【知识】pytorch中的pinned memory和pageable memory
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
概念简介
pytorch用法
速度测试
反直觉情况
概念简介

默认情况下,主机 (CPU) 数据分配是可分页的。GPU 无法直接从可分页主机内存访问数据,因此当调用从可分页主机内存到设备内存的数据传输时,CUDA 驱动程序必须首先分配一个临时的页面锁定或“固定”主机数组,将主机数据复制到固定数组,然后将数据从固定阵列传输到设备内存。
如图所示,固定内存用作从设备到主机的传输暂存区域。通过直接在固定内存中分配主机阵列,我们可以避免在可分页主机阵列和固定主机阵列之间传输的成本。使用 cudaMallocHost() 或 cudaHostAlloc() 在 CUDA C/C++ 中分配固定主机内存,并使用 cudaFreeHost() 解除分配。固定内存分配可能会失败,因此应始终检查错误。
数据传输速率可能取决于主机系统的类型(主板、CPU 和芯片组)以及 GPU。通过运行BandwidthTest会产生以下结果。可见,固定传输的速度是可分页传输的两倍多。(我的测试发现,基本上能跑满PCIe的带宽。)
Device: NVS 4200M
Transfer size (MB): 16Pageable transfersHost to Device bandwidth (GB/s): 2.308439Device to Host bandwidth (GB/s): 2.316220Pinned transfersHost to Device bandwidth (GB/s): 5.774224Device to Host bandwidth (GB/s): 5.958834不过,不应过度分配固定内存。这样做会降低整体系统性能,因为它会减少操作系统和其他程序可用的物理内存量。多少是太多是很难提前判断出来的,因此与所有优化一样,测试你的应用程序及其运行的系统以获得最佳性能参数。
用法示例
由于pinned memory后,可以使用DMA传输而不占用CPU,因此通常需要搭配non_blocking使用。
# tensor.pin_memory() 就行
pinned_tensor = torch.randn(data_size, dtype=torch.float32).pin_memory()device = torch.device("cuda")
pinned_tensor.to(device, non_blocking=True)速度测试
import torch
import time
import torch.multiprocessing as mp# 数据大小
data_size = 10**7 # 例如,10M数据def test_pinned_memory(rank, normal_tensor, pinned_tensor, device):# 测试普通内存到GPU传输时间start_time = time.perf_counter()normal_tensor_gpu = normal_tensor.to(device, non_blocking=True)torch.cuda.synchronize() # 等待数据传输完成normal_memory_time = time.perf_counter() - start_timeprint(f"[进程 {rank}] 普通内存到GPU传输时间: {normal_memory_time:.6f} 秒")# 测试固定内存到GPU传输时间start_time = time.perf_counter()pinned_tensor_gpu = pinned_tensor.to(device, non_blocking=True)torch.cuda.synchronize() # 等待数据传输完成pinned_memory_time = time.perf_counter() - start_timeprint(f"[进程 {rank}] 固定内存到GPU传输时间: {pinned_memory_time:.6f} 秒")# 比较结果speedup = normal_memory_time / pinned_memory_timeprint(f"[进程 {rank}] 固定内存的传输速度是普通内存的 {speedup:.2f} 倍")if __name__ == '__main__':# 分配普通内存中的张量normal_tensor = torch.randn(data_size, dtype=torch.float32)# 分配固定内存中的张量pinned_tensor = torch.randn(data_size, dtype=torch.float32).pin_memory()# 目标设备device = torch.device("cuda")# 使用mp.spawn启动多进程测试mp.spawn(test_pinned_memory, args=(normal_tensor, pinned_tensor, device), nprocs=2, join=True)
输出:
[进程 0] 普通内存到GPU传输时间: 1.054590 秒
[进程 0] 固定内存到GPU传输时间: 0.012945 秒
[进程 0] 固定内存的传输速度是普通内存的 81.47 倍
[进程 1] 普通内存到GPU传输时间: 1.169124 秒
[进程 1] 固定内存到GPU传输时间: 0.013019 秒
[进程 1] 固定内存的传输速度是普通内存的 89.80 倍
可以看到速度还是非常快的。
反直觉情况
我再瞎试的过程中发现,如果将pinned memory放在一个class中,那么多进程时候,pinned memory的移动很慢。暂不清楚为什么。
示例代码(反例,仅供观看,请勿使用):
import torch
import torch.multiprocessing as mp
class PinnedMemoryManager:def __init__(self, data_size):self.data_size = data_sizeself.normal_tensor = Noneself.pinned_tensor = Nonedef allocate_normal_memory(self):# 分配普通内存self.normal_tensor = torch.randn(self.data_size, dtype=torch.float32)def allocate_pinned_memory(self):# 分配固定内存self.pinned_tensor = torch.randn(self.data_size, dtype=torch.float32).pin_memory()def transfer_to_device(self, device, use_pinned_memory=False):# 选择使用普通内存或固定内存tensor = self.pinned_tensor if use_pinned_memory else self.normal_tensorif tensor is None:raise ValueError("Tensor not allocated. Call allocate_memory first.")# 数据传输start_time = torch.cuda.Event(enable_timing=True)end_time = torch.cuda.Event(enable_timing=True)start_time.record()tensor_gpu = tensor.to(device, non_blocking=True)end_time.record()# 同步并计算传输时间torch.cuda.synchronize()transfer_time = start_time.elapsed_time(end_time) / 1000.0 # 转换为秒return tensor_gpu, transfer_timedef free_memory(self):# 释放内存del self.normal_tensordel self.pinned_tensorself.normal_tensor = Noneself.pinned_tensor = Nonedef test_pinned_memory(rank, manager, device):# 测试普通内存到GPU传输时间normal_gpu, normal_memory_time = manager.transfer_to_device(device, use_pinned_memory=False)print(f"[进程 {rank}] 普通内存到GPU传输时间: {normal_memory_time:.6f} 秒")# 测试固定内存到GPU传输时间pinned_gpu, pinned_memory_time = manager.transfer_to_device(device, use_pinned_memory=True)print(f"[进程 {rank}] 固定内存到GPU传输时间: {pinned_memory_time:.6f} 秒")# 比较结果speedup = normal_memory_time / pinned_memory_timeprint(f"[进程 {rank}] 固定内存的传输速度是普通内存的 {speedup:.2f} 倍")if __name__ == '__main__':# 数据大小data_size = 10**7 # 例如,10M数据# 初始化固定内存管理器manager = PinnedMemoryManager(data_size)manager.allocate_normal_memory()manager.allocate_pinned_memory()# 目标设备device = torch.device("cuda")# 使用mp.spawn启动多进程测试mp.spawn(test_pinned_memory, args=(manager, device), nprocs=2, join=True)# 释放内存manager.free_memory()
输出:
[进程 1] 普通内存到GPU传输时间: 0.013695 秒
[进程 1] 固定内存到GPU传输时间: 0.013505 秒
[进程 1] 固定内存的传输速度是普通内存的 1.01 倍
[进程 0] 普通内存到GPU传输时间: 0.013752 秒
[进程 0] 固定内存到GPU传输时间: 0.013593 秒
[进程 0] 固定内存的传输速度是普通内存的 1.01 倍
可以看到基本上没啥改进。
暂不清楚原因,只能先无脑避免这种用法了。
相关文章:
【知识】pytorch中的pinned memory和pageable memory
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 概念简介 pytorch用法 速度测试 反直觉情况 概念简介 默认情况下,主机 (CPU) 数据分配是可分页的。GPU 无…...

【系统架构设计】数据库系统(五)
数据库系统(五) 数据库模式与范式数据库设计备份与恢复分布式数据库系统数据仓库数据挖掘NoSQL大数据 数据库模式与范式 数据库设计 备份与恢复 分布式数据库系统 数据仓库 数据挖掘 对数据挖掘技术进行支持的三种基础技术已经发展成熟,…...

如何对人工智能系统进行测试|要点,方法及流程
当今社会,人工智能发展非常快。现在人工智能的发展已经渗透到了我们生活的方方面面,自动驾驶、或者我们手机里经常用到的一些应用都或多或少涉及到了一些人工智能的功能,比如说美图秀秀、新闻推荐、机器翻译以及个性化的购物推荐等等都涉及到…...
CVE-2023-37569~文件上传【春秋云境靶场渗透】
# 今天我们拿下CVE-2023-37569这个文件上传漏洞# 经过简单账号密码猜测 账号:admin 密码:password# 找到了文件上传的地方# 我们直接给它上传一句话木马并发现上传成功# 上传好木马后,右键上传的木马打开发现上传木马页面# 直接使用蚁剑进行连…...

MySQL简介 数据库管理与表管理
文章目录 1 MySQL的优势2 MySQL数据类型1 数字类型2 日期和时间类型3 字符串类型 3 数据库管理4 数据表管理参考 1 MySQL的优势 性能优化:通过优化存储引擎(InnoDB,MyISAM)和查询优化。解决大规模数据处理和查询优化开源…...

PHP 函数性能优化的技巧是什么?
本文由 ChatMoney团队出品 本文将详细介绍 PHP 函数性能优化的技巧。通过分析 PHP 函数的执行过程和性能瓶颈,提供一系列实用的优化方法,并结合代码示例,帮助读者提升 PHP 代码的执行效率。文章内容将涵盖变量作用域、递归算法、循环优化、内…...
)
小程序支付(前端)
前端只需要调用 wx.requestPayment(Object object) 文档 参考代码 const openId wx.getStorageSync(openId)payOrder({payId: this.data.resData.payId,openId}).then((res) > {console.log(2222, res);try {const data JSON.parse(res.res)console.log(22, data)const {…...

开发一个自己的VSCode插件
1、前言 对于一个前端开发者来说,开发工具,最常用的应该就是VSCode了,因为它免费,速度快,提供了丰富了插件等优点,使得越来越多的前端开发者都来使用它了,在开发的时候如果有丰富的插件提供支持…...

Milvus 向量数据库进阶系列丨构建 RAG 多租户/多用户系统 (上)
本系列文章介绍 在和社区小伙伴们交流的过程中,我们发现大家最关心的问题从来不是某个具体的功能如何使用,而是面对一个具体的实战场景时,如何选择合适的向量数据库解决方案或最优的功能组合。在 “Milvus 向量数据库进阶” 这个系列文章中&…...
)
前缀和(更新中)
目录 1.寻找数组的中心下标 2.除自身以外数组的乘积 3.和为k的子数组 4.可被k整除的子数组 5.连续数组 1.寻找数组的中心下标 . - 力扣(LeetCode) class Solution { public:int pivotIndex(vector<int>& nums) {int size nums.size();v…...

记录一次单例模式乱用带来的危害。
项目场景: 我们在接受到短信网关下发的回执之后,需要将回执内容也下发给我们的下游服务。为了防止下游响应超时,我们需要将超时的信息存放到Redis中然后进行补发操作。 问题描述 在使用Redis进行数据存储的时候,报NPE问题。 原因…...

外卖项目day14(day11)---数据统计
Apache ECharts 大家可以看我这篇文章: Apache ECharts-CSDN博客 营业额统计 产品原型 接口设计 新建admin/ReportController /*** 数据统计相关接口*/ RestController RequestMapping("/admin/report") Api(tags "数据统计相关接口") Slf…...

养猫科普!牙口不好的猫咪怎么选粮?好吃易消化主食罐推荐
我家的猫猫已经九岁了,已经是一位老奶奶了,她的牙口不太好。对于她来说,膨化猫粮过于硬,很难咀嚼,所以我为她准备了质地柔软的主食罐头。哪种主食罐头更适合牙口不好的猫咪呢?下面,我就来分享一…...

力扣刷题之3143.正方形中的最多点数
题干描述 给你一个二维数组 points 和一个字符串 s ,其中 points[i] 表示第 i 个点的坐标,s[i] 表示第 i 个点的 标签 。 如果一个正方形的中心在 (0, 0) ,所有边都平行于坐标轴,且正方形内 不 存在标签相同的两个点,…...
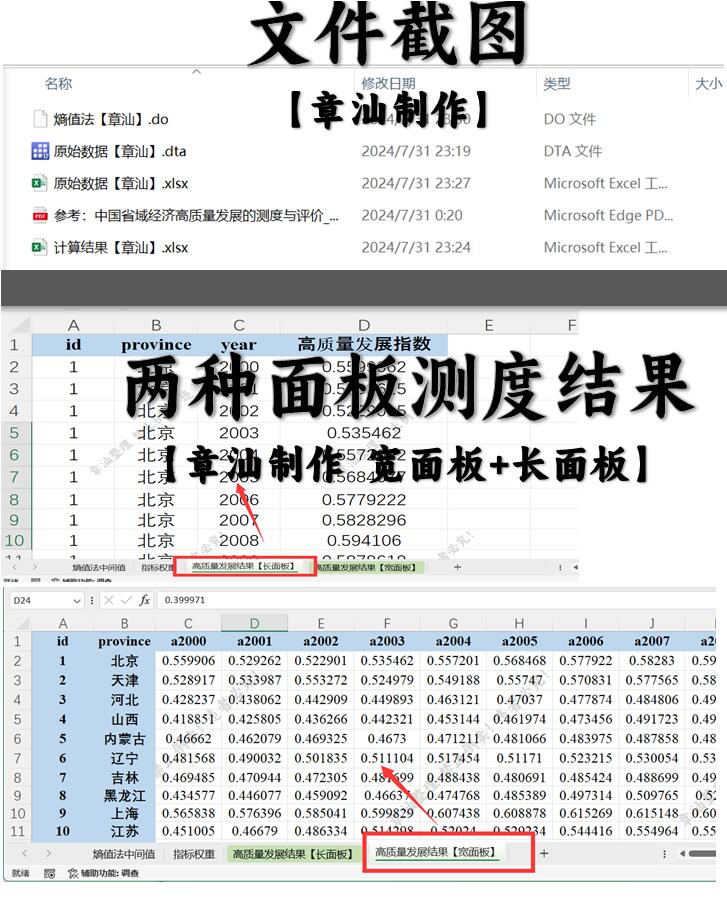
【更新2022】省级经济高质量发展指标体系测度 含代码 2000-2022
重磅更新!【章汕】制作“省级经济高质量发展指标体系测度 含代码”,市面上有这个版本的数据,但其内容非常不全面,个别指标有误,没有stata和代码,即使有代码小白也很容易报错;没有权重、宽面板等…...

缓冲流练习
练习1:拷贝文件 四种方式拷贝文件,并统计各自用时。 字节流的基本流:一次读写一个字节 字节流的基本流:一次读写一个字节数组 字节缓冲流:一次读写一个字节 字节缓冲流:一次读写一个字节数组 这里我只使用了…...

自己履行很多的话语,依旧按照这个方式进行生活
《明朝那些事儿》最后一段讲述了徐霞客的故事,作者当年明月通过徐霞客的生平表达了一种人生哲学。在书的结尾,当年明月写道:"成功只有一个——按照自己的方式,去度过人生",这句话被用作《明朝那些事儿》的结…...

交通预测数据文件梳理:METR-LA
文章目录 前言一、adj_METR-LA.pkl文件读取子文件1读取子文件2读取子文件3 二、METR-LA.h5文件 前言 最近做的实验比较多,对于交通预测数据的各种文件和文件中的数据格式理解愈加混乱,因此打算重新做一遍梳理来加深实验数据集的理解,本文章作…...

按钮类控件
目录 1.Push Button 代码示例: 带有图标的按钮 代码示例: 带有快捷键的按钮 代码示例: 按钮的重复触发 2.Radio Buttion 代码示例: 选择性别 代码示例: click, press, release, toggled 的区别 代码示例: 单选框分组 3.3 Check Box 代码示例: 获取复选按钮的取值 1.Pu…...

opencascade AIS_ViewController源码学习 视图控制、包含鼠标事件等
opencascade AIS_ViewController 前言 用于在GUI和渲染线程之间处理视图器事件的辅助结构。 该类实现了以下功能: 缓存存储用户输入状态(鼠标、触摸和键盘)。 将鼠标/多点触控输入映射到视图相机操作(平移、旋转、缩放࿰…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...