【C语言】你真的了解结构体吗

引言✨
我们知道C语言中存在着整形(int、short...),字符型(char),浮点型(float、double)等等内置类型,但是有时候,这些内置类型并不能解决我们的需求,因为我们无法用这些单一的内置类型来描述一些复杂的对象,如一个学生,一本书等等。出于这个原因,C语言还给我们提供了一些自定义的数据类型使我们可以自己来构建类型,如结构体、枚举、联合体。其中最常使用的就是我们本期的主题:结构体。
可能有很多人已经使用过结构体类型来解决一些实际问题了。但是对于结构体,还是有很多细节值得我们去深挖的,下面就让我们来看看吧!
温馨提示:可以通过目录进行快速定位哦😍
结构体的声明💫
2.1 结构体的基础知识
在开启本期内容之前,我们先来回顾以下结构体的基本概念:
结构体是C语言中一个非常重要的数据类型。该数据类型是由一组称为成员变量的数据组成,其中每个成员可以是不同类型的变量,甚至可以是另一个结构体变量。结构体通常用来表示类型不同但又相关的若干数据。
2.2 结构体的声明
结构体的声明格式如下:
struct tag
{member-list;
}variable-list;struct是结构体关键字,我们要定义结构体类型时必须使用它
tag是结构体标签,它用来区分不同的结构体类型
结构体关键词与标签共同组成了结构体的类型,与int,float这些是一个意思,我们可以使用struct tag+变量名来定义一个结构体变量。
member-list代表成员列表,它包含了结构体的成员变量。
variable-list表示变量列表,我们可以在声明结构体类型的同时创建结构体变量。当然我们也可以不写,仅声明一个结构体类型。
结构体大括号后面的分号必不可少。
例如,我们可以这样使用结构体来描述一个学生:
//声明一个学生类型
struct Student
{char name[20];//姓名char sex[5];//性别char id[20];//学号int age;//年龄float score;//绩点
};int main()
{struct Student s1;//定义一个学生结构体变量s1
}当然,如果你嫌结构体的类型名太长,写起来麻烦,可以使用typedef对类型进行重命名,如下:
//声明一个学生类型,并用typedef类型重定义为Stu
typedef struct Student
{char name[20];//姓名char sex[5];//性别char id[20];//学号int age;//年龄float score;//绩点
}Stu;int main()
{Stu s1;//相当于sturuct Student s1
}2.3 特殊的声明
除以上的声明方式,我们也可以使用不完全的声明。例如:
//声明匿名结构体类型
struct
{int a;char b;float c;
}x;struct
{int a;char b;float c;
}a[20], *p;
上面两个结构体的声明省略了结构体标签tag,我们把这样的结构体类型称作匿名结构体类型。
但是,这样子的声明往往是一次性的。由于我们省略了标签,我们就无法在其他地方使用这个类型来创建一个结构体变量。毕竟连名字都没有,怎么用来定义变量。
当然,如果你只想用一次你创建的类型,或者你不想要这个结构体类型被别人使用,你可以声明一个匿名结构体类型。
那么问题来了:
int main()
{//在上面匿名结构体声明的基础上,下面的代码合法吗?p = &x;
}答案是编译器会报警告:
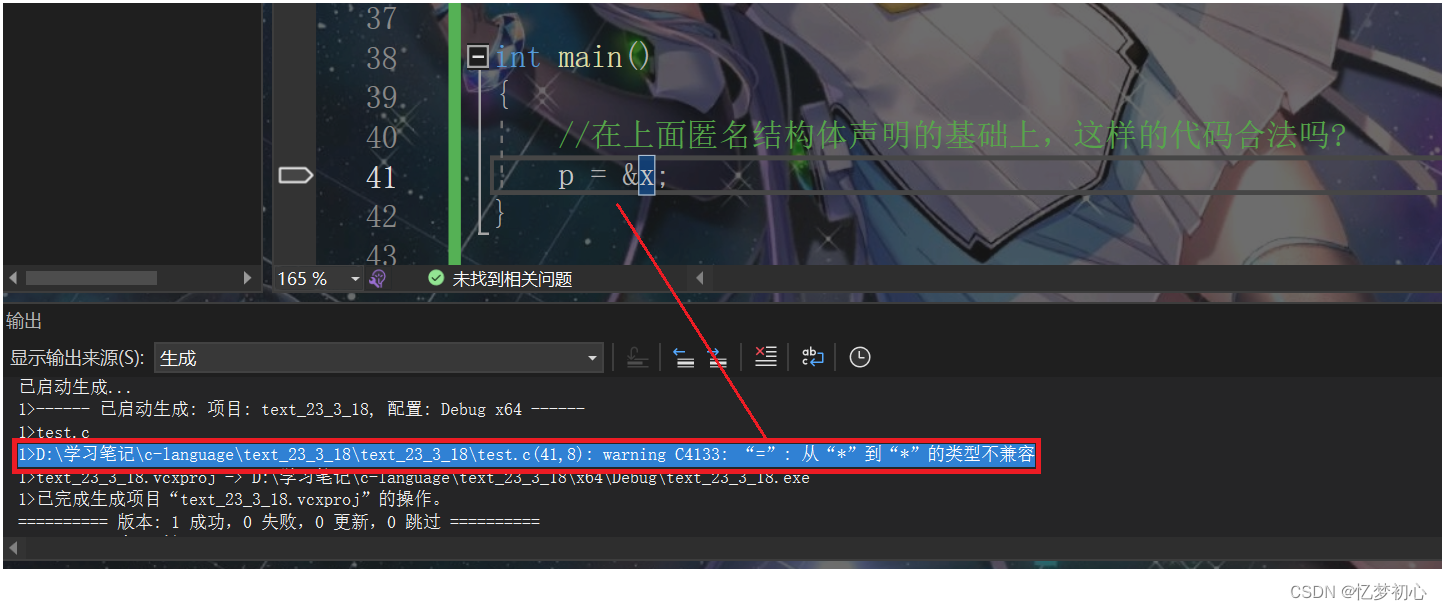
尽管两个匿名结构体的成员列表一模一样,但是编译器依然会将其当作两个完全不同的类型,两个不透类型的指针相互赋值自然是非法的。
结构体的自引用🌟
我们在创建链表时,往往用结构体来表示链表的结点。结构体的成员分为数据域与指针域:
数据域:用来存储当前结点的值
指针域:用来存储指向下一结点的地址
typedef int ListDataType;
struct ListNode
{ListDataType val;//数据域struct ListNode* next;//指针域
};我们将上面这种结构体中包含有指向自身结构体变量的指针的方式称作结构体的自引用。其中val占4个字节,next是个指针,占4/8个字节,结构体具有一个确定的大小。
那既然我们这样声明结点目的是为了能够找到下一结点的位置,那我们可不可以这样设计结点:
typedef int ListDataType;
struct ListNode
{ListDataType val;//数据域struct ListNode next;//保存下一结点
};答案是不行的。假如可以这样设计,那么sizeof( struct ListNode)的大小该是多少呢?我们是求不出来的,因为假设我们用这个类型创建了一个结构体变量n,那么n中包含着next,next也是结构体变量,又包含着一个next变量,next又包含着next...,这样下去就变成了无限套娃。既然不知道大小,我们又要如何分配空间给结构体变量呢?
注意:
//这样写代码,可行否?
typedef struct
{int data;Node* next;
}Node;显然是不行的,凡是都要讲究个先来后到。当我们在成员列表中定义Node*类型的变量时,此时编译器还不知道Node是什么鬼东西,自然会报错。我们可以这样修改代码:
//解决方案:
typedef struct Node
{int data;struct Node* next;
}Node;Node* pn;//定义一个结构体指针pn4. 结构体变量的定义和初始化🌊
有了结构体类型,那我们要如何定义变量呢?实则很简单
struct Point
{int x;int y;
}p1; //声明类型的同时定义变量p1struct Stu //类型声明
{char name[15];//名字int age; //年龄
};
int main()
{//定义结构体变量p2struct Point p2; //初始化:定义变量的同时赋初值。struct Point p3 = { 3, 4 };//初始化struct Stu s = { "zhangsan", 20 };
}结构体嵌套结构体的初始化方式如下:
struct Point
{int x;int y;
}p1; //声明类型的同时定义变量p1
struct Node
{int data;struct Point p;struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化int main()
{struct Node n2 = { 20, {5, 6}, NULL };//结构体嵌套初始化
}5.结构体的内存对齐
🔉快醒醒,别睡了
终于到了本期的重点内容了,我们来看下面例题:
//练习
struct S1
{char c1;int i;char c2;
};
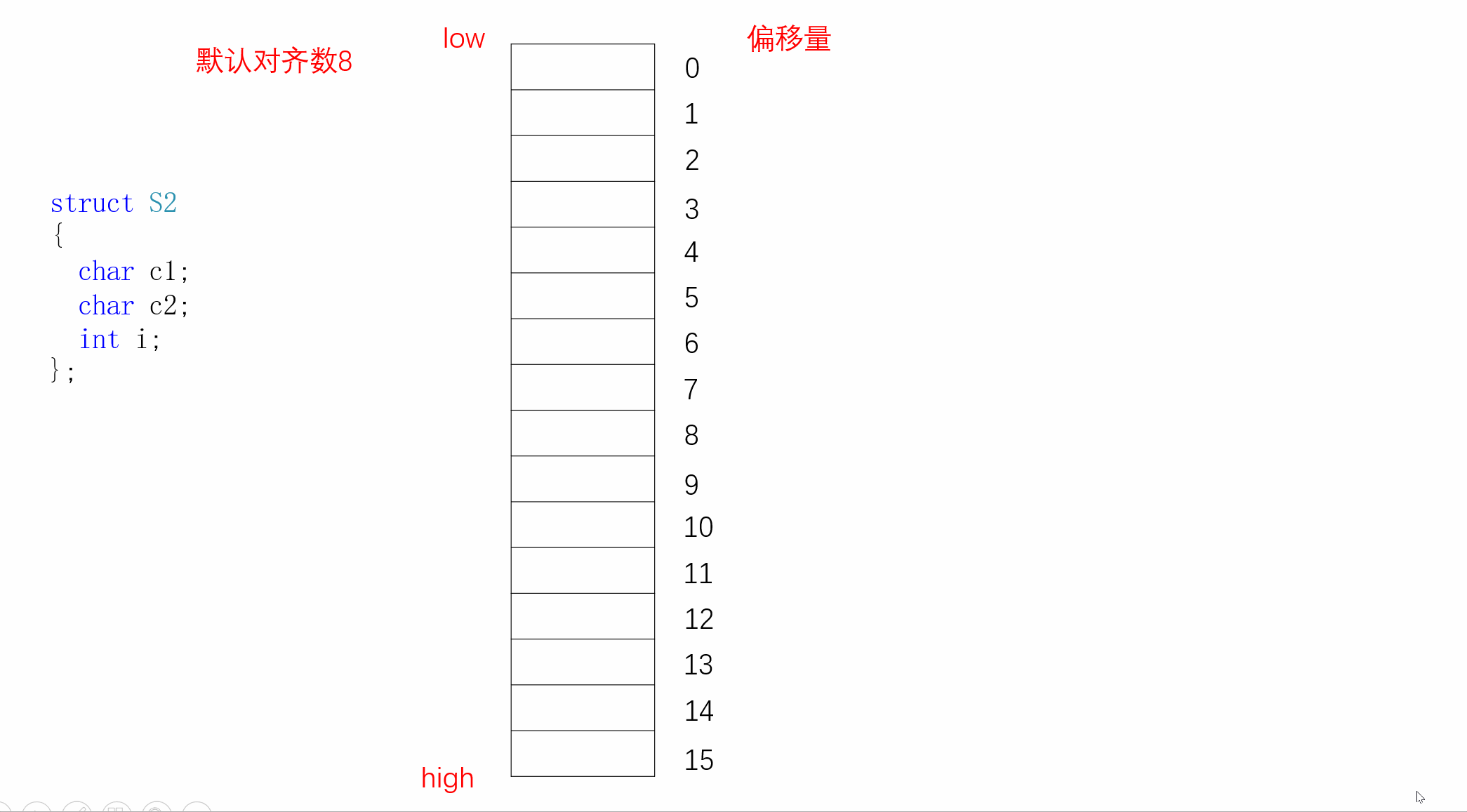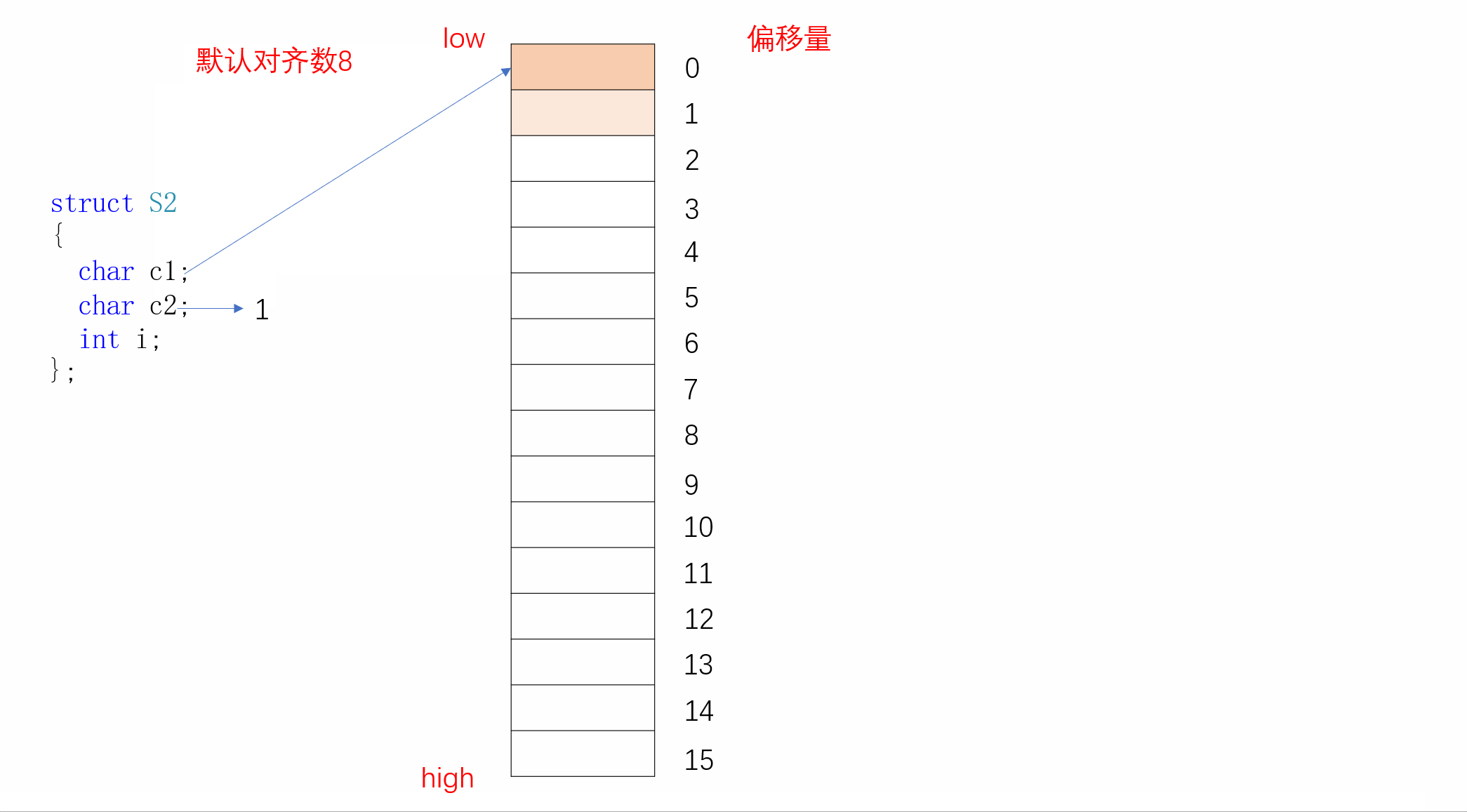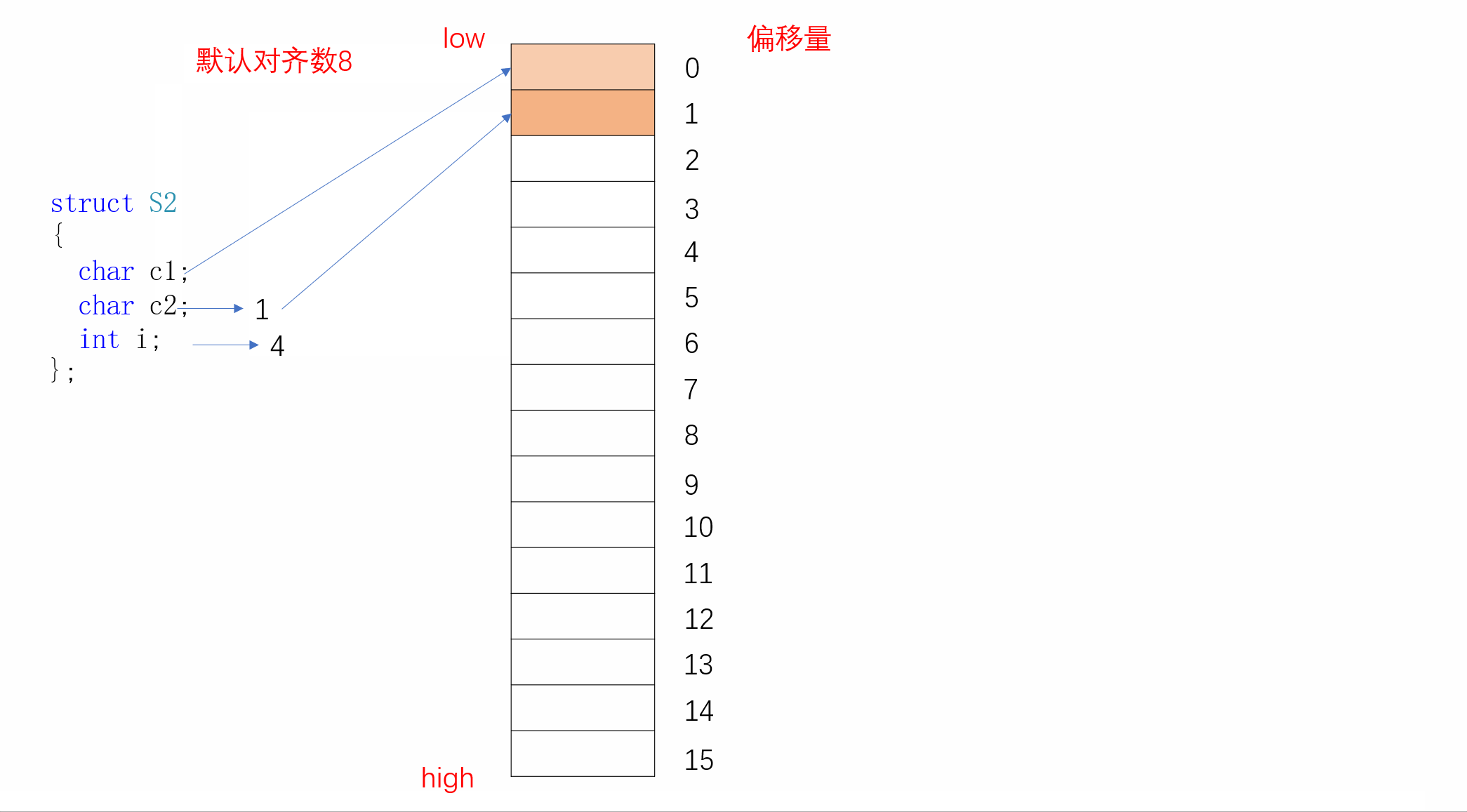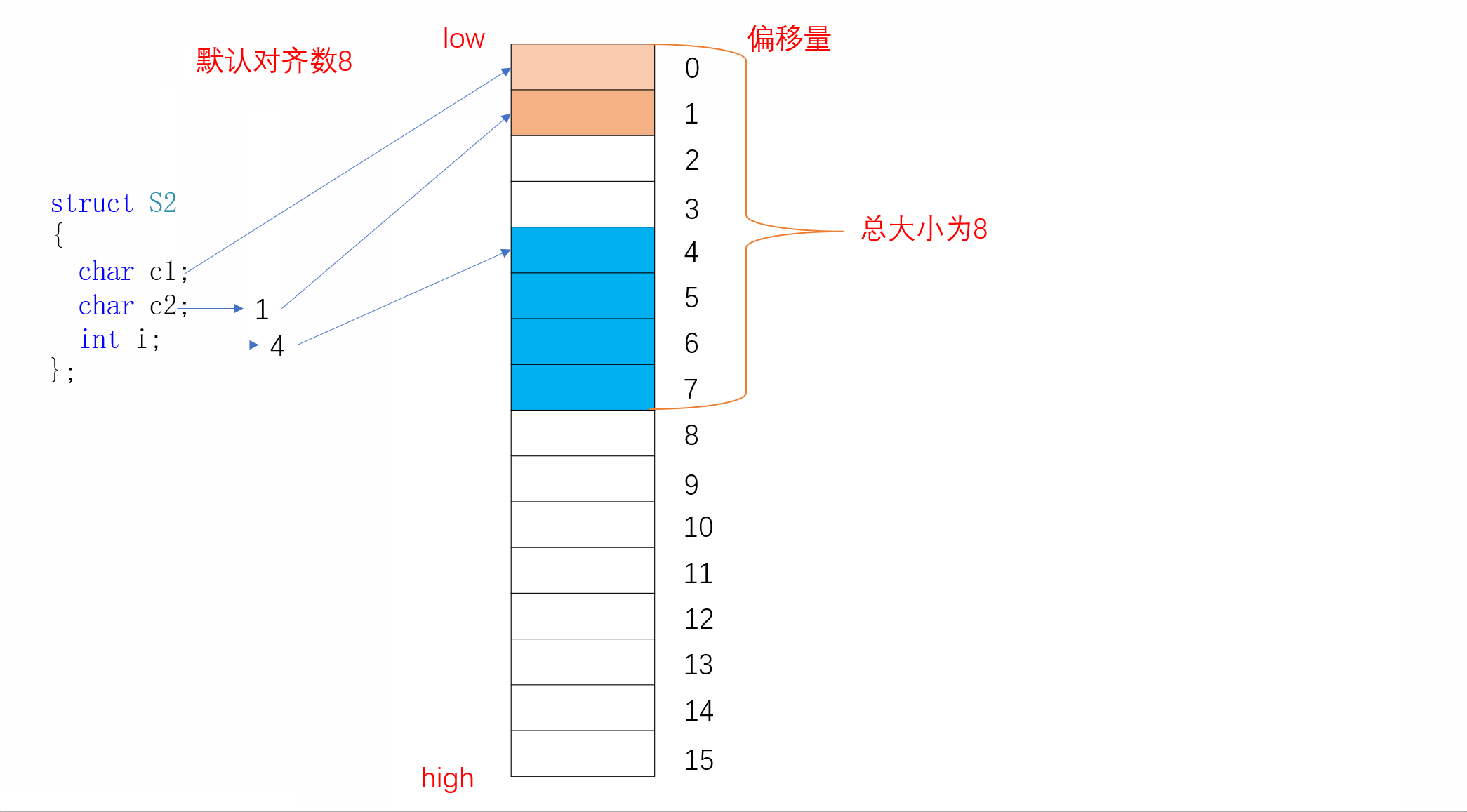
struct S2
{char c1;char c2;int i;
};
int main()
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}答案如下:

这里可能有人就纳闷了,欸,char类型占1个字节,int类型占4个字节,s1与s2的大小不应该都是1+1+4=6吗?怎么会是12和8呢?这就要谈到结构体在内存中的存储了,即结构体的内存对齐。
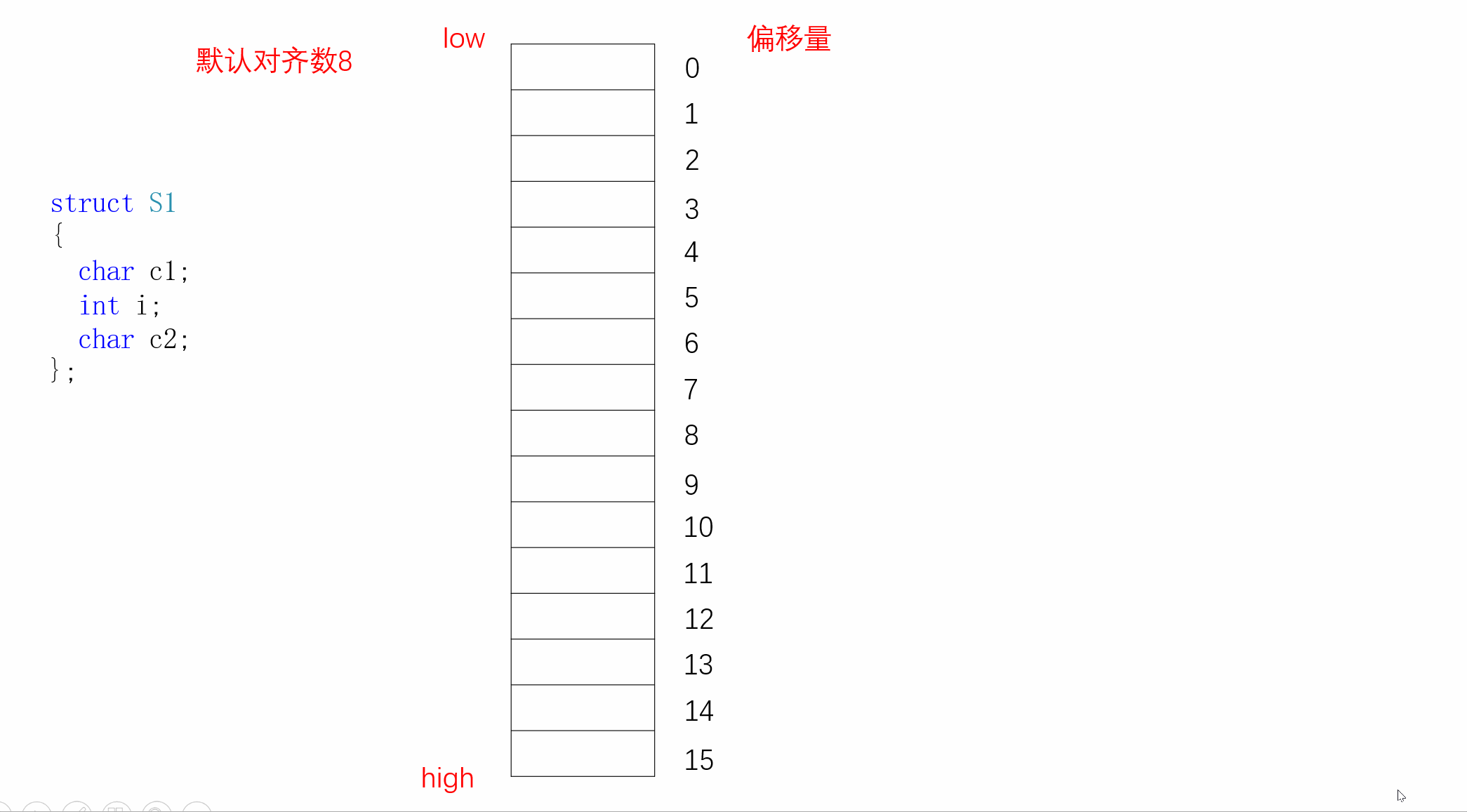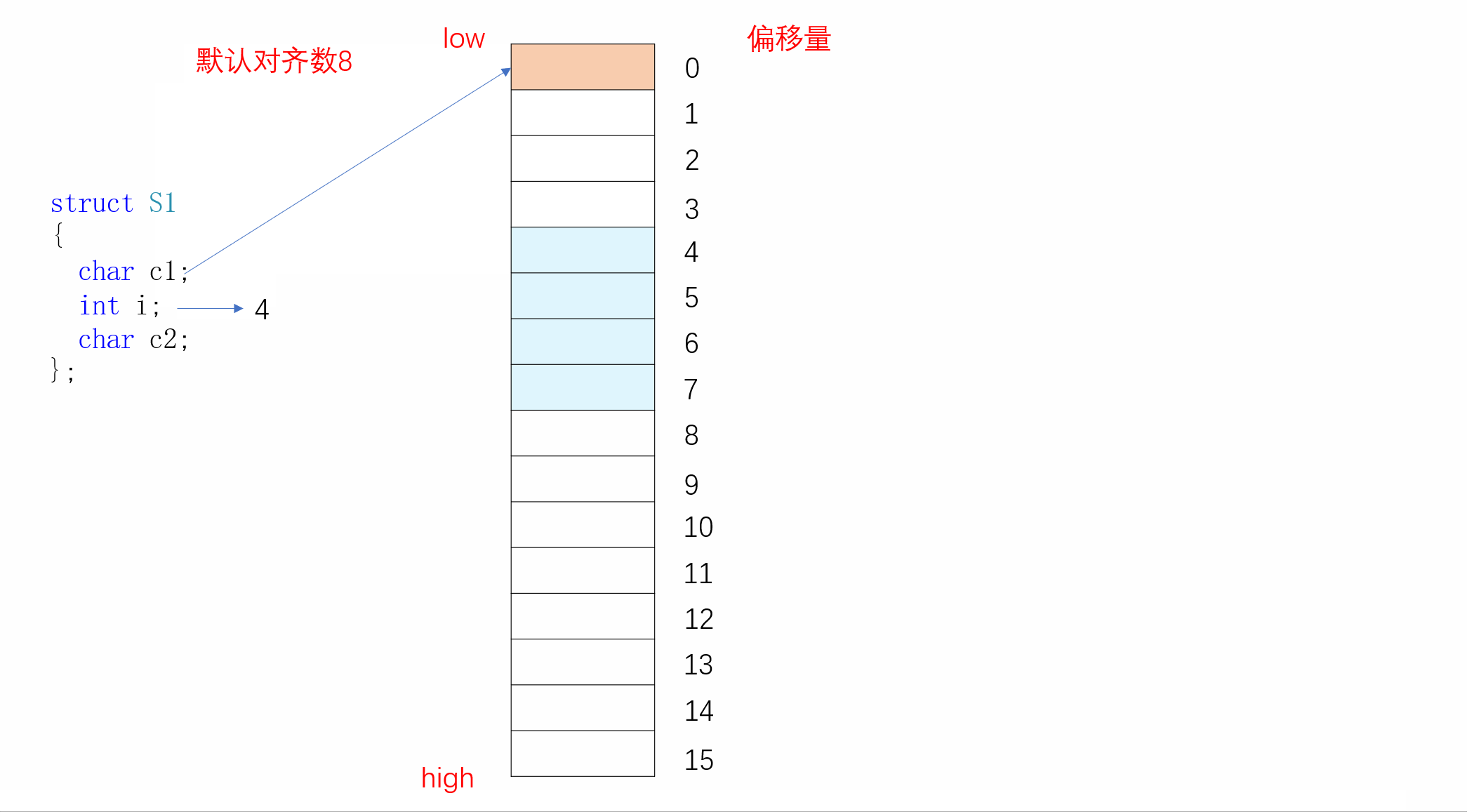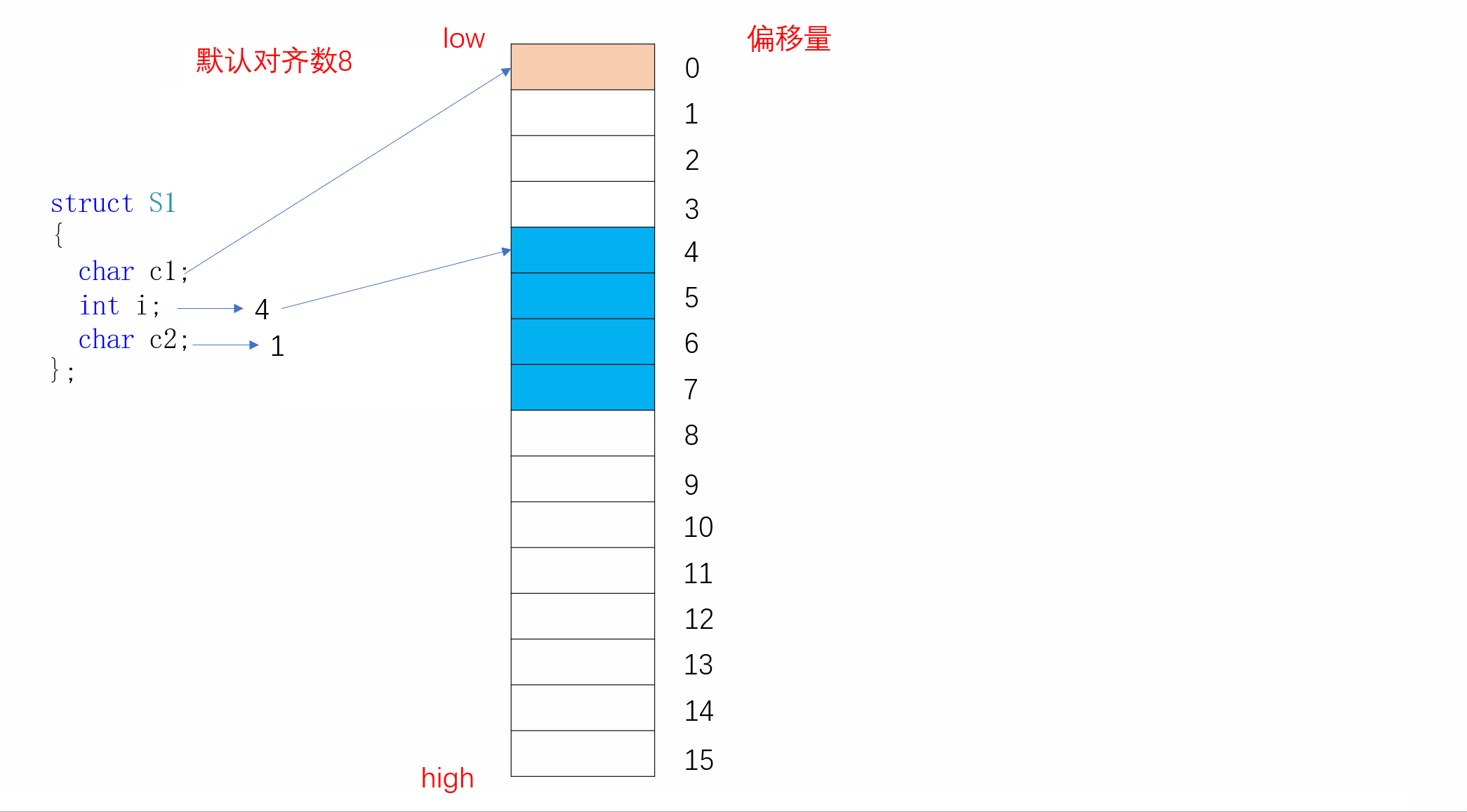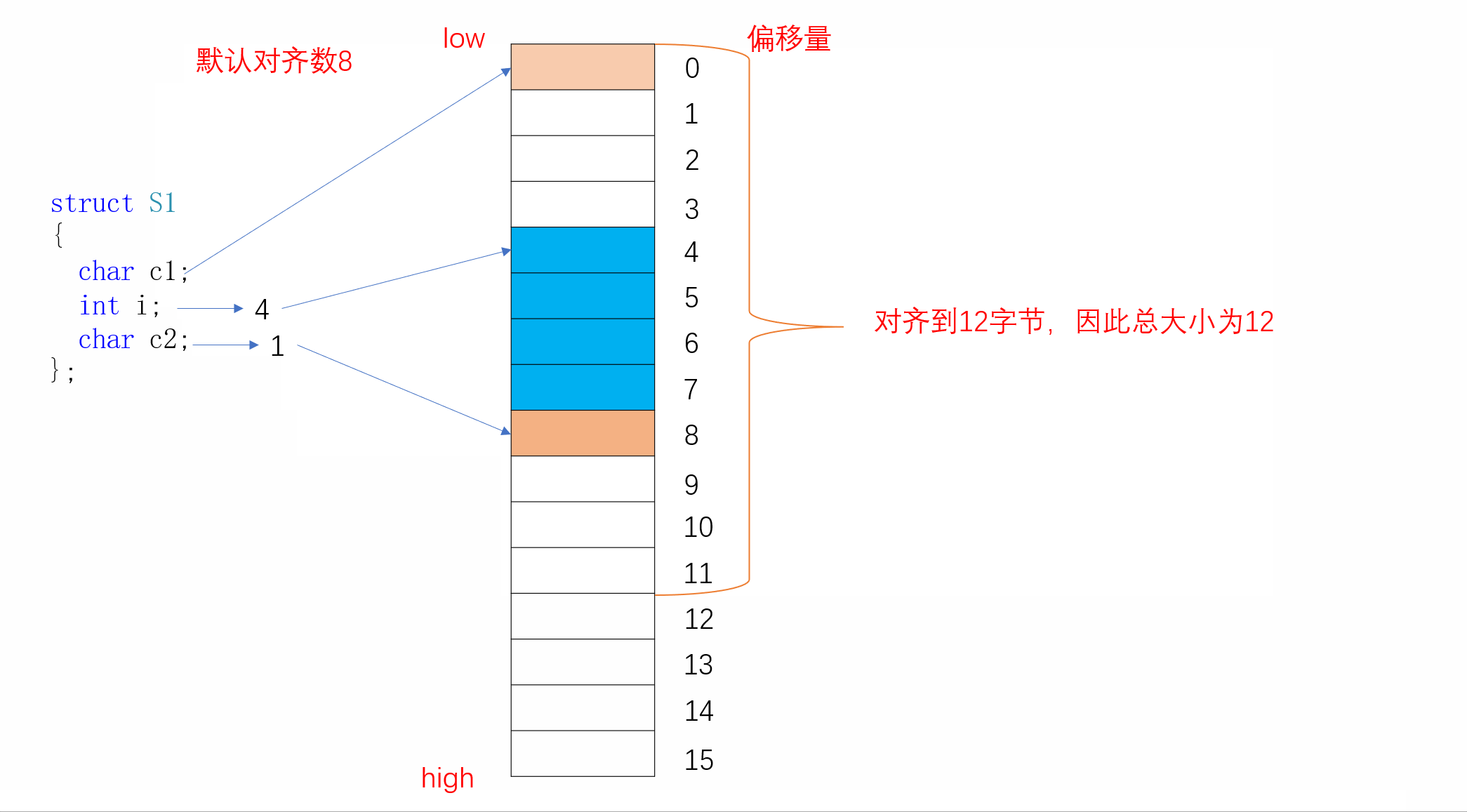
实际上S1在内存中的存储方式是这样子的:
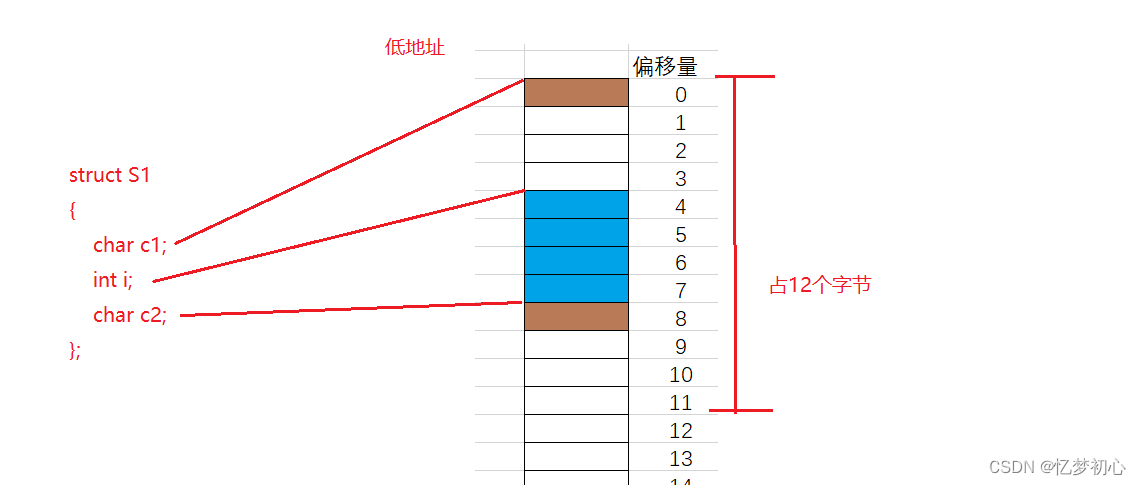
我们看到c1存放完后,i并不是紧挨着c1进行存放,而是从偏移量为4的地方开始存储,中间空出三个字节的空间。这就是结构体的内存对齐,下面我们来了解其内存对齐的规则:
结构体的第一个成员在与结构体变量偏移量为0的地址处
其他成员变量要对齐到某个数字(我们称作对齐数)的整数倍的地址处
对齐数=编译器默认的一个对齐数与该变量大小的较小值。vs的默认对齐数为8
结构体的总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
对于嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
我们可以模拟一下s1的内存对齐方式:
同样,S2的内存对齐方式如下:
如果你还是不确定,C语言给我们提供了offsetof宏来计算结构体成员的偏移量,原型如下:

需要注意:使用时我们需要先包含stddef.h头文件:
#include<stddef.h>
#include<stdio.h>
struct S1
{char c1;int i;char c2;
};
struct S2
{char c1;char c2;int i;
};
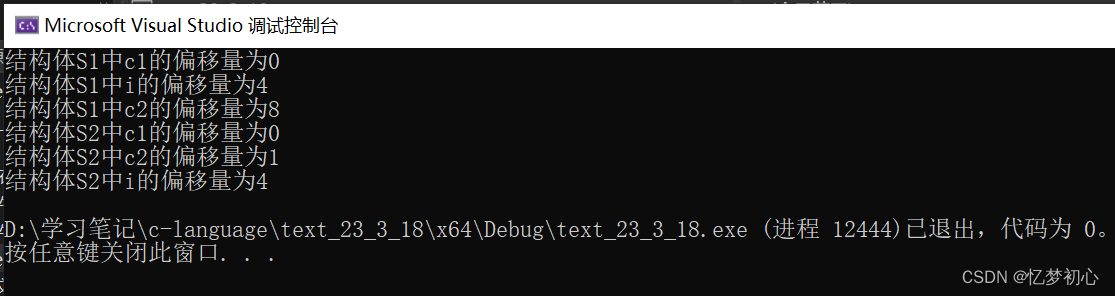
int main()
{printf("结构体S1中c1的偏移量为%zd\n",offsetof(struct S1,c1 ));printf("结构体S1中i的偏移量为%zd\n", offsetof(struct S1, i));printf("结构体S1中c2的偏移量为%zd\n", offsetof(struct S1, c2));printf("结构体S2中c1的偏移量为%zd\n", offsetof(struct S2, c1));printf("结构体S2中c2的偏移量为%zd\n", offsetof(struct S2, c2));printf("结构体S2中i的偏移量为%zd\n", offsetof(struct S2, i));return 0;
}结果如下,与我们上述的分析过程如出一辙:
我们再来看一个例子:
//结构体嵌套问题
struct S3
{double d;char c;int i;
};
struct S4
{char c1;struct S3 s3;double d;
};int main()
{printf("%d\n", sizeof(struct S4));return 0;
}
怎么样,你做对了吗👀
步骤如下:
根据内存对齐算出s3所占的空间大小为16
根据对齐规则的第5点得出s3的要对齐到8的整数倍,即对齐到偏移量为8处
double d的对齐数为8,因此对齐到偏移量为24处
最终大小为最大偏移量8的整数倍,即为32。
想必有人会有疑问,内存对齐那么麻烦,为什么存在内存对齐?主要有以下两点原因:
平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器可能需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总的来说:
结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足内存,又要节省空间,我们要如何做到:
让占用空间小的成员尽量集中在一起
//例如:
//c1与c2不相邻
struct S1
{char c1;int i;char c2;
};//c1与c2相邻
struct S2
{char c1;char c2;int i;
};虽然S1和S2类型的成员一模一样,但是S1占12个字节,S2占8个字节,这就是合理安排位置所带来的好处。
6.默认对齐数的修改🌷
在C语言中,我们也可以修改结构体的默认对齐数,只需用#pragma这个预处理指令即可。如下:
#include<stdio.h>
#pragma pack(1) //修改默认对齐数为1
struct S1
{char c1;int i;char c2;
};struct S2
{char c1;char c2;int i;
};
int main()
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}上面我们将默认对齐数设置成1,由于对齐数是默认对齐数和成员大小较小者,因此默认对齐数为1相当于不对齐,S1与S2的结果相同都为6:

7. 结构体的传参
话不多说,我们直接上代码来说明:
#include<stdio.h>
struct S
{int data[1000];int size;
};
//传值
void print(struct S s)
{printf("%d", s.size);
}
//传址
void print(struct S* sp)
{printf("%d", sp->size);
}
int main()
{struct S s1;print1(s1);print2(&s1);
}
print1()和print2()哪个函数好呢?
答案是print2()函数。
为什么呢?
print1()和print2()分别对应着传值调用和传址调用。我们知道无论是传值还是传址,函数在将要调用时实参都会形成临时拷贝并压入栈中。压栈的这个过程是需要成本的,成本体现在时间和空间上。
如果传递一个结构体对象的时候,结构体过大(例如我们上面的s1),参数压栈的的成本比较大,就会导致性能的下降。所以我们传递像结构体这种数据量较大的变量时,一般传地址,地址占4个或者8个字节,极大程度上减少了所需的成本。
综上所述,我们进行结构体传参时要传结构体的地址。
8.位段🌸
8.1 位段的特征与声明
讲完结构体后我们就必须再来讲讲结构体实现位段的能力,位段满足以下两点特征:
1.位段的成员必须是int、unsigned int或者char这些整型家族的成员
2.位段的成员名后有一个冒号和数字,数字表示成员占多少个二进制位(bit位)
3.位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
例如下面的A就是一个位段类型:
struct A
{char a : 1;char b : 4;char c : 5;char d : 5;
};其中a占1个二进制位,b占4个二进制位,c占5个二进制位,d占5个二进制位。那么位段A的大小是多少呢?这就要来谈谈位段的内存分配了。
8.2 位段的内存分配
事实上,C语言并没有明确规定位段的内存分配方式,也就是说:
1.我们并不知道位段中的成员在内存中是从左向右分配二进制位还是从右向左分配二进制位
2.我们不清楚当一个结构包含两个以上位段,第二个位段成员比较大,第一个位段剩余的二进制位无法容纳第二个位段,是舍弃剩余的位还是将其利用,这是不确定的。
正因如此,位段在不同的编译环境下所展现出来的效果很可能会有所不同。我们可以探究一下A当其从右向左分配并且不足时舍去剩余位时的内存分配情况,如下(VS2022环境下):
struct A
{char a : 1;char b : 4;char c : 5;char d : 5;
}s={0};
int main()
{s.a = 11;s.b = 12;s.c = 3;s.d = 4;printf("%d", sizeof(s));//计算s所占大小return 0;
}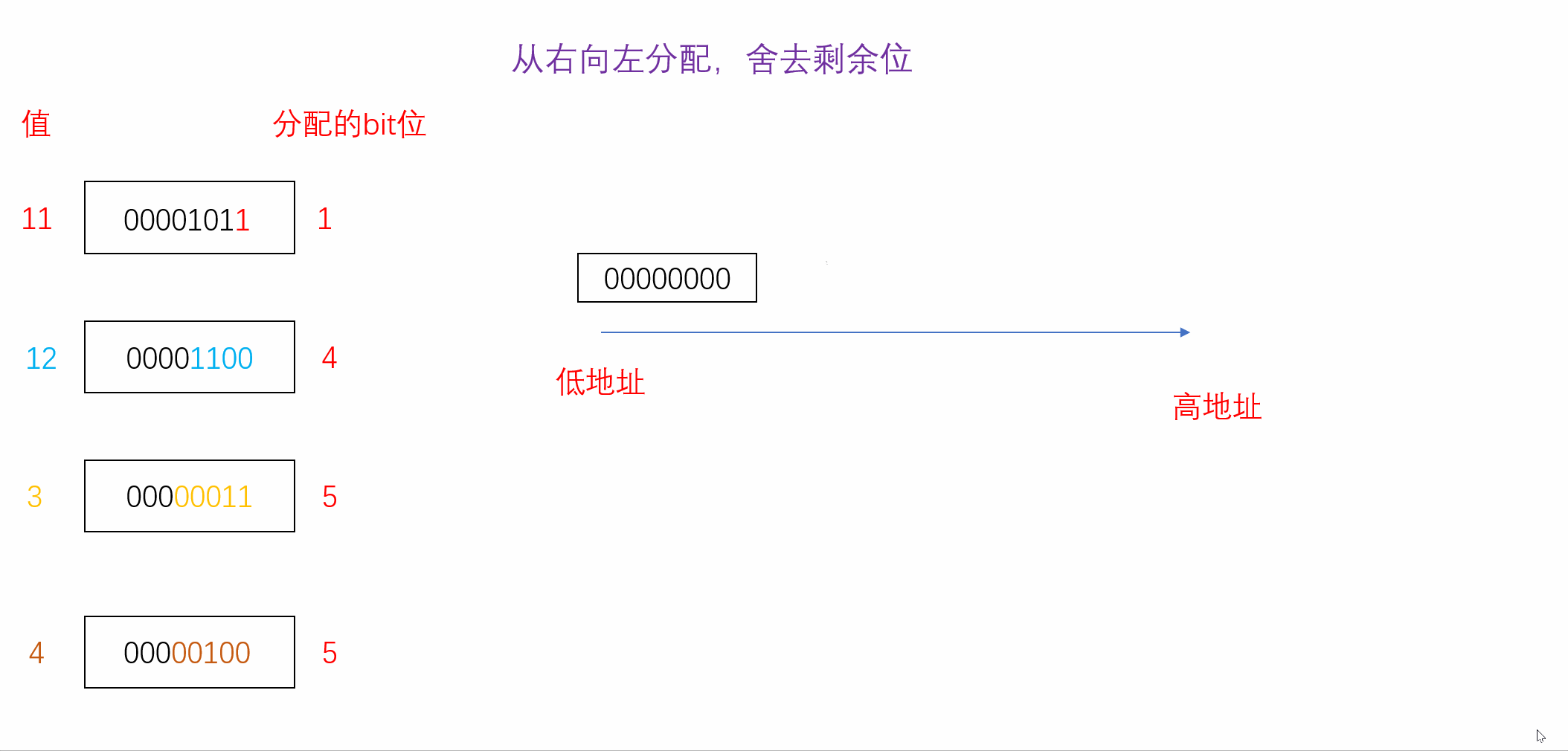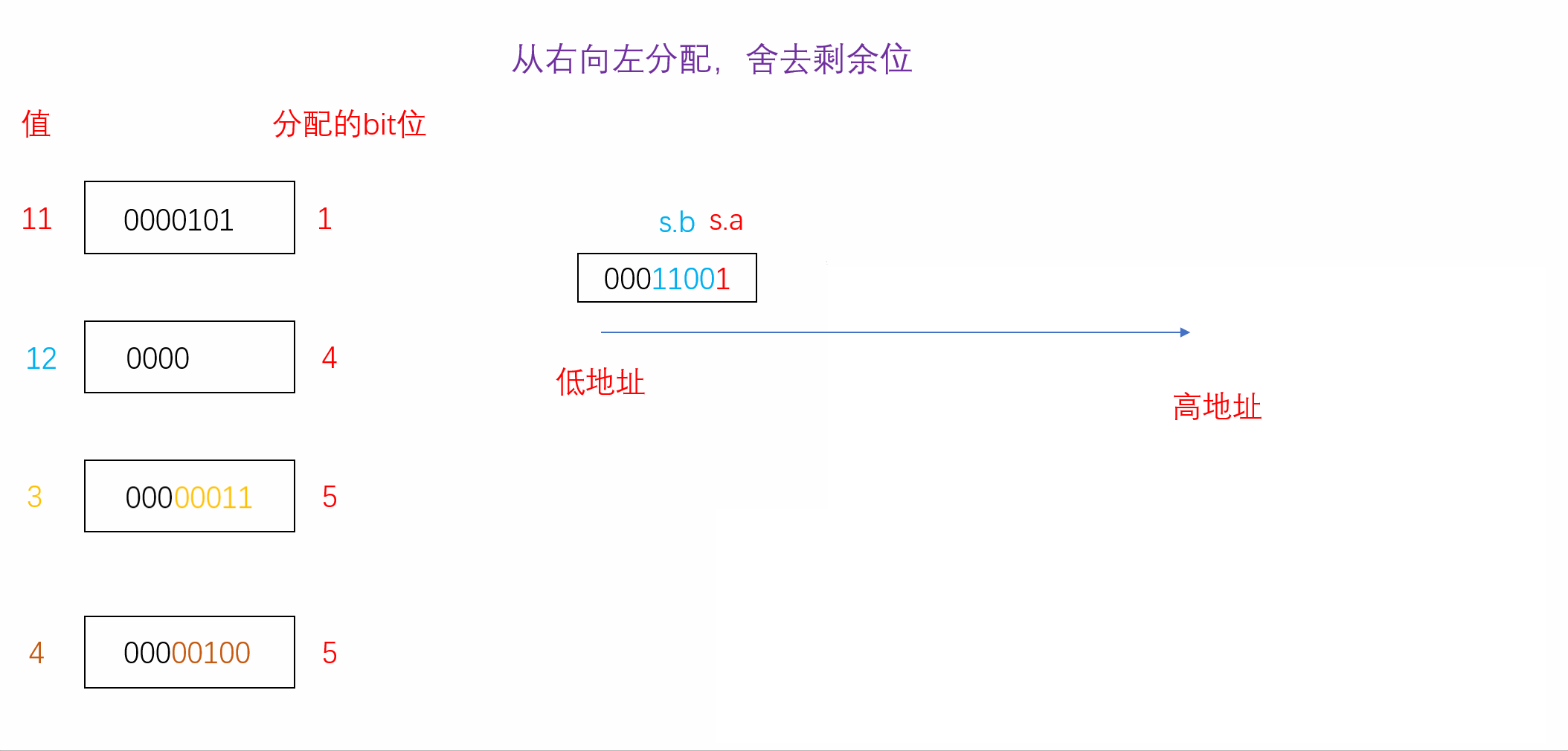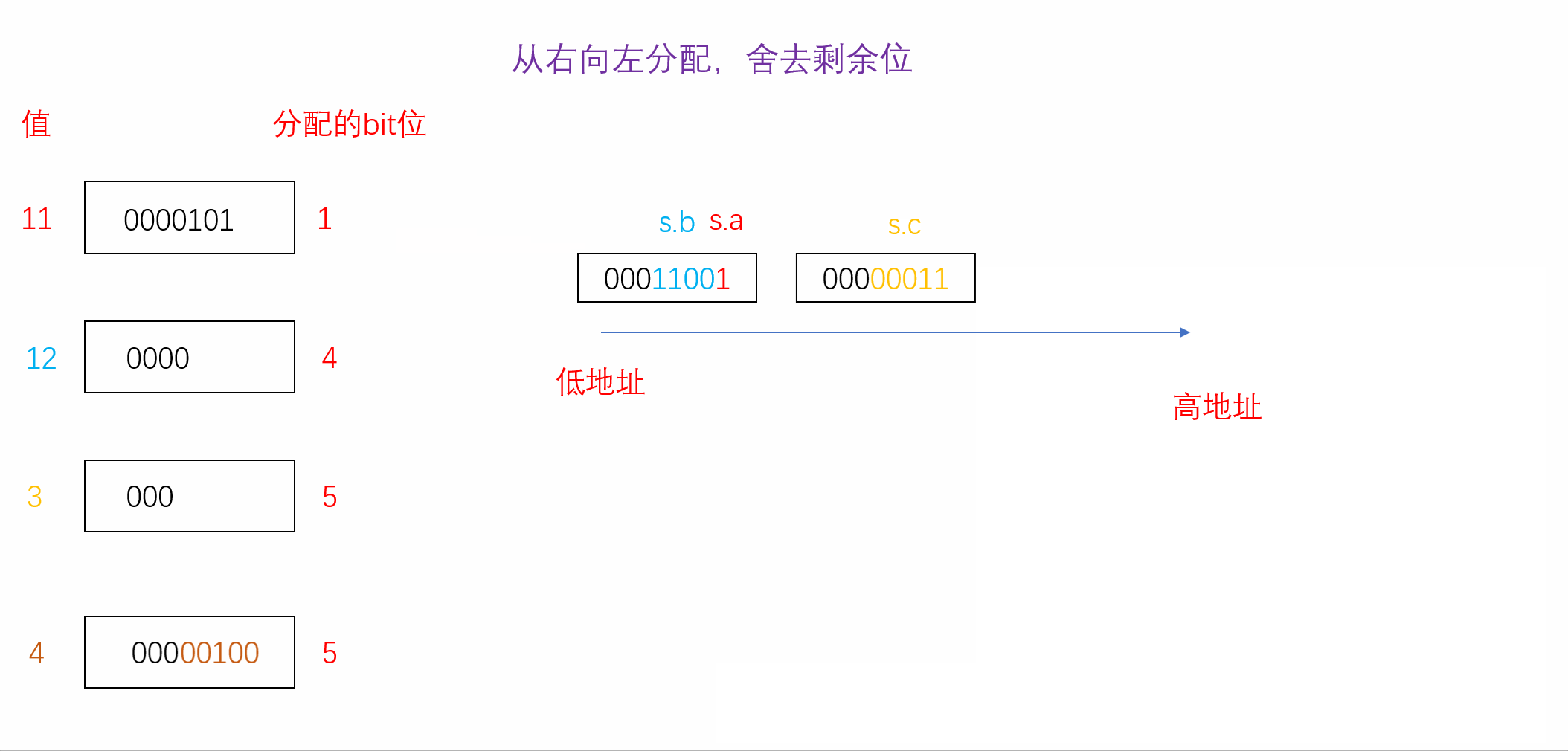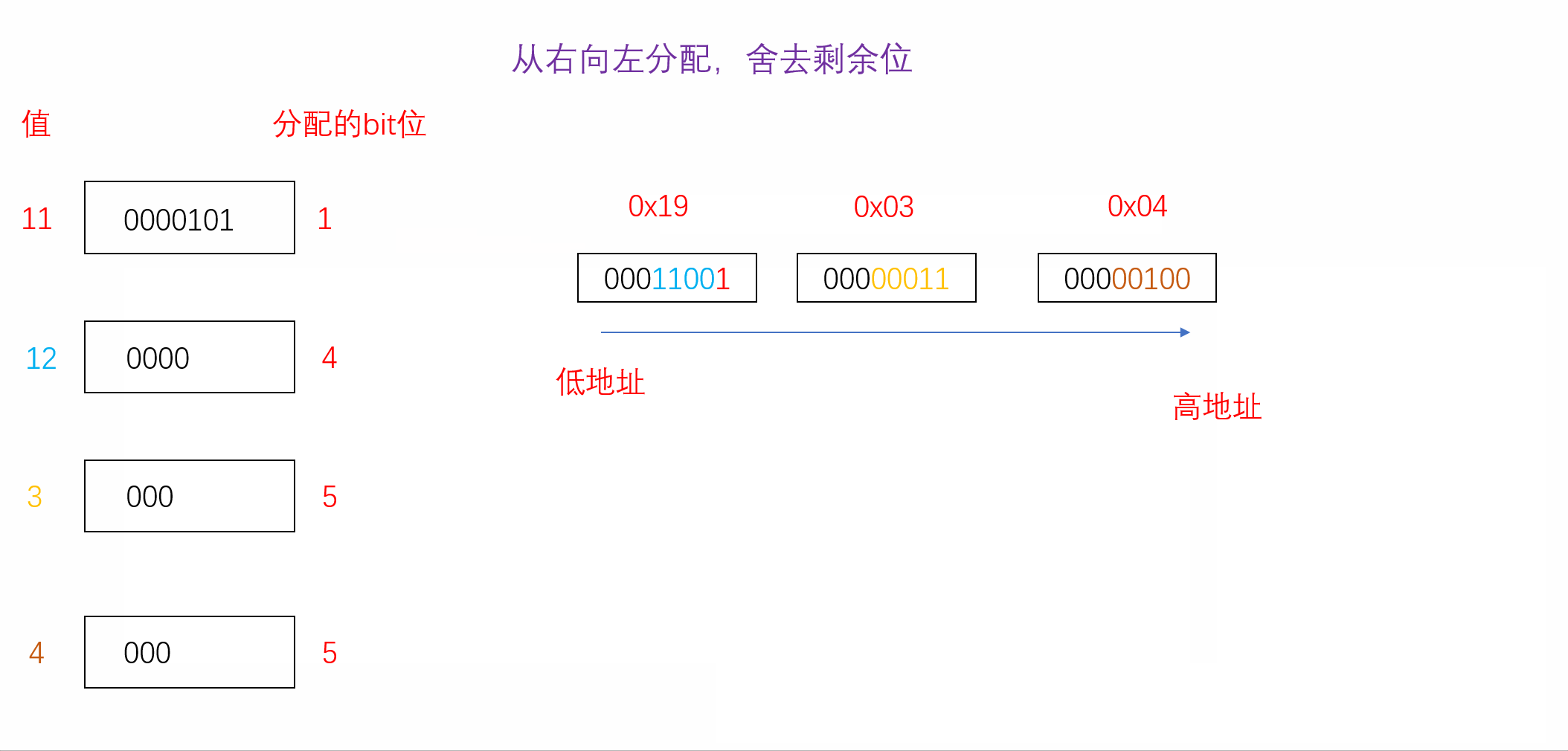
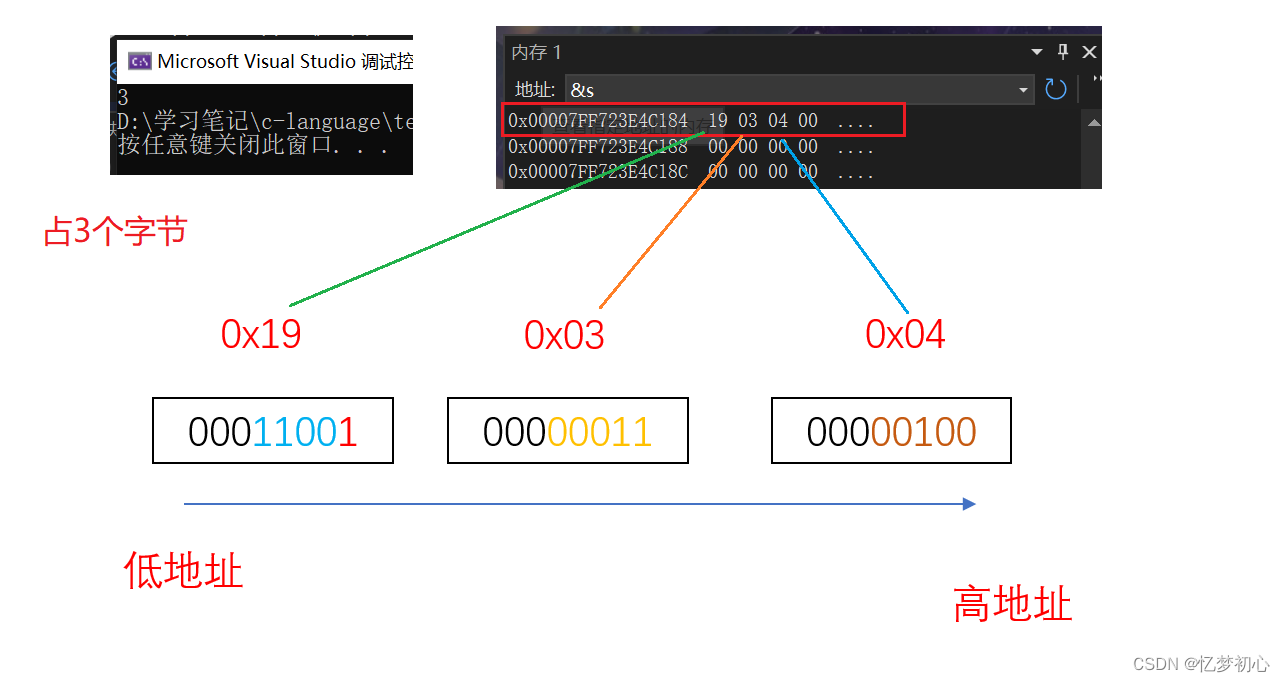
我们发现按照我们的假设计算出来的结果与vs2022监视器中内存的分配结果一模一样,因此我们可以得知在vs2022编译器下位段是从右向左分配且不足时舍弃剩余位。
8.3 位段的跨平台问题
由于以下问题的存在,位段的可移植性很差,即存在着跨平台问题:
1. int 位段被当成有符号数还是无符号数是不确定的。
2. 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机 器会出问题。
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
8.4 位段的应用
位段在网络中的应用比较多,例如以下ip数据包格式:

当我们在网络上给某人发送一个消息时,这个消息就会封装成如上图所示的一个数据包用于在网络上精确地找到接收人。我们可以看出每一行都恰好的被设计成了int型宽度,每个部分我们使用位段来进行排列封装,使得空间最大利用。而如果我们使用结构体来进行封装每个部分,由于内存对齐的原因,势必会额外浪费空间造成数据包变得巨大,从而使网络状态变差。
总的来说,跟结构体相比,位段也可以达到一样的效果,其可以帮助我们节省空间,但是也带来了跨平台性的问题。
以上,就是本期的全部内容啦🌸
制作不易,能否点个赞再走呢🙏
相关文章:
【C语言】你真的了解结构体吗
引言✨我们知道C语言中存在着整形(int、short...),字符型(char),浮点型(float、double)等等内置类型,但是有时候,这些内置类型并不能解决我们的需求,因为我们无法用这些单一的内置类型来描述一些复杂的对象,…...

血氧仪是如何得出血氧饱和度值的?
目录 一、血氧饱和度概念 二、血氧饱和度监测意义 三、血氧饱和度的监测方式 四、容积脉搏波计算血氧饱和度原理 五、容积脉搏波波形的测量电路方案 1)光源和光电探测器的集成测量模块:SFH7050—反射式 2)模拟前端 六、市面上血氧仪类型…...
接口和抽象类)
Java全栈知识(3)接口和抽象类
1、抽象类 抽象类就是由abstract修饰的类,其中没有只声明没有实现的方法就是抽象方法,抽象类中可以有0个或者多个抽象方法。 1.1、抽象类的语法 抽象类不能被final修饰 因为抽象类是一种类似于工程中未完成的中间件。需要有子类进行继承完善其功能,所…...
)
JavaScript == === Object.is()
文章目录JavaScript & & Object.is() 相等运算符 全等运算符Object.is() 值比较JavaScript & & Object.is() 相等运算符 相等运算符,会先进行类型转换,将2个操作数转为相同的类型,再比较2个值。 console.log("10&…...
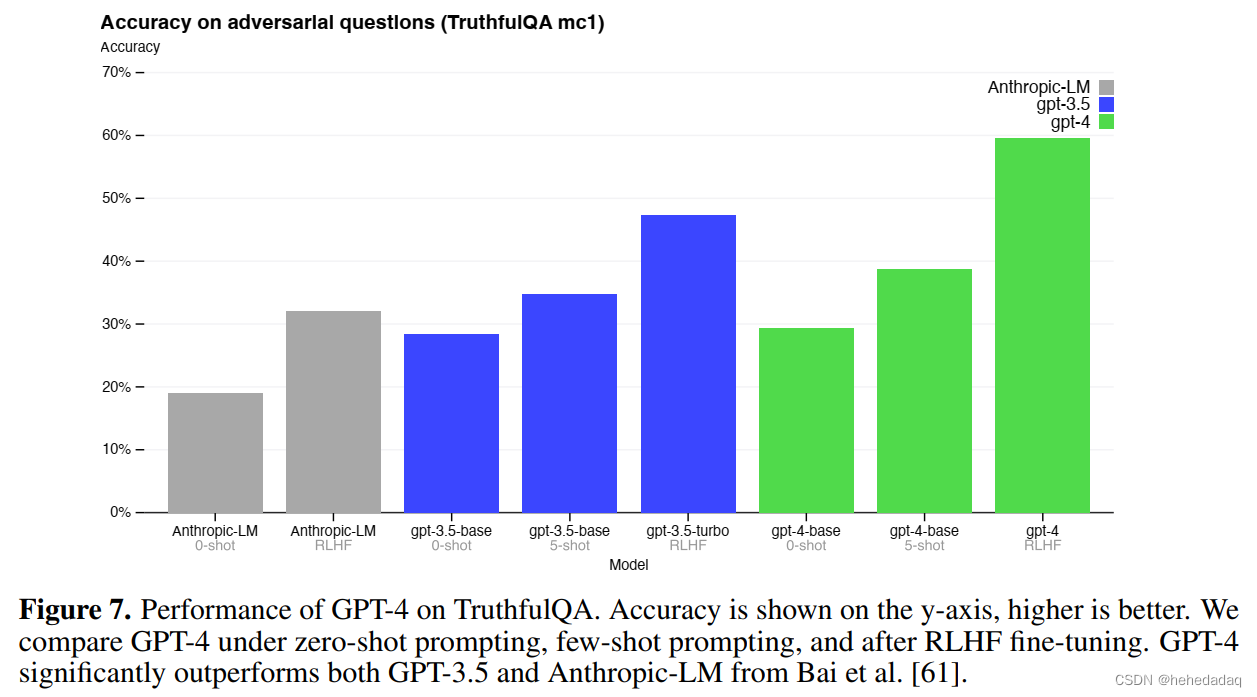
GPT4论文翻译 by GPT4 and Human
GPT-4技术报告解读 文章目录GPT-4技术报告解读前言:摘要1 引言2 技术报告的范围和局限性3 可预测的扩展性3.1 损失预测3.2 人类评估能力的扩展4 能力评估4.1 视觉输入 !!!5 限制6 风险与缓解:7 结论前言: 这篇报告内容太多了!&am…...
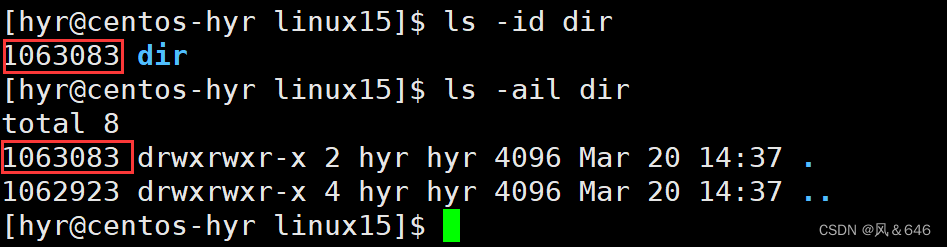
inode和软硬链接
文章目录:一、理解文件系统1.1 什么是inode1.2 磁盘了解1.2.1磁盘的硬件结构1.2.2 磁盘的分区1.2.3 EXT2文件系统二、软硬链接2.1 软链接2.2 硬链接一、理解文件系统 1.1 什么是inode inodes 是文件系统中存储文件元数据的数据结构。每个文件或目录都有一个唯一的 …...

简单分析Linux内核基础篇——initcall
写过Linux驱动的人都知道module_init宏,因为它声明了一个驱动的入口函数。 除了module_init宏,你会发现在Linux内核中有许多的驱动并没有使用module_init宏来声明入口函数,而是看到了许多诸如以下的声明: static int __init qco…...
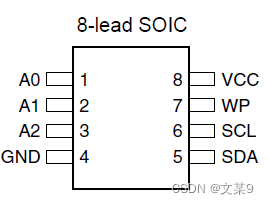
硬件速攻-AT24CXX存储器
AT24C02是什么? AT24CXX是存储芯片,驱动方式为IIC协议 实物图? 引脚介绍? A0 地址设置角 可连接高电平或低电平 A1 地址设置角 可连接高电平或低电平 A2 地址设置角 可连接高电平或低电平 1010是设备前四位固定地址 …...

C# tuple元组详解
概念 本质就是个数据结构,它是将多个数据元素分组成一个轻型数据结构。 如何声明元组变量(针对.net framework 4.7 和 .net core 2.0) 不带字段名称元组 ## t1就是个变量 它的类型是元组类型 ## 左侧括号定义的是参数列表 等于号右侧就是个t1赋值 #…...
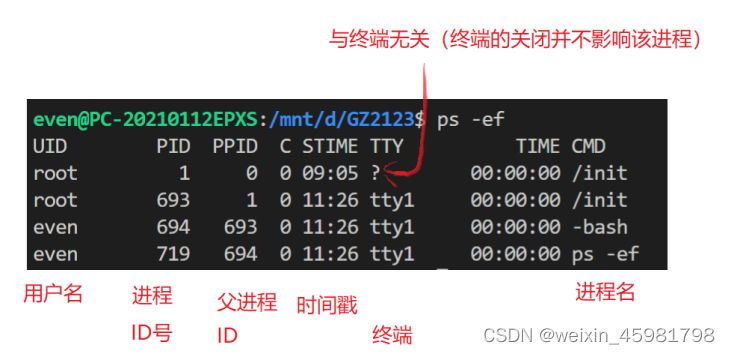
1、Linux初级——linux命令
下载镜像:http://cn.ubuntu.com/dowload 一、基本命令 1、alias(给命令取别名) 例如:alias clls -la(只是临时的) 2、配置文件$ vim ~/.bashrc $ vim ~/.bashrc // 使用vim打开配置文件 (1)在配置文件…...
ChatGPT助力校招----面试问题分享(四)
1 ChatGPT每日一题:电阻如何选型 问题:电阻如何选型 ChatGPT:电阻的选型通常需要考虑以下几个方面: 额定功率:电阻的额定功率是指电阻能够承受的最大功率。在选型时,需要根据电路中所需要的功率确定所选…...
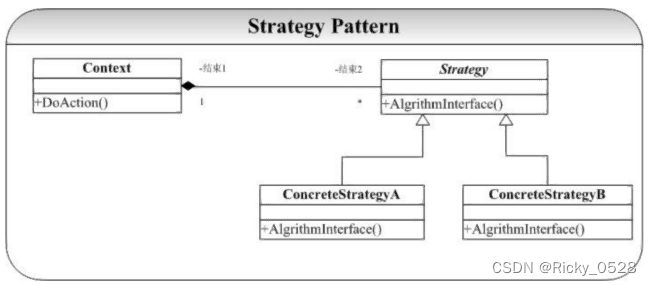
【设计模式】创建型设计模式
文章目录1. 基础①如何学习设计模式② 类模型③ 类关系2. 设计原则3. 模板方法① 定义②背景③ 要点④ 本质⑤ 结构图⑥ 样例代码4. 观察者模式① 定义②背景③ 要点④ 本质⑤ 结构图⑥ 样例代码5. 策略模式① 定义②背景③ 要点④ 本质⑤ 结构图⑥ 样例代码1. 基础 ①如何学习…...

Linux 信号(signal):信号的理解
目录一、理解信号1.信号是什么2.信号的种类二、简单理解信号的生命周期一、理解信号 1.信号是什么 Linux中的信号其实和日常生活中的信号还是挺像的,LInux中的信号是一种事件通知机制,通知进程发生了某个事件。进程接收到信号后,就会中断当前…...
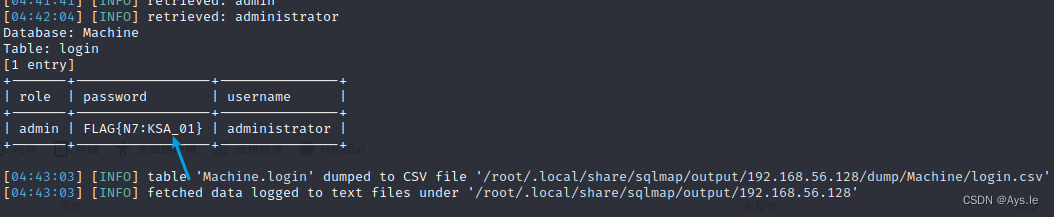
Vulnhub项目:Web Machine(N7)
靶机地址:Web Machine(N7)渗透过程:kali ip:192.168.56.104,靶机ip,使用arp-scan进行查看靶机地址:192.168.56.128收集靶机开放端口:nmap -sS -sV -T5 -A 192.168.56.128开放了80端口࿰…...
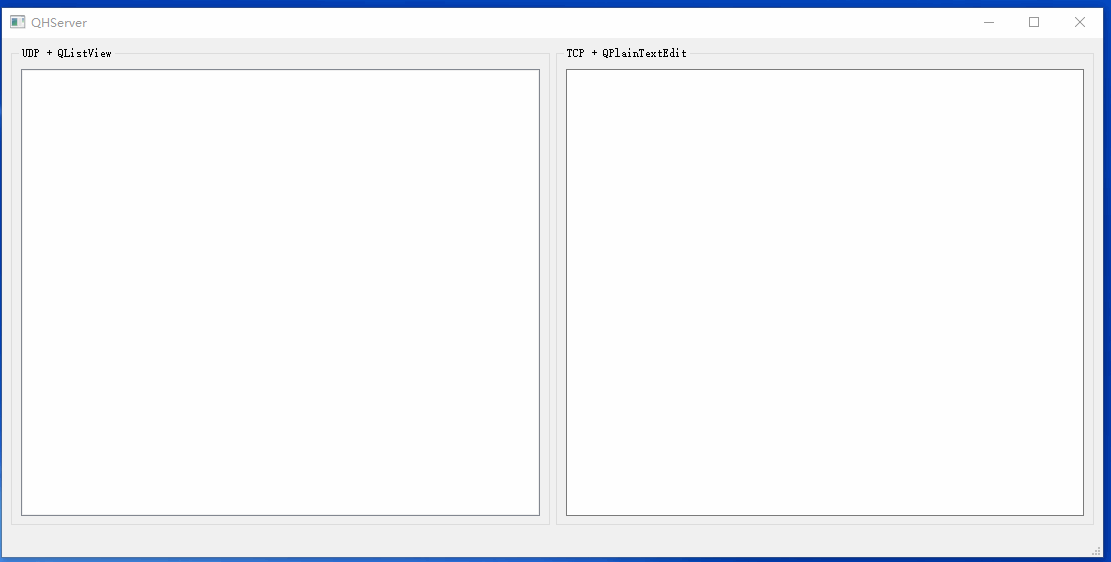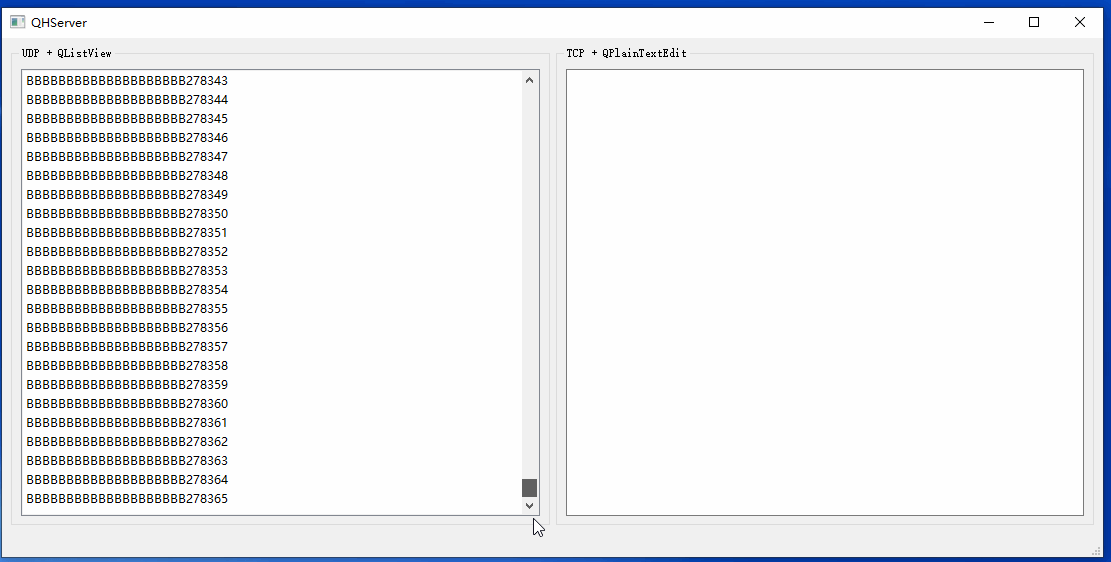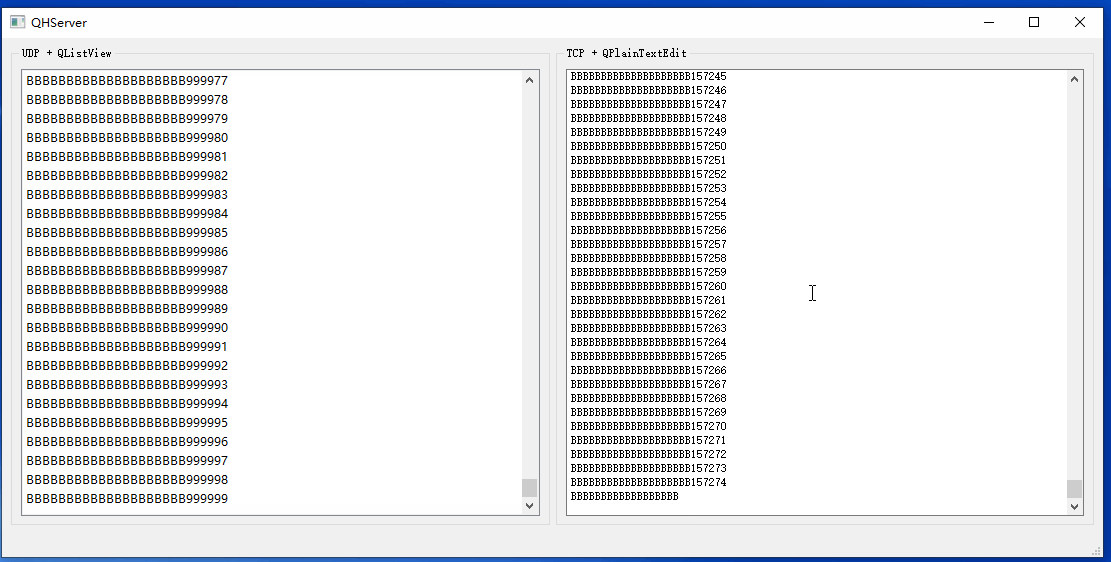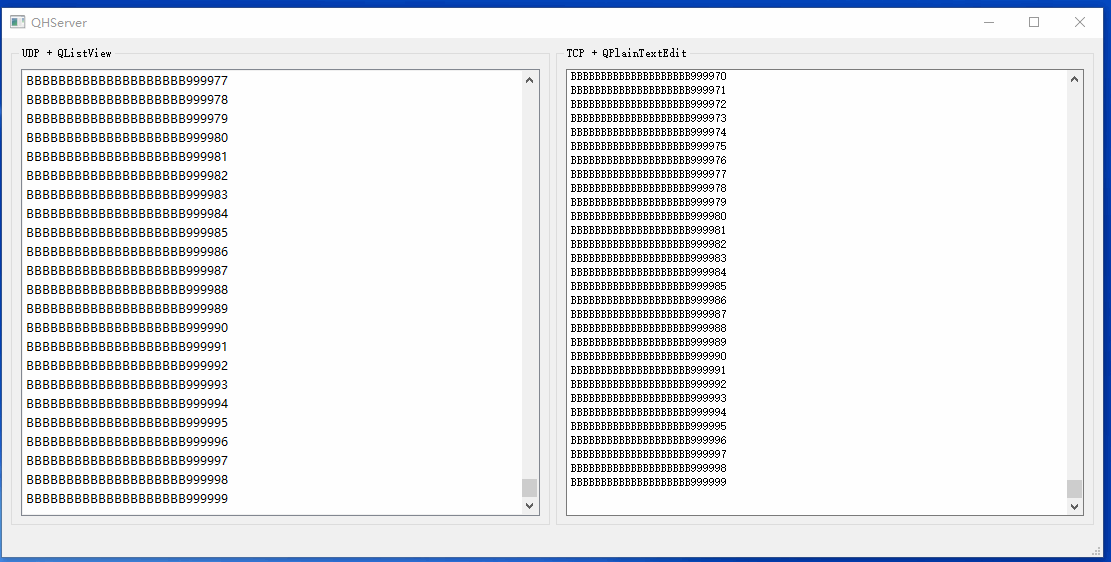
Qt基础之三十三:海量网络数据实时显示
开发中我们可能会遇到接收的网络数据来不及显示的问题。最基础的做法是限制UI中加载的数据行数,这样一来可以防止内存一直涨,二来数据刷新非常快,加载再多也来不及看。此时UI能看到数据当前处理到什么阶段就行,实时性更加重要,要做数据分析的话还得查看日志文件。 这里给出…...

linux console快捷键
Ctrl C:终止当前正在运行的程序。Ctrl D:关闭当前终端会话。Ctrl Z:将当前程序放入后台运行。Ctrl L:清除当前屏幕并重新显示命令提示符。Ctrl R:在历史命令中进行逆向搜索。Ctrl A:将光标移动到行首…...
)
弗洛伊德龟兔赛跑算法(弗洛伊德判圈算法)
弗洛伊德( 罗伯特・弗洛伊德)判圈算法(Floyd Cycle Detection Algorithm),又称龟兔赛跑算法(Tortoise and Hare Algorithm),是一个可以在有限状态机、迭代函数或者链表上判断是否存在环,以及判断环的起点与长度的算法。昨晚刷到一个视频&…...
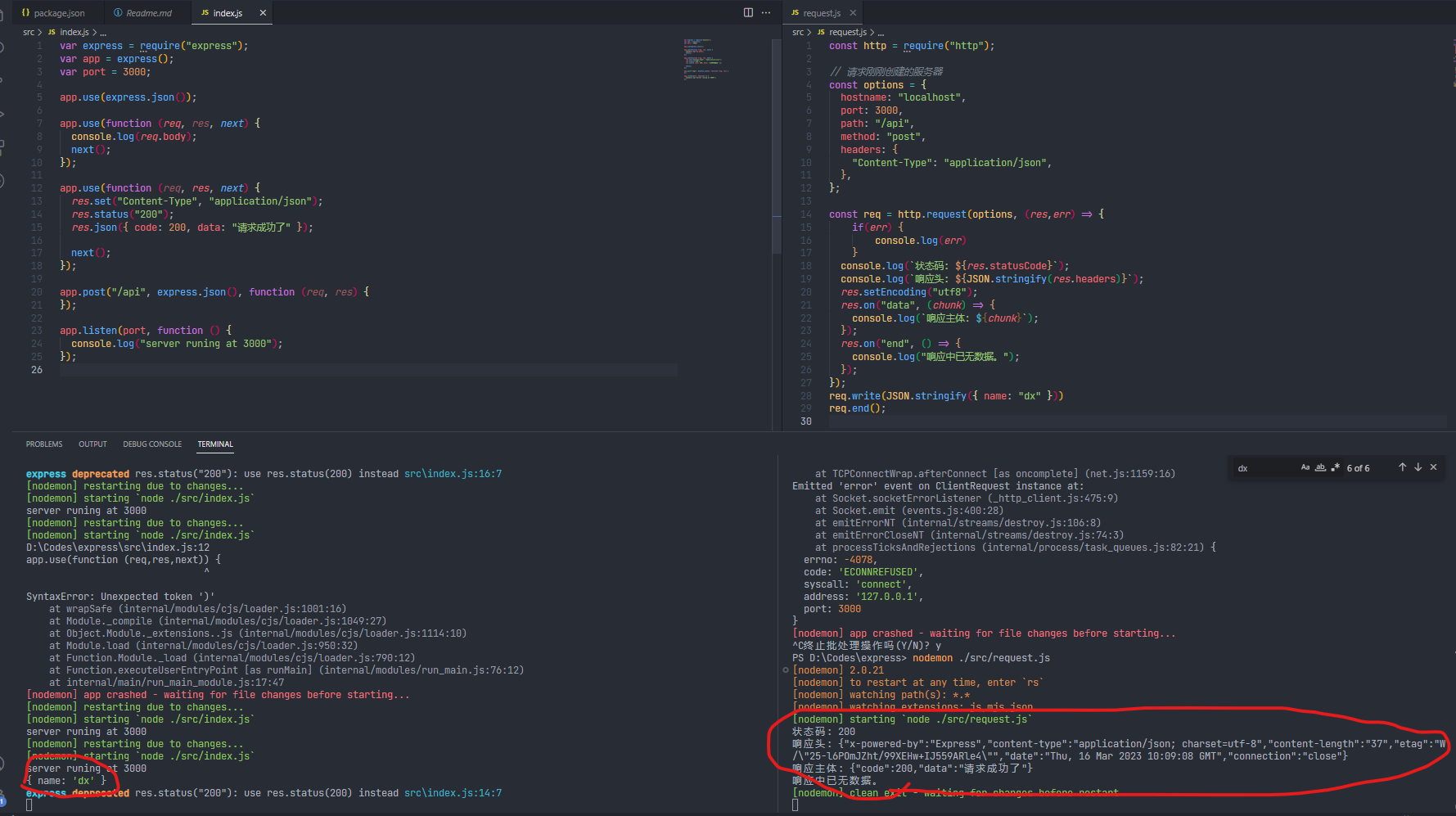
nodejs篇 express(1)
文章目录前言express介绍安装RESTful接口规范express的简单使用一个最简单的服务器,仅仅只需要几行代码便可以实现。restful规范的五种接口类型请求信息req的获取响应信息res的设置中间件的使用自定义中间件解决跨域nodejs相关其它内容前言 express作为nodejs必学的…...

Java实习生------Redis常见面试题汇总(AOF持久化、RDB快照、分布式锁、缓存一致性)⭐⭐⭐
“年轻人,就要勇敢追梦”🌹 参考资料:图解redis 目录 谈谈你对AOF持久化的理解? redis的三种写回策略是什么? 谈谈你对AOF重写机制的理解?AOF重写机制的具体过程? 谈谈你对RDB快照的理解&a…...
seata服务搭建
它支持两种存储模式,一个是文件,一个是数据库,下面我们分别介绍一下这两种配置nacos存储配置,注意如果registry.conf中注册和配置使用的是file,就会去读取file.config的配置,如果是nacos则通过nacos动态读取…...

Qwen2.5-14B-Instruct在AI编剧赛道的突破:像素剧本圣殿Glitch标题交互体验分享
Qwen2.5-14B-Instruct在AI编剧赛道的突破:像素剧本圣殿Glitch标题交互体验分享 1. 像素剧本圣殿:AI编剧的新范式 在数字内容创作领域,剧本创作一直是最具挑战性的任务之一。传统编剧需要花费大量时间构思情节、塑造角色、打磨对白ÿ…...

Go Module 依赖冲突调试方法
Go Module 依赖冲突调试方法 在Go语言开发中,依赖管理是一个关键环节。随着项目规模的扩大,依赖的第三方库越来越多,版本冲突问题也愈发常见。Go Module作为官方推荐的依赖管理工具,虽然简化了依赖管理流程,但在多级依…...
)
Cocos Creator实战:5步搞定棋牌游戏大厅场景开发(附完整代码)
Cocos Creator实战:5步构建高交互棋牌游戏大厅(附模块化代码) 棋牌游戏大厅作为玩家进入游戏的第一印象,其体验直接决定了用户留存率。根据行业数据,精心设计的大厅界面能提升30%以上的玩家次日留存。不同于传统游戏开…...

s2-pro语音合成新玩法:用标签控制语气,轻松制作带情绪的语音内容
s2-pro语音合成新玩法:用标签控制语气,轻松制作带情绪的语音内容 1. 语音合成技术的新突破 在数字内容创作领域,语音合成技术正变得越来越重要。传统的语音合成系统往往只能生成单调、机械的语音,缺乏情感表达和自然韵律。而s2-…...

MongoDB高级面试:进阶面试题50题及答案详解
更多内容请见: 《深入掌握MongoDB数据库》 - 专栏介绍和目录 文章目录 一、高级查询优化与执行计划 (8题) 二、高级索引策略 (8题) 三、高级分片策略与优化 (8题) 四、性能调优与瓶颈分析 (7题) 五、高级复制集配置与故障处理 (6题) 六、高级事务与一致性模型 (5题) 七、安全高…...

一篇帮你搞定Arrays工具类!!!
一、引言最近在刷算法题的时候,用到了很多次Arrays的方法,因此,写一篇博客来整理一下相关用法二、介绍java.util.Arrays 是 Java 提供的数组操作工具类,包含了数组排序、查找、复制、比较、打印、填充等常用静态方法,无…...
】人工智能 · 参考答案与解析(按分类))
【系统架构设计师-案例题(5)】人工智能 · 参考答案与解析(按分类)
文章目录目录一、机器学习基本概念单选 迁移学习单选 强化学习的核心特点二、人工智能分类(弱人工智能与强人工智能)单选 主要区别三、人工智能关键技术单选 说法错误项(选非)单选 哪项不是人工智能关键技术(选非…...

SDMatte与LSTM结合研究:时序视频抠图的初步探索
SDMatte与LSTM结合研究:时序视频抠图的初步探索 1. 引言:视频抠图的新挑战 视频抠图技术一直是影视后期和内容创作领域的重要工具。传统的静态图像抠图方法在处理视频时常常面临一个棘手问题:帧与帧之间的结果不一致,导致最终视…...

从数学直觉到代码实践:Harris角点检测的算法拆解与性能调优
1. 角点检测:计算机视觉的基石 想象一下你正在玩一个拼图游戏。当两块拼图能够严丝合缝地拼接在一起时,往往是因为它们在某些关键位置完美匹配——这些位置通常是拼图块的拐角处。计算机视觉中的角点检测,本质上就是在做类似的事情࿱…...
)
Simulink SVPWM模块输出对不上?别慌,可能是这两个参数没设对(附24V电机FOC仿真案例)
Simulink SVPWM模块输出差异排查指南:从参数配置到波形修正 引言 在电机控制系统的仿真与开发过程中,Simulink的SVPWM模块是工程师们常用的工具之一。然而,许多开发者在对比自带模块与自建模型输出时,经常会遇到令人困惑的波形不一…...