JVM系列 | 对象的消亡3——垃圾收集器的对比与实现细节
垃圾收集器
文章目录
- 各收集器简单对比
- 收集器启动参数
- 各收集器详细说明
- JDK 1.3 之前
- JDK 1.3 | Serial
- JDK 1.4 | ParNew
- JDK 1.4 | Parallel Scavenge
- JDK 5 | CMS 收集器
- JDK 7 | G1
各收集器简单对比
| 收集器名称 | 出现时间 | 淘汰时间 | 目标 | 采用技术 | 线程数 | STW | 分代 | 备注 |
|---|---|---|---|---|---|---|---|---|
| 无名 | JDK 1.3之前 | JDK 1.3 | 无 | 标记清除 | 1 | 是 | 不分代 | |
| Serial | JDK 1.3 | 至今仍作为客户端默认的收集器 | 无 | 标记复制 | 1 | 是 | 新生代/老年代 | 由于简单而高效,仍作为客户端系统的默认垃圾收集器。 |
| ParNew | JDK 1.4 | 自JDK9开始只能与CMS搭配只用 | 高效的回收垃圾 | 标记复制 | 默认与核心线程数一样多 | 是 | 新生代 | 可以看做是Serial的多线程版本 |
| Parallel Scavenge | JDK 1.4 | 至今仍活跃,尤其是需要吞吐量的场景,如大量计算等 | 最大吞吐量 | 标记复制 | 默认与核心线程数一样多 | 是 | 新生代 | 吞吐量优先收集器(吞吐量需满足下方公式) |
| CMS | JDK 5 | JDK9标记为过时/JDK14被正式移除 | 最短回收停顿时间 | 标记清除 | (处理器核心数量+3)/4 | 否 | 老年代 | 第一个可以与用户线程同时工作的垃圾收集器,工作时长更长了,但是用户线程停顿更短饿了 |
| Serial Old | 不明确/1.2之前 | JDK之前与Parallel Scavenge,现在一般作为CMS失败的备用方案 | 无 | 标记整理 | 1 | 是 | 老年代 | Serial的老年版 |
| Parallel Old | JDK 6 | 至今 | 最大吞吐量 | 标记整理 | N | 是 | 老年代 | Parallel Scavenge的老年斑 |
| G1/Garbage First | JDK 7 | 至今 | 时间可控/全功能 | 标记复制 | N | 是 | Region分区 | G1淘汰了CMS |
| Shenandoah | OpenJDK 12 | 至今 | 10毫秒内垃圾收集 | 标记整理 | N | 否 | Region分区 | RedHat开发;JDK中没有,只有OpenJDK中才有 |
| ZGC | JDK 11 | 至今 | 10毫秒内垃圾收集 | 标记整理 | N | 否 | Region分区 | 使用了读屏障、染色指针和内存多重映射等技术 |
名词解释:STW(Stop The World)指停止用户线程,该值为否则表示可以与用户线程同时进行。(也许不是整个清理阶段都与用户线程并行,可能只是其中某些阶段)
吞吐量 = 运行用户代码时间 运行用户代码时间 + 运行垃圾收集时间 吞吐量={运行用户代码时间\over{运行用户代码时间+运行垃圾收集时间}} 吞吐量=运行用户代码时间+运行垃圾收集时间运行用户代码时间
收集器启动参数
在本部分中有一些启动项目的命令,这里采用Github开源项目·Zfile进行示例。
| 收集器名称 | 启动该收集器 |
|---|---|
| Serial | -XX:+UseSerialGC |
| ParNew | -XX:+UseParNewGC |
| Parallel Scavenge | -XX:+UseParallelGC |
| CMS | -XX:+UseConcMarkSweepGC |
| Serial Old | 使用Serial收集器时,会自动启动Serial Old收集器 |
| Parallel Old | -XX:+UseParallelOldGC |
| G1/Garbage First | -XX:+UseG1GC |
| Shenandoah | -XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC |
# Serial
java -XX:+UseSerialGC -jar zfile.jar# ParNew
java -XX:+UseParNewGC -jar zfile.jar # ParNew + CMS
java -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -jar zfile.jar# Parallel Scavenge
java -XX:+UseParallelGC -jar zfile.jar
java -XX:+UseParallelGC -XX:GCTimeRatio=1 -jar zfile.jar # 垃圾收集器占比不超过1%
java -XX:+UseParallelGC -XX:+UseAdaptiveSizePolicy -jar zfile.jar # 虚拟机优化内存# CMS
java -XX:+UseConcMarkSweepGC -jar zfile.jar# Parallel Old收集器
java -XX:+UseParallelOldGC -jar zfile.jar# G1
java -XX:+UseG1GC -jar zfile.jar# Shenandoah | 由于现在还在测试阶段,需要使用 -XX:+UnlockExperimentalVMOptions
java -XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC -jar zfile.jar
各收集器详细说明
JDK 1.3 之前
JDK 1.3 之前并没有一个真正像样的垃圾收集器(据说Serial Old是1.2之前出现的,其余不详),那个时代的垃圾收集器甚至没有一个名字,资料只能搜索到“标记-清除垃圾收集器”,很明显是基于标记清除算法实现的,特点是单线程,需要停止用户线程,没有分代,效率低下等…
JDK 1.3 | Serial
Serial收集器采用标记-清除算法,单线程处理,在进行垃圾收集的时候必须停止用户线程(STW/Stop The World),Serial收集的比较“慢”,这也是一开始都诟病Java慢的主要原因。
但是,Serial的优点是简单,它不需要太多的内存空间,也没有线程切换的资源消耗,就像是一个扫地僧一样默默地进行着自己的工作。而且虽然“慢”,但是一般来说也就只有几十~上百毫秒,虽然这个时间对于服务端程序来说可能十分宝贵,但是对于客户端程序来说无伤大雅,可能你使用的Java App一直每隔一段时间暂停几十毫秒,而你根本察觉不到。正是由于它简单(不消耗太多内存等)高效(相对于其它多线程版本的一条线程来说),所以Serial被广泛使用在客户端程序中。
Serial收集器的工作过程如下(图片来源于《深入理解Java虚拟机》):

可以看出,每次需要进行垃圾收集的时候,都需要停顿用户线程,且每次只有一个线程在进行垃圾收集
JDK 1.4 | ParNew
ParNew收集器是Serial收集器的多线程版本,在操作上除了是采用多线程的方式来进行的以外,其余与Serial区别不大。需要注意的是:由于ParNew还需要有现成切换的成本,所以其单线程的效率是比Serial低的,也就是说核心数为1时,其工作效率不如Serial收集器。
所以ParNew收集器更适合于核心线程数尚且客观(4~6个)的一些老项目中。
JDK 1.4 | Parallel Scavenge
吞吐量公式说明
Parallel Scavenge是一款吞吐量收集器,主要关注程序的吞吐量,首先了解下吞吐量计算公式:
吞吐量 = 运行用户代码时间 运行用户代码时间 + 运行垃圾收集时间 吞吐量={运行用户代码时间\over{运行用户代码时间+运行垃圾收集时间}} 吞吐量=运行用户代码时间+运行垃圾收集时间运行用户代码时间
如果程序运行需要99毫秒,垃圾回收需要1毫秒,那么吞吐量就是 99/(1 + 99) = 99%。
相关参数
我们可以通过下面一些指令来控制吞吐量,也可以直接控制最大垃圾收集停顿时间等,或者直接将这些参数交给虚拟机来进行控制。
| 指令 | 接收参数 | 说明 |
|---|---|---|
-XX:MaxGCPauseMillis | 大于0的毫秒数 | 控制最大垃圾收集停顿时间 |
-XX:GCTimeRatio | 大于0小于100的整数,也就是垃圾收集时间占总时间的比率 | 直接设置吞吐量大小 |
-XX:+UseAdaptiveSizePolicy | 允许虚拟机自动对内存进行调优,从而控制吞吐量 |
JDK 5 | CMS 收集器
CMS简介
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用集中在互联网网站或者基于浏览器的B/S系统的服务端上,这类应用通常都会较为关注服务的响应速度,希望系统停顿时间尽可能短,以给用户带来良好的交互体验。CMS收集器就非常符合这类应用的需求。
CMS收集器采用标记清除算法,其工作分为四个步骤:
-
初始标记:初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快
-
并发标记(CMS concurrent mark) 与用户线程同时:并发标记阶段就是从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行
-
重新标记(CMS remark):重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间通常会比初始标记阶段稍长一些,但也远比并发标记阶段的时间短
-
并发清除(CMS concurrent sweep) 与用户线程同时:最并发清除阶段,清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发的
并发清除一定会面临两个问题:浮动垃圾与消失对象问题,CMS采用的是增量更新的解决方案,在之前的博客中已经介绍过了,请点此查看。
CMS的缺点
-
**处理器资源敏感:**CMS默认启动的回收线程数是(处理器核心数量+3)/4,也就是说,如果处理器核心数在四个或以上,并发回收时垃圾收集线程只占用不超过25%的处理器运算资源,并且会随着处理器核心数量的增加而下降。但是当处理器核心数量不足四个时,CMS对用户程序的影响就可能变得很大。如果应用本来的处理器负载就很高,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然大幅降低
-
Full GC问题:由于CMS收集器无法处理“浮动垃圾”(Floating Garbage),有可能出现“Concurrent Mode Failure”失败进而导致另一次完全“Stop The World”的Full GC的产生(我的理解是由于浮动垃圾的存在导致浪费了一定的空间,并且垃圾收集过程中用户线程还在继续,还在产生新的垃圾,最终内存空间不足导致直接触发FullGC)。因此CMS一般会在内存空间达到一定阈值后直接进行垃圾回收,JDK5默认是68%,JDK6默认为92%,可以通过
-XX:CMSInitiatingOccupancyFraction调整阈值大小。 -
空间碎片问题:由于CMS是基于标记清除算法进行工作的,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很多剩余空间,但就是无法找到足够大的连续空间来分配当前对象,而不得不提前触发一次Full GC的情况。
CMS运行示意图

JDK 7 | G1
G1收集器具有里程碑式意义,它开创了收集器面向局部收集的设计思路和基于Region的内存布局形式。简单来说,传统的垃圾收集器都是一个老年代,一个新生代,老年代用来存放存活时间较长的对象(或一些大对象),新生代用来存放新对象。而G1收集器采用的是
在G1收集器出现之前的所有其他收集器,包括CMS在内,垃圾收集的目标范围要么是整个新生代(Minor GC),要么就是整个老年代(Major GC),再要么就是整个Java堆(Full GC)。而G1跳出了这个樊笼,它可以面向堆内存任何部分来组成回收集(Collection Set,一般简称CSet)进行回收,衡量标准不再是它属于哪个分代,而是哪块内存中存放的垃圾数量最多,回收收益最大,这就是G1收集器的Mixed GC模式。
简单来说,G1收集器不再是传统的老年代与新生代,而是将连续的Java堆划分为多个大小相等的独立区域(Region),每一个Region都可以根据需要扮演老年代、新生代的角色。G1收集器会根据
Region是最小的的单位,每次垃圾收集的内存空间一定是Region的整数倍。G1会根据回收收益情况,判断回收哪些Region空间。
Region中还有一类特殊的Humongous区域,**专门用来存储大对象。**G1认为只要大小超过了一个Region容量一半的对象即可判定为大对象。每个Region的大小可以通过参数-XX:G1HeapRegionSize设定,取值范围为1MB~32MB,且应为2的N次幂。而对于那些超过了整个Region容量的超级大对象,将会被存放在N个连续的Humongous Region之中,G1的大多数行为都把Humongous Region作为老年代的一部分来进行看待。

产生的问题与解决方案
**跨区引用问题:**每个Region都维护有自己的记忆集,这些记忆集会记录下别的Region指向自己的指针,并标记这些指针分别在哪些卡页的范围之内。G1的记忆集在存储结构的本质上是一种哈希表,Key是别的Region的起始地址,Value是一个集合,里面存储的元素是卡表的索引号。这种“双向”的卡表结构(卡表是“我指向谁”,这种结构还记录了“谁指向我”)比原来的卡表实现起来更复杂,同时由于Region数量比传统收集器的分代数量明显要多得多,因此G1收集器要比其他的传统垃圾收集器有着更高的内存占用负担。
**收集线程与用户线程互不干扰的运行:**首先要解决的是用户线程改变对象引用关系时,必须保证其不能打破原本的对象图结构,导致标记结果出现错误(见《HotSpot实现细节-原是快照》);此外,垃圾收集对用户线程的影响还体现在回收过程中新创建对象的内存分配上,程序要继续运行就肯定会持续有新对象被创建,G1为每一个Region设计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上。G1收集器默认在这个地址以上的对象是被隐式标记过的,即默认它们是存活的,不纳入回收范围。与CMS中的“Concurrent Mode Failure”失败会导致Full GC类似,如果内存回收的速度赶不上内存分配的速度,G1收集器也要被迫冻结用户线程执行,导致Full GC而产生长时间“Stop The World”。
**怎样建立起可靠的停顿预测模型?**用户通过-XX:MaxGCPauseMillis参数指定的停顿时间只意味着垃圾收集发生之前的期望值,但G1收集器要怎么做才能满足用户的期望呢?G1收集器的停顿预测模型是以衰减均值(Decaying Average)为理论基础来实现的,在垃圾收集过程中,G1收集器会记录每个Region的回收耗时、每个Region记忆集里的脏卡数量等各个可测量的步骤花费的成本,并分析得出平均值、标准偏差、置信度等统计信息。这里强调的“衰减平均值”是指它会比普通的平均值更容易受到新数据的影响,平均值代表整体平均状态,但衰减平均值更准确地代表“最近的”平均状态。换句话说,Region的统计状态越新越能决定其回收的价值。然后通过这些信息预测现在开始回收的话,由哪些Region组成回收集才可以在不超过期望停顿时间的约束下获得最高的收益。
回收过程
-
**初始标记(Initial Marking):**仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
-
**并发标记(Concurrent Marking):**从GC Root开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。当对象图扫描完成以后,还要重新处理SATB记录下的在并发时有引用变动的对象。
-
**最终标记(Final Marking):**对用户线程做另一个短暂的暂停,用于处理并发阶段结束后仍遗留下来的最后那少量的SATB记录。
-
**筛选回收(Live Data Counting and Evacuation):**负责更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多条收集器线程并行完成的。

相关文章:
JVM系列 | 对象的消亡3——垃圾收集器的对比与实现细节
垃圾收集器 文章目录 各收集器简单对比收集器启动参数各收集器详细说明JDK 1.3 之前JDK 1.3 | SerialJDK 1.4 | ParNewJDK 1.4 | Parallel ScavengeJDK 5 | CMS 收集器JDK 7 | G1 各收集器简单对比 收集器名称出现时间淘汰时间目标采用技术线程数STW分代备注无名JDK 1.3之前JD…...

C# Unity 面向对象补全计划 七大原则 之 开闭原则(OCP) 难度:☆ 总结:已经写好的就别动它了,多用继承
本文仅作学习笔记与交流,不作任何商业用途,作者能力有限,如有不足还请斧正 本系列作为七大原则和设计模式的进阶知识,看不懂没关系 请看专栏:http://t.csdnimg.cn/mIitr,查漏补缺 1.开闭原则(OC…...

微信防封指南请收好
一、新号与老号的添加限制 建议新注册的微信号主动添加好友的数量不宜过多,推荐每日添加不超过5个好友;对于老号,建议每日添加不超过20个好友。保持适度的添加速度,避免被系统判定为异常操作。 二、避免使用营销性词汇 在发送消…...

选择排序算法改进思路和算法实现
选择排序 在未排序的数组中,用第一个数去和后面的数比较,找出最小的数,和第一个数交换。第一个数已为已排序的数。 相当于0~7 从0~7中找到最小的数放在0 从1~7中找到最小的数放在1 从2~7中找到最小的数放在2 ...以此类推 从6~7中找到最…...

【文件解析漏洞复现】
一.IIS解析漏洞复现 1.IIS6.X 方式一:目录解析 搭建IIS环境 在网站下建立文件夹的名字为.asp/.asa 的文件夹,其目录内的任何扩展名的文件都被IIS当作asp文件来解析并执行。 访问成功被解析 方式一:目录解析 在IIS 6处理文件解…...

【STL】 vector的底层实现
1.vector的模拟代码完整实现(后面会拆分开一个一个细讲) #pragma once #include<assert.h>// 抓重点namespace bit {/*template<class T>class vector{public:typedef T* iterator;private:T* _a;size_t _size;size_t _capacity;};*/templa…...

责任链模式:解耦职责,优化请求处理
在软件设计中,如何有效地处理复杂的请求是一个重要的课题。 责任链模式(Chain of Responsibility Pattern)提供了一种解耦请求发送者和接收者的方法,使得多个对象都有机会处理请求,从而达到灵活和可扩展的设计。 什么…...

【Scene Transformer】scene transformer论文阅读笔记
文章目录 序言(Abstract)(Introduction)(Related Work)(Methods)(Scene-centric Representation for Agents and Road Graphs)(Encoding Transformer)(Predicting Probabilities for Each Futures)(Joint and Marginal Loss Formulation) (Results)(Discussion)(Questions) sce…...

ESP32在ESP-IDF环境下禁用看门狗
最近使用了一款ESP32的开发板。但在调试时发现出现许多看门狗复位事件: E (8296) task_wdt: Task watchdog got triggered. The following tasks/users did not reset the watchdog in time: E (8296) task_wdt: - IDLE (CPU 0) E (8296) task_wdt: Tasks curre…...

基于 uniapp html5plus API,怎么把图片保存到相册
要将图片保存到相册中,可以使用HTML5 API中的plus.gallery.save方法。以下是一个示例代码,展示如何将图片保存到手机相册: // 图片的URL,可以是本地路径或网络路径 var imageUrl path/to/your/image.jpg;// 调用plus.gallery.sa…...

3.特征工程-特征抽取、特征预处理、特征降维
文章目录 环境配置(必看)头文件引用1.数据集: sklearn代码运行结果 2.字典特征抽取: DictVectorizer代码运行结果稀疏矩阵 3.文本特征抽取(英文文本): CountVectorizer()代码运行结果 4.中文文本分词(中文文本特征抽取使用)代码运行结果 5.中文文本特征抽…...

RISC-V (五)上下文切换和协作式多任务
任务(task) 所谓的任务就是寄存器的当前值。 -smp后面的数字指的是hart的个数,qemu模拟器最大可以有8个核,此文围绕一个核来讲。 QEMU qemu-system-riscv32 QFLAG -nographic -smp 1 -machine virt -bios none 协作式多任务 …...
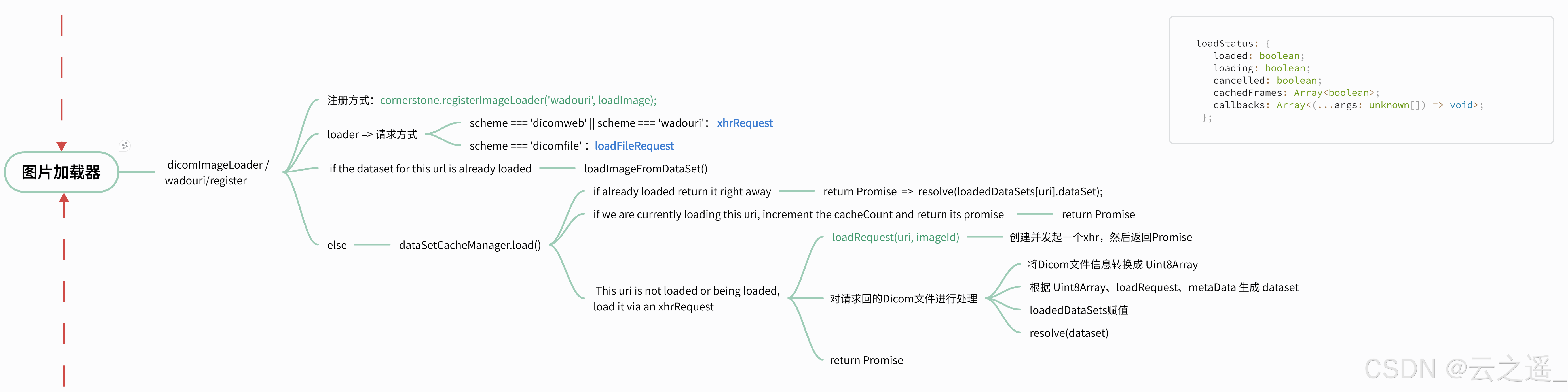
Cornerstone加载本地Dicom文件第二弹 - Blob篇
🍀 引言 当我们刚接触Cornerstone或拿到一组Dicom文件时,如果没有ImageID和后台接口,可能只是想简单测试Cornerstone能否加载这些Dicom文件。在这种情况下,可以使用本地文件加载的方法。之前我们介绍了通过node启动服务器请求文件…...

C语言中整数类型及其类型转换
1.数据的存储和排列 是的,在C语言中,整数类型通常以补码(twos complement)形式存储在内存中。这是因为补码表示法在处理有符号整数的加减运算上更为简便和高效。 2.有符号数和无符号数之间的转换 在C语言中,有符号数和…...

powerjob连接postgresql数据库(支持docker部署)
1.先去pg建一个powerjob-product库 2.首先去拉最新的包,然后找到server模块,把mysql的配置文件信息替换成pg的 spring.datasource.hikari.auto-committrue spring.datasource.remote.hibernate.properties.hibernate.dialecttech.powerjob.server.pers…...
)
浅谈位运算及其应用(c++)
目录 一、位运算的基础(一)位与(&)(二)位或(|)(三)位异或(^)(四)位取反(~)&#x…...

Git版本管理中下列不适于Git的本地工作区域的是
Git版本管理中下列不适于Git的本地工作区域的是 A. 工作目录 B. 代码区 C. 暂存区 D. 资源库 选择B Git本地有四个工作区域: 工作目录(Working Directory)、 暂存区(Stage/Index)、 资源库(Repository或Git Directory)、 git仓库(Remote Di…...

webGL + WebGIS + 数据可视化
webGL: 解释:用于在浏览器中渲染 2D 和 3D 图形。它是基于 OpenGL ES 的,提供了直接操作 GPU 的能力。 库: Three.jsBabylon.jsPixiJSReglGlMatrixOsgjs WebGIS: 解释:用于在 Web 浏览器中处理和展示地…...

职场“老油条”的常规操作,会让你少走许多弯路,尤其这三点
有句话说得好:“在成长的路上,要么受教育,要么受教训。” 挨过打才知道疼,吃过亏才变聪明,从职场“老油条”身上能学到很多经验,不一定全对,但至少有可以借鉴的地方,至少能让你少走…...

Ceres Cuda加速
文章目录 一、简介二、准备工作三、实现代码四、实现效果参考资料一、简介 字Ceres2.2.1版本之后,作者针对于稠密矩阵的分解计算等操作进行了Cuda加速,因此这里就基于此项改动测试一下效果。 二、准备工作 1、首先是需要安装Cuda这个英伟达第三方库,https://developer.nvidi…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...