elasticsearch教程
1. 单点部署(rpm):
#提前关闭firewalld,否则无法组建集群
#1. 下载ES rpm包
]# https://www.elastic.co/cn/downloads
#2. 安装es
]# rpm -ivh elasticsearch-7.17.5-x86_64.rpm
#3. 调整内核参数(太低的话es会启动报错)
echo "vm.max_map_count=655360
fs.file-max = 655350
fs.nr_open = 655350" > /etc/sysctl.d/es.conf
sysctl -f /etc/sysctl.d/es.confulimit -n 655350
ulimit -u 655350
echo "* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350" > /etc/security/limits.d/es7.conf#4. 修改es的配置文件--------------------------------------------------
]# vim /etc/elasticsearch/elasticsearch.yml
...
#ES服务监听对外暴露服务的地址
network.host: 0.0.0.0
# 指定ES集群的节点IP
discovery.seed_hosts: ["10.0.0.101"]
# 指定参与master选举的节点
cluster.initial_master_nodes: ["10.0.0.101"]
#----------------------------------------------------------------
#5. 启动ES服务
]# systemctl enable --now elasticsearch#6. 验证节点是否正常工作
]# ss -taunlp|grep java
tcp LISTEN 0 128 [::]:9200 [::]:* users:(("java",pid=4192,fd=302))
tcp LISTEN 0 128 [::]:9300 [::]:* users:(("java",pid=4192,fd=287)) users:(("java",pid=2813,fd=287))
#9200端口作用: 对ES集群外部提供http/https服务。可以理解为对客户端提供服务。
#9300端口作用: 对ES集群内部进行数据通信传输端口。走的时候tcp协议。#7.客户端验证
]# curl 10.0.0.101:9200
{"name" : "elk1","cluster_name" : "elasticsearch","cluster_uuid" : "V_9NnNDdSDOy-OcrZBTFFA","version" : {"number" : "7.17.5","build_flavor" : "default","build_type" : "rpm","build_hash" : "8d61b4f7ddf931f219e3745f295ed2bbc50c8e84","build_date" : "2022-06-23T21:57:28.736740635Z","build_snapshot" : false,"lucene_version" : "8.11.1","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}2. 集群部署(rpm)
集群节点:10.0.0.101,10.0.0.102,10.0.0.103
#提前关闭firewalld,否则无法组建集群
#1. 所有节点下载ES软件包
]# https://www.elastic.co/cn/downloads
#2. 所有节点安装es
]# rpm -ivh elasticsearch-7.17.5-x86_64.rpm
#3. 调整内核参数(太低的话es会启动报错)
echo "vm.max_map_count=655360
fs.file-max = 655350
fs.nr_open = 655350" > /etc/sysctl.d/es.conf
sysctl -f /etc/sysctl.d/es.confulimit -n 655350
ulimit -u 655350
echo "* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350" > /etc/security/limits.d/es7.conf
#4. 101修改es的配置文件--------------------------------------------------
]# vim /etc/elasticsearch/elasticsearch.yml
...
#集群名称
cluster.name: ES-CLUSTER1#ES服务监听对外暴露服务的地址
network.host: 0.0.0.0
# 指定ES集群的节点IP
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]
# 指定参与master选举的节点
cluster.initial_master_nodes: ["10.0.0.101","10.0.0.102","10.0.0.103"]
#----------------------------------------------------------------#5. 在101上把配置文件拷贝到102,103上
]# scp /etc/elasticsearch/elasticsearch.yml root@10.0.0.102:/etc/elasticsearch/
]# scp /etc/elasticsearch/elasticsearch.yml root@10.0.0.103:/etc/elasticsearch/#6. 所有节点启动ES服务
]# systemctl enable --now elasticsearch#7. 三个节点,验证节点是否正常工作
]# ss -taunlp|grep java
tcp LISTEN 0 128 [::]:9200 [::]:* users:(("java",pid=4192,fd=302))
tcp LISTEN 0 128 [::]:9300 [::]:* users:(("java",pid=4192,fd=287)) users:(("java",pid=2813,fd=287))
#9200端口作用: 对ES集群外部提供http/https服务。可以理解为对客户端提供服务。
#9300端口作用: 对ES集群内部进行数据通信传输端口。走的时候tcp协议。#8.验证ES集群节点是否正常工作
]# curl 10.0.0.101:9200/_cat/nodes
10.0.0.103 9 79 0 0.06 0.13 0.14 cdfhilmrstw - elk3
10.0.0.101 15 79 0 0.01 0.15 0.18 cdfhilmrstw - elk1
10.0.0.102 11 80 2 0.02 0.16 0.18 cdfhilmrstw * elk2]# curl 10.0.0.101:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.0.0.103 9 79 0 0.03 0.12 0.14 cdfhilmrstw - elk3
10.0.0.101 16 79 0 0.16 0.17 0.18 cdfhilmrstw - elk1
10.0.0.102 11 80 0 0.01 0.15 0.18 cdfhilmrstw * elk2
]# curl 10.0.0.101:9200/_cluster/health?pretty
{"cluster_name" : "tom-es","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 3,"active_shards" : 6,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
#集群必须保证半数以上的节点存活,集群才能正常3. 基于二进制部署ElasticSearch集群
集群节点:10.0.0.101,10.0.0.102,10.0.0.103
下载二进制压缩包
#1. 10.0.0.101 下载ES二进制压缩包
]# https://www.elastic.co/cn/downloads2.10.0.0.101解压缩
mkdir -p /data/{tools,logs,data}/es
tar -xvf elasticsearch-7.17.5-linux-x86_64.tar.gz -C /data/tools/es3.编辑配置文件
cp /data/tools/es/elasticsearch-7.17.5/config/elasticsearch.yml{,.back}
cat > /data/tools/es/elasticsearch-7.17.5/config/elasticsearch.yml <<EOF
cluster.name: ES-CLUTER2
path.data: /data/data/es/
path.logs: /data/logs/es/
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101", "10.0.0.102","10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101", "10.0.0.102","10.0.0.103"]
EOF
4.使用systemctl管理ES服务
cat > /usr/lib/systemd/system/elasticsearch.service <<EOF
[Unit]
Description=es
After=network.target[Service]
Type=simple
ExecStart=/data/tools/es/elasticsearch-7.17.5/bin/elasticsearch
User=elastic
LimitNOFILE=131070[Install]
WantedBy=multi-user.target
EOF5.把相关目录传到102,103上
scp -r /data/ root@10.0.0.102:/
scp -r /data/ root@10.0.0.103:/
scp /usr/lib/systemd/system/elasticsearch.service root@10.0.0.102:/usr/lib/systemd/system/elasticsearch.service
scp /usr/lib/systemd/system/elasticsearch.service root@10.0.0.103:/usr/lib/systemd/system/elasticsearch.service6.101,102,103
#上创建es配置目录软连接
ln -s /data/tools/es/elasticsearch-7.17.5/config/ /etc/elasticsearch
#创建elastic用户
useradd elastic
#修改目录归属
chown -R elastic.elastic /data/tools/es/ /data/logs/es/ /data/data/es/
#加载服务
systemctl daemon-reload7.调整内核参数(太低的话es会启动报错)
echo "vm.max_map_count=655360
fs.file-max = 655350
fs.nr_open = 655350" > /etc/sysctl.d/es.conf
sysctl -f /etc/sysctl.d/es.confulimit -n 655350
ulimit -u 655350
echo "* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350" > /etc/security/limits.d/es7.conf
8.#启动elasticsearch
systemctl enable elasticsearch.service --now9.检查集群状态
]# curl 10.0.0.101:9200/_cluster/health?pretty
{"cluster_name" : "ES-CLUTER","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 3,"active_shards" : 6,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}4. 堆内存设置
背景说明:es堆内存默认设置为主机内存的一半,如果主机内存大于64G,则需要手动设置堆内存最大为32G
设置方式为:vim /etc/elasticsearch/jvm.options
-Xms32g
-Xmx32g
5. swapping是性能的坟墓
禁用swapping
#临时禁用
swapoff -a
#永久禁用,需要注释掉 /etc/fstab中/dev/mapper/centos-swap开头的行如果由于其他原因不能禁用的,可以进行如下操作
echo "vm.swappiness = 1" >> /etc/sysctl.d/es.conf
sysctl -f /etc/sysctl.d/es.conf6. ES的常见术语:
索引(index): 用户写入ES集群的逻辑单元。
分片(shard): 一个索引最少一个分片。作用为将索引的数据分布式的存储在ES集群。
副本(replica): 一个分片可以有0个或多个副本。作用为同一个分片数据提供数据冗余。
文档(docment): 实际存储数据的媒介。这些文档存储在分片中。
主分片和副本分片的区别: 主分片可以用于读写操作(rw)。副本分片仅能用于读取操作(ro)。
集群的颜色:
- green 表示所有的主分片和副本分片均正常工作。
- yellow 表示有部分副本分片不正常工作。
- red 表示有部分主分片不正常工作。7. ES的API
安装postman,用于api测试
7.1. 索引管理API:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices.html
-1. 查看索引(1)查看所有的索引
curl -X GET 10.0.0.101:9200/_cat/indices
--------------------------------------------------------------------------
-2. 创建索引(1)创建默认索引,默认是一个分片和一个副本
curl -XPUT 10.0.0.101:9200/tom1(2)创建指定的分片
curl -XPUT 10.0.0.101:9200/tom2
{"settings":{"number_of_shards": 3}
}(3)创建指定的分片和副本
curl -XPUT 10.0.0.101:9200/tom3
{"settings":{"number_of_shards": 3,"number_of_replicas":2}
}
--------------------------------------------------------------------------
-3. 修改索引(1)修改副本
curl -XPUT 10.0.0.101:9200/tom3/_settings
{"number_of_replicas": 1
}(2)修改分片,不能修改,会报错
curl -XPUT 10.0.0.101:9200/tom3/_settings
{"number_of_shards": 10
}
--------------------------------------------------------------------------
-4 删除索引(1)删除单个索引
curl -XDELETE 10.0.0.101:9200/tom1(2)基于通配符删除多个索引
curl -XDELETE 10.0.0.101:9200/tom*
--------------------------------------------------------------------------
-5 索引别名(1)添加索引别名
curl -XPOST http://10.0.0.101:9200/_aliases
{"actions": [{"add": {"index": "tom1","alias": "2024"}},{"add": {"index": "tom1","alias": "DBA"}},{"add": {"index": "tom2","alias": "2024"}},{"add": {"index": "tom2","alias": "DBA"}}]
}(2)查看索引别名
curl -XGET http://10.0.0.101:9200/_aliases(3)修改索引别名
curl -XPOST http://10.0.0.101:9200/_aliases
{"actions": [{"remove": {"index": "tom2","alias": "DBA"}},{"add": {"index": "tom2","alias": "数据库"}}]
}(4)删除索引别名
curl -XPOST http://10.0.0.101:9200/_aliases
{"actions": [{"remove": {"index": "tom2","alias": "数据库"}}]
}
curl -XDELETE http://10.0.0.101:9200/tom1/_alias/DBA
--------------------------------------------------------------------------
-6 打开关闭索引
(1)关闭索引:
curl -XPOST 10.0.0.101:9200/tom3/_close
(2)打开索引:
curl -XPOST 10.0.0.101:9200/tom3/_open
--------------------------------------------------------------------------
-7 创建索引的规范:
1.索引名称不要以"."",""_"开头
2.索引名称不能出现大写,必须小写
3.生产环境中尽量避免使用通配符,尤其是删除操作
7.2. 文档管理API:
- 文档的基础操作1.创建文档1.1 不指定文档ID
POST 10.0.0.101:9200/student/_doc
{"name": "tom","hobby": ["唱K","泡妞","rap"]
}1.2 指定文档ID(ID相同,名字不同的,会覆盖)
POST 10.0.0.101:9200/student/_doc/100
{"name": "jack","hobby": ["篮球","足球","乒乓球"]
}
---------------------------------------------------------------- 2.文档修改2.1 全量更新
POST 10.0.0.101:9200/student/_doc/100
{"name": "jack"
}2.2 局部更新
POST 10.0.0.101:9200/student/_doc/100/_update
{"doc":{"age":20,"hobby":["抽烟","喝酒","烫头"]}
}
---------------------------------------------------------------- 3.文档的查看
GET 10.0.0.101:9200/student/_search
----------------------------------------------------------------4.删除文档
DELTE 10.0.0.101:9200/student/_doc/100
----------------------------------------------------------------
-5 文档的批量操作(1)批量创建
POST 10.0.0.101:9200/_bulk
{ "create": { "_index": "elk"} }
{ "name": "tom","hobby":["bas","foot"] }
{ "create": { "_index": "elk" }
{ "name": "jack","hobby":["rap","ktv"] }(2)批量修改
POST 10.0.0.101:9200/_bulk
{ "update" : {"_id" : "J9My45ABMF1IlwvY5XsY", "_index" : "elk"} }
{ "doc" : {"name" : "tom1"} }
{ "update" : {"_id" : "KNMy45ABMF1IlwvY5XsY", "_index" : "elk"} }
{ "doc" : {"name" : "jack1"} }(3)查询文档
POST 10.0.0.101:9200/_mget
{"docs": [{"_index": "elk","_id": "J9My45ABMF1IlwvY5XsY"},{"_index": "elk","_id": "KNMy45ABMF1IlwvY5XsY"}]
}(4)批量删除
POST 10.0.0.101:9200/_bulk
{ "delete" : { "_index" : "elk", "_id" : "J9My45ABMF1IlwvY5XsY" } }
{ "delete" : { "_index" : "elk", "_id" : "KNMy45ABMF1IlwvY5XsY" } }
7.3. 使用mapping自定义数据类型
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
1. IP案例:(1)创建索引时指定映射关系
PUT 10.0.0.101:9200/ip
{"mappings": {"properties": {"ip_add": {"type": "ip" }}}
}(2)查看索引的映射关系
GET 10.0.0.101:9200/ip(3)创建测试数据
POST 10.0.0.101:9200/_bulk
{ "create": { "_index": "ip"} }
{ "name": "tom","ip_add": "192.168.1.4" }
{ "create": { "_index": "ip"} }
{ "name": "jack","ip_add": "192.168.1.10" }
{ "create": { "_index": "ip"} }
{ "name": "lucy","ip_add": "10.168.1.10" }(4)查看数据
GET 10.0.0.101:9200/ip/_search
POST 10.0.0.101:9200/ip/_search
{"query":{"match":{"ip_add": "192.168.0.0/16"}}
}(5)删除数据
DELETE 10.0.0.101:9200/ip/_doc/KtNV45ABMF1IlwvYAXsz
-----------------------------------------------------------------------------
2. date案例:(1)创建索引时指定映射关系
PUT http://10.0.0.101:9200/date
{"mappings": {"properties": {"birthday": {"type": "date","format": "yyyy-MM-dd"}}}
}(2)查看索引的映射关系
GET http://10.0.0.101:9200/date(3)创建测试数据
POST 10.0.0.101:9200/_bulk
{ "create": { "_index": "date"} }
{ "name": "tom","birthday": "2002-10-01" }
{ "create": { "_index": "date"} }
{ "name": "jack","birthday": "1996-05-01" }(4)查看数据
GET 10.0.0.101:9200/date/_search(5)删除数据
DELETE 10.0.0.101:9200/date/_doc/KtNV45ABMF1IlwvYAXsz
---------------------------------------------------------------------------------
-3 综合案例(1)创建索引
PUT http://10.0.0.101:9200/elk1(2)查看索引信息
GET http://10.0.0.101:9200/elk1(3)为已创建的索引修改数据类型
PUT http://10.0.0.101:9200/elk1/_mapping
{"properties": {"name": {"type": "text","index": true},"gender": {"type": "keyword","index": true},"province": {"type": "keyword","index": true},"city": {"type": "keyword","index": false},"email": {"type": "keyword"},"ip_addr": {"type": "ip"},"birthday": {"type": "date","format": "yyyy-MM-dd"}}
}(4)添加测试数据
POST http://10.0.0.101:9200/_bulk
{ "create": { "_index": "elk1"}}
{ "name": "tom","gender":"男性的","telephone":"1111111111","province":"广西","city":"北海市","email":"tom@qq.com","ip_addr":"192.168.25.201","birthday":"1999-04-05"}
{ "create": { "_index": "elk1"}}
{ "name": "jack","gender":"女性的","telephone":"222222222","province":"河南","city":"濮阳市","email":"jack@qq.com","ip_addr":"192.168.15.31","birthday":"2003-09-05","hobby":["抽烟","喝酒","烫头","足疗"]}(5)查看数据-基于gender-匹配keyword类型
GET http://10.0.0.101:9200/elk1/_search
{"query":{"match":{"gender": "女"}}
}(6)查看数据-基于name字段搜索-匹配text类型
GET http://10.0.0.101:9200/elk1/_search
{"query":{"match":{"name": "吴"}}
}(7)查看数据-基于email字段搜索-匹配keyword类型
GET http://10.0.0.101:9200/elk1/_search
{"query":{"match":{"email": "jack@qq.com"}}
}(8)查看数据-基于ip_addr字段搜索-匹配ip类型
GET http://10.0.0.101:9200/elk1/_search
{"query": {"match" : {"ip_addr": "192.168.15.0/24"}}
}(9)查看数据-基于city字段搜索,无法完成,该字段无法被检索
GET http://10.0.0.101:9200/elk1/_search
{"query":{"match":{"city": "濮阳市"}}
}7.4. 分词器:
注意:所有ES节点都要安装
1.内置的标准分词器-分析英文
GET http://10.0.0.101:9200/_analyze
{"analyzer": "standard","text": "My name is Jason Yin, and I'm 18 years old !"
}
温馨提示:标准分词器模式使用空格和符号进行切割分词的。2.内置的标准分词器-分析中文并不友好
GET http://10.0.0.101:9200/_analyze
{"analyzer": "standard","text": "我爱北京天安门!"
}3.安装IK分词器 3.1 在线安装方式:]# /data/tools/es/elasticsearch-7.17.5/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.53.2 离线安装方式:#创建IK分词器目录mkdir /data/tools/es/elasticsearch-7.17.5/plugins/ik#下载安装包到ik目录https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.17.5.zip#解压软件包cd /data/tools/es/elasticsearch-7.17.5/plugins/ikunzip elasticsearch-analysis-ik-7.17.5.ziprm -f elasticsearch-analysis-ik-7.17.5.zip
4. 重启服务
systemctl restart elasticsearch.service5. 测试IK中文分词器5.1 测试IK中文分词器-细粒度拆分
GET http://10.0.0.101:9200/_analyze
{"analyzer": "ik_max_word","text": "我爱北京天安门!"
}5.2 测试IK中文分词器-粗粒度拆分
GET http://10.0.0.101:9200/_analyze
{"analyzer": "ik_smart","text": "我爱北京天安门!"
}
----------------------------------------------------------------
6. 自定义IK分词器的字典(1)进入到IK分词器的插件安装目录
cd /data/tools/es/elasticsearch-7.17.5/plugins/ik/config(2)自定义字典
cat > tom.dic <<'EOF'
德玛西亚
艾欧尼亚
亚索
上号
带你飞
贼6
EOF(3)加载自定义字典
vim IKAnalyzer.cfg.xml
...
<entry key="ext_dict">tom.dic</entry>(4)重启ES集群
systemctl restart elasticsearch.service(5)测试分词器
GET http://10.0.0.101:9200/_analyze
{"analyzer": "ik_smart","text": "嗨,哥们! 上号,我德玛西亚和艾欧尼亚都有号! 我亚索贼6,肯定能带你飞!!!"
}(6)使用分词器#创建索引mnapping
POST 10.0.0.101:9200/tom4/
{"mappings":{"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}
#创建文档
POST 10.0.0.101:9200/_bulk
{ "create": { "_index": "tom4"} }
{ "content": "美国留给伊拉克的是个烂摊子吗" }
{ "create": { "_index": "tom4"} }
{ "content": "公安部:各地校车将享最高路权" }
{ "create": { "_index": "tom4"} }
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
#查询文档
GET 10.0.0.101:9200/tom4/_search
{"query" : { "match" : { "content" : "中国" }}
}7.5. 索引模板
什么是索引模板: 索引可使用预定义的模板进行创建,这个模板称作Index templates。
模板设置包括设置和映射,通过模式匹配的方式使得多个索引重用一个模板。1.查看索引模板(1)查看所有的索引模板
GET http://10.0.0.103:9200/_template(2)查看单个索引模板
GET http://10.0.0.103:9200/_template/.monitoring-es2.创建/修改索引模板
POST http://10.0.0.103:9200/_template/java
{"aliases": {"DBA": {},"SRE": {},"K8S": {}},"index_patterns": ["java*"],"settings": {"index": {"number_of_shards": 3,"number_of_replicas": 1}},"mappings": {"properties":{"ip_addr": {"type": "ip"},"access_time": {"type": "date"},"address": {"type" :"text"},"name": {"type": "keyword"}}}
}3.删除索引模板:
DELETE http://10.0.0.103:9200/_template/java7.6. DSL语句查询(运维开发或者DBA重点掌握)
什么是DSL:Elasticsearch 提供了基于JSON的完整 Query DSL(领域特定语言)来定义查询。
下面的请求url都为 POST 10.0.0.101:9200/shopping/_search
全文检索-match查询:(1)查询tom收集的数据
{"query":{"match":{"auther":"tom"}}
}精确匹配-match_phrase查询(1)查询tom的数据
{"query":{"match_phrase":{"auther":"tom"}}
}全量查询-match_all查询(查询所有结果)
{"query": {"match_all": {}}
}
-----------------------------------------------------------------------------
分页查询
(1)每页显示3条数据,查询第四页
{"query":{"match_phrase":{"auther":"tom"}},"size": 3,"from":9
} (2)查询第六组数据,每页显示7条数据,查询第9页
{"query":{"match":{"group":6}},"size":7,"from": 56
}相关参数说明:size:指定每页显示多少条数据,默认值为10.from:指定跳过数据偏移量的大小,默认值为0,即默认看第一页。查询指定页码的from值 = "(页码 - 1) * 每页数据大小(size)"温馨提示:生产环境中,不建议深度分页,百度的页码数量控制在76页左右。
--------------------------------------------------------------------------
使用"_source"查看的指定字段
{"query":{"match_phrase":{"auther":"tom"}},"_source":["title","auther","price"]
}
---------------------------------------------------------------------------
查询存在某个字段的文档-exists
{"query": {"exists" : {"field": "hobby"}}
}
---------------------------------------------------------------------------
语法高亮
{"query": {"match_phrase": {"title": "孙子兵法"}},"highlight": {"pre_tags": ["<span style='color:red;'>"],"post_tags": ["</span>"],"fields": {"title": {}}}
}
参数说明:
highlight: 设置高亮
fields: 指定对哪个字段进行语法高亮
pre_tags: 自定义高亮的前缀标签
post_tags: 自定义高亮的后缀标签
------------------------------------------------------------------------------
排序查询:01-升序查询最便宜商品及价格
{"query":{"match_phrase":{"auther":"tom"}},"sort":{"price":{"order": "asc"}},"size":1
}02-降序查询最贵的商品及价格
{"query":{"match_phrase":{"auther":"tom"}},"sort":{"price":{"order": "desc"}},"size":1
}
相关字段说明:
sort: 基于指定的字段进行排序。此处为指定的是"price"
order: 指定排序的规则,分为"asc"(升序)和"desc"(降序)。
----------------------------------------------------------------
多条件查询-bool01-查看作者是tom且商品价格为24.90(bool,must)
{"query": {"bool": {"must": [{"match_phrase": {"auther": "tom"}},{"match": {"price": 24.90}}]}}
}
02-查看作者是tom或者是jack的商品并降序排序(bool,should)
{"query": {"bool": {"should": [{"match_phrase": {"auther": "tom"}},{"match_phrase": {"auther": "jack"}}]}},"sort":{"price":{"order": "desc"}}
}
03-查看作者是tom或者是jack且商品价格为168或者198
{"query": {"bool": {"should": [{"match_phrase": {"auther": "于萌"}},{"match_phrase": {"auther": "高超"}},{"match": {"price": 168.00}},{"match": {"price": 198.00}}],"minimum_should_match": "60%"}}
}04-查看作者不是tom或者是jack且商品价格为168或者198的商品
{"query": {"bool": {"must_not": [{"match_phrase": {"auther": "tom"}},{"match_phrase": {"auther": "jack"}}],"should": [{"match": {"price": 168.00}},{"match": {"price": 198.00}}],"minimum_should_match": 1}}
}05-综合案例
零食商品,作者不是tom和jack的,价格168.00或者9.9或19.9的,
且只看title,price,auther,按照价格降序,标题高亮,
{"query": {"bool": {"must": [{"match_phrase": {"title": "零食"}}],"must_not": [{"match_phrase": {"auther": "tom"}},{"match_phrase": {"auther": "jack"}}],"should": [{"match": {"price": 168.00}},{"match": {"price": 9.9}},{"match": {"price": 19.9}}],"minimum_should_match": 1}},"highlight": {"pre_tags": ["<span style='color:red;'>"],"post_tags": ["</span>"],"fields": {"title": {}}},"_source": ["title","price","auther"],"sort": {"price": {"order": "desc"}}
}
---------------------------------------------------------------------------
过滤查询:
01-查询3组成员产品价格3599到10500的商品的最便宜的3个
{"query": {"bool": {"must": [{"match": {"group": 3}}],"filter": {"range": {"price": {"gte": 3599,"lte": 10500}}}}},"sort": {"price": {"order": "asc"}},"size": 3
}02-查询2,4,6这3个组的最贵的3个产品且不包含酒的商品
{"query":{"bool":{"must_not":[{"match":{"title": "酒"}}],"should": [{"match":{"group":2}},{"match":{"group":4}},{"match":{"group":6}}]}},"sort":{"price":{"order": "desc"}},"size":3
}
----------------------------------------------------------------------------
精确匹配多个值-terms:
01-查询商品价格为9.9和19.8的商品
{"query": {"terms": {"price": [9.9,19.9]}}
}
---------------------------------------------------------------------------
多词搜索:
01-多词搜索包含"小面包"关键字的所有商品
{"query": {"bool": {"must": [{"match": {"title": {"query": "小面包","operator": "and"}}}]}},"highlight": {"pre_tags": ["<h1>"],"post_tags": ["</h1>"],"fields": {"title": {}}}
}
参数说明:
operator: 为and表示查询query中的词必须连续,为or表示query中的词可以分开,默认是or
-------------------------------------------------------------------------------
聚合查询01-统计每个组收集的商品数量
{ "aggs": {"group": {"terms":{"field": "group"}}},"size": 0
}02-统计2组最贵的商品
{"query": {"match": {"group": 2}},"aggs": {"max_shopping": {"max": {"field": "price"}}},"sort":{"price":{"order":"desc"}},"size": 1
}03-统计3组最便宜的商品
{"query": {"match": {"group": 3}},"aggs": {"min_shopping": {"min": {"field": "price"}}},"sort":{"price":{"order": "asc"}},"size": 1
}04-统计4组商品的平均价格
{"query": {"match": {"group": 4}},"aggs": {"avg_shopping": {"avg": {"field": "price"}}},"size": 0
}05-统计买下5组所有商品要多少钱
{"query": {"match": {"group":5}},"aggs": {"sum_shopping": {"sum": {"field": "price"}}},"size": 0
}
7.7. 集群迁移实战
Reindex API | Elasticsearch Guide [8.14] | Elastic
7.7.1. 搭建2套ES集群
[root@elk1 data]# curl 10.0.0.101:19200/_cat/nodes
10.0.0.103 66 96 1 0.19 0.42 0.30 cdfhilmrstw - elk3
10.0.0.101 66 96 3 0.41 0.45 0.41 cdfhilmrstw - elk1
10.0.0.102 54 96 1 0.14 0.44 0.36 cdfhilmrstw * elk2
[root@elk1 data]# curl 10.0.0.101:9200/_cat/nodes
10.0.0.102 63 96 5 0.14 0.44 0.36 cdfhilmrstw - elk2
10.0.0.103 36 96 9 0.17 0.42 0.30 cdfhilmrstw * elk3
10.0.0.101 69 96 7 0.38 0.44 0.41 cdfhilmrstw - elk17.7.2. 同一个集群内部迁移数据
POST http://10.0.0.101:9200/_reindex
{"source": {"index": "student"},"dest": {"index": "student-new"}
}7.7.3. 不同集群迁移
把9200的数据迁移到19200集群上3.1 修改所有19200端口的配置文件
vim /data/tools/es2/elasticsearch-7.17.5/config/elasticsearch.yml
...
# 添加如下一行代码,表示添加远程主机的白名单,用于数据迁移信任的主机。
reindex.remote.whitelist: "10.0.0.*:9200"3.3 重启所有节点19200的ES服务
systemctl restart elastic2.service3.4 迁移数据
POST http://10.0.0.101:19200/_reindex
{"source": {"index": "student","remote": {"host": "http://10.0.0.101:9200"} },"dest": {"index": "student"}
}3.5 验证数据
GET 10.0.0.101:19200/student/_search说明:reindex时,可以使用DSL语句来对源数据进行过滤7.8. 集群常用的API
7.8.1. 集群健康状态API
]# curl 10.0.0.101:9200/_cluster/health?pretty
{"cluster_name" : "ES-CLUTER","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 28,"active_shards" : 56,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}相关参数说明:cluster_name 集群的名称。status 集群的健康状态,基于其主分片和副本分片的状态。ES集群有以下三种状态:green 所有分片都已分配。yellow 所有主分片都已分配,但一个或多个副本分片未分配。如果集群中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。red 一个或多个主分片未分配,因此某些数据不可用。这可能会在集群启动期间短暂发生,因为分配了主分片。timed_out 是否在参数false指定的时间段内返回响应(默认情况下30秒)。number_of_nodes 集群内的节点数。number_of_data_nodes 作为专用数据节点的节点数。active_primary_shards 可用主分片的数量。active_shards 可用主分片和副本分片的总数。relocating_shards 正在重定位的分片数。initializing_shards 正在初始化的分片数。unassigned_shards 未分配的分片数。delayed_unassigned_shards 分配因超时设置而延迟的分片数。number_of_pending_tasks 尚未执行的集群级别更改的数量。number_of_in_flight_fetch 未完成的提取次数。task_max_waiting_in_queue_millis 自最早启动的任务等待执行以来的时间(以毫秒为单位)。active_shards_percent_as_number 集群中活动分片的比率,以百分比表示。#要想获取某项的值,可以通过jq命令(yum -y install jq)
]# curl 10.0.0.101:9200/_cluster/health?pretty 2>/dev/null|jq .status
"green"7.8.2. ES集群的设置及优先级(settings)
如果您使用多种方法配置相同的设置,Elasticsearch 会按以下优先顺序应用这些设置:(1)Transient setting(临时配置,集群重启后失效)(2)Persistent setting(持久化配置,集群重启后依旧生效)(3)elasticsearch.yml setting(配置文件)(4)Default setting value(默认设置值)(1)查询集群的所有配置信息
GET http://10.0.0.103:9200/_cluster/settings?include_defaults=true&flat_settings=true (2)修改集群的配置信息
PUT http://10.0.0.103:9200/_cluster/settings
{"transient": {"cluster.routing.allocation.enable": "none"}
}相关参数说明:
"cluster.routing.allocation.enable":"all": 允许所有分片类型进行分配。"primaries" 仅允许分配主分片。"new_primaries" 仅允许新创建索引分配主分片。"none": 不允许分配任何类型的分配。参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-get-settings.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-update-settings.html
7.8.3. 集群状态API
集群状态是一种内部数据结构,它跟踪每个节点所需的各种信息,包括:(1)集群中其他节点的身份和属性(2)集群范围的设置(3)索引元数据,包括每个索引的映射和设置(4)集群中每个分片副本的位置和状态
(1)查看集群的状态信息
GET http://10.0.0.103:9200/_cluster/state(2)只查看节点信息。
GET http://10.0.0.103:9200/_cluster/state/nodes(3)查看nodes,version,routing_table这些信息,并且查看以"oldboyedu*"开头的所有索引
http://10.0.0.103:9200/_cluster/state/nodes,version,routing_table/oldboyedu*推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-state.html7.8.4. 集群统计API
Cluster Stats API 允许从集群范围的角度检索统计信息。
返回基本索引指标(分片数量、存储大小、内存使用情况)和
有关构成集群的当前节点的信息(数量、角色、操作系统、jvm 版本、内存使用情况、cpu 和已安装的插件)。(1)查看统计信息
GET http://10.0.0.103:9200/_cluster/stats推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-stats.html7.8.5. 查看集群的分片分配情况(allocation)
集群分配解释API的目的是为集群中的分片分配提供解释。
对于未分配的分片,解释 API 提供了有关未分配分片的原因的解释。
对于分配的分片,解释 API 解释了为什么分片保留在其当前节点上并且没有移动或重新平衡到另一个节点。
当您尝试诊断分片未分配的原因或分片继续保留在其当前节点上的原因时,
此 API 可能非常有用,而您可能会对此有所期待。(1)分析teacher索引的0号分片未分配的原因。
GET http://10.0.0.101:9200/_cluster/allocation/explain
{"index": "teacher","shard": 0,"primary": true
}
推荐阅读: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-allocation-explain.html7.8.6. 集群分片重路由API(reroute)
reroute 命令允许手动更改集群中各个分片的分配。
例如,可以将分片从一个节点显式移动到另一个节点,可以取消分配,
并且可以将未分配的分片显式分配给特定节点。(1)将"student"索引的0号分片从elk102节点移动到elk101节点。
POST http://10.0.0.101:9200/_cluster/reroute
{"commands": [{"move": {"index": "student","shard": 0,"from_node": "elk102","to_node": "elk101"}}]
}(2)取消当前已在某个节点上的副本分片,其副本会重新初始化分配。
POST http://10.0.0.101:9200/_cluster/reroute
{"commands": [{"cancel": {"index": "student","shard": 0,"node": "elk103"}}]
}推荐阅读:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/cluster-reroute.html
8. ES文档写入和读取流程
8.1. ES文档写入流程
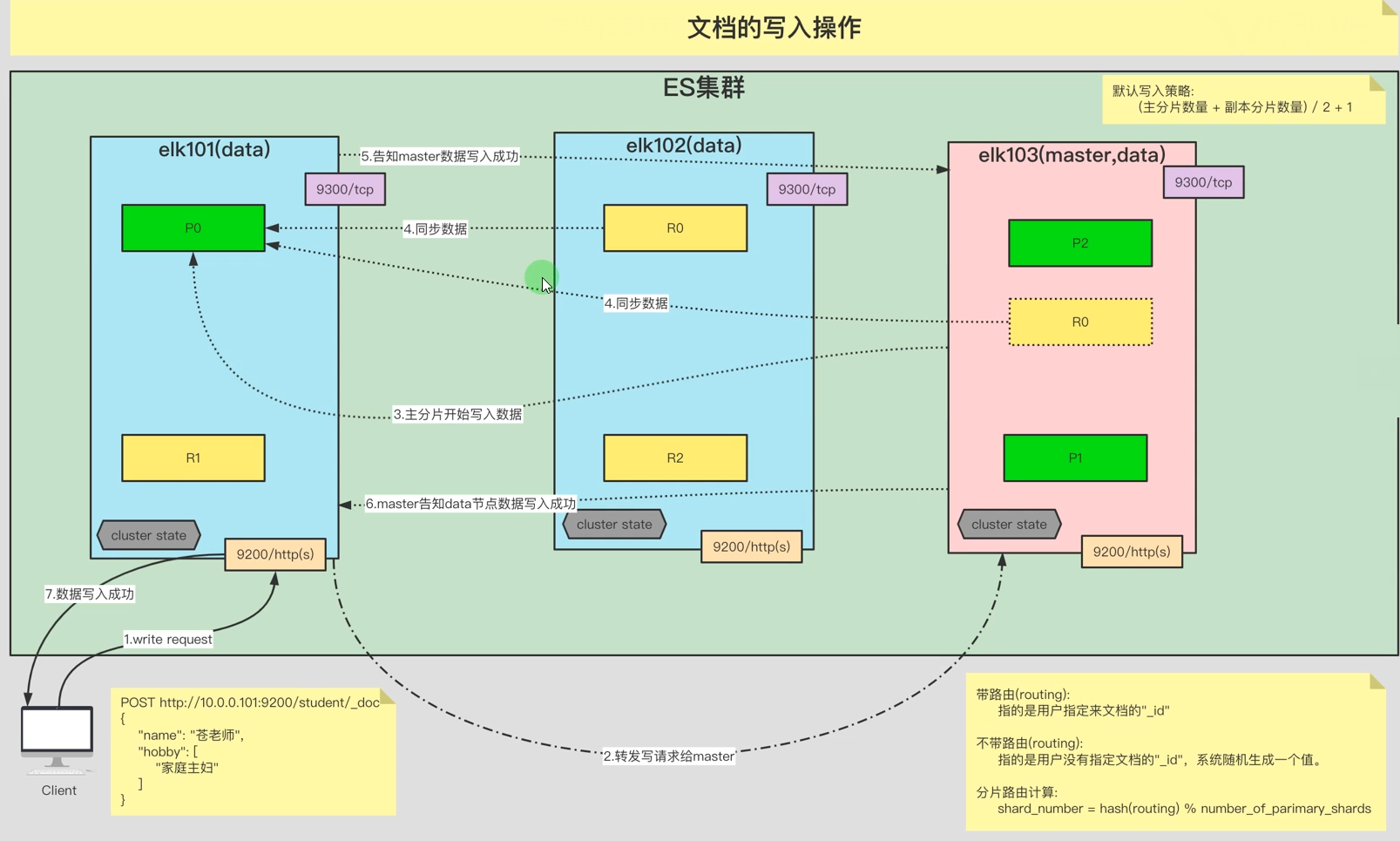
ES文档写入流程
第一步:客户端写请求给协调节点(ES的所有节点都是协调节点)
第二步:协调节点会把写请求转发给master节点
第三步:master通过分片路由计算,得出数据节点,然后就把数据写到数据节点上。
第四步:副本分片同步主分片的数据,写入成功的依据是 (主分片+副本分片)/2+1的分片数写入成功了,就算成功
第五步:数据写入成功后,通知master数据写入成功
第六步:master通知协调节点数据写入成功
第七步:协调节点通知客户端数据写入成功8.2. ES文档读取流程(单文档)
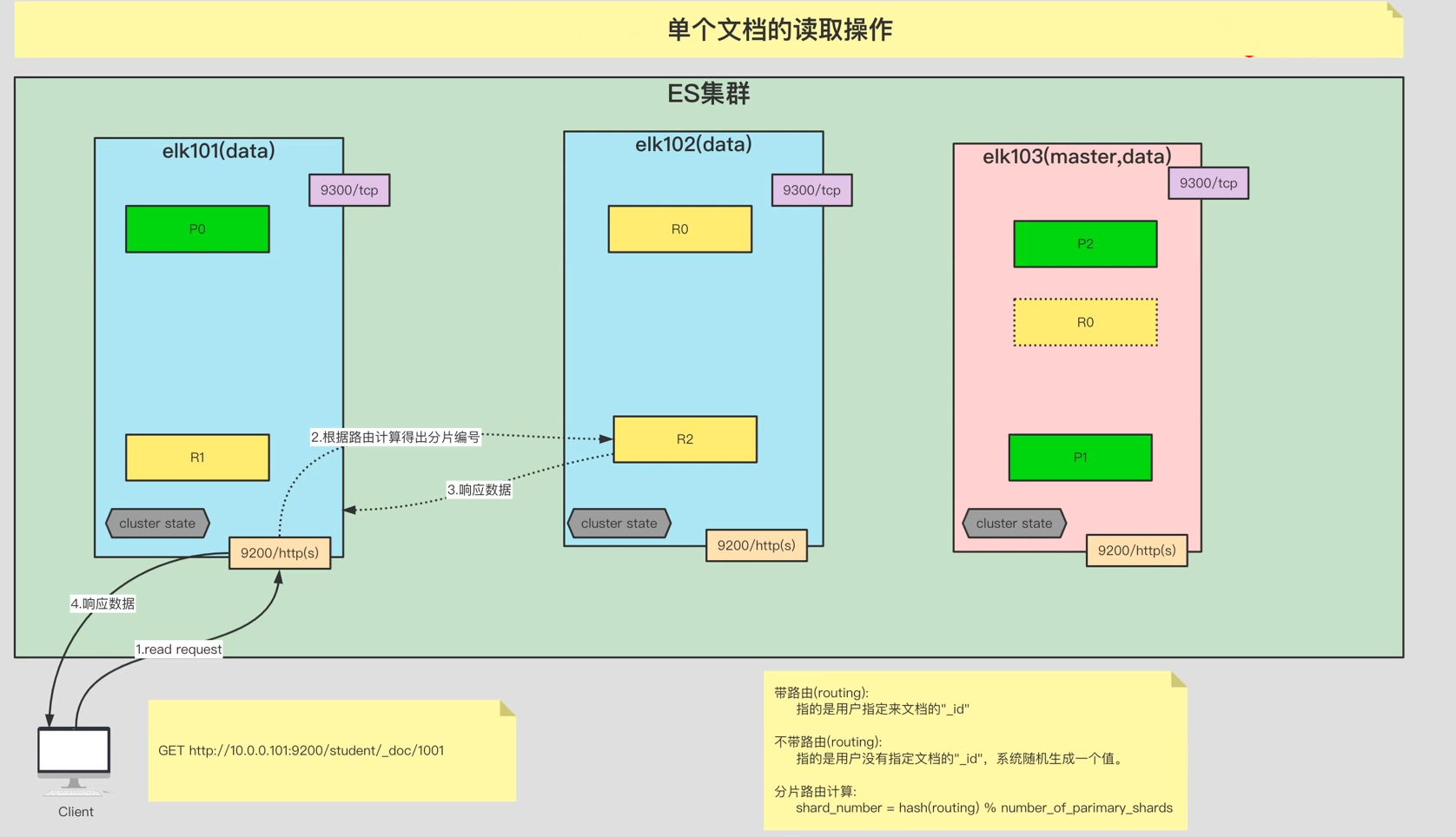
ES文档读取流程(单个文档):
第一步:客户端发送请求到协调节点。
第二步:节点通过分片路由计算,将请求路由到包含数据的主分片或者副本分片上
第三步:目标节点上的分片执行读取操作,并将数据返回给原节点。
第四步:原节点将数据返回给客户端。8.3. ES文档读取流程(全)
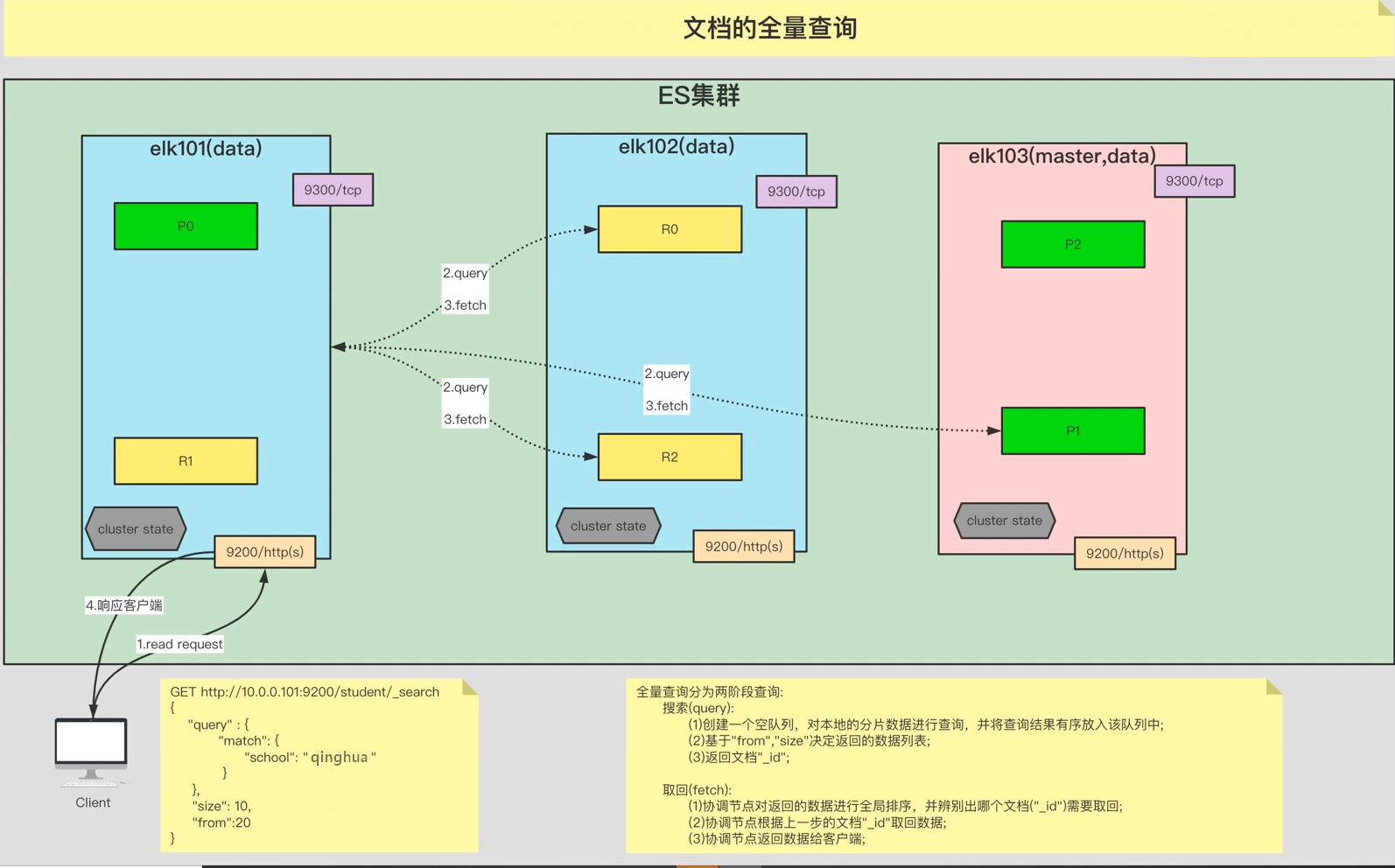
ES文档读取流程(全量查询):
第一步:客户端发送请求到协调节点。
第二步:搜索阶段(query):协调节点从各个分片上查询到的查询到的文档id,保存到一个队列
第三步:取回阶段(fetch):协调节点对返回的数据进行全局排序,根据id取出数据
第四步:协调节点将数据返回给客户端。9. ES集群TSL认证设置
在Elasticsearch中,TLS(传输层安全性)是一种加密数据传输的方法,可以提高集群的安全性。
配置ES集群TSL认证:(1)elk101节点生成证书文件
cd /data/tools/es/elasticsearch-7.17.5
./bin/elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass "" --days 36500(2)elk101节点同步证书文件到其他节点
scp config/elastic-certificates.p12 root@10.0.0.102:/data/tools/es/elasticsearch-7.17.5/config/
scp config/elastic-certificates.p12 root@10.0.0.103:/data/tools/es/elasticsearch-7.17.5/config/(3)所有节点为证书文件修改属主和属组
chown -R elastic.elastic /data/tools/es/elasticsearch-7.17.5/config/elastic-certificates.p12(4)elk101节点修改ES集群的配置文件
vim /oldboyedu/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
...
cluster.name: oldboyedu-linux85-binary
path.data: /oldboyedu/data/es7
path.logs: /oldboyedu/logs/es7
network.host: 0.0.0.0
discovery.seed_hosts: ["elk101.oldboyedu.com","elk102.oldboyedu.com","elk103.oldboyedu.com"]
cluster.initial_master_nodes: ["elk103.oldboyedu.com"]
reindex.remote.whitelist: "10.0.0.*:19200"
node.data: true
node.master: true
# 在最后一行添加以下内容
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12(5)elk101节点同步ES配置文件到其他节点
scp config/elasticsearch.yml root@10.0.0.102:/data/tools/es/elasticsearch-7.17.5/config/
scp config/elasticsearch.yml root@10.0.0.103:/data/tools/es/elasticsearch-7.17.5/config/(6)所有节点重启ES集群
systemctl restart es7(7)生成随机密码
[root@elk1 elasticsearch-7.17.5]# ./bin/elasticsearch-setup-passwords auto
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.
The passwords will be randomly generated and printed to the console.
Please confirm that you would like to continue [y/N]yChanged password for user apm_system
PASSWORD apm_system = g1gZM89D5TRR5Ug5b0jfChanged password for user kibana_system
PASSWORD kibana_system = 27uCGSOYM3iPC3CKLM3FChanged password for user kibana
PASSWORD kibana = 27uCGSOYM3iPC3CKLM3FChanged password for user logstash_system
PASSWORD logstash_system = cm7vkBpUETCNvspA5RSKChanged password for user beats_system
PASSWORD beats_system = BnOxVmGyslw8K9kh4HG8Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = GalMty6IrqPn9xV3a2hDChanged password for user elastic
PASSWORD elastic = JEVB5iv4SV4m2uerl8yN(8)测试用户名密码:
[root@elk1]# curl -u elastic:JEVB5iv4SV4m2uerl8yN 10.0.0.101:9200/_cat/nodes
10.0.0.101 72 77 1 0.08 0.11 0.13 cdfhilmrstw - elk1
10.0.0.103 76 74 0 0.02 0.12 0.12 cdfhilmrstw - elk3
10.0.0.102 66 82 2 0.03 0.19 0.17 cdfhilmrstw * elk210. 使用kibana实现基于角色的权限控制
10.1. 给filebeat和logstash创建相对应的权限账户
给filebeat和logstash设置专门权限的用户写数据,不要用超级用户,否则有可能发生权限的泄露
10.1.1. 图形界面方式-创建filebeat和logstash的角色账户
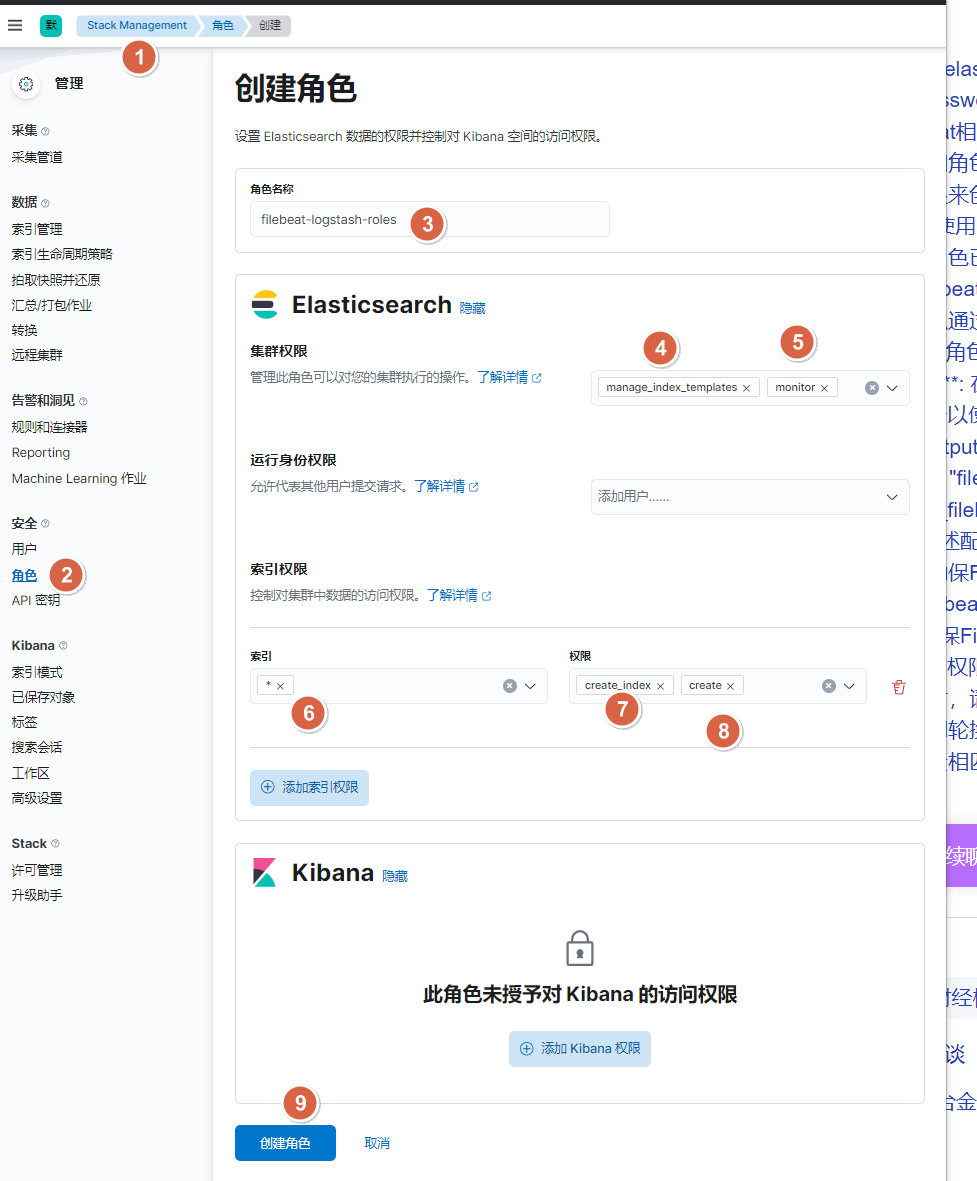
10.1.2. 图形界面方式-创建filebeat账户,logstash账户
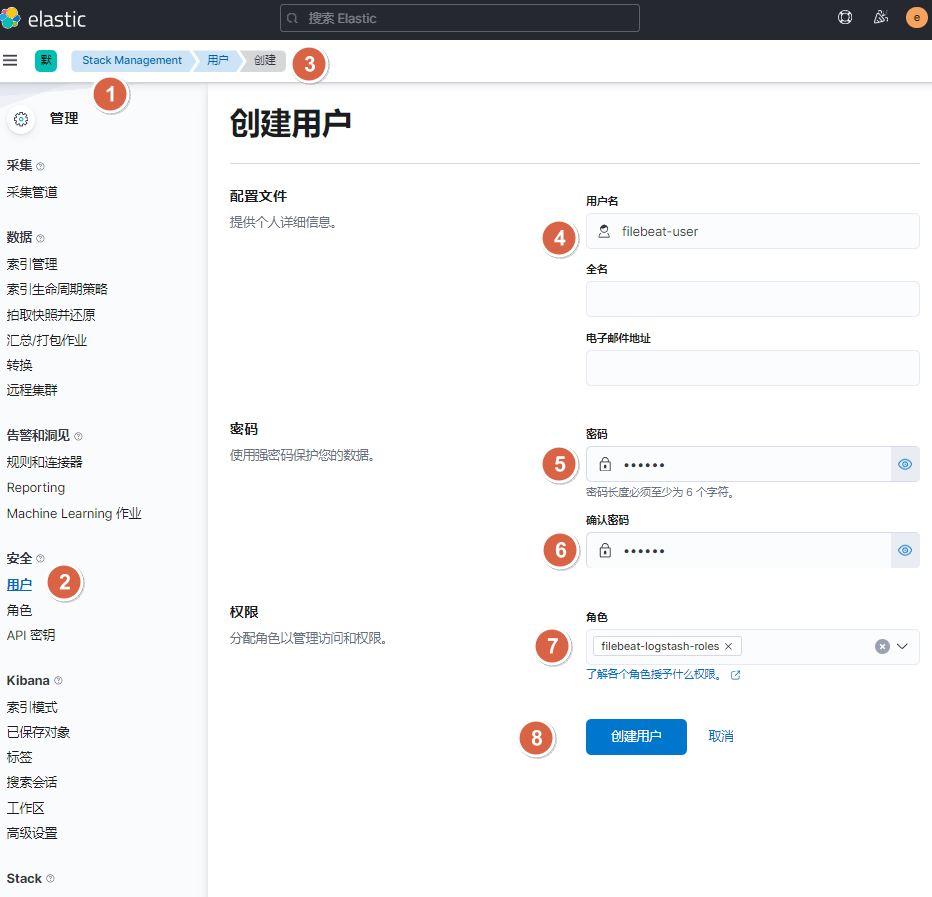
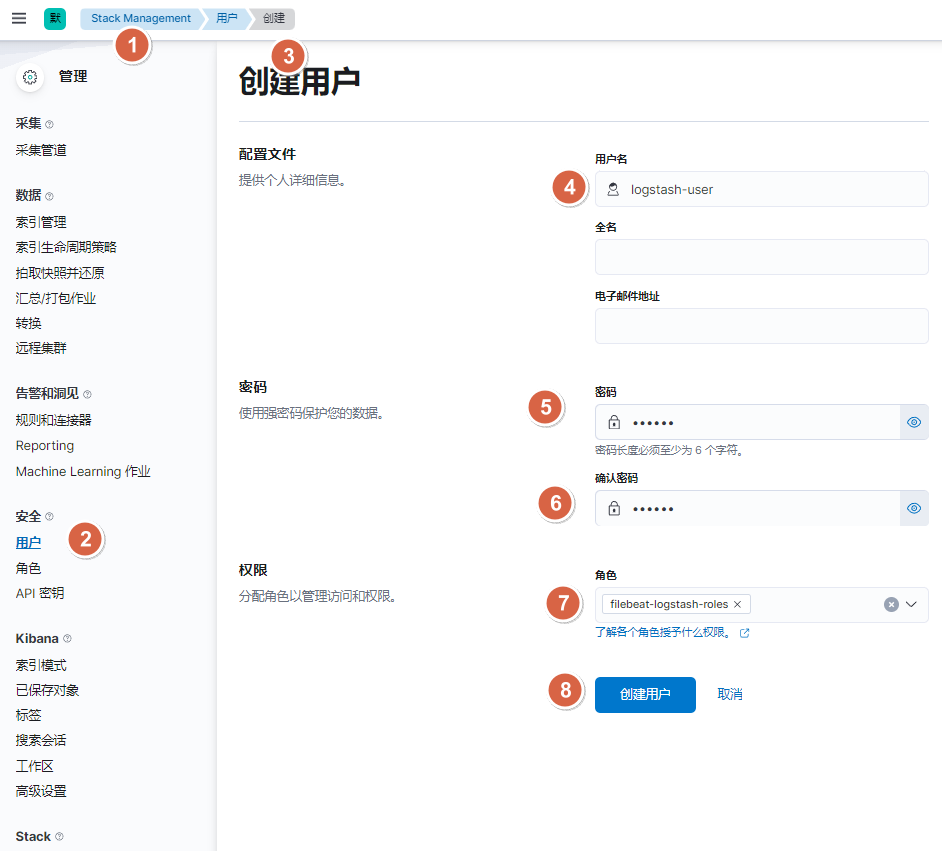
10.1.3. api接口方式-创建filebeat账户,logstash角色及用户
# 创建Filebeat角色,并授予相应的索引权限
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/role/filebeat-logstash-roles" -H "Content-Type: application/json" -d'
{"cluster" : ["manage_index_templates", "monitor"],"indices" : [ { "names" : [ "*" ], "privileges" : [ "write", "create" ] } ]
}' # 创建Filebeat用户
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/user/filebeat-user" -H "Content-Type: application/json" -d'
{"password" : "123456","roles" : [ "filebeat-logstash-roles" ],"full_name" : "Filebeat User"
}'# 创建logstash用户
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/user/logstash-user" -H "Content-Type: application/json" -d'
{"password" : "123456","roles" : [ "filebeat-logstash-roles" ],"full_name" : "logstash User"
}'#查看角色
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/role/filebeat-logstash-roles?pretty"
#查看用户
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/user/filebeat-user?pretty"10.2. 创建区分开发和运维的账户
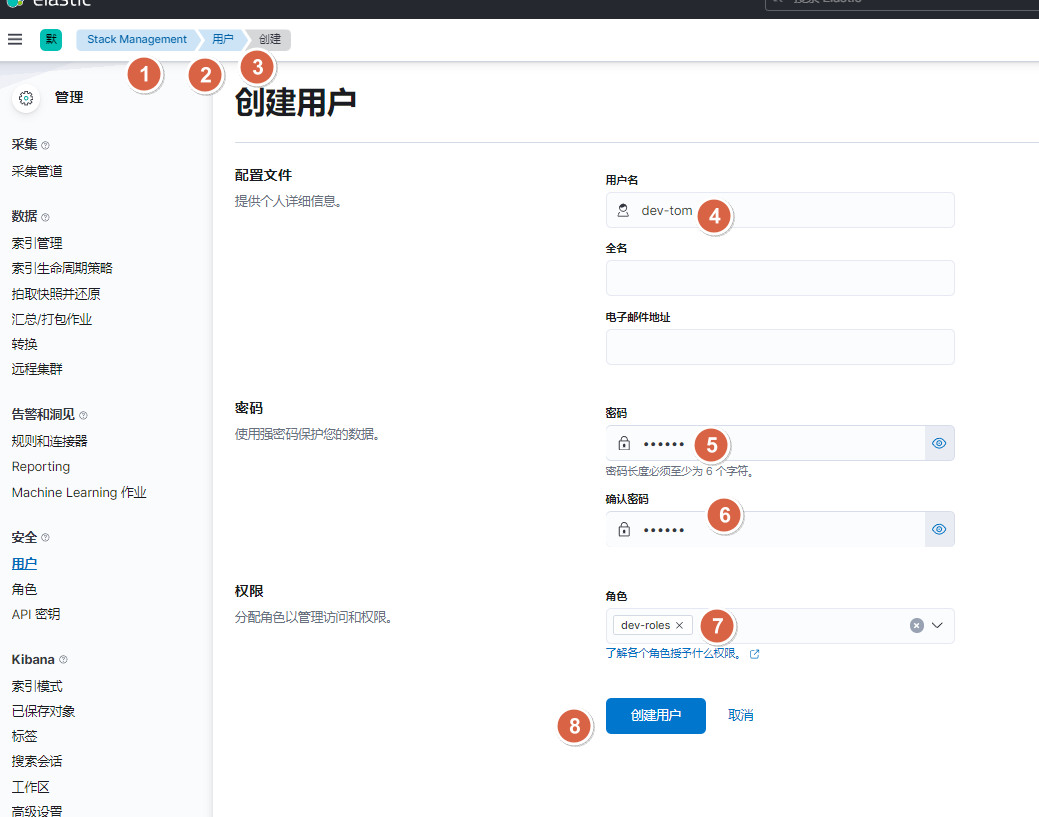
10.2.1. 图形界面方式-创建dev角色
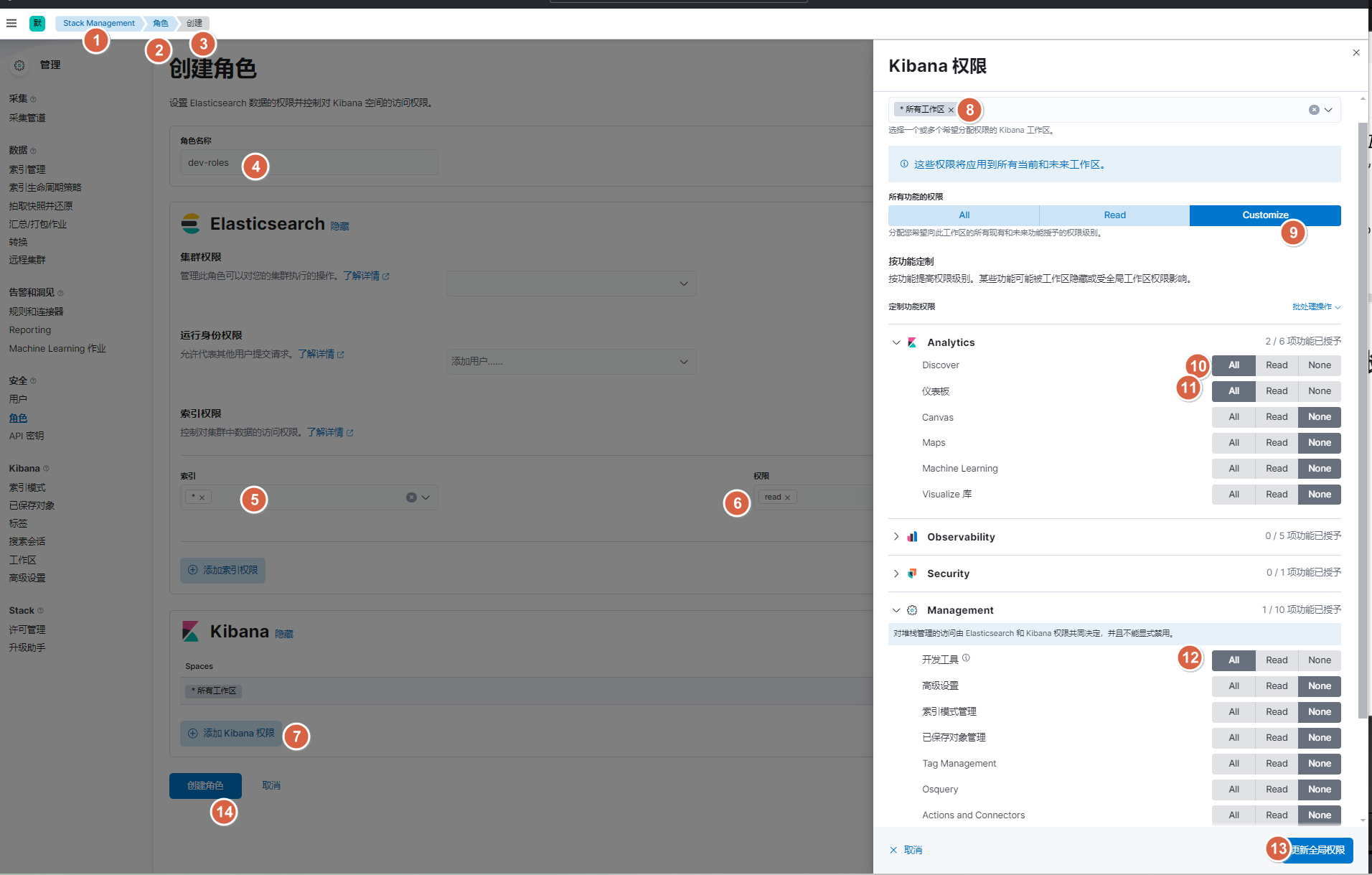
10.2.2. 图形界面方式-创建dev用户
10.2.3. api接口方式-创建dev角色及用户
# 创建dev角色
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/role/dev-roles" -H "Content-Type: application/json" -d'
{ "indices" : [ { "names" : [ "*" ], "privileges" : [ "read" ] } ],"applications" : [{"application" : "kibana-.kibana","privileges" : ["feature_discover.all","feature_dashboard.all","feature_dev_tools.all"],"resources" : ["*"]}]
}'# 创建dev用户
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/user/dev-jack" -H "Content-Type: application/json" -d'
{"password" : "123456","roles" : [ "dev-roles" ],"full_name" : "dev-jack"
}'#查看角色
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/role/dev-roles?pretty"
#查看用户
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/user/dev-jack?pretty"10.2.4. 图形界面方式-创建运维权限角色
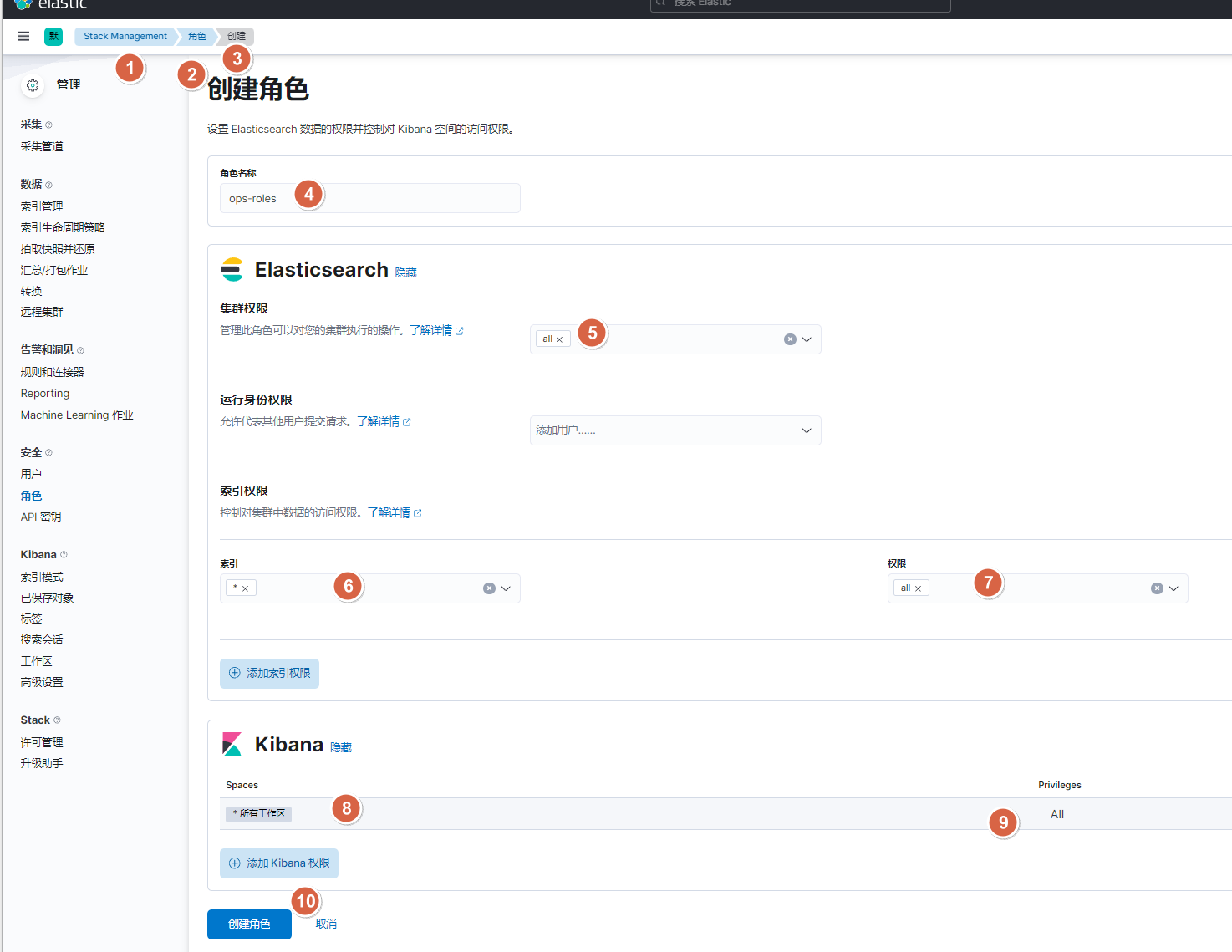
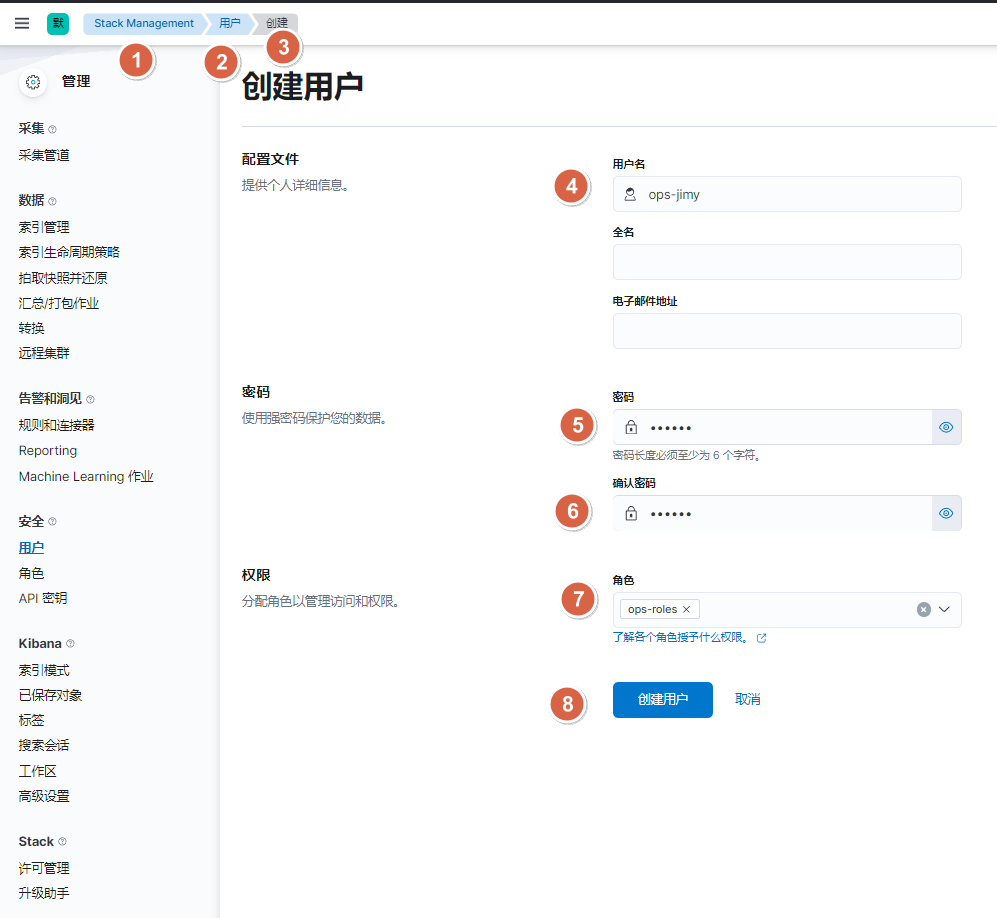
10.2.5. api接口方式-创建运维角色及用户
# 创建ops角色
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/role/ops-roles" -H "Content-Type: application/json" -d'
{ "cluster" : [ "all" ],"indices" : [ { "names" : [ "*" ], "privileges" : [ "all" ] } ],"applications" : [{"application" : "kibana-.kibana","privileges" : [ "all" ],"resources" : [ "*" ]}]
}' # 创建ops用户
curl -u elastic:123456 -XPOST "10.0.0.101:9200/_security/user/ops-jimy" -H "Content-Type: application/json" -d'
{"password" : "123456","roles" : [ "ops-roles" ],"full_name" : "ops-jimy"
}'#查看角色
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/role/ops-roles?pretty"
#查看用户
]# curl -u elastic:123456 -XGET "10.0.0.101:9200/_security/user/ops-jimy?pretty"相关文章:
elasticsearch教程
1. 单点部署(rpm): #提前关闭firewalld,否则无法组建集群 #1. 下载ES rpm包 ]# https://www.elastic.co/cn/downloads #2. 安装es ]# rpm -ivh elasticsearch-7.17.5-x86_64.rpm #3. 调整内核参数(太低的话es会启动报错) echo "vm.max_map_count655360 fs.file-max 655…...

Arrays、Lambda表达式、Collection集合
1. Arrays 1.1 操作数组的工具类 方法名说明public static String toString(数组)把数组拼接成一个字符串public static int binarySearch(数组,查找的元素)二分查找法查找元素public static int[] copyOf(原数组,新数组长度)拷贝数组public static int[] copyOfRange(原数组…...

2024年前端趋势:全栈或许是不容错过的选择!
近年来,前端开发的技术不断推陈出新,2024年也不例外。在这个变化迅速的领域,全栈开发逐渐成为一股不容忽视的趋势。无论你是经验丰富的开发者,还是刚刚入门的新手,掌握全栈技术都能让你在竞争中脱颖而出。而在这个过程…...
MySQL 实战 45 讲(01-05)
本文为笔者学习林晓斌老师《MySQL 实战 45 讲》课程的学习笔记,并进行了一定的知识扩充。 sql 查询语句的执行流程 大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。 Server 层包括连接器、查询缓存、分析器、优化器和执行器。 连接器负责接收客…...

仓颉编程语言入门 -- Array数组详解
仓颉编程语言入门 – Array数组详解 一. 如何创建Array数组 我们可以使用 Array 类型来构造单一元素类型,有序序列的数据。 1.仓颉使用 Array 来表示 Array 类型。T 表示 Array 的元素类型,T 可以是任意类型 , 类似于泛型的概念 var arr:Array<St…...

C#初级——简单单例模式使用
单例模式 单例模式是一种常用的软件设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例,通过单例模式防止私有成员被多次引用,防止数据被随意纂改。本文使用的是线程不安全的懒汉式单例。 创建单例模式 首…...

2024.07.29 校招 实习 内推 面经
地/球🌍 : neituijunsir 交* 流*裙 ,内推/实习/校招汇总表格 1、校招 | 美/团// 快驴、小象、优/选/事/业/部2024年校/园/招聘(内推) 校招 | 美团快驴、小象、优选事业部2024年校园招聘(内推ÿ…...

速盾:爬虫攻击和cc攻击的区别是什么?
爬虫攻击和CC(Distributed Denial of Service)攻击是网络安全领域两种不同类型的攻击方式。尽管它们都涉及对目标网站或服务器的非法访问,但它们的目的、方法和影响各不相同。在接下来的文章中,我们将详细介绍这两种攻击方式的区别…...

Tomcat与Nginx的区别详解
目录 引言Tomcat概述 Tomcat的历史Tomcat的架构Tomcat的功能Nginx概述 Nginx的历史Nginx的架构Nginx的功能Tomcat与Nginx的区别 架构上的区别...

【大模型从入门到精通5】openAI API高级内容审核-1
这里写目录标题 高级内容审核利用 OpenAI 内容审核 API 的高级内容审核技术整合与实施使用自定义规则增强审核综合示例防止提示注入的策略使用分隔符隔离命令理解分隔符使用分隔符实现命令隔离 高级内容审核 利用 OpenAI 内容审核 API 的高级内容审核技术 OpenAI 内容审核 AP…...

JVM系列 | 对象的消亡3——垃圾收集器的对比与实现细节
垃圾收集器 文章目录 各收集器简单对比收集器启动参数各收集器详细说明JDK 1.3 之前JDK 1.3 | SerialJDK 1.4 | ParNewJDK 1.4 | Parallel ScavengeJDK 5 | CMS 收集器JDK 7 | G1 各收集器简单对比 收集器名称出现时间淘汰时间目标采用技术线程数STW分代备注无名JDK 1.3之前JD…...

C# Unity 面向对象补全计划 七大原则 之 开闭原则(OCP) 难度:☆ 总结:已经写好的就别动它了,多用继承
本文仅作学习笔记与交流,不作任何商业用途,作者能力有限,如有不足还请斧正 本系列作为七大原则和设计模式的进阶知识,看不懂没关系 请看专栏:http://t.csdnimg.cn/mIitr,查漏补缺 1.开闭原则(OC…...

微信防封指南请收好
一、新号与老号的添加限制 建议新注册的微信号主动添加好友的数量不宜过多,推荐每日添加不超过5个好友;对于老号,建议每日添加不超过20个好友。保持适度的添加速度,避免被系统判定为异常操作。 二、避免使用营销性词汇 在发送消…...

选择排序算法改进思路和算法实现
选择排序 在未排序的数组中,用第一个数去和后面的数比较,找出最小的数,和第一个数交换。第一个数已为已排序的数。 相当于0~7 从0~7中找到最小的数放在0 从1~7中找到最小的数放在1 从2~7中找到最小的数放在2 ...以此类推 从6~7中找到最…...

【文件解析漏洞复现】
一.IIS解析漏洞复现 1.IIS6.X 方式一:目录解析 搭建IIS环境 在网站下建立文件夹的名字为.asp/.asa 的文件夹,其目录内的任何扩展名的文件都被IIS当作asp文件来解析并执行。 访问成功被解析 方式一:目录解析 在IIS 6处理文件解…...

【STL】 vector的底层实现
1.vector的模拟代码完整实现(后面会拆分开一个一个细讲) #pragma once #include<assert.h>// 抓重点namespace bit {/*template<class T>class vector{public:typedef T* iterator;private:T* _a;size_t _size;size_t _capacity;};*/templa…...

责任链模式:解耦职责,优化请求处理
在软件设计中,如何有效地处理复杂的请求是一个重要的课题。 责任链模式(Chain of Responsibility Pattern)提供了一种解耦请求发送者和接收者的方法,使得多个对象都有机会处理请求,从而达到灵活和可扩展的设计。 什么…...

【Scene Transformer】scene transformer论文阅读笔记
文章目录 序言(Abstract)(Introduction)(Related Work)(Methods)(Scene-centric Representation for Agents and Road Graphs)(Encoding Transformer)(Predicting Probabilities for Each Futures)(Joint and Marginal Loss Formulation) (Results)(Discussion)(Questions) sce…...

ESP32在ESP-IDF环境下禁用看门狗
最近使用了一款ESP32的开发板。但在调试时发现出现许多看门狗复位事件: E (8296) task_wdt: Task watchdog got triggered. The following tasks/users did not reset the watchdog in time: E (8296) task_wdt: - IDLE (CPU 0) E (8296) task_wdt: Tasks curre…...

基于 uniapp html5plus API,怎么把图片保存到相册
要将图片保存到相册中,可以使用HTML5 API中的plus.gallery.save方法。以下是一个示例代码,展示如何将图片保存到手机相册: // 图片的URL,可以是本地路径或网络路径 var imageUrl path/to/your/image.jpg;// 调用plus.gallery.sa…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

13456
12356...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...