100道C/C++面试题
- 1. static的作用
- 2. 引用与指针的区别
- 3. .h头文件中的ifndef/define/endif 的作用
- 4 #include<file.h>与#include"file.h"的区别?
- 5 描述实时系统的基本特性
- 6 全局变量和局部变量在内存中是否有区别?如果有,是什么区别?
- 7 什么是平衡二叉树?
- 8 堆栈溢出一般是由什么原因导致的?
- 9 冒泡排序算法的时间复杂度是什么?
- 10 什么函数不能声明为虚函数
- 11 栈和队列的区别
- 12 switch不支持的参数类型
- 13 局部变量是否可以和全局变量重名
- 14 全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
- 15 简述程序的内存分配
- 16 解释堆和栈的区别
- 17 gcc四部曲
- 18 const关键字
- 19 volatile关键字
- 20 三种基本的数据类型
- 21 结构体与联合体的区别
- 22 const与#define相比的优点
- 23 简述数组与指针的区别
- 24 如何判断程序是由c编译还是c++编译
- 25 讨论含参数的宏与函数的优缺点
- 26 什么是中断
- 27 什么是boa服务器
- 28 共享内存如何使用
- 29.消息队列如何使用
- 30.怎样实现进程间同步
- 31.网关有什么作用
- 32.线程间的同步互斥是怎么实现的
- 33.什么是同步什么是互斥
- 34.文件流指针指的是什么
- 35.文件i/o和标准i/o的区别,两者描述文件的方式
- 36.UDP可不可以实现可靠的数据传输
- 37.TCP的缺点
- 39.register关键字解析
- 38.介绍select,poll,epoll
- 40.符号关键字(unsigned)
- 41.函数指针,指针函数,指针数组,数组指针
- 42.出现野指针的情况
- 43.结构体,枚举,宏定义
- 44.进程线程程序的区别
- 45.动态库和静态库的区别
- 46.什么是回调函数
- 47.地址能否用%u打印
- 48.声明变量和定义变量的区别
- 49.赋值和赋初值有什么区别
- 50.如何引用一个定义过的外部变量
- 51.为什么函数形参数组和指针可以互换
- 52.形参和实参有什么区别
- 53.void指针就是空指针么,有什么作用
- 54.指针,数组,地址之间有什么关系
- 55.字符设备,块设备,管道等在linux下的统称是什么
- 56.查看一个文件类型有哪几种方式
- 57.Linux下常用安装工具
- 58.分别解释shell命令,shell,shell脚本
- 59.printf与scanf操作的是否是同一个文件
- 60.Linux常用的文件系统类型?如何查看文件系统类型?
- 61.windows下有没有文件系统?文件系统有何作用?
- 62.头文件和库文件一般在哪个路径下?
- 63.系统如何区别同名的文件
- 64.系统如何区别不同的进程。
- 65.查看文件有哪些命令
- 66.如何修改文件的权限
- 67.什么是符号链接?
- 68.数据结构主要研究的是什么?
- 69.数组和链表的区别(逻辑结构、内存存储、访问方式三个方面辨析)
- 70.快速排序的算法
- 71.hash查找的算法
- 72.判断单链表是否有环
- [73.判断一个括号字符串是否匹配正确,如果括号有多种,怎么做?如(([]))正确,[(()错误
- 74.简述系统调用?
- 75.如何将程序执行直接运行于后台?
- 76.进程的状态
- 77.简述创建子进程中的写时拷贝技术?
- 78.线程池的使用?
- 79.简述互斥锁的实现原理?
- 80.简述死锁的情景?
- 81.简述信号量的原理?
- 82.管道的通信原理?
- 83.用户进程对信号的响应方式?
- 84.ISO七层网络通信结构,每层的主要作用,主要的协议
- 85.TCP/IP四层网络通信结构
- 86.io模型有哪几种
- 87.如何实现并发服务器,并发服务器的实现方式以及有什么异同
- 88.网络超时检测的本质和实现方式
- 89.udp本地通信需要注意哪些方面
- 90.怎么修改文件描述符的标志位
- 91.TCP和UDP的区别
- 92.TCP的三次握手和四次挥手分别作用,主要做什么
- 93.new、delete、malloc、free关系
- 94.delete与delete[]区别
- 95.C++有哪些性质(面向对象特点)
- 96.子类析构时要调用父类的析构函数吗?
- 97.多态,虚函数,纯虚函数
- 98.什么是“引用”?申明和使用“引用”要注意哪些问题?
- 99.将“引用”作为函数参数有哪些特点?
- 100.在什么时候需要使用“常引用”?
1. static的作用
静态局部变量:
延长局部变量的生命周期至整个程序运行期间,但作用域仍限于定义它的函数内部。
静态全局变量:
限制全局变量的作用域至定义它的文件,防止其在其他文件中被访问。
静态成员变量:
使成员变量属于类而非类的实例,所有对象共享同一个静态成员变量。
静态成员函数:
使成员函数属于类而非类的实例,可以通过类名直接调用,且只能访问静态成员变量和静态成员函数。
2. 引用与指针的区别
引用:
引用是另一个变量的别名,必须在定义时初始化,且不能为空。
引用一旦初始化后,就不能再指向其他变量。
不需要手动管理内存,引用本身不占用额外内存.指针:
指针是一个变量,存储另一个变量的地址,可以不初始化或指向nullptr。
指针可以在其生命周期内指向不同的对象或变量
需要手动管理内存,可能涉及动态内存分配和释放。3. .h头文件中的ifndef/define/endif 的作用
#ifndef、#define和#endif预处理指令用于防止头文件内容被多次包含.具体作用如下:
#ifndef:检查指定的宏是否未定义,如果未定义则执行后续代码。
#define:定义一个宏,确保后续包含该头文件时,#ifndef检查将失败,避免重复包含。
#endif:结束#ifndef块。
4 #include<file.h>与#include"file.h"的区别?
区别在于搜索路径和顺序:#include <file.h>:编译器在系统的标准包含目录中搜索头文件,通常用于标准库或第三方库头文件。
#include "file.h":编译器首先在当前源文件所在目录搜索头文件,若未找到则转至标准包含目录,通常用于项目自定义头文件。
5 描述实时系统的基本特性
实时系统的基本特性包括:时间约束性:必须在规定时间内完成任务处理。
可预测性:系统行为和性能需在给定时间内可预测。
确定性:相同事件的响应时间应一致。
可靠性:系统需在各种环境下稳定运行。
优先级调度:采用优先级调度机制确保高优先级任务优先处理。
资源管理:有效管理资源,确保关键任务获得所需计算资源。
容错性:具备一定容错能力,确保系统稳定性和可靠性。
这些特性确保实时系统在严格时间约束下对外部事件作出及时、准确的响应。
6 全局变量和局部变量在内存中是否有区别?如果有,是什么区别?
全局变量和局部变量在内存中的主要区别如下:全局变量存储在全局数据区,程序启动时分配,结束时释放。
全局变量从程序启动到结束持续存在。
全局变量在整个程序中可访问。未初始化的全局变量自动初始化为零或空值。局部变量存储在栈上,随函数调用动态分配和释放。
局部变量仅在其定义的代码块执行期间存在。
局部变量仅在其定义的代码块内可访问。7 什么是平衡二叉树?
平衡二叉树是一种特殊的二叉搜索树,
其每个节点的左右子树高度差不超过1,确保树的高度保持在O(log n),
从而保证插入、删除和查找操作的时间复杂度为O(log n)。常见的平衡二叉树包括AVL树和红黑树。8 堆栈溢出一般是由什么原因导致的?
递归调用过深:递归层次过深导致堆栈内存不断增加。
局部变量过多或过大:大量或大内存占用的局部变量导致堆栈空间耗尽。
堆栈大小限制:程序所需堆栈空间超过系统或编译器设定的限制。
无限循环或错误逻辑:程序逻辑错误导致函数不断被调用,堆栈空间耗尽。
缓冲区溢出:未正确检查边界的缓冲区操作破坏堆栈结构。
9 冒泡排序算法的时间复杂度是什么?
冒泡排序算法的时间复杂度是O(n^2),原因是每一次循环都需要进行n-1次比较,
10 什么函数不能声明为虚函数
静态成员函数:属于类而非实例,不与特定对象关联。
内联函数:编译时展开,与虚函数的运行时动态绑定不兼容。
构造函数:用于对象创建,虚函数机制在对象创建后生效。
友元函数:虽可访问私有成员,但不属于类成员函数。
全局函数:不属于任何类。
11 栈和队列的区别
数据存储方式:
栈:后进先出(LIFO),数据从栈顶插入和删除。
队列:先进先出(FIFO),数据从队尾插入,从队头删除。操作方式:
栈:主要操作是压栈(插入)和弹栈(删除)。
队列:主要操作是入队(插入)和出队(删除)。
12 switch不支持的参数类型
浮点类型:如float和double,因比较复杂且可能有精度问题。
字符串类型:如std::string,因字符串比较和匹配复杂。
自定义对象类型:因switch仅支持整数和枚举类型。
布尔类型:虽为整数类型,但通常用if-else更直观。
13 局部变量是否可以和全局变量重名
在C++中,局部变量可以与全局变量重名。当局部变量与全局变量重名时,
在局部变量的作用域内,局部变量会屏蔽(隐藏)同名的全局变量。
这意味着在局部变量的作用域内,访问该变量名时将引用局部变量,而不是全局变量。
14 全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
全局变量不应定义在可被多个.C文件包含的头文件中,因为这会导致重复定义错误。
每个包含该头文件的.C文件都会有一份全局变量的定义,链接时会引发重复定义错误。
正确的做法是将全局变量的声明放在头文件中,并在一个.C文件中进行定义。
头文件中使用extern关键字声明全局变量,表示该变量在其他地方定义。
15 简述程序的内存分配
栈(Stack):存储函数的局部变量、参数和返回地址,自动管理,后进先出。
堆(Heap):动态内存分配,由程序员通过new和delete操作符手动管理。
全局/静态存储区:存储全局变量和静态变量,生命周期从程序启动到结束。
常量存储区:存储常量数据,如字符串常量和const修饰的变量,不可修改。
代码段:存储程序的机器指令,只读,防止运行时修改。
16 解释堆和栈的区别
栈:
自动管理,由编译器负责,函数调用时分配,返回时释放。
局部变量和函数参数的生命周期由函数调用和返回决定。
访问速度较快,因为栈的内存分配和释放是连续的。
后进先出(LIFO),内存分配和释放按固定顺序进行。堆:
手动管理,由程序员通过new和delete操作符显式分配和释放。
动态分配的内存生命周期由程序员控制,直到显式释放。
访问速度较慢,因为堆的内存分配和释放是动态的,可能涉及内存碎片和复杂的分配算法。
内存分配和释放没有固定顺序,可以按需进行。17 gcc四部曲
预处理:处理预处理指令,生成预处理后的源文件。 (展开宏定义,包含头文件内容,移除注释等,)
编译:将预处理后的源文件编译成汇编代码。 (词法分析、语法分析、语义分析和代码优化,生成对应的汇编代码。)
汇编:将汇编代码汇编成目标文件。 (汇编语言文件转换成机器代码)
链接:将目标文件与库链接,生成可执行文件。
18 const关键字
const关键字可以提高代码的安全性、保护数据不被修改。1. 常量变量定义初始化后不可更改的变量。
2. 常量指针指针指向的值不可变。指针本身不可变。指针和指针指向的值都不可变。
3. 常量成员函数在类中,修饰成员函数表示该函数不会修改类的成员变量。
4. 常量函数参数在函数参数中使用,表示函数内部不能修改该参数的值。
5. 常量返回值修饰函数返回值,表示返回值不可修改。19 volatile关键字
(答案存疑)
volatile关键字在C++中用于告诉编译器,
某个变量的值可能会在程序的控制之外被改变,
因此编译器不应该对该变量进行优化。
20 三种基本的数据类型
整型(Integer)、浮点型(Floating-Point)和字符型(Character)
21 结构体与联合体的区别
结构体:
每个成员有独立内存,总大小是各成员大小之和(考虑内存对齐)。
可同时存储多个不同类型的数据。可同时访问和修改所有成员。
适用于多数据存储,表示复杂对象。联合体:
所有成员共享内存,大小等于最大成员的大小。
同一时间只能存储一个成员的值。只能访问和修改当前存储的成员。
适用于节省内存或实现多态。22 const与#define相比的优点
const:
提供类型检查,确保类型安全。
具有作用域,可在局部或类作用域定义。
可被调试器识别和显示,便于调试。
可存储在只读存储区,优化内存管理。
更易读和维护,有明确的类型和作用域。#define:
无类型信息,缺乏类型检查。
全局作用域,易引发命名冲突。
预处理阶段被替换,难以调试。
不占用内存空间。
代码中直接替换,可能导致代码膨胀和可读性下降。
23 简述数组与指针的区别
1. 定义和初始化
数组:需指定元素类型和数量。
指针:需指定指向的变量类型。
2. 内存分配
数组:静态分配连续内存。
指针:可动态分配内存。
3. 访问元素
数组:用下标访问。
指针:用指针运算访问。
4. 赋值和复制
数组:不能直接赋值,需逐元素复制。
指针:可以直接赋值。
5. 函数参数传递
数组:退化为指针,传递首地址。
指针:传递指针变量的值(地址)。
6. 类型信息
数组:数组名表示整个数组。
指针:表示指向的变量类型。
24 如何判断程序是由c编译还是c++编译
C源文件:通常使用.c扩展名。 生成的目标文件通常带有c标记。
C++源文件:通常使用.cpp、.cc、.cxx等扩展名。 生成的目标文件通常带有cpp或cxx标记。
25 讨论含参数的宏与函数的优缺点
宏函数
预处理阶段展开,无函数调用开销,执行速度快。
避免函数调用的堆栈操作,适用于性能敏感代码。
可接受任意类型参数,不进行类型检查。
可读性和维护性差:宏代码在预处理阶段展开,可能导致代码膨胀,难以调试。
宏定义分散,不易阅读和维护。
不进行类型检查,可能导致类型相关的错误。函数:
函数有明确的定义和调用,代码结构清晰,易于阅读和维护。
便于调试和测试。
编译器进行类型检查,确保类型安全,减少运行时错误。
函数调用涉及堆栈操作,可能带来额外开销26 什么是中断
中断是计算机系统中的一种机制,用于在执行程序的过程中,
临时暂停当前任务,转而处理更为紧急或重要的任务。
中断可以由硬件设备或软件触发,
处理过程包括中断请求、中断响应、保存现场、中断处理和恢复现场。
这一机制提高了系统的响应速度和处理能力,广泛应用于设备驱动程序、操作系统内核和实时系统等领域。
27 什么是boa服务器
OA服务器是一种轻量级、高性能的Web服务器软件,
专为嵌入式系统和资源受限的环境设计。
它具有代码量小、占用资源少、处理性能高、配置简单、稳定可靠等特点。
BOA服务器广泛应用于嵌入式Linux系统,
提供基本的HTTP服务,如静态网页访问和简单的CGI脚本执行,
适用于物联网设备、路由器、网络存储设备等领域。
28 共享内存如何使用
共享内存是一种高效的进程间通信机制,
通过系统调用创建、附加、使用、分离和删除共享内存段,
实现多个进程间的数据共享。使用时需注意同步问题,以确保数据一致性。常见的同步机制包括信号量、互斥锁等
-----------------
1创建共享内存:
使用系统调用(如shmget)创建一个新的共享内存段,或者获取一个已存在的共享内存段的标识符。
2附加共享内存:
使用系统调用(如shmat)将共享内存段附加到进程的地址空间中,使得进程可以访问这块内存。
3使用共享内存:
进程可以直接读写附加到其地址空间中的共享内存区域,进行数据交换。
4分离共享内存:
当进程不再需要访问共享内存时,使用系统调用(如shmdt)将共享内存段从其地址空间中分离。
5删除共享内存:
当所有进程都不再需要使用共享内存时,使用系统调用(如shmctl)删除共享内存段,释放系统资源。29.消息队列如何使用
消息队列是一种进程间通信(IPC)机制,允许多个进程通过发送和接收消息来进行异步通信。以下是消息队列的基本使用步骤:创建消息队列:
使用系统调用(如msgget)创建一个新的消息队列,或者获取一个已存在的消息队列的标识符。发送消息:
使用系统调用(如msgsnd)将消息发送到消息队列中。消息通常包含一个类型字段和一个数据字段。接收消息:
使用系统调用(如msgrcv)从消息队列中接收消息。接收方可以根据消息类型选择性地接收消息。控制消息队列:
使用系统调用(如msgctl)对消息队列进行控制操作,如修改队列属性、删除队列等。消息队列的使用提供了进程间异步通信的能力,
发送方和接收方不需要同时处于活动状态,
消息会在队列中等待直到被处理。这种机制适用于需要解耦和异步处理的场景。
30.怎样实现进程间同步
进程间同步的常见方法包括:信号量:
计数器,控制共享资源访问,通过semget、semop、semctl系统调用实现。互斥锁(Mutex):
二进制信号量,确保同一时间只有一个进程访问资源,通过pthread_mutex_init、pthread_mutex_lock、pthread_mutex_unlock实现。条件变量(Condition Variable):
允许进程在特定条件满足时等待或唤醒,通过pthread_cond_init、pthread_cond_wait、pthread_cond_signal实现。文件锁(File Lock):
通过文件系统提供的锁机制,控制对文件的访问,通过fcntl系统调用实现。这些方法确保进程按序访问共享资源,避免数据竞争和不一致。
31.网关有什么作用
网关是连接不同网络的关键设备,主要作用包括:协议转换:在不同网络协议间进行转换。
数据转发:将数据从一个网络传输到另一个网络。
安全控制:实施防火墙等安全策略,保护网络免受威胁。
地址转换:进行网络地址转换(NAT),实现私有IP与公共IP的转换。
路由选择:根据路由表选择最佳路径,确保数据高效传输。
服务提供:提供DHCP、DNS等服务,简化网络管理。网关确保网络间的顺畅通信和安全防护,是网络通信的桥梁和安全屏障。
32.线程间的同步互斥是怎么实现的
线程间同步互斥的实现方法包括:互斥锁(Mutex):
通过pthread_mutex_init、pthread_mutex_lock、pthread_mutex_unlock实现,确保同一时间只有一个线程访问资源。条件变量(Condition Variable):
通过pthread_cond_init、pthread_cond_wait、pthread_cond_signal实现,允许线程在特定条件满足时等待或唤醒。读写锁(Reader-Writer Lock):
通过pthread_rwlock_init、pthread_rwlock_rdlock、pthread_rwlock_wrlock、pthread_rwlock_unlock实现,允许多个读线程同时访问,但写线程独占访问。信号量(Semaphore):
通过sem_init、sem_wait、sem_post实现,控制对共享资源的访问。这些机制确保线程按序访问共享资源,避免数据竞争和不一致。
33.什么是同步什么是互斥
同步(Synchronization):确保多个线程或进程按特定顺序执行,避免竞态条件,常用机制包括条件变量、信号量、屏障等。互斥(Mutual Exclusion):确保同一时间只有一个线程或进程访问共享资源,常用机制包括互斥锁、临界区等。
34.文件流指针指的是什么
文件流指针(File Stream Pointer):指向文件内部位置的指针,用于指示当前读写操作的位置,通过fopen、fread、fwrite、fseek等函数操作。
35.文件i/o和标准i/o的区别,两者描述文件的方式
文件I/O(低级I/O):
直接使用系统调用(如open、read、write、close),操作文件描述符,性能高但编程复杂。标准I/O(高级I/O):
使用标准库函数(如fopen、fread、fwrite、fclose),操作文件流指针,提供缓冲机制,编程简单但性能稍低。描述文件方式:
文件I/O使用文件描述符(整数)。
标准I/O使用文件流指针(FILE*)。
36.UDP可不可以实现可靠的数据传输
UDP本身不可靠,但可通过应用层实现可靠性:使用确认机制、重传机制、序号和校验和等手段,在应用层实现类似TCP的可靠性。
37.TCP的缺点
TCP缺点:头部较大,开销高。
传输速度受拥塞控制影响,可能较慢。
连接建立需三次握手,延迟较高。
不支持多播和广播。
39.register关键字解析
register关键字:建议编译器将变量存储在寄存器中,提高访问速度。
编译器可忽略此建议,现代编译器优化能力强,register使用较少。限制:不能取地址,不能用于数组和结构体。
38.介绍select,poll,epoll
select:监控多个文件描述符(FD),最大数量有限(通常1024)。
使用位图表示FD集合,每次调用需传递整个集合,效率低。
适用于简单、FD数量少的场景。
poll:使用链表管理FD,无最大数量限制。
每次调用需传递整个链表,效率随数量增加下降。
适用于FD数量较多但仍有限的场景。
epoll:Linux特有,高效处理大量FD。
使用事件驱动,仅通知有事件发生的FD,无需遍历所有FD。
支持边缘触发(ET)和水平触发(LT),性能稳定,适用于高并发场景。
40.符号关键字(unsigned)
unsigned关键字:用于声明无符号整数类型,表示数值范围从0开始,无负数。
常见用法:unsigned int、unsigned char、unsigned long等。
增加正数范围,减少负数范围。
41.函数指针,指针函数,指针数组,数组指针
函数指针:
指向函数的指针,用于调用函数,声明如int (*func_ptr)(int, int);。指针函数:
返回指针的函数,如int* func(int x);。指针数组:
存储指针的数组,如int* arr[10];。数组指针:
指向数组的指针,如int (*arr_ptr)[10];。
42.出现野指针的情况
野指针情况:未初始化指针,如int* p;。
释放内存后未置空,如free(p); p = NULL;。
指针越界访问,超出分配内存范围。
多线程环境下未同步访问共享指针。
43.结构体,枚举,宏定义
结构体:
用户定义的数据类型,组合多个不同类型数据,如struct Point { int x; int y; };。枚举:
定义一组命名常量,如enum Color { RED, GREEN, BLUE };。宏定义:
预处理器指令,定义常量或代码片段,如#define PI 3.14,#define SQUARE(x) ((x) * (x))。
44.进程线程程序的区别
进程:操作系统资源分配和调度基本单位,拥有独立内存空间、文件描述符等资源。
进程间通信(IPC)复杂,如管道、消息队列、共享内存等。
创建、销毁、切换开销大。线程:进程内执行单元,共享进程资源(内存、文件),独立执行流。
线程间通信简单,通过共享内存或线程同步机制(如互斥锁、条件变量)。
创建、销毁、切换开销小,适用于并发处理。程序:静态代码和数据的集合,存储在磁盘上,未运行状态。
通过操作系统加载和执行,转化为进程,开始运行。
程序本身不占用系统资源,进程是程序的动态执行实例。
45.动态库和静态库的区别
静态库:编译时链接到可执行文件,包含所有代码和数据。
可执行文件体积大,部署简单,运行时无需外部库。动态库:运行时加载,多个程序共享,节省内存。
可执行文件体积小,需依赖外部库,部署复杂。
更新动态库不影响可执行文件,便于维护。
46.什么是回调函数
回调函数:作为参数传递给其他函数的函数,在特定事件或条件触发时被调用。
实现异步编程、事件驱动编程,提高代码灵活性和可扩展性。
常见于事件处理、异步操作、库函数接口等场景。
47.地址能否用%u打印
地址通常不能用%u打印:%u用于无符号整数,地址类型为指针(如void*)。
应使用%p格式符打印指针地址,如printf("%p", ptr);。
确保类型匹配,避免未定义行为。
48.声明变量和定义变量的区别
声明变量:
告知编译器变量存在,但不分配内存,如extern int x;。定义变量:
实际分配内存,创建变量,如int x;。
定义隐含声明,但声明不隐含定义。区别:
声明不分配内存,定义分配内存。
多个声明合法,重复定义非法。
49.赋值和赋初值有什么区别
赋值:
将值赋予已存在的变量,如int x; x = 10;。赋初值:
在变量定义时赋予初始值,如int x = 10;。区别:
赋值操作变量已存在,赋初值伴随变量定义。
赋初值确保变量初始状态,避免未定义行为。
50.如何引用一个定义过的外部变量
引用外部变量:使用extern关键字声明,如extern int x;。
确保外部变量在其他文件中已定义,如int x;。
编译器链接时解析外部变量引用。
51.为什么函数形参数组和指针可以互换
函数形参数组和指针互换原因:数组名在函数参数列表中退化为指向首元素的指针。
如void func(int arr[])等同于void func(int *arr)。
编译器处理数组参数为指针,传递数组地址,提高效率。
区别:数组参数声明更直观,指针参数更灵活。
数组参数隐含大小信息,指针参数无此信息。
52.形参和实参有什么区别
形参是函数定义时声明的参数,用于接收调用时传递的值;
实参是函数调用时传递给函数的具体值或变量。
简单来说,形参是“形式上的参数”,实参是“实际的参数”。
53.void指针就是空指针么,有什么作用
void指针(void *)是一种特殊类型的指针,它可以指向任何数据类型,
但本身不指定具体类型。它不是空指针(NULL或nullptr),
空指针表示指针不指向任何有效的内存地址。void指针的作用包括:通用数据类型的指针,适用于需要处理多种数据类型的函数。
在函数参数中使用,实现泛型编程。
动态内存分配时,返回的指针类型通常是void *。
54.指针,数组,地址之间有什么关系
指针、数组和地址之间有密切的关系:指针:指针是一个变量,存储另一个变量的内存地址。
数组:数组是一组相同类型的元素的集合,数组名本身代表数组首元素的地址。
地址:地址是内存中存储单元的编号,通过地址可以访问存储在该位置的数据。关系如下:
数组名可以看作指向数组首元素的常量指针。
指针可以用来访问和操作数组元素。
通过指针和数组名,可以对内存地址进行操作和访问
55.字符设备,块设备,管道等在linux下的统称是什么
在Linux下,字符设备、块设备、管道等统称为特殊文件或设备文件。
它们通常位于/dev目录下,用于与硬件设备或特定系统功能进行交互。
56.查看一个文件类型有哪几种方式
查看文件类型有以下几种方式:file命令:使用file命令可以查看文件的类型。file filenamels -l命令:使用ls -l命令查看文件的详细信息,第一列显示文件类型和权限。ls -l filenamestat命令:使用stat命令查看文件的详细状态信息。stat filename文件扩展名:虽然Linux不依赖文件扩展名来判断文件类型,但某些应用程序和用户习惯使用扩展名来标识文件类型。
57.Linux下常用安装工具
APT(Advanced Package Tool):Debian及其衍生发行版(如Ubuntu)的包管理工具。sudo apt updatesudo apt install package_nameYUM(Yellowdog Updater, Modified):Red Hat及其衍生发行版(如CentOS)的包管理工具。sudo yum install package_nameDNF(Dandified YUM):YUM的继任者,用于Fedora和较新的Red Hat发行版。sudo dnf install package_namePacman:Arch Linux及其衍生发行版的包管理工具。sudo pacman -S package_nameZypper:openSUSE的包管理工具。sudo zypper install package_nameSnap和Flatpak:用于跨发行版的通用包管理工具。sudo snap install package_namesudo flatpak install package_name58.分别解释shell命令,shell,shell脚本
Shell命令:Shell命令是用户通过Shell(命令行解释器)输入的指令,用于执行特定的操作,如文件管理、进程控制、系统配置等。例如,ls、cd、mkdir等。Shell:Shell是操作系统的外壳,作为用户与内核之间的接口,负责解释和执行用户输入的命令。常见的Shell有Bash(Bourne Again SHell)、Zsh、Fish等。Shell脚本:Shell脚本是用Shell语言编写的脚本文件,包含一系列Shell命令和控制结构(如循环、条件判断等),用于自动化执行一系列任务。Shell脚本通常以.sh为扩展名,可以通过sh或bash等Shell解释器执行。
59.printf与scanf操作的是否是同一个文件
printf和scanf操作的默认情况下是同一个文件,即标准输入输出文件。具体来说:printf:用于向标准输出(通常是终端屏幕)打印数据。
scanf:用于从标准输入(通常是键盘)读取数据。
在默认情况下,标准输出和标准输入分别对应文件描述符1和0。
用户可以通过重定向操作符(如>、<、>>)将这些标准流重定向到其他文件或设备。
60.Linux常用的文件系统类型?如何查看文件系统类型?
Linux常用的文件系统类型包括:ext4:第四代扩展文件系统,是大多数Linux发行版的默认文件系统。
ext3:第三代扩展文件系统,是ext4的前身。
ext2:第二代扩展文件系统。
XFS:高性能的日志文件系统,常用于大型文件系统和高性能计算。
Btrfs:B-tree文件系统,具有高级功能,如快照、数据校验和、动态inode分配等。
NTFS:Windows的默认文件系统,在Linux中可以通过NTFS-3G等驱动程序进行读写。
FAT32:常见的跨平台文件系统,兼容性好,但功能有限。查看文件系统类型的方法:df命令:使用df -T命令查看挂载点上的文件系统类型。df -Tlsblk命令:使用lsblk -f命令查看块设备的文件系统类型。lsblk -ffile命令:使用file -s命令查看特定设备上的文件系统类型。file -s /dev/sda1blkid命令:使用blkid命令查看块设备的UUID和文件系统类型。blkid61.windows下有没有文件系统?文件系统有何作用?
Windows操作系统下有多种文件系统,常见的包括:NTFS(New Technology File System):Windows的默认文件系统,支持大容量磁盘、文件权限控制、加密、压缩等高级功能。
FAT32(File Allocation Table 32):较早的文件系统,兼容性好,但文件大小和分区大小有限制。
exFAT(Extended File Allocation Table):用于闪存驱动器和大容量存储设备,支持更大的文件和分区。文件系统的作用主要包括:
组织和管理文件:文件系统负责在存储设备上组织和管理文件,包括文件的存储位置、目录结构、文件名等。
数据存储和检索:文件系统提供数据存储和检索的机制,确保数据能够高效、可靠地存储和访问。
文件权限和安全:某些文件系统(如NTFS)提供文件权限控制、加密等功能,保护数据安全。
磁盘空间管理:文件系统管理磁盘空间,分配和回收存储空间,确保磁盘空间的高效利用。
总之,文件系统是操作系统中负责管理文件和目录、控制文件存储和检索的关键组件。
62.头文件和库文件一般在哪个路径下?
头文件和库文件在不同操作系统及编译环境下的默认路径有所不同:头文件(Header Files):Linux:通常位于/usr/include或/usr/local/include目录下。
Windows:通常位于编译器或开发环境的安装目录下的include文件夹中,例如Visual Studio的VC\include目录。库文件(Library Files):
Linux:通常位于/usr/lib或/usr/local/lib目录下。
Windows:通常位于编译器或开发环境的安装目录下的lib文件夹中,例如Visual Studio的VC\lib目录。此外,用户也可以自定义头文件和库文件的路径,通过编译器的选项(如-I指定头文件路径,-L指定库文件路径)来指定。
63.系统如何区别同名的文件
系统通过以下几种方式来区别同名文件:目录结构:文件系统通过文件所在的目录来区分同名文件。例如,/home/user1/file.txt和/home/user2/file.txt是两个不同的文件,即使它们具有相同的文件名。文件路径:完整的文件路径(包括目录和文件名)唯一标识一个文件。例如,C:\Documents\file.txt和C:\Downloads\file.txt是两个不同的文件。文件扩展名:虽然文件扩展名不是必须的,但在某些情况下,扩展名可以用来区分同名文件。例如,file.txt和file.doc是两个不同的文件。文件属性:某些文件系统支持文件属性(如标签、颜色标记等),这些属性可以用来区分同名文件。文件系统UUID:某些文件系统(如NTFS)为每个文件分配唯一的UUID(Universally Unique Identifier),即使文件名相同,UUID也能唯一标识文件。硬链接和符号链接:硬链接和符号链接可以指向同一个文件,但它们在文件系统中表现为不同的条目。总之,文件系统通过文件的完整路径、目录结构、扩展名、属性、UUID等方式来确保同名文件在系统中能够被正确区分和管理。
64.系统如何区别不同的进程。
系统通过以下几种方式来区别不同的进程:进程ID(PID):每个进程在系统中都有一个唯一的进程ID(PID),这是一个正整数,用于标识进程。PID由操作系统内核分配,并在进程的生命周期内保持不变。父进程ID(PPID):每个进程都有一个父进程ID(PPID),表示创建该进程的父进程的PID。通过PPID,可以追踪进程的创建关系。进程名称:进程通常有一个名称,可以通过命令行工具(如ps、top)查看。虽然名称不是唯一的,但结合PID可以唯一标识一个进程。进程状态:进程在不同状态下(如运行、等待、停止等)可以被区分。状态信息可以通过系统调用或命令行工具查看。用户和组ID:进程运行在特定的用户和组上下文中,用户ID(UID)和组ID(GID)可以用来区分不同用户或组的进程。内存地址空间:每个进程都有独立的内存地址空间,包括代码段、数据段、堆、栈等。通过内存地址空间的隔离,系统可以区分不同的进程。文件描述符:每个进程都有一组文件描述符,用于管理打开的文件和设备。文件描述符的集合可以用来区分不同的进程。进程控制块(PCB):操作系统内核为每个进程维护一个进程控制块(PCB),包含进程的所有信息(如PID、状态、优先级、寄存器值等)。PCB是内核区分和管理进程的核心数据结构。通过这些方式,操作系统能够有效地管理和区分系统中的不同进程。
65.查看文件有哪些命令
在Linux和Unix系统中,有多种命令可以用来查看文件内容和属性。以下是一些常用的命令:cat:显示文件的全部内容。cat filenamemore:分页显示文件内容,适合查看长文件。more filenameless:与more类似,但功能更强大,支持向前和向后滚动。less filenamehead:显示文件的前几行(默认10行)。head filenametail:显示文件的最后几行(默认10行),常用于查看日志文件的更新。tail filenamenl:显示文件内容并添加行号。nl filenameod:以八进制或其他格式显示文件内容,用于查看二进制文件。od filenamefile:显示文件类型。file filenamestat:显示文件的详细状态信息。stat filenamels:列出目录内容,包括文件和子目录。ls -l filenamewc:统计文件的行数、字数和字节数。wc filenamegrep:搜索文件中包含特定模式的行。grep pattern filename这些命令提供了多种方式来查看文件的内容和属性,用户可以根据需要选择合适的命令。
66.如何修改文件的权限
简要概述如何修改文件权限:使用chmod命令:通过chmod命令修改文件权限。符号模式:用户类别:u(用户),g(组),o(其他),a(所有)
操作:+(添加),-(移除),=(设置)
权限:r(读),w(写),x(执行)
示例:chmod u+x file(给用户添加执行权限)
八进制模式:每位八进制数对应一组权限:4(读),2(写),1(执行)
组合这些值来表示权限:例如,7(4+2+1,即rwx)
示例:chmod 755 file(设置用户读、写、执行权限,组和其他用户读、执行权限)
通过这些方式,可以灵活地修改文件的权限。
67.什么是符号链接?
简要概述符号链接:定义:符号链接(Symbolic Link),又称软链接(Soft Link),是一种特殊类型的文件,指向另一个文件或目录。
特点:
指向性:可以指向文件或目录,跨文件系统。
独立性:有自己的inode和权限,不影响目标文件或目录。
透明性:访问时自动重定向到目标。
脆弱性:目标删除或移动后,链接失效。
创建:使用ln -s命令,语法为ln -s 目标文件或目录 符号链接文件。
符号链接类似于Windows中的快捷方式,用于方便地访问文件或目录
68.数据结构主要研究的是什么?
数据结构主要研究的是如何在计算机中组织和存储数据,以便高效地进行操作。具体来说,数据结构研究以下几个方面:数据组织:研究如何将数据元素按照一定的逻辑关系组织起来,形成一个数据集合。常见的数据组织方式包括线性结构(如数组、链表)、树形结构(如二叉树、B树)和图形结构(如图、网络)。数据存储:研究如何在计算机内存中存储数据,以便快速访问和操作。不同的数据结构有不同的存储方式,例如数组在内存中是连续存储的,而链表则是通过指针链接的。数据操作:研究如何对数据进行增、删、改、查等操作,以及这些操作的时间复杂度和空间复杂度。高效的数据操作是数据结构研究的核心内容之一。算法设计:数据结构与算法紧密相关,研究数据结构的同时,也需要设计相应的算法来操作这些数据结构。例如,针对不同的数据结构,设计排序、搜索、遍历等算法。性能分析:研究不同数据结构和算法的性能,包括时间复杂度(操作所需的时间)和空间复杂度(操作所需的内存空间),以便选择最适合特定应用场景的数据结构和算法。总之,数据结构主要研究数据的组织、存储、操作和性能分析,旨在提供高效的数据处理方法,以满足各种应用需求。
69.数组和链表的区别(逻辑结构、内存存储、访问方式三个方面辨析)
数组和链表是两种常见的数据结构,它们在逻辑结构、内存存储和访问方式上有显著的区别:逻辑结构
数组:数组的元素在逻辑上是连续的,每个元素有一个固定的位置(索引),可以通过索引直接访问任意元素。
链表:链表的元素在逻辑上通过指针(或引用)链接在一起,每个元素(节点)包含数据和指向下一个节点的指针。访问链表中的元素通常需要从头节点开始,逐个遍历。内存存储
数组:数组的元素在内存中是连续存储的,这使得数组可以通过基地址和元素大小快速计算出任意元素的内存地址。
链表:链表的元素在内存中可以是非连续存储的,每个节点通过指针链接。这种存储方式使得链表在插入和删除操作时更为灵活,但需要额外的内存空间来存储指针。访问方式
数组:数组支持随机访问,即可以通过索引直接访问任意位置的元素,时间复杂度为O(1)。
链表:链表支持顺序访问,访问某个元素需要从头节点开始逐个遍历,时间复杂度为O(n),其中n是链表的长度。总结
数组:逻辑上连续,内存中连续存储,支持随机访问。
链表:逻辑上通过指针链接,内存中可以非连续存储,支持顺序访问。数组和链表各有优缺点,选择哪种数据结构取决于具体的应用场景和操作需求。
70.快速排序的算法
快速排序(QuickSort)是一种高效的排序算法,采用分治法策略。其主要步骤包括:选择基准值:从数列中选择一个元素作为基准(pivot)。
分区操作:重新排列数列,将所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准后面。分区完成后,基准元素处于其最终位置。
递归排序:对基准左右两边的子数列递归地进行快速排序。快速排序的核心在于分区操作,通过选择合适的基准值和分区策略,可以实现高效的排序。
快速排序的平均时间复杂度为O(n log n),
但在最坏情况下(如每次选择的基准值都是最小或最大元素),时间复杂度为O(n^2)。#include <iostream>
#include <vector>// 分区函数
int partition(std::vector<int>& arr, int low, int high) {int pivot = arr[high]; // 选择最后一个元素作为基准int i = low - 1; // i是较小元素的索引for (int j = low; j < high; ++j) {if (arr[j] < pivot) {i++;std::swap(arr[i], arr[j]);}}std::swap(arr[i + 1], arr[high]);return i + 1;
}// 快速排序函数
void quicksort(std::vector<int>& arr, int low, int high) {if (low < high) {int pi = partition(arr, low, high);quicksort(arr, low, pi - 1); // 递归排序左子数列quicksort(arr, pi + 1, high); // 递归排序右子数列}
}int main() {std::vector<int> arr = {10, 7, 8, 9, 1, 5};int n = arr.size();quicksort(arr, 0, n - 1);std::cout << "Sorted array: ";for (int i : arr) {std::cout << i << " ";}std::cout << std::endl;return 0;
}71.hash查找的算法
哈希查找(Hash Search)是一种基于哈希表(Hash Table)的查找算法。哈希表是一种数据结构,通过哈希函数将键(Key)映射到表中的一个位置,从而实现快速的插入、删除和查找操作。哈希查找的核心在于哈希函数的设计和冲突解决方法。哈希查找的基本步骤
哈希函数:将键转换为哈希表中的索引。一个好的哈希函数应该尽可能均匀地分布键,减少冲突。
冲突解决:当两个或多个键映射到同一个位置时,需要解决冲突。常见的冲突解决方法有链地址法(Chaining)和开放地址法(Open Addressing)。
查找操作:根据键计算哈希值,找到对应的索引,然后在该位置查找目标元素。#include <iostream>
#include <vector>
#include <list>class HashTable {
private:int size;std::vector<std::list<std::pair<int, std::string>>> table;int hashFunction(int key) {return key % size;}public:HashTable(int s) : size(s) {table.resize(size);}void insert(int key, std::string value) {int hashIndex = hashFunction(key);for (auto& pair : table[hashIndex]) {if (pair.first == key) {pair.second = value;return;}}table[hashIndex].push_back(std::make_pair(key, value));}std::string search(int key) {int hashIndex = hashFunction(key);for (const auto& pair : table[hashIndex]) {if (pair.first == key) {return pair.second;}}throw std::out_of_range("Key not found");}void remove(int key) {int hashIndex = hashFunction(key);for (auto it = table[hashIndex].begin(); it != table[hashIndex].end(); ++it) {if (it->first == key) {table[hashIndex].erase(it);return;}}}
};int main() {HashTable ht(10);ht.insert(1, "Value1");ht.insert(11, "Value11");ht.insert(21, "Value21");try {std::cout << "Search 1: " << ht.search(1) << std::endl;std::cout << "Search 11: " << ht.search(11) << std::endl;std::cout << "Search 21: " << ht.search(21) << std::endl;std::cout << "Search 31: " << ht.search(31) << std::endl; // This will throw an exception} catch (const std::out_of_range& e) {std::cerr << "Exception: " << e.what() << std::endl;}ht.remove(11);try {std::cout << "Search 11 after removal: " << ht.search(11) << std::endl; // This will throw an exception} catch (const std::out_of_range& e) {std::cerr << "Exception: " << e.what() << std::endl;}return 0;
}72.判断单链表是否有环
判断单链表是否有环是一个经典的问题,常用的解决方法是使用快慢指针(Floyd's Tortoise and Hare Algorithm)。该算法通过两个指针以不同的速度遍历链表,如果链表中有环,快指针最终会追上慢指针。算法步骤
初始化两个指针,慢指针(tortoise)和快指针(hare),都指向链表的头节点。
慢指针每次移动一步,快指针每次移动两步。
如果链表中有环,快指针最终会追上慢指针,即两个指针会相遇。
如果快指针到达链表的末尾(即指向NULL),则链表中没有环。#include <iostream>// 定义链表节点结构
struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};// 判断链表是否有环的函数
bool hasCycle(ListNode *head) {if (head == NULL || head->next == NULL) {return false;}ListNode *slow = head;ListNode *fast = head->next;while (slow != fast) {if (fast == NULL || fast->next == NULL) {return false;}slow = slow->next;fast = fast->next->next;}return true;
}int main() {// 创建一个有环的链表ListNode *head = new ListNode(1);head->next = new ListNode(2);head->next->next = new ListNode(3);head->next->next->next = head->next; // 创建环if (hasCycle(head)) {std::cout << "链表中有环" << std::endl;} else {std::cout << "链表中没有环" << std::endl;}// 清理内存(注意:有环的链表会导致无限循环,这里不进行清理)return 0;
}73.判断一个括号字符串是否匹配正确,如果括号有多种,怎么做?如(([]))正确,[[(()错误
判断一个括号字符串是否匹配正确,可以使用栈(Stack)数据结构来实现。栈的特点是后进先出(LIFO),非常适合用于处理括号匹配问题。算法步骤
初始化一个空栈。
遍历字符串中的每一个字符:
如果是左括号(如(, [, {),将其压入栈中。
如果是右括号(如), ], }),检查栈是否为空:
如果栈为空,说明没有匹配的左括号,返回不匹配。
如果栈不为空,弹出栈顶元素,检查是否与当前右括号匹配。如果不匹配,返回不匹配。
遍历结束后,检查栈是否为空:
如果栈为空,说明所有括号都匹配正确,返回匹配。
如果栈不为空,说明有未匹配的左括号,返回不匹配。#include <iostream>
#include <stack>
#include <unordered_map>// 判断括号字符串是否匹配正确的函数
bool isValid(const std::string& s) {std::stack<char> stack;std::unordered_map<char, char> bracketMap = {{')', '('},{']', '['},{'}', '{'}};for (char ch : s) {if (bracketMap.find(ch) != bracketMap.end()) {// 当前字符是右括号if (stack.empty()) {return false;}char topElement = stack.top();stack.pop();if (topElement != bracketMap[ch]) {return false;}} else {// 当前字符是左括号stack.push(ch);}}return stack.empty();
}int main() {std::string s1 = "(([]))";std::string s2 = "[[(()]";if (isValid(s1)) {std::cout << s1 << " 是匹配的" << std::endl;} else {std::cout << s1 << " 是不匹配的" << std::endl;}if (isValid(s2)) {std::cout << s2 << " 是匹配的" << std::endl;} else {std::cout << s2 << " 是不匹配的" << std::endl;}return 0;
}74.简述系统调用?
系统调用(System Call)是操作系统提供给应用程序的一组接口,用于请求操作系统内核执行某些特权操作或访问受保护的资源。系统调用是应用程序与操作系统之间的桥梁,使得应用程序可以安全、高效地使用底层硬件和操作系统服务。系统调用的主要功能
进程控制:创建和终止进程,获取和设置进程属性,等待事件,信号处理等。
文件管理:创建、打开、关闭、读取、写入文件,获取和设置文件属性等。
设备管理:请求和释放设备,读取和写入设备,获取和设置设备属性等。
内存管理:分配和释放内存,映射文件到内存,获取和设置内存属性等。
进程间通信:管道、消息队列、信号量、共享内存等。
网络通信:套接字(Socket)接口,用于网络通信。系统调用的执行过程
用户态到内核态的切换:应用程序通过特定的指令(如x86架构的int 0x80或syscall指令)发起系统调用,导致CPU从用户态切换到内核态。
系统调用号:每个系统调用都有一个唯一的编号(系统调用号),用于标识具体的系统调用。
参数传递:系统调用的参数通常通过寄存器传递给内核。
内核处理:内核根据系统调用号和参数执行相应的操作,如访问硬件、修改内核数据结构等。
返回结果:内核将系统调用的结果返回给应用程序,并从内核态切换回用户态。
75.如何将程序执行直接运行于后台?
1. 使用 & 符号
在命令行中,可以在命令末尾添加 & 符号,使程序在后台运行。command &
例如:
./my_program &2. 使用 nohup 命令
nohup 命令可以使程序在后台运行,并且忽略挂起信号(SIGHUP),即使终端关闭,程序也会继续运行。nohup command &例如:
nohup ./my_program &
(还可补充)
76.进程的状态
进程是操作系统中运行的程序的实例,它们在执行过程中会经历不同的状态。常见的进程状态包括:1. 新建(New)
进程刚刚被创建,但还未被操作系统调度执行。2. 就绪(Ready)
进程已经准备好运行,等待操作系统分配CPU时间片。3. 运行(Running)
进程正在CPU上执行。4. 阻塞(Blocked)
进程由于等待某些事件(如I/O操作完成、信号量可用等)而暂停执行,即使CPU空闲,该进程也不会被调度。5. 挂起(Suspended)
进程被暂时移出内存,通常是因为内存不足或管理员干预。挂起的进程不占用CPU资源,直到被重新调入内存。6. 终止(Terminated)
进程执行完毕或被操作系统终止。新建|v就绪 <-----> 运行 <-----> 阻塞| | |v v v挂起 挂起 挂起| | |v v v终止 终止 终止77.简述创建子进程中的写时拷贝技术?
写时拷贝(Copy-On-Write,简称COW)是一种优化技术,主要用于在创建子进程时减少内存开销。传统的进程创建方式会为子进程复制父进程的整个地址空间,这会导致大量的内存复制操作。写时拷贝技术通过延迟复制,只在需要修改数据时才进行实际的内存复制,从而提高效率。写时拷贝的工作原理
初始共享:当创建子进程时,操作系统并不立即复制父进程的地址空间,而是让父进程和子进程共享同一份物理内存。
写时复制:当任何一个进程(父进程或子进程)尝试修改共享内存中的数据时,操作系统会检测到这一操作,并为该进程分配新的物理内存页,然后将修改前的数据复制到新的内存页中,再进行修改。
独立内存:经过写时复制后,父进程和子进程的内存页变得独立,各自拥有自己的副本,互不干扰。优点
减少内存开销:在创建子进程时,不需要立即复制整个地址空间,节省了大量内存。
提高效率:只有在实际需要修改数据时才进行复制,减少了不必要的内存复制操作,提高了系统性能。
78.线程池的使用?
线程池(Thread Pool)是一种并发编程技术,用于管理和复用线程,以提高程序的性能和资源利用率。
线程池通过预先创建一组线程,并将任务分配给这些线程来执行,从而避免了频繁创建和销毁线程的开销。线程池的主要优点
减少线程创建和销毁的开销:线程池中的线程是预先创建的,任务执行完毕后不会立即销毁,而是返回到线程池中等待下一个任务。
提高响应速度:任务可以立即分配给线程池中的空闲线程执行,无需等待新线程的创建。
控制并发数量:线程池可以限制同时运行的线程数量,避免系统资源被过度消耗。线程池的基本组成
任务队列:用于存储待执行的任务。
工作线程:线程池中预先创建的线程,负责从任务队列中取出任务并执行。
任务提交接口:用于向线程池提交任务。
线程池管理器:负责线程池的初始化、任务分配、线程管理等。线程池的使用步骤
创建线程池:初始化线程池,指定线程池的大小(即工作线程的数量)。
提交任务:将任务提交给线程池,线程池会自动分配给空闲的工作线程执行。
执行任务:工作线程从任务队列中取出任务并执行。
关闭线程池:任务执行完毕后,关闭线程池,释放资源。
79.简述互斥锁的实现原理?
互斥锁(Mutex,全称Mutual Exclusion)是一种同步机制,用于确保在多线程环境中,同一时间只有一个线程可以访问共享资源。互斥锁的实现原理主要基于操作系统的内核支持和原子操作。互斥锁的基本原理
锁定(Lock):当一个线程尝试锁定互斥锁时,如果锁是可用的(即未被其他线程持有),该线程将成功获得锁,并可以访问共享资源。如果锁已被其他线程持有,尝试锁定的线程将被阻塞,直到锁变为可用。
解锁(Unlock):持有锁的线程在访问完共享资源后,必须释放锁,使其他线程可以获得锁并访问共享资源。互斥锁的实现细节
原子操作:互斥锁的核心是原子操作,确保锁的状态在多线程环境中不会出现竞态条件。原子操作通常由硬件支持,确保操作在执行过程中不会被中断。
内核支持:操作系统内核提供互斥锁的实现,包括锁的创建、销毁、锁定和解锁等操作。内核通过调度机制管理线程的阻塞和唤醒。
等待队列:当多个线程尝试锁定同一个互斥锁时,内核会维护一个等待队列,按顺序阻塞这些线程。当锁被释放时,内核会从等待队列中选择一个线程唤醒,使其获得锁。互斥锁的状态
可用(Unlocked):锁未被任何线程持有,可以被任意线程锁定。
锁定(Locked):锁被某个线程持有,其他线程尝试锁定时将被阻塞。
80.简述死锁的情景?
死锁(Deadlock)是指在多线程或多进程系统中,两个或多个线程(或进程)互相持有对方所需的资源,并且都在等待对方释放资源,从而导致所有涉及的线程(或进程)都无法继续执行的状态。死锁是一种常见的并发问题,可能导致系统停滞。死锁的四个必要条件
互斥条件(Mutual Exclusion):资源不能被多个线程(或进程)同时访问,必须独占使用。
占有并等待(Hold and Wait):线程(或进程)已经持有一个或多个资源,并且正在等待获取其他线程(或进程)持有的资源。
不可抢占(No Preemption):资源不能被强制抢占,只能由持有资源的线程(或进程)主动释放。
循环等待(Circular Wait):存在一组线程(或进程),形成一个循环链,每个线程(或进程)都在等待下一个线程(或进程)持有的资源。死锁的典型情景
资源分配图:如果资源分配图中存在环路,则可能发生死锁。环路表示一组线程(或进程)和资源之间的循环依赖关系。
银行家算法:银行家算法是一种避免死锁的算法,通过预先检查资源分配状态,确保系统不会进入不安全状态(即可能发生死锁的状态)。死锁的解决方法
预防死锁:通过破坏死锁的四个必要条件之一来预防死锁的发生。例如,可以通过资源分级、一次性请求所有资源、资源抢占等方式来预防死锁。
避免死锁:在运行时动态检查资源分配状态,确保系统始终处于安全状态。银行家算法是一种典型的避免死锁的方法。
检测和恢复死锁:定期检测系统中是否存在死锁,一旦检测到死锁,采取措施恢复系统,如终止某些线程(或进程)、回滚事务等。
81.简述信号量的原理?
信号量(Semaphore)是一种用于多线程或多进程环境中同步和互斥的机制。信号量通过一个整数值来控制对共享资源的访问,可以用于实现线程间的同步和资源管理。信号量的原理基于计数器和等待队列。信号量的基本原理
计数器:信号量维护一个整数计数器,表示可用资源的数量。计数器的初始值可以设置为资源的初始数量。
P操作(等待操作,Proberen):线程尝试获取资源时,执行P操作。如果计数器大于零,表示有可用资源,线程可以继续执行,并将计数器减一。如果计数器为零,表示没有可用资源,线程将被阻塞,进入等待队列。
V操作(信号操作,Verhogen):线程释放资源时,执行V操作。计数器加一,并唤醒等待队列中的一个线程,使其可以继续执行。信号量的类型
二进制信号量(Binary Semaphore):计数器的值只能为0或1,类似于互斥锁,但信号量可以被任意线程释放。
计数信号量(Counting Semaphore):计数器的值可以是任意非负整数,用于控制多个资源的访问。信号量的实现细节
原子操作:信号量的P操作和V操作必须是原子操作,确保在多线程环境中的正确性。原子操作通常由硬件支持,确保操作在执行过程中不会被中断。
等待队列:信号量维护一个等待队列,用于存储被阻塞的线程。当计数器为零时,尝试获取资源的线程将被加入等待队列。当计数器增加时,信号量会从等待队列中唤醒一个线程。
82.管道的通信原理?
管道(Pipe)是一种用于进程间通信(Inter-Process Communication, IPC)的机制。管道允许一个进程将其输出直接连接到另一个进程的输入,从而实现数据的单向或双向传输。管道的通信原理基于操作系统的内核支持,通过创建一个共享的内存缓冲区来传递数据。管道的基本原理
创建管道:操作系统在内核中创建一个共享的内存缓冲区,用于存储数据。管道有两个端点:读端和写端。数据传输:写进程将数据写入管道的写端,数据被存储在共享的内存缓冲区中。读进程从管道的读端读取数据,数据从共享的内存缓冲区中取出。阻塞和非阻塞操作:如果管道的缓冲区已满,写进程将被阻塞,直到有空间可用。如果管道的缓冲区为空,读进程将被阻塞,直到有数据可用。关闭管道:当进程不再需要使用管道时,可以关闭管道的读端或写端。当所有读端和写端都关闭时,管道将被销毁。管道的类型
匿名管道(Anonymous Pipe):通常用于父子进程之间的通信,通过pipe系统调用创建。匿名管道是单向的,只能用于具有亲缘关系的进程之间。
命名管道(Named Pipe):也称为FIFO(First In, First Out),通过mkfifo系统调用创建。命名管道是双向的,可以用于任意进程之间的通信。
83.用户进程对信号的响应方式?
在Unix和类Unix操作系统中,信号(Signal)是一种用于进程间通信的机制,用于通知进程发生了某个事件。用户进程可以通过多种方式响应信号,具体取决于信号的处理方式。信号的响应方式
默认处理(Default Action):每个信号都有一个默认的处理方式,由操作系统定义。常见的默认处理方式包括终止进程、忽略信号、暂停进程、继续进程等。
忽略信号(Ignore Signal):进程可以选择忽略某个信号,即不对该信号做出任何响应。通过调用signal或sigaction函数,并将处理函数设置为SIG_IGN,可以忽略信号。
捕获信号(Catch Signal):进程可以捕获信号,并执行自定义的处理函数。通过调用signal或sigaction函数,并将处理函数设置为自定义函数,可以捕获信号并执行相应的处理逻辑。常见的信号及其默认处理方式
SIGINT:中断信号,通常由用户按下Ctrl+C产生。默认处理方式是终止进程。
SIGTERM:终止信号,通常由kill命令产生。默认处理方式是终止进程。
SIGKILL:强制终止信号,无法被捕获或忽略。默认处理方式是终止进程。
SIGSTOP:暂停信号,无法被捕获或忽略。默认处理方式是暂停进程。
SIGCONT:继续信号,默认处理方式是继续执行暂停的进程。
SIGUSR1 和 SIGUSR2:用户定义的信号,默认处理方式是终止进程。
84.ISO七层网络通信结构,每层的主要作用,主要的协议
ISO七层网络通信结构,也称为OSI(Open Systems Interconnection)模型,是一个概念性的框架,
用于描述网络通信中各个层次的功能和协议。每一层都有特定的作用和相关的协议。以下是各层的主要作用和主要的协议:1. 物理层(Physical Layer)
主要作用:负责传输原始比特流,处理电压、物理介质、数据速率等物理特性。
主要协议:RS-232、Ethernet(IEEE 802.3)、USB、Bluetooth、Wi-Fi(IEEE 802.11)。
2. 数据链路层(Data Link Layer)
主要作用:将原始比特流组织成数据帧,提供节点到节点的传输,进行错误检测和纠正。
主要协议:Ethernet(IEEE 802.3)、PPP(Point-to-Point Protocol)、HDLC(High-Level Data Link Control)、ARP(Address Resolution Protocol)。
3. 网络层(Network Layer)
主要作用:负责数据包的路由和转发,实现端到端的传输,处理逻辑地址(如IP地址)。
主要协议:IP(Internet Protocol)、ICMP(Internet Control Message Protocol)、OSPF(Open Shortest Path First)、BGP(Border Gateway Protocol)。
4. 传输层(Transport Layer)
主要作用:提供端到端的可靠数据传输服务,进行流量控制和错误恢复。
主要协议:TCP(Transmission Control Protocol)、UDP(User Datagram Protocol)、SCTP(Stream Control Transmission Protocol)。
5. 会话层(Session Layer)
主要作用:建立、管理和终止会话(通信连接),进行会话控制和同步。
主要协议:NetBIOS、RPC(Remote Procedure Call)、SSH(Secure Shell)。
6. 表示层(Presentation Layer)
主要作用:处理数据格式转换、加密、压缩等,确保数据在不同系统之间的正确解释。
主要协议:SSL/TLS(Secure Sockets Layer/Transport Layer Security)、MIME(Multipurpose Internet Mail Extensions)、ASCII、JPEG、MPEG。
7. 应用层(Application Layer)
主要作用:提供网络服务和应用程序之间的接口,直接与用户交互。
主要协议:HTTP(Hypertext Transfer Protocol)、FTP(File Transfer Protocol)、SMTP(Simple Mail Transfer Protocol)、DNS(Domain Name System)、DHCP(Dynamic Host Configuration Protocol)。
85.TCP/IP四层网络通信结构
TCP/IP(Transmission Control Protocol/Internet Protocol)是互联网的核心协议套件,它定义了数据如何在网络中传输和路由。TCP/IP模型是一个四层结构,与OSI模型的七层结构有所不同。以下是TCP/IP四层模型的详细介绍:1. 网络接口层(Network Interface Layer)
主要作用:负责将数据帧发送到物理网络或从物理网络接收数据帧。这一层对应OSI模型的物理层和数据链路层。
主要协议:Ethernet(IEEE 802.3)、Wi-Fi(IEEE 802.11)、PPP(Point-to-Point Protocol)、ARP(Address Resolution Protocol)。
2. 互联网层(Internet Layer)
主要作用:负责数据包的路由和转发,实现端到端的传输,处理逻辑地址(如IP地址)。这一层对应OSI模型的网络层。
主要协议:IP(Internet Protocol,包括IPv4和IPv6)、ICMP(Internet Control Message Protocol)、IGMP(Internet Group Management Protocol)、OSPF(Open Shortest Path First)、BGP(Border Gateway Protocol)。
3. 传输层(Transport Layer)
主要作用:提供端到端的可靠数据传输服务,进行流量控制和错误恢复。这一层对应OSI模型的传输层。
主要协议:TCP(Transmission Control Protocol)、UDP(User Datagram Protocol)、SCTP(Stream Control Transmission Protocol)。
4. 应用层(Application Layer)
主要作用:提供网络服务和应用程序之间的接口,直接与用户交互。这一层对应OSI模型的会话层、表示层和应用层。
主要协议:HTTP(Hypertext Transfer Protocol)、FTP(File Transfer Protocol)、SMTP(Simple Mail Transfer Protocol)、DNS(Domain Name System)、DHCP(Dynamic Host Configuration Protocol)、SNMP(Simple Network Management Protocol)、SSH(Secure Shell)、SSL/TLS(Secure Sockets Layer/Transport Layer Security)
86.io模型有哪几种
I/O(输入/输出)模型是指计算机系统中用于处理输入和输出操作的机制。不同的I/O模型在处理数据传输和同步方式上有所不同。以下是几种常见的I/O模型:1. 阻塞I/O(Blocking I/O)
原理:当进程调用I/O操作时,如果数据未准备好,进程会被阻塞,直到数据准备好并完成I/O操作后才继续执行。
优点:简单易用,适合简单的应用场景。
缺点:效率低,不适合高并发场景。
2. 非阻塞I/O(Non-blocking I/O)
原理:当进程调用I/O操作时,如果数据未准备好,进程不会被阻塞,而是立即返回一个错误码。进程需要不断轮询检查数据是否准备好。
优点:避免了进程被长时间阻塞,提高了并发处理能力。
缺点:需要频繁轮询,浪费CPU资源。
3. I/O多路复用(I/O Multiplexing)
原理:使用select、poll、epoll等系统调用,进程可以同时监听多个I/O事件。当某个I/O事件就绪时,进程会被通知并进行处理。
优点:高效处理多个I/O事件,适合高并发场景。
缺点:编程复杂度较高。
4. 信号驱动I/O(Signal-driven I/O)
原理:进程注册一个信号处理函数,当I/O事件就绪时,内核发送一个信号通知进程。进程在信号处理函数中进行I/O操作。
优点:避免了轮询,提高了效率。
缺点:信号处理函数的执行时间较短,不适合复杂操作。
5. 异步I/O(Asynchronous I/O)
原理:进程发起I/O操作后,立即返回,不等待I/O操作完成。I/O操作完成后,内核通知进程。
优点:真正实现了异步处理,提高了并发性能。
缺点:编程复杂度高,操作系统支持有限。
87.如何实现并发服务器,并发服务器的实现方式以及有什么异同
并发服务器是指能够同时处理多个客户端请求的服务器。实现并发服务器的方式有多种,主要包括多进程、多线程、I/O多路复用和异步I/O等。以下是这些实现方式的详细介绍及其异同点:1. 多进程(Multi-process)
实现方式:服务器主进程接受客户端连接,并为每个连接创建一个子进程来处理请求。
优点:进程之间相互独立,稳定性高,适合处理计算密集型任务。
缺点:进程创建和销毁开销大,资源消耗多,不适合高并发场景。2. 多线程(Multi-thread)
实现方式:服务器主线程接受客户端连接,并为每个连接创建一个子线程来处理请求。
优点:线程创建和销毁开销小,资源消耗少,适合处理I/O密集型任务。
缺点:线程之间共享内存,需要考虑同步和互斥问题,容易引发竞态条件。3. I/O多路复用(I/O Multiplexing)
实现方式:使用select、poll、epoll等系统调用,服务器可以同时监听多个I/O事件。当某个I/O事件就绪时,服务器进行处理。
优点:单线程或单进程即可处理多个连接,资源消耗少,适合高并发场景。
缺点:编程复杂度较高,需要处理事件驱动的逻辑。4. 异步I/O(Asynchronous I/O)
实现方式:服务器发起I/O操作后,立即返回,不等待I/O操作完成。I/O操作完成后,内核通知服务器进行处理。
优点:真正实现了异步处理,提高了并发性能,适合高并发场景。
缺点:编程复杂度高,操作系统支持有限。异同点资源消耗:多进程消耗资源最多,多线程次之,I/O多路复用和异步I/O消耗资源最少。
编程复杂度:多进程和多线程相对简单,I/O多路复用和异步I/O编程复杂度较高。
并发处理能力:I/O多路复用和异步I/O的并发处理能力最强,多进程和多线程次之。
适用场景:多进程适合计算密集型任务,多线程适合I/O密集型任务,I/O多路复用和异步I/O适合高并发场景。
88.网络超时检测的本质和实现方式
网络超时检测的本质是在网络通信中设置一个合理的时间阈值,如果在该时间内没有收到预期的响应或完成预期的操作,则认为发生了超时事件。超时检测的目的是确保网络通信的可靠性和效率,避免因长时间等待响应而导致的资源浪费和性能下降。实现方式
网络超时检测可以通过多种方式实现,以下是几种常见的实现方式:1. 定时器(Timer)
原理:在发起网络请求时启动一个定时器,如果在定时器到期前没有收到响应,则认为发生了超时。
实现:可以使用操作系统的定时器机制(如alarm、setitimer)或编程语言提供的定时器功能(如setTimeout、Timer)。
2. 超时参数(Timeout Parameter)
原理:在网络协议或API调用中设置超时参数,指定等待响应的最大时间。如果在该时间内没有收到响应,则认为发生了超时。
实现:例如,在HTTP请求中设置timeout参数,或在数据库连接中设置connectTimeout和readTimeout。
3. 心跳检测(Heartbeat Detection)
原理:在长连接或持续通信中,定期发送心跳包(Heartbeat Packet),如果在一定时间内没有收到对方的心跳响应,则认为连接超时。
实现:例如,在WebSocket连接中定期发送PING帧,或在TCP连接中定期发送心跳包。
4. 重传机制(Retransmission Mechanism)
原理:在网络协议中设置重传机制,如果在一定时间内没有收到确认(ACK),则重新发送数据包。通过重传次数和重传间隔来间接实现超时检测。
实现:例如,在TCP协议中,如果发送的数据包在一定时间内没有收到ACK,则会触发重传。
89.udp本地通信需要注意哪些方面
UDP(User Datagram Protocol)是一种无连接的、不可靠的传输层协议,
适用于对传输速度要求高、对数据可靠性要求相对较低的应用场景。
在使用UDP进行本地通信时,需要注意以下几个方面:1. 端口选择
选择未被占用的端口:确保选择的本地端口未被其他应用程序占用,避免端口冲突。
使用知名端口:对于特定应用,可以使用知名的端口号(如DNS使用53端口),但需要注意权限问题(知名端口通常需要管理员权限)。
2. 数据包大小
避免IP分片:UDP数据包的大小应小于网络的最大传输单元(MTU),避免IP分片。通常建议UDP数据包大小不超过1472字节(以太网MTU为1500字节,减去20字节的IP头和8字节的UDP头)。
考虑应用需求:根据应用需求合理设置数据包大小,避免过大或过小的数据包影响传输效率。
3. 错误检测
校验和:UDP头部包含16位的校验和字段,用于检测数据包在传输过程中是否发生错误。虽然UDP校验和是可选的,但建议启用以提高数据可靠性。
应用层校验:在应用层进行额外的错误检测和纠正,如使用CRC(循环冗余校验)等。
4. 流量控制和拥塞控制
应用层实现:UDP不提供内置的流量控制和拥塞控制机制,需要在应用层实现相应的控制策略,避免网络拥塞和数据丢失。
5. 安全性
数据加密:对于敏感数据,建议在应用层进行加密,确保数据在传输过程中的安全性。
访问控制:限制UDP通信的源地址和端口,避免未授权访问。
6. 超时重传
应用层实现:UDP不提供超时重传机制,需要在应用层实现超时检测和重传策略,确保数据的可靠传输。
90.怎么修改文件描述符的标志位
文件描述符的标志位(File Descriptor Flags)用于控制文件描述符的行为。在Unix和类Unix系统中,可以使用fcntl系统调用来修改文件描述符的标志位。fcntl函数提供了丰富的控制功能,包括设置文件描述符的标志位。修改文件描述符标志位的步骤
打开文件:使用open系统调用打开文件,获取文件描述符。
获取当前标志位:使用fcntl函数获取文件描述符的当前标志位。
修改标志位:根据需要修改标志位。
设置新的标志位:使用fcntl函数设置新的标志位。常用的文件描述符标志位
O_APPEND:追加模式,每次写操作前将文件指针移动到文件末尾。
O_NONBLOCK:非阻塞模式,读写操作不会阻塞。
O_ASYNC:异步I/O,当文件描述符可读或可写时,发送信号通知进程。91.TCP和UDP的区别
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是互联网协议族中的两个重要传输层协议,
它们在数据传输方式、可靠性、连接状态等方面有显著的区别。以下是TCP和UDP的主要区别:1. 连接状态
TCP:面向连接的协议,传输数据前需要建立连接(三次握手),传输完成后需要释放连接(四次挥手)。
UDP:无连接的协议,传输数据前不需要建立连接,每个数据包都是独立的。
2. 可靠性
TCP:提供可靠的数据传输服务,确保数据按顺序、无丢失、无重复地到达目的地。通过确认机制、重传机制、流量控制和拥塞控制等机制实现可靠性。
UDP:提供不可靠的数据传输服务,不保证数据包的顺序、不重传丢失的数据包、不进行流量控制和拥塞控制。
3. 传输效率
TCP:由于需要建立连接、维护连接状态、进行复杂的错误检测和恢复机制,传输效率相对较低。
UDP:由于没有连接建立和维护的开销,传输效率较高,适合对实时性要求高的应用。
4. 数据包大小
TCP:没有数据包大小的限制,数据以字节流的形式传输。
UDP:每个数据包(数据报)有大小限制,通常不超过65507字节(以太网MTU为1500字节,减去20字节的IP头和8字节的UDP头)。
5. 头部开销
TCP:头部开销较大,通常为20字节,加上可选字段最多可达60字节。
UDP:头部开销较小,固定为8字节。
6. 适用场景
TCP:适用于对数据可靠性要求高的应用,如文件传输、电子邮件、网页浏览等。
UDP:适用于对实时性要求高、对数据可靠性要求相对较低的应用,如视频流、在线游戏、VoIP(Voice over IP)等。
92.TCP的三次握手和四次挥手分别作用,主要做什么
TCP(Transmission Control Protocol)是一种面向连接的、可靠的传输层协议。为了确保数据传输的可靠性和连接的建立与释放,TCP使用了三次握手(Three-way Handshake)和四次挥手(Four-way Handshake)机制。三次握手(Three-way Handshake)
三次握手用于在客户端和服务器之间建立连接。其主要作用是确保双方都准备好进行数据传输,并且同步初始序列号(ISN)。具体步骤
SYN(Synchronize Sequence Number):客户端向服务器发送一个SYN包,请求建立连接,并包含一个初始序列号(ISN)。
SYN-ACK(Synchronize-Acknowledge):服务器收到SYN包后,向客户端发送一个SYN-ACK包,确认收到客户端的请求,并包含服务器自己的初始序列号(ISN)。
ACK(Acknowledge):客户端收到SYN-ACK包后,向服务器发送一个ACK包,确认收到服务器的响应,并进入连接建立状态。主要作用
同步序列号:双方通过交换初始序列号,确保数据传输的顺序和可靠性。
确认双方准备就绪:通过三次握手,双方确认对方已经准备好进行数据传输。四次挥手(Four-way Handshake)
四次挥手用于在客户端和服务器之间释放连接。其主要作用是确保双方都完成数据传输,并安全地关闭连接。具体步骤
FIN(Finish):主动关闭方(通常是客户端)向被动关闭方(通常是服务器)发送一个FIN包,请求关闭连接。
ACK(Acknowledge):被动关闭方收到FIN包后,向主动关闭方发送一个ACK包,确认收到关闭请求,并进入半关闭状态(被动关闭方仍然可以发送数据)。
FIN(Finish):被动关闭方完成数据传输后,向主动关闭方发送一个FIN包,请求关闭连接。
ACK(Acknowledge):主动关闭方收到FIN包后,向被动关闭方发送一个ACK包,确认收到关闭请求,并进入TIME_WAIT状态。经过一段时间后,连接完全关闭。主要作用
确保数据传输完成:通过四次挥手,双方确认对方已经完成数据传输。
安全关闭连接:确保双方都同意关闭连接,避免数据丢失或重复传输。三次握手
Client Server| ||---- SYN(ISN) ---->|| ||<--- SYN-ACK(ISN+1) || ||---- ACK(ISN+1) --->|| |四次挥手Client Server| ||---- FIN --------->|| ||<--- ACK || || ||<--- FIN || ||---- ACK --------->|| |93.new、delete、malloc、free关系
new、delete、malloc和free是C++和C语言中用于动态内存管理的函数和操作符。它们之间的关系和区别如下:malloc 和 free
malloc:是C语言中的一个标准库函数,用于在堆上分配指定字节数的内存,并返回指向该内存块的指针。malloc不会初始化内存,返回的指针类型为void*,需要显式转换为合适的类型。
free:是C语言中的一个标准库函数,用于释放由malloc、calloc或realloc分配的内存。释放后,内存块可以被系统重新分配。new 和 delete
new:是C++中的一个操作符,用于在堆上分配内存,并调用对象的构造函数进行初始化。new返回指向分配内存的指针,类型为对象类型。
delete:是C++中的一个操作符,用于释放由new分配的内存,并调用对象的析构函数进行清理。delete确保对象的析构函数被正确调用,避免内存泄漏和资源泄漏。关系和区别内存分配和初始化:
malloc只分配内存,不进行初始化。
new不仅分配内存,还调用对象的构造函数进行初始化内存释放和清理:
free只释放内存,不进行任何清理。
delete不仅释放内存,还调用对象的析构函数进行清理。类型安全:
malloc返回void*指针,需要显式转换为合适的类型,不进行类型检查。
new返回特定类型的指针,进行类型检查,确保类型安全。错误处理:
malloc在内存分配失败时返回NULL。
new在内存分配失败时抛出std::bad_alloc异常。使用场景:
malloc和free主要用于C语言和需要与C语言兼容的C++代码。
new和delete主要用于C++代码,提供更高级的内存管理功能,包括构造函数和析构函数的调用。
94.delete与delete[]区别
在C++中,delete和delete[]是用于释放动态分配内存的操作符,但它们有不同的用途和行为。以下是它们的区别:delete用途:用于释放由new操作符分配的单个对象的内存。行为:调用单个对象的析构函数,并释放该对象占用的内存。
delete[]用途:用于释放由new[]操作符分配的数组内存。行为:调用数组中每个对象的析构函数,并释放整个数组占用的内存。区别析构函数调用:delete只调用单个对象的析构函数。delete[]调用数组中每个对象的析构函数。
内存释放:delete只释放单个对象占用的内存。delete[]释放整个数组占用的内存。
95.C++有哪些性质(面向对象特点)
C++是一种多范式编程语言,支持面向对象编程(OOP)、泛型编程和过程式编程。C++的面向对象特点主要包括以下几个方面:1. 封装(Encapsulation)
定义:将数据(属性)和操作数据的方法(行为)绑定在一起,形成一个类(Class),并通过访问控制符(如public、private、protected)隐藏内部实现细节,只暴露必要的接口。
优点:提高代码的可维护性和可重用性,减少外部对内部数据的直接访问,增强安全性。
2. 继承(Inheritance)
定义:允许一个类(派生类)继承另一个类(基类)的属性和方法,从而实现代码的复用和扩展。
优点:减少代码冗余,提高代码的可扩展性和可维护性。
类型:单继承、多继承(C++支持,但需谨慎使用)、多层继承。
3. 多态(Polymorphism)
定义:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。多态性分为编译时多态(静态多态,如函数重载和运算符重载)和运行时多态(动态多态,如虚函数)。
优点:提高代码的灵活性和可扩展性,使代码更易于维护和扩展。
实现:通过虚函数(Virtual Function)和抽象类(Abstract Class)实现运行时多态。
4. 抽象(Abstraction)
定义:将复杂的事物简单化,隐藏不必要的细节,只关注关键的属性和行为。抽象可以通过类和接口(纯虚函数)来实现。
优点:提高代码的可读性和可维护性,使设计更加清晰和模块化。
5. 构造函数和析构函数
构造函数:用于初始化对象,在对象创建时自动调用。
析构函数:用于清理对象,在对象销毁时自动调用。
6. 友元(Friend)
定义:允许特定的函数或类访问另一个类的私有成员。
优点:在某些情况下,提供了一种灵活的访问控制机制。
7. 运算符重载(Operator Overloading)
定义:允许用户定义的类型(如类)重新定义或重载运算符的行为。
优点:使自定义类型的操作更加直观和符合习惯。
96.子类析构时要调用父类的析构函数吗?
在C++中,子类的析构函数在执行时会自动调用父类的析构函数。
这是C++语言的特性,确保在子类对象销毁时,父类的资源也能被正确释放。析构函数的调用顺序
1.子类析构函数:首先调用子类的析构函数,清理子类特有的资源。
2.父类析构函数:然后自动调用父类的析构函数,清理父类的资源。
97.多态,虚函数,纯虚函数
多态(Polymorphism)、虚函数(Virtual Function)和纯虚函数(Pure Virtual Function)是C++中面向对象编程的三个重要概念,它们共同支持运行时多态性,使得代码更加灵活和可扩展。多态(Polymorphism)
定义:多态是指同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。多态性分为编译时多态(静态多态)和运行时多态(动态多态)。
静态多态:通过函数重载(Function Overloading)和运算符重载(Operator Overloading)实现,在编译时确定。
动态多态:通过虚函数(Virtual Function)实现,在运行时确定。虚函数(Virtual Function)
定义:虚函数是在基类中使用virtual关键字声明的函数,允许在派生类中重写(Override)。通过基类指针或引用调用虚函数时,实际调用的是派生类中的重写版本,从而实现运行时多态。
特点:
虚函数在基类中声明,可以在派生类中重写。
通过基类指针或引用调用虚函数时,实际调用的是派生类中的版本。
虚函数在基类中必须有定义,即使派生类不重写它。纯虚函数(Pure Virtual Function)
定义:纯虚函数是在基类中声明的虚函数,但没有实现,通过在函数声明后加上= 0来表示。包含纯虚函数的类称为抽象类(Abstract Class),不能直接实例化,只能用作基类。
特点:
纯虚函数在基类中没有实现,必须在派生类中重写。
包含纯虚函数的类是抽象类,不能直接实例化。
纯虚函数提供了一个接口规范,强制派生类实现该函数。
98.什么是“引用”?申明和使用“引用”要注意哪些问题?
引用(Reference)是C++中的一种别名机制,用于提供对现有变量的直接访问。
引用在声明时必须初始化,且一旦初始化后不能重新绑定到其他变量。使用引用时需要注意以下几点:
初始化:引用必须在声明时初始化。
不能为空:引用不能为空,必须始终指向有效的对象或函数。
不能重新绑定:引用一旦初始化后,不能指向其他变量。
常量引用:常量引用可以绑定到临时对象或常量,但不能通过常量引用修改原始对象的值。
函数参数和返回值:引用常用作函数参数和返回值,以避免拷贝开销,并提供更好的接口。99.将“引用”作为函数参数有哪些特点?
1. 避免拷贝开销
特点:引用作为函数参数时,不会创建参数的副本,而是直接操作原始对象。这对于大型对象或复杂结构尤其重要,因为拷贝这些对象可能会带来显著的性能开销。
2. 提供更好的接口
特点:引用参数使得函数调用更加直观,调用者可以清晰地看到参数可能会被修改。这增强了代码的可读性和可维护性,因为调用者可以立即知道哪些参数可能会在函数内部被改变。
3. 支持修改原始对象
特点:通过引用参数,函数可以直接修改调用者传入的原始对象,而不需要返回值。这使得函数能够以更自然的方式影响调用者的状态,而不需要复杂的返回值处理。
4. 常量引用用于保护原始对象
特点:使用常量引用(const &)可以避免修改原始对象,同时避免拷贝开销。这对于只需要读取而不需要修改参数的函数特别有用,因为它既保证了参数的安全性,又提高了性能。
5. 支持多态
特点:通过基类引用,可以实现运行时多态,调用派生类的重写方法。这使得函数能够处理不同类型的对象,只要这些对象继承自同一个基类并且重写了相关的方法。
100.在什么时候需要使用“常引用”?
1. 避免拷贝开销
场景:当函数需要传递大型对象或复杂结构时,为了避免拷贝开销,可以使用常引用。
原因:常引用不会创建参数的副本,直接操作原始对象,从而提高性能。
2. 保护原始对象不被修改
场景:当函数只需要读取参数的值而不需要修改它时,使用常引用可以防止意外修改。
原因:常引用确保函数内部不能修改参数,增强了代码的安全性和可维护性。
3. 传递临时对象
场景:当函数需要接受临时对象(如字面量或表达式结果)作为参数时,常引用是唯一的选择。
原因:临时对象不能绑定到非常量引用,但可以绑定到常量引用。
4. 支持多态
场景:当函数需要通过基类引用实现运行时多态时,常引用可以确保基类对象不被修改。
原因:常引用结合虚函数可以实现安全的运行时多态,同时保护基类对象不被修改。
相关文章:

100道C/C++面试题
1. static的作用2. 引用与指针的区别3. .h头文件中的ifndef/define/endif 的作用4 #include<file.h>与#include"file.h"的区别?5 描述实时系统的基本特性6 全局变量和局部变量在内存中是否有区别?如果有,是什么区别?7 什么是平衡二叉树?8 堆栈溢…...

Python(模块)
模块编写完成就可以被其他模块进行调用并使用被调用模块的功能。 import导入方式的语法结构: import模块名称【as别名】 from……import导入方式的语法结构: from模块名称,import变量/函数/类/*(*是通配符) impor…...

【八股文】Java基础篇
1. 和 equals的区别是什么? 判断两个变量或者实例是否都指向同一内存空间的值(不仅值相同,地址也要相同)equals是判断两个变量执行的内存空间的值是否相同(值相同,地址可以不同),所…...

python rsa如何安装
Python中的一些模块是用一个包管理器来发布的,RSA模块就是,所以首先需要安装setup tools工具。 1、下载文件:ez_setup.py 2、安装: sudo python ez_setup.py 3、下载RSA安装包:rsa-3.1.1-py2.7.egg 4、安装RSA&…...

P10289 [GESP样题 八级] 小杨的旅游
Description 给定一棵 n n n 个点的树,每条边权值均为 1 1 1,树上有 k k k 个关键点,关键点们在 0 0 0 的时间内相互可达, q q q 次询问,求 s → t s\to t s→t 的最短路。 Analysis 考虑暴力建图,…...

网络编程 ----------- 4、组播与广播
1、广播 broadcast 广播是指向同一个网络中所有的主机传输数据只有传输层协议为 UDP协议时,才支持广播 TCP是端对端,广播是一对多 ,所以无法符合其要求。 1)广播地址 广播地址的计算: 子网掩码…...

最短路径算法:Bellman-Ford算法
引言 在图论中,Bellman-Ford算法是一种用于计算单源最短路径的算法。与Dijkstra算法不同,Bellman-Ford算法可以处理带有负权边的图,并且可以检测图中是否存在负权环。本文将详细介绍Bellman-Ford算法的定义、步骤及其实现。 Bellman-Ford算…...

爬虫:xpath模块及昵图网实例
xpath模块 from lxml import etreestr1 """ <div><ul><li class"item-0"><a href"link1.html">first item</a></li><li class"item-1"><a href"link2.html">second…...

高级java每日一道面试题-2024年8月03日-web篇-forward和redirect有什么区别?
如果有遗漏,评论区告诉我进行补充 面试官: forward和redirect有什么区别? 我回答: 在Java Web开发中,forward和redirect是Servlet容器提供的两种用于页面跳转的技术。它们的主要区别在于客户端感知的方式、URL地址的变化、请求对象的共享等方面。下面详细介绍两…...

如何让你的网站拥有更好的体验
在HTML中,属性是用于提供关于HTML元素的额外信息。接下来我们将讲解13个可以让用户拥有更好体验的HTML属性。 Accept 属性 我们可以在<input>元素(仅适用于文件类型)中使用accept属性来指定服务器可以接受的文件类型。 <input ty…...

opencascade AIS_TypeFilter AIS_XRTrackedDevice源码学习
opencascade AIS_TypeFilter 前言 通过它们的类型选择交互对象。该过滤器会对本地上下文中的每个交互对象提出问题, 以确定它是否具有非空的所有者,并且如果是,则检查它是否是所需类型。 如果对象在每种情况下都返回 true,则保留…...

使用Spring AOP监控指定方法执行时间
文章目录 一、加入pom依赖二、切面类和注解三、执行方法 一、加入pom依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency>二、切面类和注解 import java.lang.…...

最新CSS3纵向菜单的实现
纵向菜单 通过下面例子,你会知道把列表转换成菜单的关键技术 a中的#是URL的占位符可以点击,真正用途中写实际URL <nav class"list1"><ul><li><a href"#">Alternative</a></li><li><…...

GooLeNet模型搭建
一、model import torch from torch import nn from torchsummary import summaryclass Inception(nn.Module):def __init__(self, in_channels, c1, c2 , c3 , c4):super(Inception, self).__init__()self.ReLU nn.ReLU()#路线1:1x1卷积self.p1_1 nn.Conv2d(in_channels i…...

使用ThreadLocal来存取单线程内的数据
一.什么是ThreadLocal? ThreadLocal,即线程本地变量。如果你创建了一个 ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是在操作自己本地内存里面的变量&…...
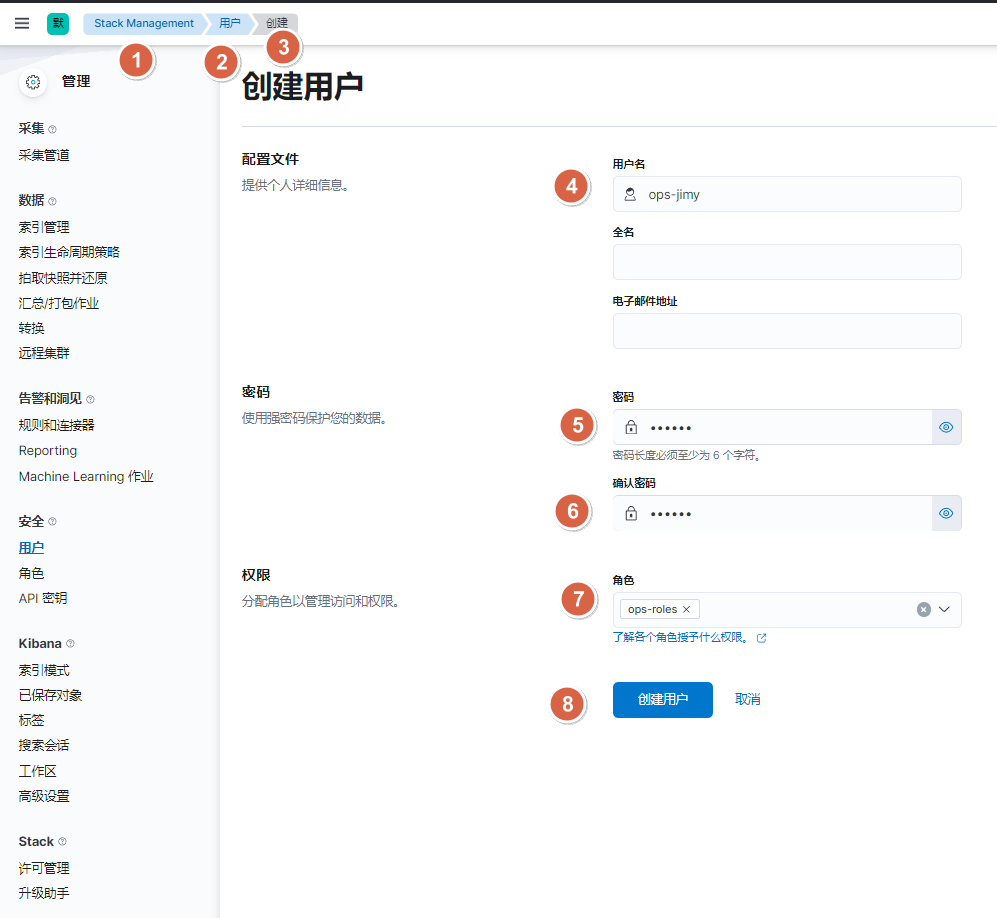
elasticsearch教程
1. 单点部署(rpm): #提前关闭firewalld,否则无法组建集群 #1. 下载ES rpm包 ]# https://www.elastic.co/cn/downloads #2. 安装es ]# rpm -ivh elasticsearch-7.17.5-x86_64.rpm #3. 调整内核参数(太低的话es会启动报错) echo "vm.max_map_count655360 fs.file-max 655…...

Arrays、Lambda表达式、Collection集合
1. Arrays 1.1 操作数组的工具类 方法名说明public static String toString(数组)把数组拼接成一个字符串public static int binarySearch(数组,查找的元素)二分查找法查找元素public static int[] copyOf(原数组,新数组长度)拷贝数组public static int[] copyOfRange(原数组…...

2024年前端趋势:全栈或许是不容错过的选择!
近年来,前端开发的技术不断推陈出新,2024年也不例外。在这个变化迅速的领域,全栈开发逐渐成为一股不容忽视的趋势。无论你是经验丰富的开发者,还是刚刚入门的新手,掌握全栈技术都能让你在竞争中脱颖而出。而在这个过程…...
MySQL 实战 45 讲(01-05)
本文为笔者学习林晓斌老师《MySQL 实战 45 讲》课程的学习笔记,并进行了一定的知识扩充。 sql 查询语句的执行流程 大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。 Server 层包括连接器、查询缓存、分析器、优化器和执行器。 连接器负责接收客…...

仓颉编程语言入门 -- Array数组详解
仓颉编程语言入门 – Array数组详解 一. 如何创建Array数组 我们可以使用 Array 类型来构造单一元素类型,有序序列的数据。 1.仓颉使用 Array 来表示 Array 类型。T 表示 Array 的元素类型,T 可以是任意类型 , 类似于泛型的概念 var arr:Array<St…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...