建模块,就是使用这种方式进行配置的。
3.2.2、SpringProcessEngineConfiguration
通过org.activiti.spring.SpringProcessEngineConfiguration 与Spring整合。
3.3、Servcie服务接口
Service是工作流引擎提供用于进行工作流部署、执行、管理的服务接口,我们使用这些接口可以就是操作服务对应的数据表,并且在这里通过processEngine对象get对应的service就可以获取到service对象了。
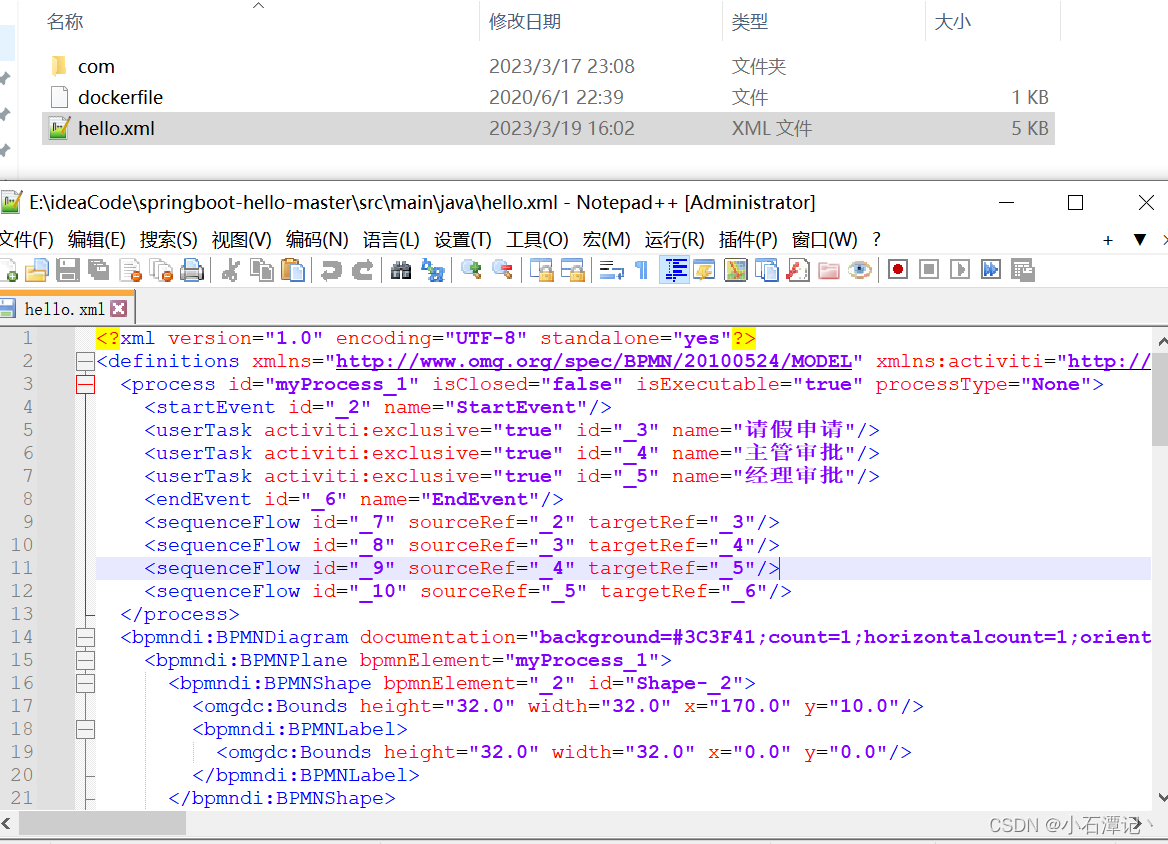
4、流程的创建与操作
4.1 流程图的绘制,安装bpmn插件
 将文件后缀bpmn改为xml,打开文件如下
将文件后缀bpmn改为xml,打开文件如下
4.2.1 单个文件部署方式
将上面的流程部署到activiti的数据库中,就是流程定义部署。
/*** 单个文件部署流程*/@Testpublic void develop() {// 创建流程对象ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();// 获取service对象RepositoryService repositoryService = processEngine.getRepositoryService();// 流程部署 设置名字 将bpmn和png部署进去Deployment deploy = repositoryService.createDeployment().addClasspathResource("bpmn/hello.bpmn").addClasspathResource("bpmn/hello.png").name("请假流程").deploy();System.out.println("id = " + deploy.getId());System.out.println("name = " + deploy.getName());}之后直接启动这个测试方法进行流程部署,可以观察日志,整个部署的过程当中总共操作了三张表
- act_re_deployment 流程定义部署表,每部署一次增加一条记录
- act_re_procdef 流程定义表,部署每个新的流程定义都会在这张表中增加一条记录
- act_ge_bytearray 流程资源表
act_re_deployment 和 act_re_procdef一对多关系,一次部署在流程部署表生成一条记录,但一次部署可以部署多个流程定义,每个流程定义在流程定义表生成一条记录。每一个流程定义在act_ge_bytearray会存在两个资源记录,bpmn和png。
4.2.2 使用压缩包的方式
/*** 压缩包的方式部署*/@Testpublic void devoZip(){ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();InputStream inputStream = this.getClass().getClassLoader().getResourceAsStream("bpmn/hello.zip");ZipInputStream zipInputStream = new ZipInputStream(inputStream);Deployment deploy = repositoryService.createDeployment().addZipInputStream(zipInputStream).deploy();System.out.println("id = " + deploy.getId());System.out.println("name = " + deploy.getName());}4.3 开始流程
启动一个流程表示发起一个新的请假申请,这就相当于java类与java对象的关系,类定义好后需要new创建一个对象使用,当然可以new多个对象。对于请出差申请流程,发起一个请假申请单需要启动一个流程实例,请假申请单发起请假也需要启动一个流程实例。
流程实例的key查看数据库
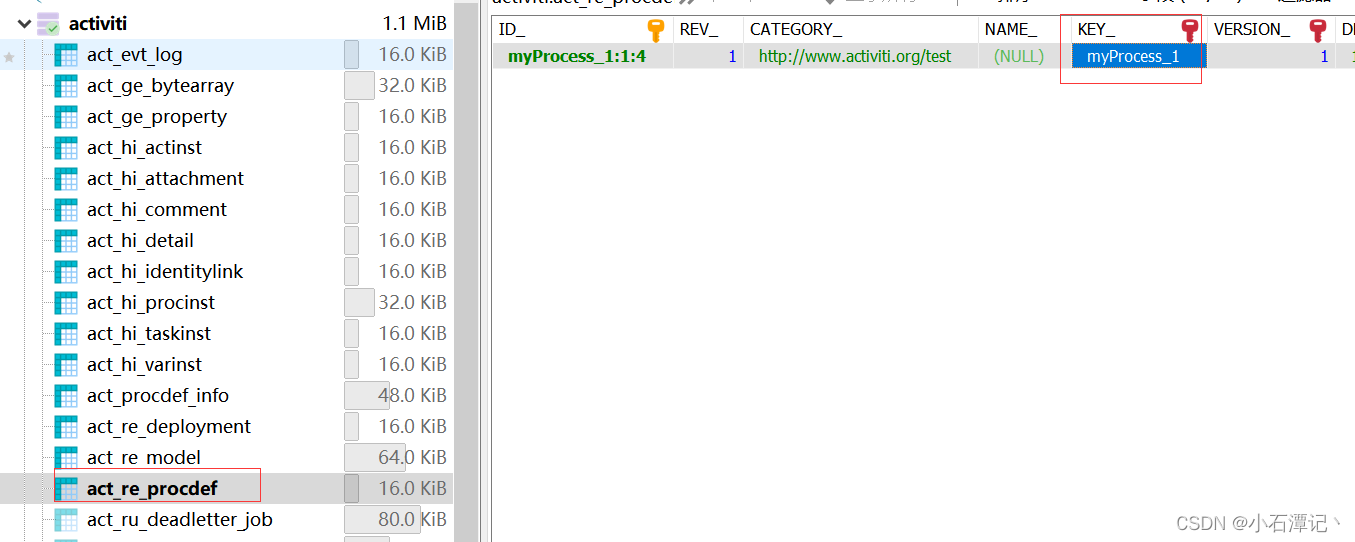
/*** 开始流程*/@Testpublic void start(){ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();// 根据流程id启动流程 act_re_procdef表里的keyProcessInstance instance = runtimeService.startProcessInstanceByKey("myProcess_1");System.out.println("流程id = " + instance.getProcessDefinitionId());System.out.println("实例id = " + instance.getId());System.out.println("活动id = " + instance.getActivityId());}
流程开始成功。
4.4 任务查询
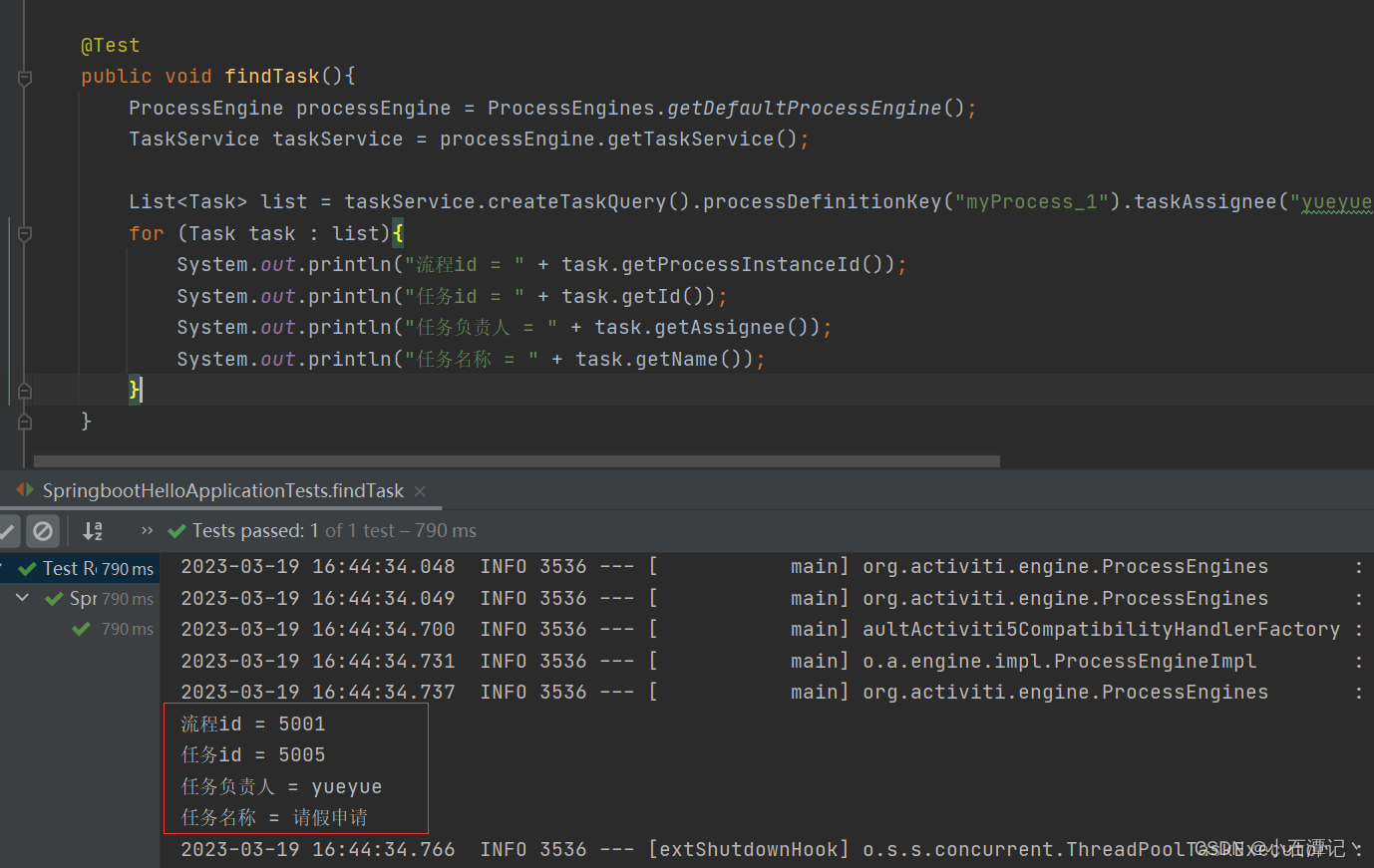
流程启动后,任务的负责人就可以查询自己当前需要处理的任务,查询出来的任务都是该用户的待办任务。
/*** 查找任务*/@Testpublic void findTask(){ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();// act_ru_task表里的assignee字段就是处理人 可以手动设置List<Task> list = taskService.createTaskQuery().processDefinitionKey("myProcess_1").taskAssignee("cxb").list();for (Task task : list){System.out.println("流程id = " + task.getProcessInstanceId());System.out.println("任务id = " + task.getId());System.out.println("任务负责人 = " + task.getAssignee());System.out.println("任务名称 = " + task.getName());}}而对应的查询语句也是:根据流程的Key以及负责人去task当中查询任务。
SELECT DISTINCT RES.* FROM ACT_RU_TASK RES INNER JOIN ACT_RE_PROCDEF D ON RES.PROC_DEF_ID_ = D.ID_
WHERE RES.ASSIGNEE_ = 'yueyue' AND D.KEY_ = 'myLeave' ORDER BY RES.ID_ ASC LIMIT 2147483647 OFFSET 0 
这里设置处理人。
4.5 任务推动
在前面我们可以获取到负责人所有的任务,并且可以获取到相对应的任务id,这里只需要获取id进行推动流程即可。
/*** 任务推动*/@Testpublic void next(){ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();taskService.complete("5005");// 获取单个流程数据进行操作,替换掉上面的2505// Task task = taskService.createTaskQuery().processDefinitionKey("myProcess_1").taskAssignee("zhangsan").singleResult();// taskService.complete(task.getId());System.out.println("任务完成");}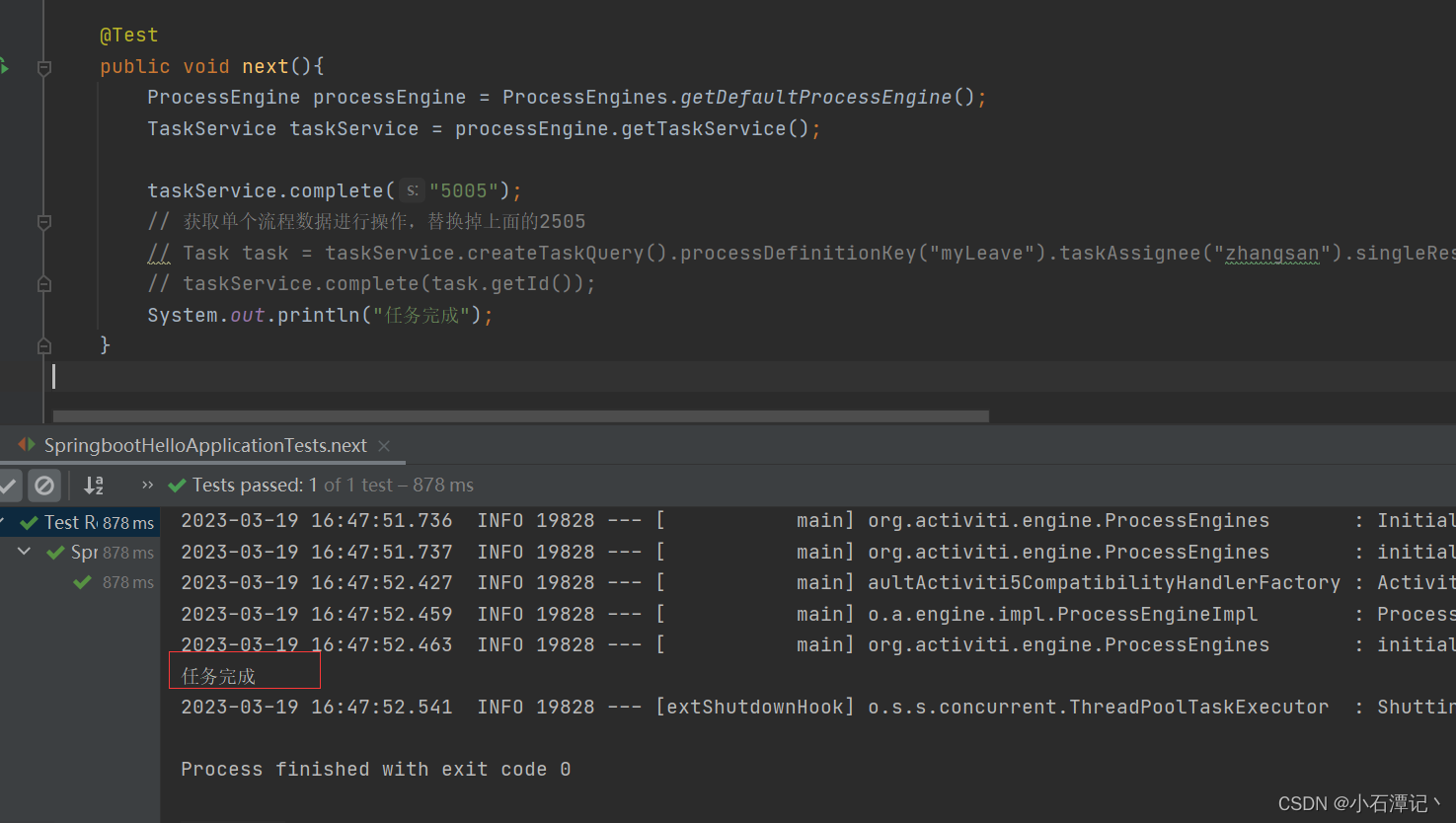
任务推动之后还是和查询任务一致的查询语句获取当前负责人的数据,也可以直接查看 act_ru_task这张表的流程数据推动了没,而之前的流程会保存在 act_hi_taskinst 这张表当中。而这里对后续的几个流程的推动也是相同的道理,就不继续进行流程推动了,当最后一步的流程走完之后,整个流程已经结束,在act_ru_task这张表就不会存在当前这个流程的数据了。
4.6 流程定义信息查询
查询流程相关信息,包含流程定义,流程部署,流程定义版本
/*** 流程定义信息查询*/@Testpublic void processInfo() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();ProcessDefinitionQuery processDefinitionQuery = repositoryService.createProcessDefinitionQuery();List<ProcessDefinition> list = processDefinitionQuery.processDefinitionKey("myProcess_1").orderByProcessDefinitionVersion().desc().list();for (ProcessDefinition definition : list) {System.out.println("id = " + definition.getId());System.out.println("name = " + definition.getName());System.out.println("key = " + definition.getKey());System.out.println("version = " + definition.getVersion());}}
4.7 流程删除
/*** 删除流程*/@Testpublic void deleteProcess() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();
// repositoryService.deleteDeployment("1");// 如果该流程定义下存在已经运行的流程,使用普通删除报错,可用级联删除方法将流程及相关记录全部删除。// 先删除没有完成流程节点,最后就可以完全删除流程定义信息repositoryService.deleteDeployment("1", true);}
4.8 下载资源文件
首先可以知道资源文件存在 act_ge_bytearray 这张表当中,而对于流程的数据bpmn和png文件的DEPLOYMENT_ID这个字段是相同的,因此只需要获取到这个id就能得到相对应的数据,这个id如何获取呢?在前面4.6获取流程信息当中就可以获取到这个id,因此把之前获取全部改为获取单个,就能拿到这个id了。而后续根据repositoryService来进行获取需要两个参数,一个就是这个id,另外一个就是文件的路径,文件的路径可以在 act_re_procdef 当中进行获取。
/*** 下载资源文件* @throws IOException*/@Testpublic void getBolb() throws IOException {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();ProcessDefinitionQuery processDefinitionQuery = repositoryService.createProcessDefinitionQuery();ProcessDefinition definition = processDefinitionQuery.processDefinitionKey("myProcess_1").orderByProcessDefinitionVersion().desc().singleResult();// 获取流程id 文件名String deploymentId = definition.getDeploymentId();String diagramResourceName = definition.getDiagramResourceName();String resourceName = definition.getResourceName();// 得到input流InputStream pngInput = repositoryService.getResourceAsStream(deploymentId, diagramResourceName);InputStream bpmnInput = repositoryService.getResourceAsStream(deploymentId, resourceName);File pngFile = new File("d:/leave.png");File bpmnFile = new File("d:/leave.bpmn");FileOutputStream pngOutputStream = new FileOutputStream(pngFile);FileOutputStream bpmnOutputStream = new FileOutputStream(bpmnFile);// 输入输出转换IOUtils.copy(pngInput, pngOutputStream);IOUtils.copy(bpmnInput, bpmnOutputStream);pngInput.close();pngOutputStream.close();bpmnInput.close();bpmnOutputStream.close();}并且这里使用到的IOUtils工具类是apache提供的,需要引入新的依赖
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency>
4.9 流程历史信息查看
即使流程定义已经删除了,流程执行的历史信息通过前面的分析,依然保存在activiti的act_hi_*相关的表中。所以我们还是可以查询流程执行的历史信息,可以通过HistoryService来查看相关的历史记录。
/*** 查看流程历史信息*/@Testpublic void findHistory() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();HistoryService historyService = processEngine.getHistoryService();// 设置查询条件进行查询List<HistoricActivityInstance> list = historyService.createHistoricActivityInstanceQuery().orderByHistoricActivityInstanceStartTime().asc().processInstanceId("12501").list();for (HistoricActivityInstance historiy : list) {System.out.println("activiti id = " + historiy.getActivityId());System.out.println("activiti name = " + historiy.getActivityName());System.out.println("process definition id = " + historiy.getProcessDefinitionId());System.out.println("process instance id = " + historiy.getProcessInstanceId());System.out.println("start time = " + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(historiy.getStartTime()));System.out.println("===============================================");}}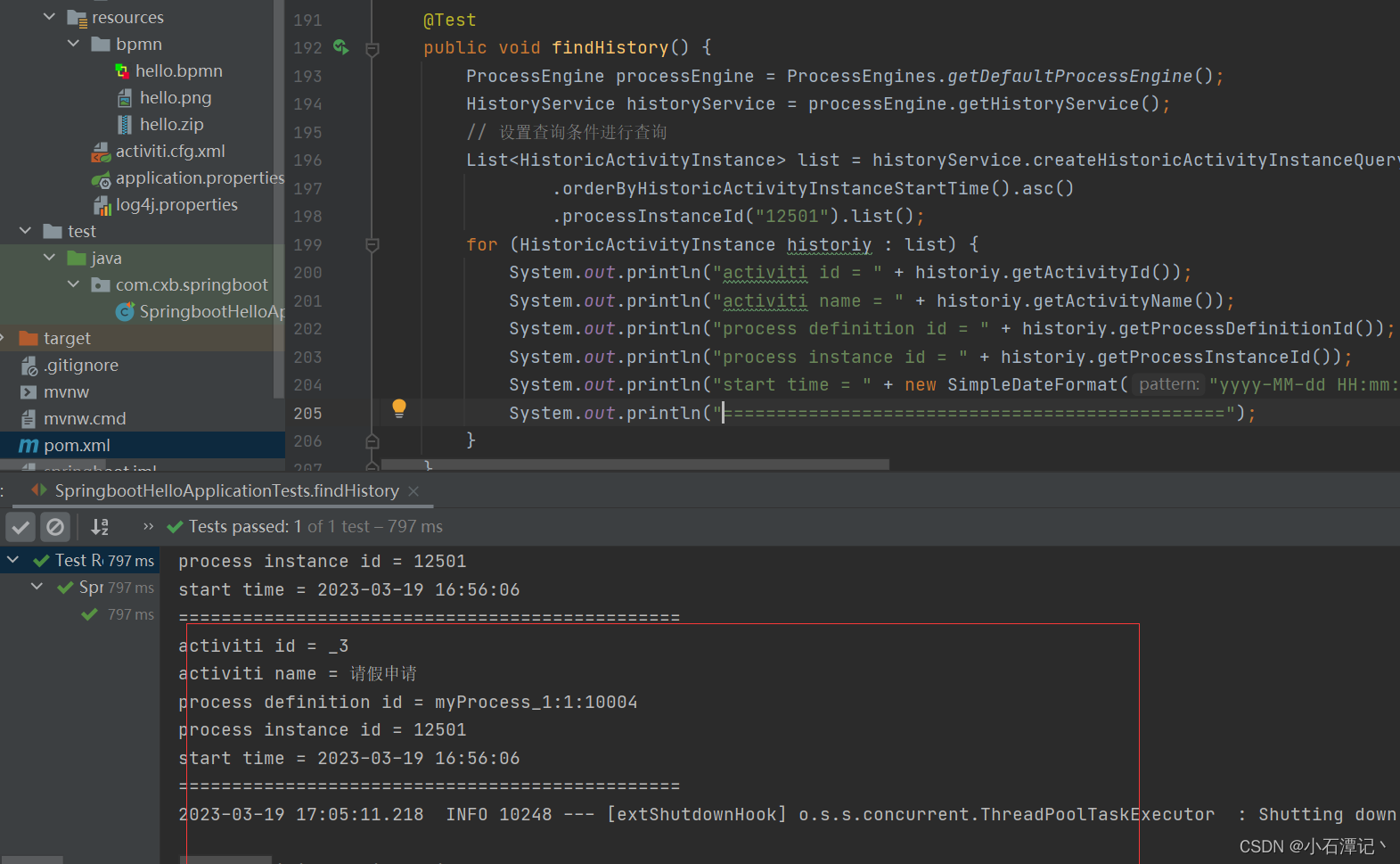
4.10、给流程实例添加Businesskey(业务标识)
启动流程实例时,指定的businesskey,就会在act_ru_execution #流程实例的执行表中存储businesskey。
Businesskey:业务标识,通常为业务表的主键,业务标识和流程实例一一对应。业务标识来源于业务系统。存储业务标识就是根据业务标识来关联查询业务系统的数据。
/*** 增加业务标识*/@Testpublic void addLeaveKey() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();ProcessInstance myLevel = runtimeService.startProcessInstanceByKey("myProcess_1", "1001");System.out.println(myLevel.getBusinessKey());}
4.11 流程的挂起与激活
4.11.1、全部流程实例挂起
操作流程定义为挂起状态,该流程定义下边所有的流程实例全部暂停:流程定义为挂起状态该流程定义将不允许启动新的流程实例,同时该流程定义下所有的流程实例将全部挂起暂停执行。
/*** 全部流程实例挂起*/@Testpublic void suspendAll() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();ProcessDefinition definition = repositoryService.createProcessDefinitionQuery().processDefinitionKey("myProcess_1").singleResult();// 是否暂停boolean suspended = definition.isSuspended();String id = definition.getId();if (suspended) {repositoryService.activateProcessDefinitionById(id, true, null);System.out.println("id = " + id + " 激活");} else {repositoryService.suspendProcessDefinitionById(id, true, null);System.out.println("id = " + id + " 挂起");}}4.11.2、单个流程实例挂起
操作流程实例对象,针对单个流程执行挂起操作,某个流程实例挂起则此流程不再继续执行,完成该流程实例的当前任务将报异常。
@Testpublic void suspendOne() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();ProcessInstance processInstance = runtimeService.createProcessInstanceQuery().processInstanceId("12501").singleResult();boolean suspended = processInstance.isSuspended();String id = processInstance.getId();if (suspended) {runtimeService.activateProcessInstanceById(id);System.out.println("id = " + id + " 激活");} else {runtimeService.suspendProcessInstanceById(id);System.out.println("id = " + id + " 挂起");}}
4.11.3 流程实例推动
在前面我们对一个整个的流程以及单个流程进行了激活和挂起操作,之后可以编写一段代码来进行推动流程操作,主要是用来当流程被挂起后流程还能否被继续推动。很显然,当挂起的流程去进行流程推动是不允许推动流程的,必须是流程是激活状态下才能够被推动。
具体的实例id和assignee值根据自己数据库的值来进行处理。
/*** 流程实例推动*/@Testpublic void complete() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Task task = taskService.createTaskQuery().processInstanceId("15001").taskAssignee("cxb").singleResult();System.out.println("id = " + task.getId());System.out.println("name = " + task.getName());System.out.println("assignee = " + task.getAssignee());taskService.complete(task.getId());}
5、个人任务
5.1、分配任务责任人
5.1.1、固定负责人
在进行业务流程建模时指定固定的任务负责人,直接在bpmn当中指定assignee。
5.1.2、表达式分配
由于固定分配方式,任务只管一步一步执行任务,执行到每一个任务将按照 bpmn 的配置去分配任务负责人。和前面一样进行指定,使用${变量名}的方式进行指定。而指定之后的这些变量在流程启动的时候可以通过一个map对象来进行赋值。
/*** 表达式分配*/@Testpublic void startDistribution () {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();// 根据流程id启动流程Map<String, Object> map = new HashMap();map.put("assignee", "huangyueyue");map.put("director", "yueyueniao");map.put("manager", "zhangsan");ProcessInstance instance = runtimeService.startProcessInstanceByKey("myProcess_1", map);}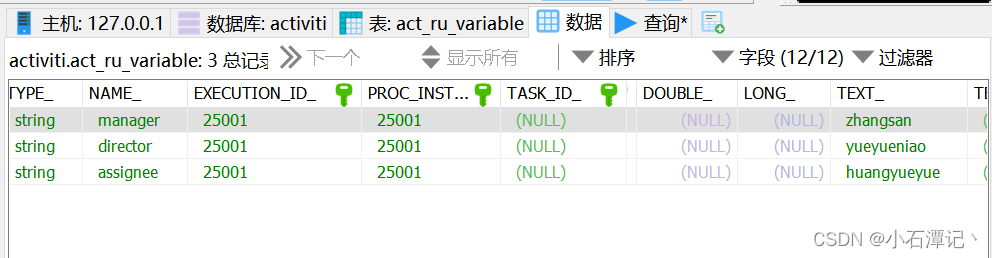
5.1.3、监听器分配
任务监听器的Event的选项包含:
- Create:任务创建后触发
- Assignment:任务分配后触发
- Delete:任务完成后触发
- All:所有事件发生都触发
定义任务监听类,且类必须实现 org.activiti.engine.delegate.TaskListener 接口
package com.cxb.springboot.listener;import org.activiti.engine.delegate.DelegateTask;
import org.activiti.engine.delegate.TaskListener;public class MyTaskListener implements TaskListener {@Overridepublic void notify(DelegateTask delegateTask) {if (delegateTask.getName().equals("请假申请") &&delegateTask.getEventName().equals("create")) {// 这里指定任务负责人delegateTask.setAssignee("黄阅阅");}}
}<userTask activiti:exclusive="true" id="_3" name="请假申请"><extensionElements><activiti:taskListener class="com.cxb.springboot.listener.MyTaskListener" event="all"/></extensionElements></userTask>
5.2、查询任务
在前面就已经可以通过流程key和负责人就可以查询出这个人负责的流程单,而实际应用时,查询待办任务可能要显示出业务系统的一些相关信息。这里可以通过 businessKey(业务标识 )关联查询业务系统的数据。
/*** 查询任务*/@Testpublic void findProcessInstance() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();RuntimeService runtimeService = processEngine.getRuntimeService();Task task = taskService.createTaskQuery().processDefinitionKey("myProcess_1").taskAssignee("cxb").singleResult();String processInstanceId = task.getProcessInstanceId();ProcessInstance processInstance = runtimeService.createProcessInstanceQuery().processInstanceId(processInstanceId).singleResult();String businessKey = processInstance.getBusinessKey();System.out.println("businessKey==" + businessKey);} 查询业务标识码
5.3、任务推动
在之前可以通过TaskService这个类的complate方法推动任务的流动,而在这里我们还需要对当前用户是否拥有推动该流程的权限,只需要先通过查询当前负责人的所有流程进行判断即可。有该流程即可推动,反之无法推动流程。
@Testpublic void completeTask() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Task task = taskService.createTaskQuery().taskId("20005").taskAssignee("cxb").singleResult();if (task != null) {taskService.complete("20005");System.out.println("完成任务");}}
6、流程变量与组任务
6.1、流程变量概述
6.1.1、流程变量是什么
流程变量在 activiti 中是一个非常重要的角色,流程运转有时需要靠流程变量,业务系统和 activiti 结合时少不了流程变量,流程变量就是 activiti 在管理工作流时根据管理需要而设置的变量。
虽然流程变量中可以存储业务数据可以通过activiti的api查询流程变量从而实现查询业务数据,但是不建议这样使用,因为业务数据查询由业务系统负责,activiti设置流程变量是为了流程执行需要而创建。
6.1.2、流程变量作用域
流程变量的作用域可以是一个流程实例,或一个任务,或一个执行实例
1、global变量
流程变量的默认作用域是流程实例。当一个流程变量的作用域为流程实例时,可以称为 global 变量。
global 变量中变量名不允许重复,设置相同名称的变量,后设置的值会覆盖前设置的变量值。
2、local变量任务和执行实例仅仅是针对一个任务和一个执行实例范围,范围没有流程实例大, 称为 local 变量。
Local 变量由于在不同的任务或不同的执行实例中,作用域互不影响,变量名可以相同没有影响。
Local 变量名也可以和 global 变量名相同,没有影响。
6.2、使用global变量控制流程
还是和前面的整个流程一样,现在对流程的分支进行控制,通过流程变量来进行控制,当天数大于或等于三天还需要通过经理审批,反之直接通过主管审批就结束了整个流程。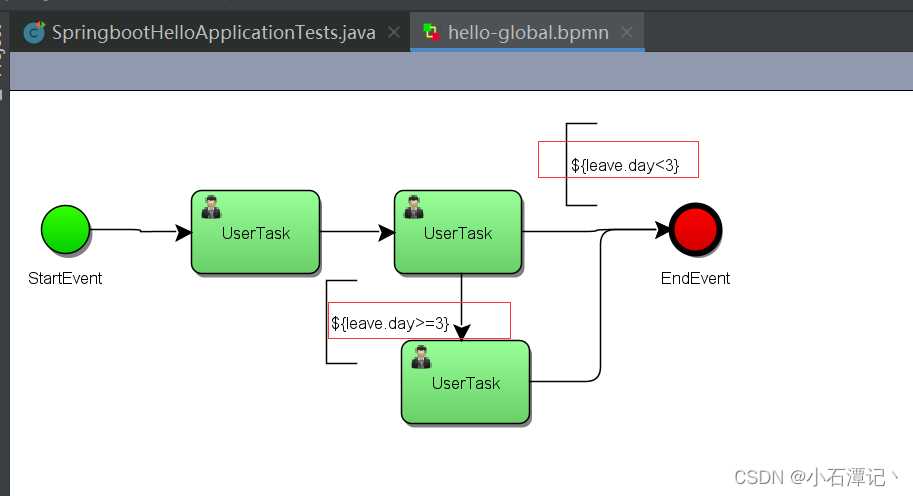
这里的话使用的UEL表达式使用的是uel-method来进行赋值,所以在这里需要一个实体类来进行值的给予,先定义一个类。该类当中必须包含这个day变量,也就是在bpmn文件当中指定的变量,以及该类必须实例化。并且加上getset方法。
public class Leave implements Serializable {private Double day;
}
6.2.1、启动流程时设置变量
在启动流程时设置流程变量,变量的作用域是整个流程实例。通过Map<key,value>设置流程变量,map中可以设置多个变量,这个key就是流程变量的名字。后续通过TaskService的compele方法来进行推动流程实例的代码就不给出了,直接获取taskid进行推动,查看流程的走向。
/*** 单个文件部署流程*/@Testpublic void developGlobal() {// 创建流程对象ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();// 获取service对象RepositoryService repositoryService = processEngine.getRepositoryService();// 流程部署 设置名字 将bpmn和png部署进去Deployment deploy = repositoryService.createDeployment().addClasspathResource("bpmn/hello-global.bpmn").addClasspathResource("bpmn/hello-global.png").name("请假流程全局设置变量").deploy();System.out.println("id = " + deploy.getId());System.out.println("name = " + deploy.getName());}/*** 启动流程时设置变量*/@Testpublic void startSetGlobal() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();Leave leave = new Leave();leave.setDay(4d);Map map = new HashMap();map.put("leave", leave);map.put("assignee", "yueyueniao");map.put("director", "张三");map.put("manager", "黄阅阅");ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("myProcess_1", map);System.out.println(processInstance);}6.2.2 任务办理时设置变量
在完成任务时设置流程变量,该流程变量只有在该任务完成后其它结点才可使用该变量,它的作用域是整个流程实例,如果设置的流程变量的key在流程实例中已存在相同的名字则后设置的变量替换前边设置的变量。这样对前面6.2.1的代码当中往map对象当中添加leave的代码注掉。
/*** 任务办理时设置变量*/@Testpublic void completeSet() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Leave leave = new Leave();leave.setDay(4d);Map map = new HashMap();map.put("leave", leave);Task task = taskService.createTaskQuery().processDefinitionKeyLike("myLeaveGlabal").taskAssignee("张三").singleResult();if (task != null) {taskService.complete(task.getId(), map);}}6.2.3 通过当前流程实例设置
通过流程实例id设置全局变量,该流程实例必须未执行完成。
@Testpublic void setGlobalVariableByExecutionId() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();Leave leave = new Leave();leave.setDay(4d);runtimeService.setVariable("75001", "leave", leave);}
6.2.4 通过当前任务设置
@Testpublic void setGlobalVariableByTaskId() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Leave leave = new Leave();leave.setDay(4d);taskService.setVariable("75001", "leave", leave);}
6.3 组任务办理流程***
1)查询组任务
指定候选人,查询该候选人当前的待办任务。候选人不能立即办理任务。
2)拾取任务
该组任务的所有候选人都能拾取。将候选人的组任务,变成个人任务。原来候选人就变成了该任务的负责人。如果拾取后不想办理该任务,需要将已经拾取的个人任务归还到组里边,将个人任务变成了组任务。
3)查询个人任务
查询方式同个人任务部分,根据assignee查询用户负责的个人任务。
4)办理个人任务
首先创建一个bpmn文件,在user当中可以对candidateUsers进行设置多个人员,之间用都好进行隔开,而对应的xml如下:
<userTask activiti:candidateUsers="zhangsan,lisi" activiti:exclusive="true" id="_3" name="申请-group"/><userTask activiti:candidateUsers="wangwu,zhaoliu" activiti:exclusive="true" id="_4" name="审核-group"/>
之后将该bpmn进行部署,并且启动任务。
6.3.1 查询组任务
根据候选人查询组任务,可以看到这个task在act_ru_task这张表当中的assignee却是一个null,也就是该用户虽然可以查询出该任务,却无法对该任务进行处理。
@Testpublic void findGroup() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();List<Task> list = taskService.createTaskQuery().processDefinitionKey("myLeaveGroup").taskCandidateUser("zhangsan").list();for (Task task : list) {System.out.println("instance id = " + task.getProcessInstanceId());System.out.println("id = " + task.getId());System.out.println("assignee = " + task.getAssignee());System.out.println("name = " + task.getName());}}
6.3.2 拾取任务
候选人员拾取组任务后该任务变为自己的个人任务。用户拾取任务之后,对应的act_ru_task表对应的行数据的assignee就会变成相对应的人员。
@Testpublic void getTask() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Task task = taskService.createTaskQuery().taskId("87505").taskCandidateUser("zhangsan").singleResult();if (task != null) {taskService.claim("87505", "zhangsan");System.out.println("用户拾取");}}
6.3.3 归还组任务
直接通过assignee进行查询,查询到数据再将assignee置空也就表示归还了任务。同理任务的交接就不用设置为空了,直接设置给另一个用户即可。
@Testpublic void returnTask() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Task task = taskService.createTaskQuery().taskId("87505").taskAssignee("zhangsan").singleResult();if (task != null) {taskService.setAssignee("87505", null);System.out.println("用户归还");}}
7、网关
7.1 排他网关
排他网关,用来在流程中实现决策。 当流程执行到这个网关,所有分支都会判断条件是否为true,如果为true则执行该分支,注意:排他网关只会选择一个为true的分支执行。如果有两个分支条件都为true,排他网关会选择id值较小的一条分支去执行。

在这里对A流程后设置一个排他网关进行流程分支,这两条分支线也就对应两个uel表达式进行判断,而后就可以直接把这个流程进行部署,部署之后在启动流程的时候就给这个day进行设置值,直接进行推动流程,查看流程的流转。
@Testpublic void startSet() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RuntimeService runtimeService = processEngine.getRuntimeService();Leave leave = new Leave();leave.setDay(-4d);Map map = new HashMap();map.put("leave", leave);ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("gateway-pt", map);}@Testpublic void compete() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();TaskService taskService = processEngine.getTaskService();Task task = taskService.createTaskQuery().processDefinitionKey("gateway-pt").taskAssignee("张三").singleResult();if (task != null) {taskService.complete(task.getId());}}
7.2 并行网关
并行网关允许将流程分成多条分支,也可以把多条分支汇聚到一起,并行网关的功能是基于进入和外出顺序流的:
fork分支:并行后的所有外出顺序流,为每个顺序流都创建一个并发分支。
join汇聚:所有到达并行网关,在此等待的进入分支, 直到所有进入顺序流的分支都到达以后, 流程就会通过汇聚网关。
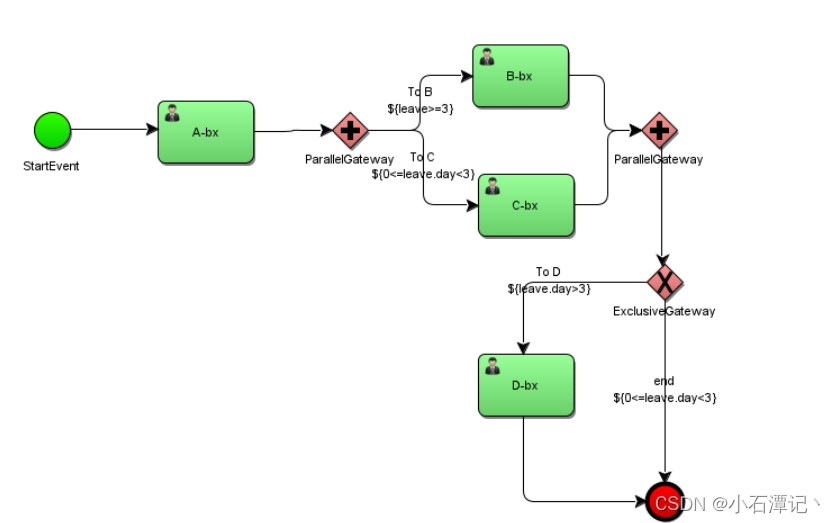
并行网关的测试代码和前面排他网关的代码基本一致,在首先进行部署之后启动流程,给流程设置一个天数,而之后推动任务之后,首先进入到并行网关,这里并不会进行判断,这里的意思是表示B和C都可以进行对该任务流程进行操作,并且只有到B和C都做了相关的操作流程才会继续往后流转,后面接的排他网关直接通过最开始设置的值再进行判断做流程的流转。
7.3 包含网关
包含网关可以看做是排他网关和并行网关的结合体。和排他网关一样,可以在外出顺序流上定义条件,包含网关会解析它们。 但是主要的区别是包含网关可以选择多于一条顺序流,这和并行网关一样。
1、分支:所有外出顺序流的条件都会被解析,结果为true的顺序流会以并行方式继续执行, 会为每个顺序流创建一个分支。
2、汇聚:所有并行分支到达包含网关,会进入等待状态, 直到每个包含流程token的进入顺序流的分支都到达。 这是与并行网关的最大不同。换句话说,包含网关只会等待被选中执行了的进入顺序流。 在汇聚之后,流程会穿过包含网关继续执行。
和之前的网关一样进行部署推动流程,可以发现在进入到包含网关的时候,网关会对条件进行判断再进行流转。二里面的包含又相当于并行网关,当并行的流程都执行完成之后再由包含网关进行汇聚。之后走排他网关进行判断流转。
7.4 事件网关
事件网关允许根据事件判断流向。网关的每个外出顺序流都要连接到一个中间捕获事件。 当流程到达一个基于事件网关,网关会进入等待状态:会暂停执行。与此同时,会为每个外出顺序流创建相对的事件订阅。
事件网关的外出顺序流和普通顺序流不同,这些顺序流不会真的"执行", 相反它们让流程引擎去决定执行到事件网关的流程需要订阅哪些事件。 要考虑以下条件:
1、事件网关必须有两条或以上外出顺序流;
2、事件网关后,只能使用intermediateCatchEvent类型(activiti不支持基于事件网关后连接ReceiveTask)
3、连接到事件网关的中间捕获事件必须只有一个入口顺序流。
参考
相关文章:
Activiti 工作流简介
1、什么是工作流 工作流(Workflow),就是通过计算机对业务流程自动化执行管理。它主要解决的是“使在多个参与者之间按照某种预定义的规则自动进行传递文档、信息或任务的过程,从而实现某个预期的业务目标,或者促使此目标的实现”。 1.2、工作…...
【华为机试真题详解 Python实现】统计差异值大于相似值二元组个数【2023 Q1 | 100分】
文章目录 前言题目描述输入描述输出描述题目解析参考代码前言 《华为机试真题详解》专栏含牛客网华为专栏、华为面经试题、华为OD机试真题。 如果您在准备华为的面试,期间有想了解的可以私信我,我会尽可能帮您解答,也可以给您一些建议! 本文解法非最优解(即非性能最优)…...
【C++】Google编码风格学习
Google规范线上地址:https://zh-google-styleguide.readthedocs.io/en/latest/ 文章目录1. 头文件2. 作用域3. 类4. 函数5. 其他C特性6. 命名约定7. 注释8. 格式1. 头文件 每个cpp/cc文件都对应一个h头文件,除单元测试代码和只包含main()的文件外。 所…...

JavaScript 中的Promise 函数
JavaScript 中的Promise 函数 目录JavaScript 中的Promise 函数1 创建Promise2 Promise的方法3 Promises的状态4 Promise的使用5 返回 Promise 类型6 Promise级联使用在现在的前端开发中我们常常会使用到 JavaScript Promise 函数,但是很多人都不能正确理解Promise …...

学校教的Python,找工作没企业要,太崩溃了【大四真实求职经历】
如果只靠学校学的东西去找工作,能找到工作吗? 今天给大家看一个粉丝的真实求职案例,想做Python方面的工作,投了二十几个简历却没人要,心态崩了。为什么没人要?我来告诉你答案。 然后我还会结合我的这些年的…...
快看!这只猫两次登上 Github Trending !!!
前几天我在逛 Github Trending,无意间发现这个Postcat 登上榜单 !好奇心驱使我去了解这个 Postcat。近期它上新了几个有意思的插件,其中 ChatGPT 插件,用户可以直接省去复杂的流程,直接体验 ChatGPT,懂的都懂ÿ…...

Linux->文件系统初识
目录 前言: 1 认识文件 2 文件使用 2.1 文件加载 2.2 外设文件使用 3 文件接口和文件描述符 3.1 文件系统调用接口 open: 3.2 文件描述符 4 缓冲区 前言: 在大家看这篇文章之前,我得提出几个问题: 1. 我们有多…...

InfluxDB和IotDB介绍与性能对比
InfluxDB简介 InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。用于存储和分析时间序列数据的开源数据库。 适合存储设备性能、日志、物联网传感器等带时间戳的数据,其设计目标是实现分布式和水平伸缩扩展。 InfluxDB 包括用于存储和…...

计算机体系结构(校验码+总线)
校验码计算机系统运行时,为了确保数据在传送过程中正确无误,一是提高硬件电路的可靠性;二就是是提高代码的校验能力,包括查错和纠错。通常使用校验码的方法检测传送的数据是否出错。这里的校验码主要是指循环冗余校验码࿰…...

JavaWeb《三》Request请求转发与Response响应
🍎道阻且长,行则将至。🍓 本文是javaweb的第三篇,介绍了Request请求转发与Response响应。 上一篇:JavaWeb《二》Servlet、Request请求 下一篇:敬请期待 目录一、Request请求转发🍏二、Response对…...
断言assert
assert作用:我们使用assert这个宏来调试代码语法:assert(bool表达式)如果表达式为false,会调用std::cout<<abort函数,弹出对话框,#include<iostream> #include<cassert> void…...

【Java项目】完善基于Java+MySQL+Tomcat+maven+Servlet的博客系统
目录一、准备工作二、引入依赖三、创建必要的目录四、编写代码五/六、打包部署(直接基于 smart tomcat)七、验证代码正式编写服务器代码编写数据库相关的操作代码创建数据库/表结构(数据库设计)数据库代码封装数据库操作封装针对数据的增删改查!博客列表页约定前后端…...

详解结构体内存对齐
目录 前言 一、内存大小的计算 1.规则 2.练习 二、为什么要有内存对齐 1.移植原因 2.性能原因 三、修改默认对齐数 总结 前言 本文针对结构体大小的计算进行深度剖析。结构体的大小要遵守内存对齐,在绝大数情况下,会浪费空间。但是有其的价值&…...

指针:程序员的望远镜
指针:程序员的望远镜一、什么是指针1.1 指针的定义1.2 指针和普通变量的区别1.3 指针的作用1.4 指针的优点和缺点二、指针的基本操作2.1 取地址运算符"&"2.2 指针的声明与定义2.3 指针的初始化2.4 指针的解引用2.5 指针的赋值2.6 指针的运算2.7 指针的…...

【python实现学生选课系统】
一、要求: 选课系统 管理员: 创建老师:姓名、性别、年龄、资产 创建课程:课程名称、上课时间、课时费、关联老师 使用pickle保存在文件 学生: 学生:用户名、密码、性别、年龄、选课列表[]、上课记录{课程…...

备受青睐的4D毫米波成像雷达,何以助力高阶自动驾驶落地?
近日,海外媒体曝出特斯拉已向欧洲监管机构提交车辆变更申请,并猜测特斯拉最新的自动驾驶硬件HW4.0或将很快量产上车。据爆料,HW4.0最大的变化是马斯克放弃的毫米波雷达又加了回来,根据国外知名博主Greentheonly的拆解分析…...
 LeetCode 合并两个有序数组)
3.20算法题(一) LeetCode 合并两个有序数组
题目链接:算法面试题汇总 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 题目描述:给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元…...
QT | 编写一个简单的上位机
QT | 编写一个简单的上位机 时间:2023-03-19 参考: 1.易懂 | 手把手教你编写你的第一个上位机 2.QT中修改窗口的标题和图标 3.图标下载 1.打开QT Creator 2.新建工程 Qt Creator 可以创建多种项目,在最左侧的列表框中单击“Application”&am…...

DirectX12(D3D12)基础教程(二十一)—— PBR:IBL 的数学原理(2/5)
目录3、IBL 数学原理3.1、基于微平面理论的 “Cook-Torrance” 模型回顾3.2、 ksk_sks 项与菲涅尔项等价消除3.3、拆分“漫反射项”和“镜面反射项”3、IBL 数学原理 接下来,就让我们正式进入整个 IBL 的数学原理的旅程。请注意,前方高能! …...

嵌入式学习笔记——SysTick(系统滴答)
系统滴答前言SysTick概述SysTick是个啥SysTick结构框图1. 时钟选择2.计数器部分3.中断部分工作一个计数周期(从重装载值减到0)的最大延时时间工作流程SysTick寄存器1.控制和状态寄存器SysTick->CTRL2.重装载值寄存器SysTick->LOAD3.当前值寄存器Sy…...

零基础教程:5个简单步骤用Mi-Create打造个性化小米手表表盘
零基础教程:5个简单步骤用Mi-Create打造个性化小米手表表盘 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create Mi-Create是一款专为小米穿戴设备用户打…...

Qwen3.5-2B多场景教程:农业技术人员上传病虫害图→识别种类→推荐药剂
Qwen3.5-2B多场景教程:农业技术人员上传病虫害图→识别种类→推荐药剂 1. 引言:农业病虫害识别的技术痛点 在农业生产中,病虫害防治一直是困扰农户的核心问题。传统识别方式存在三大痛点: 识别门槛高:需要专业农技人…...

告别电量焦虑:能源之星X如何让Windows笔记本续航轻松翻倍
告别电量焦虑:能源之星X如何让Windows笔记本续航轻松翻倍 【免费下载链接】EnergyStarX 🔋 Improve your Windows 11 devices battery life. A WinUI 3 GUI for https://github.com/imbushuo/EnergyStar. 项目地址: https://gitcode.com/gh_mirrors/en…...

2026年4月怎么搭建OpenClaw?腾讯云保姆级5分钟安装及百炼APIKey配置方法
2026年4月怎么搭建OpenClaw?腾讯云保姆级5分钟安装及百炼APIKey配置方法。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群…...

LongCat-Video:AI视频生成技术的范式突破与实践指南
LongCat-Video:AI视频生成技术的范式突破与实践指南 【免费下载链接】LongCat-Video 项目地址: https://ai.gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video 在数字内容创作领域,AI视频生成技术正经历从实验性探索到产业化应用的关键转折…...

Phi-4-mini-reasoning部署教程:多模型共存时GPU显存隔离配置技巧
Phi-4-mini-reasoning部署教程:多模型共存时GPU显存隔离配置技巧 1. 模型介绍 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个模型主打"小参数、强推理、长上下文、低延迟&quo…...

像素史诗惊艳效果展示:10份高质量研报生成过程与成品对比
像素史诗惊艳效果展示:10份高质量研报生成过程与成品对比 1. 像素史诗:当AI研究遇上像素艺术 在数字内容创作领域,一款名为像素史诗(Pixel Epic)的工具正在重新定义研究报告的生成方式。这款基于AgentCPM-Report大模型构建的智能终端&#…...

【水声信号处理】突破物理极限:下视多波束声呐超分辨率技术原理与公式详解
【水声信号处理】突破物理极限:下视多波束声呐超分辨率技术原理与公式详解 文章目录【水声信号处理】突破物理极限:下视多波束声呐超分辨率技术原理与公式详解一、 为什么我们需要“超分辨率”?(痛点分析)二、 声呐回波…...

Mi-Create:零基础打造个性化小米穿戴表盘的完整实战指南
Mi-Create:零基础打造个性化小米穿戴表盘的完整实战指南 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create Mi-Create是一款专为小米穿戴设备用户打造…...

W25Q16 Flash存储器:从基础概念到SPI通信实战
1. 认识W25Q16 Flash存储器 第一次接触W25Q16是在做一个智能家居项目时,需要保存用户的WiFi配置和房间温湿度记录。当时试过用单片机内部的EEPROM,但容量太小不够用,后来发现了这款性价比超高的外部Flash芯片。简单来说,W25Q16就像…...