大模型学习笔记 - LLM 之RLHF人类对齐的简单总结
LLM - RLHF人类对齐的简单总结
- LLM-人类对齐
- 1. RLHF(Reinforcement Learning from Human Feedback, RLHF),基于人类反馈的强化学习
- 2 奖励模型训练
- 3 强化学习训练
- 3.1 PPO介绍
- 3.2 进阶的RLHF的介绍
- 3.2.1. 过程监督奖励模型
- 3.2.2. 基于AI反馈的强化学习
- 3.2.3. 非强化学习的对齐方法
- 4 关于SFT和RLHF的进一步讨论
本篇完全参考 大语言模型综述 ,学习完大模型学习笔记 - InstructGPT中的微调与对齐 之后 再看书中的这一章节,对InstructGPT的RLHF理解的可以更透彻一些。
1. RLHF(Reinforcement Learning from Human Feedback, RLHF),基于人类反馈的强化学习
- RLHF首先需要收集人类对于不同模型输出的偏好,然后使用收集到的人类反馈数据训练奖励模型,最后基于奖励模型使用强化学习算法(Proximal Policy Optimization,PPO)微调大语言模型。 这是人类对齐的主要途径之一。
- RLHF 关键步骤:
- 监督微调: 指令微调(有监督的训练)为了指令遵循能力。
- 奖励模型:第二步是使用人类反馈数据训练奖励模型。首先使用语言模型针对任务指令生成一定数量的后选输出,随后标注员进行偏好标注,进一步使用人工标注好的数据进行奖励模型训练,使其能够建模人类偏好。
- 强化学习训练:这一步骤中,语言模型对齐被转化为一个强化学习问题,具体来说,待对齐语言模型担任策略实施者的角色(策略模型),它接受提示作为输入并返回输出文本,其动作空间是词汇表中的所有词元,状态指的是当前已生成的词元序列。奖励模型则根据当前语言模型的状态提供相应的奖励分数,用于指导策略模型的优化。为了避免当前训练轮次的语言模型明显偏离初始(强化学习训练之前)的语言模型,通常会在原始优化目标中加一个惩罚性(如KL散度)比如InstructGPT使用PPO算法来优化待对齐语言模型以最大化奖励模型的奖励,对于每个输入提示,InstructGPT 计算当前语言模型与初始语言模型生成结果之间的KL 散度作为惩罚项。KL 散度越大,意味着当前语言模型越偏离初始语言模型。这个对齐过程可以进行多次迭代,从而更好地对齐大语言模型。
2 奖励模型训练
-
训练方式:
- 打分式: 会有标注人员主观bias误差
- 对比式: 一对pair 正负关系。降低标注难度和减少标注不一致性误差
- 排序式:(考虑两两偏序关系)
-
训练策略:为了进一步增强奖励模型对于人类偏好的拟合能力,可以通过修改目标函数、选取合适的基座模型和设置合理的奖励计算形式等方式俩优化奖励模型的训练过程。
-
目标函数的优化:为了避免奖励模型的过拟合问题,可以将最佳的模型输出所对应的语言模型损失作为正则项,从而缓解奖励模型在二元分类任务上的过拟合问题。因此可以在对比式方法的损失函数的基础上添加模仿学习的损失函数,即奖励模型在学习最大化正负例分数差距的同时也学习基于输入x生成正例y+.
L = − E x , y + , y − D [ l o g ( σ ( r θ ( x , y + ) − r θ ( x , y − ) ) ) ] − β E x , y + D [ ∑ t = 1 T l o g ( y t + ∣ x , y < t + ) ] L = -E_{x,y+,y-}~D[log(\sigma(r_\theta(x,y+)-r_\theta(x,y-)))]-\beta E_{x,y+}~D[\sum_{t=1}^T log(y^+_t|x,y^+_{<t})] L=−Ex,y+,y− D[log(σ(rθ(x,y+)−rθ(x,y−)))]−βEx,y+ D[t=1∑Tlog(yt+∣x,y<t+)]
具体解释可以参考:大模型学习笔记 - InstructGPT中的微调与对齐
- 基座模型选取:尽管InstructGPT使用了一个较小的奖励模型(6B参数的GPT3模型),使用更大的奖励模型(例如与原始模型尺寸相等或更大的模型)通常能够更好地判断模型输出质量,提供更准确的反馈信号。LLaMA-2在训练过程中使用相同的checkpoint来初始化待对齐语言模型和奖励模型,由于奖励模型与待对齐模型拥有相同的预训练知识,这方面可以有效地减少两者之间的信息不匹配问题,加强模型对齐效果。
- 奖励计算形式:由于对齐存在多个标准(比如有用性和诚实性),单一奖励模型很难满足所有对齐标准,因此可以针对不同对齐标准训练多个特定的奖励模型 r i ( x , y ) i = 1 n {r_i(x,y)}^n_{i=1} ri(x,y)i=1n,然后使用特定的组合策略(如加权平均)计算基于这些奖励模型的最终奖励。 如其中一种加和组合策略:$ r(x,y) = \sum_{i=1}^n \lambda_i * r_i(x,y) ,其中 r ( ∗ ) 表第 i 种对齐标准的奖励函数, ,其中r(*)表第i种对齐标准的奖励函数, ,其中r(∗)表第i种对齐标准的奖励函数,\lambda_i$ 表示系数。
-
-
奖励函数训练代码
- 以对比式训练的方式,并且添加了模仿学习的正则项来缓解过拟合问题。
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import LlamaForCausalLM,class LlamaRewardRewardModel(LlamaForCausalLM):def __init__(self, config):super().__init__(config)## 初始化线性变换层,将隐状态映射为标量,用于输出最终奖励self.reward_head = nn.Linear(config.hidden_size, 1, bias=False)def _forward_rmloss(self, input_ids, attention_mask, **kwargs):# input_ids:输入词元的标号序列# attention_mask: 与输入相对应的注意力掩码# 将输入词元通过大语言模型进行编码,转化为隐状态output = self.model.forward(input_ids = input_ids,attention_mask = attention_mask,return_dict=True,use_cache=False)#使用线性变换层,将隐状态映射为标量logits = self.reward_head(output.last_hidden_state).squeeze(-1)return logitsdef _forward_lmloss(self, prompt_ids, lm_attn_mask, response_ids):# prompt_ids: 输入词元和输出词元拼接后的标号序列# lm_attn_mask:对应的注意力掩码# response_ids: 计算交叉熵损失时目标的标号序列# 将输入词元通过大语言模型进行编码,转化为隐状态outputs = self.model.forward(input_ids = prompt_ids, attention_mask = lm_attn_mask,return_dict = True,use_cache = False)# 使用交叉熵计算模仿学习的损失,作为最终损失函数中的正则项hidden_states = outputs.last_hidden_statelogits = self.lm_head(hidden_states)loss_fct = nn.CrossEntropyLoss()logits = logits.view(-1, self.config.vocab_size)response_ids = response_ids.view(-1)loss = loss_fct(logits, response_ids)return lossdef forward(self, sent1_idx, attention_mask_1, sent2_idx, attention_mask_2, labels, prompt_ids, lm_attn_mask, response_ids, **kwargs):# sent1_ids: 输入词元和正例输出词元拼接后的标号序列# sent2_ids: 输入词元和负例输出词元拼接后的标号序列# attention_maks_1/2: 正负例对应的掩码# labels: 正例输出所在的序列(均为0,表示正例在sent1_idx中)# prompt_ids:输入词元和正例输出词元拼接后的标号序列# lm_attn_mask:# response_ids: 计算交叉熵损失时目标的标号序列。# 计算正例输出的奖励值reward0 = self._forward_rmloss(input_ids = sent1_ids, attention_mask = attention_mask_1)# 计算负例输出奖励值reward1 = self._forward_rmloss(input_ids = sent2_ids,attention_mask = attention_mask_2)# 计算对比式训练方法的损失函数logits = reward0 - reward1rm_loss = F.binary_cross_entropy_with_logits(logits, labels.to(logits.dtype), reduction='mean')# 计算模仿学习的正则项损失函数lm_loss = self._forward_lmloss(prompt_ids, lm_attn_mask, response_ids)# 计算最终损失loss = rm_loss + lm_lossreturn loss3 强化学习训练
强化学习是RLHF中核心优化算法。一般来说,强化学习旨在训练一个智能体,该智能体与外部环境进行多轮交互,通过学习合适的策略进而最大化从外部环境获得的奖励。在强化学习过程中,智能体是根据外部环境决定下一步行动的决策者,因此其被称为策略模型。在智能体和外部环境第t次交互的过程中,智能体需要根据当前外部环境的状态 s t s_t st选择何时的策略,决定下一步该做出的行动 a t a_t at。当智能体采取了某个行动后,外部环境会从原来的状态 s t s_t st 变化为新的状态 s t + 1 s_{t+1} st+1。此时,外部环境会给与智能体一个奖励分数 r t r_t rt。在和外部环境交互的过程中,智能体的目标是最大化所有决策 t = a 1 , a 2 , . . . . t={a_1,a_2,....} t=a1,a2,.... 能获得的奖励的总和 R ( t ) = ∑ t = 1 T r t R(t)= \sum_{t=1}^T r_t R(t)=∑t=1Trt。形式化来说,假设参数为 θ \theta θ 的策略模型做出的决策轨迹 t的概率为 P θ ( t ) P_\theta(t) Pθ(t), 该决策轨迹在最终状态能够累计获得的奖励为 R ( t ) R(t) R(t),而强化学习的目标就是最大化获得的奖励,即
J ( θ ) = a r g m a x θ E t P θ [ R ( t ) ] = a r g m a x θ ∑ t R ( t ) P θ ( t ) J(\theta) = argmax_\theta E_{t~P_\theta} [R(t)] = argmax_\theta \sum_t R(t)P_\theta (t) J(θ)=argmaxθEt Pθ[R(t)]=argmaxθt∑R(t)Pθ(t)
在自然语言生成任务重,大语言模型(即策略模型)需要根据用户输入的问题和已经生成的内容(即当前状态),生成下一个词元(即对下一步行动做出决策)。当大语言模型完整生成整个回复之后(即决策轨迹),标注人员(或奖励模型)会针对大语言模型生成的恢复进行偏好打分(即奖励分数)。大语言模型需要学习生成回应的有效策略,使得生成的内容能获得尽可能高的奖励,即其生成的内容尽可能符合人类的价值观和偏好。
策略梯度(policy gradient)是一种基础的强化学习算法,训练策略模型在于外部环境交互的过程中学习到较好的更新策略。为了能够对策略模型进行优化,需要计算目标函数的梯度,具体如下式所示:
∇ J ( θ ) = ∑ t R ( t ) ∇ P θ ( t ) \nabla J(\theta) = \sum_t R(t)\nabla P_\theta(t) ∇J(θ)=t∑R(t)∇Pθ(t)
由于 R ( t ) R(t) R(t)为外部环境根据决策轨迹给出的奖励,于策略模型无关,因此该项可以被认为是常数项,计算梯度时不需要进行求导。
得到相应梯度信息后,由于优化目标是最大化获得的奖励总和,因此可以使用梯度上升的方式对决策模型的参数进行优化
θ = θ + n ∗ ∇ J ( θ ) \theta = \theta + n*\nabla J(\theta) θ=θ+n∗∇J(θ)
其中 n为学习率。 在自然语言场景下,生成候选词元的策略空间非常大,因此很难精确计算所有决策轨迹能获得的奖励期望( E t P θ [ R ( t ) ] E_{t~P_\theta} [R(t)] Et Pθ[R(t)])。 为了解决这个问题,一般情况下使用采样算法选取多条决策轨迹,通过计算这些决策轨迹的平均奖励来近似所有决策轨迹的期望奖励。在决策空间 τ \tau τ 中进行采样的时候,需要对目标函数进行如下变化:

其中, τ \tau τ 是所有可能得策略集合,N 表示策略空间 τ \tau τ中采样得到的策略轨迹的数量。
- 在策略梯度算法中,策略模型和外部环境进行交互,并使用交互得到的数据对策略模型的参数进行优化,这是一种在线策略的训练方式(on-policy)。基于在线策略的训练方法,为了保证采样得到的策略轨迹能够近似策略模型做出的决策的期望,需要在每次调整策略模型参数之后重新进行采样。因此策略梯度算法具有较低的数据利用率和鲁棒性。
- 与策略梯度算法不同,近端策略优化使用了离线策略(off-policy) 的训练方式,即训练过程中负责交互与负责学习的策略模型不同。也就是说负责学习的策略模型通过另一个模型与环境交互产生的轨迹进行优化。使用离线测量的训练方法,由于采样的模型是固定的,所以同一批数据可以对负责学习的策略模型进行多次优化,以提升数据的使用效率,使训练过程更为稳定。
3.1 PPO介绍
近端策略优化(Proximal Policy optimization, PPO) 算法是强化学习领域的一种重要优化方法,主要用于训练能够根据外部环境做出行为决策的策略模型。PPO算法在策略梯度算法的基础上,主要使用优势估计来更加准确的评估决策轨迹能获得的奖励,使用了重要性采样来进行离线策略训练。此外为了保证重要性采样的稳定性,PPO算法通过在目标函数中加入了梯度裁剪以及相关的惩罚项来减少采样误差。为了能够实现上述优化过程,PPO在策略模型和奖励模型的基础上,还引入了参考模型和评价模型,下面针对PP0算法的关键步骤进行重点介绍:
- 优势估计:为了能够更好地计算在状态 s t s_t st 做出决策 a t a_t at时的奖励分数,PPO引入了优势函数 A t = Q ( s t , a t ) − V ( s t ) A_t=Q(s_t, a_t) - V(s_t) At=Q(st,at)−V(st),其中 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)表示在当前状态 s t s_t st选取特定决策 a t a_t at能获得的奖励分数, V ( s t ) V(s_t) V(st)表示从当前状态 s t s_t st开始所有决策能够得到的奖励的期望值。 一般情况下, Q ( s t , a t ) Q(s_t,a_t) Q(st,at)的值可以供给与奖励模型计算获得,而 V ( s t ) V(s_t) V(st) 的值则需要训练一个评价模型获得。评价模型可以使用奖励模型来进行初始化,随着PPO 过程中策略模型的训练而进行动态调整。优势函数的作用是引导模型从当前能够做出的所有决策中挑选最佳的决策。
传统策略模型的问题如下:
由于传统策略模型是随机采样的,但凡采样得到的奖励结果是 >0 的 就会提高产生本次采样的概率,然而 虽然奖励是正向的,但是也不是最优决策。
在PPO的优势函数中,通过将决策的奖励与期望奖励做差,产生较低奖励的决策将会得到一个负的优势值,而产生较高奖励的决策会得到一个正的优势值。这些相对较差的决策就会被抑制,同时鼓励策略模型产生收益更高的决策。因此优势函数可以帮助策略模型学习在众多决策中做出更好的选择。
- 重要性采样:important sampling是一种通用的采样技术,通过使用在一个分布P上采样得到的样本,来近似另一个分布q上样本的分布。主要用于分布q难于计算或者采样的情况。 假设需要求解变量x在分布q上函数 f(x)的期望 E x q [ f ( x ) ] E_{x~q}[f(x)] Ex q[f(x)],重要性采样首先将期望转化为积分的形式,然后建立分布p和分布q之间的关系,具体推导如下:

所以分布q上的函数期望,可以通过在分布p上进行采样并且乘以系数 q(x)/p(x)计算进行估计。在离线策略的强化学习训练中,需要使用策略模型 π θ o l d \pi_{\theta_{old}} πθold 与环境进行交互并采样决策轨迹,使用采样得到的决策轨迹近似估算策略模型 π θ \pi_\theta πθ 与环境交互时能获得的奖励的期望。因此可以使用重要性采样来解决这个问题。

基于这个公式,可以针对PPO算法的目标函数进行如下修改,以支持离线策略的训练方式:
-
基于梯度裁剪的目标函数:PPO算法在更新策略时引入了一个关键的限制,通过裁剪策略比率的变化范围,防止策略更新过于激进。
-
基于KL散度的目标函数。PPO可以使用KL散度作为惩罚项来限制策略模型更新幅度。
-
PPO算法步骤:
- 首先,使用经过监督微调的大语言模型作为初始化策略模型 π θ \pi_\theta πθ 和 π θ o l d \pi_{\theta_{old}} πθold。
- 然后,将策略模型 π θ o l d \pi_{\theta_{old}} πθold与环境进行交互,生成决策轨迹。
- 进一步,PPO算法会计算“优势估计”,用于横岭实际奖励与预期奖励之间的差异。
- 最后PPO算法会尝试更新策略模型的参数,使用梯度剪裁或者引入KL散度惩罚的方法,防止策略更新过于激进。
- 经过一定次数的迭代后,PPO算法会重新评估新策略的性能。如果新策略比旧策略有提升,那么新策略就会被接受。

-
训练策略
- 为了提高PPO算法训练的稳定性和训练效率,我们从模型初始化和效率提升两个方面进行讲解:
- 模型初始化:强化学习的训练过程通常具有较高的不稳定性,并且对超参数设置比较敏感,因此在强化学习之前,语言模型通常要经过指令微调,以建立更强的基础模型能力。此外还可以采用“拒绝采样”或“最佳N样本采样”等方法进一步优化语言模型。具体来说,对于给定的对齐数据集中的任务提示,首先使用大语言模型按照特定算法采样N个输出,由奖励模型选择最优的输出。然后使用这些质量较高的输出对策略模型进行监督微调,直至收敛。最后再执行强化学习算法的优化为了保证奖励模型在对齐过程中能够更好地对策略模型的输出进行打分,在LLAMA-2的训练过程中,使用RLHF技术迭代训练了5个版本的模型,奖励模型伴随着大语言模型的优化而逐步改进。在每轮迭代中,针对当前的模型检查点,需要重新收集人类偏好数据,这些偏好数据可以更好地反应当前模型checkpoint的问题,从而针对这些问题进行针对性的调整。
- 效率提升,由于强化学习训练涉及到的大语言模型和奖励模型的迭代解码过程,这将显著增加内存开销和计算成本。为了解决这个问题,一个实用技巧是将两个模型部署在不同额服务器上,并通过调用相应的网络API实现两个模型之间的协同训练,这种方法可以减少单台机器中显卡的显存占用。例如,需要进行训练的策略模型和评价模型部署在服务器A 上,而不需要训练的奖励模型和参考模型部署在服务器B 上。当采样到若干决策轨迹之后,调用网络API 使用奖励模型对这些决策轨迹进行打分,并将分数传回到服务器A 上,对策略模型和评价模型进行训练。此外,RLHF 算法要求大语言模型生成多个候选输出,这一过程需要进行多次采样解码算法的调用。为了加速这一过程,可以采用束搜索解码算法。这种策略可以通过一次解码生成多个候选输出,同时增强生成候选输出的多样性。
-
代表性RLHF工作
- InstructGPT: 《Train Language Models to Follow Instructions with Human Feedback》具体解析请参考 大模型学习笔记 - InstructGPT中的微调与对齐
- 收集指令数据,并对大语言模型进行有监督微调。
- 收集人类反馈数据训练奖励模型。标注人员对于模型生成的输出进行对比与排序,然后训练奖励模型来拟合标注人员的偏好。
- 使用PPO算法和奖励模型进行大语言模型强化学习训练。结合第一步的SFT模型和第二步的奖励模型,使用奖励模型对SFT模型进行微调,从而实现人类价值对齐。后两个步骤迭代多次,基于当前最佳语言模型持续收集数据,进一步训练奖励模型和优化模型的生成策略。
- InstructGPT 1.3B 性能上超过175B的GPT-3.
- LLaMA-2 模型:TODO : 深入学习Llama 2: Open foundation and fine-tuned chat models
-
人类反馈数据收集。考虑开源闭源数据集。随着LLaMA-2训练过程的机械能,模型生成内容的分布会发生改变,进而导致奖励模型发生退化,为了防止这个现象的出现,需要在训练过程中标注新的反馈数据来重新训练奖励模型。
-
奖励模型训练:分开了安全性任务和有用性任务。引入了一个离散函数m(y+,y-)来衡量正例与负例之间的人类偏好差距。

-
强化学习算法:LLaMA-2使用了拒绝采样微调和PPO算法相结合的方法对于模型进行迭代训练。不同于PPO 算法对同一输入仅采样一条回复,拒绝采样微调采样了𝐾 条不同的回复,并使用其中最好的回复对模型进行监督微调。直观上来说,模型更容易从自身生成的示例数据学习到所蕴含的正确行为,这种方法也在实践中被广泛使用。进一步,使用经过拒绝采样微调的模型来初始化PPO 训练中的策略模型,可以提高训练过程的稳定性。
-
- InstructGPT: 《Train Language Models to Follow Instructions with Human Feedback》具体解析请参考 大模型学习笔记 - InstructGPT中的微调与对齐
3.2 进阶的RLHF的介绍
3.2.1. 过程监督奖励模型
强化学习训练的监督信号主要分为两类:结果监督信号和过程监督信号。在结果监督的RLHF算法中,使用一个单独的分数来评估模型生成的整个文本的质量,并且引导大语言模型生成得分高的文本。而过程监督的RLHF算法中,针对模型输出内容的每个组成部分(句子、单词、推理)分别进行评估,从而提供细粒度的监督信号来加强大语言模型的训练,引导模型尽可能高质量地生成每个组成部分,帮助模型改进不理想的生成内容。
- 数据集:OpenAI开放了一个带有细粒度标注数据集合PRM800K
- RLHF训练数据:在RLHF过程中,可以将过程监督奖励模型对于每个标签的预测概率作为监督信号,甚至作为强化学习中优势函数的一个组成部分。为了有效利用奖励模型产生的过程监督信息,可以使用专家迭代的方法来训练大语言模型,这是一种通过向专家策略学习进而改进基础策略的强化学习方法。通常,专家迭代方法包含两个主要阶段:策略改进和蒸馏。在策略改进阶段,转接策略进行广泛的搜索并生成样本,过程监督奖励模型引导专家策略在搜索过程中生成高质量的样本。具体来说,在专家策略在搜索过程中,过程监督奖励模型基于当前的状态和决策轨迹,对专家策略的下一步决策进行打分,辅助专家策略选取更好的决策(即分数更高的决策)。随后在蒸馏阶段,进一步使用第一阶段由专家策略生成的样本对基础策略(待对齐的语言模型)进行监督微调。
- 过程监督奖励模型的扩展功能:
3.2.2. 基于AI反馈的强化学习
收集人类反馈是一件非常耗时和耗资源的工作。所以基于AI的反馈可以降低成本。
- 已对齐大语言模型的反馈:Constitutional AI. 该算法分为监督微调与强化学习两个步骤,首先利用经过RLHF训练的大语言模型,针对输入的问题生成初步回复。为确保生成的回复与人类价值观和偏好相符,算法进一步采用评价和修正的方法对初步回复进行调整和修改。具体来说,在评价阶段,使用提示引导大语言模型判断之前生成的初步回复是否存在问题,在修正阶段,将大语言模型生成的初步回复和评价进行拼接,使用提示引导大语言模型对初步回复进行修改,以得到符合人类价值观的回复。这些输入问题及最终与人类价值观相符的回复被用于大语言模型的监督微调阶段,以提升模型的性能。微调完成后,利用一个独立的偏好模型对微调模型输出进行评估,从两个输出中挑选更符合人类价值观的输出,并根据评估结果训练一个奖励模型,最终将第一步中经过微调的模型通过奖励模型的反馈进行强化学习,得到与人类偏好对齐的大语言模型。在大语言模型对齐方面,RLAIF能够取得与RLHF相近的效果,甚至在部分任务重RLAIF的性能超越了RLHF.
- 待对齐大语言模型的自我反馈: MetaAI 和NYU 研究团队共同提出了一个新的RLAIF算法。使用策略模型对自己的输出进行反馈,通过自我反馈进行对齐训练。首先使用策略模型针先对输入文本生成多个候选输出。然后 使用相应的提示引导策略模型对自己生成的文本进行打分,得到了所有候选输出的打分之后,根据分数高低选择该输入文本对应的期望输出(即正例) 和不期望输出(即负例)。输入文本及其对应的正例输出和负例输出构成了训练过程所需的数据集。当训练数据构造完成之后,使用DPO算法对策略模型进行训练,进一步提升模型的性能,研究人员使用70B参数的LLaMA-2来初始化策略模型并进行训练,对齐后的策略模型在AlpacaEval2.0的评测排行榜上超过了Claude-2,GeminiPro 和GPT-4 0613的性能。
- TODO 学习 Self-Rewarding Language Models 论文, Constitutional AI: Harmlessness from AI Feedback 论文。
3.2.3. 非强化学习的对齐方法
RLHF虽然有效,但是也有一些局限性。
首先,RLHF训练过程中,需要同时维护和更新多个模型,这些模型包括 策略模型、奖励模型、参考模型以及评价模型。这不仅会占用大量的内存资源,而且整个算法的执行过程也相对复杂。此外,RLHF中常用的近端策略优化算法在优化过程中的稳定性欠佳,对超参数取值较为敏感,这进一步增加了模型训练的难度和不确定性。为了克服这些问题,研究人员提出了一些列直接基于监督微调的对齐方法,旨在通过更简洁、更直接的方式来实现大语言模型与人类价值对齐,进而避免复杂的强化学习算法带来的种种问题。
非强化学习的对齐方法旨在利用高质量的对齐数据集,通过特定的监督学习算法对于大语言模型进行微调。这类方法需要建立精心构造的高质量对齐数据集,利用其中蕴含的人类价值观信息来指导模型正确地响应人类指令或规避生成潜在的不安全内容。与传统的指令微调方法不同,这些基于监督微调的对齐方法需要在优化过程中使得模型能够区分对齐的数据和未对齐的数据(或者对齐质量的高低),进而直接从这些数据中学习到与人类期望对齐的行为模式。
重点:构建高质量对齐数据集, 设计监督微调对齐算法。
- 对齐数据集
- 基于奖励模型的方法
- 基于大语言模型的方法
- 监督微调对齐算法
- 代表性监督对齐算法DPO(Direct Preference Optimization,DPO) 直接偏好优化,是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO可以通过与有监督微调相似的复杂度实现模型对齐、不再需要再训练过程中针对大语言模型进行采样,同时超参数的选择更加容易。
- DPO算法介绍:
- 由于奖励建模的过程较为复杂,需要额外的计算开销,DPO 算法的主要思想是在强化学习的目标函数中建立决策函数与奖励函数之间的关系,以规避奖励建模的过程。DPO 算法首先需要找到奖励函数𝑟 (𝑥, 𝑦) 与决策函数𝜋𝜃 (𝑦|𝑥)之间的关系,即使用𝜋𝜃 (𝑦|𝑥) 来表示𝑟 (𝑥, 𝑦)。然后,通过奖励建模的方法(如公式8.2)来直接建立训练目标和决策函数𝜋𝜃 (𝑦|𝑥) 之间的关系。这样,大语言模型就能够通过与强化学习等价的形式学习到人类的价值观和偏好,并且去除了复杂的奖励建模过程。
- 其他有监督对齐算法
- 基于质量提示的训练目标
- 基于质量对比的训练目标
4 关于SFT和RLHF的进一步讨论
指令微调是一种基于格式化的指令示例数据(即任务描述与期望输出相配对的数据)对大语言模型进行训练的过程。在大语言模型的背景下,这种利用配对文本进行训练的方法也被广泛地称为监督微调(SupervisedFine-Tuning, SFT)。为了保持与相关学术论文中术语的一致性,我们在本章后续的内容中将主要采用“监督微调”这一术语,而非“指令微调”。在InstructGPT 中,研究人员将监督微调(SFT)作为RLHF 算法的第一个步骤。为了更好地阐述这两种技术的重要性及其相关特点,我们将SFT 和RLHF 视为两种独立的大模型训练方法

4.1 基于学习方式的总体比较:
我们可以将文本生成问题看作为一个基于强化学习的策过程。具体来说,当给定一个提示作为输入时,大语言模型的任务是生成与任务指令相匹配的输出文本。这个生成过程可以被分解为一系列逐个词元的生成步骤。在每个步骤中,大语言模型会根据已有的策略模型(即模型本身)在当前状态下的情况(包括当前已生成的词元序列以及可利用的上下文信息)来选择下一个动作,即生成下一个词元。
在这种设定下,我们优化的目标是让大语言模型能够不断优化其生成策略,生成更高质量的输出文本,获得更高的奖励分数。
总体来说,RLHF 和SFT 可以被视为两种优化大语言模型决策过程的训练方法。
- 在RLHF 中,我们首先学习一个奖励模型,然后利用该奖励模型通过强化学习算法(如PPO)来改进大语言模型。
- 而在SFT 中,我们则采用了Teacher-Forcing 的方法,直接优化模型对实例输出的预测概率。从本质上说,SFT 所采用的这种词元级别的训练方式是一种“行为克隆”(模仿学习的一种特殊算法)。它利用教师的行为数据(即每个步骤的目标词元)作为监督标签,来直接训练大语言模型模仿教师的行为。
- 在实现上,SFT 主要依赖于序列到序列的监督损失来优化模型,而RLHF 则主要通过强化学习方法来实现大模型与人类价值观的对齐。本质上来说,为了学习教师的生成策略,SFT 采用了基于示例数据的“局部”优化方式,即词元级别的损失函数。作为对比,RLHF 则采用了涉及人类偏好的“全局”优化方式,即文本级别的损失函数.
4.2 SFT 优缺点
关于SFT,人们普遍认为其作用在于“解锁”大语言模型的能力,而非向大语言模型“注入”新能力。因此,试图通过SFT 激发大语言模型的非内生能力时,可能会出现一些负面问题。当待学习的标注指令数据超出了大语言模型的知识或能力范围,例如训练大语言模型回答关于模型未知事实的问题时,可能会加重模型的幻象(Hallucination)行为。OpenAI 强化学习研究团队的负责人、PPO 算法的作者John Schulman 在一场关于RLHF 的讲座中提出了一个有趣的观点:通过蒸馏较大模型来训练较小模型可能会增加模型生成幻觉文本的可能性,从而可能影响大语言模型的事实准确性。实际上,目前无论学术界和工业界都在大量使用GPT-4 进行指令微调数据的蒸馏,在这一过程中除了要考虑指令数据本身的质量外,还需要进一步关注模型自身的知识与能力边界,从而减少微调过程中所产生的负面效应,如上述提到的幻象问题。此外,作为一种基于行为克隆的学习方法,SFT 旨在模仿构建标注数据的教师的行为,而无法在这一过程中进行有效的行为探索。然而,标注者在写作风格、创作水平和主题偏好等方面经常存在一定的差异,这些都会使得标注数据中出现不一致的数据特征,进而影响SFT 的学习性能。因此,在SFT 阶段,高质量的指令数据(而非数量)是影响大语言模型训练的主要因素。
4.3 RLHF 优缺点
在InstructGPT中,研究人员主要关注使用RLHF 加强模型对于人类价值观的遵循,减少模型输出的有害性。
在最近的研究中,相关研究发现RLHF 在减少有害内容输出的同时,也能够有效增强模型的综合能力,这一点在LLaMA-2 的论文中有着充分讨论。LLaMA-2 通过广泛的实验证明RLHF 可以同时提高模型的有用性和无害性分数,并从两个方面解释了RLHF 相比SFT 的潜在优势。
- 首先,在RLHF 算法中,标注员主要为训练过程提供偏好标注数据,而不是直接生成示例数据,因此它可以减少标注员之间的不一致。
- 其次,与编写示例数据相比,偏好标注更为简单易行。标注员甚至可以评估超出自己创作水平的模型输出质量,使得模型能够探索标注员能力之外的状态空间,而不用受限于给定的教师示例。
- 上述这两个方面都使得RLHF在数据标注阶段相比SFT 更加具有优势,更加容易充分发挥人类指导的作用。
在模型学习阶段,RLHF 通过对比模型的输出数据(区分“好”输出与“坏”输出)来指导大语言模型学习正确的生成策略,它不再强迫大语言模型模仿教师的示例数据,因此可以缓解上述提到的SFT 所导致的幻象问题。在RLHF 方法中,奖励模型非常重要。一般来说,奖励模型应该能够了解待对齐的大语言模型的知识或能力范畴。例如,LLaMA-2 采用了待对齐语言模型的检查点来初始化奖励模型。实际上,RLHF 已被证明是减少GPT-4 幻觉生成的重要方法。然而,RLHF也继承了经典强化学习算法的缺点,如样本学习效率低和训练过程不稳定等问题。因此,当训练语言模型时,RLHF 需要依赖于经过SFT 的模型作为策略模型的初始模型,从而快速达到较好的表现。这也是InstructGPT 采用SFT 作为RLHF 方法的第一步的主要原因。此外,RLHF 的过程通常会持续多轮,这是一个复杂的迭代优化过程,其中涉及了很多重要细节的设定(例如提示选择、奖励模型训练、PPO的超参数设置以及训练过程中对超参数的调整),都会影响整个模型的性能,对于精确的高效复现提出了较大挑战。
总的来说,SFT 特别适合预训练后增强模型的性能,具有实现简单、快速高效等优点;而RLHF 可在此基础上规避可能的有害行为并进一步提高模型性能,但是实现较为困难,不易进行高效优化。未来的研究仍然需要探索更为有效的对齐方法,同时结合SFT 与RLHF 的优点。此外,还需要关注当模型能力达到较强水平后更为有效的对齐方法。针对这个问题,OpenAI 提出了“超级对齐”(Super-alignment)这一研究方向,旨在能够有效监管具有超级智能的人工智能系统。
参考:
大语言模型综述
相关文章:
大模型学习笔记 - LLM 之RLHF人类对齐的简单总结
LLM - RLHF人类对齐的简单总结 LLM-人类对齐 1. RLHF(Reinforcement Learning from Human Feedback, RLHF),基于人类反馈的强化学习2 奖励模型训练3 强化学习训练 3.1 PPO介绍3.2 进阶的RLHF的介绍 3.2.1. 过程监督奖励模型3.2.2. 基于AI反馈的强化学习3.2.3. 非强化学习的对齐…...

【从零开始一步步学习VSOA开发】 概述
概述 概念 VSOA(Vehicle SOA)是翼辉为了解决任务关键型系统不能适用当前微服务通信架构问题而设计的⼀个轻量级适用于任务关键领域的微服务通信架构,以方便开发者构建大型分布式松耦合软件系统,且支持并行开发。 特点 其主要特…...

小程序背景图片无法通过 WXSS 获取
问题:pages/index/index.wxss 中的本地资源图片无法通过 WXSS 获取 可以使用网络图片,或者 base64,或者使用标签。 将图片转换为base64,地址 base64图片在线转换工具 - 站长工具 在这里把要使用的图片转换一把,然后将得…...

CC++内存魔术:掌控无形资源
hello,uu们,今天呢我们来详细讲解C&C的内存管理,好啦,废话不多讲,开干 1:C/C内存分布 2:C语言中动态内存管理方式:malloc/calloc/realloc/free 3:C内存管理方式 3.1:new/delete操作内置类型 3.1.1:代码1 3.1.2:代码2 3.2:new和delete操作自定义类型 3.2.1:C语言创建…...
算法--初阶
1、tips 1.1、set求交集 {1,2,3} & {2,3} & {1,2} {2} 其实就是位运算, 只有set可以这样使用, list没有这种用法 {1,2,3} | {2,3, 4} | {1,2} {1, 2, 3, 4} 并集 1.2、*与** * 序列(列表、元组)解包,如果是字典,那…...

通过Java实现插入排序(直接插入,希尔)与选择排序(直接选择,堆排)
目录 (一)插入排序 1.直接插入排序 (1)核心思想: (2)代码实现(以从小到大排序为例): (3)代码分析: 2.希尔排序(…...

大型分布式B2B2C多用户商城7.0企业版源码分享【java语言、方便二次开发】
项目介绍 项目基于SpringBoot开发,运营端和商户端采用ElementVue,买家使用采用VueIviewnuxt服务端渲染。使用到的中间件有Redis、RabbitMQ、ElasticSearch、FastDFS、Mongodb等。主要功能包括有运营管理、商品管理、订单管理、售后管理、会员管理、财务…...
)
C++的结构体、联合体、枚举类型(一)
1.C++的结构体 2.C++的联合体 3.C++的枚举类型 1.C++的结构体 (1)C++中定义结构体变量,可以省略struct关键字 struct XX{…}; XX x;//定义结构体变量直接省略struct(2)C++结构体中可以直接定义函数,谓之成员函数(又叫方法)(3)在成员函数中可以直接访问该结构体的成员变…...
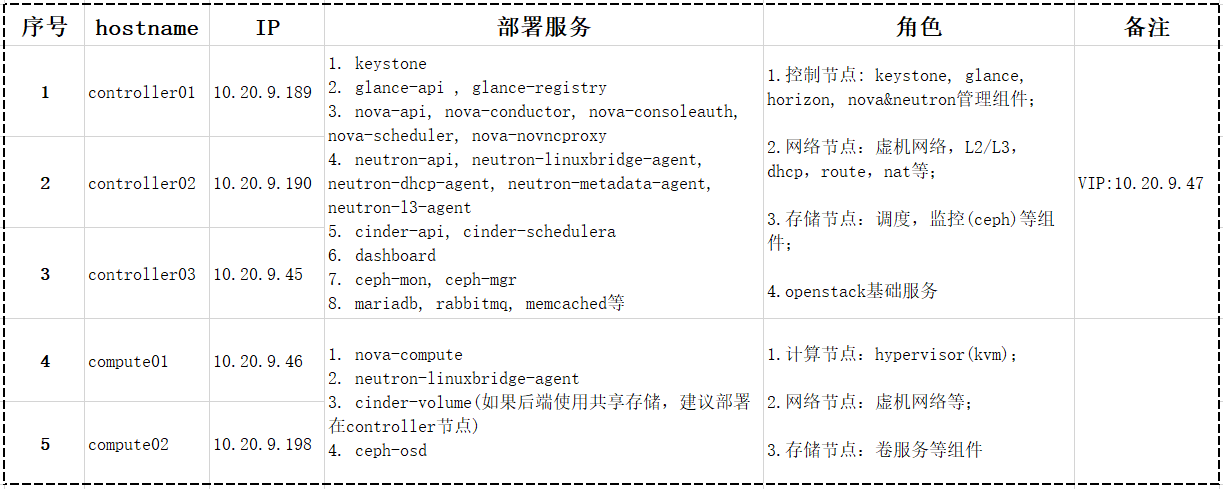
搭建高可用OpenStack(Queen版)集群(一)之架构环境准备
一、搭建高可用OpenStack(Queen版)集群之架构环境准备 一、架构设计 二、初始化基础环境 1、管理节点创建密钥对(方便传输数据) 所有控制节点操作 # ssh-keygen #一路回车即可 Generating public/private rsa key pair. Enter f…...
通过Stack Overflow线程栈溢出的问题实例,详解C++程序线程栈溢出的诸多细节
目录 1、问题说明 2、从Visual Studio输出窗口中找到了线索,发生了Stack Overflow线程栈溢出的异常 3、发生Stack Overflow线程栈溢出的原因分析 4、线程占用的栈空间大小说明 5、引发线程栈溢出的常见原因和场景总结 6、在问题函数入口处添加return语句&…...

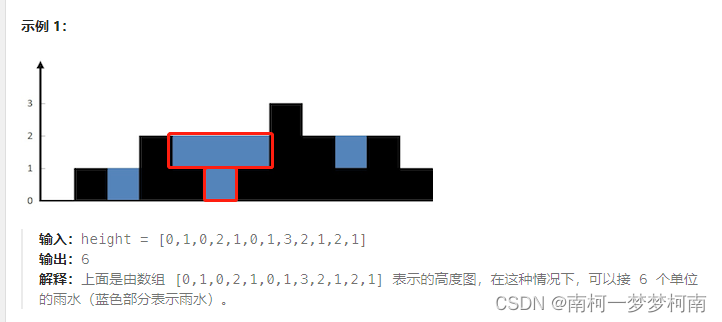
LeetCode刷题笔记 | 3 | 无重复字符的最长子串 | 双指针 | 滑动窗口 | 2025兴业银行秋招笔试题 | 哈希集合
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 这是一道银行的面试题,就是简单?! LeetCode链接:3. 无重复字符的最长子串 1.题目描述 给定一个字符串 s ,…...

验证cuda和pytorch都按照成功了
要验证您的PyTorch是否能够调用CUDA,您可以执行以下步骤: 1. **检查CUDA是否可用**: 在Python中运行以下代码来检查CUDA是否可用: python import torch print(torch.cuda.is_available()) 如果输出为 True&…...

iOS开发如何自己捕获Crash
为了在iOS中捕获和处理未捕获的Objective-C异常和系统信号引起的崩溃,可以使用NSSetUncaughtExceptionHandler和标准的Unix信号处理机制来实现。这能帮助你记录绝大部分的崩溃信息。以下是详细的实现步骤和代码示例: 一、系统崩溃处理 通过NSSetUncaug…...
)
雪花算法(Snowflake Algorithm)
雪花算法(Snowflake Algorithm)是一种分布式唯一ID生成算法,主要用于生成全球唯一的ID,广泛应用于分布式系统中,例如在数据库中作为主键。这个算法最初由Twitter提出,并且被广泛使用在很多大规模系统中。有…...

〖任务1〗ROS2 jazzy Linux Mint 22 安装教程
前言: 本教程在Linux系统上使用。 目录 一、linux安装二、linux VPN安装三、linux anaconda安装(可选)四、linux ROS2 安装五、rosdep init/update 解决方法六、安装GUI 一、linux安装 移动硬盘安装linux:[LinuxToGo教程]把ubunt…...

图像增强:使用周围像素填充掩码区域
制作图像需要填充的掩码区域,对需要填充的位置的mask赋值非0,不需要填充赋值为0使用cv2.inpaint对图像掩码mask中非0元素位置的图像像素进行修复。从而实现使用周围像素填充掩码区域cv2.inpaint 是 OpenCV 库中的一个函数,用于图像修复(inpainting),即填充图像中的损坏区…...

给虚拟机Ubuntu扩展硬盘且不丢数据
1.Ubuntu关机状态下先扩展,如扩展20GB 2.进入ubuntu,切换root登录,必须是root全选,否则启动不了分区工具gparted 将新的20GB创建好后,选择ext4,primary; 3.永久挂载 我的主目录在/并挂载到/dev/sda1 从图…...
如何使用PL/SQL批量处理数据?)
Oracle(41)如何使用PL/SQL批量处理数据?
在PL/SQL中,批量处理数据是一种高效的方法,可以在数据库中处理大量数据,而无需逐行操作。批量处理数据的关键技术包括: PL/SQL表(索引表):在内存中存储数据以进行批量操作。FORALL语句…...

JavaEE 第2节 线程安全知识铺垫1
目录 一、通过jconsole.exe查看线程状态的方法 二、Thread类的几种常见属性 三、线程状态 一、通过jconsole.exe查看线程状态的方法 通过jconsole查看线程状态非常实用的方式 只要你安装了jdk,大致按照这个目录就可以找到这个可执行程序: 然后双击这…...

LeetCode Hot100 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的。 示…...

终极指南:如何使用ROFL-Player轻松管理英雄联盟回放文件
终极指南:如何使用ROFL-Player轻松管理英雄联盟回放文件 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 英雄联盟回放分析工…...

终极指南:5分钟为Jellyfin打造专业中文动漫库的完整方案
终极指南:5分钟为Jellyfin打造专业中文动漫库的完整方案 【免费下载链接】jellyfin-plugin-bangumi bgm.tv plugin for jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-bangumi 还在为Jellyfin动漫库信息不全而烦恼吗?Je…...

从拧电阻到看数码管:蓝桥杯NE555频率测量实验的硬件原理与软件实现全解
从拧电阻到看数码管:蓝桥杯NE555频率测量实验的硬件原理与软件实现全解 当你第一次面对蓝桥杯开发板上那个小小的蓝色NE555芯片和密密麻麻的电阻电容时,可能会感到一丝困惑。为什么调节RB3电阻会改变数码管显示的数字?为什么NE555的输出要接到…...

PowerToys Awake:三招告别电脑自动休眠,让工作流程永不中断
PowerToys Awake:三招告别电脑自动休眠,让工作流程永不中断 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trend…...

暗黑破坏神2存档修改器终极指南:3步打造完美角色
暗黑破坏神2存档修改器终极指南:3步打造完美角色 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit Diablo Edit2是一款功能强大的暗黑破坏神2存档修改工具,这款开源免费的存档…...

2026最权威的降AI率网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 如今,AIGC内容检测技术越来越成熟,这使得机器生成的文本面临着严格的…...

DiffThinker:多模态扩散模型的推理与生成实践
1. 项目背景与核心价值 DiffThinker这个项目名称本身就透露着有趣的矛盾感——将"扩散模型"(Diffusion)与"思维者"(Thinker)结合,暗示了一种能像人类一样进行多模态推理的生成系统。作为一名长期跟…...
)
PHP 9.0协程+AI SDK双引擎落地指南:7步从Hello World到生产级聊天机器人(含OpenAI/本地LLM双路径)
更多请点击: https://intelliparadigm.com 第一章:PHP 9.0协程与AI聊天机器人的时代交汇 PHP 9.0 正式引入原生协程(Coroutines)支持,通过 async/await 语法与轻量级用户态调度器,彻底摆脱传统阻塞 I/O 的…...

Word2Vec原理与应用:从词向量到NLP实战
1. Word2Vec:当词语成为魔法向量的秘密 2003年,我在处理一个新闻分类项目时首次遭遇了"语义鸿沟"问题——计算机无法理解"苹果"和"Orange"都是水果,而"Apple"同时还代表科技公司。直到2013年Word2Ve…...
Unity UI动效新思路:用TextMeshPro的Sprite Asset制作动态表情和图标文字(含在线工具推荐)
Unity UI动效新思路:用TextMeshPro的Sprite Asset制作动态表情和图标文字 在游戏UI设计中,动态表情和图标文字是提升用户体验的关键细节。传统的实现方式往往需要依赖多个Image组件和Animator控制器,不仅增加场景复杂度,还会影响…...