C++ ---- vector的底层原理剖析及其实现
vector
- 一、定义
- 二、常用接口及模拟实现
- 三、vector迭代器失效问题
- 四、使用memcpy拷贝会出现的问题
- 五、二维数组vector<vector< T >> vv
一、定义
vector 是 C++ 标准模板库(Standard Template Library, STL)中的一个非常有用的容器。它是一个序列容器,可以存储具有相同数据类型的元素集合,这些元素在内存中连续存储。与数组相似,但 vector 提供了更多的灵活性和功能。
主要特点:
1.动态数组:vector 可以动态地增加或减少其大小,这意味着你可以根据需要存储更多的元素,而不需要担心数组越界的问题。
2.随机访问:vector 支持随机访问,即你可以使用下标(索引)直接访问容器中的任何元素,其时间复杂度为 O(1)。
3.内存连续:vector 中的元素在内存中是连续存储的,这使得在需要时(如使用迭代器)可以高效地遍历整个容器。
4.容量和大小:vector 有两个重要的属性:size() 和 capacity()。size() 返回容器中当前元素的数量,而 capacity() 返回容器在不重新分配内存的情况下可以存储的元素的最大数量。当 vector 的大小超过其容量时,它会分配更多的内存空间并可能移动所有元素到新的内存位置。
常用操作:
1.插入元素:可以使用 push_back() 在 vector 的末尾添加新元素,或者使用 insert() 在指定位置插入元素。
2.删除元素:可以使用 pop_back() 删除 vector 的最后一个元素,或者使用 erase() 删除指定位置的元素或元素范围。
3.访问元素:可以直接使用下标操作符 [] 访问元素。
4.遍历元素:可以使用迭代器或者范围基 for 循环遍历 vector 中的所有元素。
获取大小和容量:如前所述,可以使用 size() 和 capacity() 方法分别获取 vector 的大小和容量。
二、常用接口及模拟实现
成员变量:
/这里加缺省值的原因:当对象是通过拷贝构造形成的时,这三个指针
/就不会初始化了(默认是随机值,而不是nullptr(0)),而在拷贝构造函数里,会运用到size(),capacity()之类的需要
/这三个指针相减,而随机值相减可能是很大的数字
/而加了缺省值,进入拷贝构造函数后会先进入这里初始化这三个值iterator _start=nullptr; /指向第一个元素
iterator _finish=nullptr; /指向最后一个元素的下一个位置
iterator _end_of_storage=nullptr; /指向最大容量的位置
(1)构造函数
| (constructor)构造函数声明 | 接口说明 |
|---|---|
| vector() | 无参构造 |
| vector(size_type n, const value_type& val =value_type() | 构造并初始化n个val |
| vector (const vector& x) | 拷贝构造 |
| vector (InputIterator first, InputIterator last) | 使用迭代器进行初始化构 |
模拟实现:
vector():_start(nullptr),_finish(nullptr),_end_of_storage(nullptr) {
}vector(size_t n, const T& val) {_start = new T[n](val);_finish = _start + n;_end_of_storage = _finish;
}vector(const vector<T>& v) {/写法1:/_start = new T[v.capacity()];memcpy(_start, v._start, sizeof(T) * v.size());_finish = _start + v.size();_end_of_storage = _start + v.capacity();//写法2:reserve(v.capacity()); /避免push_back多次扩容for (auto& num : v) {push_back(num);}
}
template<class Inputiterator> //说明:成员函数里面可以有模板函数vector(Inputiterator begin, Inputiterator end) { //用迭代器区间进行构造和初始化//这里重新定义一个Inputiterator而不用vector里面的iterator,是//因为如果用了iterator,那么调用该函数构造的对象所传的实参只能是vector的迭代器//而不能是诸如list ,map等容器的迭代器,而如果想用list或者其他容器的值来//初始化vector对象的话,只能如此定义一个迭代器模板 。//该构造函数支持任意容器的迭代器来初始化,但前提是这些容器所存的数据与//该vector所存的数据类型一致,如:list<int>l 用该方法来初始化 vector<int> v//它们存的都是int类型的数据while (begin != end) {push_back(*begin);begin++;}}(2)vector的迭代器
vector的迭代器有两种:
- iterator:typedef T* iterator
- const_iterator:typedef const T* const_iterator
(T是vector存的数据类型)
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对
指针进行了封装(list容器的迭代器),比如:vector的迭代器就是原生态指针T* 。
(3)begin()/end(),rbegin()/rend()接口函数
| 接口 | 说明 |
|---|---|
| begin()、end() | 获取第一个数据位置的iterator/const_iterator, 获取最后一个数据的下一个位置的iterator/const_iterator |
| rbegin()、rend() | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator |


模拟实现:
iterator begin() const{return _start;}iterator end()const {return _finish;}
(4)空间增长函数
| 容量空间 | 接口说明 |
|---|---|
| size() | 获取容器中数据个数 |
| capacity() | 获取容量大小 |
| empty() | 判断容器是否为空 |
| resize() | 改变vector的size |
| reserve() | 改变vector的capacity |
- capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2
倍增长的。因此vector的增容都具体增长多少是根据具体的需求定义的。vs是PJ版本STL,g++是SGI版本STL。 - reserve只负责开辟空间,如果确定知道需要用多少空间,reserve可以缓解vector增容的代
价缺陷问题。 - resize在开空间的同时还会进行初始化,影响size。
模拟实现:
size_t size()const {return _finish - _start; //两指针相减,结果为两指针之间的数据个数
}
size_t capacity() const{return _end_of_storage - _start;
}
void resize(size_t n, T val = T()) {if (n < size()) {//保留n个数据 _finish = _start + n;}else {reserve(n);while (_finish < _start + n) { //扩容并追加n-size()个val值(*_finish) = val;_finish++;}}
}
void reserve(size_t n) {if (n > capacity()) {size_t presize = size(); //要提前记录_start 与_finish 的相对位置//因为下面的_start先更新了,会导致size()函数//出错 (除非_finish先更新:_finish=tmp+size(),_start=tmpT* tmp = new T[n];//不严谨的拷贝数据://memcpy(tmp, _start, sizeof(T) * presize); //拷贝数据//严谨的拷贝数据:for (size_t i = 0; i < presize; i++) {tmp[i] = _start[i];}//这是因为假如类型T是string或者是vector<int>,而memcpy又是单纯的将内存的空间逐个字节拷贝//就导致vector存的string对象的char*指针(或者vector<int>的int*)// 也是单纯的直接拷贝给tmp,//即tmp里的string对象里的指针指向的空间和待释放的vector对象存的//string对象里的指针指向的空间是一样的。//下面delete[] _start 时,会先调用每个string对象的析构函数。//其实就是,vector深拷贝了,但是vector存的string没有深拷贝//而如果将该this对象的内容逐个拷贝给tmp,每次拷贝时都会调用string的深拷贝//从而避免了该情况。// tmp[i]=_start[i]本质上是:string s =string s'(string的拷贝构造) delete[] _start;//更新三个迭代器所指向的位置:_start = tmp;_finish = tmp + presize;_end_of_storage = tmp + n;}}
测试vector在不同平台下的扩容机制:
// 测试vector的默认扩容机制
void TestVectorExpand()
{size_t sz;vector<int> v;sz = v.capacity();cout << "making grow:\n";for (int i = 0; i < 100; ++i){v.push_back(i);if (sz != v.capacity()){sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}
/vs:运行结果:vs下使用的STL基本是按照1.5倍方式扩容
making grow:
capacity changed: 1
capacity changed: 2
capacity changed: 3
capacity changed: 4
capacity changed: 6
capacity changed: 9
capacity changed: 13
capacity changed: 19
capacity changed: 28
capacity changed: 42
capacity changed: 63
capacity changed: 94
capacity changed: 141/g++运行结果:linux下使用的STL基本是按照2倍方式扩容
making grow:
capacity changed: 1
capacity changed: 2
capacity changed: 4
capacity changed: 8
capacity changed: 16
capacity changed: 32
capacity changed: 64
capacity changed: 128
// 如果已经确定vector中要存储元素大概个数,可以提前将空间设置足够
// 就可以避免边插入边扩容导致效率低下的问题了
void TestVectorExpandOP()
{vector<int> v;size_t sz = v.capacity();v.reserve(100); / 提前将容量设置好,可以避免一遍插入一遍扩容cout << "making bar grow:\n";for (int i = 0; i < 100; ++i){v.push_back(i);if (sz != v.capacity()){sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}
(5)vector的增删查改
| vector增删查改 | 接口说明 |
|---|---|
| push_back()(重点) | 尾插 |
| pop_back() (重点) | 尾删 |
| find() | 查找。(注意这个是算法模块实现,不是vector的成员接口) |
| insert() | 在position之前插入val |
| erase() | 删除position位置的数据 |
| swap() | 交换两个vector的数据空间 |
| operator (重点) | 像数组一样访问 |
模拟实现:
void push_back(const T& x) { //T可能是自定义类型,所以用const引用较好if (_finish == _end_of_storage) {//扩容reserve(capacity() == 0 ? 4 : 2 * capacity());}*_finish = x; //如果T是string ,这里会调用string的拷贝构造_finish++;
}void pop_back() { assert(_start != _finish);--_finish;} iterator find(iterator begin, iterator end, const T& x) {vector<T>::iterator it = begin;while (it != end) {if (*it == x) {return it;}it++;}return end;}void insert(iterator pos, const T& x) {if (_finish == _end_of_storage) {//扩容size_t pre_distance = pos - _start;reserve(capacity() == 0 ? 4 : 2 * capacity());pos = _start + pre_distance; //因为_start在扩容时指向的空间变化了,//因此pos也要相应的变化} //否则会出现迭代器失效的情况iterator end = _finish-1;while (end >=pos) {*(end + 1) = *end;end--;}*pos = x;++_finish;
}void erase(iterator pos) {assert(pos >= _start);assert(pos < _finish);iterator it = pos;while (it < _finish-1) {*(it) = *(it + 1);it++;}_finish--;}void swap(vector<T>& v) {std::swap(_start, v._start);std::swap(_finish, v._finish);std::swap(_end_of_storage, v._end_of_storage);}T& operator[](int i) {assert(i < size() && i >= 0);return _start[i];}
三、vector迭代器失效问题
迭代器失效实际就是迭代器
底层对应指针所指向的空间被销毁了,而仍然使用这一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
对于vector可能会导致其迭代器失效的操作有:
- 会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。即如果已经有了一个迭代器指向一块空间,但是这个空间被上述可以改变空间结构的函数给销毁了,那么这个迭代器也就失效了。
- 指定位置元素的删除操作–erase
using namespace std;
#include <vector>
int main()
{int a[] = { 1, 2, 3, 4 };vector<int> v(a, a + sizeof(a) / sizeof(int));//发生隐式类型转化,调用迭代器区间构造函数// 使用find查找3所在位置的iteratorvector<int>::iterator pos = find(v.begin(), v.end(), 3);// 删除pos位置的数据,导致pos迭代器失效。v.erase(pos);cout << *pos << endl; // 此处会导致非法访问return 0;
}
说明:
erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理
论上讲迭代器不应该会失效。但是,如果pos刚好是最后一个元素,删完之后pos刚好是end
的位置,而end位置是没有元素的,那么pos就失效了。因此删除vector中任意位置上元素
时,vs就认为该位置迭代器失效了。
3.注意:Linux下,g++编译器对迭代器失效的检测并不是非常严格,处理也没有vs下极端。
/ 1. 扩容之后,迭代器已经失效了,程序虽然可以运行,但是运行结果已经不对了
int main()
{
vector<int> v{1,2,3,4,5};
for(size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
auto it = v.begin();
cout << "扩容之前,vector的容量为: " << v.capacity() << endl;
// 通过reserve将底层空间设置为100,目的是为了让vector的迭代器失效
v.reserve(100);
cout << "扩容之后,vector的容量为: " << v.capacity() << endl;
// 经过上述reserve之后,it迭代器肯定会失效,在vs下程序就直接崩溃了,但是linux
下不会
// 虽然可能运行,但是输出的结果是不对的
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序输出:
1 2 3 4 5
扩容之前,vector的容量为: 5
扩容之后,vector的容量为: 100
0 2 3 4 5 409 1 2 3 4 5/ 2. erase删除任意位置代码后,linux下迭代器并没有失效
// 因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的
#include <vector>
#include <algorithm>
int main()
{
vector<int> v{1,2,3,4,5};
vector<int>::iterator it = find(v.begin(), v.end(), 3);
v.erase(it);
cout << *it << endl;
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序可以正常运行,并打印:
4
4 5/ 3: erase删除的迭代器如果是最后一个元素,删除之后it已经超过end
/ 此时迭代器是无效的,++it导致程序崩溃
int main()
{
vector<int> v{1,2,3,4,5};
// vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
while(it != v.end())
{
if(*it % 2 == 0)
v.erase(it);
++it;
}
for(auto e : v)
cout << e << " ";
cout << endl;
return 0;
}
总结:
从上述三个例子中可以看到:SGI STL中,迭代器失效后,代码并不一定会崩溃,但是运行
结果肯定不对,如果it不在begin和end范围内,肯定会崩溃的。
四、使用memcpy拷贝会出现的问题
注:reserve接口:
void reserve(size_t n) {if (n > capacity()) {size_t presize = size(); //要提前记录_start 与_finish 的相对位置//因为下面的_start先更新了,会导致size()函数//出错 (除非_finish先更新:_finish=tmp+size(),_start=tmpT* tmp = new T[n];memcpy(tmp, _start, sizeof(T) * presize); //拷贝数据delete[] _start;//更新三个迭代器所指向的位置:_start = tmp;_finish = tmp + presize;_end_of_storage = tmp + n;}}
#include<string>
int main()
{
Myvector::vector<string> v; //vector是自己实现的,string是库实现的v.push_back("wwww");
v.push_back("eeee");
v.push_back("rrrr");
return 0;
}
上述代码所导致的问题剖析:


正确拷贝数据的方法:(逐个数据拷贝)
void reserve(size_t n) {if (n > capacity()) {size_t presize = size(); //要提前记录_start 与_finish 的相对位置//因为下面的_start先更新了,会导致size()函数//出错 (除非_finish先更新:_finish=tmp+size(),_start=tmpT* tmp = new T[n];for (size_t i = 0; i < presize; i++) {tmp[i] = _start[i];}//这是因为假如类型T是string或者是vector<int>,而memcpy又是单纯的将内存的空间逐个字节拷贝//就导致vector存的string对象的char*指针(或者vector<int>的int*)// 也是单纯的直接拷贝给tmp,//即tmp里的string对象里的指针指向的空间和待释放的vector对象存的//string对象里的指针指向的空间是一样的。//下面delete[] _start 时,会先调用每个string对象的析构函数。//其实就是,vector深拷贝了,但是vector存的string没有深拷贝//而如果将该this对象的内容逐个拷贝给tmp,每次拷贝时都会调用string的深拷贝//从而避免了该情况。// tmp[i]=_start[i]本质上是:string s =string s'(string的拷贝构造) delete[] _start;//更新三个迭代器所指向的位置:_start = tmp;_finish = tmp + presize;_end_of_storage = tmp + n;}}
总结:不仅vector存stirng类型会出现该问题,只要是存的对象里有指向堆空间的类型(如还有下面的二维数组),都是有memcpy拷贝问题的,而存储自定义类型就不会。
五、二维数组vector<vector< T >> vv
对c语言来说,创建一个二维数组的方法:
test()
{//三行四列int **two=(int**)malloc(sizeof(int*)*3);for(int i=0;i<3;i++){two[i]=(int*)malloc(sizeof(int)*4);}
}
vector<vecot< T >> vv 的底层空间示意图:

相关文章:
C++ ---- vector的底层原理剖析及其实现
vector 一、定义二、常用接口及模拟实现三、vector迭代器失效问题四、使用memcpy拷贝会出现的问题五、二维数组vector<vector< T >> vv 一、定义 vector 是 C 标准模板库(Standard Template Library, STL)中的一个非常有用的容器。它是一个…...

跑酷视频素材去哪里下载?哪里有跑酷游戏视频素材?
在这个快节奏的视觉时代,跑酷视频因其惊险和动感吸引了众多动作爱好者和视频创作者的目光。如果您正在寻找高质量的跑酷视频素材来丰富您的项目,无论是增强视频的视觉冲击力还是展现跑酷运动的魅力,以下几个推荐的网站将是您的理想选择。 蛙…...

Centos 7配置问题
在VMWare12上面安装Centos 7 Linux虚拟机,在切换到命令界面时,需要登录用户名和密码,但发现输入用户后有字符显示,但是密码没有。 经过一系列查看后,发现这个是Linux的一种机制,即当你输入密码时不显示&…...

浮动IP(Floating IP)计费;OpenStack算力共享;OpenStack实现资源虚拟化;算力调度策略
目录 浮动IP(Floating IP)计费 浮动IP的定义与作用 计费中的浮动IP数据 浮动IP在计费中的作用 OpenStack算力共享 一、OpenStack在算力共享中的角色 二、OpenStack与算力共享的结合方式 三、实际应用案例 算力调度策略 算力计费策略 OpenStack实现资源虚拟化 1.虚…...

Android 源码单独编译Settings模块
一般我们编译源码,只需要在源码的根目录下执行三个命令就行 . build/envsetup.sh 或者source build/envsetup.sh lunch 选择编译目标 make -j60make 不带参数的编译方式是直接编译整个系统,我们也可以使用make带模块名或者使用mmm等命令单独编译某个模块。 首先找到对应模块…...

虚拟机类加载机制
与那些编译时需要进行连接的语言不同,在java语言中,类型的 动态加载:编写一个面向接口的应用程序,可以等到运行时再指定其实现类。 类加载:加载-连接-初始化-使用-卸载 一个类被调用时,会将其class文件从…...
——逐月筛选影像,并给影像集合添加新的属性)
Google Earth Engine(GEE)——逐月筛选影像,并给影像集合添加新的属性
简介 导入影像集合首先,您需要导入您要筛选的影像集合。使用Google Earth Engine的ImageCollection类来导入影像集合。您可以通过ee.ImageCollection()函数传递影像集合的ID或通过一个ee.ImageCollection()对象导入影像集合。 例如,导入Landsat 8卫星每月影像集合的代码如下…...
如何从智联招聘网站快速抓取职位详情?两大技巧揭秘
摘要: 本文将揭秘如何利用Python爬虫技术,高效且合法地从智联招聘网站抓取职位详情信息。通过实战示例,展现两大核心技巧,助你在大数据时代抢占先机,为你的市场分析、人才研究提供强大支持。 一、引言:数据…...

C#知识|ini文件操作
哈喽,你好啊,我是雷工! 本节学习ini文件的操作,之前练习过通过ini文件导出采集模块的配置信息,然后再另一个模块中导入配置信息,如此实现快速配置采集模块,提高效率。 以下为学习笔记。 01 认识ini文件 ini文件是一种文件格式,类似txt,xml等, ini文件在上位机开发中使…...

Linux系统学习之路
一、Linux基础训练 https://mp.weixin.qq.com/mp/appmsgalbum?actiongetalbum&__bizMzUxNjMwMzk4MQ&scene1&album_id3544800080551952390&count3#wechat_redirect...

DNS介绍与部署-Day 01
1. 什么是DNS DNS(Domain Name System)域名系统,是一种采用客户端/服务器机制,负责实现计算机名称与IP地址转换的系统。DNS作为一种重要的网络服务,既是Internet工作的基础,同时在企业内部网络中也得到了广…...

python 图片爬虫记录
感谢大家的点赞。再补充一点。 对于这个 url https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjEqB5nighYsMZE7kexaVNJfxy3OkRutNEKatksw9u5f-ckHNROLzFyx2Uty3zYWNEaeOmzsljGr3eARiDWaM9DM8G2hPuPf8uZP0NO3kNUCnM2Cjb3ZKtLhJDBwqeR4ElpJ7ID5_wIHGQ/s200 这个url最…...

本地安装Llama3.1与LobeChat可视化UI界面并实现远程访问大模型实战
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

MSF回弹木马在Ubuntu中测试
1.创建文件 网站地址为192.168.30.129 首先在Ubuntu中use/local/nginx/sbin路径下创建一个PHP文件; 如图所示: 然后进入网页下载PHP文件如图所示: 什么都不显示说明这个没有问题就怕访问失败。 2.使用蚂键连接网站 在蚂键中的URL地址栏中…...

大数据等保测评
在当今数字化浪潮汹涌澎湃的时代,大数据已成为企业和组织创新发展的核心驱动力。然而,随着大数据应用的日益广泛和深入,其安全问题也日益凸显。大数据等保测评作为保障大数据安全的重要手段,具有至关重要的意义。 大数据的特点决定…...

CSS对元素的分类
文章目录 概述置换元素/非置换元素置换元素非置换元素 行内元素/块级元素/行内块级元素行内元素块级元素行内块级元素 概述 CSS从两个维度上将HTML元素进行了分类: 从元素内容的表现形式上,将元素分为:置换元素、非置换元素。从元素自身的显…...
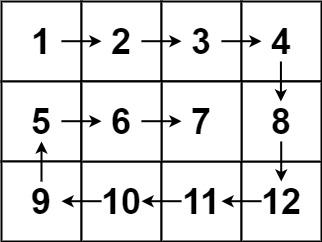
力扣第五十四题——螺旋矩阵
内容介绍 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2: 输入:matrix …...

中创算力:以知识产权转化运用促进高质量发展
创新是引领发展的第一动力,保护知识产权就是保护创新。为深入实施知识产权公共服务普惠工程,促进知识产权公共服务更好服务高水平科技,国家知识产权局发布关于全面提升知识产权公共服务效能的指导意见。 在政策落地过程中,如何精…...

C语言9~10 DAY(合集)
数组的概念 什么是数组 数组是相同类型,有序数据的集合。 数组的特征 数组中的数据被称为数组的元素,是同构的 数组中的元素存放在内存空间里 (char player_name[6]:申请在内存中开辟6块连续的基于char类型的变量空间) 衍生概念&#x…...

【Kubernetes】应用的部署(一):金丝雀部署
应用的部署(一):金丝雀部署 在项目迭代开发过程中,经常需要对应用进行上线部署。上线部署策略主要有 3 种:金丝雀部署、蓝绿部署 和 滚动部署。 金丝雀部署 也被叫作 灰度部署。金丝雀部署过程:先让一部分…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

Redis 客户端连接详解
Redis 客户端连接详解 引言 Redis 是一款高性能的内存数据结构存储系统,常用于缓存、会话管理、实时排行榜等功能。客户端连接是 Redis 生态系统中的重要组成部分,本文将详细介绍 Redis 客户端连接的相关知识,包括连接方式、连接配置、连接管理等方面。 Redis 客户端连接…...