实时数仓分层架构详解
数据仓库的概念可以追溯到20世纪80年代,当时IBM的研究人员提出了商业数据仓库的概念。数据仓库概念的提出,是为了解决和数据流相关的各种问题,特别是多重数据复制带来的高成本问题。
数据仓库之父Bill Inmon在1991年出版的Building the Datla Warehouse一书中首次提出了数据仓库的概念。Inmon将数据仓库描述为一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。这个定义一直延续至今,Bill Inmon也被称为数据仓库之父。

大约在2000年前后数据仓库开始进入中国,最开始主要集中在银行业和电信业。银行业建设数据仓库的动力来自于监管要求和1104监管报送系统,电信业的动力主要是推动省市级子公司汇总数据到总公司,构建统一的财务分析报表。两个行业的应用,为数据仓库概念在中国的普及奠定了基础。
在2010年以后,随着大数据技术的发展扩展到其它行业。互联网、零售、制造、医疗行业等各行各业都在推广数据仓库。
然后是数据仓库技术的发展。
在2010年前后,数据仓库系统主要由数据库、ETL平台、BI工具三个商业套件组成。常见的数据库主要是Oracle、DB2、Teradata,对应的ETL平台分别是IBM DataStage、Informatica PowerCenter、Microsoft SQL Server Integration Services (SSIS),主流的商业BI平台主要是BIEE、Cognos、BO。对于以上这些名词可能今天的听众都很陌生,但是在2010年前后,这些就是数据仓库的代名词。
与此同时,随着移动互联网的兴起,以BAT为代表的互联网企业高喊着“去IOE”(去ioe是指在阿里巴巴的IT架构中,去掉IBM的小型机、Oracle数据库、EMC存储设备,代之以自己在开源软件基础上开发的系统。早在20世纪90年代,中国国内就逐渐形成了Oracle垄断电信行业,IBM垄断金融行业的格局。)口号,推动数据仓库从商业时代走向了开源时代,也从单体架构走向分布式架构。这里面最具代表性的就是阿里巴巴和腾讯公司分别2009年引入Hadoop集群,并且持续迭代升级并一直使用至今。互联网公司引入Hadoop体系的原因也很简单,因为传统的商业数据库已经无法满足互联网企业的数据存储计算需求了。传统的商业数据库扩展能力有限,硬件价格高昂,并发执行能力不足,Hadoop则刚好可以解决这些痛点,加上HiveQL可以满足大部分数据开发的需求,因此Hive数仓逐步替代了商业数据库。但是前期Hadoop、Hive、sqoop等开源软件并不成熟,需要投入大量的技术研发来完善这些软件,修复其中的bug,优化某些模块的性能或者功能,这个过程也比较缓慢,所以前期大家对Hadoop和Hive的感受都是很难用、不稳定,在2016年底,互联网公司开始引入Kafka。

后面的故事大家基本上都知道了,2016年前后,随着Hive2.3和Hive3.0版本的发布,Hadoop体系逐渐走向成熟稳定,Hortonworks和Cloudera公司分别为Hadoop生态贡献了Tez引擎、Ambari管理平台和Impala引擎,与此同时,内存计算引擎Spark强势崛起,为Hive提高了新的强大动力;Hive母公司Facebook又进一步开源了MPP框架的查询引擎Presto,大幅提升了Hive数仓的查询能力。
站在当前时间点,我们谈论的Hive数仓,一般默认包括HDFS存储系统、Yarn资源管理平台、Hive元数据管理、Spark计算引擎、Presto查询引擎,这些构成了离线数仓的技术栈。
这里简单介绍一下各个技术栈的功能和作用:
1.Apache Hadoop:Apache Hadoop是一个开源的分布式计算框架,提供了可扩展的存储和处理大规模数据的能力。它的核心组件包括Hadoop Distributed File System (HDFS)、MapReduce和Yarn资源管理组件,主要用于离线数仓数据存储和资源调度。
2. Apache Hive:Apache Hive是基于Hadoop的数据仓库基础架构,提供了类似SQL的查询语言(HiveQL),使用户可以通过SQL风格的语法进行数据查询和分析。它支持将结构化数据映射到Hadoop集群上的HDFS,并利用MapReduce、Spark、Tez等计算引擎进行查询和数据加工。
3.Sqoop:一个短命而重要的Hadoop组件,用于从关系型数据库抽取数据到Hive数仓中或者从Hive数仓中导出数据到关系型数据库。sqoop是一个非常重要的组件,但是不知道出于什么原因,很早就停止了更新,目前国内基本上都是用阿里巴巴开源的DataX替代其功能。
4. Apache Spark:Apache Spark是一个快速、通用的大数据处理引擎,可用于构建离线数据仓库和实时数据分析系统。Spark提供了高性能的数据处理和分析能力,并支持多种编程语言,如Scala、Java和Python。
5. Apache Kylin:Apache Kylin是一个开源的分布式分析引擎,专门用于构建OLAP(联机分析处理)数据仓库。它支持在Hadoop上构建多维数据模型,提供快速的查询性能和高度可扩展性。这是一款由国人主导和开源的大数据项目,也是一款专注于OLAP查询的Apache顶级开源项目。
6. Presto:Presto是一个分布式SQL查询引擎,可用于构建大规模数据仓库和数据查询引擎。它支持在多个数据源上执行高性能的查询,包括Hive、MySQL、PostgreSQL等。
说完数据仓库,就要说说OLAP查询了。在传统的数据仓库架构里,ETL是在数据仓库之外,OLAP在数据仓库之内的。在Hadoop体系引入数据仓库领域以后,大大提升了数据ETL处理的能力、集群的扩展能力、数据存储的稳定性,但是牺牲了数据的查询能力。所以就诞生了OLAP查询这个专业领域。
在离线数仓技术中,除了前面介绍的Kylin、Presto、Impala、Druid都是为了解决OLAP查询而设计的,但是这些基于HDFS设计的OLAP引擎都只是加速了查询速度,还没能达到令人满意或者令人惊艳的速度。于是,ClickHouse和Doris横空出世,一举成为了OLAP领域的王者。
ClickHouse是俄罗斯的 Yandex 于2016年开源的用于在线分析查询的数据管理系统,是一款基于MPP架构的列式存储数据库,能够使用 SQL 查询语句实时生成数据分析结果。ClickHouse的全称是Click Stream,Data WareHouse。ClickHouse 也是第一款实现向量化查询引擎的开源数据库,也是一款专注于OLAP查询的数据库。ClickHouse直接将OLAP查询的耗时压缩到了压秒级。
Apache Doris也是一个MPP架构的、专门用于OLAP查询的数据库产品。Apache Doris不仅可以满足多种数据分析需求,如固定历史报表,实时数据分析,交互式数据分析,探索式数据分析,而且集群扩展能力非常突出,可以支持10PB以上的超大数据集。另外,Apache Doris对实时数据的支持也非常强大,因此是一款综合能力非常强的数据库。由于Apache Doris是本次分享的重点,所以这里只是简单介绍一下,后面再展开。
这里插入一个知识点,也是我在整理PPT的时候看到的一个总结。ClickHouse为什么快?这里总结了几个点,其中最主要的是:C++语言可以利用硬件优势,底层数据选择列存储,支持向量化查询引擎,利用单节点的多核并行处理能力,数据写入时建立一级、二级和稀疏索引。这些特点为新兴的OLAP查询数据库研发指明了方向,这也是Doris的基本特点。
再说说第三个概念,MPP架构。MPP是大规模并行处理框架的简称。MPP是Shared Nothing架构,是将任务并行地分散到多个服务器和节点上,在每个节点上的计算完成后,将各部分的结果汇总在一起得到最终的结果。
前文说到的Teradata是业界最早的知名MPP架构的数据库,之后是Greenplum以及和Greenplum架构类似GBase、GaussDB等都是MPP架构。Hadoop体系的Presto、HAWQ、Impala都宣称是MPP架构,还有前面说到的Clickhouse和Doris两个新生物种。由于MPP家族越来越庞大,加上Hadoop生态的跨界“打劫”,所以现在很难定义什么是MPP架构。MPP架构和Hadoop架构在一定层次上走向融合,目前最大的区别就在于计算资源的分配上。Hadoop架构还遵从Yarn分配资源,而MPP架构都是独立使用本地内存和CPU。再就是过程备份和失败重试机制,hadoop都会保留中间计算过程,计算失败的部分节点有自动重试机制,而MPP架构一般是一次性过程,如果执行失败了就会告诉用户执行失败,以此换取更好的查询性能。
最后再来说说实时数仓。传统的数据仓库都是利用夜间的业务低峰期来完成数据的ETL加工处理,并且为白天的日常分析提供数据支撑,所以在这个应用前提下,数据仓库默认都是按天计算和加工数据的,俗称T+1数仓。但是随着业务的发展和技术的成熟,我们不再满足于今天看昨天的数据,而是想要今天就看到今天的数据,于是就有了实时数仓的概念。实时数仓是指数据的实时性更高、延迟性低的数据仓库,一般是统计当天发生的业务数据。实时数仓一般包括按小时执行的小时级、分钟级的延时的准实时和秒级延时纯实时数仓。
从前面的介绍我们可以看出,早期的Hive数仓技术并不完善,连实时OLAP查询都很难做到,所以要做到实时数仓就更加难上加难。所以Kafka诞生这么多年,实时数仓还要等到Flink火爆才流行起来。纯实时数据仓库是指能够以近乎实时的方式处理和分析数据的数据仓库。它的目标是将数据的捕获、处理和分析的速度提高到接近实时的水平,以支持实时决策和洞察。
纯实时数据仓库颠覆了离线数仓的架构,包括数据采集、数据加工、数据查询和分析都需要采用一套新的技术栈。
在数据采集方面,要做到较低延迟的采集数据,常用的方法是读取数据库变更日志(也叫CDC)或者直接接入在线的Kafka数据流。

在数据加工方面,实时数据一般采用Apache Flink或者Spark Streaming来完成数据加工,中间过程数据一般保存在Kafka。

在实时数据查询方面,一般只支持将数据汇总写入MySQL等关系型数据库或者Redis缓存,以便于快速获取结果。为了支持更快的查询,我们也可以将数据写入Clickhouse和Doris进行查询。
这种加工虽然可以做到数据的秒级延迟,但是牺牲了数据的准确性和数据分析维度,高度聚合的数据虽然可以满足一些场景的使用,但是无法进一步分析和深挖数据价值。所以大多数情况下,我们会在实时架构和离线架构之间做一个折中处理,就前半部分实时,后半部分离线,数据接入实时,数据加工采用离线微批处理。如果交易系统无法支持CDC变更日志,我们甚至可以基于数据的创建时间和修改时间,做微批的增量数据抽取。微批处理的好处在于:数据准确度比实时高,技术比较成熟,开发运维成本低。具体的实现方法我们将在第三部分展开。
实时数仓的应用场景也是在逐步丰富的,我在工作中遇到的主要有:
①实时业务监控和预警,避免线上业务中断未能及时发现造成的损失。
②实时大屏,主要用于618或者双十一大促期间监控业绩目标达成情况。
③实时机器人播报,通过实时数据加工,及时向相关同事通报当日业绩进展情况和排名。
④移动端实时数据展现,方便领导、管理人员实时查看业绩完成情况。
⑤实时自助分析,主要是给自助分析补充当日数据。
⑥实时看板。例如,按照五分钟的粒度查看成交指标,并和同期进行对比,便于及时发现业务故障,比实时监控更直观。
⑦实时数据接口。有一些数据对外的场景,需要实时提供最新的数据,便于跨系统对接,不过这种场景大多数在交易系统完成。
⑧实时推荐,例如商品实时销售排行榜等。
实时数仓的实现也有很多难点,我这里总结主要是三个点。
第一,多表关联,也叫多流jion,当其中一方数据延迟时,如果另外一边的流数据不在数据窗口范围中,将无法关联。例如销售订单父表和销售明细子表,如果业务系统出现明细表变更超出窗口范围的数据,双流jion将会丢失数据,导致变更记录丢失。
第二,维度数据变更。当维度数据发生变化时,历史数据和新写入的数据将存在不一致。如果是离线数仓,我们一般用当日凌晨确定时间点的维度状态作为统一维度;如果是纯实时数仓,维度变化前后的数据将出现不一致,而历史数据按照新维度清洗将成为一大难题。
第三个点是数据失效。数据失效包括数据物理删除和状态变为无效。数据物理删除,是指交易系统直接删除了对应的记录,这个在增量数据处理和实时数据抽取中都是难点,幸运的是CDC日志可以捕获到删除的记录;状态变为无效是指原来有效的数据变为无效数据,例如订单支付后关单。对于数据失效,我们一般的处理方法是生成一条指标为负数的对冲记录,将汇总结果中的指标扣减掉。但是在计算成交人数等指标则无法做到剔除。
以上三种情况在传统方案的实时数仓领域是无解的,但是使用FineDataLink,我们是可以很轻易的解决这些痛点。
帆软软件推出的FineDataLink提供了一套完整而灵活的解决方案,可以帮助用户快速构建可靠的高时效/近实时数据仓库系统。在构建高时效/近实时数据仓库时,帆软FDL有以下优势:
1. 操作界面简洁清晰,无代码配置,字段自动映射,无需专业的编程能力即可完成任务配置。

2. 提供统一的错误队列管理、预警机制、日志管理,支持脏数据阈值设置和通知功能,可通过短信、邮件、平台消息等进行消息提醒,保证企业敏感数据的安全性。

3. 打破数据壁垒,实现低成本业务系统的数据实时同步,从多个业务数据库实时捕获源数据库的变化并毫秒内更新到目的数据库。

综上所述,数仓建设是企业数据管理和决策支持的关键环节,在实践中,企业需要根据自身业务需求和数据规模,选择合适的数仓建设方案和技术方案,以提高企业数据资产的价值和利用效率。
FineDataLink——小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,另外它可以满足数据实时同步的场景,应有尽有,功能很强大。如果您需要进行实时数仓建设,帆软FDL会是您的最优解。

了解更多数据仓库与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能
往期推荐:
【大数据】什么是数据集市?如何创建数据集市?-CSDN博客
关于实时ODS层数仓搭建的三个问题_数仓直接依赖ods层有什么风险-CSDN博客
数据管道为什么选择Kafka作为消息队列?-CSDN博客
相关文章:
实时数仓分层架构详解
首先,我们从数据仓库说起。 数据仓库的概念可以追溯到20世纪80年代,当时IBM的研究人员提出了商业数据仓库的概念。数据仓库概念的提出,是为了解决和数据流相关的各种问题,特别是多重数据复制带来的高成本问题。 数据仓库之父Bill …...

计算机“八股文”在实际工作中是助力、阻力还是空谈?
“八股文”在实际工作中是助力、阻力还是空谈? 作为现在各类大中小企业面试程序员时的必问内容,“八股文”似乎是很重要的存在。但“八股文”是否能在实际工作中发挥它“敲门砖”应有的作用呢?有IT人士不禁发出疑问:程序员面试考…...

新160个crackme - 022-CM_2
运行分析 需破解Name和Serial,输入的小写字母都会变为大写字母 PE分析 C程序,32位,无壳 静态分析&动态调试 发现关键字符串 ida动态调试,发现Name和Serial长度需要大于5,且Serial前6位明文爆出,6287-A …...

在.c和.h 文件里定义数组的区别
在C语言开发中,掌握如何在.c文件和.h文件中合理定义数组,对于维护代码的模块化和避免不必要的编译错误至关重要。本文将探讨在这两种类型的文件中定义数组时需要注意的几个关键方面,包括定义性质、作用域、重复定义问题以及外部可见性等&…...
使用Step Functions运行AWS Backup时必备的权限要点
引言 在尝试从Step Functions执行AWS Backup的按需备份时,我在权限方面遇到了一些困难。为了备忘,我将这些经验写成这篇文章。 概述 从Step Functions执行AWS Backup时,需要分配以下权限: AWS Backup相关权限 执行备份的权限…...

强化JS基础水平的10个单行代码来喽!(必看)
目录 生成数组 数组简单数据去重 多数组取交集 重新加载当前页面 滚动到页面顶部 查找最大值索引 进制转换 文本粘贴 删除无效属性 随机颜色生成 生成数组 当你需要要生成一个0-99的数组 // 生成一个0-99的数组 // 方案一 const createArr n > Array.from(new A…...

大模型学习笔记 - 大纲
LLM 大纲 LLM 大纲 1. LLM 模型架构 LLM 技术细节 - 注意力机制LLM 技术细节 - 位置编码 2. LLM 预训练3. LLM 指令微调 LLM 高效微调技术 4. LLM 人类对齐 LLM InstructGPTLLM PPO算法LLM DPO 算法 5. LLM 解码与部署6. LLM 模型LLaMA 系列7. LLM RAG 1. LLM 模型架构 大模…...

苹果电脑可以玩什么小游戏 适合Mac电脑玩的休闲游戏推荐
对于游戏爱好者而言,Mac似乎并不是游戏体验的首选平台。这主要是因为相较于Windows系统,Mac上的游戏资源显得相对有限。不过,这并不意味着Mac用户就与游戏世界绝缘。实际上,Mac平台上有着一系列小巧精致且趣味横生的小游戏&#x…...
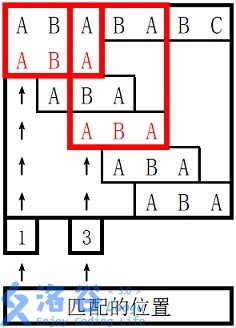
浅谈KMP算法(c++)
目录 前缀函数应用【模板】KMP题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示样例 1 解释数据规模与约定 思路AC代码 本质不同子串数 例题讲解[NOI2014] 动物园题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示思路AC代码 [POI2006] OKR-Periods of …...
关于C++编程注意点(竞赛)
赛前准备 多复习 重中之重, 多刷题 确保手感 参加几场模拟赛,熟悉流程 熟悉 Linux 系统,否则你将会手忙脚乱 放松心情,调整心态,分数 实力 心态 赛中注意 输入输出方面 在数据范围超过 时尽量使用 scanf pr…...
Markdown文本编辑器:Typora for Mac/win 中文版
Markdown 是一种轻量级的标记语言,它允许用户使用易读易写的纯文本格式编写文档。Typora 支持且仅支持 Markdown 语法的文本编辑,生成的文档后缀名为 .md。 这款软件的特点包括: 实时预览:Typora 的一个显著特点是实时预览&#x…...

Mysql-窗口函数一
文章目录 1. 窗口函数概述1.1 介绍1.2 作用 2. 场景说明2.1 准备工作2.2 场景说明2.3 分析2.4 实现2.4.1 非窗口函数方式实现2.4.2 窗口函数方式实现 3. 窗口函数分类4. 窗口函数基础用法:OVER关键字4.1 语法4.2 场景一 :计算每个值和整体平均值的差值4.2.1 需求4.2…...

Python3 爬虫 数据抓包
一、数据抓包 所谓抓包(Package Capture),简单来说,就是在网络数据传输的过程中对数据包进行截获、查看、修改或转发的过程。如果把网络上发送与接收的数据包理解为快递包裹,那么在快递运输的过程中查看里面的内容&…...

js强制刷新
在JavaScript中触发强制刷新通常指的是强制浏览器重新加载页面,忽略缓存。以下是几种实现强制刷新的方法: ### 使用 location.reload() 这是最简单的方法,它会重新加载当前页面。 javascript location.reload(true); // 传入true参数表示强制…...

yolov5 part2
two-stage (两阶段):Faster-rcnn Mask-Rcnn系列 one-stage (单阶段):YOLO系列 最核心的优势:速度非常快,适合实时监测任务。但是缺点也有,效果可能不好 速度较慢在2018…...

Hive3:表操作常用语句-内部表、外部表
一、内部表 1、基本介绍 (CREATE TABLE table_name ......) 未被external关键字修饰的即是内部表, 即普通表。 内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/ware…...

【PXE+kickstart】linux网络服务之自动装机
PXE: 简介:PXE(Preboot execute environment 是一种能够让计算机通过网络启动的引导方式,只要网卡支持PXE协议即可使用Kickstart 是一种无人值守的安装方式,工作原理就是预先把原本需要运维人员手工填写的参数保存成一个 ks.cfg 文…...

vmware ubuntu虚拟机网络联网配置
介绍vmware虚拟机配置基础网络环境,同时连接外网(通过桥接模式),以及ubuntu下输入法等基础工具安装。 本文基于ubuntu22.04,前提虚拟机已经完成安装。本文更多是针对vmware虚拟机的设置,之前有一篇针对ubun…...

Vue3_对接声网实时音视频_多人视频会议
目录 一、声网 1.注册账号 2.新建项目 二、实时音视频集成 1.声网CDN集成 2.iframe嵌入html 3.自定义UI集成 4.提高进入房间速度 web项目需要实现一个多人会议,对接的声网的灵动课堂。在这里说一下对接流程。 一、声网 声网成立于2014年,是全球…...

慧灵科技:创新引领自动化未来
在智能制造与自动化生产日益成为主流趋势的今天,慧灵科技凭借其卓越的技术创新能力和产品优势,在机器人领域崭露头角。 自2015年在深圳成立以来,慧灵科技专注于核心技术的研发与产品创新,为各行业提供性价比极高的机器人产品及自…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...