目标检测 | yolov1 原理和介绍
1. 简介
论文链接:https://arxiv.org/abs/1506.02640
时间:2015年
作者:Joseph Redmon
代码参考:https://github.com/abeardear/pytorch-YOLO-v1
yolo属于one-stage算法,仅仅使用一个CNN网络直接预测不同目标的类别与位置,提供end-to-end的预测,该类算法是速度快,但是准确性要低(two-stage,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal[区域方案],然后再在Region Proposal上做分类与回归。相当于粗略检测,再细致检测)
yolo算法很好的解决了滑动窗口这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
2. 设计理念
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图所示:首先将输入图片resize到 448 × 448 448\times 448 448×448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的

具体来说,Yolo的CNN网络将输入的图片分割成 S × S S\times S S×S 网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测 B 个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为 P r ( o b j e c t ) Pr(object) Pr(object),当该边界框是背景时(即不包含目标),此时 P r ( o b j e c t ) = 0 Pr(object)=0 Pr(object)=0 。而当该边界框包含目标时, P r ( o b j e c t ) = 1 Pr(object)=1 Pr(object)=1 。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为 I O U IOU IOU 。因此置信度可以定义为 P r ( o b j e c t ) ∗ I O U Pr(object) * IOU Pr(object)∗IOU 。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用 4 4 4个值来表征: ( x , y , w , h ) (x,y,w,h) (x,y,w,h) ,其中 ( x , y ) (x,y) (x,y) 是边界框的中心坐标,而 w w w 和 h h h 是边界框的宽与高。还有一点要注意,中心坐标的预测值 ( x , y ) (x,y) (x,y) 是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图所示。而边界框的 w w w 和 h h h 预测值是相对于整个图片的宽与高的比例,这样理论上 4 4 4个元素的大小应该在 [ 0 , 1 ] [0,1] [0,1] 范围。这样,每个边界框的预测值实际上包含 5 5 5个元素: ( x , y , w , h ) (x,y,w,h) (x,y,w,h) ,其中前4个表征边界框的大小与位置,而最后一个值是置信度。

还有分类问题,对于每一个单元格其还要给出预测出 C C C 个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。但是这些概率值其实是在各个边界框置信度下的条件概率,即 P r ( c l a s s i ∣ o b j e c t ) Pr(classi|object) Pr(classi∣object)。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolo算法的一个缺点,在后来的改进版本中,Yolo9000是把类别概率预测值与边界框是绑定在一起的。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores):
Pr ( class i ∣ o b j e c t ) ∗ Pr ( object ) ∗ I O U pred truth = Pr ( class i ) ∗ I O U pred truth \operatorname{Pr}\left(\text { class }_i \mid o b j e c t\right) * \operatorname{Pr}(\text { object }) * \mathrm{IOU}_{\text {pred }}^{\text {truth }}=\operatorname{Pr}\left(\text { class }_i\right) * \mathrm{IOU}_{\text {pred }}^{\text {truth }} Pr( class i∣object)∗Pr( object )∗IOUpred truth =Pr( class i)∗IOUpred truth
边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。后面会说,一般会根据类别置信度来过滤网络的预测框。
总结一下,每个单元格需要预测 ( B ∗ 5 + C ) (B*5+C) (B∗5+C) 个值。如果将输入图片划分为 S ∗ S S*S S∗S网格,那么最终预测值为 S ∗ S ∗ ( B ∗ 5 + C ) S*S*(B*5+C) S∗S∗(B∗5+C) 大小的张量。整个模型的预测值结构如下图所示。对于PASCAL VOC数据,其共有 20 20 20个类别,如果使用 S = 7 , B = 2 S=7,B=2 S=7,B=2 ,那么最终的预测结果就是 7 × 7 × 30 7 \times 7 \times 30 7×7×30 大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
3. 网络
Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含 24 24 24个卷积层和 2 2 2个全连接层,如图所示。对于卷积层,主要使用 1 × 1 1 \times 1 1×1卷积来做channle reduction,然后紧跟 3 × 3 3 \times 3 3×3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数: m a x ( 0.1 x , x ) max(0.1x, x) max(0.1x,x)。但是最后一层却采用线性激活函数。

可以看到网络的最后输出为 7 × 7 × 30 7 \times 7 \times 30 7×7×30 大小的张量。这和前面的讨论是一致的。这个张量所代表的具体含义如图所示。对于每一个单元格,前 20 20 20个元素是类别概率值,然后 2 2 2个元素是边界框置信度,两者相乘可以得到类别置信度,最后 8 8 8个元素是边界框的 ( x , y , w , h ) (x,y,w,h) (x,y,w,h) 。大家可能会感到奇怪,对于边界框为什么把置信度 c c c 和 ( x , y , w , h ) (x,y,w,h) (x,y,w,h) 都分开排列,而不是按照 ( x , y , w , h , c ) (x,y,w,h,c) (x,y,w,h,c) 这样排列,其实纯粹是为了计算方便,因为实际上这 30 30 30个元素都是对应一个单元格,其排列是可以任意的。但是分离排布,可以方便地提取每一个部分。这里来解释一下,首先网络的预测值是一个二维张量 P P P ,其shape为 [ b a t c h , 7 ∗ 7 ∗ 30 ] [batch, 7*7*30] [batch,7∗7∗30] 。采用切片,那么 P [ : , 0 : 7 ∗ 7 ∗ 20 ] P[:,0:7*7* 20] P[:,0:7∗7∗20] 就是类别概率部分,而 P [ : , 0 : 7 ∗ 7 ∗ 20 : 7 ∗ 7 ∗ ( 20 + 2 ) ] P[:,0:7 * 7 * 20:7* 7 * (20+2)] P[:,0:7∗7∗20:7∗7∗(20+2)] 是置信度部分,最后剩余部分 P [ : , 0 : 7 ∗ 7 ∗ 20 : ] P[:,0:7*7*20:] P[:,0:7∗7∗20:] 是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。
4. 训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从 224 × 224 224\times224 224×224增加到了 448 × 448 448\times448 448×448。
下面是训练损失函数的分析,Yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重 λ coord = 5 \lambda_{\text {coord }}=5 λcoord =5 。然后其区分不包含目标的边界框与含有目标的边界框的置信度,对于前者,采用较小的权重值 λ noobj = 0.5 \lambda_{\text {noobj }}=0.5 λnoobj =0.5 。其它权重值均设为 1 1 1。然后采用均方误差,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为 ( x , y , w , h ) (x, y, \sqrt{w}, \sqrt{h}) (x,y,w,h) 。
另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,坐标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
5. 损失函数
综上讨论,最终的损失函数计算如下:

其中第一项是边界框中心坐标的误差项, 1 i j o b j 1_{i j}^{o b j} 1ijobj 指的是第 i i i 个单元格存在目标,且该单元格中的第 j j j 个边界框负责预测该目标,如果该矩形框负责预测一个目标则其大小为1,否则等于0。第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项, 1 i o b j 1_{i }^{o b j} 1iobj 指的是第 i i i 个单元格存在目标。这里特别说一下置信度的 t a r g e t target target值 C i C_i Ci ,如果是不存在目标,此时由于 Pr ( \operatorname{Pr}( Pr( object ) = 0 )=0 )=0,那么 C i = 0 C_i=0 Ci=0 。如果存在目标, Pr ( \operatorname{Pr}( Pr( object ) = 1 )=1 )=1 ,此时需要确定 I O U pred truth \mathrm{IOU}_{\text {pred }}^{\text {truth }} IOUpred truth ,当然你希望最好的话,可以将IOU取 1 1 1,这样 C i = 1 C_i=1 Ci=1 ,但是在YOLO实现中,使用了一个控制参数rescore(默认为1),当其为 1 1 1时,IOU不是设置为 1 1 1,而就是计算truth和pred之间的真实IOU。不过很多复现YOLO的项目还是取 C i = 0 C_i=0 Ci=0 ,这个差异应该不会太影响结果吧。
6. 标签分配
YOLOv1的标签分配策略是,如果一个ground truth(真实框)的中心落在某个网格中,则该网格的两个预测框中与ground truth IOU最大的预测框被选为正样本,其余为负样本。这种设计使得每个网格单元最多只能预测一个目标,这限制了YOLOv1对密集目标的检测能力
7. 预测
下面就来分析Yolo的预测过程,这里我们不考虑batch,认为只是预测一张输入图片。根据前面的分析,最终的网络输出是 7 × 7 × 30 7\times7\times30 7×7×30 ,但是我们可以将其分割成三个部分:类别概率部分为 [ 7 , 7 , 20 ] [7,7,20] [7,7,20] ,置信度部分为 [ 7 , 7 , 2 ] [7,7,2] [7,7,2] ,而边界框部分为 [ 7 , 7 , 2 , 4 ] [7,7,2,4] [7,7,2,4] (对于这部分不要忘记根据原始图片计算出其真实值)。然后将前两项相乘(矩阵 [ 7 , 7 , 20 ] [7,7,20] [7,7,20] 乘以 [ 7 , 7 , 2 ] [7,7,2] [7,7,2] 可以各补一个维度来完成 [ 7 , 7 , 1 , 20 ] × [ 7 , 7 , 2 , 1 ] [7,7,1,20] \times [7,7,2,1] [7,7,1,20]×[7,7,2,1] )可以得到类别置信度值为 [ 7 , 7 , 2 , 20 ] [7,7,2,20] [7,7,2,20] ,这里总共预测了 7 × 7 × 2 = 98 7\times7\times2=98 7×7×2=98 个边界框。
所有的准备数据已经得到了,那么我们先说第一种策略来得到检测框的结果,我认为这是最正常与自然的处理。首先,对于每个预测框根据类别置信度选取置信度最大的那个类别作为其预测标签,经过这层处理我们得到各个预测框的预测类别及对应的置信度值,其大小都是 [ 7 , 7 , 2 ] [7,7,2] [7,7,2] 。一般情况下,会设置置信度阈值,就是将置信度小于该阈值的box过滤掉,所以经过这层处理,剩余的是置信度比较高的预测框。最后再对这些预测框使用NMS算法,最后留下来的就是检测结果。一个值得注意的点是NMS是对所有预测框一视同仁,还是区分每个类别,分别使用NMS。Ng在deeplearning.ai中讲应该区分每个类别分别使用NMS,但是看了很多实现,其实还是同等对待所有的框,我觉得可能是不同类别的目标出现在相同位置这种概率很低吧。
上面的预测方法应该非常简单明了,但是对于Yolo算法,其却采用了另外一个不同的处理思路(至少从C源码看是这样的),其区别就是先使用 N M S NMS NMS,然后再确定各个box的类别。其基本过程如图所示。对于 98 98 98个boxes,首先将小于置信度阈值的值归 0 0 0,然后分类别地对置信度值采用 N M S NMS NMS,这里NMS处理结果不是剔除,而是将其置信度值归为 0 0 0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。Yolo论文里面说 N M S NMS NMS算法对Yolo的性能是影响很大的,所以可能这种策略对Yolo更好。但是我测试了普通的图片检测,两种策略结果是一样的。
8. 性能分析
这里看一下Yolo算法在PASCAL VOC 2007数据集上的性能,这里Yolo与其它检测算法做了对比,包括DPM,R-CNN,Fast R-CNN以及Faster R-CNN。其对比结果如表所示。与实时性检测方法DPM对比,可以看到Yolo算法可以在较高的mAP上达到较快的检测速度,其中Fast Yolo算法比快速DPM还快,而且mAP是远高于DPM。但是相比Faster R-CNN,Yolo的mAP稍低,但是速度更快。所以。Yolo算法算是在速度与准确度上做了折中。

为了进一步分析Yolo算法,文章还做了误差分析,将预测结果按照分类与定位准确性分成以下5类:
- Correct:类别正确,IOU>0.5;(准确度)
- Localization:类别正确,0.1 < IOU<0.5(定位不准);
- Similar:类别相似,IOU>0.1;
- Other:类别错误,IOU>0.1;
- Background:对任何目标其IOU<0.1。(误把背景当物体)
Yolo与Fast R-CNN的误差对比分析如下图所示:

可以看到,Yolo的Correct的是低于Fast R-CNN。另外Yolo的Localization误差偏高,即定位不是很准确。但是Yolo的Background误差很低,说明其对背景的误判率较低。Yolo的那篇文章中还有更多性能对比,感兴趣可以看看。
9. 优缺点
现在来总结一下Yolo的优缺点。首先是优点,Yolo采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end,所以Yolo算法比较简洁且速度快。第二点由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。其实我觉得全连接层也是对这个有贡献的,因为全连接起到了attention的作用。另外,Yolo的泛化能力强,在做迁移时,模型鲁棒性高。
最后不得不谈一下Yolo的缺点,首先Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。这方面的改进可以看SSD,其采用多尺度单元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。当然Yolo的定位不准确也是很大的问题。
相关文章:
目标检测 | yolov1 原理和介绍
1. 简介 论文链接:https://arxiv.org/abs/1506.02640 时间:2015年 作者:Joseph Redmon 代码参考:https://github.com/abeardear/pytorch-YOLO-v1 yolo属于one-stage算法,仅仅使用一个CNN网络直接预测不同目标的类别与…...

excel中有些以文本格式存储的数值如何批量转换为数字
一、背景 1.1 文本格式存储的数值特点 在平时工作中有时候会从别地方导出来表格,表格中有些数值是以文本格式存储的(特点:单元格的左上角有个绿色的小标)。 1.2 文本格式存储的数值在排序时不符合预期 当我们需要进行排序的时候…...

原神升级计划数据表:4个倒计时可以修改提示信息和时间,可以点击等级、命座、天赋、备注进行修改。
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><title>原神倒计时</title><style>* {margin: 0;padding: 0;box-sizing: border-box;body {background: #0b1b2c;}}header {width: 100vw;heigh…...

YoloV10 论文翻译(Real-Time End-to-End Object Detection)
摘要 近年来,YOLO因其在计算成本与检测性能之间实现了有效平衡,已成为实时目标检测领域的主流范式。研究人员对YOLO的架构设计、优化目标、数据增强策略等方面进行了探索,并取得了显著进展。然而,YOLO对非极大值抑制࿰…...

第R1周:RNN-心脏病预测
本文为🔗365天深度学习训练营 中的学习记录博客 原作者:K同学啊 要求: 1.本地读取并加载数据。 2.了解循环神经网络(RNN)的构建过程 3.测试集accuracy到达87% 拔高: 1.测试集accuracy到达89% 我的环境&a…...

Golang | Leetcode Golang题解之第321题拼接最大数
题目: 题解: func maxSubsequence(a []int, k int) (s []int) {for i, v : range a {for len(s) > 0 && len(s)len(a)-1-i > k && v > s[len(s)-1] {s s[:len(s)-1]}if len(s) < k {s append(s, v)}}return }func lexico…...

远程连接本地虚拟机失败问题汇总
前言 因为我的 Ubuntu 虚拟机是新装的,并且应该装的是比较纯净的版本(纯净是指很多工具都尚未安装),然后在使用远程连接工具 XShell 连接时出现了很多问题,这些都是我之前没遇到过的(因为之前主要使用云服…...
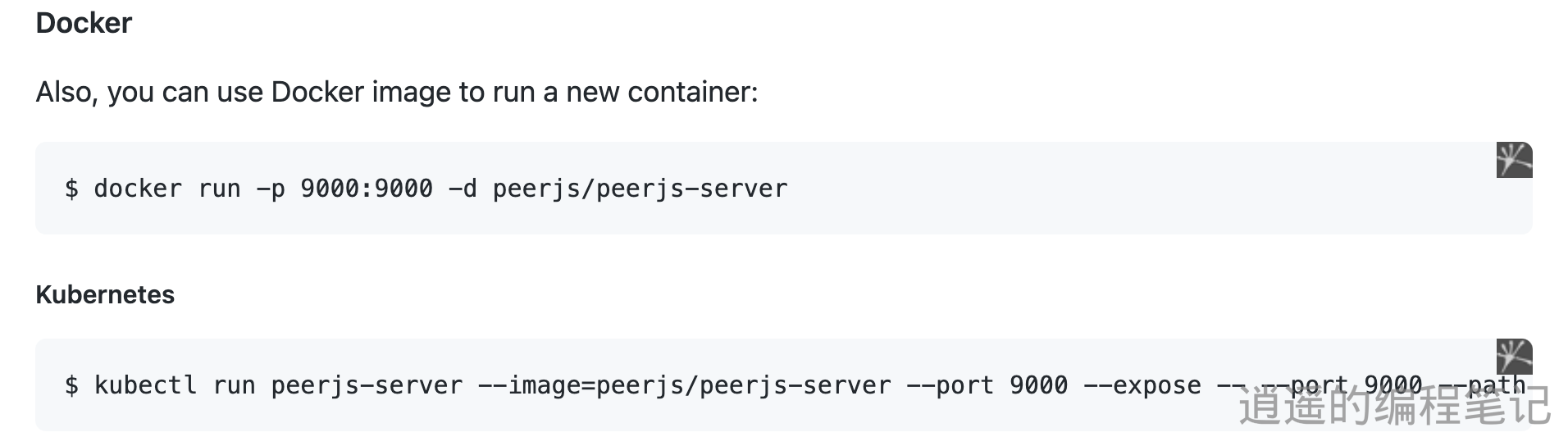
WebRTC 初探
前言 项目中有局域网投屏与文件传输的需求,所以研究了一下 webRTC,这里记录一下学习过程。 WebRTC 基本流程以及概念 下面以 1 对 1 音视频实时通话案例介绍 WebRTC 的基本流程以及概念 WebRTC 中的角色 WebRTC 终端,负责音视频采集、编解码、NAT 穿…...

Python:read,readline和readlines的区别
在Python中,read(), readline(), 和 readlines() 是文件操作中常用的三个方法,它们都用于从文件中读取数据,但各自的使用方式和适用场景有所不同。 read() 方法: read(size-1) 方法用于从文件中读取指定数量的字符。如果指定了si…...

重生之我学编程
编程小白如何成为大神?大学新生的最佳入门攻略 编程已成为当代大学生的必备技能,但面对众多编程语言和学习资源,新生们常常感到迷茫。如何选择适合自己的编程语言?如何制定有效的学习计划?如何避免常见的学习陷阱&…...
如何将PostgreSQL的数据实时迁移到SelectDB?
PostgreSQL 作为一个开源且功能强大的关系型数据库管理系统,在 OLTP 系统中得到了广泛应用。很多企业利用其卓越的性能和灵活的架构,应对高并发事务、快速响应等需求。 然而对于 OLAP 场景,PostgreSQL 可能并不是最佳选择。 为了实现庞大规…...

关于c语言的const 指针
const * type A 指向的数据是常量 如上所示,运行结果如下,通过解引用的方式,改变了data的值 const type * A 位置是常量,不能修改 运行结果如下 type const * A 指针是个常量,指向的值可以改变 如上所示,…...

万能门店小程序开发平台功能源码系统 带完整的安装代码包以及安装搭建教程
互联网技术的迅猛发展和用户对于便捷性需求的不断提高,小程序以其轻量、快捷、无需安装的特点,成为了众多商家和开发者关注的焦点。为满足广大商家对于门店线上化、智能化管理的需求,小编给大家分享一款“万能门店小程序开发平台功能源码系统…...
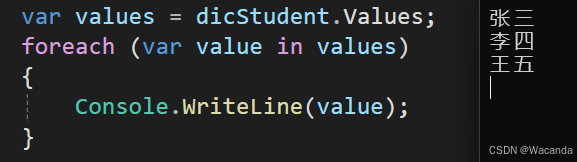
C#初级——字典Dictionary
字典 字典是C#中的一种集合,它存储键值对,并且每个键与一个值相关联。 创建字典 Dictionary<键的类型, 值的类型> 字典名字 new Dictionary<键的类型, 值的类型>(); Dictionary<int, string> dicStudent new Dictionary<int, str…...

git版本控制的底层实现
目录 前言 核心概念串讲 底层存储形式探测 本地仓库的详细解析 提交与分支的深入解析 几个问题的深入探讨 前言 Git的重要性 Git是一个开源的版本控制工具,广泛用于编程开发领域。它极大地提高了研发团队的开发协作效率。对于开发者来说,Git是一个…...

深入解析数据处理的技术与实践
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 工💗重💗hao💗:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。 ⭐…...

python-调用c#代码
环境: win10,net framework 4,python3.9 镜像: C#-使用IronPython调用python代码_ironpython wpf-CSDN博客 https://blog.csdn.net/pxy7896/article/details/119929434 目录 hello word不接收参数接收参数 其他例子 hello word 不…...
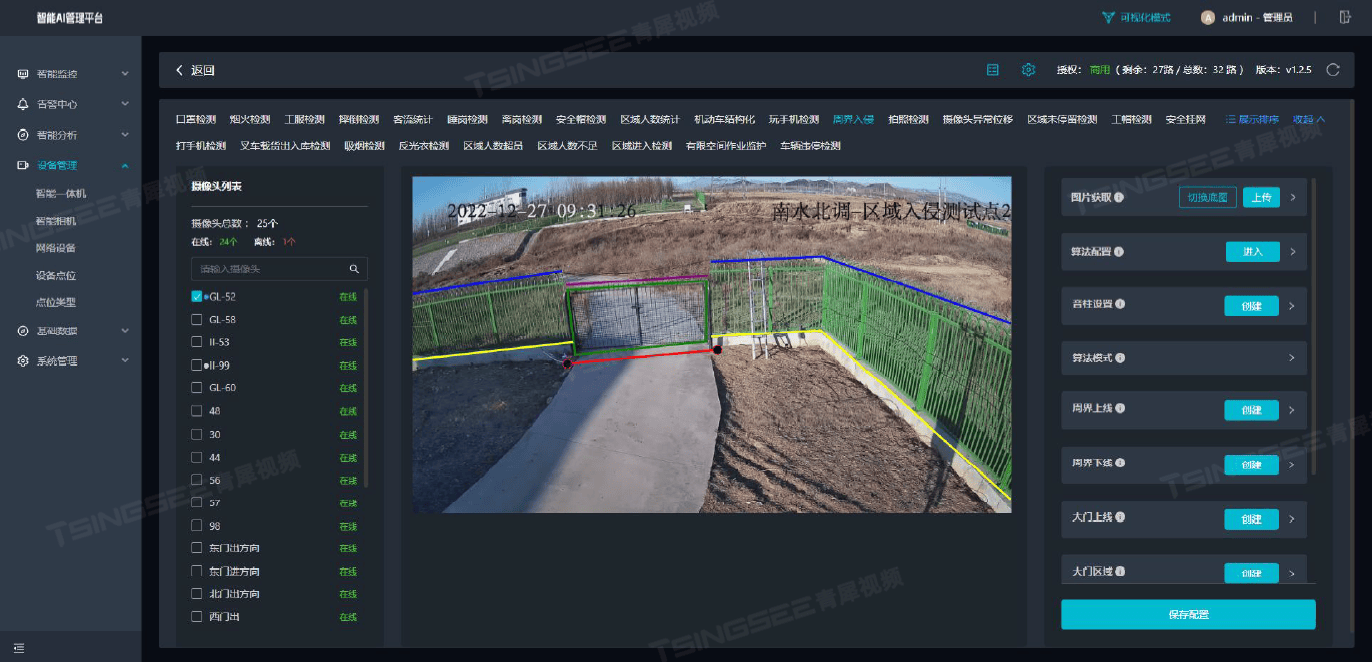
构建铁路安全防线:EasyCVR视频+AI智能分析赋能铁路上道作业高效监管
一、方案背景 随着我国铁路特别是高速铁路的快速发展,铁路运营里程不断增加,铁路沿线的安全环境对保障铁路运输的安全畅通及人民群众的生命财产安全具有至关重要的作用。铁路沿线安全环境复杂多变,涉及多种风险因素,如人员入侵、…...

openai command not found (mac)
题意:mac 系统上无法识别 openai 的命令 问题背景: Im trying to follow the fine tuning guide for Openai here. 我正在尝试遵循 OpenAI 的微调指南 I ran: 我运行以下命令 pip install --upgrade openaiWhich install without any errors.…...

鸿蒙(API 12 Beta2版)NDK开发【LLDB高性能调试器】调试和性能分析
概述 LLDB(Low Level Debugger)是新一代高性能调试器。 当前HarmonyOS中的LLDB工具是在[llvm15.0.4]基础上适配演进出来的工具,是HUAWEI DevEco Studio工具中默认的调试器,支持调试C和C应用。 工具获取 可通过HUAWEI DevEco S…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...
)
Windows11上VMware Workstation 16.1.1保姆级安装与Win11虚拟机配置全流程(含激活与优化)
Windows 11 虚拟化开发环境搭建全指南:从 VMware 安装到系统优化虚拟化技术已经成为现代开发者和运维人员的必备技能。想象一下,你正在开发一个需要跨平台测试的应用程序,或者需要在不影响主系统的情况下尝试新软件——这时候一个可靠的虚拟化…...

清华大学学位论文LaTeX模板:告别格式烦恼的终极指南
清华大学学位论文LaTeX模板:告别格式烦恼的终极指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 还在为论文格式调整而烦恼吗?清华大学thuthesis LaTeX模…...