Elasticsearch 的DSL查询,聚合查询与多维度数据统计
文章目录
-
- 搜索
- 聚合
- 高阶概念
搜索
即从一个索引下按照特定的字段或关键词搜索出符合用户预期的一个或者一堆cocument,然后根据文档的相关度得分,在返回的结果集里并根据得分对这些文档进行一定的排序。
聚合
根据业务需求,对文档中的某个或某几个字段进行数据的分组并做一些指标数据的统计分析,比如要计算一批文档中某个业务字段的总数,平均数,最大最小值等,都属于聚合的范畴。
以上两个概念后是理解下面实验的基础,如果是传统关系数据库mysql、oracle等存储的数据,也可以搜索和聚合,但是在数据聚合分析一块,毕竟不是它们的强项,而且需要在程序中做大量的处理,耗时费力,尤其是大数据量的情况下就有些力不从心了。
但在es中,由于内置了聚合统计的相关功能,只需要使用好它的语法即可达到几近实时的聚合统计,和搜索花费时间基本上没有太大差别,因此使用es很适合在数据量大的业务场景下做聚合统计与分析。
高阶概念
- Buckets(桶/集合):满足特定条件的文档的集合
- Metrics(指标):对桶内的文档进行统计计算(例如最小值,求和,最大值等)
在聚合统计分析中,使用很频繁的一个名词叫 aggs,它是聚合的关键词之一,下面就用实验来演示一下使用aggs进行数据聚合的多种场景。
1、实验准备数据,首先往es整合批量插入一些实验数据,这里我们以一个家电卖场的电视为背景进行模拟
设定文档中field的相关分词属性。
PUT http://192.168.56.235:9201/demo2{"setting":{"index":{"number_of_shards":5,"number_of_replicats":1}},"mappings":{"sales":{"properties":{"price":{"type":"long"},"color":{"type":"keyword"},"brand":{"type":"keyword"},"sold_date":{"type":"date"}}}}
}2、批量插入数据
POST http://192.168.56.235:9201/demo2/sales{ "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-10-28" }
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" }
{ "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2017-05-18" }
{ "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2017-07-02" }
{ "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2018-08-19" }
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2017-11-05" }
{ "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2017-01-01" }
{ "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2018-02-12" }
数据准备完毕

2、按照颜色分组统计各种颜色电视的数量
查询语法如下:
GET http://192.168.56.235:9201/demo2/sales/_search
{"size":0,"aggs":{"group_color":{"terms":{"field":"color"}}}
}查询结果如下,这里简单对其中的几个参数和结果名称做一下说明。
在查询语句中:
size:0表示聚合查询的结果不需要返回中间的文档内容,group_color我们自定义的分组名字,最好是见名知意的
在返回结果中:
hits:{},这部分存放的是返回结果的基本统计结果,如果上面的size制指定了不为0,文档内容则会放在这个里面buckets:存放聚合后的统计结果详细信息,以key-value的形式展现

3、按照颜色分组统计各种颜色电视的数量,并在此基础上,统计出各种颜色电视的平均价格
分析:
按照color去分bucket,可以拿到每个color bucket中的数量,这个仅仅只是一个bucket操作, doc_count其实只是es的bucket操作默认执行的一个内置metric。
在一个aggs执行的bucket操作(terms),平级的json结构下,再加一个aggs,这个第二个aggs内部,同样取个名字,执行一个metric操作,avg,对之前的每个bucket中的数据的指定的field、price
field,求一个平均值
就是一个metric,就是一个对一个bucket分组操作之后,对每个bucket都要执行的一个metric,也可以理解成功嵌套聚合,在es中获取到某个指标的数据后,继续对这个指标的数据进行其他聚合分析也被叫做下钻
该需求查询语句如下:
{"size":0,"aggs":{"group_color":{"terms":{"field":"color"},"aggs":{"avg_color_price":{"avg":{"field":"price"}}}}}
}返回结果如下,通过结果可以很清晰的看出来,在颜色统计分析的基础上,每一个{}里面还增加了一个指标,即自定义的计算平均值的avg_color_price,这个查询几乎是毫秒级的,基本没有延迟,如果转化为sql查询应该是这样的:
select avg(price) from tvs.sales group by color
4、根据颜色分组,求出每种颜色的电视价格的最大值,最小值,平均值
{"size":0,"aggs":{"group_by_color":{"terms":{"field":"color"},"aggs":{"max_price":{"max":{"field":"price"}},"min_price":{"min":{"field":"price"}},"avg_price":{"avg":{"field":"price"}}}}}
}所得结果如下:
{"took": 4,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 7,"max_score": 0,"hits": []},"aggregations": {"group_by_color": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "红色","doc_count": 4,"max_price": {"value": 8000},"min_price": {"value": 1000},"avg_price": {"value": 3250}},{"key": "蓝色","doc_count": 2,"max_price": {"value": 2500},"min_price": {"value": 1500},"avg_price": {"value": 2000}},{"key": "绿色","doc_count": 1,"max_price": {"value": 1200},"min_price": {"value": 1200},"avg_price": {"value": 1200}}]}}
}5、按照不同的价格区间对电视进行划分,并求出每个价格区间的电视的平均价格
在es中根据区间间隔划分,有一个叫做 histogram的语法可以帮助我们执行,类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作。
“histogram”:{“field”: “price”,“interval”: 2000
},- interval:2000,划分范围,0 ~ 2000,2000 ~ 4000,4000 ~ 6000,6000 ~ 8000,8000 ~ 10000,buckets
- 根据price的值,比如2500,看落在哪个区间内,比如2000 ~ 4000,此时就会将这条数据放入2000 ~ 4000对应的那个bucket中
- bucket划分的方法
terms,将field值相同的数据划分到一个bucket中 - bucket有了之后,一样的,去对每个bucket执行
avg,count,sum,max,min,等各种metric操作,聚合分析
{"size":0,"aggs":{"interval_price":{"histogram":{"field":"price","interval":2000},"aggs":{"revenue":{"avg":{"field":"price"}}}}}
}查询的结果如下:可以看到,按照2000一个等级将所有电视的价格划分在不同的区间了,并将每个区间的价格平均值统计了出来
{"took": 7,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 7,"max_score": 0,"hits": []},"aggregations": {"interval_price": {"buckets": [{"key": 0,"doc_count": 3,"revenue": {"value": 1233.3333333333333}},{"key": 2000,"doc_count": 3,"revenue": {"value": 2166.6666666666665}},{"key": 4000,"doc_count": 0,"revenue": {"value": null}},{"key": 6000,"doc_count": 0,"revenue": {"value": null}},{"key": 8000,"doc_count": 1,"revenue": {"value": 8000}}]}}
}6、按照不同的时间区间对电视进行划分,并求出每个价格区间的电视的平均价格
date histogram,按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket,这个概念的理解和上一个有点类似,可以对照理解。
date interval = 1 month
2017-01-01~2017-01-31,就是一个bucket
2017-02-01~2017-02-28,就是一个bucket
然后会去扫描每个数据的date field,判断date落在哪个bucket中,就将其放入那个bucket
2017-01-05,就将其放入2017-01-01~2017-01-31,就是一个bucket
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的
extended_bounds,min,max:划分bucket的时候,会限定在这个起始日期,和截止日期内
根据上述分析我们构建查询语句
{"size":0,"aggs":{"sales":{"date_histogram":{"field":"sold_date","interval":"month","format":"yyyy-MM-dd","min_doc_count":0,"extended_bounds":{"min":"2017-01-01","max":"2018-12-31"}}}}
}返回结果如下,按照月份,将指定区间内各个月份的数量做了统计

当然,如果我们觉得按照月份统计粒度太细,也可以根据季度对数据进行统计,只需要将month换成quarter即可,查询语法如下:
{"size":0,"aggs":{"sales":{"date_histogram":{"field":"sold_date","interval":"quarter","format":"yyyy-MM-dd","min_doc_count":0,"extended_bounds":{"min":"2017-01-01","max":"2018-12-31"}}}}
}查询结果如下:

相关文章:
Elasticsearch 的DSL查询,聚合查询与多维度数据统计
文章目录 搜索聚合高阶概念 搜索 即从一个索引下按照特定的字段或关键词搜索出符合用户预期的一个或者一堆cocument,然后根据文档的相关度得分,在返回的结果集里并根据得分对这些文档进行一定的排序。 聚合 根据业务需求,对文档中的某个或…...

【如何高效处理前端常见问题:策略与实践】
在快速发展的Web开发领域,前端作为用户与应用程序直接交互的界面,其重要性不言而喻。然而,随着技术的不断演进和项目的复杂化,前端开发者在日常工作中难免会遇到各种挑战和问题。本文旨在深入探讨前端开发中常见的问题类型&#x…...

聊聊前端 JavaScript 的扩展运算符 “...“ 的使用场景
前言 在 JavaScript 中,... 被称为 “扩展运算符” 或 “剩余参数运算符”。 扩展运算符是在 ES6(ECMAScript 2015)中被引入的,目的是为了提高语言的表达能力和代码的可读性。 根据上下文不同,它主要用在数组、对象…...

华为续签了,但我准备离职了
离职华为 今天在牛客网看到一篇帖子,名为《华为续签了,但我准备离职了》。 讲得挺真诚,可能也是一类毕业进华为的同学的心声。 贴主提到,当年自己还是应届毕业的时候,手握多个 offer,最终选的华为ÿ…...

RocketMQ 的认证与授权机制
Apache RocketMQ 是一个高性能、高吞吐量、分布式的消息中间件,广泛应用于异步通信、应用解耦、流量削峰等场景。在企业级应用中,消息安全尤为重要,本文将深入探讨 RocketMQ 的认证与授权机制,帮助开发者和系统管理员更好地理解和…...

【设计模式】六大原则-上
首先什么是设计模式? 相信刚上大学的你和我一样,在学习这门课的时候根本不了解这些设计原则和模式有什么用处,反而不如隔壁的C更有意思,至少还能弹出一个小黑框,给我个hello world。 如何你和我一样也是这么想…...

CRC16循环冗余校验
代码: #include<stdio.h> #include <stdint.h>#define uchar unsigned char #define uint unsigned int static const uint8_t auchCRCHi[] { 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x0…...

Mysql80主从复制搭建;遇到问题 Slave_IO_Running: Connecting和Slave_SQL_Running以及解决过程
总结主要步骤 1.配置一个提供复制的账号; 创建用户 CREATE USER replication% IDENTIFIED BY your_password; GRANT REPLICATION SLAVE ON *.* TO replication%; FLUSH PRIVILEGES;2.修改配置 选择模式 主库配置; windows的得话是my.ini文件 默认这个目…...

Yarn网络代理配置指南:在受限网络环境中优化依赖管理
Yarn是一个现代的包管理器,用于JavaScript项目,它提供了快速、可靠和安全的依赖管理方式。然而,在某些受限的网络环境中,例如公司内网或某些国家地区,直接连接到公共npm仓库可能不可行或效率低下。这时,配置…...

AOE网及其求解关键路径
全称 Activity on Edge Network 边活动网 特点 仅存在 有向无环图 作用 用于记录完成整个工程至少花费的时间 > 哪条路径最耗时?也就是“ 关键路径 ” AOE网元素介绍 关键活动 关键路径上的活动称为关键活动 , 关键活动是不允许拖延的&#x…...

【FPGA】modelsim编译verilog代码产生错误集合
错误1: LHS in procedural continuous assignment may not be a net 可能是一些变量不能放在一些begin和end中,改下assign的位置 新手求助 LHS in procedural continuous assignment may not be a net - 数字IC设计讨论(IC前端|FPGA|ASIC) - EETOP 创…...
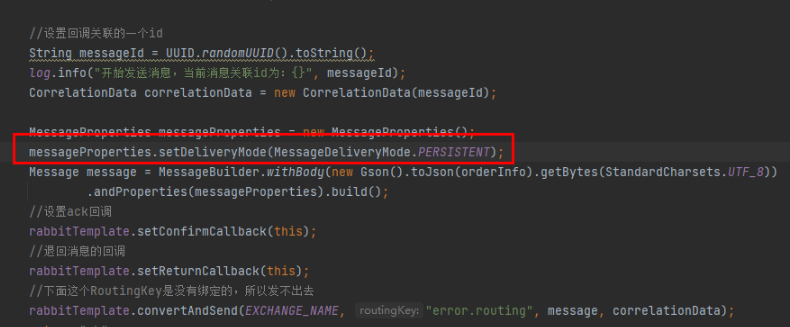
Rabbitmq的持久化机制
我们通过手动应答处理了在消费者出故障消息丢失的情况,但是如何保障当 RabbitMQ 服务停掉以后消息生产者发送过来的消息不丢失。默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它会清空队列和消息,除非告知它不要这样做。确保消息不会丢失可…...

Unity UnityWebRequest封装类
简化api调用流程,非常奈斯。 RestWebClient.cs using System; using System.Collections; using UnityEngine; using UnityEngine.Networking;namespace MYTOOL.RestClient {/// <summary>/// UnityWebRequest封装类/// </summary>public class RestW…...

JVM内存划分
Java虚拟机(JVM)的内存划分是指JVM在运行时所使用的内存区域的组织和管理方式。JVM内存主要分为以下几个区域: 堆区(Heap): 用途:用于存储所有对象实例和数组,是JVM中最大的一块内存…...

c++ 全排列
在C中,全排列(permutation)可以使用递归算法或标准库函数来实现。以下是使用递归和STL库std::next_permutation来生成一个集合的全排列的两种方法。 方法一:递归算法 递归方法通过交换元素来生成所有可能的排列组合。 #include…...
未授权访问漏洞系列详解⑤!
Kubernetes Api Server未授权访问漏洞 Kubernetes 的服务在正常启动后会开启两个端口:Localhost Port(默认8080)Secure Port(默认6443)。这两个端口都是提供 Api Server 服务的,一个可以直接通过Web 访问,另一个可以通过 kubectl 客户端进行调用。如果运…...

【CONDA】库冲突解决办法
如今,使用PYTHON作为开发语言时,或多或少都会使用到conda。安装Annaconda时一般都会选择在启动终端时进入conda的base环境。该操作,实际上是在~/.bashrc中添加如下脚本: # >>> conda initialize >>> # !! Cont…...

【网络世界】数据链路层
目录 🌈前言🌈 📁 初识数据链路层 📂 概念 📂 协议格式 📁 MAC地址 📂 概念 📂 与IP地址的区别 📁 MTU 📂 对IP协议的影响 📂 对UDP协议的影响…...

AllReduce通信库;Reduce+LayerNorm+Broadcast 算子;LayerNorm(层归一化)和Broadcast(广播)操作;
目录 AllReduce通信库 一、定义与作用 二、常见AllReduce通信库 三、AllReduce通信算法 四、总结 Reduce+LayerNorm+Broadcast 算子 1. Reduce 算子 2. LayerNorm 算子 3. Broadcast 算子 组合作用 LayerNorm(层归一化)和Broadcast(广播)操作 提出的创新方案解析 优点与潜在…...

2024.8.5 作业
使用有名管道实现,一个进程用于给另一个进程发消息,另一个进程收到消息后,展示到终端上,并且将消息保存到文件上一份 代码: /*******************************************/ 文件名:create.c /********…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

在数据预处理与分析流水线中集成大模型API进行智能标注与摘要
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理与分析流水线中集成大模型API进行智能标注与摘要 对于数据工程师而言,处理海量非结构化文本数据是一项常见…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...